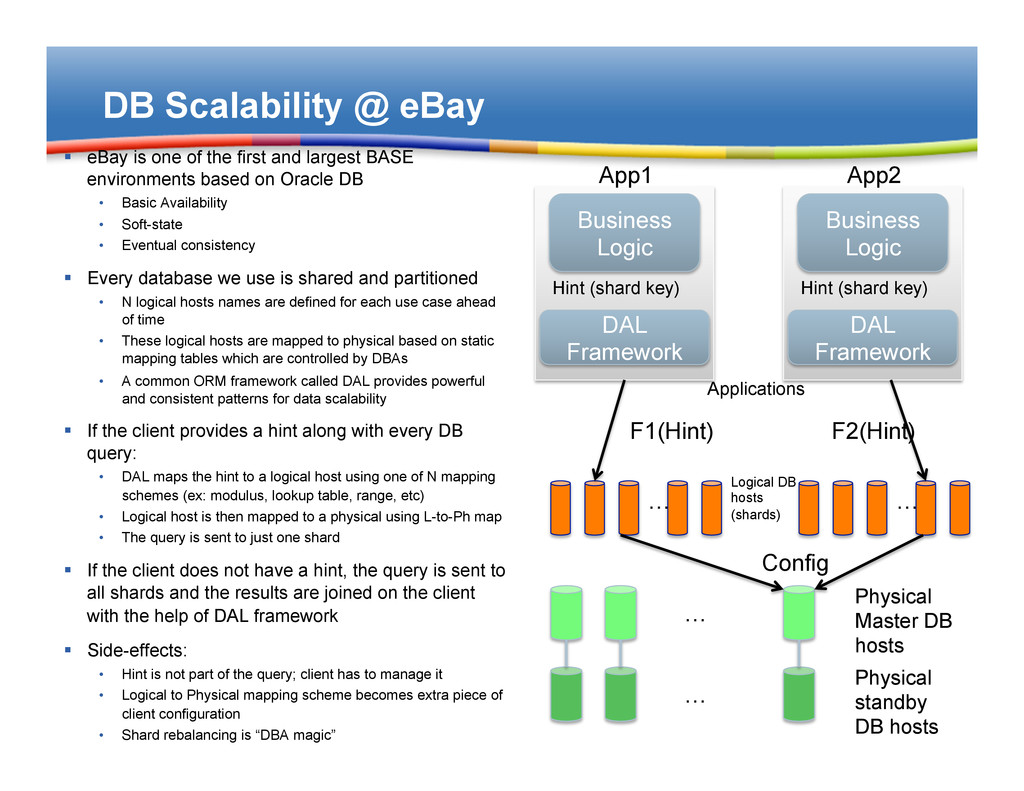
first and largest BASE environments based on Oracle DB • Basic Availability • Soft-state • Eventual consistency § Every database we use is shared and partitioned • N logical hosts names are defined for each use case ahead of time • These logical hosts are mapped to physical based on static mapping tables which are controlled by DBAs • A common ORM framework called DAL provides powerful and consistent patterns for data scalability § If the client provides a hint along with every DB query: • DAL maps the hint to a logical host using one of N mapping schemes (ex: modulus, lookup table, range, etc) • Logical host is then mapped to a physical using L-to-Ph map • The query is sent to just one shard § If the client does not have a hint, the query is sent to all shards and the results are joined on the client with the help of DAL framework § Side-effects: • Hint is not part of the query; client has to manage it • Logical to Physical mapping scheme becomes extra piece of client configuration • Shard rebalancing is “DBA magic” … Physical Master DB hosts … Logical DB hosts (shards) Applications DAL Framework Business Logic Hint (shard key) F1(Hint) Config DAL Framework Business Logic Hint (shard key) … F2(Hint) … Physical standby DB hosts App1 App2
scheme outlined above § It’s proven to scale to tens of thousands of developers, petabytes of data, hundreds of millions of SQL queries per day § But there is always room for improvements and new ideas • ORM is not the fastest way to develop; how do we achieve faster development cycles and reduce schema mapping frictions? • How do we add new attributes to tables faster and without DBA’s involvement? Schema free approach sounds interesting. • Can we make the hint transparent, ex: auto-extract it from queries? • Can we rebalance the data seamlessly and automatically? • Can we add shards faster in order to scale out on demand and transparently to applications? • How do we deploy new DBs to the cloud on demand? § And what about performance? Can we use RAM more aggressively and seamlessly to speed up queries?
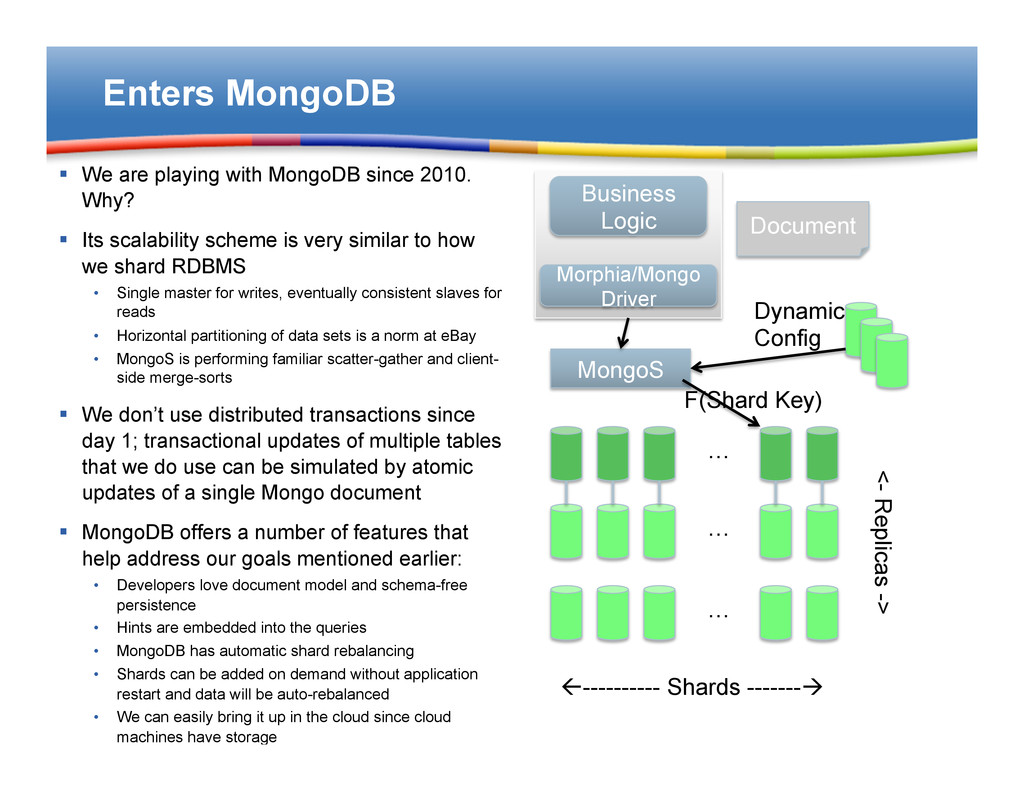
Why? § Its scalability scheme is very similar to how we shard RDBMS • Single master for writes, eventually consistent slaves for reads • Horizontal partitioning of data sets is a norm at eBay • MongoS is performing familiar scatter-gather and client- side merge-sorts § We don’t use distributed transactions since day 1; transactional updates of multiple tables that we do use can be simulated by atomic updates of a single Mongo document § MongoDB offers a number of features that help address our goals mentioned earlier: • Developers love document model and schema-free persistence • Hints are embedded into the queries • MongoDB has automatic shard rebalancing • Shards can be added on demand without application restart and data will be auto-rebalanced • We can easily bring it up in the cloud since cloud machines have storage … ß---------- Shards -------à … … <- Replicas -> Morphia/Mongo Driver Business Logic MongoS Dynamic Config F(Shard Key) Document
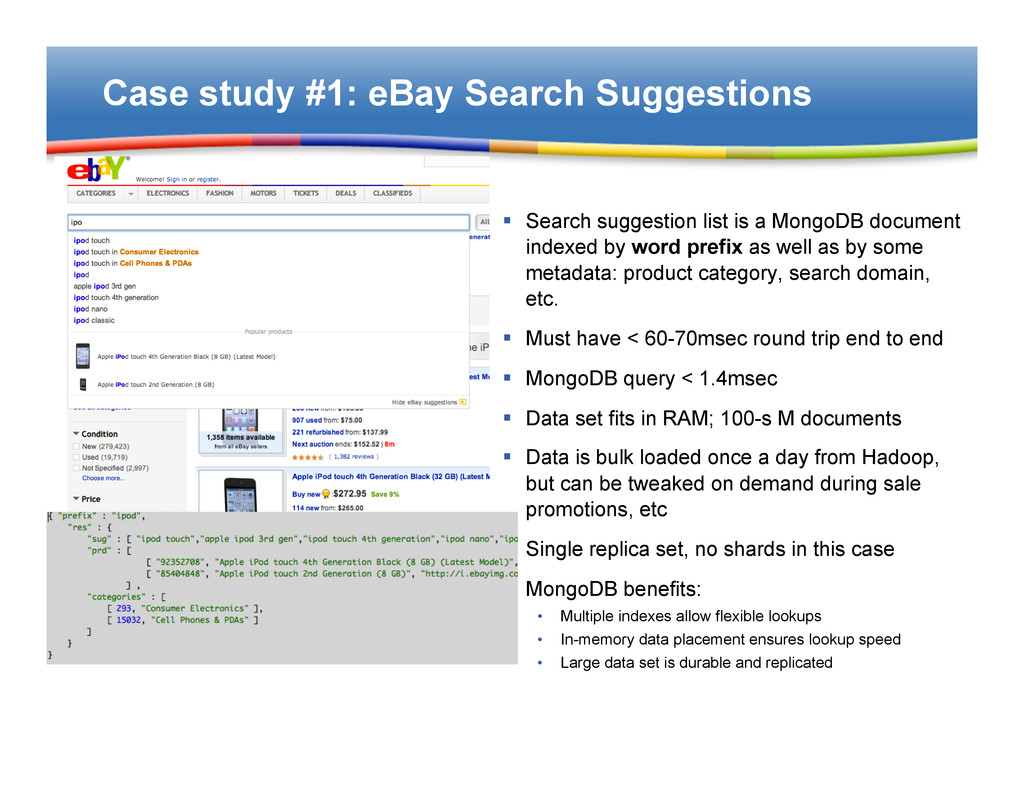
is a MongoDB document indexed by word prefix as well as by some metadata: product category, search domain, etc. § Must have < 60-70msec round trip end to end § MongoDB query < 1.4msec § Data set fits in RAM; 100-s M documents § Data is bulk loaded once a day from Hadoop, but can be tweaked on demand during sale promotions, etc § Single replica set, no shards in this case § MongoDB benefits: • Multiple indexes allow flexible lookups • In-memory data placement ensures lookup speed • Large data set is durable and replicated
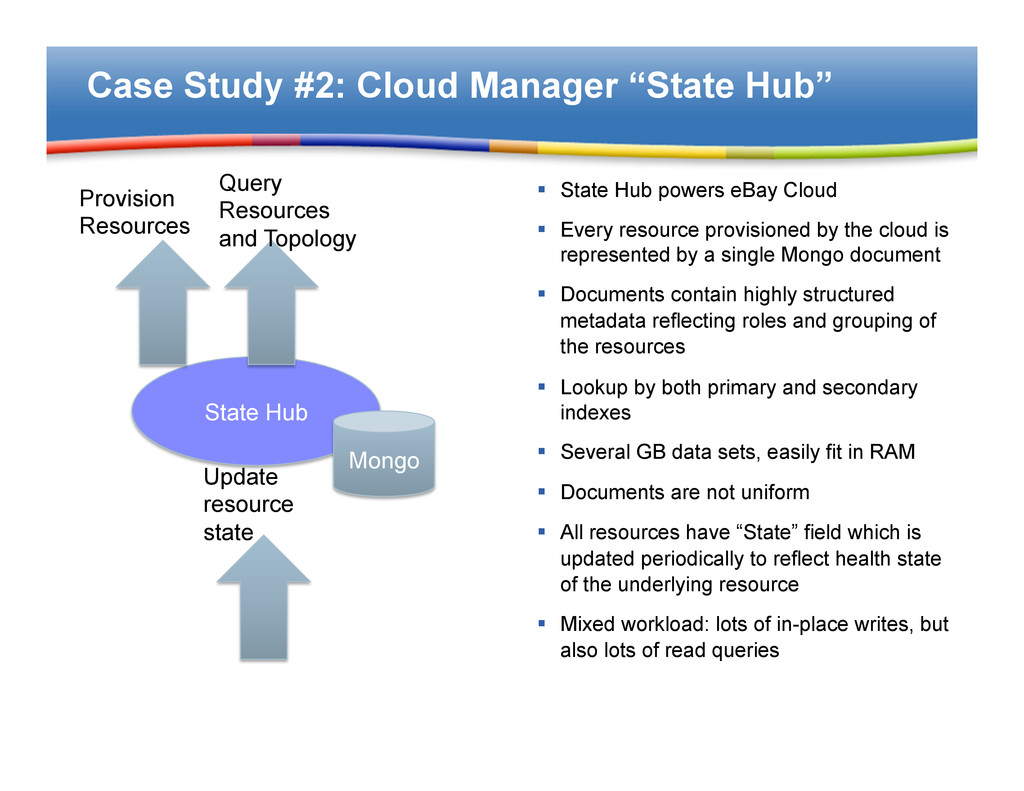
powers eBay Cloud § Every resource provisioned by the cloud is represented by a single Mongo document § Documents contain highly structured metadata reflecting roles and grouping of the resources § Lookup by both primary and secondary indexes § Several GB data sets, easily fit in RAM § Documents are not uniform § All resources have “State” field which is updated periodically to reflect health state of the underlying resource § Mixed workload: lots of in-place writes, but also lots of read queries State Hub Provision Resources Query Resources and Topology Update resource state Mongo
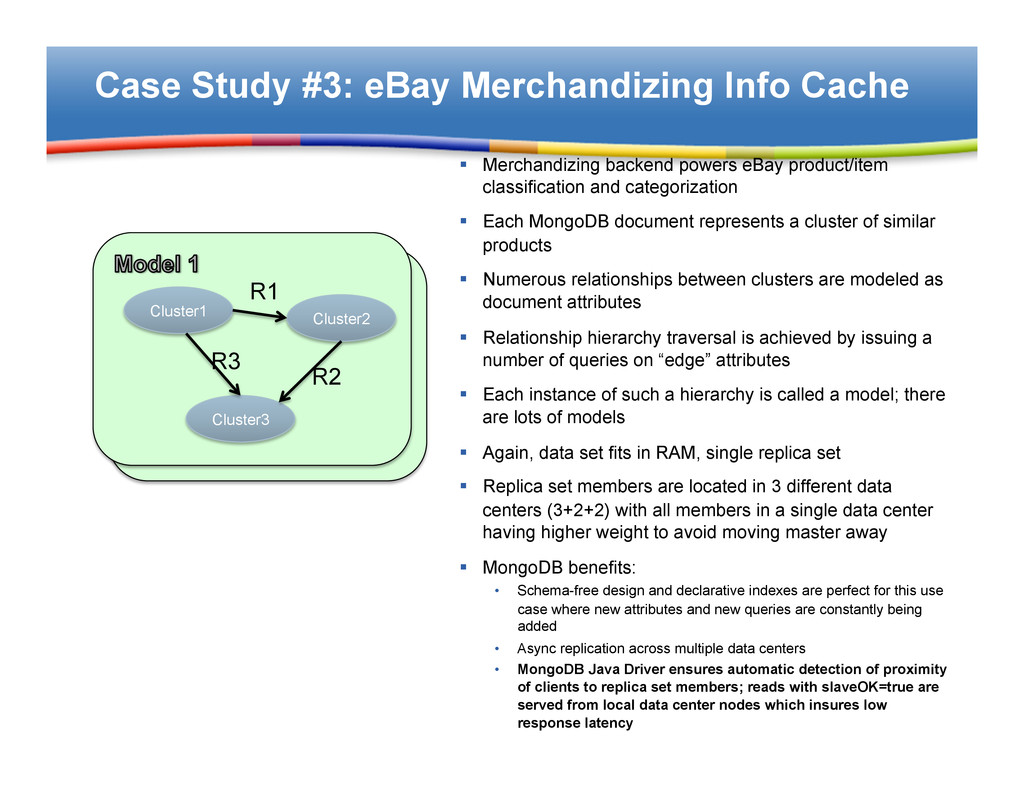
powers eBay product/item classification and categorization § Each MongoDB document represents a cluster of similar products § Numerous relationships between clusters are modeled as document attributes § Relationship hierarchy traversal is achieved by issuing a number of queries on “edge” attributes § Each instance of such a hierarchy is called a model; there are lots of models § Again, data set fits in RAM, single replica set § Replica set members are located in 3 different data centers (3+2+2) with all members in a single data center having higher weight to avoid moving master away § MongoDB benefits: • Schema-free design and declarative indexes are perfect for this use case where new attributes and new queries are constantly being added • Async replication across multiple data centers • MongoDB Java Driver ensures automatic detection of proximity of clients to replica set members; reads with slaveOK=true are served from local data center nodes which insures low response latency Cluster1 Cluster2 Cluster3 R1 R2 R3
is a new mega project which is a work in progress § MongoDB is being evaluated as a storage backend for all media-related metadata on the site (example: picture IDs with lots attributes) § Requirements: • Tens of TBs data set, Millions of documents: data set must be partitioned; this is our first use case where MongoDB sharding is used • System of record for picture info; data can not be lost! • Replication/DR across 2 data centers; local DC reads are required • Queries are from site-facing flows; <10msec response time SLA • Mixed workload: both inserts and reads are happening concurrently all the time § Can MongoDB do it ??
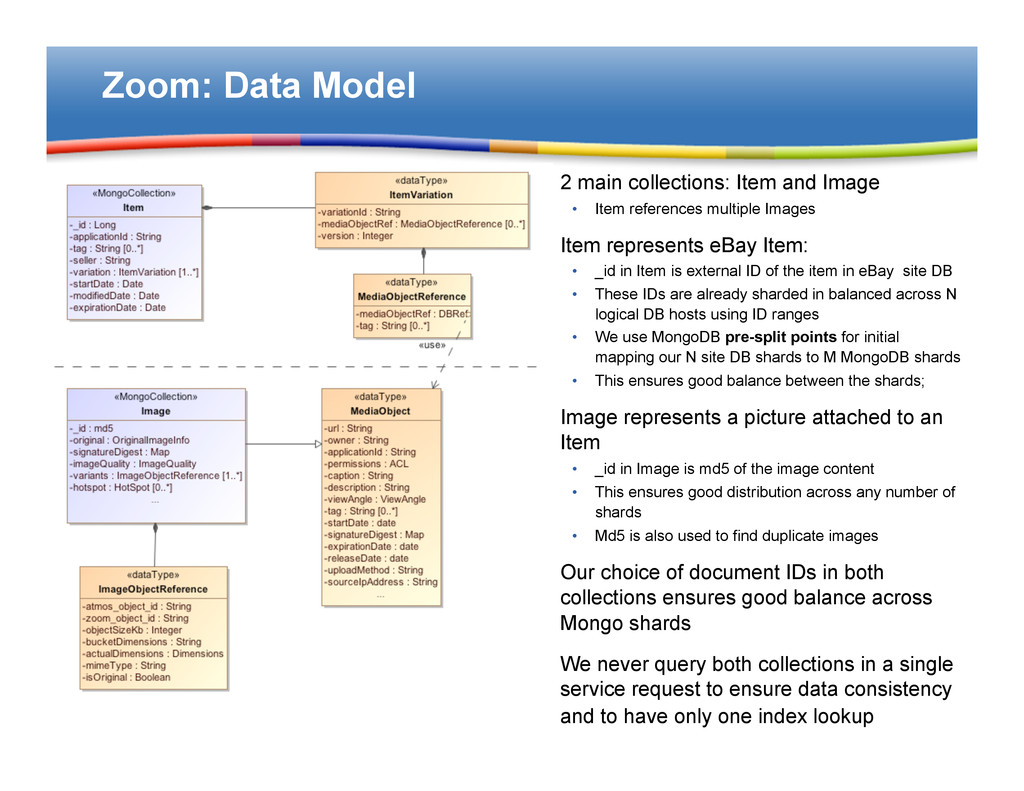
• Item references multiple Images § Item represents eBay Item: • _id in Item is external ID of the item in eBay site DB • These IDs are already sharded in balanced across N logical DB hosts using ID ranges • We use MongoDB pre-split points for initial mapping our N site DB shards to M MongoDB shards • This ensures good balance between the shards; § Image represents a picture attached to an Item • _id in Image is md5 of the image content • This ensures good distribution across any number of shards • Md5 is also used to find duplicate images § Our choice of document IDs in both collections ensures good balance across Mongo shards § We never query both collections in a single service request to ensure data consistency and to have only one index lookup
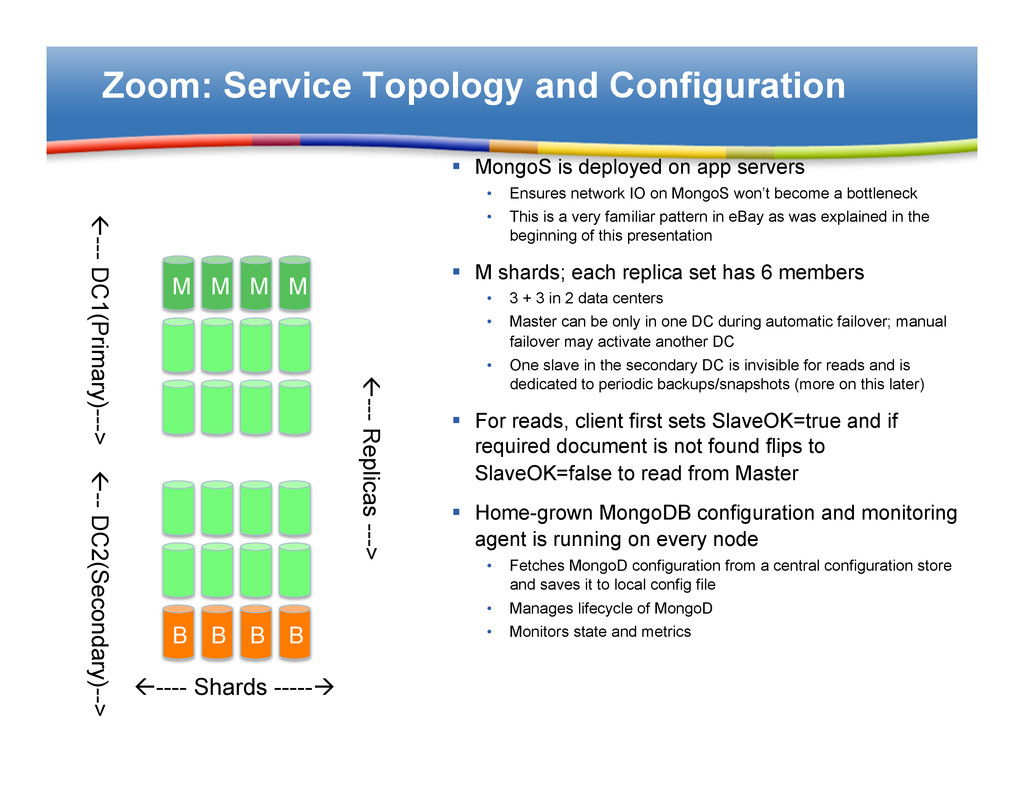
app servers • Ensures network IO on MongoS won’t become a bottleneck • This is a very familiar pattern in eBay as was explained in the beginning of this presentation § M shards; each replica set has 6 members • 3 + 3 in 2 data centers • Master can be only in one DC during automatic failover; manual failover may activate another DC • One slave in the secondary DC is invisible for reads and is dedicated to periodic backups/snapshots (more on this later) § For reads, client first sets SlaveOK=true and if required document is not found flips to SlaveOK=false to read from Master § Home-grown MongoDB configuration and monitoring agent is running on every node • Fetches MongoD configuration from a central configuration store and saves it to local config file • Manages lifecycle of MongoD • Monitors state and metrics M M M M B B B B ß---- Shards -----à ß--- Replicas ---> ß--- DC1(Primary)---> ß-- DC2(Secondary)-->
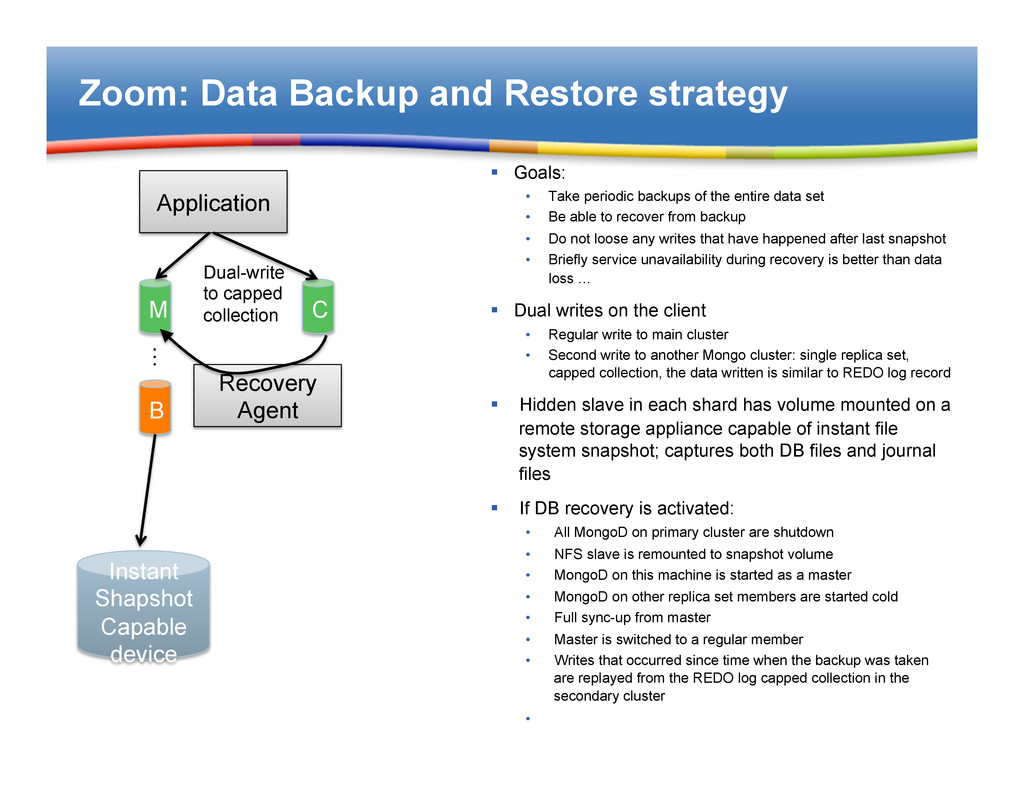
periodic backups of the entire data set • Be able to recover from backup • Do not loose any writes that have happened after last snapshot • Briefly service unavailability during recovery is better than data loss … § Dual writes on the client • Regular write to main cluster • Second write to another Mongo cluster: single replica set, capped collection, the data written is similar to REDO log record § Hidden slave in each shard has volume mounted on a remote storage appliance capable of instant file system snapshot; captures both DB files and journal files § If DB recovery is activated: • All MongoD on primary cluster are shutdown • NFS slave is remounted to snapshot volume • MongoD on this machine is started as a master • MongoD on other replica set members are started cold • Full sync-up from master • Master is switched to a regular member • Writes that occurred since time when the backup was taken are replayed from the REDO log capped collection in the secondary cluster • Application M B … Instant Shapshot Capable device C Dual-write to capped collection Recovery Agent
but use it wisely § Deletes can be slow; automatic balancer is dangerous; use it only when you must (example: be careful when adding new shards) § Use explain for every query; disable full scans to discover inefficiencies early § Query profiler is great § Retry every failed query at least once; long tail in response times is possible when data set > RAM size
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}