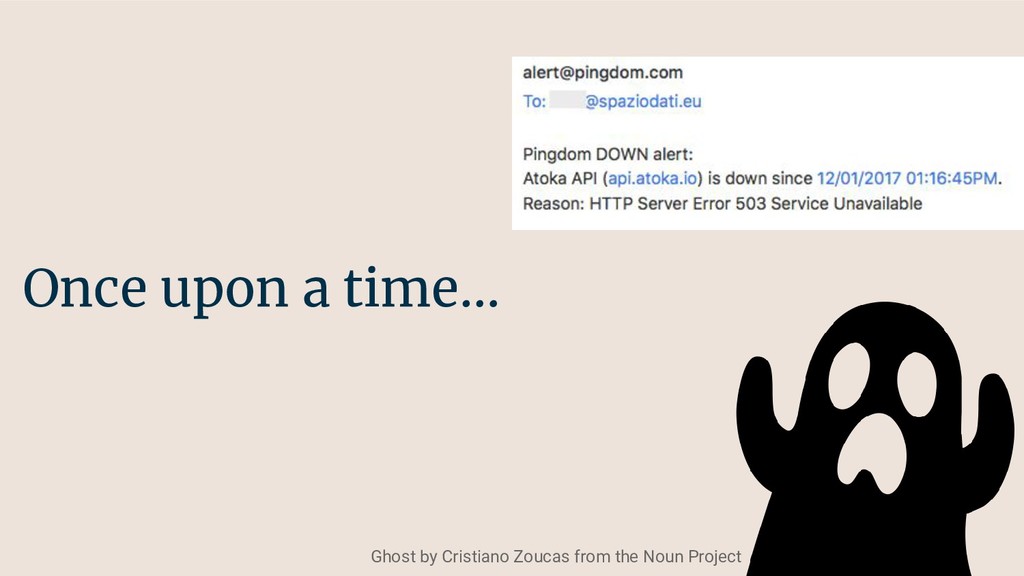
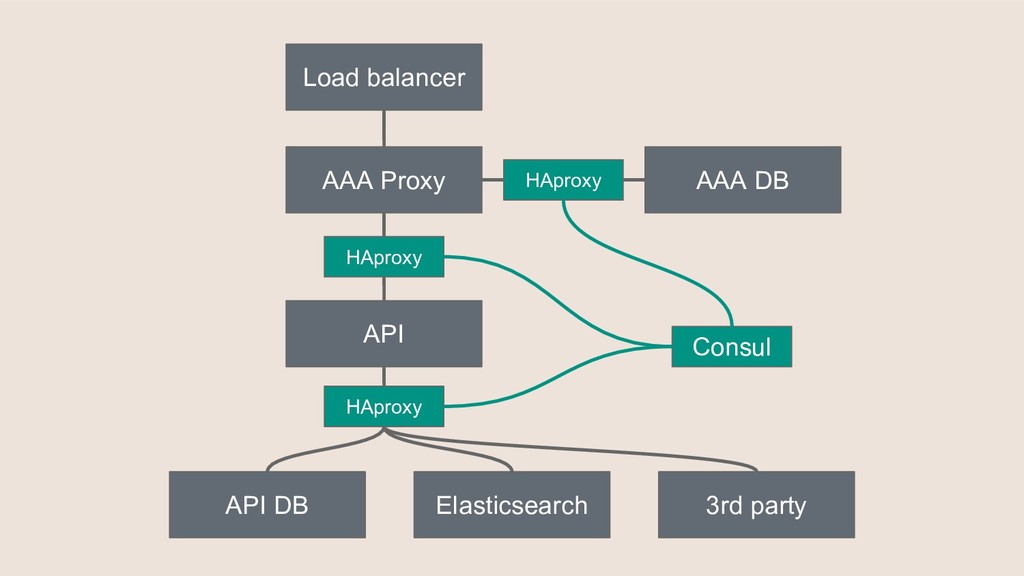
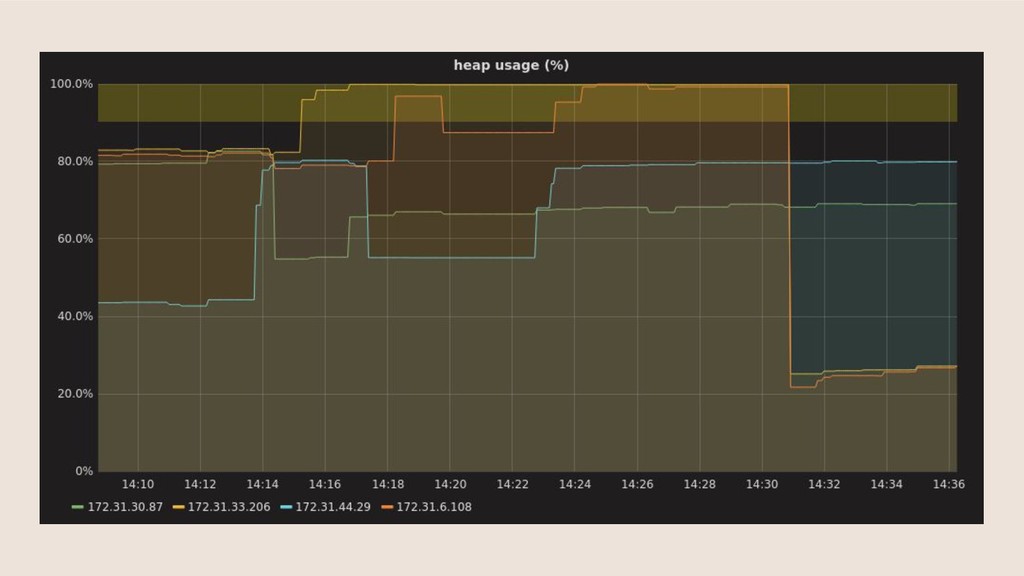
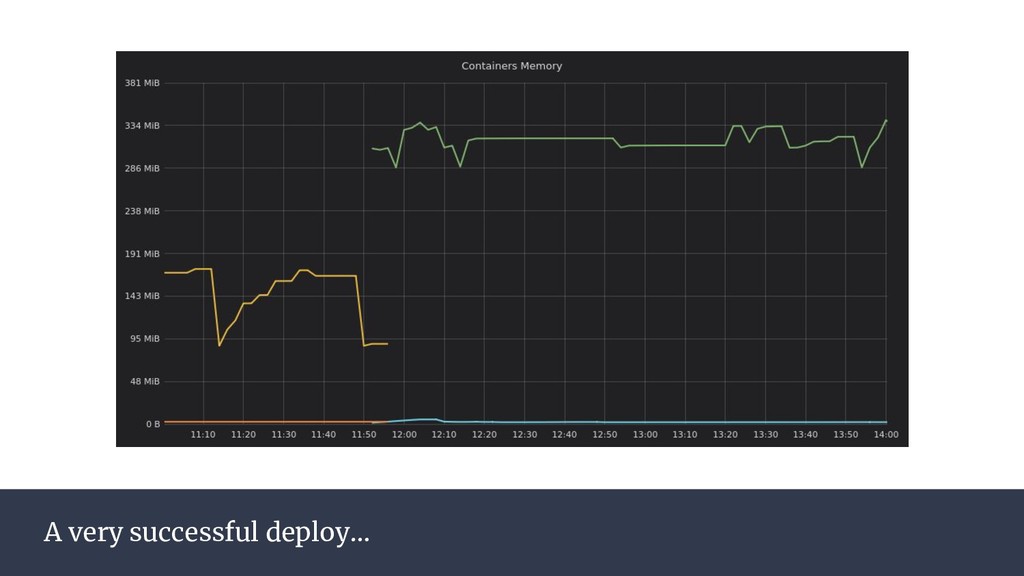
Running a production operation without monitoring is like driving a car without looking out at the road. This presentation aims to convince that monitoring is essential, show how it can be added to any application, and give some examples of what you can achieve with a well reasoned monitoring set-up.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
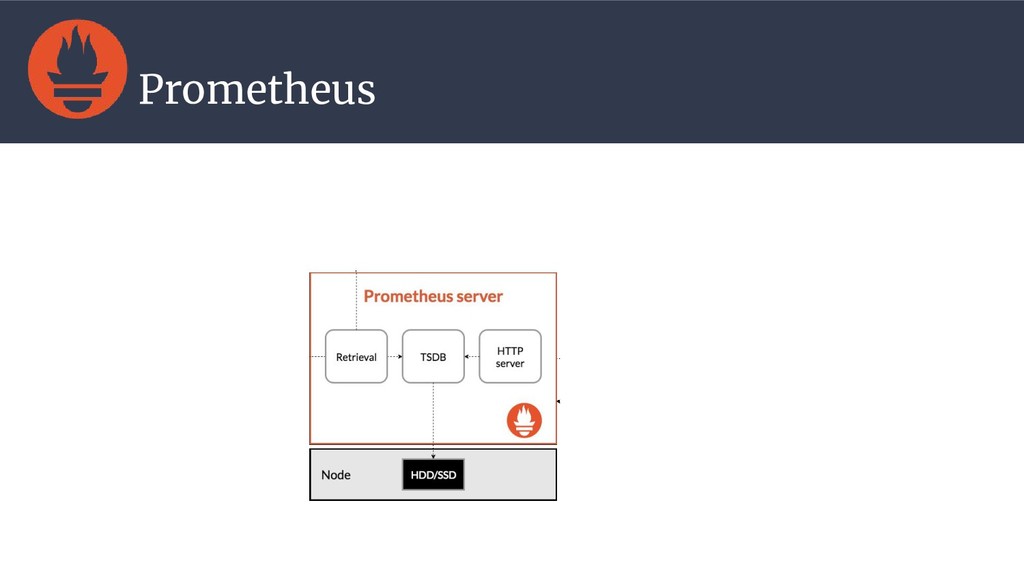{kind=link}
{kind=link}
{kind=link}
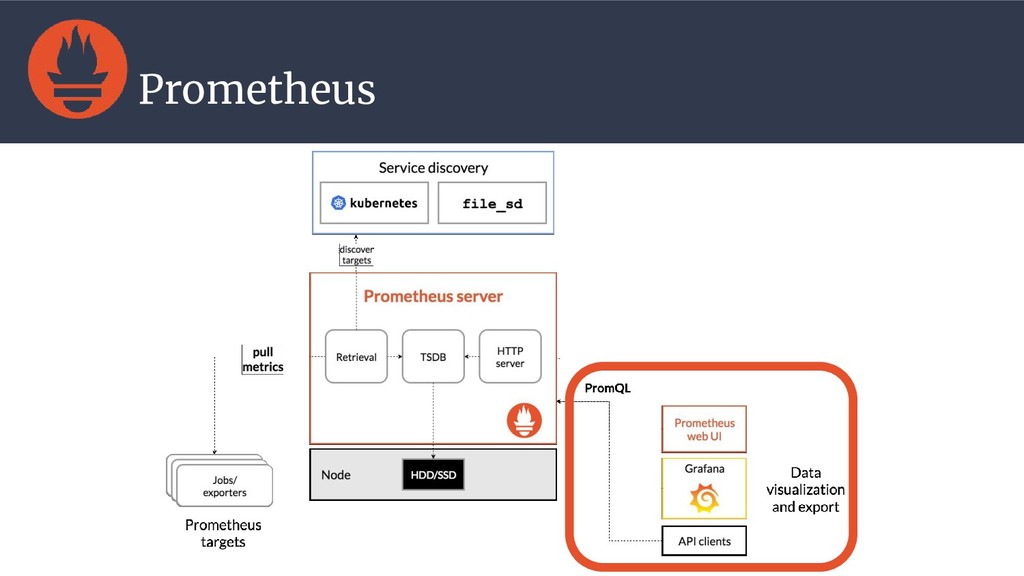{kind=link}
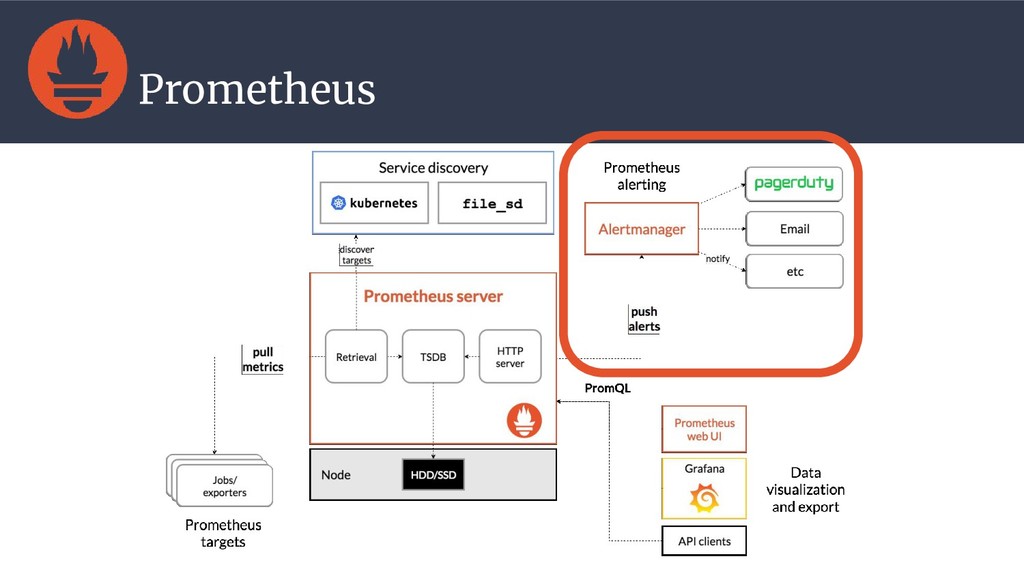{kind=link}
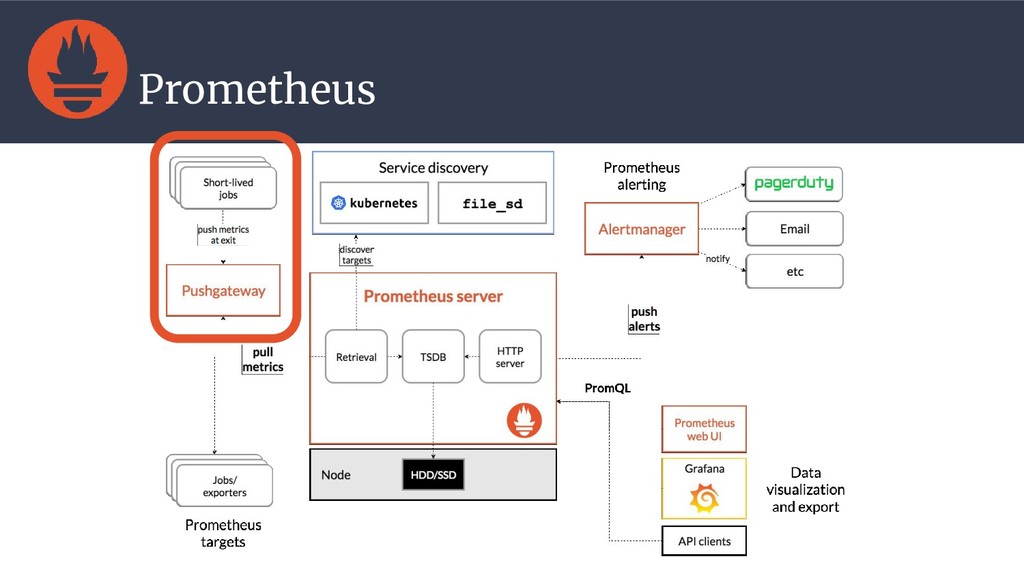{kind=link}
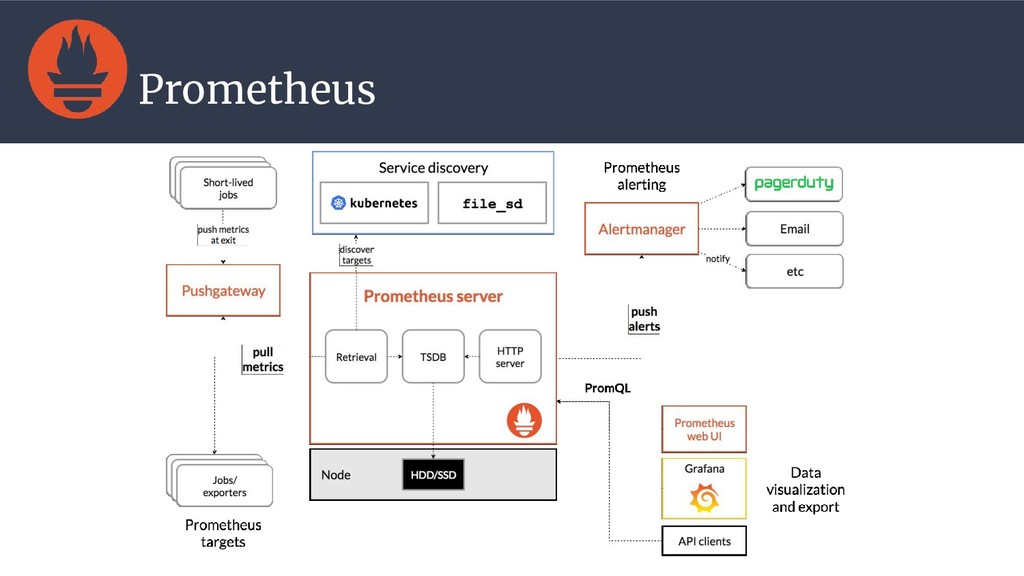{kind=link}
{kind=link}
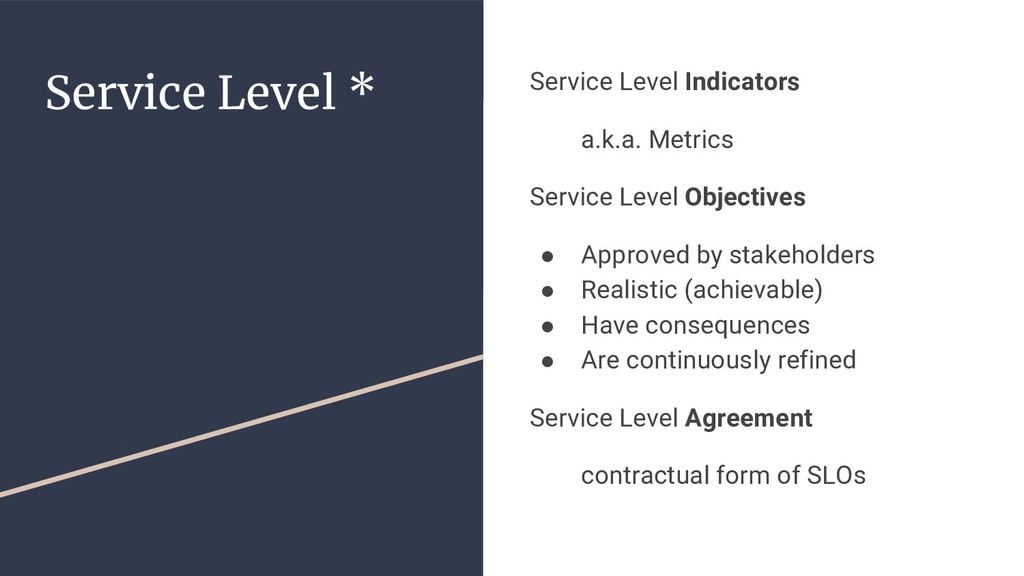{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Alerting rules - alert: CpuCreditsWillFinish expr: predict_linear(cpu_credits[1h], 2 * 3600)](https://files.speakerdeck.com/presentations/babdda7fb52f4f03897ea540b41e0d22/slide_25.jpg){kind=link}
{kind=link}
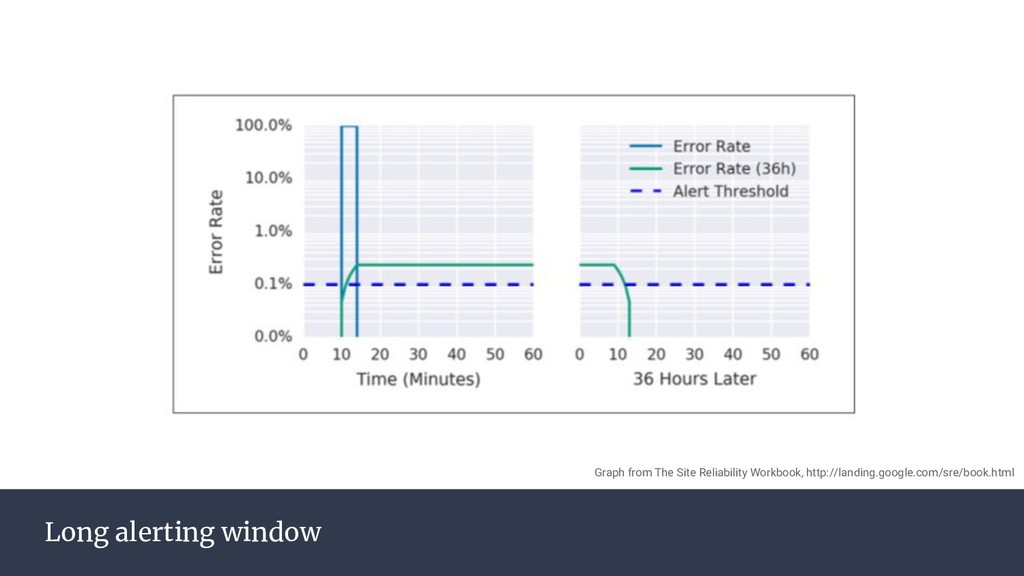{kind=link}
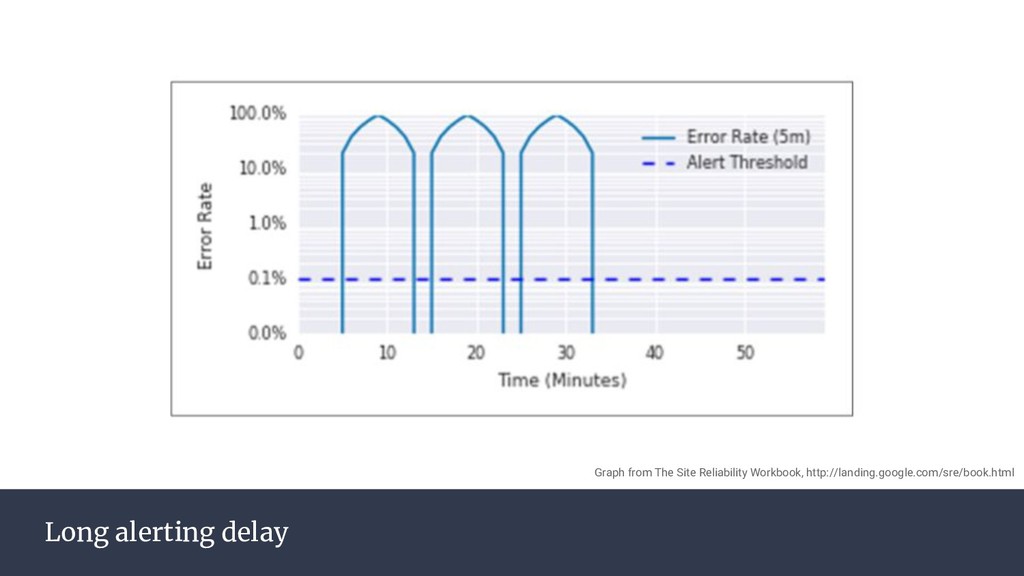{kind=link}
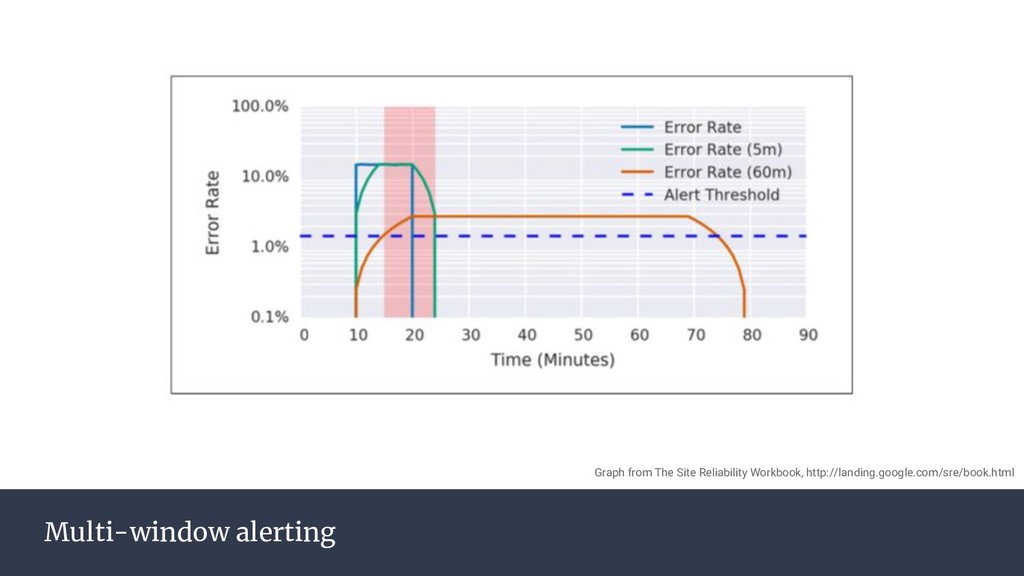{kind=link}
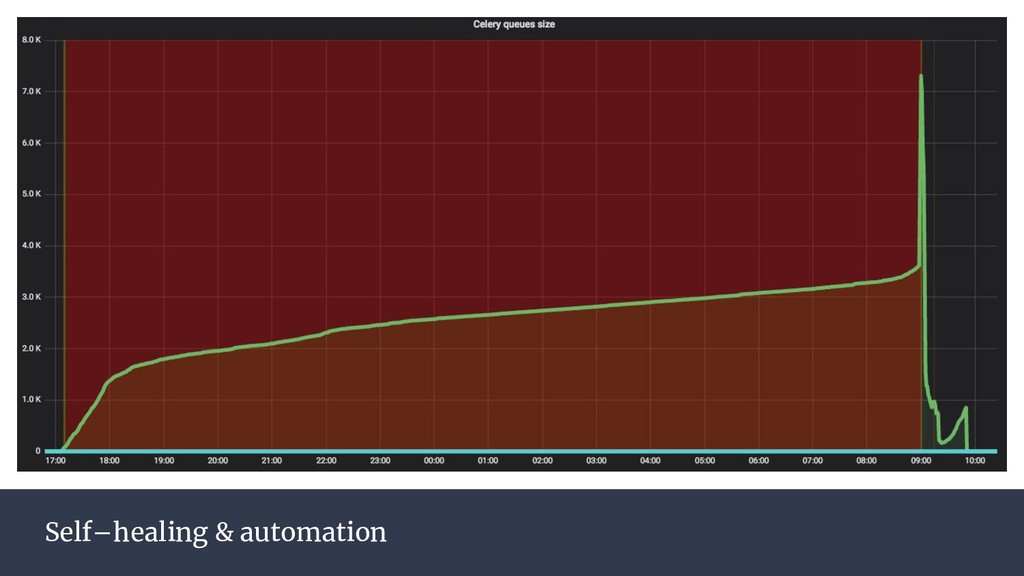{kind=link}
{kind=link}
{kind=link}
![Now go, and monitor ALL THE THINGS! @mpitt [email protected] michele.pittoni.org](https://files.speakerdeck.com/presentations/babdda7fb52f4f03897ea540b41e0d22/slide_33.jpg){kind=link}