Efficient Estimation of Word Representations in Vector Space Distributed Representations of Words and Phrases and their Compositionality (word2vec Parameter Learning Explained) (word2vec Explained: Deriving Mikolov et al’s Negative Sampling Word-Embedding Method) mt_caret (kml輪講) word2vec + 2018-05-25 2 / 28
large improvements in accuracy at much lower computa- tional cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities. 図 10: CBOWとSkip-gramの結果 mt_caret (kml輪講) word2vec + 2018-05-25 19 / 28
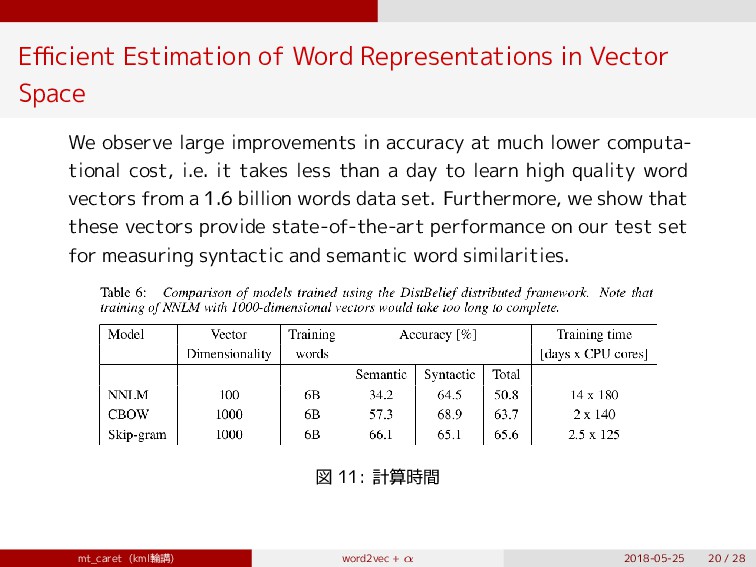
large improvements in accuracy at much lower computa- tional cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities. 図 11: 計算時間 mt_caret (kml輪講) word2vec + 2018-05-25 20 / 28
speed is significantly higher than reported earlier in this paper, i.e. it is in the order of billions of words per hour for typical hyperparameter choices. We also published more than 1.4 million vec- tors that represent named entities, trained on more than 100 billion words. Some of our follow-up work will be published in an upcoming NIPS 2013 paper. mt_caret (kml輪講) word2vec + 2018-05-25 21 / 28
paper Hierarchical Softmax – Building Babylon How does sub-sampling of frequent words work in the context of Word2Vec? - Quora Approximating the Softmax for Learning Word Embeddings A gentle introduction to Doc2Vec – ScaleAbout – Medium 異空間への埋め込み!Poincare Embeddingsが拓く表現学習の新展開 - ABEJA Arts Blog Neural Network Methods for Natural Language Processing mt_caret (kml輪講) word2vec + 2018-05-25 28 / 28
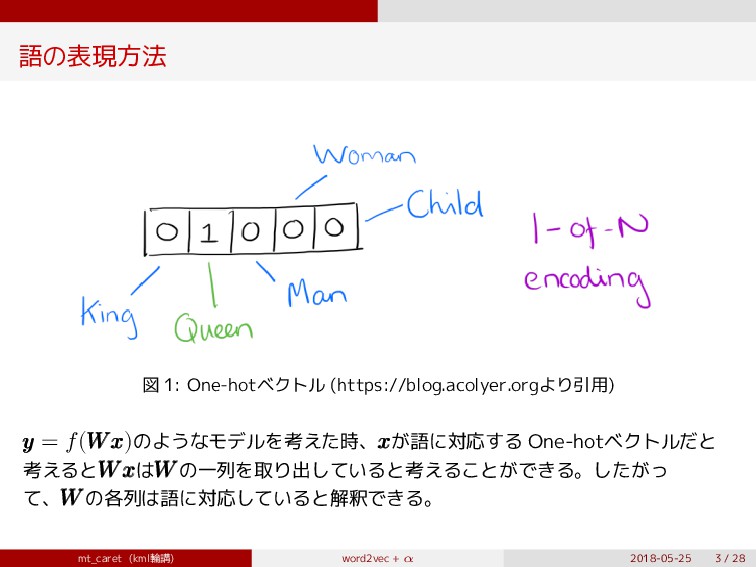
{kind=link}
{kind=link}
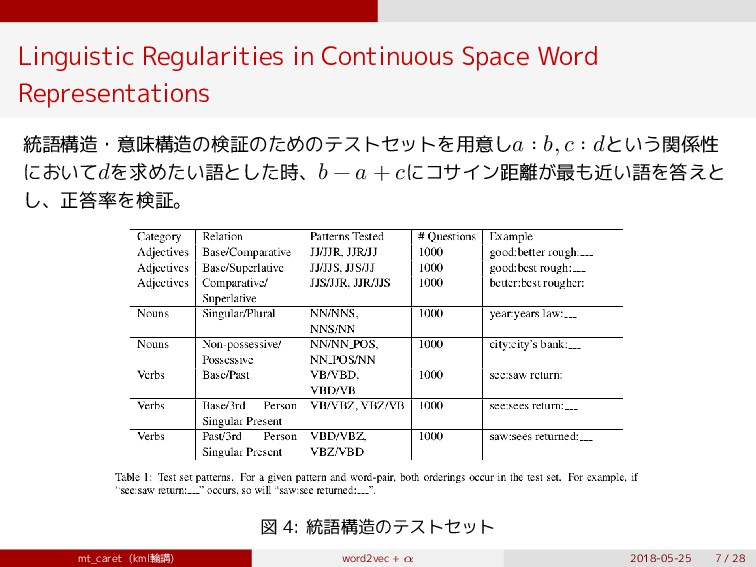
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
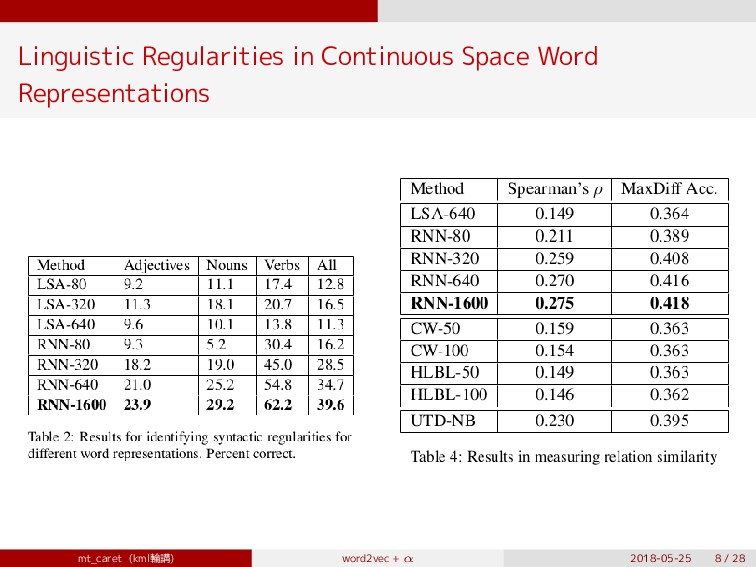{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}