Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
会議の議事録作成を省力化したい
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
murakami0923
July 15, 2025
Business
45
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
会議の議事録作成を省力化したい
AWSのAmazon Transcribeで、録画あるいは録音したデータを文字に起こし、誰が何の発言をしたのかを自動的・半自動的に記録する方法を試しました。
murakami0923
July 15, 2025
More Decks by murakami0923
See All by murakami0923
ベクトルデータベースあれこれ ~RAGのために~
murakami0923
0
29
2022/10/21 bitstar CROSS 2022 in EZO AWS ECSでのバックエンドの開発について
murakami0923
0
130
2022/08/06 JavaDo n+1問題に気を付けよう
murakami0923
0
380
Other Decks in Business
See All in Business
AWS Summit Taipei 2026: Decomposing Ontology and Agentic AI - Using Amazon Bedrock to Bring Living Water to Manufacturing ERP
dwchiang
0
380
2026.8_中途採用資料.pdf
superstudio
PRO
5
120k
「この数字おかしくない?」対応に追われていたのに、 Claude Codeで設計改善まで着手できた話
matsumotokoki
0
230
会社説明資料2026.7.1
mforce
0
190
スクラムマスターの観察眼 〜AIによる3days爆速キャッチアップと次の一手〜/The Scrum Master's Insight: Lightning-Fast 3-Day Catch-Up with AI and the Next Move
ikuodanaka
3
540
人生初のマネージャーというロールを 経験して得たもの・失ったもの / Reflections on My First Manager Role
mackey0225
0
730
スマートキャンプ株式会社 会社紹介資料 / companydeck
smartcamp
19
750k
01_全社_FLUX採用ピッチ資料_Ver.5.4
flux
11
220k
Facilo Company Deck202607_採用サイト用
facilo_inc
0
150
こだわりを手放したことで気づけたスクラムマスターとしての振る舞い
kawanotron
1
260
「正しいはずの依頼」が届かなかった理由
geneguchi
0
3.2k
株式会社ヤプリ_会社紹介資料
yappli_recruit
0
480
Featured
See All Featured
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.6k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.7k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
650
Navigating Weather and Climate Data
rabernat
0
430
The Invisible Side of Design
smashingmag
301
52k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
330
Testing 201, or: Great Expectations
jmmastey
46
8.2k
The Language of Interfaces
destraynor
162
27k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
The SEO Collaboration Effect
kristinabergwall1
1
510
Transcript
© 2025 Masashi Murakami All Right Reserved. 1 会議の議事録作成を省力化したい 2025/07/11
村上 將志
© 2025 Masashi Murakami All Right Reserved. 2 はじめに
© 2025 Masashi Murakami All Right Reserved. 3 はじめに 大事な会議では、どのような議論があって、何が決定したか、その後の宿題が何か、しっかり把握
するために、記録を撮っておくことが大切です。 一方で、会議に参加する際、議事録や議事メモ作成のためにメモを取りながら議論に参加するのは 大変ですし、自分が議論に入っている時はメモを飛ばしてしまうことも多々あります。 2020年のコロナ禍以降、ZoomやTeams、Webexなどでのオンラインの会議が増え、各ツールの録 画機能やOSでのデスクトップ録画機能などで録画をすることで振り返りにも使える一方、録画をす べてチェックする時間を取りにくいのが現実です。 そこで、AWS (Amazon Web Services)のAmazon Transcribeを用いて、録画あるいは録音した データを文字に起こし、誰が何の発言をしたのかを自動的・半自動的に記録したいと考えました。
© 2025 Masashi Murakami All Right Reserved. 4 試したこと Amazon
Transcribeで音声を文字起こしするため、下記の流れで行うことにしました。 1. 録画データを音声データに変換(ffmpegコマンド) • ※Amazon Transcribeでは動画ファイルをサポートしていないため、音声に変換します。 2. 音声データをAmazon S3にアップロード 3. Amazon TranscribeでS3上の音声を文字起こし • ※参加者の人数(最大話者数)を設定することで、声ごとに分類 4. 文字起こしのJSONファイルをダウンロード 5. Jupyter Notebookで下記の処理を実行 1. JSONを解析して話者ごとの発言内容を表示 2. 発言内容から、話者を特定→自動化不可能のため人力 3. フィラー(「えー」、「ええと」、「あのー」など)を除去 4. 会話内容をExcelに保存
© 2025 Masashi Murakami All Right Reserved. 5 前提 •
ffmpegコマンド、Jupyter Notebookの実行は、Ubuntu 24.04上で行う前提とします。 – ※Windows 11のWSL2上にUbuntu 24.04をインストールして使用しています。 • Ubuntuの中にPython 3.11、pipがインストールされている前提とします。 – ※もっと新しいバージョンでも動くとは思いますが、作成時点の3.11に合わせた方が確実 かと思います。 – ※作成時点はpyenvでPythonのバージョンを管理し、Jupyter Notebook実行のディレク トリ内にvenvを作成する方法を採りました。 • AWS (Amazon Web Services)にアカウントがあり、ユーザーに必要な権限が割り当てられて いる前提とします。 – S3バケット作成、S3への読み書き、Transcribe実行など – Power User権限のあるユーザーで確認しました。
© 2025 Masashi Murakami All Right Reserved. 6 前提 Amazon
Transcribeの音声認識ファイルの解析用Jupyter Notebookは https://github.com/murakami0923/the-minutes-python-analyze/tree/main に入れてあります。 ※「main」ブランチで作成中
© 2025 Masashi Murakami All Right Reserved. 7 録画データを音声データに変換 (ffmpegコマンド)
© 2025 Masashi Murakami All Right Reserved. 8 録画データを音声データに変換(ffmpegコマンド) •
Ubuntuにffmpegをインストールします。 – sudo apt install -y ffmpeg • Ubuntuに動画ファイルをアップロードします。 • ffmpegコマンドで変換を実行します。 – ffmpeg -i {mp4ファイル名} {mp3ファイル名}
© 2025 Masashi Murakami All Right Reserved. 9 音声データをAmazon S3にアップロード
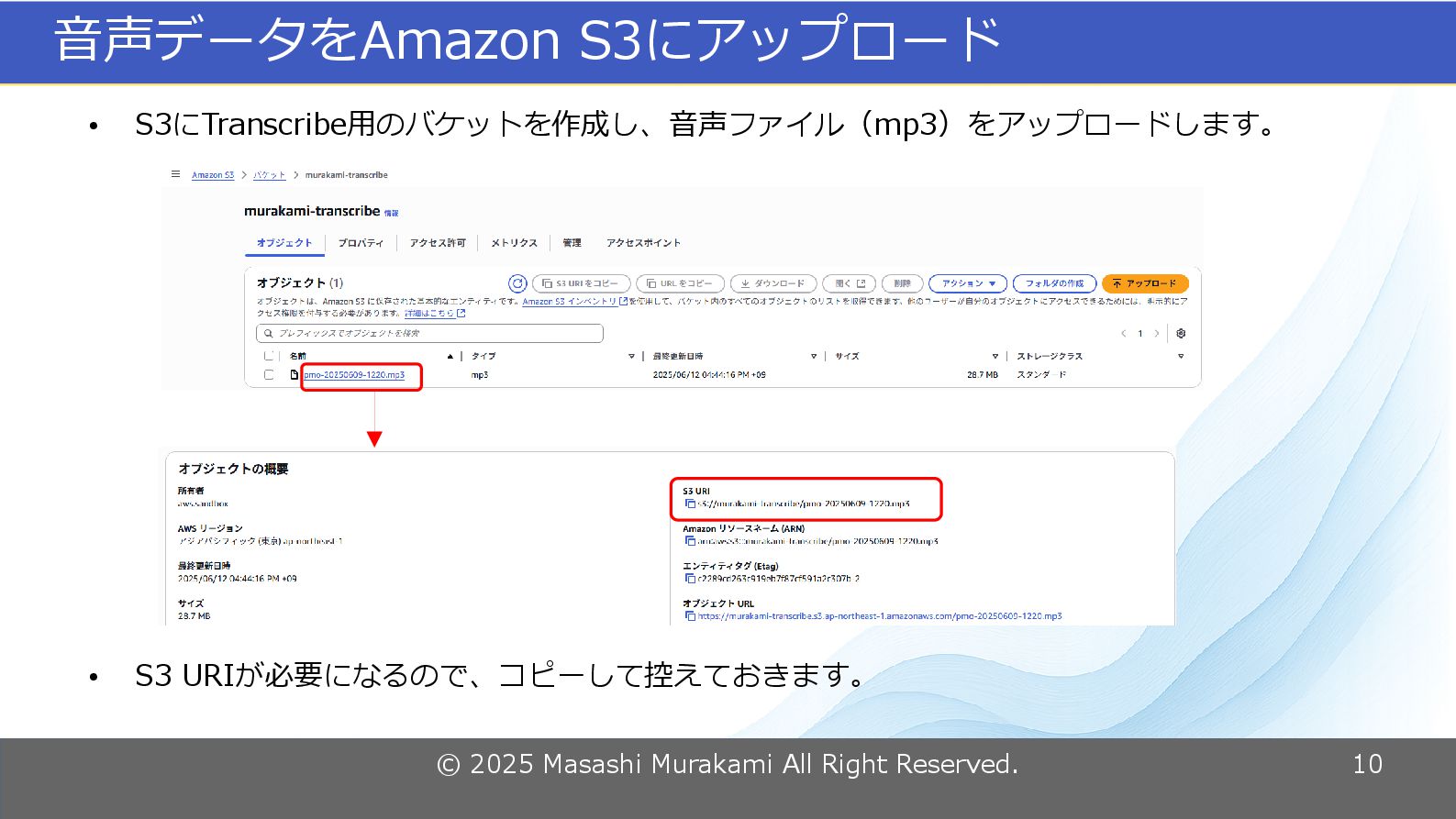
© 2025 Masashi Murakami All Right Reserved. 10 音声データをAmazon S3にアップロード
• S3にTranscribe用のバケットを作成し、音声ファイル(mp3)をアップロードします。 • S3 URIが必要になるので、コピーして控えておきます。
© 2025 Masashi Murakami All Right Reserved. 11 Amazon TranscribeでS3上の音声を文字起こし
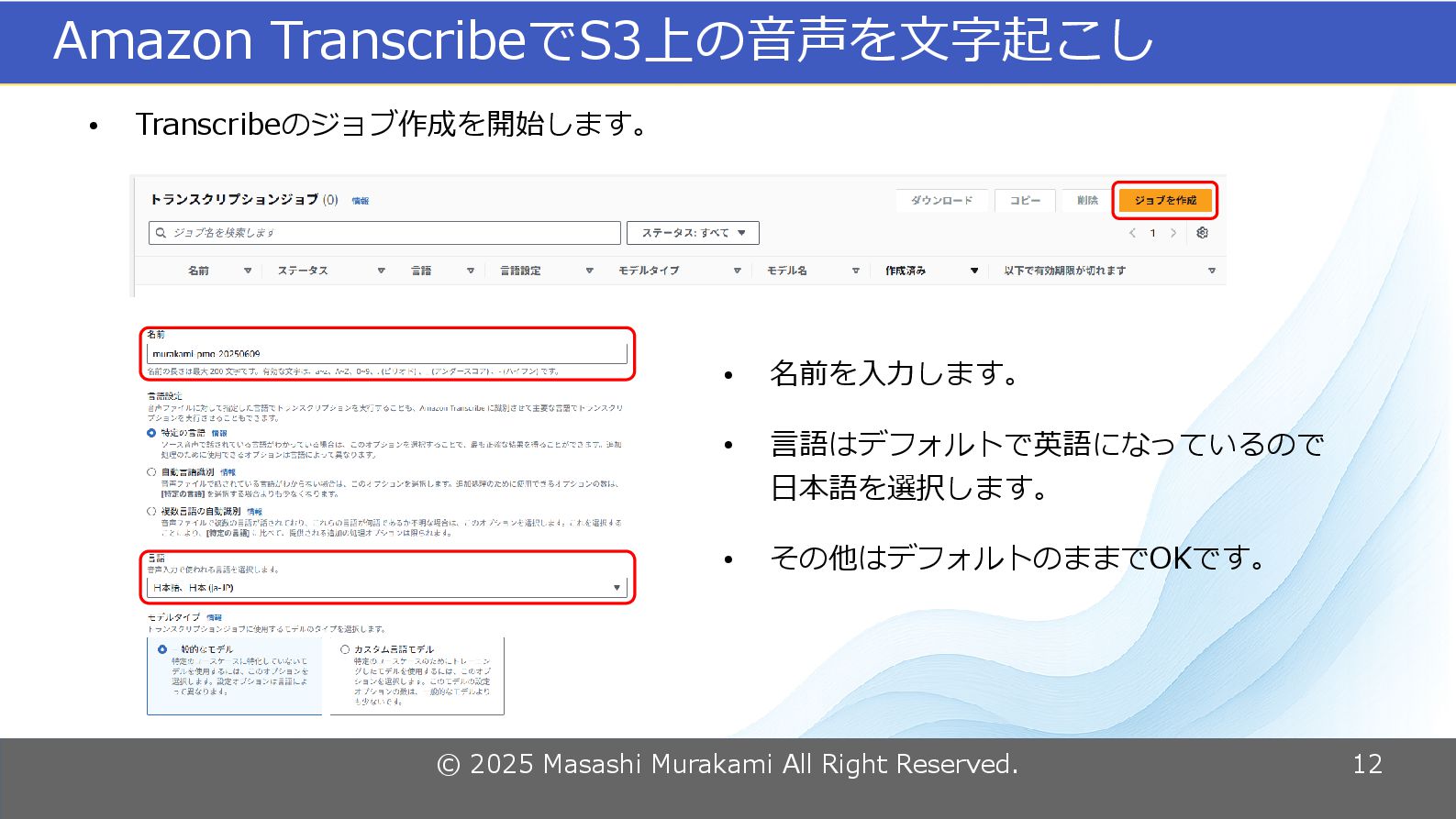
© 2025 Masashi Murakami All Right Reserved. 12 Amazon TranscribeでS3上の音声を文字起こし
• Transcribeのジョブ作成を開始します。 • 名前を入力します。 • 言語はデフォルトで英語になっているので 日本語を選択します。 • その他はデフォルトのままでOKです。
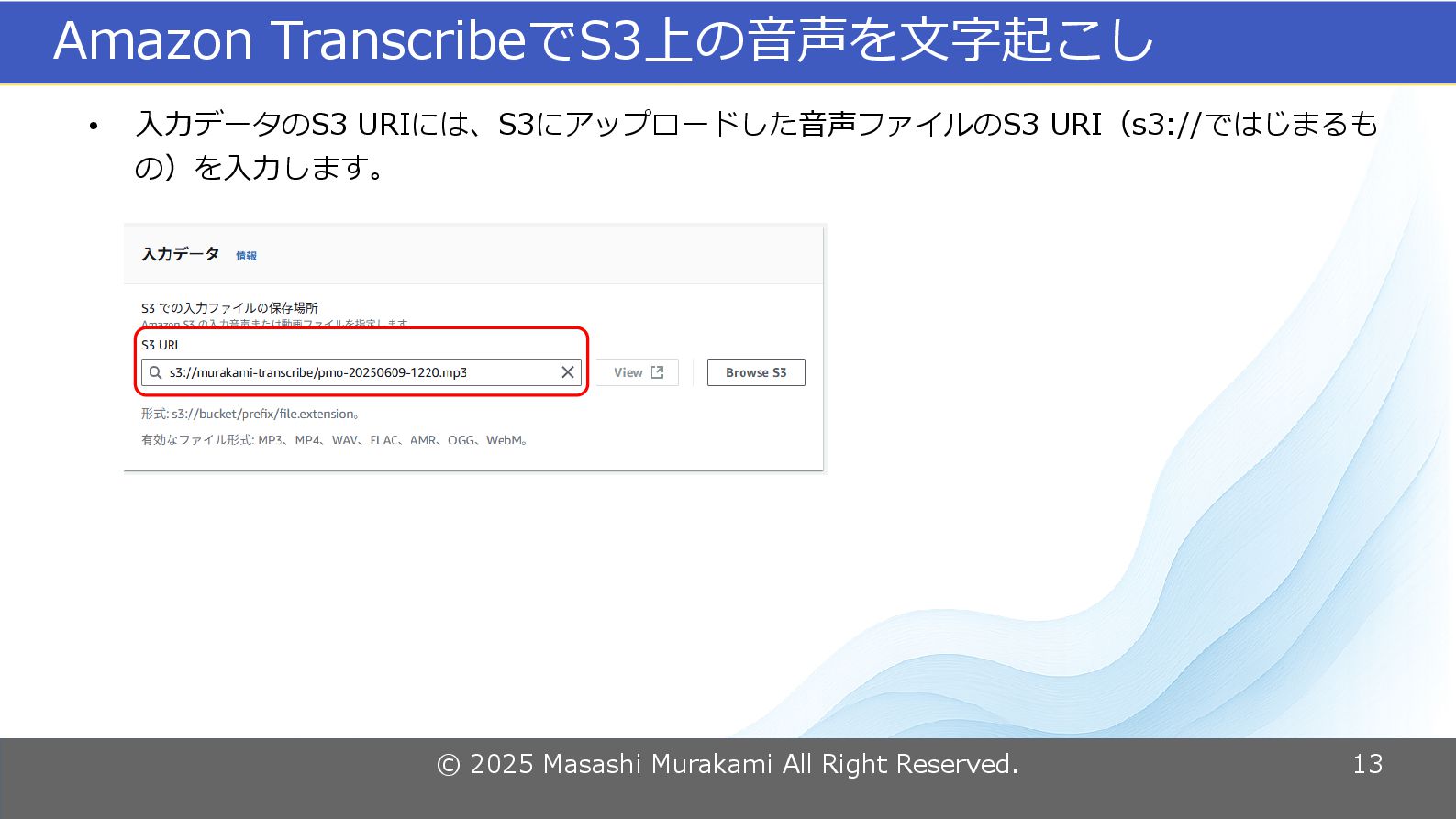
© 2025 Masashi Murakami All Right Reserved. 13 Amazon TranscribeでS3上の音声を文字起こし
• 入力データのS3 URIには、S3にアップロードした音声ファイルのS3 URI(s3://ではじまるも の)を入力します。
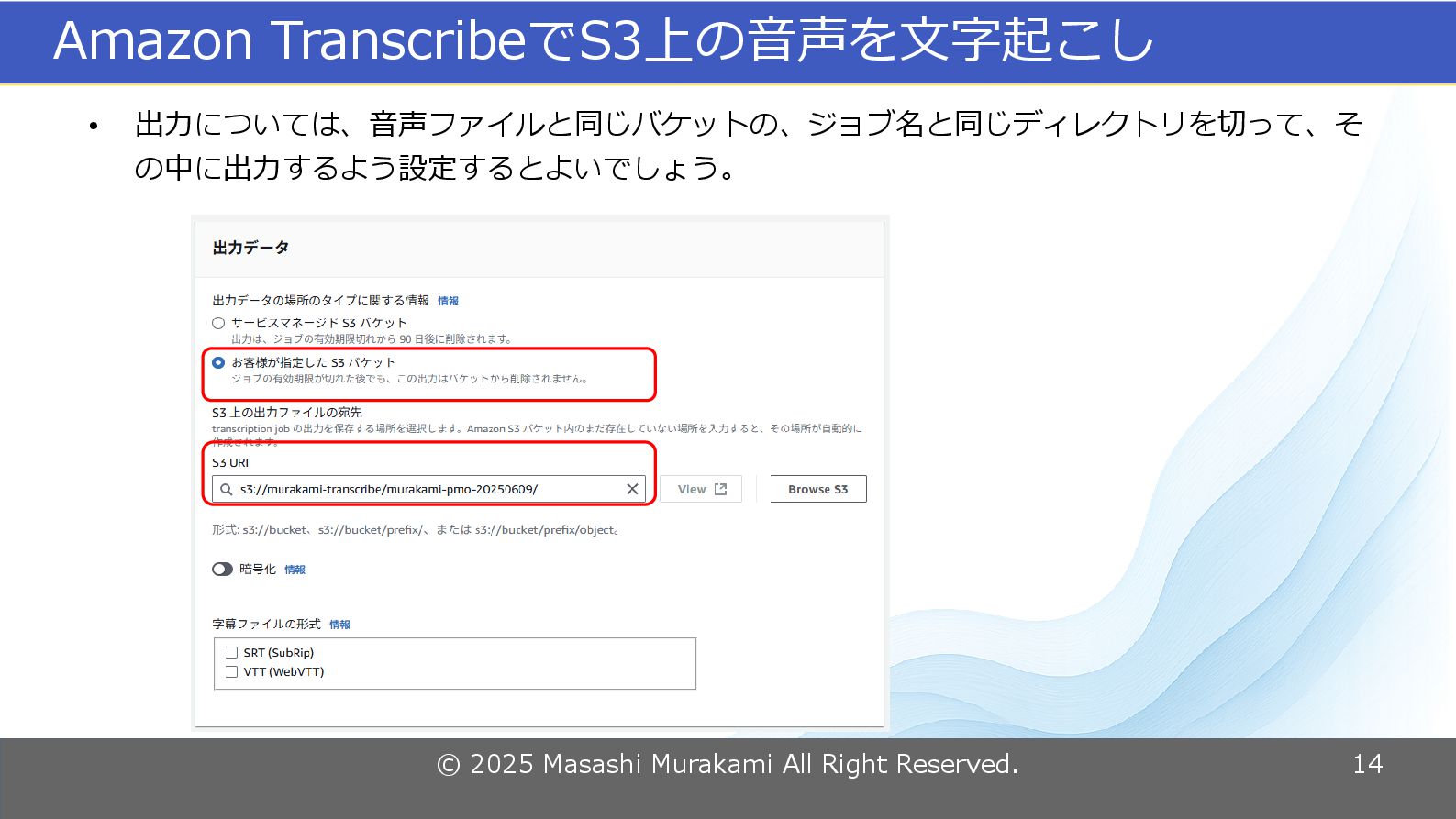
© 2025 Masashi Murakami All Right Reserved. 14 Amazon TranscribeでS3上の音声を文字起こし
• 出力については、音声ファイルと同じバケットの、ジョブ名と同じディレクトリを切って、そ の中に出力するよう設定するとよいでしょう。
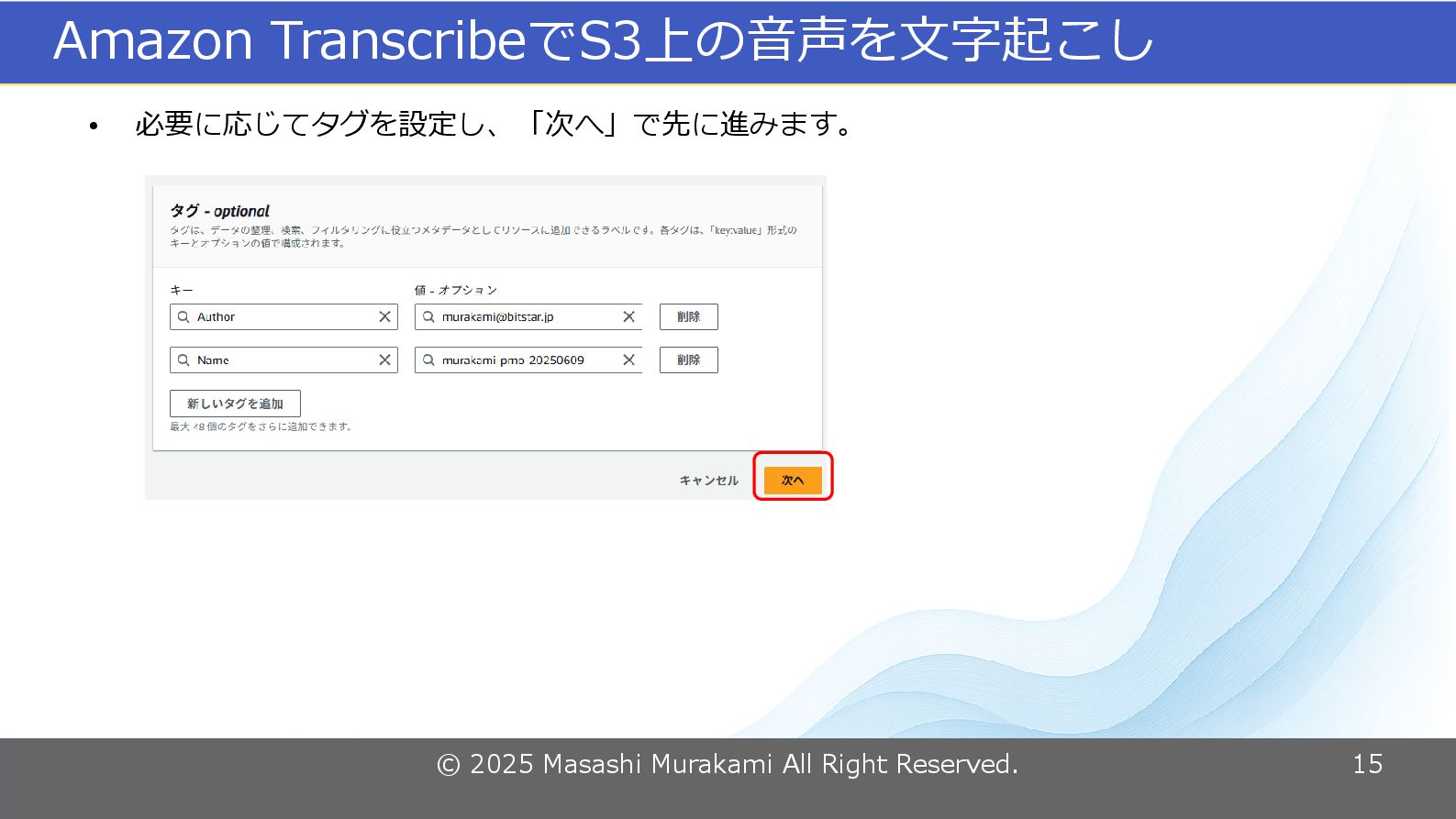
© 2025 Masashi Murakami All Right Reserved. 15 Amazon TranscribeでS3上の音声を文字起こし
• 必要に応じてタグを設定し、「次へ」で先に進みます。
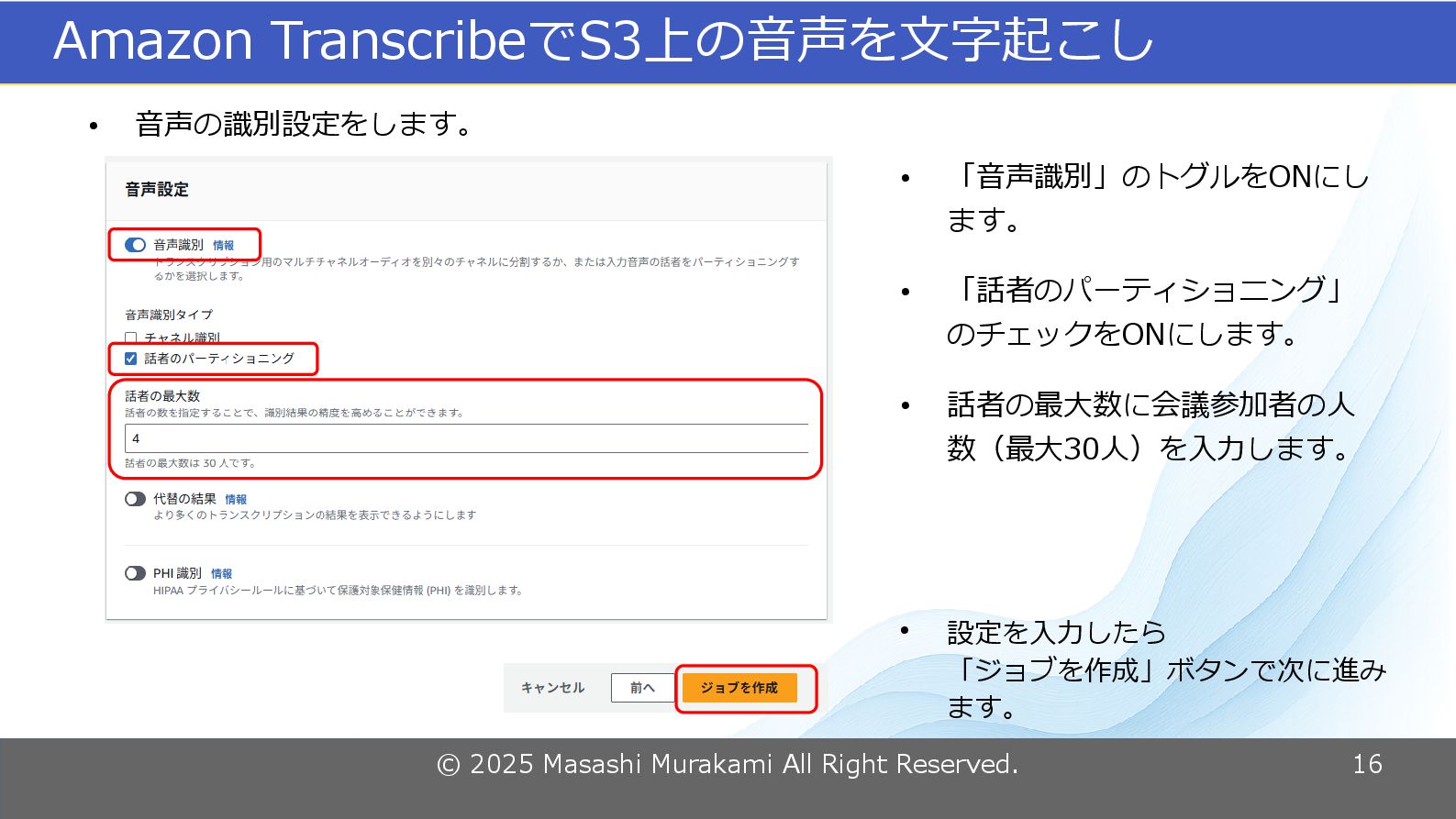
© 2025 Masashi Murakami All Right Reserved. 16 Amazon TranscribeでS3上の音声を文字起こし
• 音声の識別設定をします。 • 「音声識別」のトグルをONにし ます。 • 「話者のパーティショニング」 のチェックをONにします。 • 話者の最大数に会議参加者の人 数(最大30人)を入力します。 • 設定を入力したら 「ジョブを作成」ボタンで次に進み ます。
© 2025 Masashi Murakami All Right Reserved. 17 Amazon TranscribeでS3上の音声を文字起こし
• ジョブの一覧ページに戻るため、ステータスを確認しながら、完了するまで待ちます。 • ステータスが「完了」になったら次の手順に進みます。
© 2025 Masashi Murakami All Right Reserved. 18 文字起こしのJSONファイルをダウンロード
© 2025 Masashi Murakami All Right Reserved. 19 文字起こしのJSONファイルをダウンロード •
S3のバケットを再表示すると、Transcribeで指定したディレクトリができているので、ディレ クトリの中に入ります。 • jsonファイルができているので、ダウンロードし、Jupyter Notebook環境の 「notebooks/data」ディレクトリに保存します。
© 2025 Masashi Murakami All Right Reserved. 20 Jupyter Notebookで下記の処理を実行
© 2025 Masashi Murakami All Right Reserved. 21 Jupyter Notebookで下記の処理を実行
• Jupyter Notebookシート:analyze-amazon-transcribe-json.ipynb • 使用方法: – セル1つずつを順に実行します。 • ※途中、コードを修正する必要があるため – 前のセルに、speaker_labelごとに会話内容が表示されるので、その内容をもとに、 speaker_labelごとに名前設定する欄に、話者の名前を記載します。 – その後は最後まで順に実行します。
© 2025 Masashi Murakami All Right Reserved. 22 さいごに
© 2025 Masashi Murakami All Right Reserved. 23 さいごに(現状課題と将来について) •
Amazon Transcribeでの固有名詞について – カスタムボキャブラリーを設定し、固有名詞の認識精度の向上を試みたいと考えています。 • 話者の名前の設定について – 現状、会話の内容から手作業で設定するようにしていますが、将来的には、人の口癖などから 予測する仕組みを考えてみたいと考えています。 • フィラーの除去後について – フィラーを除去した後、同じ話者の会話が続くケースがみられたため、再度会話データのマー ジを実装したいと考えています。
© 2025 Masashi Murakami All Right Reserved. 24 ありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}