Documents (objects) map nicely to programming language data types Embedded documents and arrays reduce need for joins Dynamically-typed (schemaless) for easy schema evolution No joins and no (multi-object) transactions for high performance and easy scalability High performance No joins and no transactions makes reads and writes fast Indexes with indexing into embedded documents and arrays Optional asynchronous writes High availability Replicated servers with automatic master failover Easy scalability Eventually-consistent reads are distributed over replicated servers Automatic sharding (auto-partitioning of data across servers) Reads and writes are distributed over shards No joins and no transactions make distributed queries easy and fast Rich query language 3 Sunday, January 30, 2011
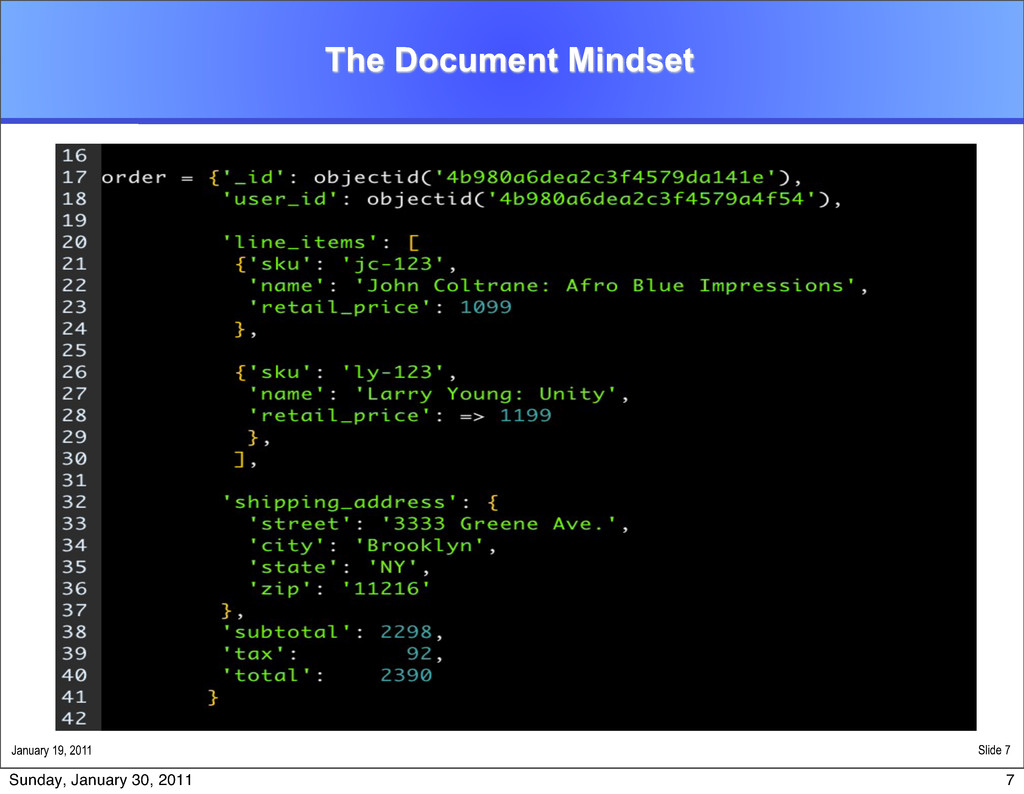
system holds a set of databases A database holds a set of collections A collection holds a set of documents A document is a set of fields A field is a key-value pair A key is a name (string) A value is a basic type like string, integer, float, timestamp, binary, etc., a document, or an array of values 6 Sunday, January 30, 2011
Slide 34 post = {author: “mike”, date: new Date(), text: “another blog post...”, tags: [“mongodb”], title: “MongoDB for Fun and Profit”} post_id = db.posts.save(post) 33 Sunday, January 30, 2011
a 12-byte value consisting of a 4-byte timestamp (seconds since epoch), a 3-byte machine id, a 2-byte process id, and a 3-byte counter. Note that the timestamp and counter fields must be stored big endian unlike the rest of BSON. This is because they are compared byte-by-byte and we want to ensure a mostly increasing order. Here's the schema: 0 1 2 3 4 5 6 7 8 9 10 11 time time time time machine machine machine pid pid inc inc inc 41 Sunday, January 30, 2011
![January 19, 2011 Shiva Thirumazhusai [email protected] CTO, Nasotech LLC Introduction](https://files.speakerdeck.com/presentations/4e15d2fe5753083376000016/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Shiva Thirumazhusai [email protected] CTO, Nasotech LLC Introduction to MongoDB 42](https://files.speakerdeck.com/presentations/4e15d2fe5753083376000016/slide_41.jpg){kind=link}