Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Road to SRE NEXT@広島
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
mmorito
July 22, 2024
320
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Road to SRE NEXT@広島
mmorito
July 22, 2024
More Decks by mmorito
See All by mmorito
WEB TOUCH MEETING #123
mmorito
0
38
Google Cloud によるDICOM管理
mmorito
0
120
JBUG広島#11
mmorito
0
450
データ分析やAIの "運用" について考える
mmorito
0
520
JP_Stripes in Setouchi #01
mmorito
0
200
Cloud Native Kansai #01
mmorito
0
1.3k
Cloud Native Sapporo #01
mmorito
0
460
GAE/Jで盛大に失敗する方法
mmorito
0
670
自社サービスにStripeを導入する話
mmorito
1
890
Featured
See All Featured
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Mobile First: as difficult as doing things right
swwweet
225
10k
Visualization
eitanlees
152
17k
Skip the Path - Find Your Career Trail
mkilby
1
170
BBQ
matthewcrist
89
10k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Transcript
複数サービスを組み合わせたパイプライン に対する監視について 2024/07/20
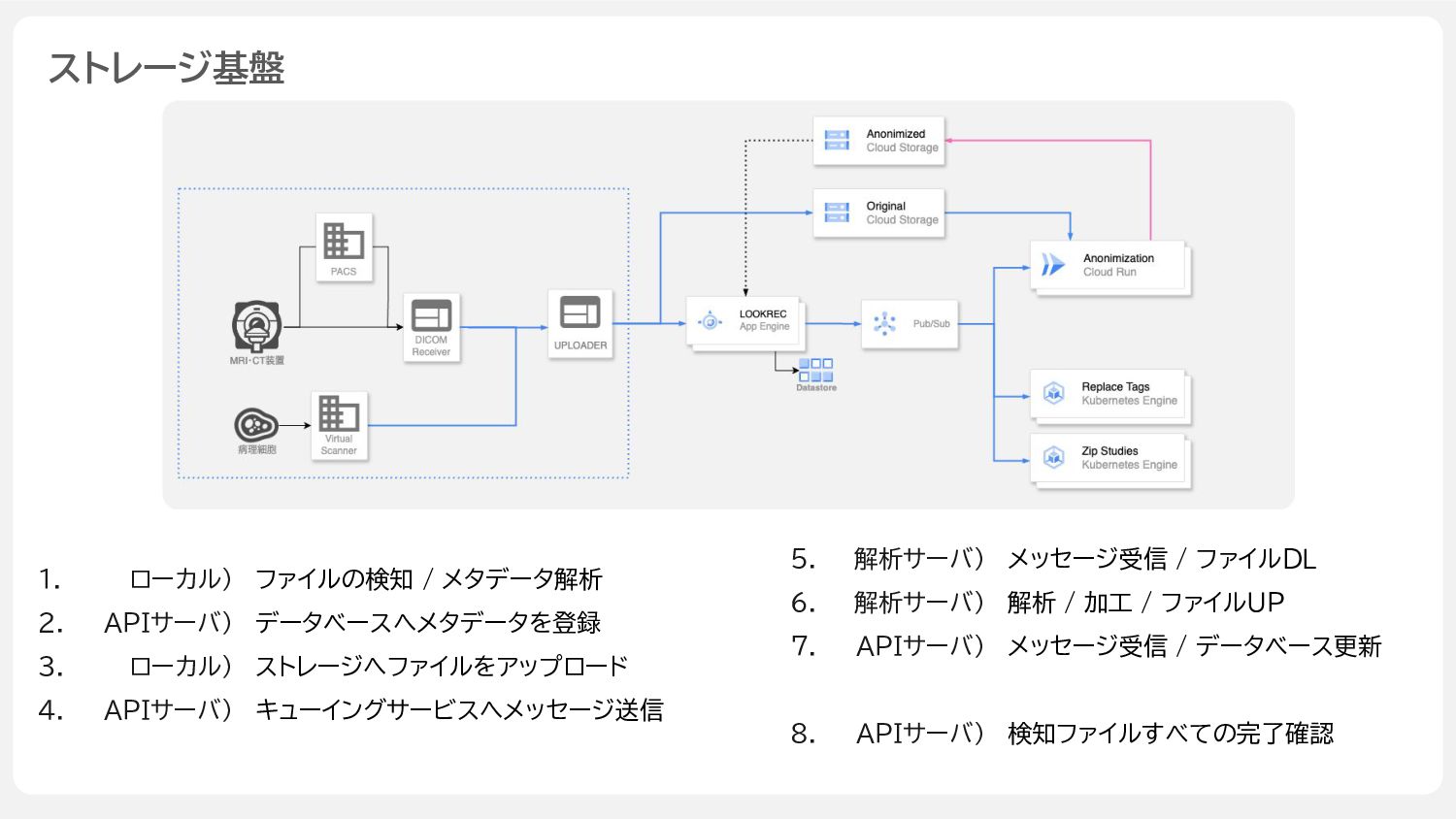
ストレージ基盤 ファイルの検知 / メタデータ解析 データベースへメタデータを登録 ストレージへファイルをアップロード キューイングサービスへメッセージ送信 ローカル) APIサーバ) ローカル)
APIサーバ) 1. 2. 3. 4. メッセージ受信 / ファイルDL 解析 / 加工 / ファイルUP メッセージ受信 / データベース更新 検知ファイルすべての完了確認 解析サーバ) 解析サーバ) APIサーバ) APIサーバ) 5. 6. 7. 8.
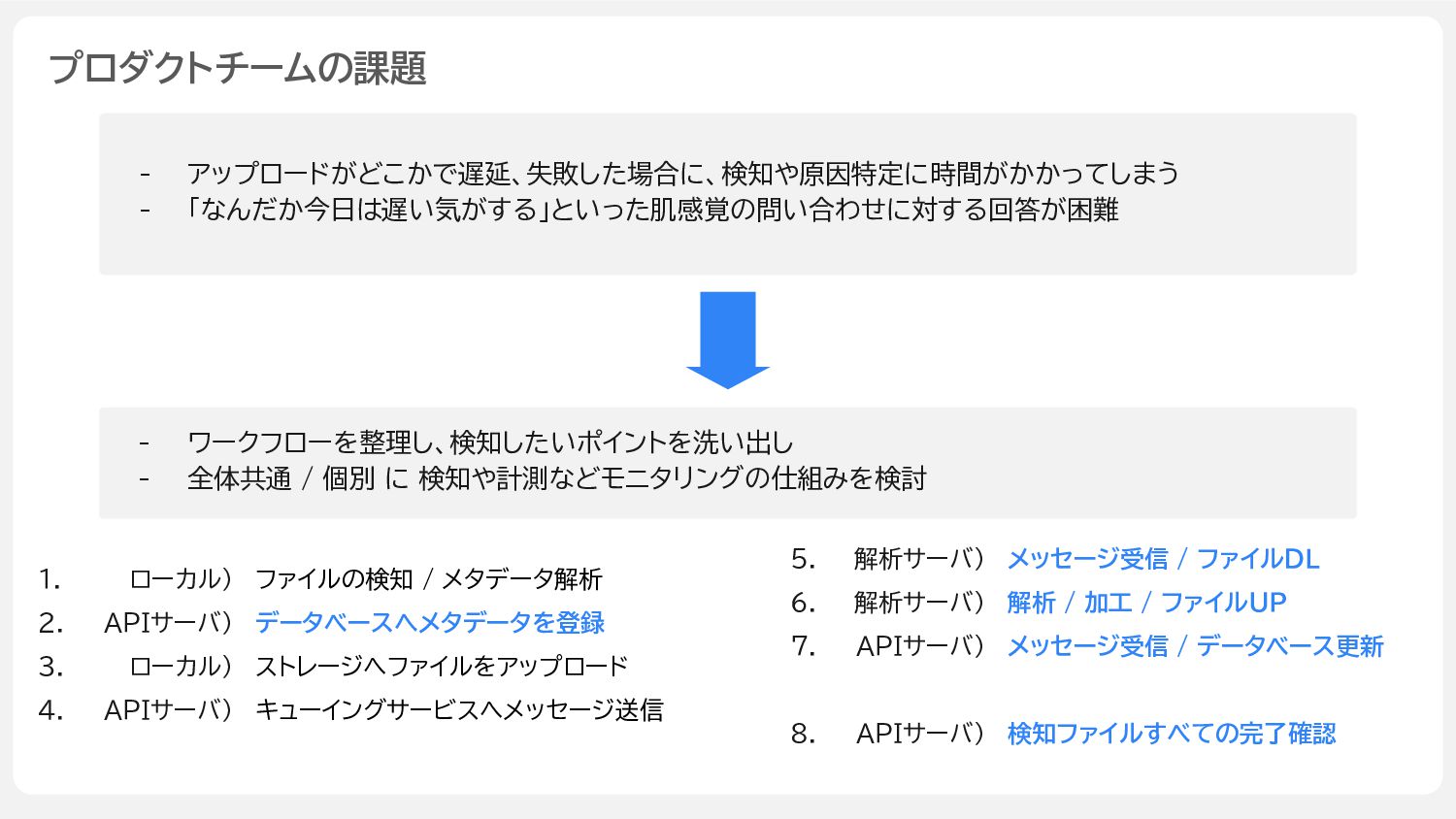
- アップロードがどこかで遅延、失敗した場合に、検知や原因特定に時間がかかってしまう - 「なんだか今日は遅い気がする」といった肌感覚の問い合わせに対する回答が困難 プロダクトチームの課題 - ワークフローを整理し、検知したいポイントを洗い出し - 全体共通 /
個別 に 検知や計測などモニタリングの仕組みを検討 ファイルの検知 / メタデータ解析 データベースへメタデータを登録 ストレージへファイルをアップロード キューイングサービスへメッセージ送信 ローカル) APIサーバ) ローカル) APIサーバ) 1. 2. 3. 4. メッセージ受信 / ファイルDL 解析 / 加工 / ファイルUP メッセージ受信 / データベース更新 検知ファイルすべての完了確認 解析サーバ) 解析サーバ) APIサーバ) APIサーバ) 5. 6. 7. 8.
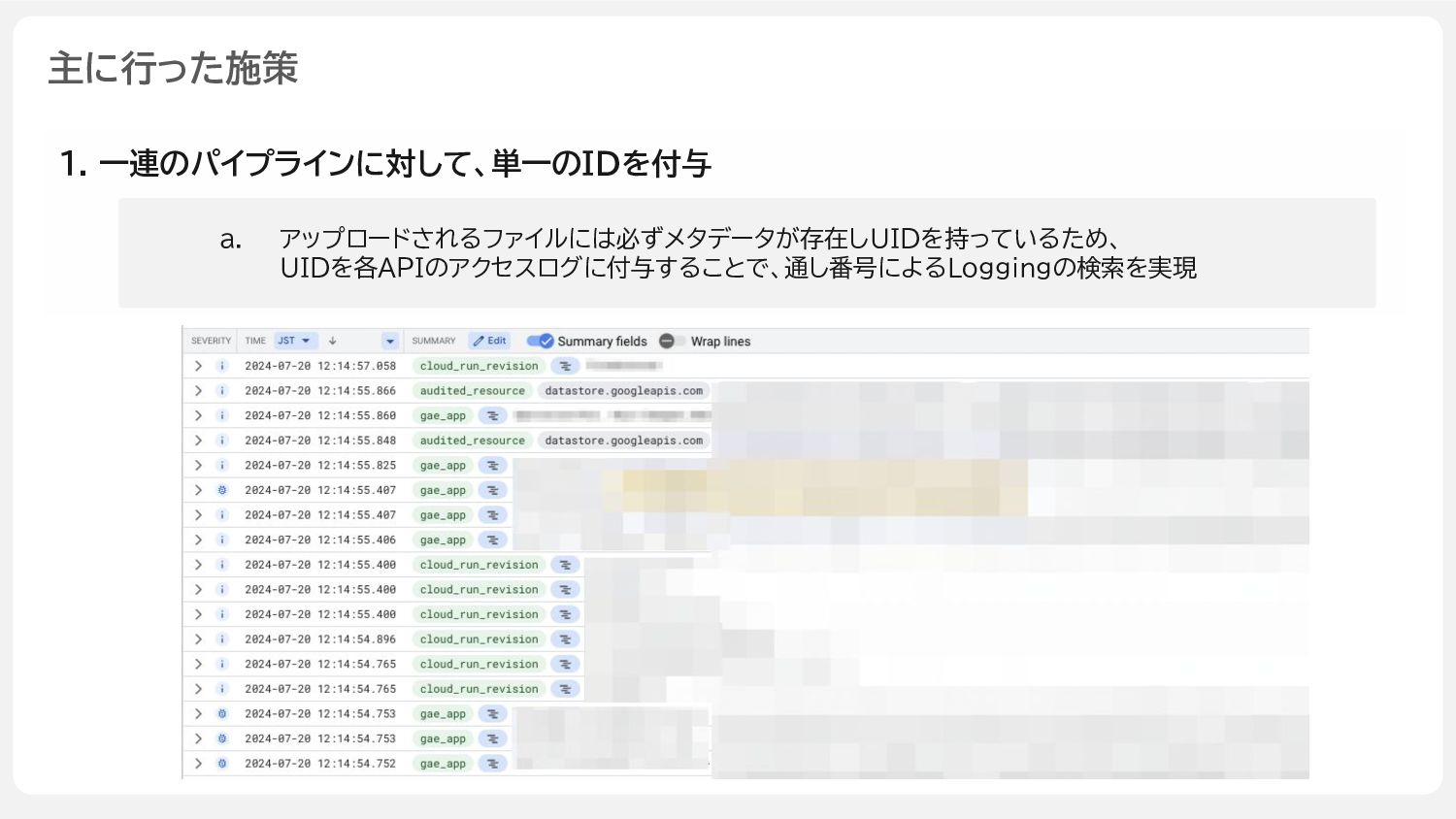
1. 一連のパイプラインに対して、単一のIDを付与 主に行った施策 a. アップロードされるファイルには必ずメタデータが存在しUIDを持っているため、 UIDを各APIのアクセスログに付与することで、通し番号によるLoggingの検索を実現
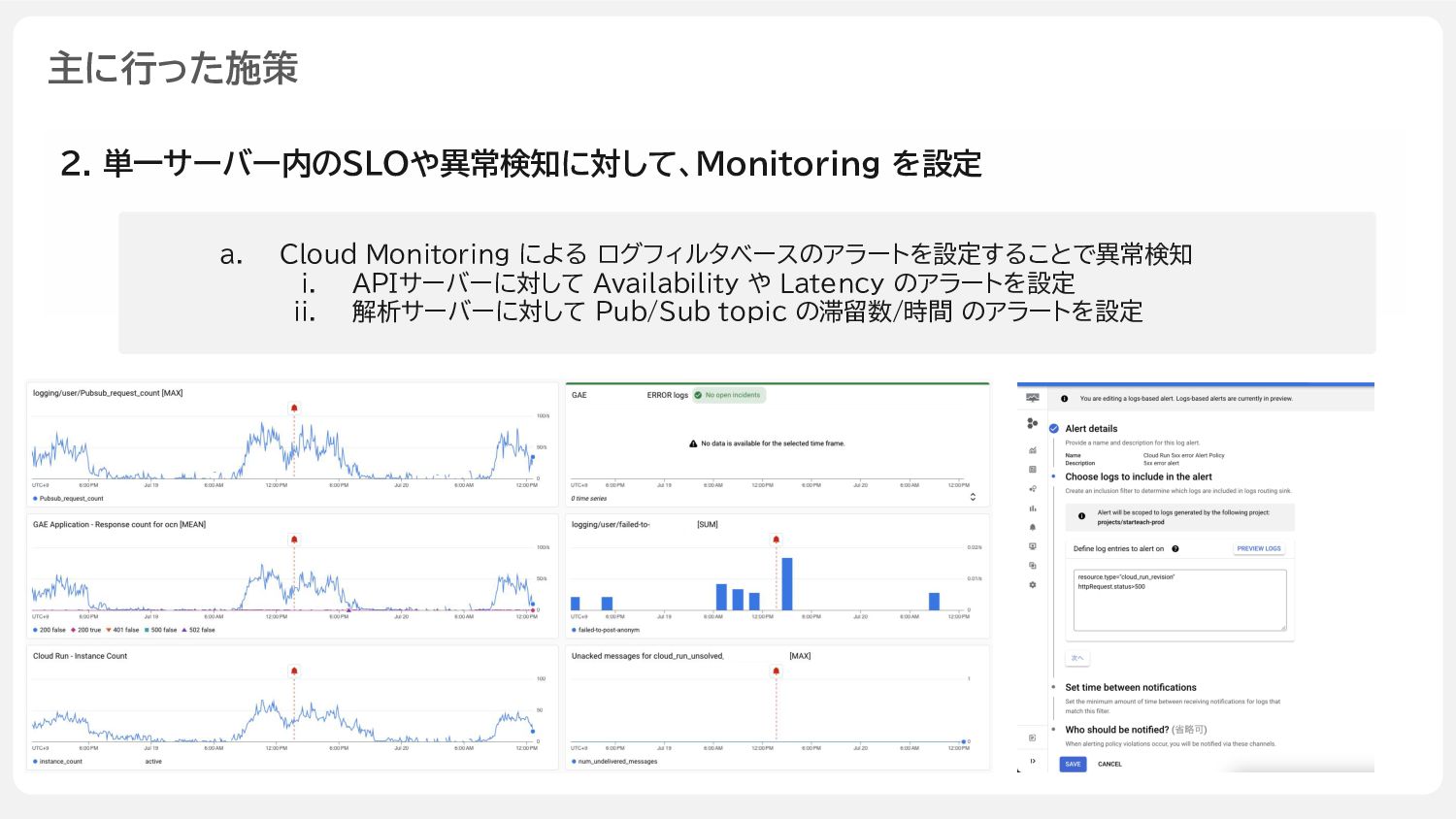
主に行った施策 2. 単一サーバー内のSLOや異常検知に対して、Monitoring を設定 a. Cloud Monitoring による ログフィルタベースのアラートを設定することで異常検知 i.
APIサーバーに対して Availability や Latency のアラートを設定 ii. 解析サーバーに対して Pub/Sub topic の滞留数/時間 のアラートを設定
主に行った施策 a. 本来実行されるはずの後続処理が何故か実行されず途中で止まってしまう → 完了確認のタスクに対して、即時Slack通知を行うよう設定 b. 「なんだか今日は遅い気がする」 対策 → Cloud
Logging を BigQuery へ ストリーミングで同期し、 SQLのテンプレートを作成して 単一 / ロット でどの程度時間がかかっているか計測 素早く問題の切り分けが行える仕組みづくりを検討 3. ログからは救済困難な失敗、遅延に対して個別の検知手段を検討
成果や新たな課題 - 問題が起きた場合に、ユーザー問い合わせより先にある程度の検知が可能 - 調査を効率化することができたことにより、これまで属人化していた調査を、 プロダクトチームやサポートチームである程度実施可能 - 調査にはSQLを直接修正してBigQueryへクエリ発行する必要があるなど、 若干非エンジニアでは対応しづらい、コスト感覚の教育が行き届かないなどの問題があるため、 ノーコードツールなどを導入して調査がし易い環境を作る必要がある
- Logging の検索しやすさなど、細かい課題がまだまだあるため、継続検討は必要 - ローカル側の問題(インターネットの遅延やオペレーションミスなど)に対して、あまり有効な対策が 打てていないため、カバー範囲を広げていく必要がある - 検知はできても、ユーザー起因 + Google側の仕様で見守るしかない問題なども発生 → 問題発生時に無関係なユーザーを巻き込まない設計なども継続して検討が必要
おしまい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}