Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
需要関数推定入門 実践編 / Practical Demand Estimation
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
mns
May 29, 2021
Research
1.4k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
需要関数推定入門 実践編 / Practical Demand Estimation
TokyoR #92で発表したスライドです。
サンプルコードは以下。
https://github.com/mns54/tokyor-demand-estimation
mns
May 29, 2021
More Decks by mns
See All by mns
需要関数推定入門 / Introduction to Demand Estimation
mns54
3
1.7k
操作変数法入門
mns54
0
3.1k
Other Decks in Research
See All in Research
NLP colloquium: AI Safety Survey
kanekomasahiro
0
540
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
200
「車1割削減、渋滞半減、公共交通2倍」を 熊本から岡山へ@RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
1
1.1k
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
2
270
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
120
Any-Optical-Model: A Universal Foundation Model for Optical Remote Sensing
satai
3
810
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
120
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
520
IEEE AIxVR 2026 Keynote Talk: "Beyond Visibility: Understanding Scenes and Humans under Challenging Conditions with Diverse Sensing"
miso2024
0
200
姫路市 -都市OSの「再実装」-
hopin
0
1.7k
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
940
量子コンピュータの紹介
oqtopus
0
320
Featured
See All Featured
Why Our Code Smells
bkeepers
PRO
340
58k
Google's AI Overviews - The New Search
badams
0
1k
Building the Perfect Custom Keyboard
takai
2
790
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
770
Marketing to machines
jonoalderson
1
5.4k
HDC tutorial
michielstock
2
690
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
600
The browser strikes back
jonoalderson
0
1.2k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
210
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
190
Transcript
需要関数推定⼊⾨ 実践編 @mns_econ TokyoR #92 2021/05/29 1
⾃⼰紹介 • Twitter: @mns_econ • 経済学専攻の⼤学院⽣ • 専⾨は実証産業組織論(多分) • TokyoR
#86「操作変数法⼊⾨」#89「需要関数推定⼊⾨」 • 今回は「需要関数推定⼊⾨」の続き • Rばかり触ってたらPython完全に忘れた • pandas.DataFrame.transformって何?? 2
需要関数の推定 本発表はTokyoR #89「需要関数推定⼊⾨」の続き https://speakerdeck.com/mns54/introduction-to-demand-estimation (前回発表の内容を知らなくても⼤丈夫…のはず) 価格や属性を変えたら売上どう変わるか知りたい! → 需要関数を推定しよう! 3 どうしたら利益
増えるかな…
Part 1 理論編 4
離散選択モデル • 消費者の購買⾏動を「離散選択」のフレームワークでモデリング • 消費者は選択肢の中から「最も効⽤が⾼い」商品を選ぶ • 選択肢には「何も買わない」も含まれる 式で書くと… • 消費者iが商品j=0,1,...,Jから得られる効⽤をUij
とする • ∀k≠j Uij ≥Uik のとき商品jを買う 5
離散選択モデル(ロジットモデル) • 「効⽤」の中⾝を以下のように定義 (市場t=1,..,T) 𝑢!"# = 𝛼𝑝"# + 𝛽𝑋"# +
𝜉"# + 𝜀!"# = 𝛿"# + 𝜀!"# δjt は商品jの「平均効⽤」 ξjt は商品jのセグメントtにおける観察できない特徴 εijt はi.i.d.なショック→消費者の異質性、消費者の認知の誤差 • εがガンベル分布(第⼀種極値分布)に従うと仮定すると… • 消費者iが商品jを買う確率 Pr 𝑢!"# ≥ 𝑢!$# ∀𝑘 ≠ 𝑗 = exp(𝛿"# ) 1 + ∑% exp(𝛿%# ) 6
離散選択モデル(ロジットモデル) • 消費者iが商品jを買う確率をiについて⾜し合わせていくと… → 市場シェア • ただし「何も買わない」の市場シェアも必要 → 商品jのセグメントtでの売上数量qjt を潜在的な市場規模Mt
で割る 𝑠"# = 𝑞"# 𝑀# , 𝑠&# = 1 − > "'( ) 𝑠"# • 前ページの選択確率をシェアとすると 𝑠!" = exp(𝛿!" ) 1 + ∑# exp(𝛿#" ) , 𝑠$" = 1 1 + ∑# exp(𝛿#" ) 7
離散選択モデル(ロジットモデル) • sjt をs0t で割ると… 𝑠"# 𝑠&# = exp(𝛿"# )
• 対数を取ると… ln 𝑠"# − ln 𝑠&# (= 𝛿"# ) = 𝛼𝑝"# + 𝛽𝑋"# + 𝜉"# ξjt は商品jのセグメントtにおける観察できない特徴 • sjt , s0t , pjt , Xjt はデータから観察できる • ξjt を誤差項と捉えると… →OLSでα, βを推定できる! 8
反実仮想分析 • α, βを推定できたら何が嬉しいの? • 離散選択モデルは消費者の⾏動をモデリングしたもの →反実仮想分析: 実際と異なる施策を「もし」やっていたらどうなった? • 例:
商品jの価格を𝑝! → / 𝑝! に変えると売上どうなる? (10%値下げとか) • 商品jの予測される平均効⽤ 0 𝛿! = 1 𝛼 / 𝑝! + 3 𝛽𝑋! • その他の商品の平均効⽤の予測値 3 𝛿% = 1 𝛼𝑝% + 3 𝛽𝑋% • 商品jの反実仮想シェア ̃ 𝑠! = exp( 0 𝛿! ) 1 + ∑% exp( 3 𝛿%) 9
補⾜: 反実仮想分析の信頼区間 • 実務での意思決定には予測の「幅」が必要→信頼区間 • 反実仮想シェアの標準誤差は解析的に導出できる • シェアと平均効⽤をベクトル表記 𝒔 =
𝒔 𝜹 , 𝜹 = 𝑋𝜷 + 𝝃 • 推定された; 𝜷の分散共分散⾏列が𝑉& 𝜷 のとき1 𝒔 = 𝒔 ; 𝜹 の分散共分散⾏列は 𝑉( 𝒔 = 𝑆𝑋𝑉& 𝜷 𝑋*𝑆*, 𝑆 = 𝜕𝒔 ; 𝜹 𝜕𝜹* ただし +,! +-! = 1 − 𝑠! 𝑠! , +,! +-" = −𝑠! 𝑠% (𝑘 ≠ 𝑗) cf. デルタ法 𝑛 ; 𝜷 − 𝜷 →. 𝑁(0, 𝑉/ )のとき 𝑛 𝒇 ; 𝜷 − 𝒇 𝜷 →. 𝑁 0, 𝐹 𝜷 𝑉/ 𝐹 𝜷 * ただし𝐹 𝜷 = +𝒇 𝜷 +𝜷# 10
でも問題点も… • 問題点1: データから観察できない商品属性ξjt を単なる誤差項としている • データから捉えられないブランド⼒とかあるのでは? • 問題点2: 価格と数量には内⽣性がある
• 需要と供給から価格と数量は同時に決定される • 「価格→数量」の因果関係は単純にデータを⾒るだけでは取り違える場合がある • 例: ホテルの空室率と価格の関係→価格上げると空室が埋まる? • 問題点3: IIA特性により商品間の代替関係をうまく捉えられない • 商品jと商品kのシェアの⽐は他の商品のシェアに依存しない • 例: コカコーラの価格が上がったときペプシとカルピスのシェアは同じ割合で増加 • 現実はペプシのほうがコカコーラ値上げの影響を⼤きく受けそう →解決策あります! 11
問題点1: 観察できない商品属性 • データから観察できない商品属性ξjt を単なる誤差項にするのは…? • 価格が⾼い商品はブランド⼒も⾼くて消費者の効⽤が⾼い場合もありそう • 以下のように定式化を変更 ln
𝑠!" − ln 𝑠$" = 𝛼𝑝!" + 𝛽𝑋!" + 𝜉! + ∆𝜉!" • ξj は商品jの固定効果 • 推定上は「商品jダミー」変数を⼊れる • Δξjt を誤差項として捉える→問題なさそう? 12
問題点2: 価格と数量の内⽣性 • 内⽣性があるためOLSでは価格の係数をうまく推定できない • 内⽣性: 𝑦1 = 𝒙1 *𝜷
+ 𝜀1 で 𝐸[𝜀1 |𝒙1 ] ≠ 0となりOLSの仮定が不成⽴ →解決策: 操作変数法 𝐸 𝜀1 𝒛1 = 0, 𝐶𝑜𝑟𝑟 𝒙1 , 𝒛1 ≠ 0となるような変数zi をxi の代わりに使う 例: 2段階最⼩⼆乗法 回帰式: 𝑦1 = 𝛽$ + 𝛽2𝑥1 + 𝜀1 →OLSだと内⽣性 1段階⽬: 𝑥1 = 𝜋$ + 𝜋2𝑧1 + 𝑢1 ただし𝐸 𝑢1 𝑧1 = 0 2段階⽬: 𝑦1 = 𝛽$ + 𝛽2 1 𝑥1 + 𝜀1 (1段階⽬から予測されるxi を使う) →βが正しく推定できる(⼀致推定量が得られる) cf. TokyoR #86「操作変数法⼊⾨」 https://speakerdeck.com/mns54/cao-zuo-bian-shu-fa-ru-men 13
問題点2: 価格と数量の内⽣性 • 価格の操作変数は何使えばいい? • いくつか提案されている • 他社商品の(数値的な)属性の平均 (Berry, 1994)
• 同じ商品の別の市場での価格の平均 (Nevo, 2001) • 他商品との属性の距離 (Gandhi and Houde, 2020) • etc. • 何が操作変数として適切かはデータや市場の特徴に応じて考える必要 14
問題点3: IIA特性 • ロジットモデルはIIA (independence of irrelevant alternatives) →2つの商品のシェアの⽐が他の商品に影響されない •
どの商品も同じ代替性→⾮現実的 • 代替性の柔軟性を上げたモデル • ⼊れ⼦ロジットモデル (nested logit) • ランダム係数モデル (random coefficients) • etc. • 本発表では⼊れ⼦ロジットモデルを紹介 15
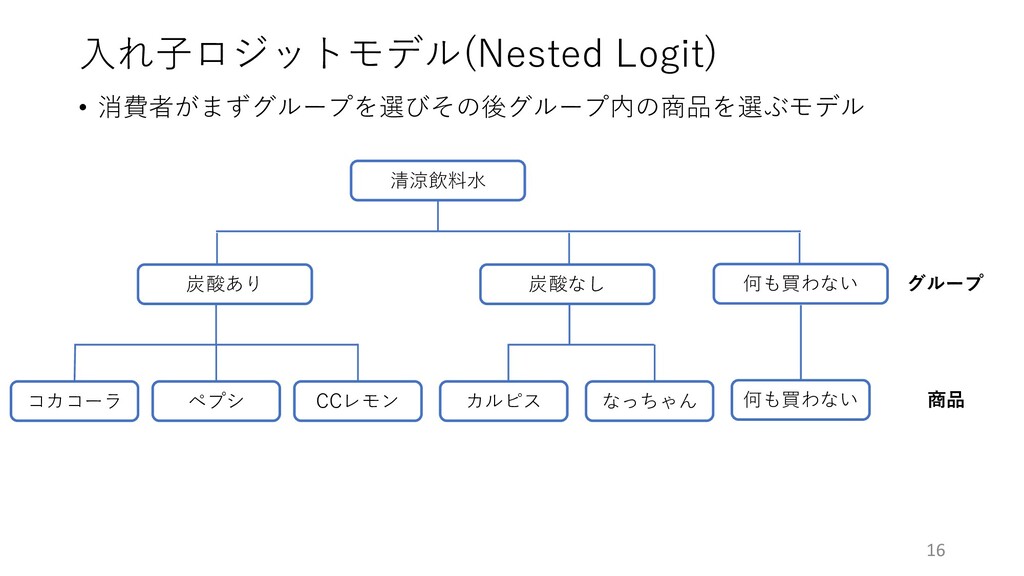
⼊れ⼦ロジットモデル(Nested Logit) • 消費者がまずグループを選びその後グループ内の商品を選ぶモデル 16 清涼飲料⽔ 炭酸あり 炭酸なし 何も買わない コカコーラ
ペプシ CCレモン カルピス なっちゃん 何も買わない グループ 商品
⼊れ⼦ロジットモデル(Nested Logit) • 消費者効⽤の誤差項を以下のように変更(⼀般化極値分布) 𝑢1!" = 𝛿!" + 𝜀13 !
" + 1 − 𝜌 𝜀1!" • 𝜀13 ! " は商品jが属するグループg(j)に共通のショック • 商品jとkの代替性はjとkが同⼀グループに属しているか異なるグループに 属しているかで異なる • 同⼀グループならより代替的 • ρ→0では通常のロジットモデルと同じ • ρ→1ではグループ間代替起こらない • グループgの商品価格が下がってもグループhを選ぶ消費者は⾒向きもしない 17
⼊れ⼦ロジットモデル • 推定する式 ln 𝑠!" − ln 𝑠$" = 𝜌
ln 𝑠!|3 ! ," + 𝛼𝑝!" + 𝛽𝑋!" + 𝜉!" = 𝜌 ln 𝑠!|3 ! ," + 𝛿!" • 𝑠!|3 ! ," は商品jのグループ内シェア 𝑠!|3 ! ," = 𝑠!" / ∑%∈3(!) 𝑠%" • 𝑠!|3 ! ," は左辺と内⽣性あるので操作変数が必要 • 反実仮想シェア 𝑠!" = exp(𝛿!"/(1 − 𝜌)) 𝐷 3 ! " 9 (1 + ∑:∈;$ 𝐷 :" 2<9) , 𝐷3" = ^ %∈3 exp 𝛿%" 1 − 𝜌 • ln 𝐷3" をグループgの包括的価値(inclusive value)と呼ぶこともある • 問題点: グループ分けが事前にわかっている必要 18
Part 2 実践編 19
Rで実際に需要関数を推定してみよう! • 今⽇からグローバル⾷品メーカーのインド配属になりました • ビスケット市場で⾃社商品の売上を増やすにはどうすればいいか? • 今回使⽤したコード https://github.com/mns54/tokyor-demand-estimation 20
データ • インドのスーパーマーケットのPOSデータ(Hackathon_Ideal_Data.csv) https://www.kaggle.com/iamprateek/store-transaction-data • インドの10店舗の3ヶ⽉分の各商品の⽉次売上数量と⾦額 • 今回はビスケットに着⽬ • 前処理後のデータ→data_biscuits
• n=762 (観察単位は⽉×店×ブランド名) • MONTH: ⽉(M1, M2, M3) • STORECODE: 店舗番号(P1, ..., P10) • SGRP: ジャンル(CREAM, GLUCOSE, MARIE, MILK, NON-SALT CRACKER, SALT CRACKER, SWEET/COOKIES, WAFER CREAMの8種類) • CMP: 企業名 • MBRD2: 「ブランド名 (ジャンル名)」異ジャンルで同ブランドの場合は別と捉える • QTY: 数量 (単位は個?) • VALUE: ⾦額 (単位は⽶ドル?) 21
やること • ロジットモデルと⼊れ⼦ロジットモデルで推定&反実仮想分析 • 各⽉・各店舗をそれぞれ⼀つの「市場」と捉える • モンデリーズ・インターナショナルの担当者になってオレオの売上を分析 • データではモンデリーズは2ブランド展開 data_biscuits
%>% filter(CMP == "MONDELEZ INTERNATIONAL") %>% distinct(MBRD2) # A tibble: 2 x 1 MBRD2 <chr> 1 OREO (CREAM) 2 BOURNVITA (SWEET/COOKIES) • BOURNVITAはインドで展開しているブランドらしい • BOURNVITAの売上も気にしながらOREOの売上を伸ばしたい • 商品間の代替関係を捉える離散選択モデルならOREOに対する施策の他商品への波及 効果も分析可能 22
データ構築 • 各⽉・各店舗をそれぞれ⼀つの「市場」と捉える # 潜在的市場規模 data_biscuits <- data_biscuits %>% group_by(MONTH,
STORECODE) %>% mutate(quantity_total = sum(QTY)) %>% # 各市場の総売上数量 group_by(STORECODE) %>% mutate(market_size = max(quantity_total) * 2) %>% #各店舗の最大総売上数量の2倍 ungroup() # シェアの列作る data_biscuits <- data_biscuits %>% mutate(share = QTY / market_size) %>% # シェア group_by(MONTH, STORECODE) %>% mutate(outshare = 1 - sum(share)) %>% # 「何も買わない」のシェア ungroup() 23
データ構築 • 価格の操作変数として同商品の同⽉他店舗(他市場)の平均価格を⽤いる # 価格の列作る data_biscuits <- data_biscuits %>% mutate(price
= VALUE / QTY) # 価格の操作変数として各商品の同月他店舗平均価格 data_biscuits <- data_biscuits %>% group_by(MONTH, MBRD2) %>% mutate(price_instruments = (sum(price) - price) / (n() - 1)) %>% ungroup() 24
データ構築 • ⼊れ⼦ロジットのグループとしてジャンル(SGRP)を設定 • グループ内シェアの操作変数として他市場でのグループ内シェアの平均 # グループ内シェア # ジャンルをグループにする data_biscuits
<- data_biscuits %>% group_by(MONTH, STORECODE, SGRP) %>% mutate(within_share = share / sum(share)) %>% ungroup() # グループ内シェアの操作変数として各商品の同月他店舗平均グループ内シェア data_biscuits <- data_biscuits %>% group_by(MONTH, MBRD2) %>% mutate(within_share_instruments = (sum(within_share) - within_share) / (n() - 1)) %>% ungroup() 25
ロジットモデルの推定 • 以下の式を推定 ln 𝑠!=" − ln 𝑠$=" = 𝛼
ln 𝑝!=" + 𝜉! + 𝑢!=" • 店舗r, ⽉t, ujrt はただの誤差項 • 価格は対数取る(消費者は価格そのものより割合の変化に反応?) • 価格には操作変数を使⽤ • ξj は固定効果 • 推定には{estimatr}パッケージのiv_robust関数を使⽤ • 操作変数を使わない場合はlm_robust関数 • 固定効果を⼊れた場合の処理が速い • 頑健標準誤差を計算 • 回帰式の指定は”y ~ x | z” • xに説明変数、zに操作変数およびxのうち外⽣変数を⼊れる 26
ロジットモデルの推定 ## plain logit推定 plain_logit <- estimatr::iv_robust( formula = log(share)
- log(outshare) ~ log(price) | log(price_instruments), data = data_biscuits, fixed_effects = MBRD2, clusters = MBRD2, se_type = 'stata’ ) > summary(plain_logit) # 推定結果 Coefficients: Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF log(price) -0.3411 0.2557 -1.334 0.1897 -0.8579 0.1756 40 • 価格の係数は負→「価格→数量」の因果関係捉えられている? 27
ロジットモデルの反実仮想分析 • オレオの価格を20%下げたときの売上数量と⾦額の変化を反実仮想分析 # 予測値を出すために商品ダミーを明示的に説明変数に入れる plain_logit_prediction <- estimatr::iv_robust( formula =
log(share) - log(outshare) ~ log(price) + factor(MBRD2) | log(price_instruments) + factor(MBRD2), data = data_biscuits ) # オレオの価格を20%安くしてみる data_biscuits_counterfactual_plain <- data_biscuits %>% mutate(price_original = price, # 元の価格を残す price = if_else(MBRD2 == "OREO (CREAM)", 0.8 * price, price)) # 平均効用deltaを計算 delta_plain <- predict(plain_logit_prediction, newdata = data_biscuits_counterfactual_plain) 28
ロジットモデルの反実仮想分析 • モデルのフィットがわからないので「(現在の価格の下での)シェアの予測 値」「(新しい価格の下での)反実仮想シェア」両⽅計算 # 反実仮想シェアを計算 data_biscuits_counterfactual_plain <- data_biscuits_counterfactual_plain %>%
mutate(delta_counterfactual = delta_plain, # 反実仮想の平均効用 delta_fitted = fitted(plain_logit) # 元の価格での平均効用のフィット ) %>% group_by(MONTH, STORECODE) %>% # 市場でグループ化 # シェア計算 mutate(share_counterfactual = exp(delta_counterfactual) / (1 + sum(exp(delta_counterfactual))), share_fitted = exp(delta_fitted) / (1 + sum(exp(delta_fitted)))) %>% ungroup() %>% 29
ロジットモデルの反実仮想分析 (前ページの続き) # 数量と金額を計算 mutate(quantity_counterfactual = share_counterfactual * market_size, quantity_fitted
= share_fitted * market_size, value_counterfactual = price * quantity_counterfactual, value_fitted = price_original * quantity_fitted) 30
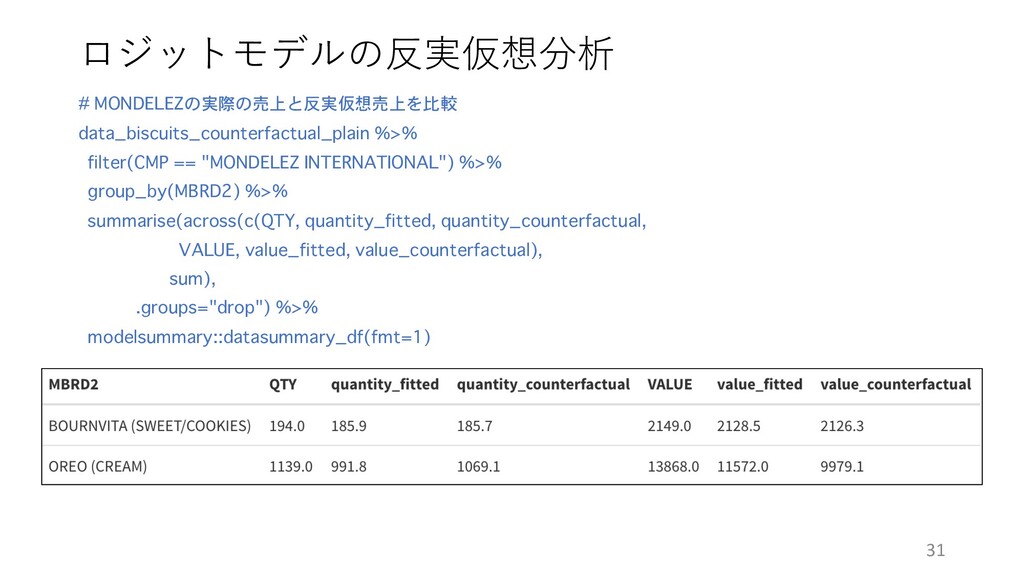
ロジットモデルの反実仮想分析 # MONDELEZの実際の売上と反実仮想売上を比較 data_biscuits_counterfactual_plain %>% filter(CMP == "MONDELEZ INTERNATIONAL") %>%
group_by(MBRD2) %>% summarise(across(c(QTY, quantity_fitted, quantity_counterfactual, VALUE, value_fitted, value_counterfactual), sum), .groups="drop") %>% modelsummary::datasummary_df(fmt=1) 31
⼊れ⼦ロジットモデルの推定 • 推定する式はロジットモデルの式に「グループ内シェア」項を加えるだけ • ただし操作変数が必要 nested_logit <- estimatr::iv_robust( formula =
log(share) - log(outshare) ~ log(price) + log(within_share) | log(price_instruments) + log(within_share_instruments), data = data_biscuits, fixed_effects = MBRD2, clusters = MBRD2, se_type = 'stata’) > summary(nested_logit) # 推定結果 Coefficients: Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF log(price) -0.2888 0.14811 -1.950 5.820e-02 -0.5881 0.01052 40 log(within_share) 0.7886 0.08169 9.653 5.298e-12 0.6235 0.95369 40 • ρ=0.79→グループ間の代替性低い? 32
⼊れ⼦ロジットモデルの反実仮想分析 • 通常のロジットモデルと同様にオレオの価格を20%下げてみる # 予測値を出すために商品ダミーを明示的に説明変数に入れる nested_logit_prediction <- estimatr::iv_robust( formula =
log(share) - log(outshare) ~ log(price) + log(within_share) + factor(MBRD2) | log(price_instruments) + log(within_share_instruments) + factor(MBRD2), data = data_biscuits ) # オレオの価格を20%安くしてみる data_biscuits_counterfactual_nested <- data_biscuits %>% mutate(price_original = price, price = if_else(MBRD2 == "OREO (CREAM)", 0.8 * price, price)) 33
⼊れ⼦ロジットモデルの反実仮想分析 # 平均効用deltaを計算 # モデルの予測値にはrho*log(within_share)の部分も含まれているのでそれを除く rho <- coef(nested_logit)['log(within_share)'] # rho
delta_nested <- predict(nested_logit_prediction, newdata = data_biscuits_counterfactual_nested) - rho * log(data_biscuits$within_share) # deltaとrhoの列を加える data_biscuits_counterfactual_nested <- data_biscuits_counterfactual_nested %>% mutate(rho = rho, delta_counterfactual = delta_nested, delta_fitted = fitted(nested_logit) - rho * log(within_share)) 34
⼊れ⼦ロジットモデルの反実仮想分析 • ⼊れ⼦ロジットモデルのシェアの計算にはδとρだけでなくグループの「 包括的価値」が必要 • 再掲: 反実仮想シェア 𝑠!" = exp(𝛿!"/(1
− 𝜌)) 𝐷 3 ! " 9 (1 + ∑:∈;$ 𝐷 :" 2<9) , 𝐷3" = ^ %∈3 exp 𝛿%" 1 − 𝜌 • 市場×グループレベルのデータフレームを作る • グループごとの包括的価値(Dgt )と市場ごとの包括的価値合計を計算する • 市場×商品のデータフレーム(元のデータフレーム)にleft_join 35
⼊れ⼦ロジットモデルの反実仮想分析 # 各グループの包括的価値(inclusive value)を計算する data_biscuits_counterfactual_nested_inclusive <- data_biscuits_counterfactual_nested %>% group_by(MONTH, STORECODE,
SGRP) %>% # 各グループの包括的価値 summarise(inclusive_counterfactual = sum(exp(delta_counterfactual / (1 - rho))), inclusive_fitted = sum(exp(delta_fitted / (1 - rho))), .groups="drop") %>% mutate(rho = rho) %>% group_by(MONTH, STORECODE) %>% # 包摂的価値の市場内集計 mutate(inclusive_counterfactual_sum = 1 + sum(inclusive_counterfactual^(1-rho)), inclusive_fitted_sum = 1 + sum(inclusive_fitted^(1-rho))) %>% ungroup() %>% select(!rho) 36
⼊れ⼦ロジットモデルの反実仮想分析 # 元のデータフレームに包摂的価値を引っ付ける data_biscuits_counterfactual_nested <- data_biscuits_counterfactual_nested %>% left_join(data_biscuits_counterfactual_nested_inclusive, by =
c("MONTH", "STORECODE", "SGRP")) # 予測シェアと数量と売上金額を計算 data_biscuits_counterfactual_nested <- data_biscuits_counterfactual_nested %>% mutate(share_counterfactual = exp(delta_counterfactual / (1 - rho)) / (inclusive_counterfactual^rho * inclusive_counterfactual_sum), share_fitted = exp(delta_fitted / (1 - rho)) / (inclusive_fitted^rho * inclusive_fitted_sum), quantity_counterfactual = share_counterfactual * market_size, quantity_fitted = share_fitted * market_size, value_counterfactual = price * quantity_counterfactual, value_fitted = price_original * quantity_fitted) 37
⼊れ⼦ロジットモデルの反実仮想分析 # MONDELEZの実際の売上と反実仮想売上を比較 data_biscuits_counterfactual_nested %>% filter(CMP == "MONDELEZ INTERNATIONAL") %>%
group_by(MBRD2) %>% summarise(across(c(QTY, quantity_fitted, quantity_counterfactual, VALUE, value_fitted, value_counterfactual), sum), .groups="drop") %>% modelsummary::datasummary_df(fmt=1) 38 • 値下げによる売上数量増は⼊れ⼦ロジットのほうが⼤きい • CREAMグループの規模が⼤きいのでグループ内代替性⾼いのが効いた?
さらに知りたい • 北野(2012) 「需要関数の推定−CPRCハンドブックシリーズ No.3−」 ⽇本語での需要関数推定の説明としてはかなり詳しい。 • Nevo (2000) “A
Practitionerʼs Guide to Estimation of Random- coefficients Logit Models of Demand” 今回紹介したロジットモデルの発展形である「ランダム係数モデル」の使 ⽤法を解説した論⽂。ロジットモデルの問題点や解決策を論じている。 • 上武・遠⼭・若森・渡辺(2021)「実証ビジネス・エコノミクス」経済セミ ナー連載 実証産業組織論で使われる⼿法を紹介する連載で需要関数推定もRコード 付きでカバーされている 39
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![⼊れ⼦ロジットモデルの反実仮想分析 # 平均効用deltaを計算 # モデルの予測値にはrho*log(within_share)の部分も含まれているのでそれを除く rho <- coef(nested_logit)['log(within_share)'] # rho](https://files.speakerdeck.com/presentations/58ce8d58149c4443927821fa95bd49ea/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}