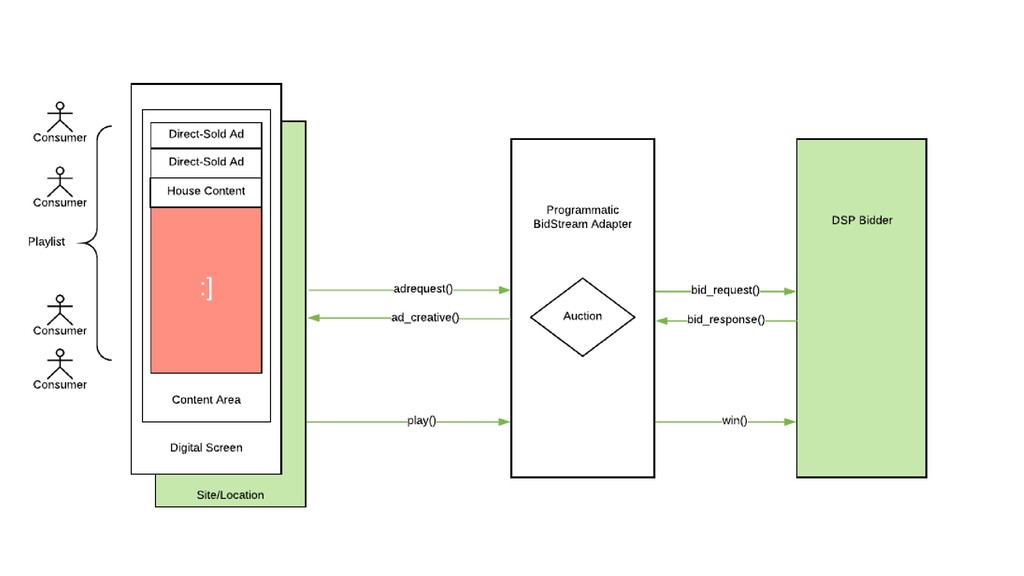
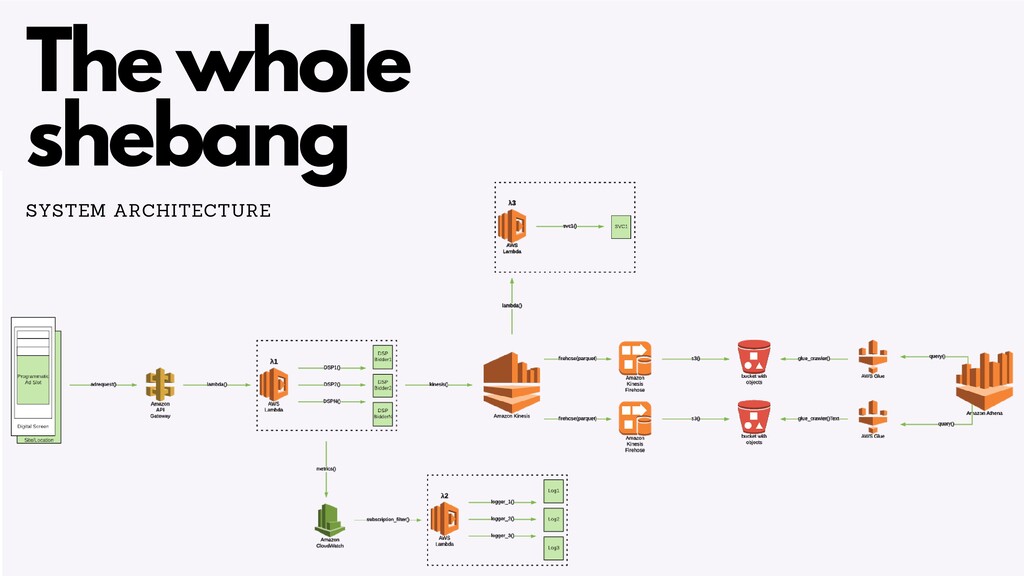
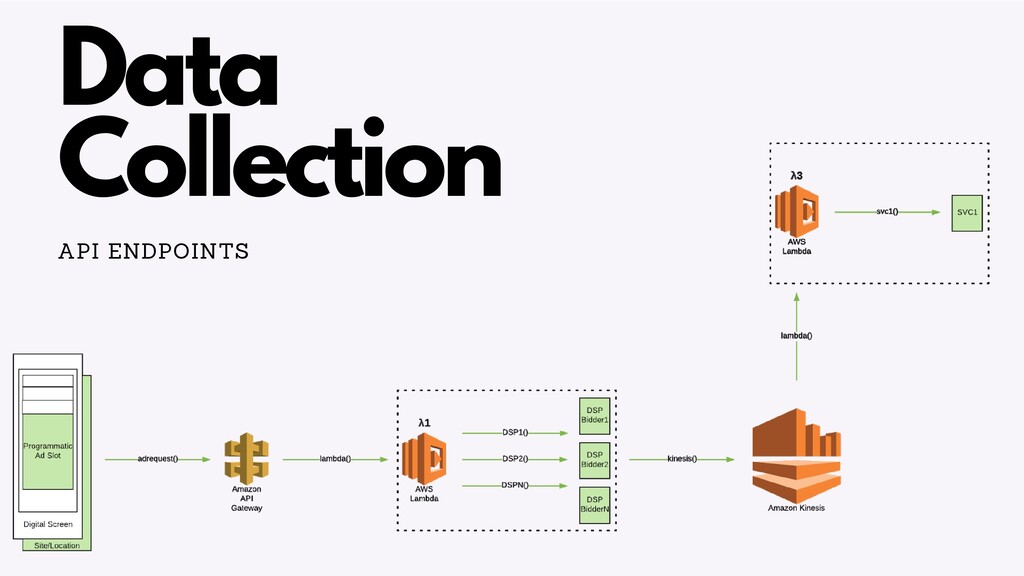
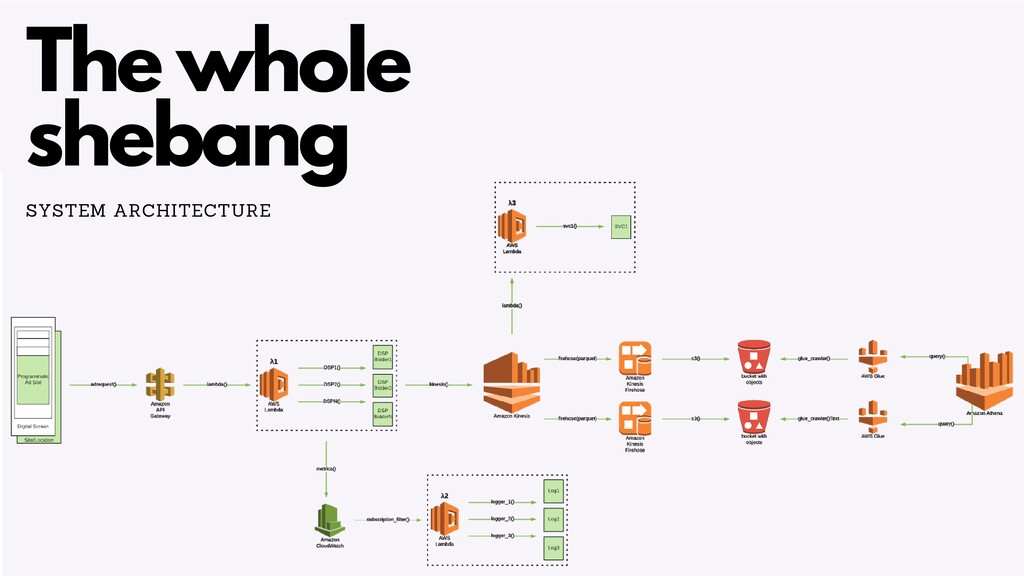
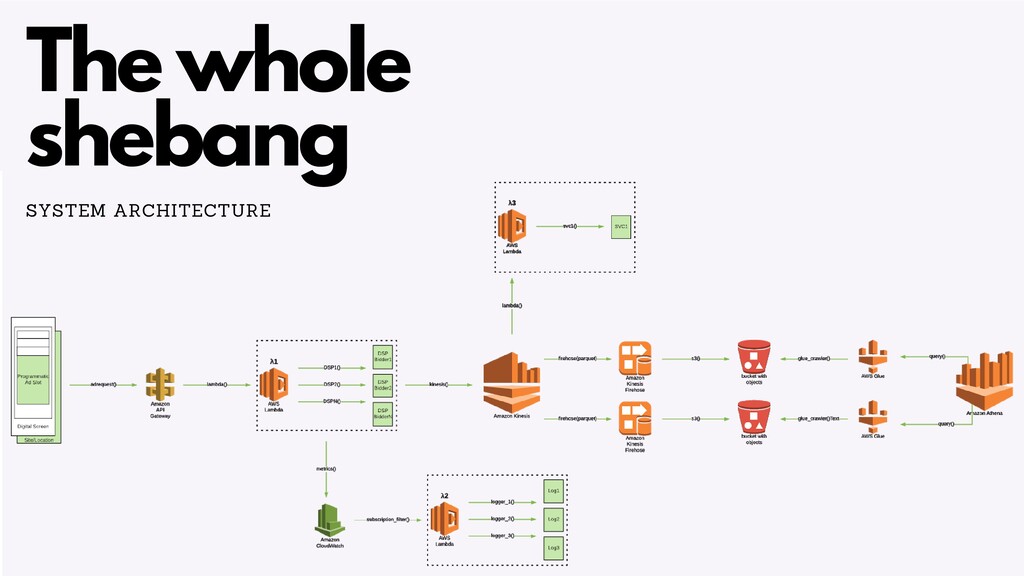
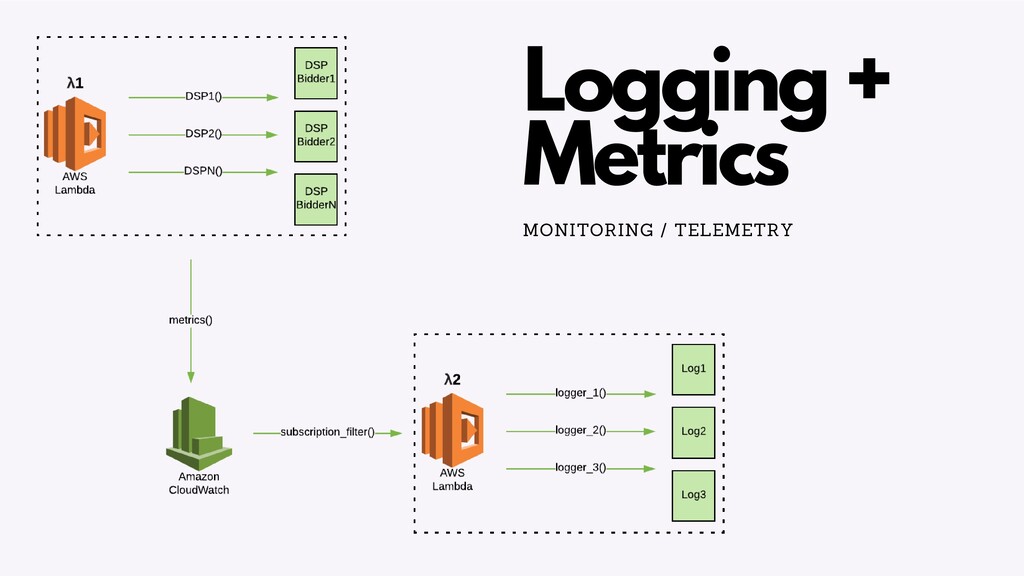
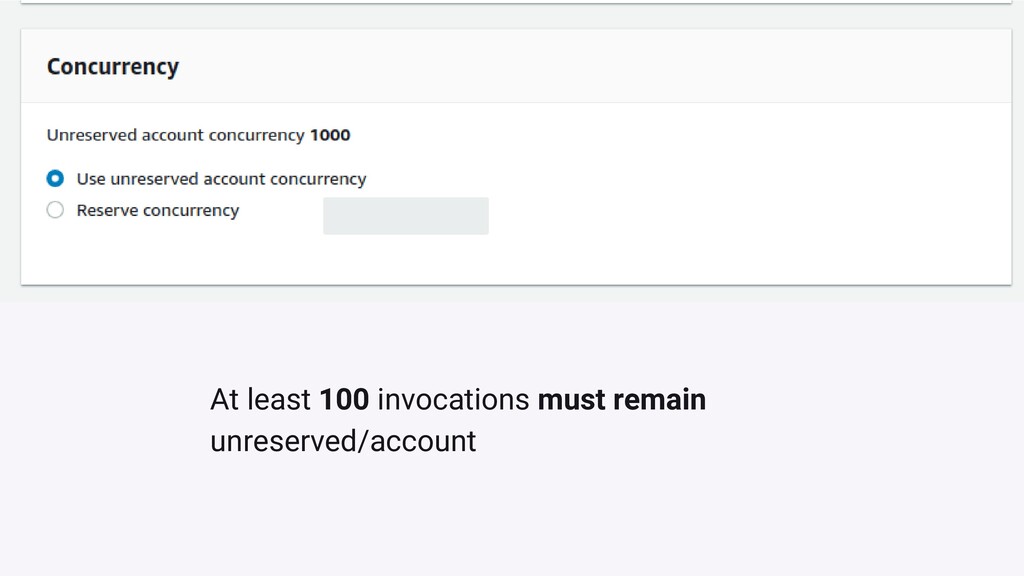
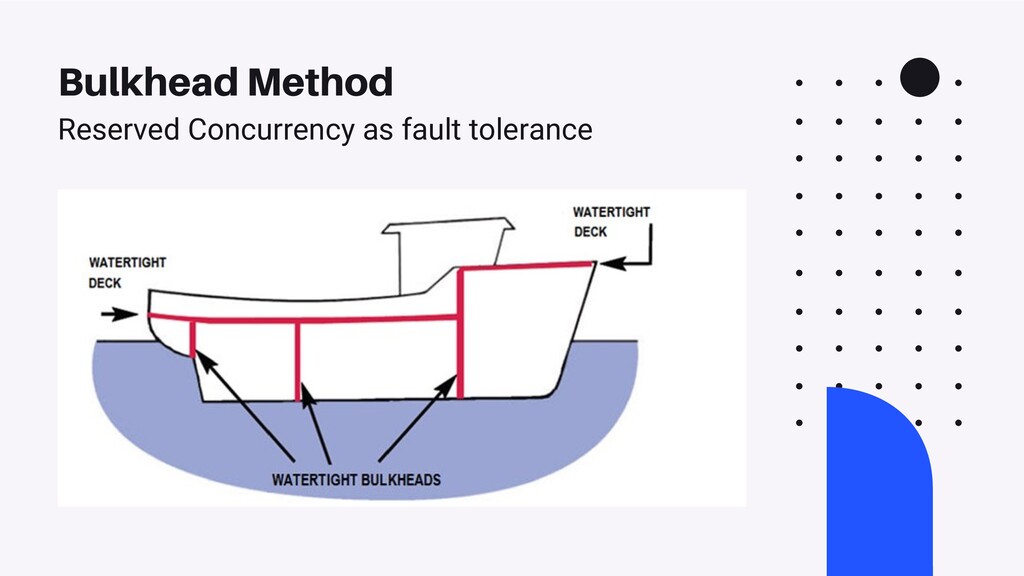
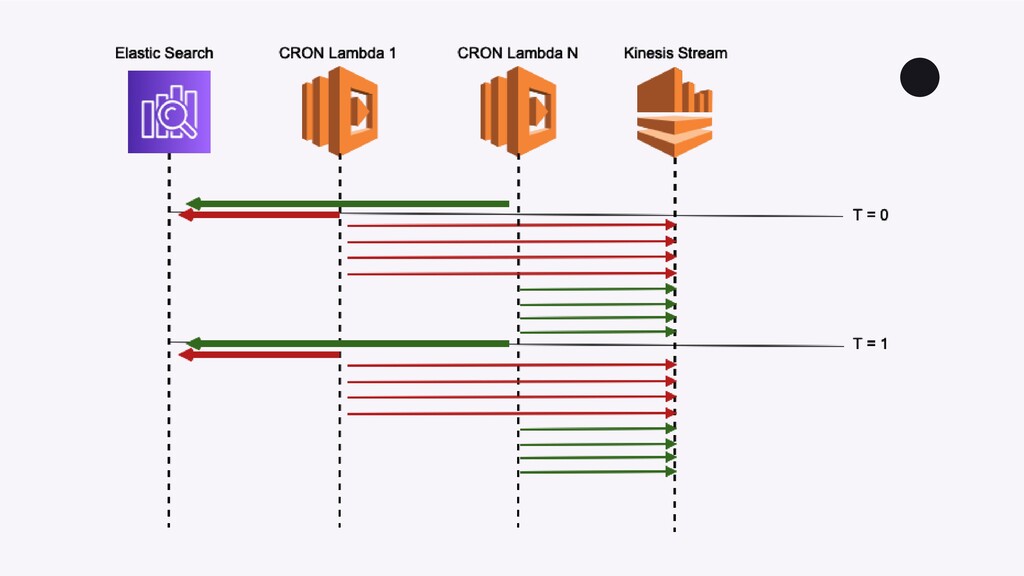
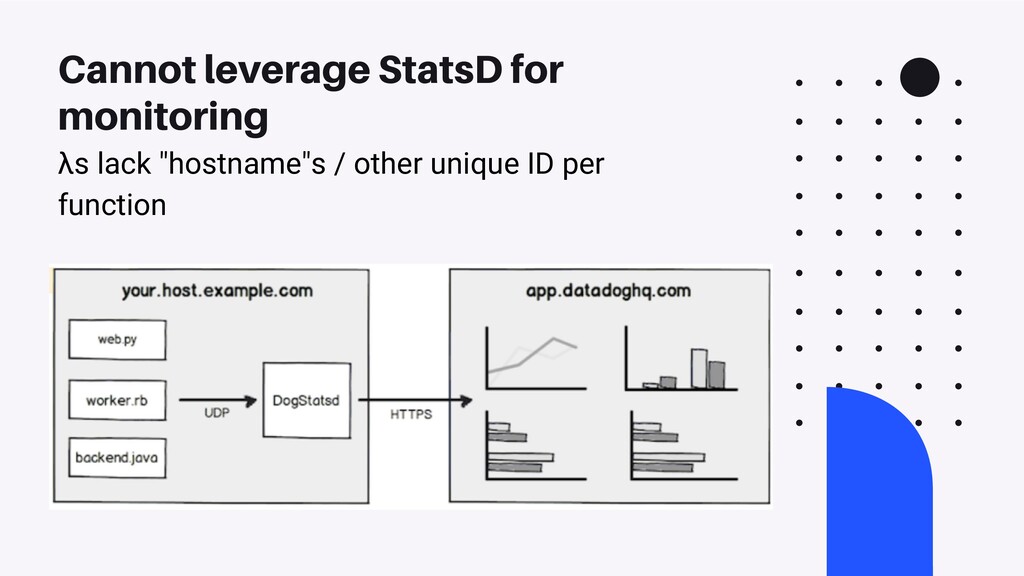
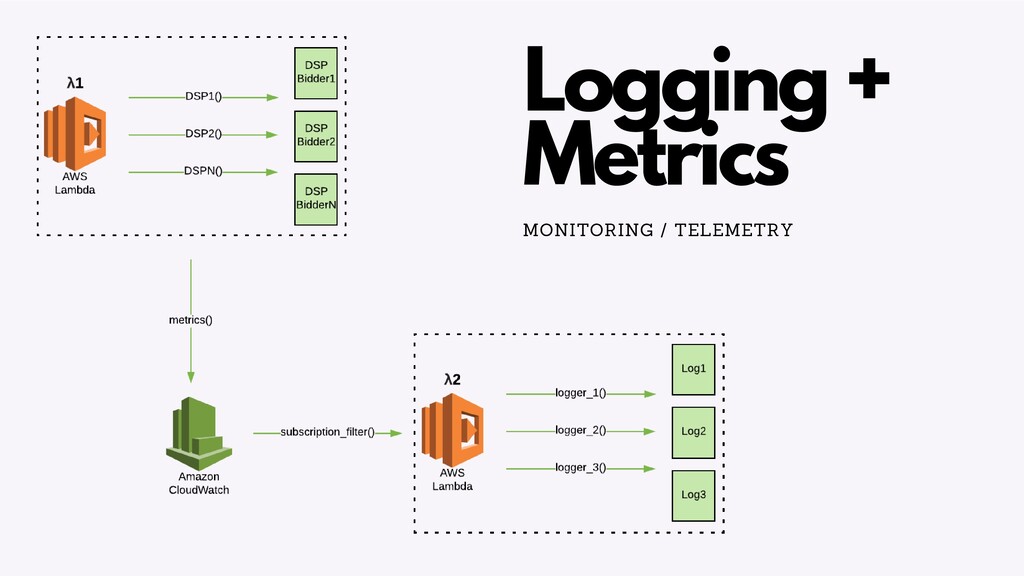
There are a number of limitation based considerations to make when deploying and maintaining an AWS Lambda based architecture at scale. In this talk, we will discuss a wide variety of constraints we considered or discovered and our workarounds or concessions for handling them. Specifically, we will talk about our experiences with: circumventing API Gateway timeouts and concurrent invocation limits experienced during load testing, contending with dependency artifact max size limits during deployment, minimizing cold start times (plus the subsequent maximum execution duration limits that resulted from it), and handling Glue ETL issues experienced when attempting to point Glue Crawlers to s3 artifacts generated from kinesis streams. In a lot of these scenarios, we did not completely solve the problem but instead came up with a solution that works “well enough”, so we will highlight tradeoffs and pro/cons of the approaches we’ve taken.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}