Benha University
Convolutional Neural Network Models - Deep Learning
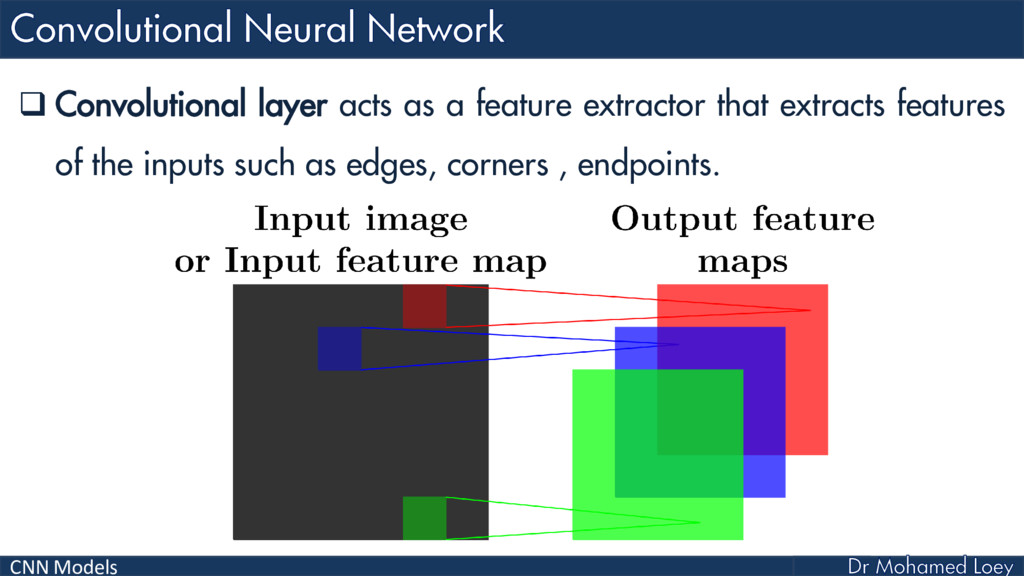
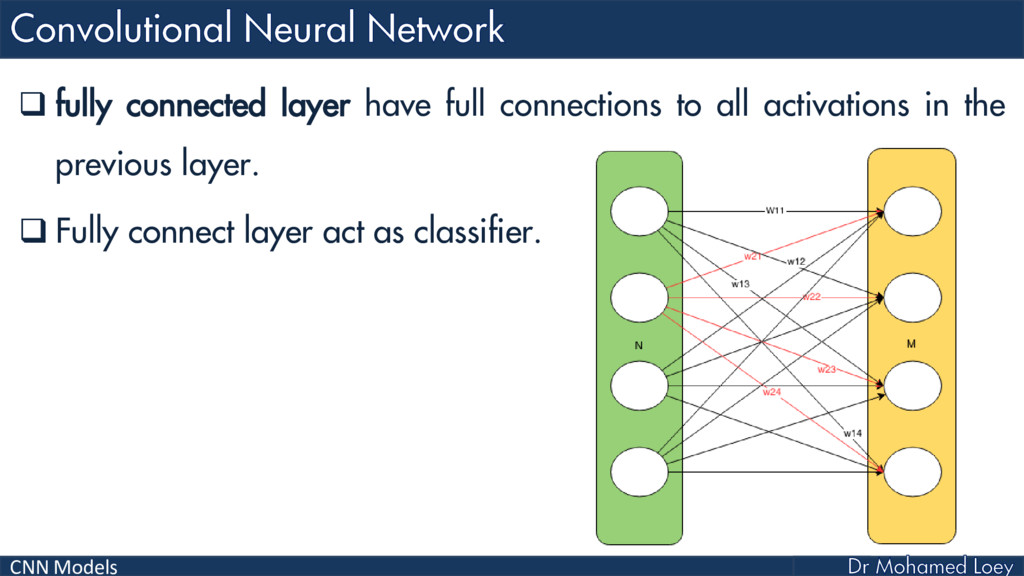
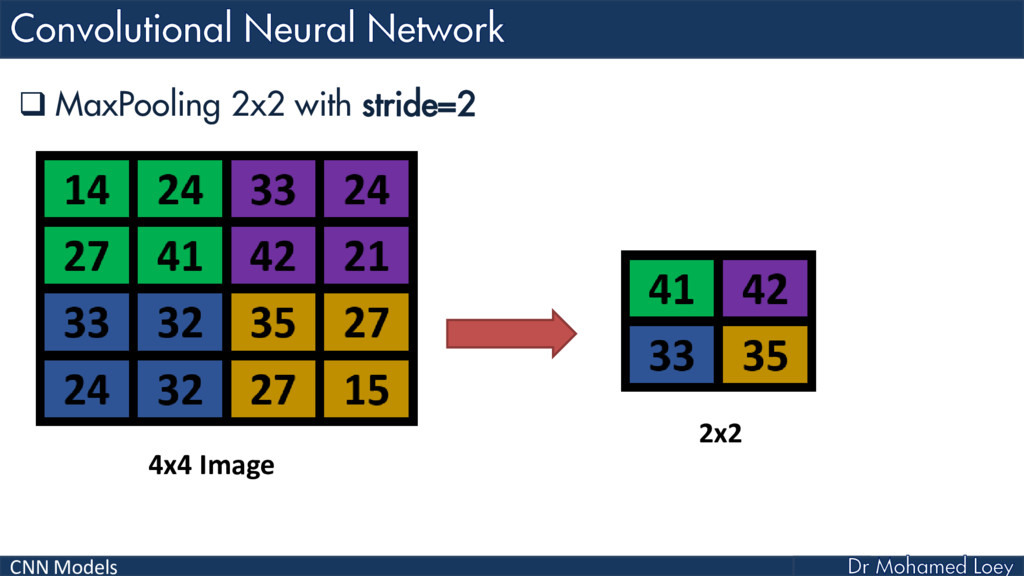
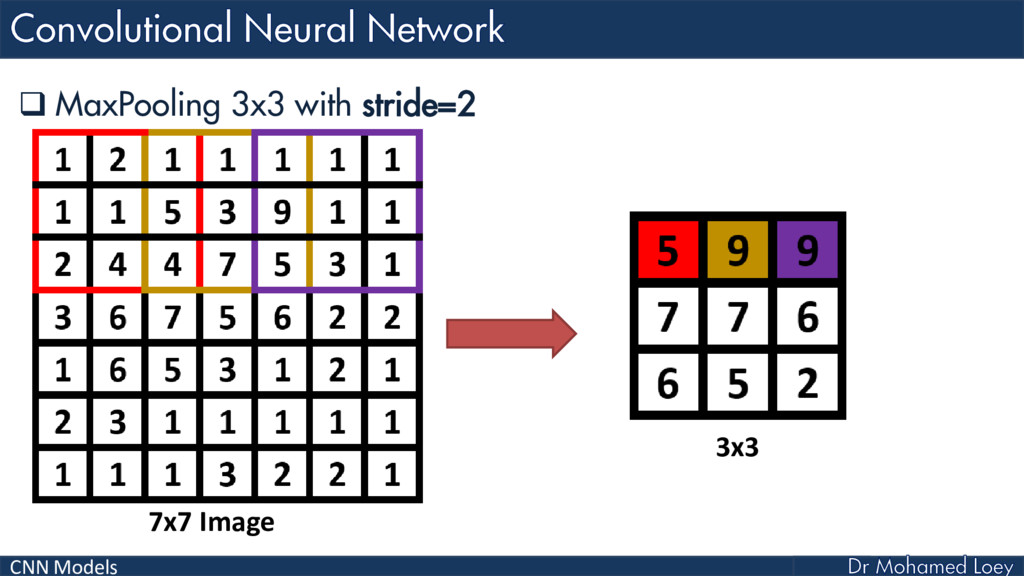
Convolutional Neural Network
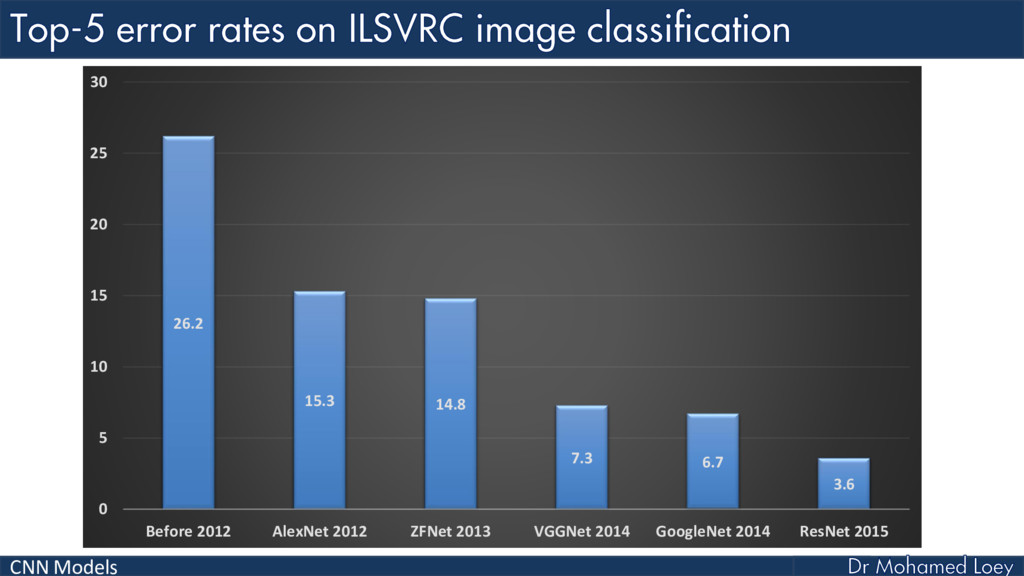
ILSVRC
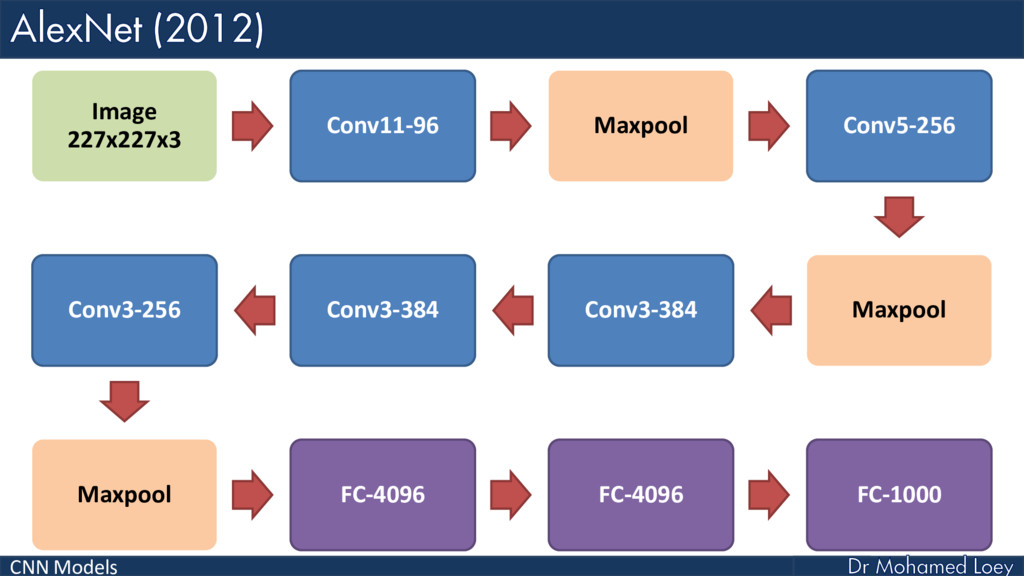
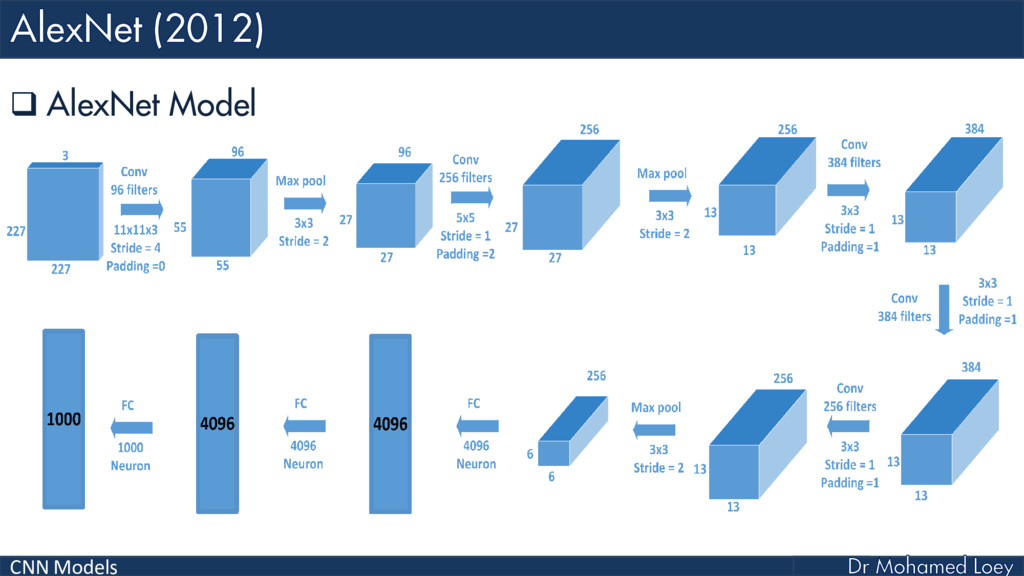
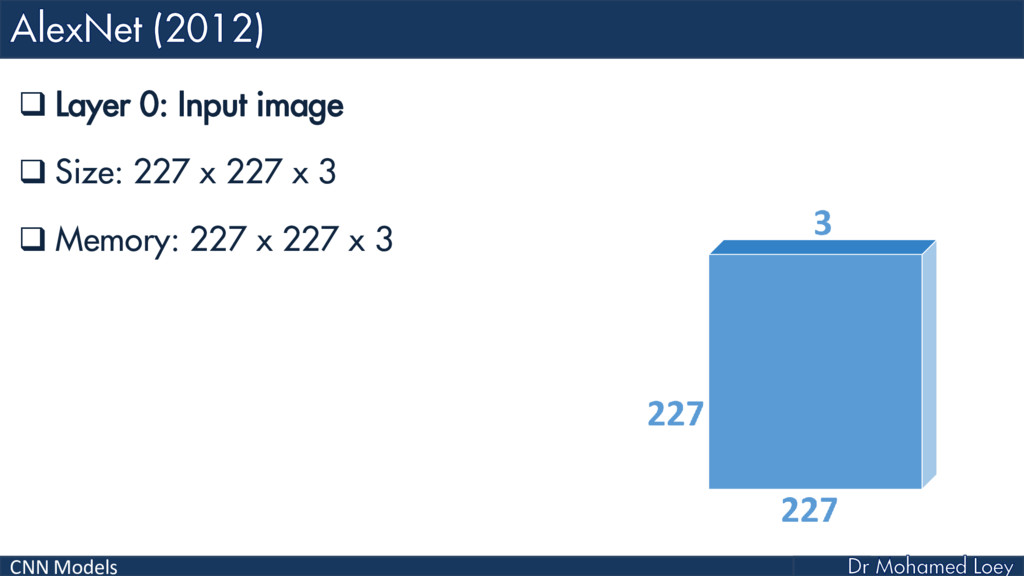
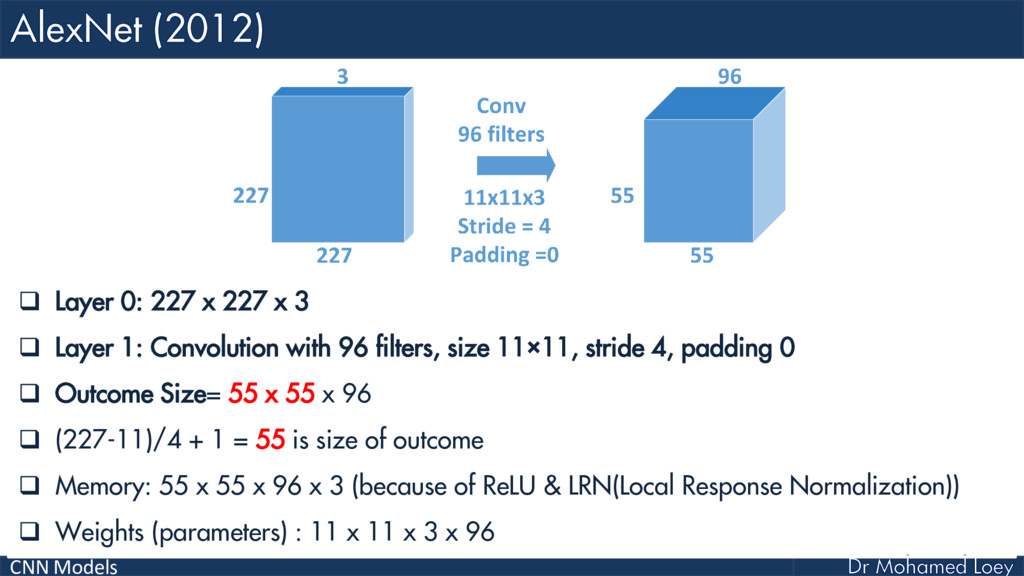
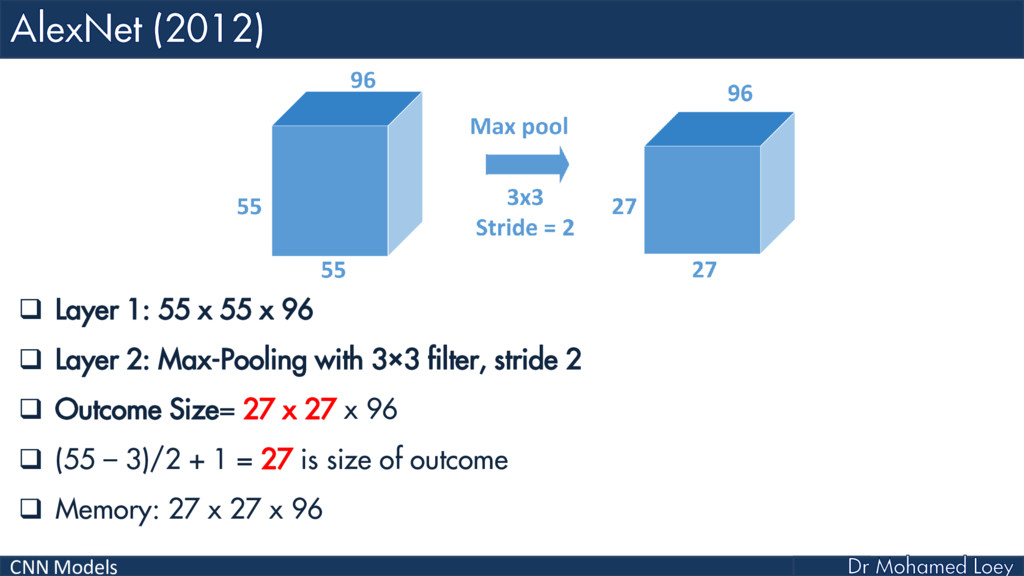
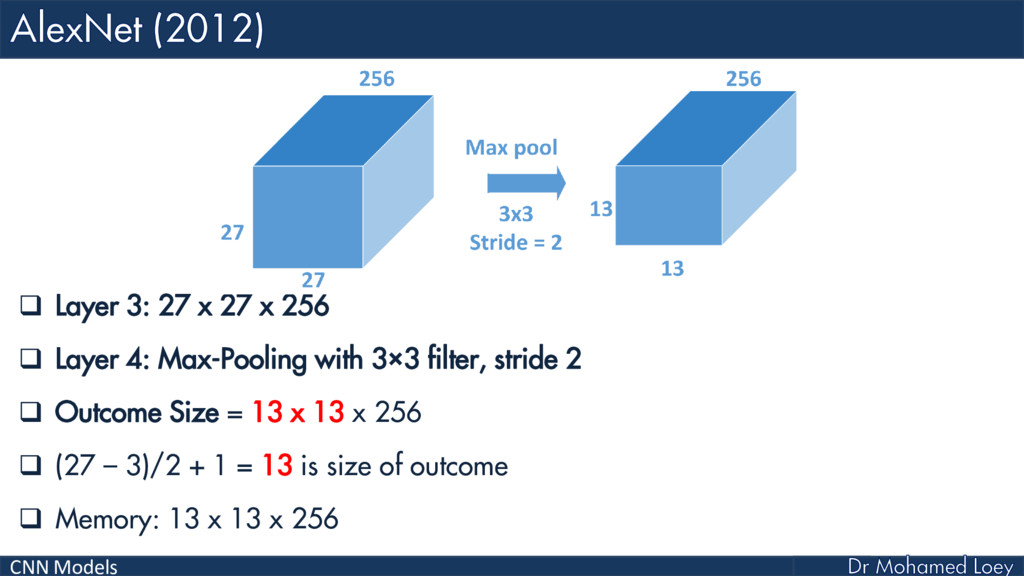
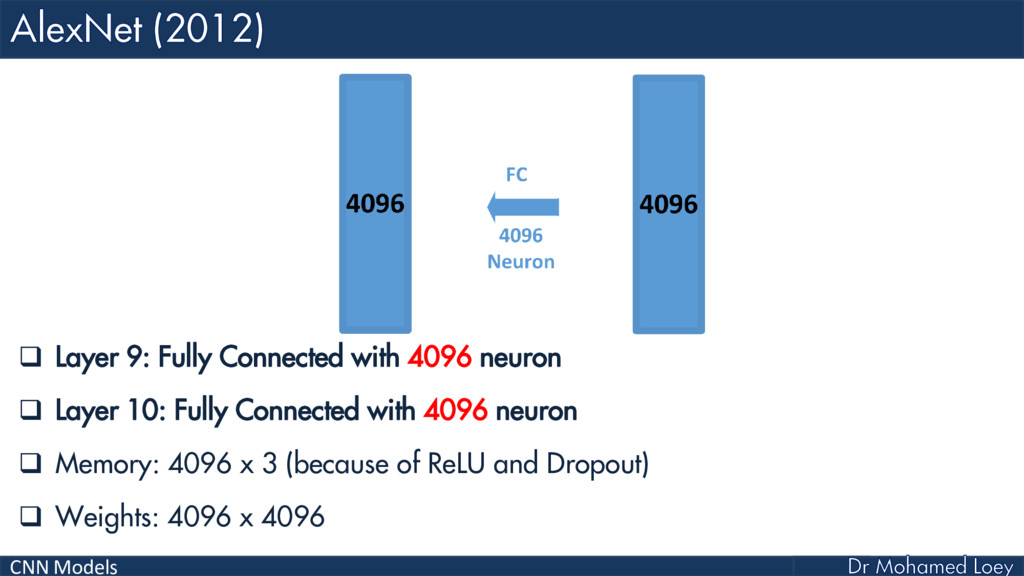
AlexNet (2012)
ZFNet (2013)
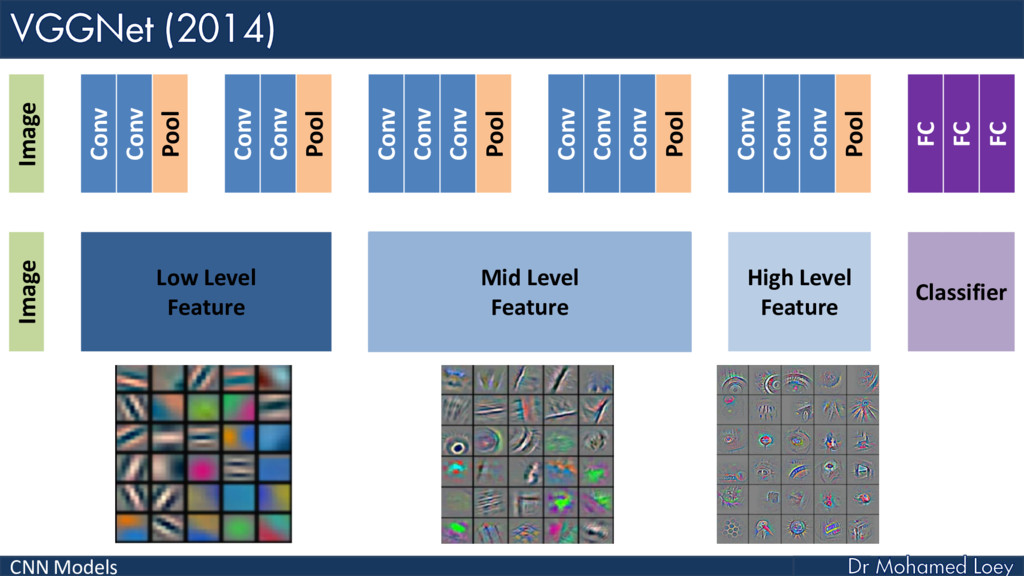
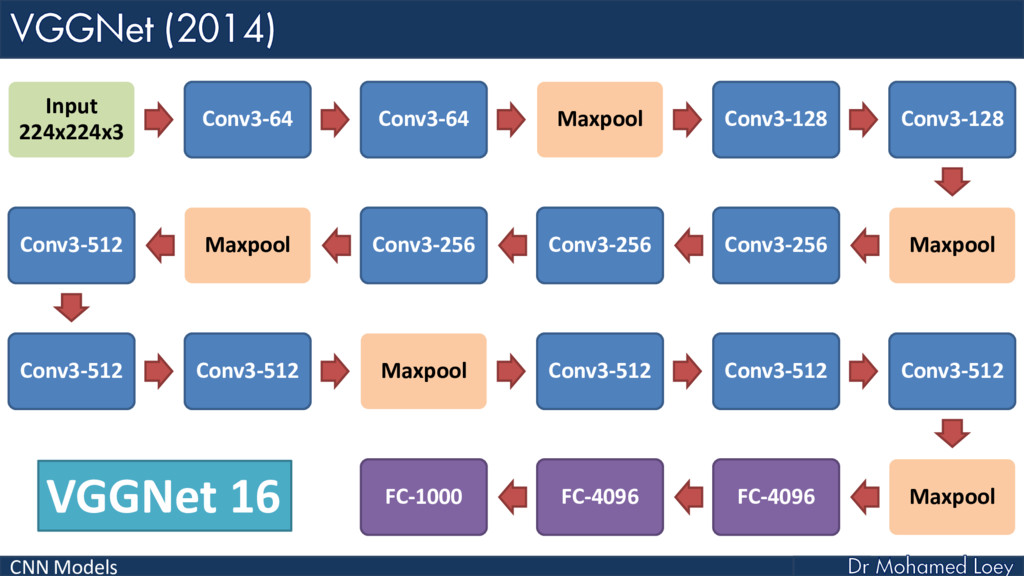
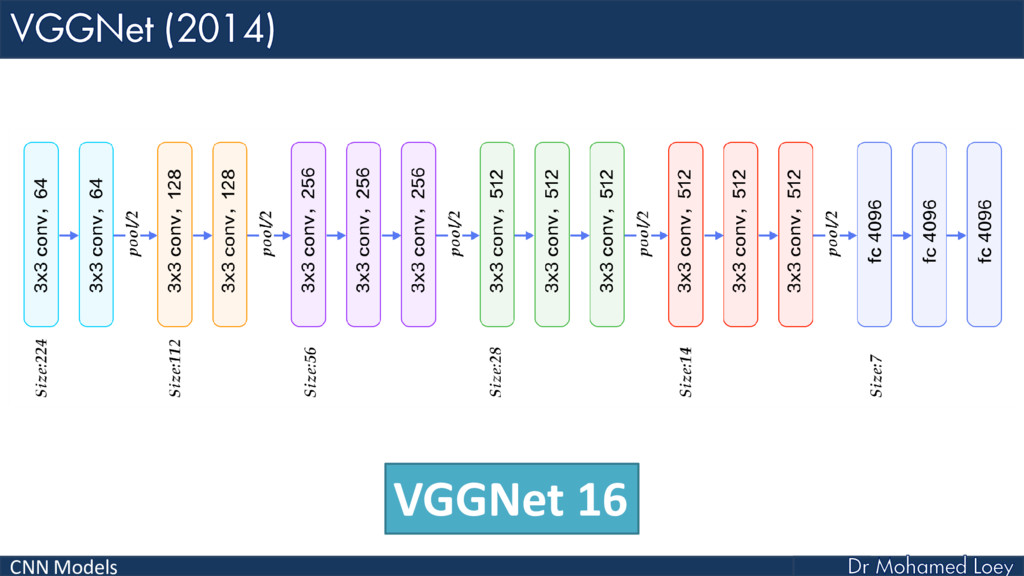
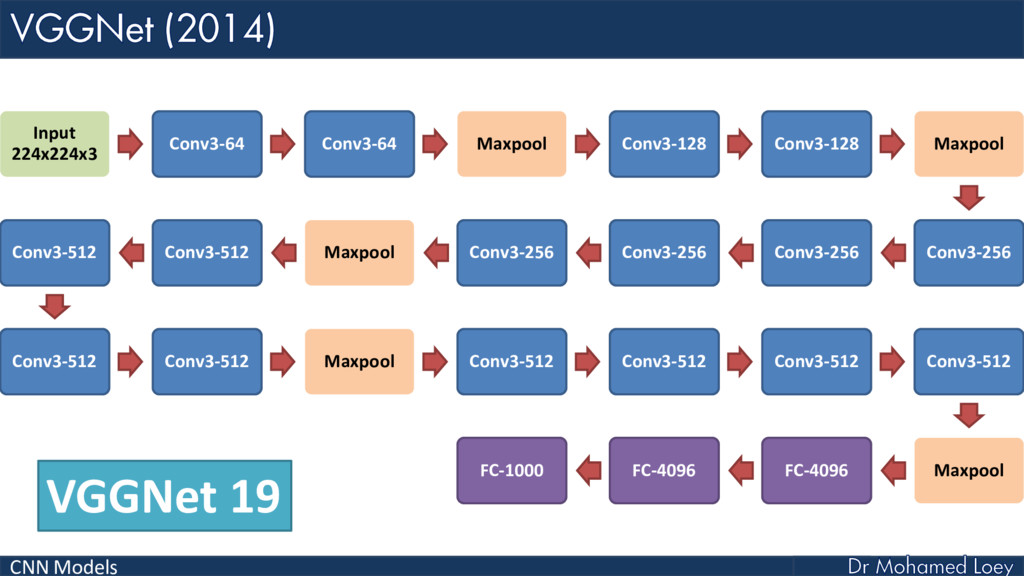
VGGNet (2014)
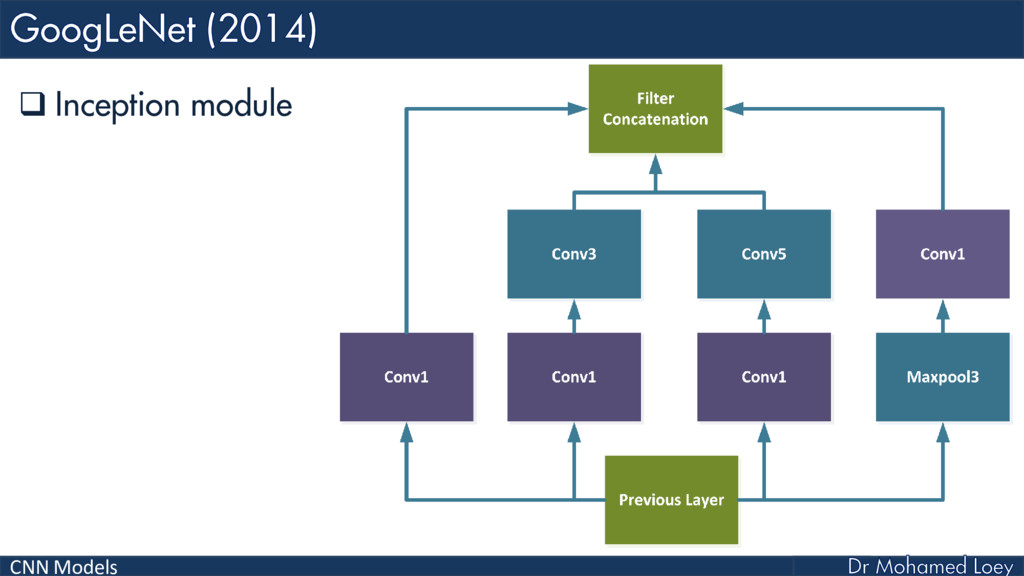
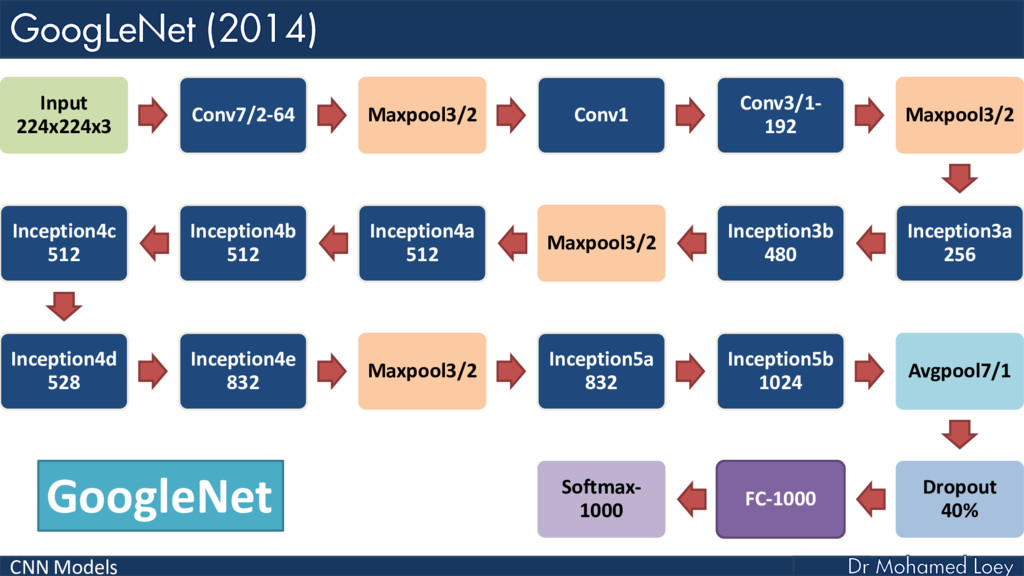
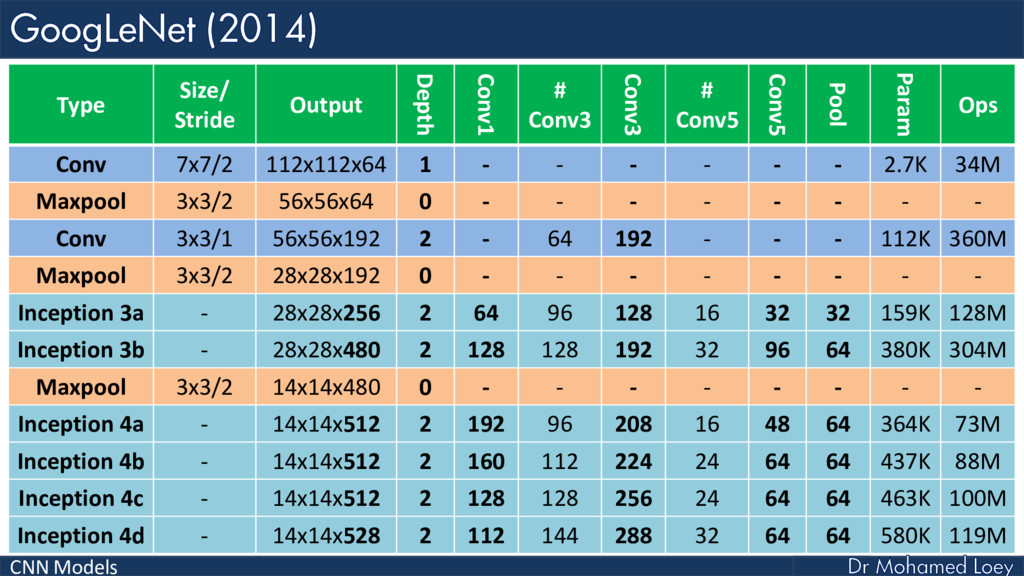
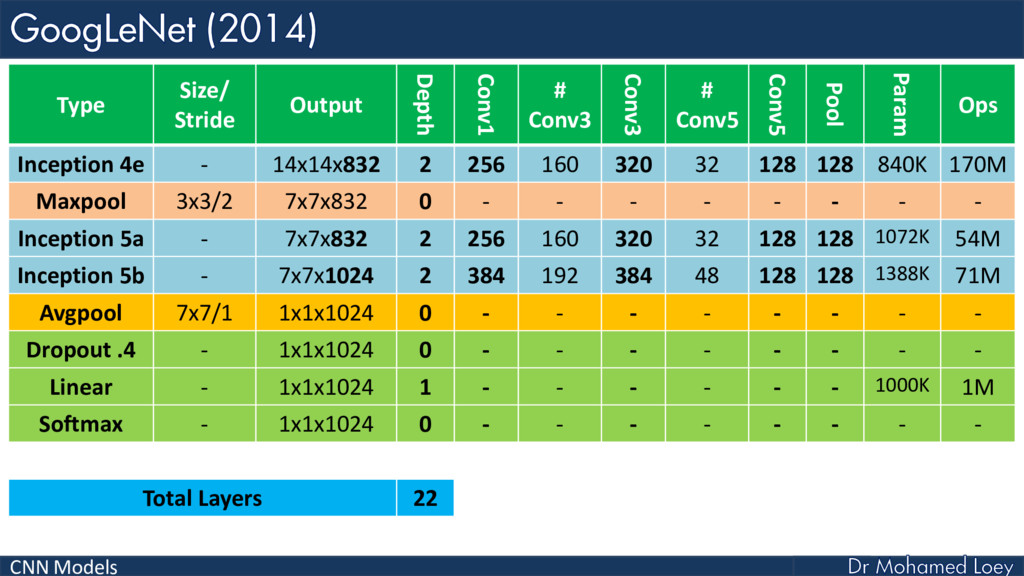
GoogleNet 2014)
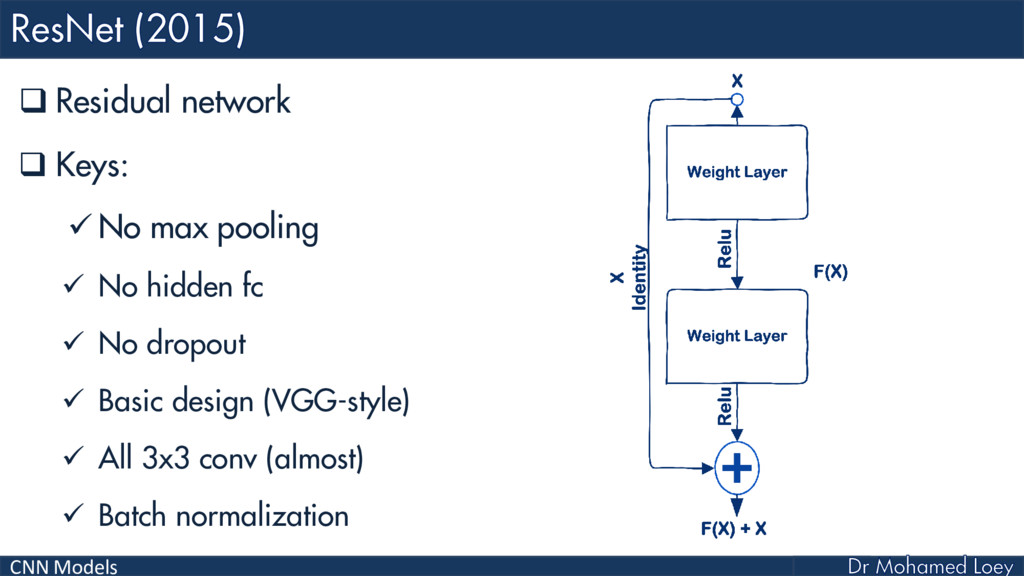
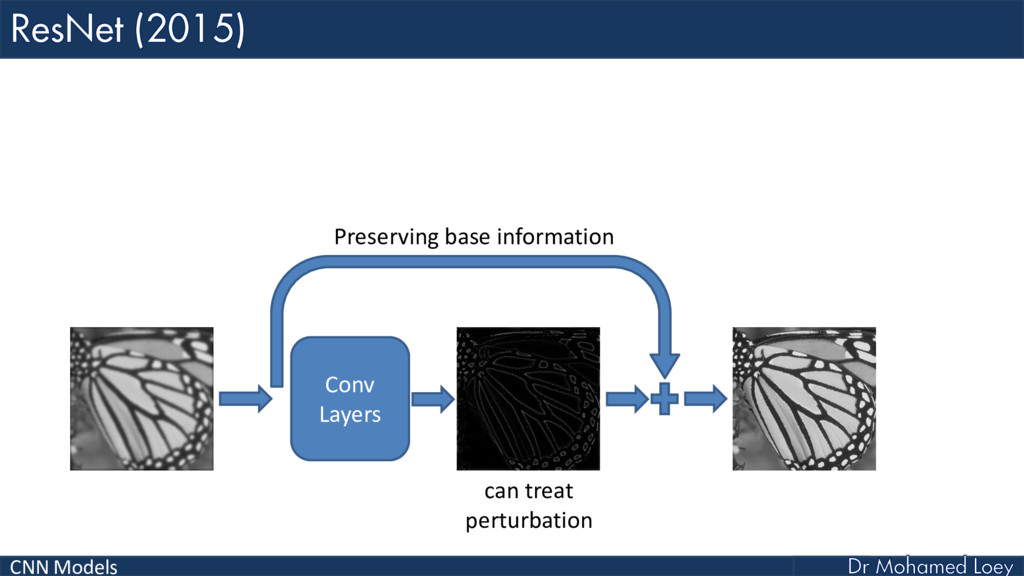
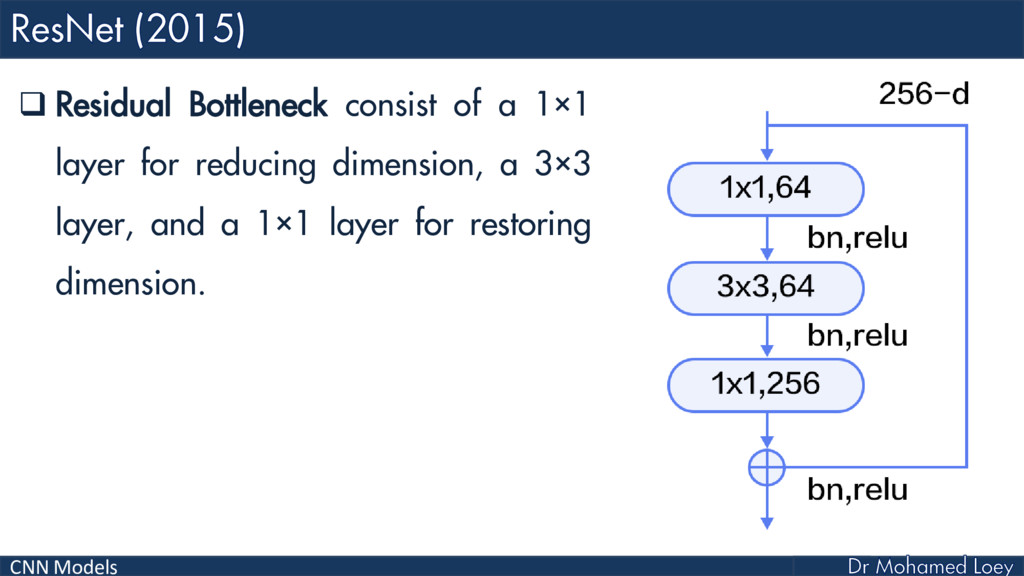
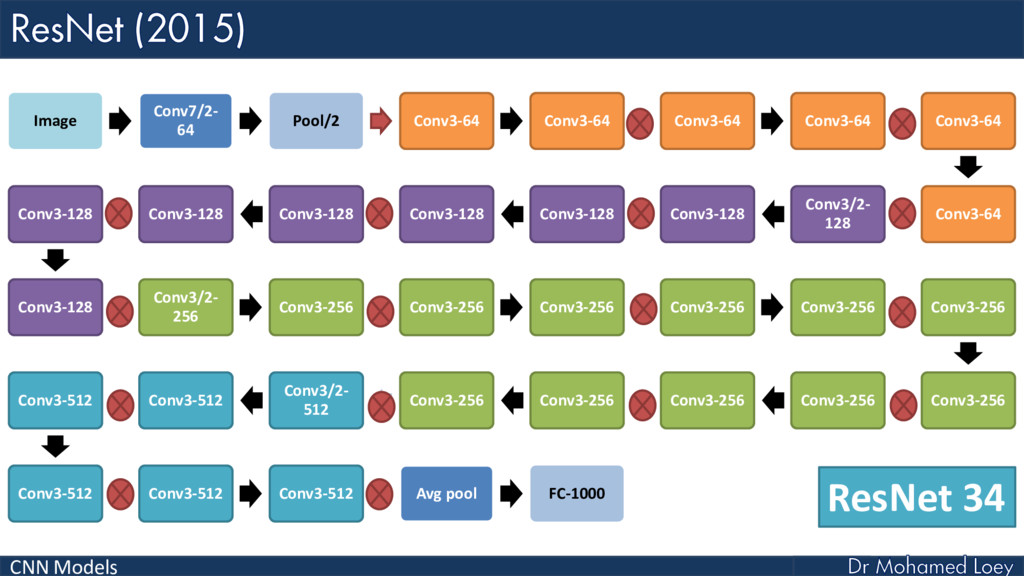
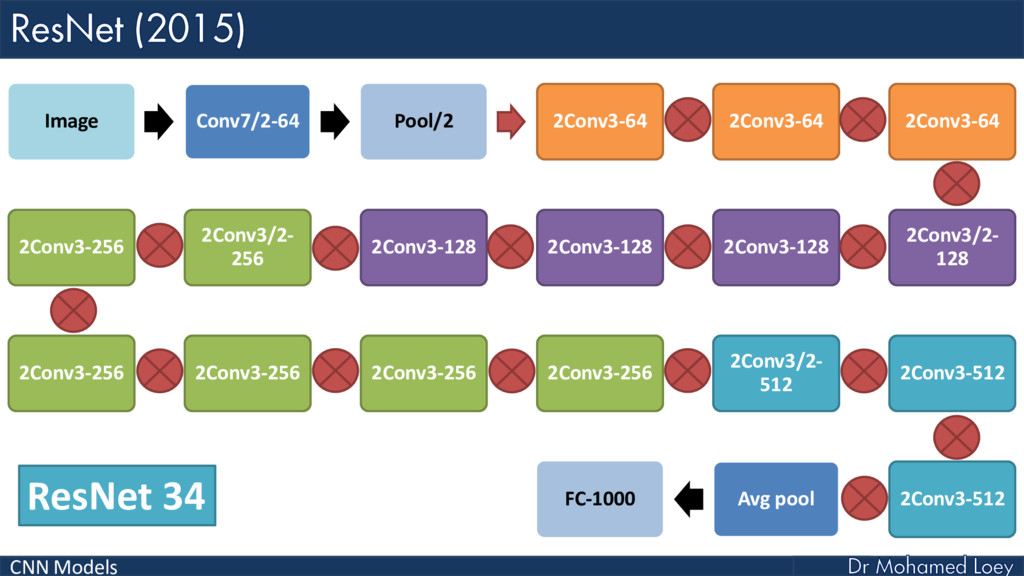
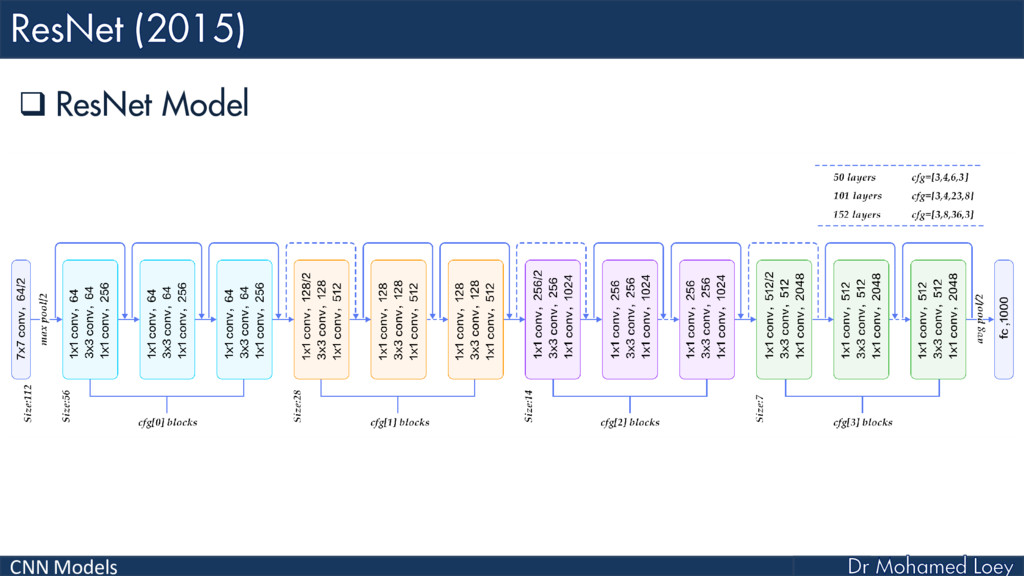
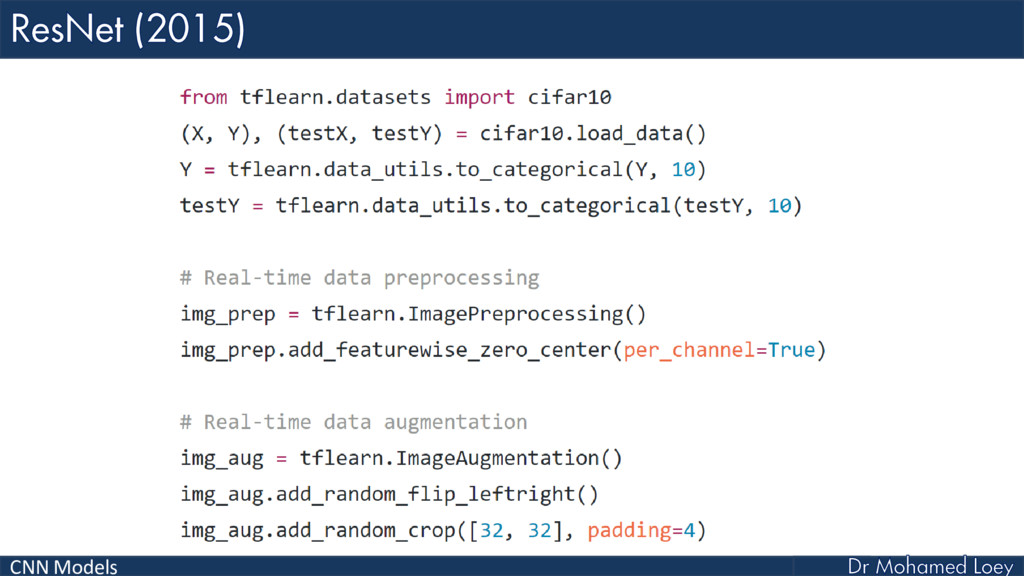
ResNet (2015)
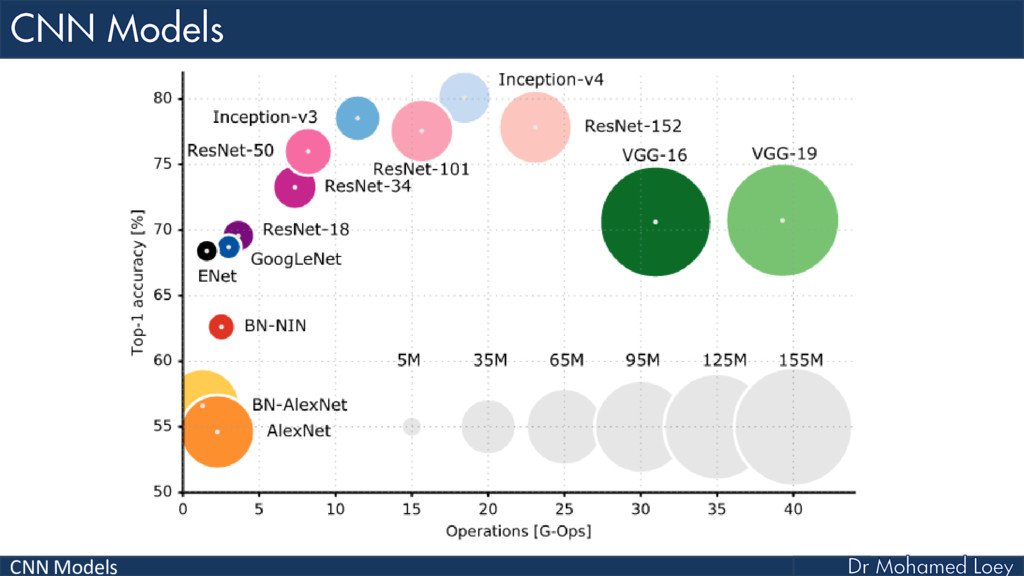
Conclusion
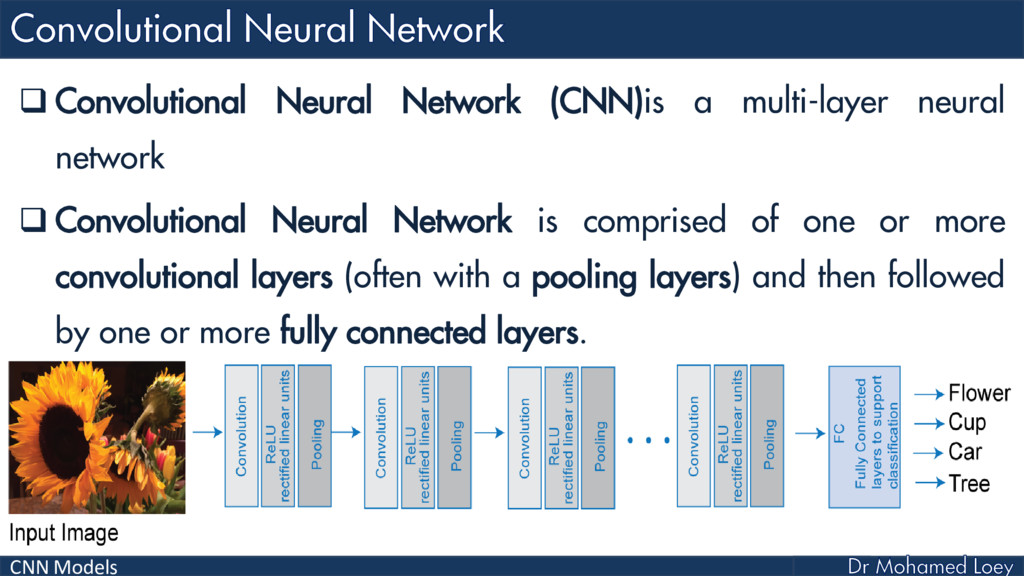
Convolutional Neural Network (CNN) is a multi-layer neural network
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
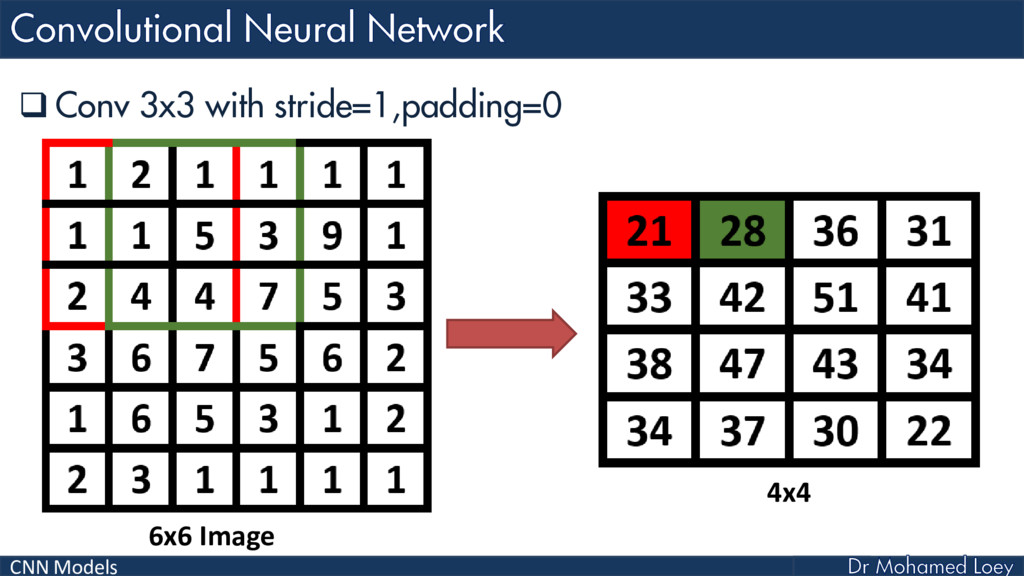{kind=link}
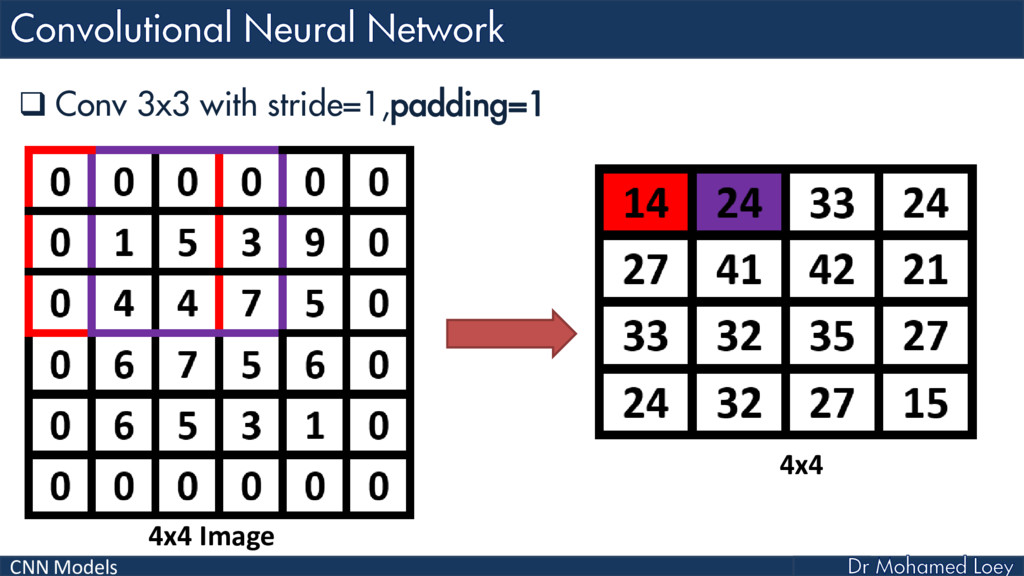{kind=link}
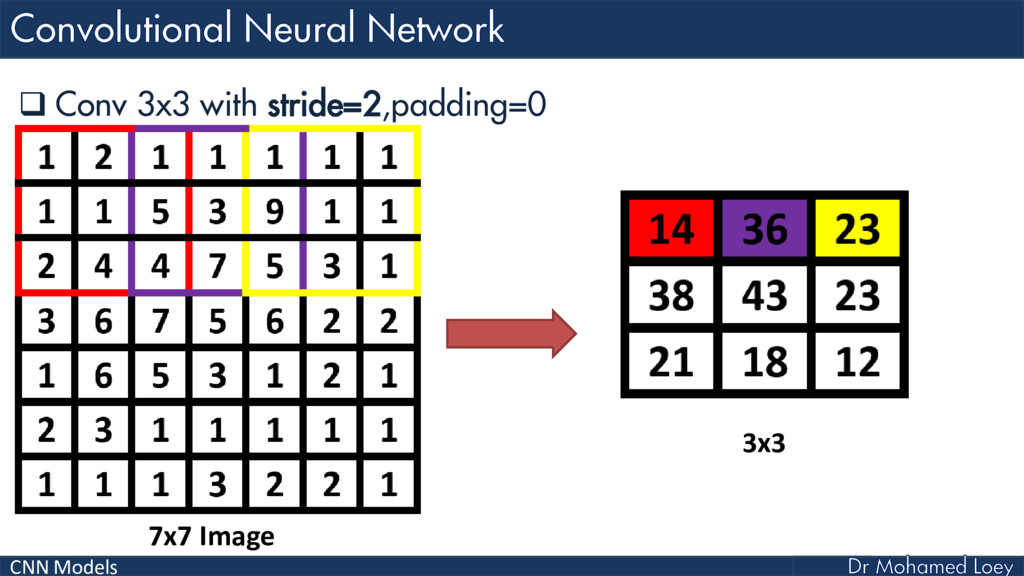{kind=link}
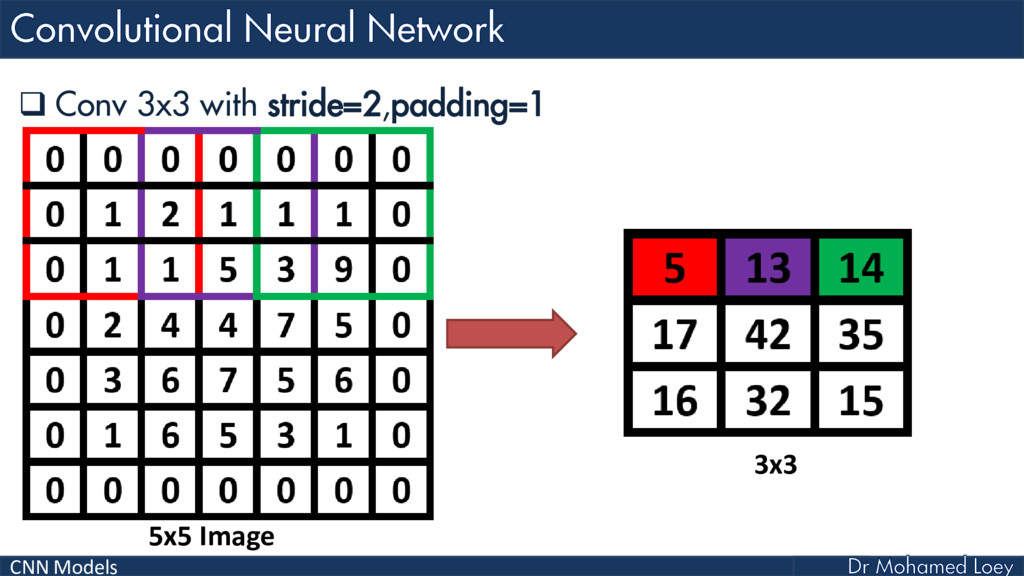{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CNN Models [227x227x3] INPUT [55x55x96] CONV1 : 96 11x11 filters](https://files.speakerdeck.com/presentations/0b48a17788194dce9bf539a2ee074c13/slide_35.jpg){kind=link}
![CNN Models [13x13x384] CONV3: 384 3x3 filters at stride 1,](https://files.speakerdeck.com/presentations/0b48a17788194dce9bf539a2ee074c13/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CNN Models facebook.com/mloey [email protected] twitter.com/mloey linkedin.com/in/mloey [email protected] mloey.github.io](https://files.speakerdeck.com/presentations/0b48a17788194dce9bf539a2ee074c13/slide_81.jpg){kind=link}
{kind=link}