第28回情報論的学習理論ワークショップ(IBIS)2025、企画セッション3「アルゴリズム・データ構造と機械学習」、2025/11/14, @那覇, 沖縄
松井勇佑(東京大学)https://yusukematsui.me/index_jp.html
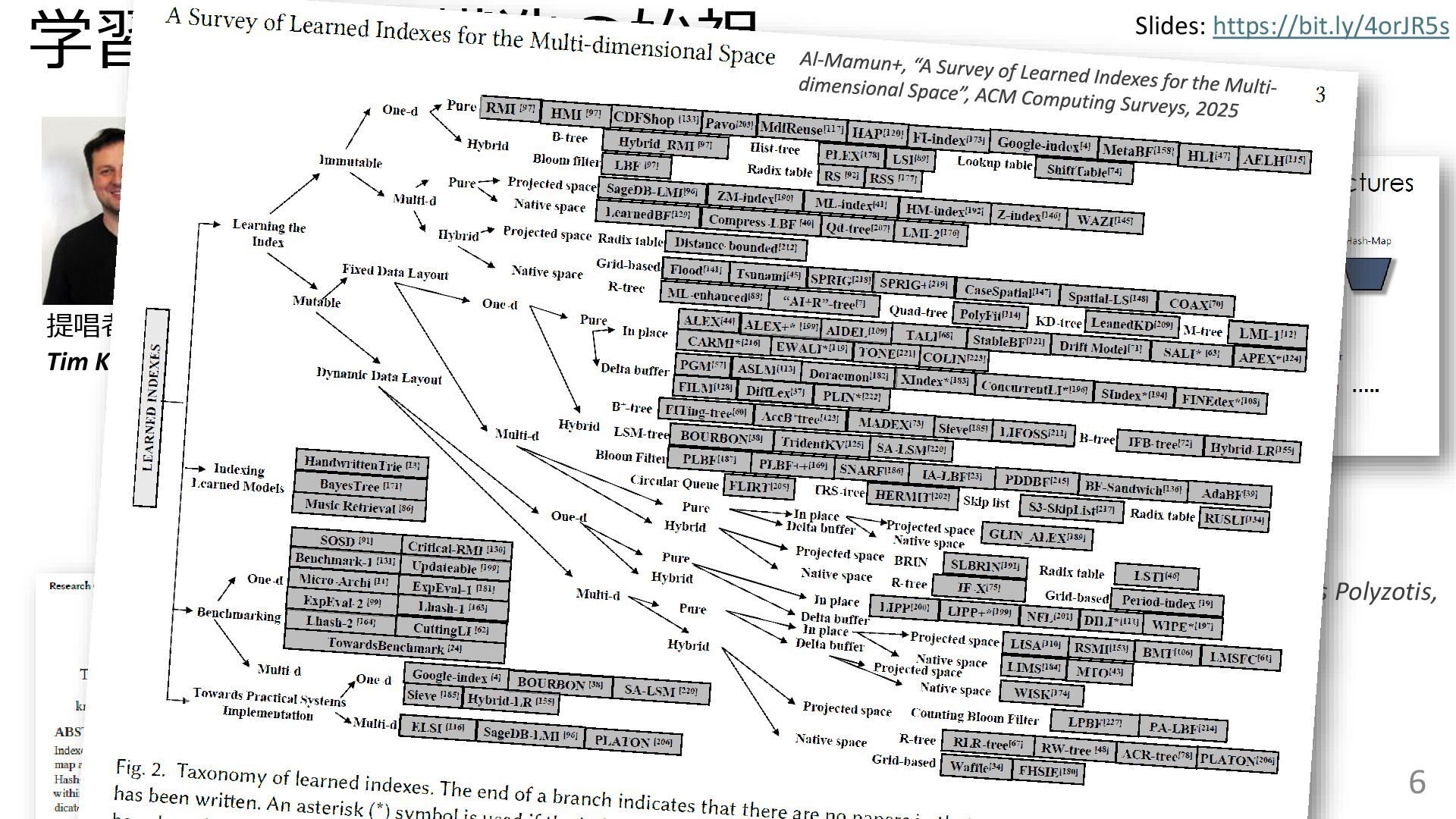
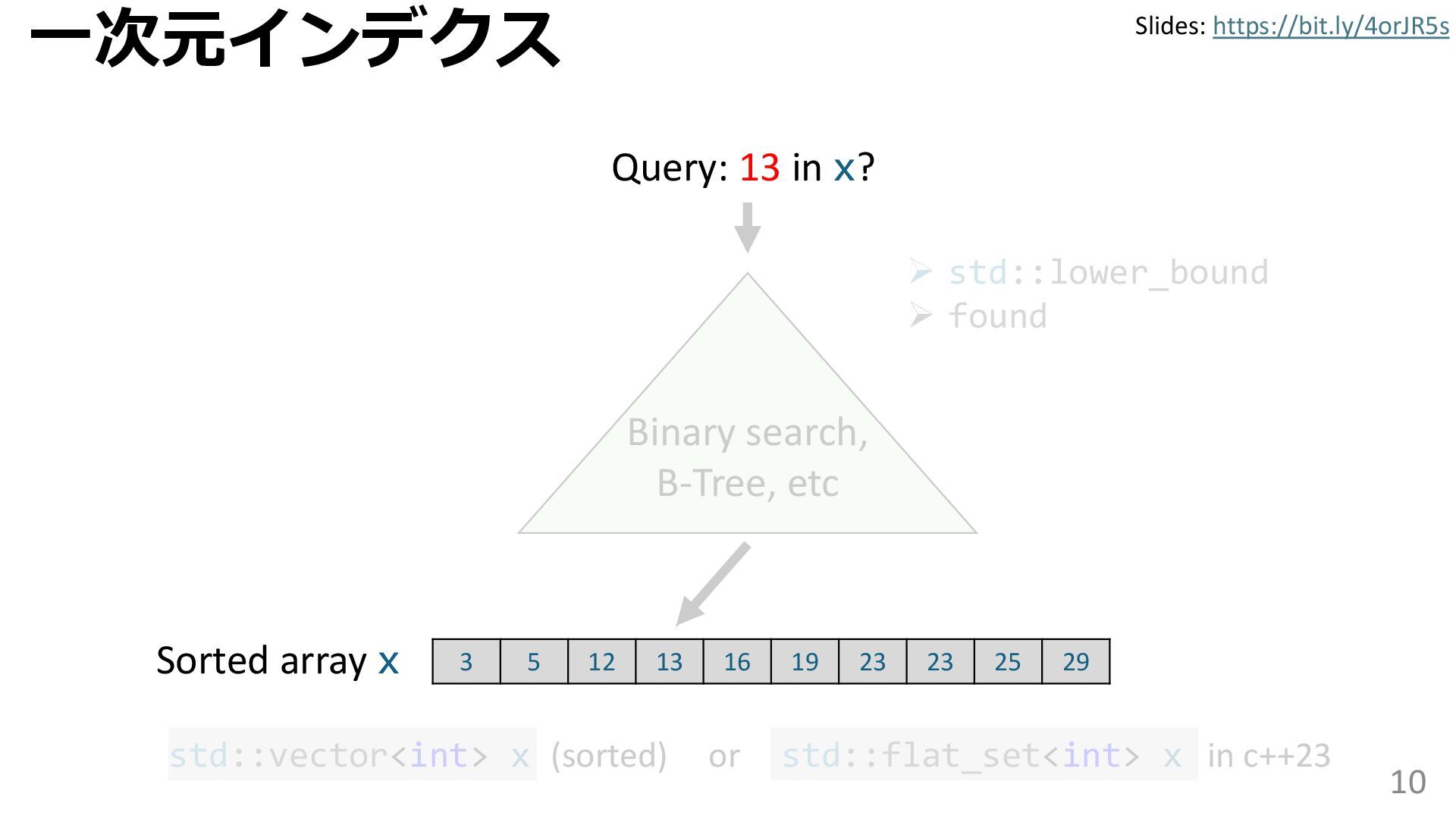
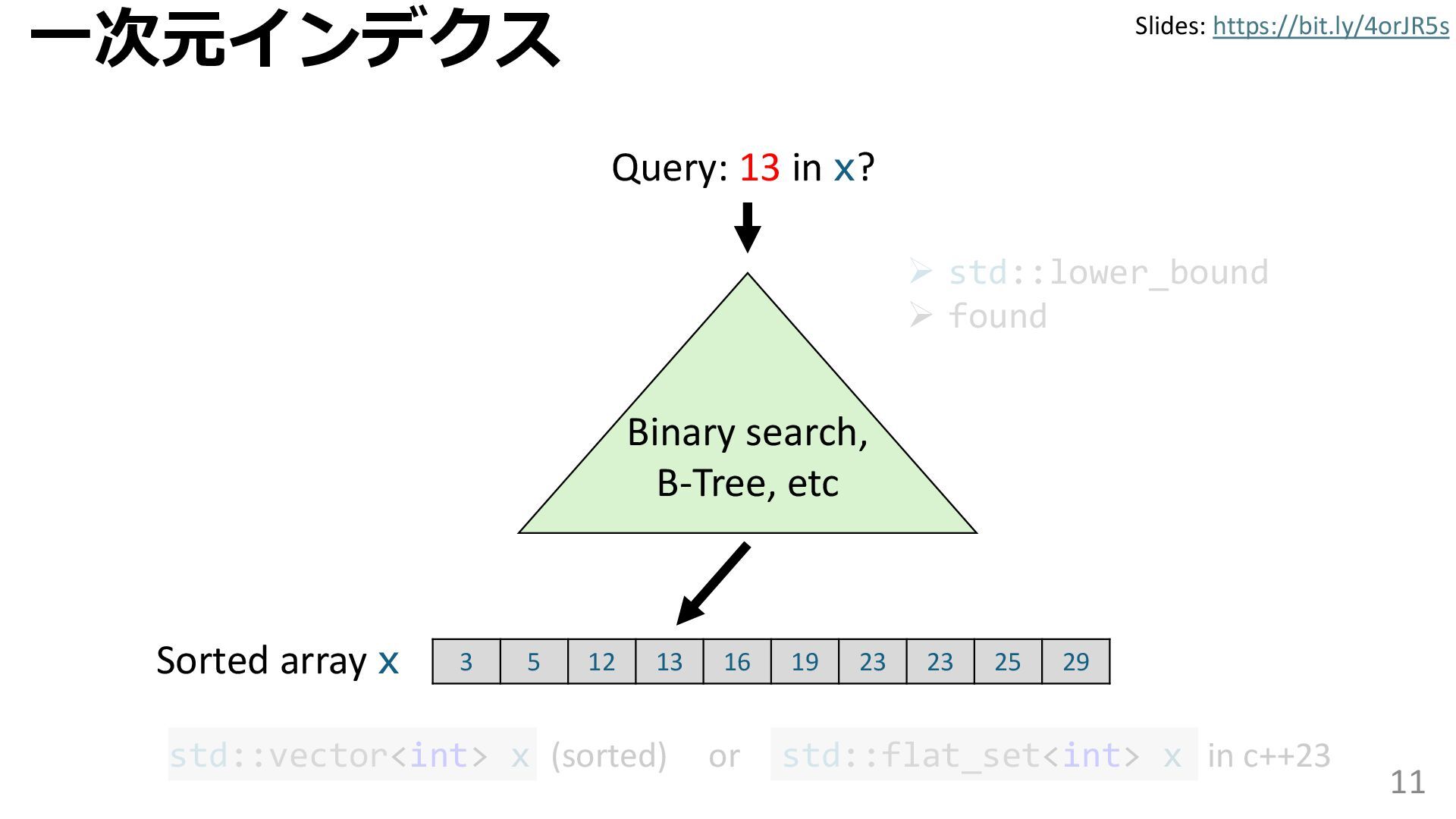
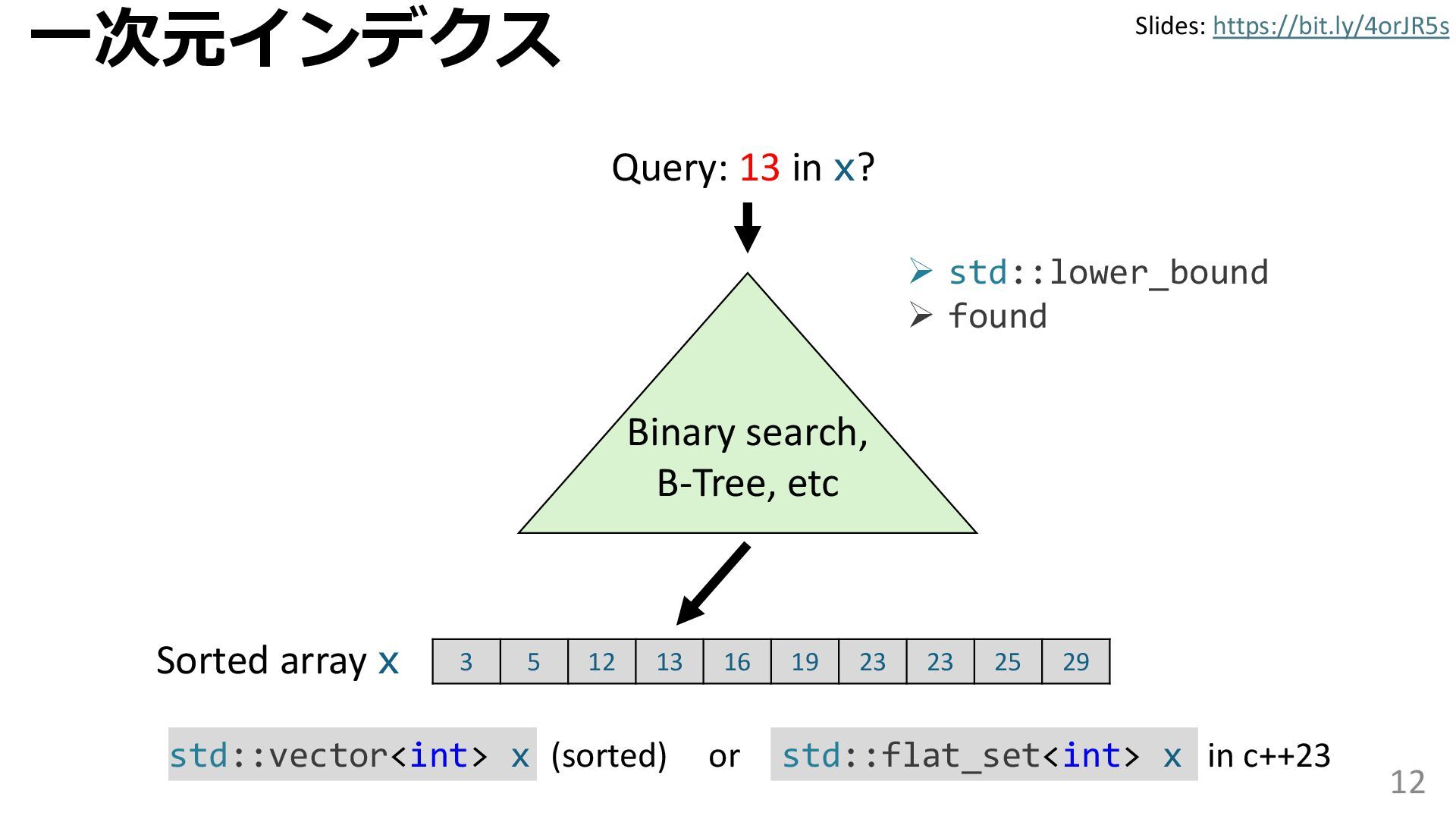
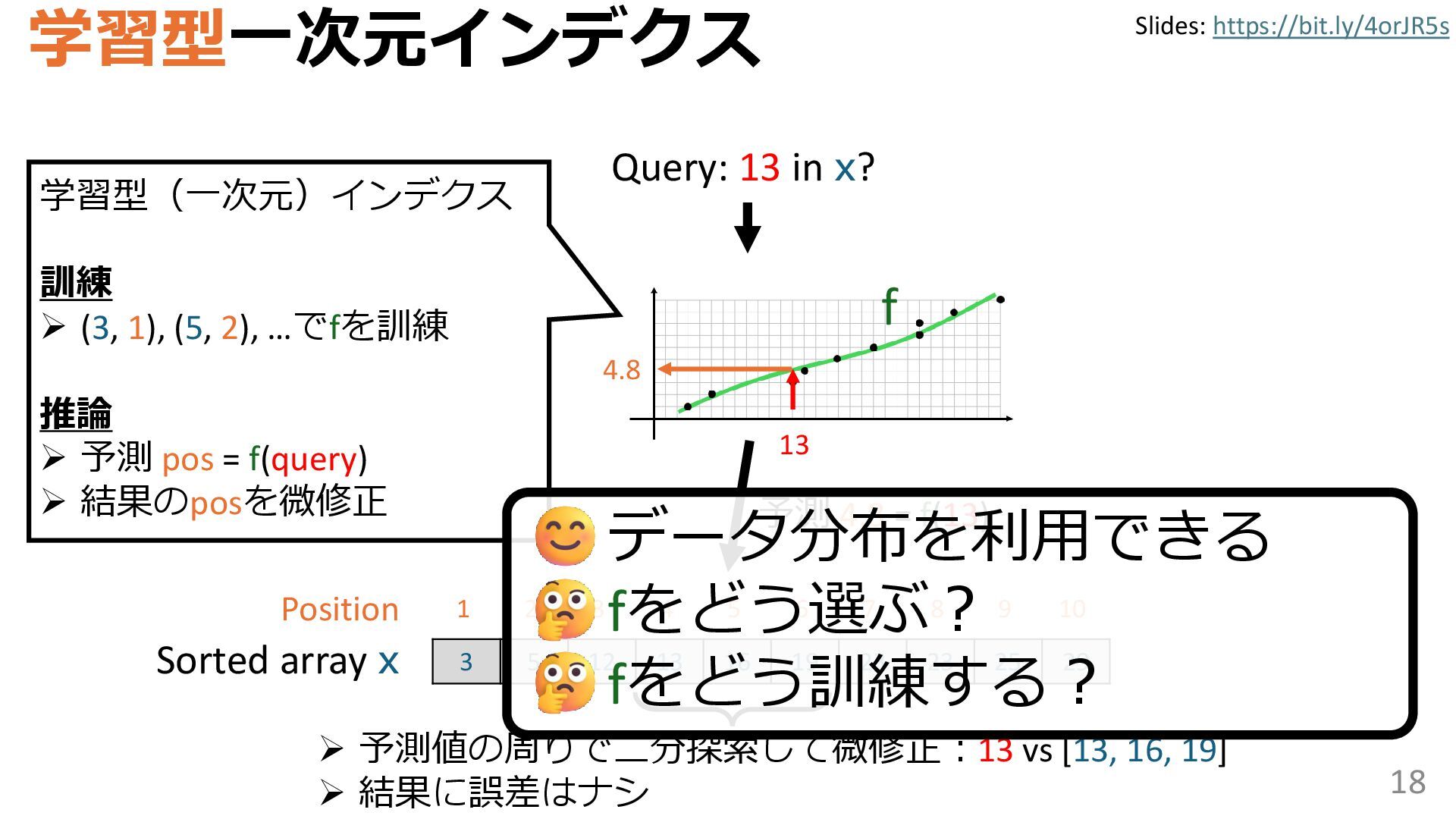
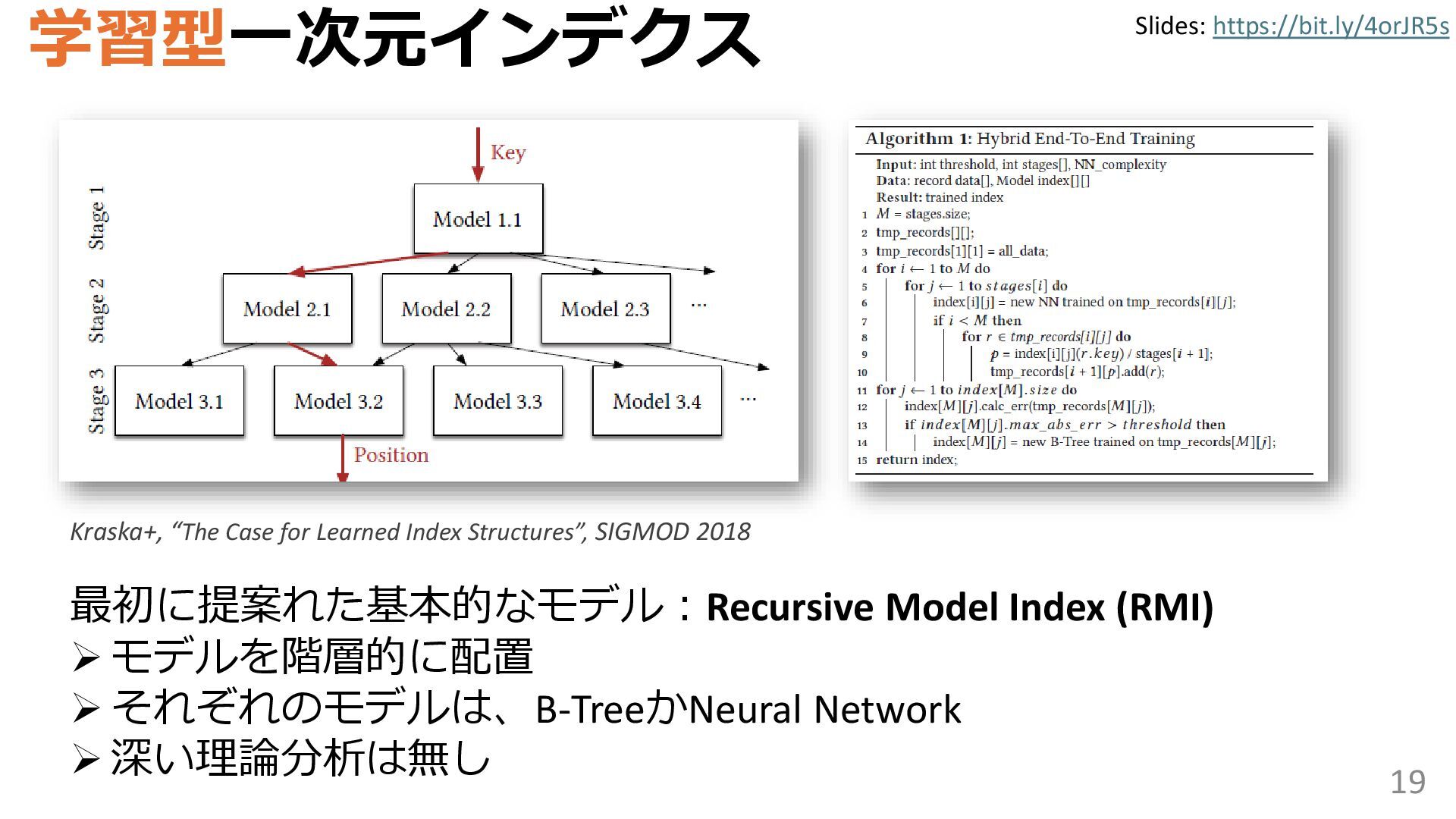
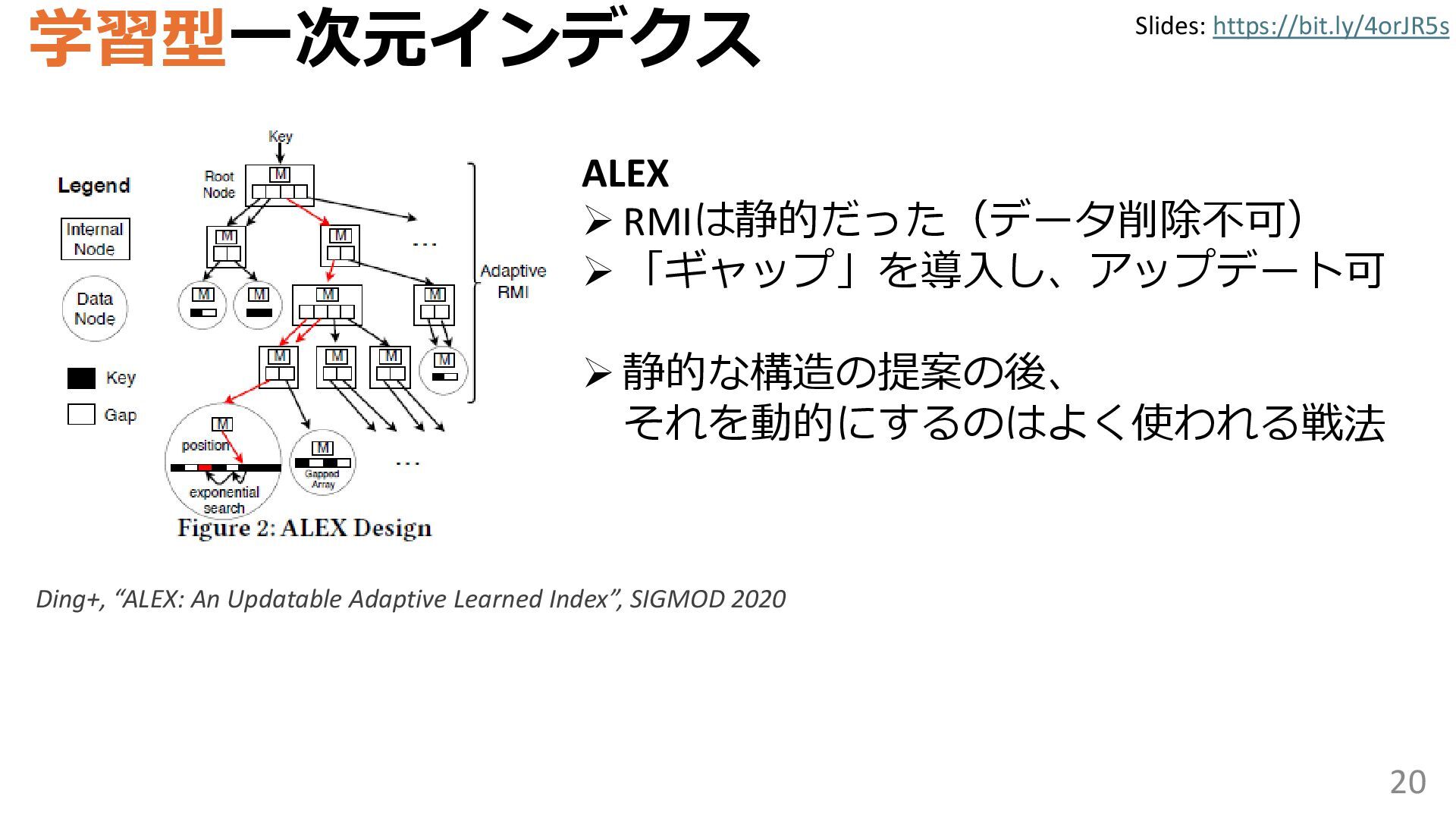
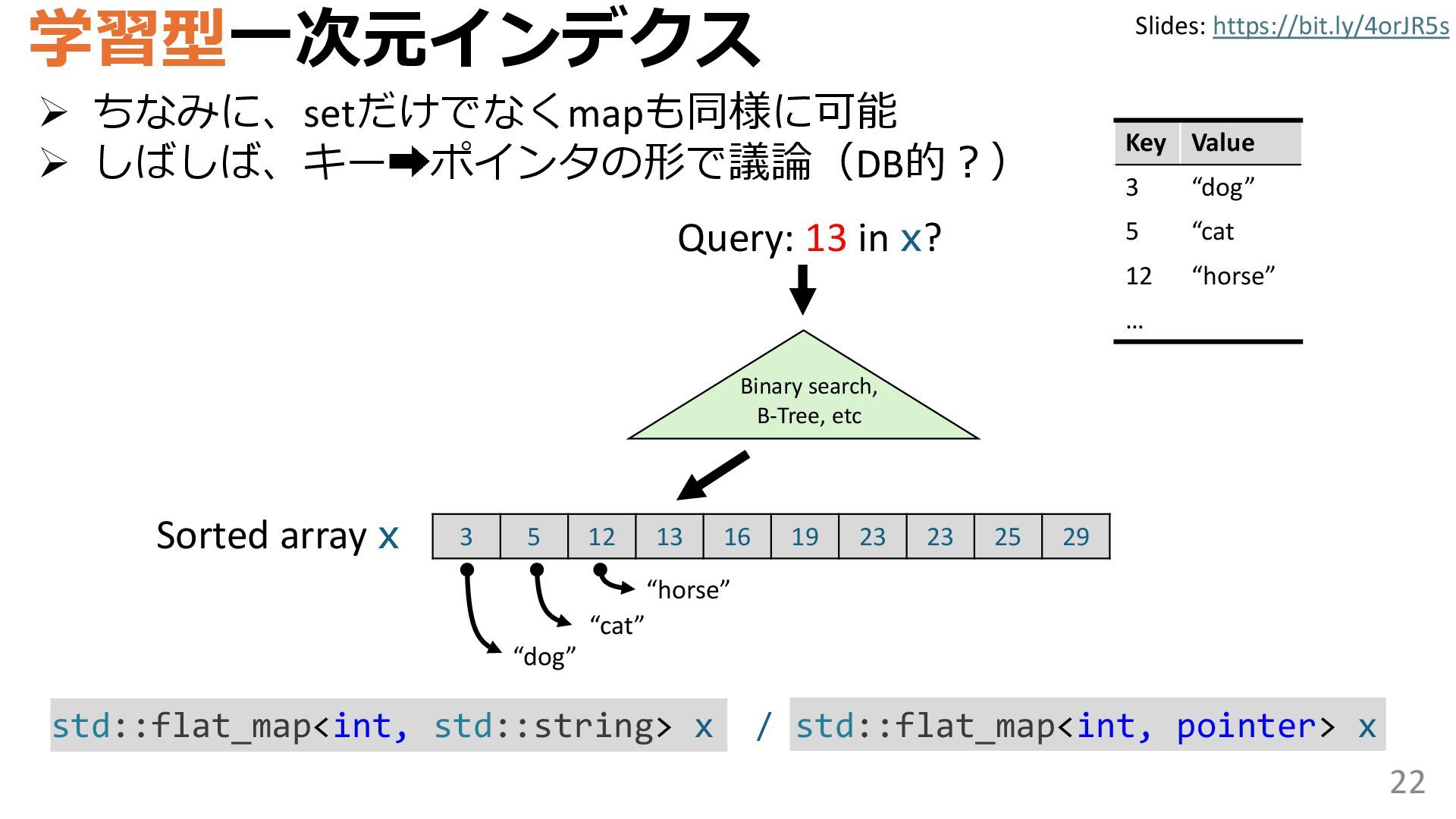
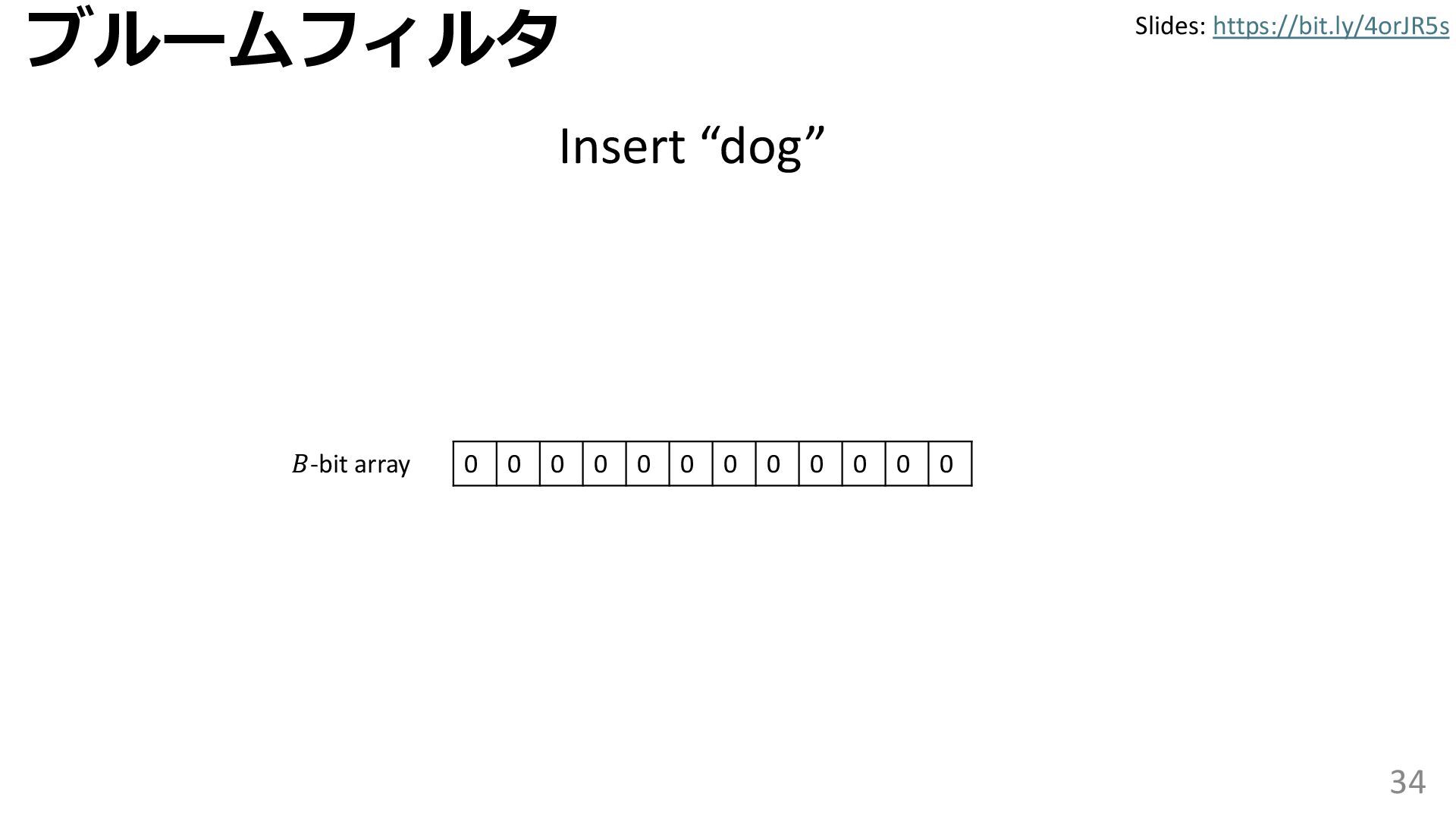
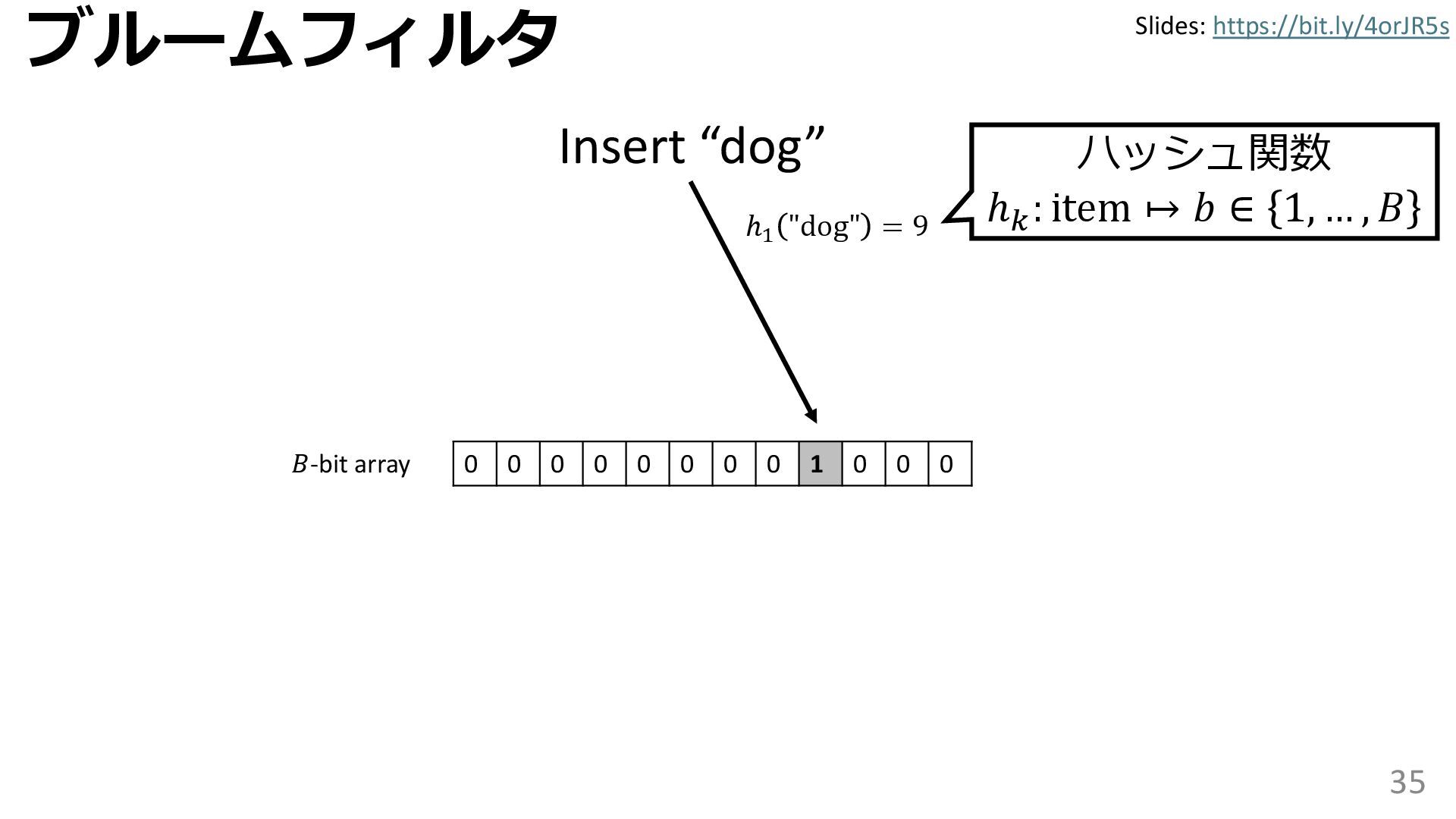
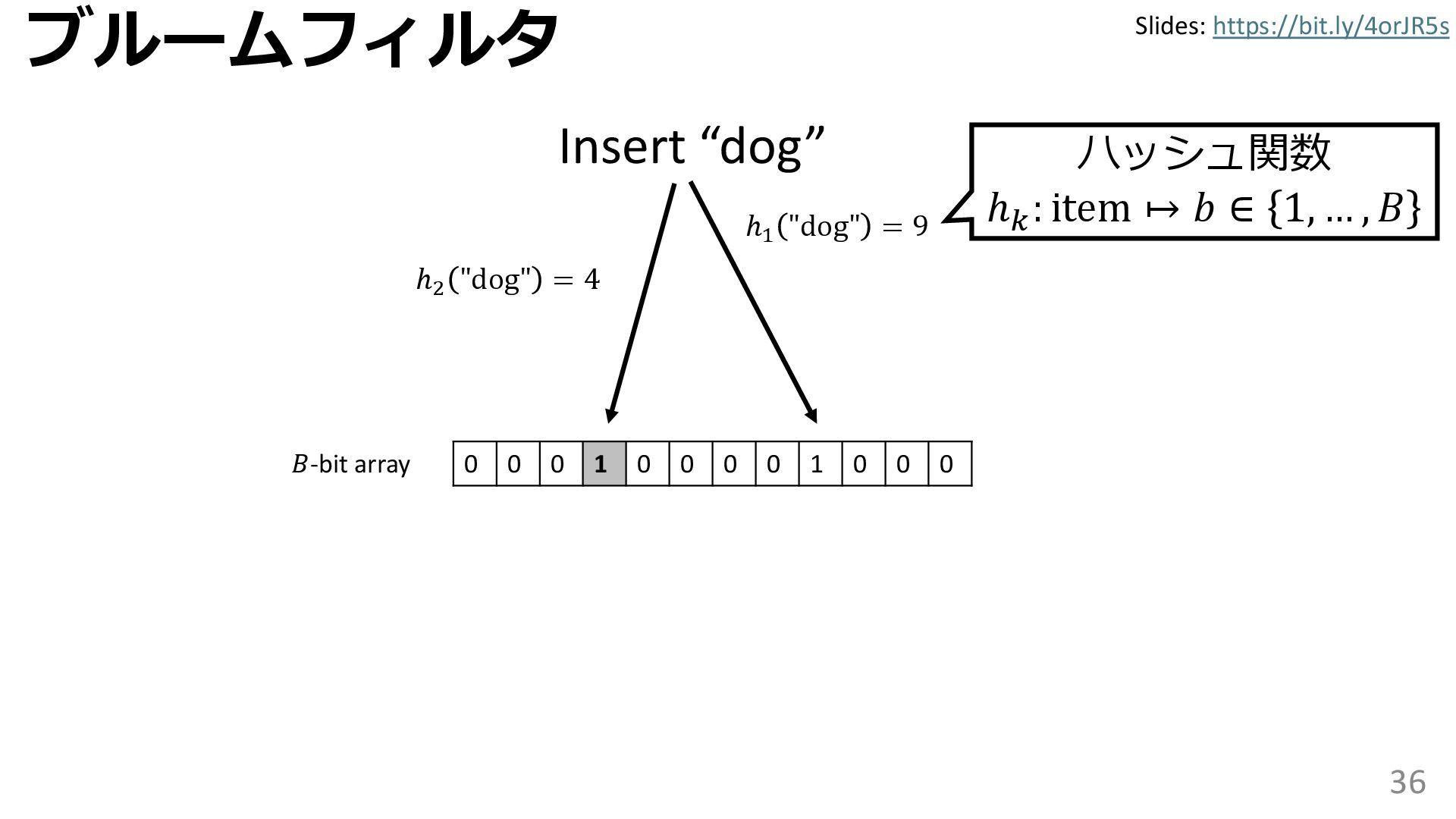
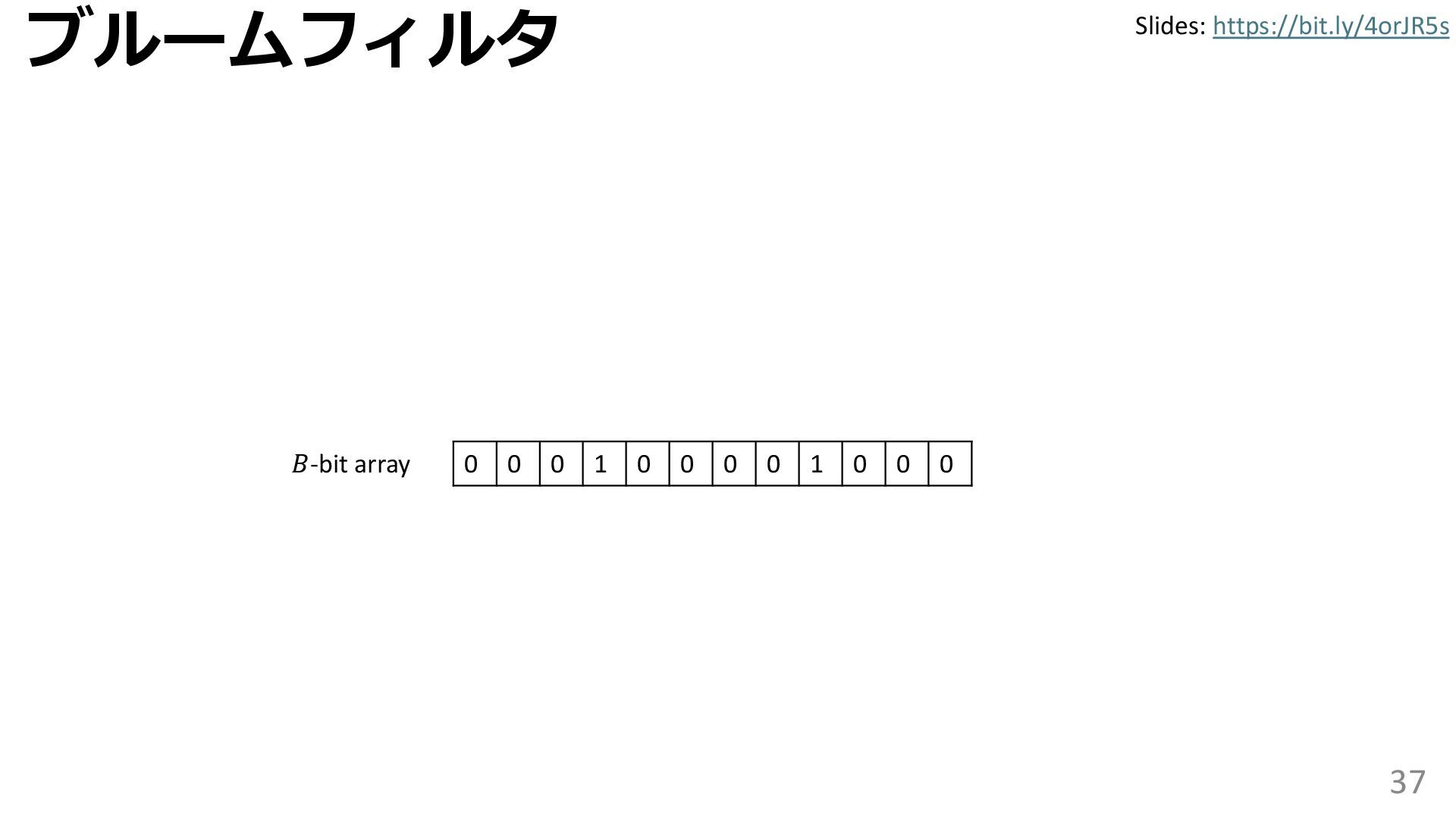
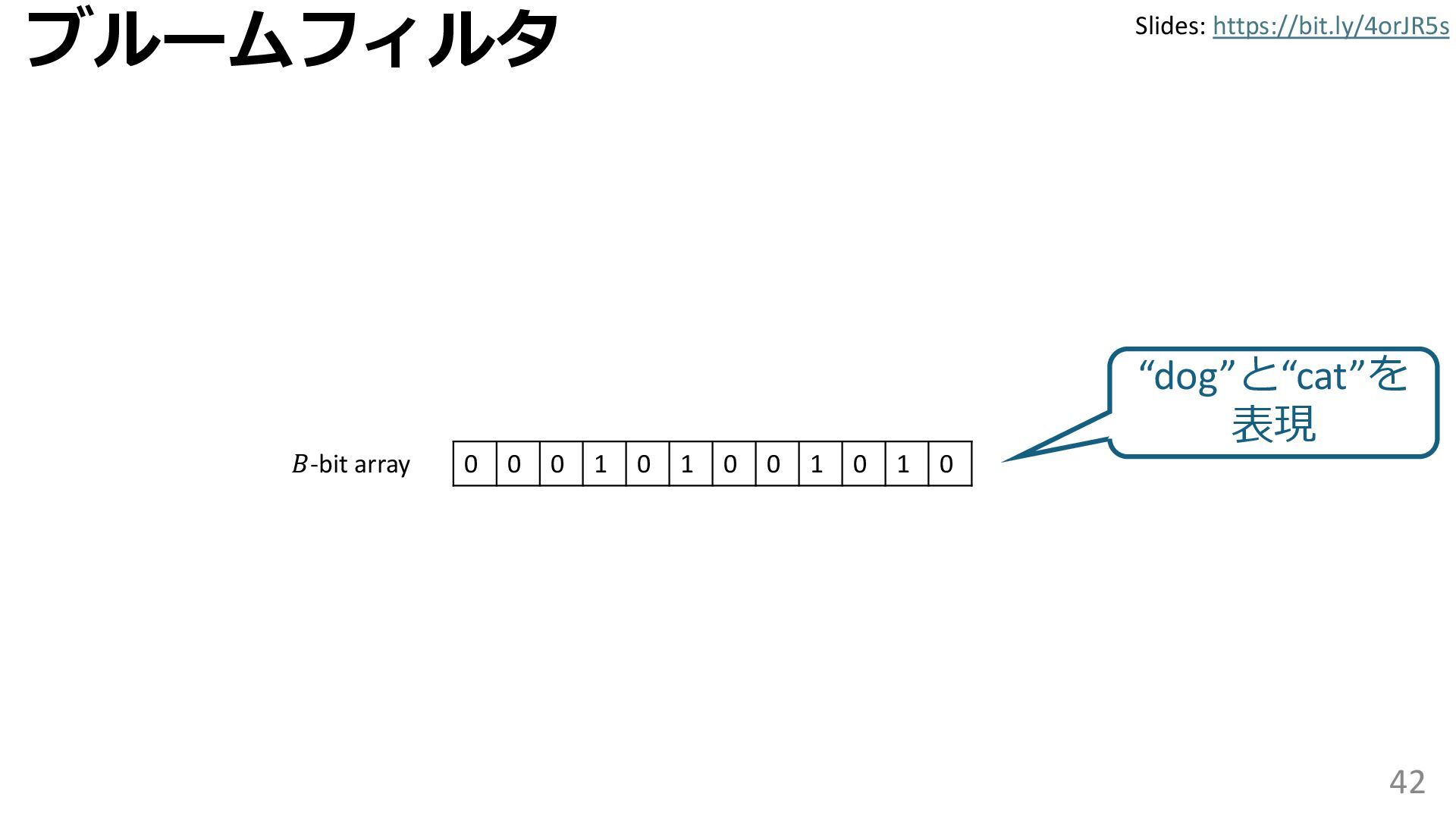
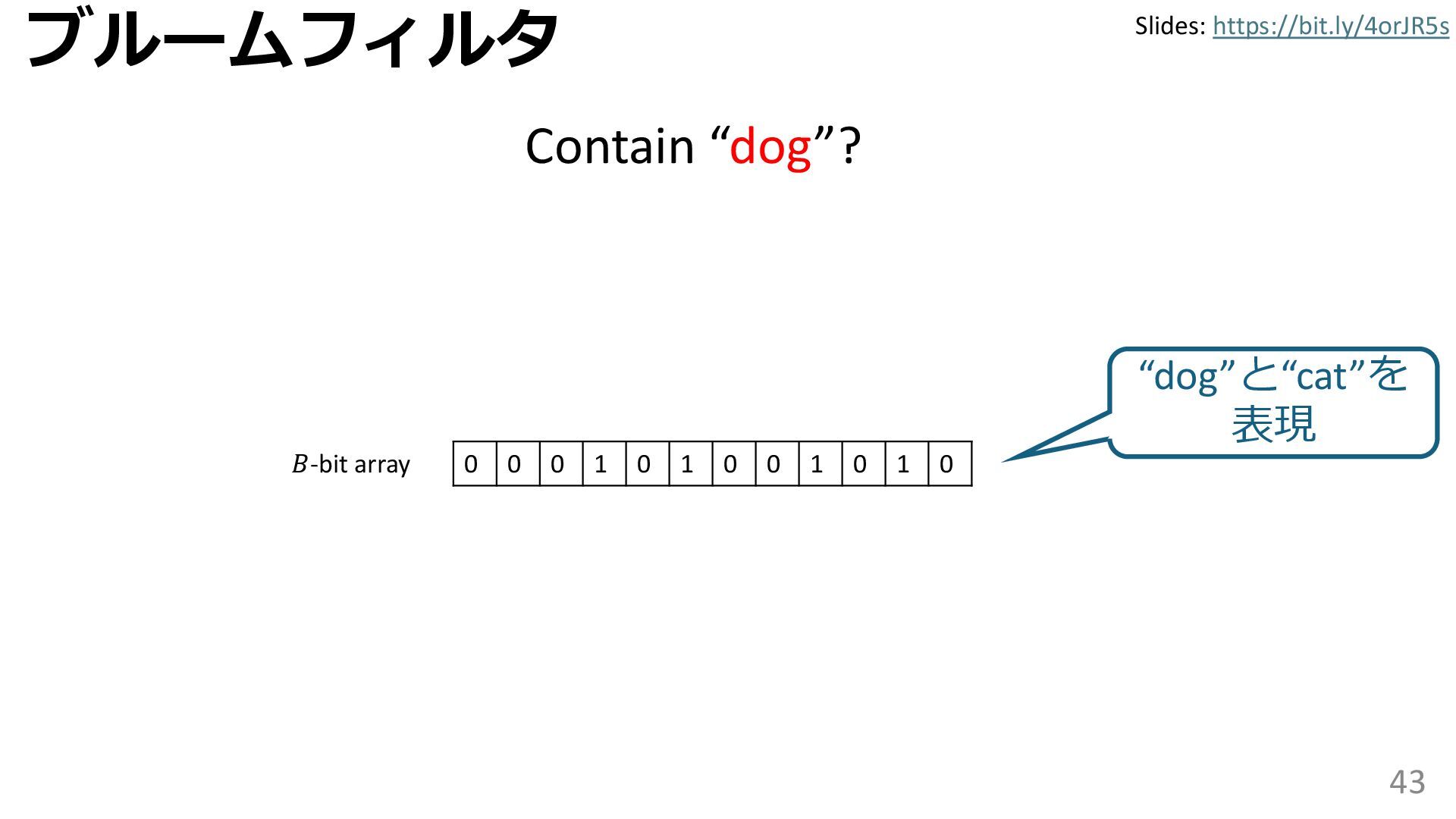
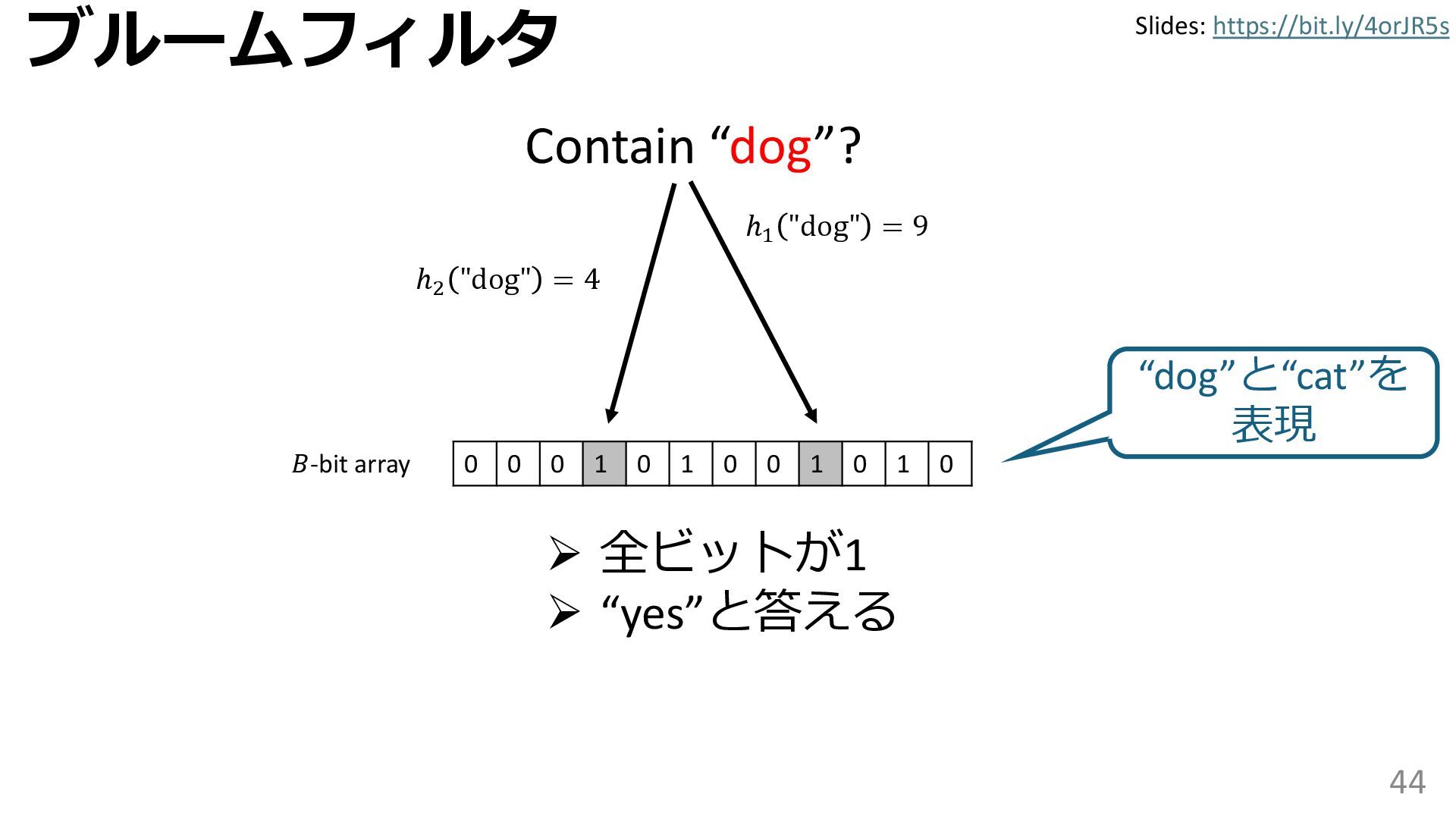
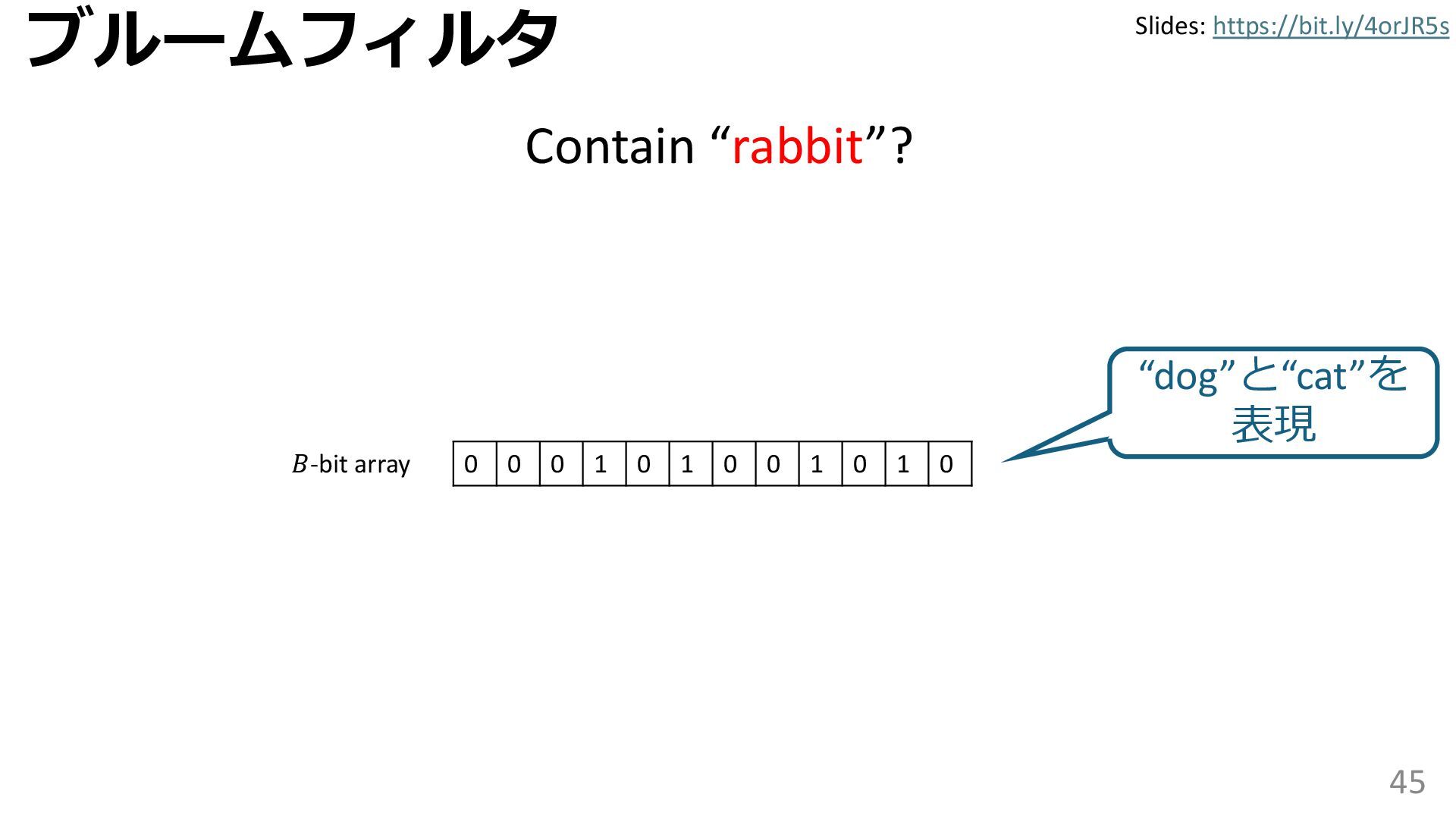
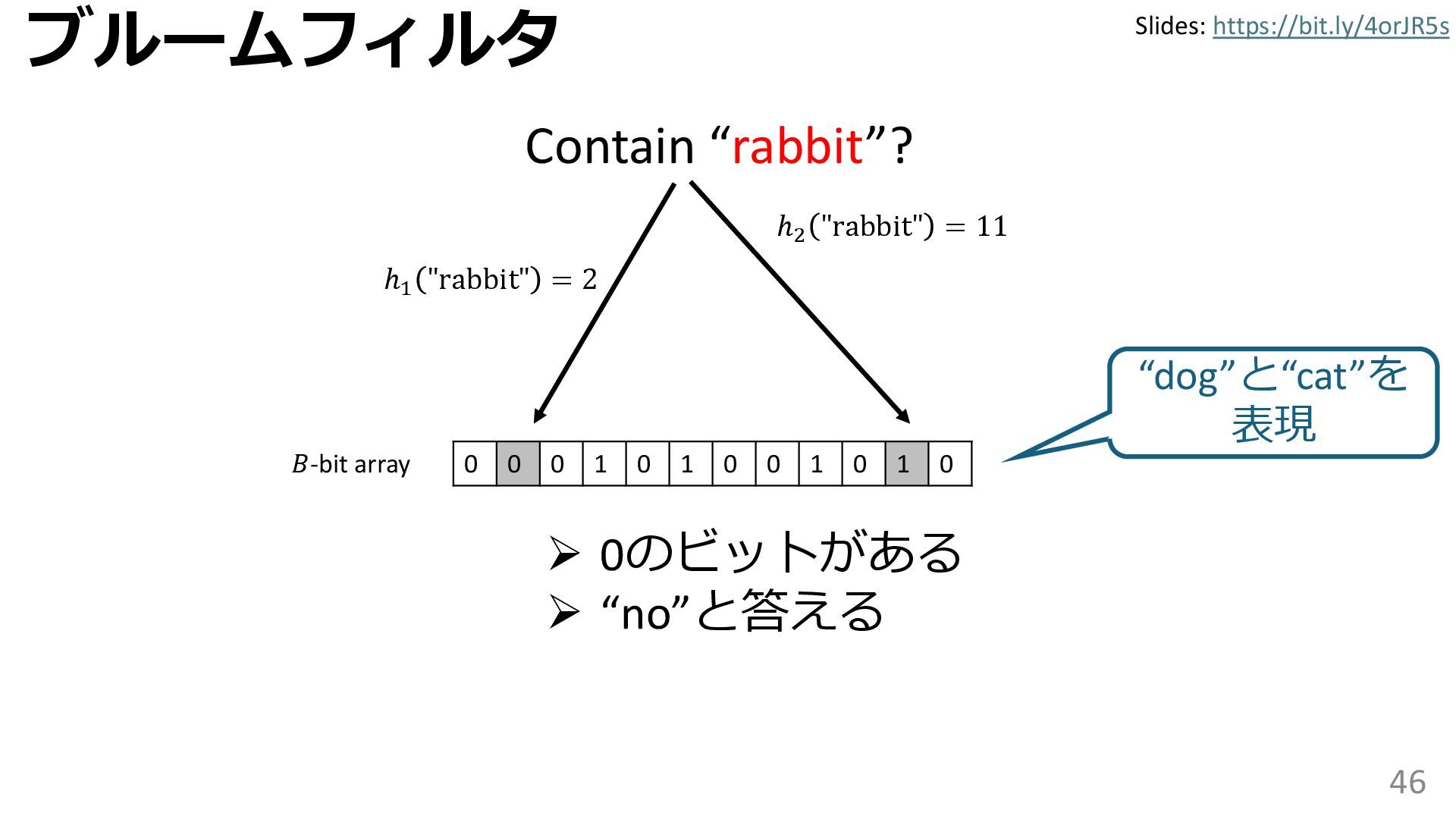
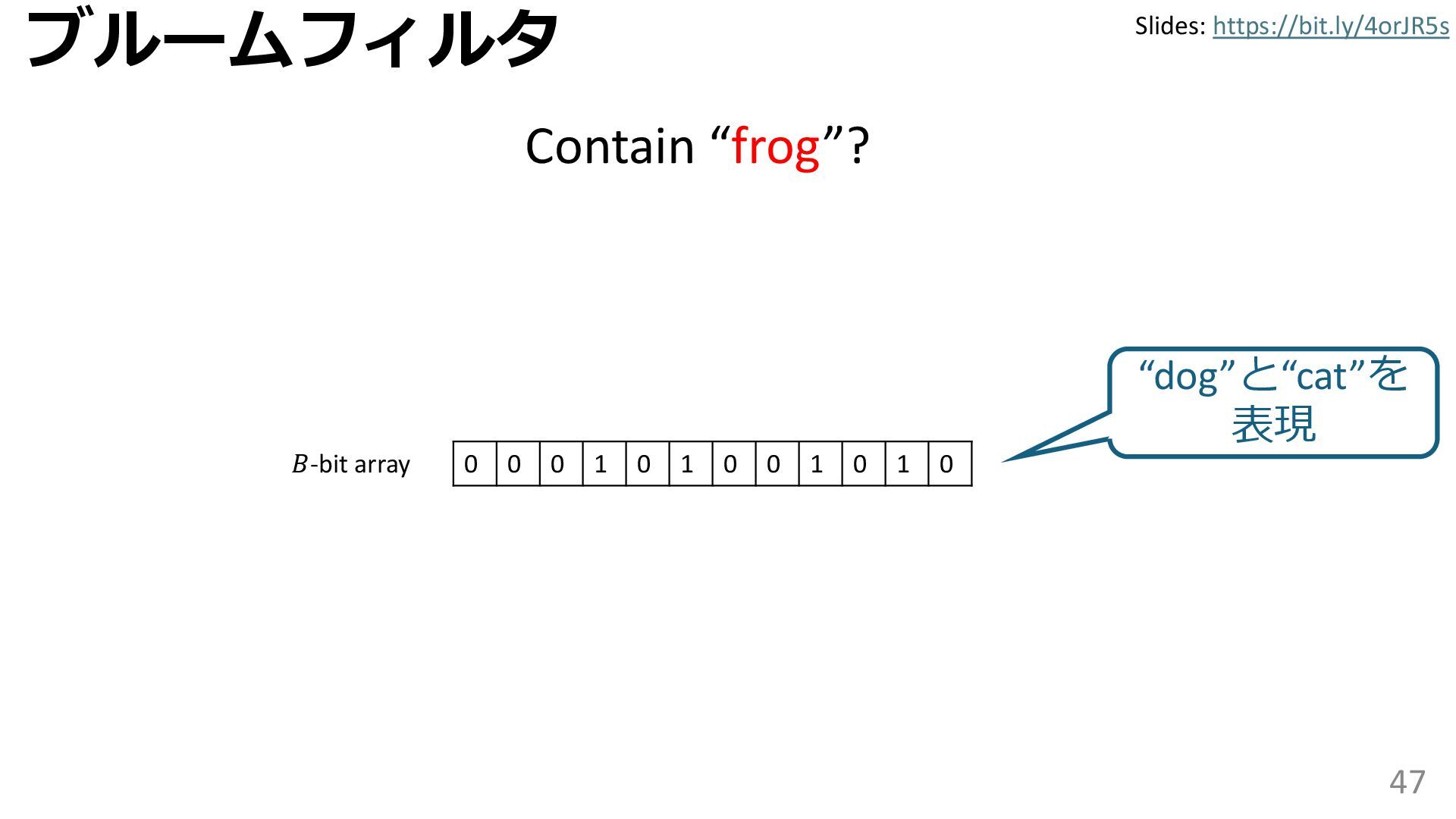
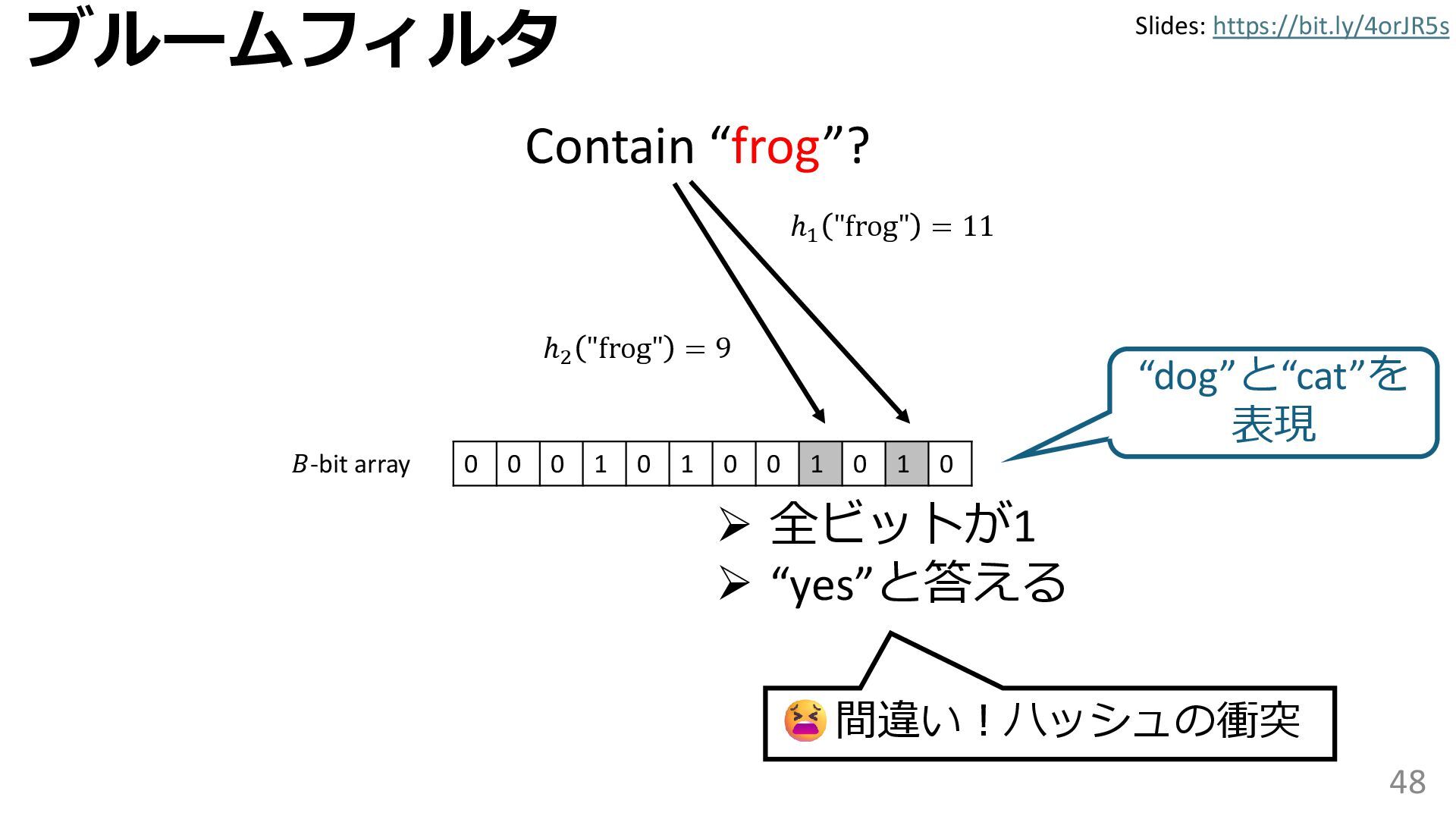
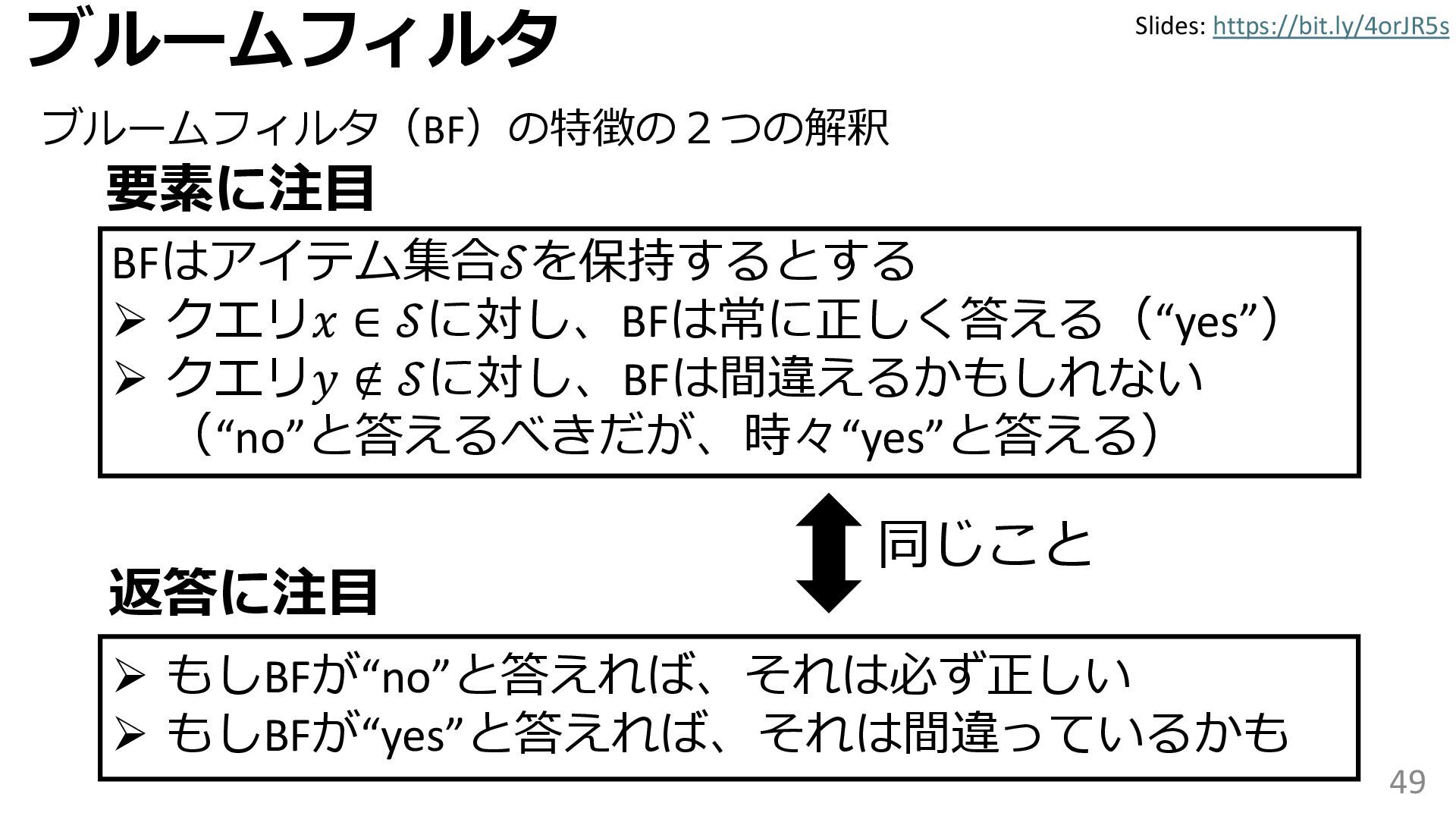
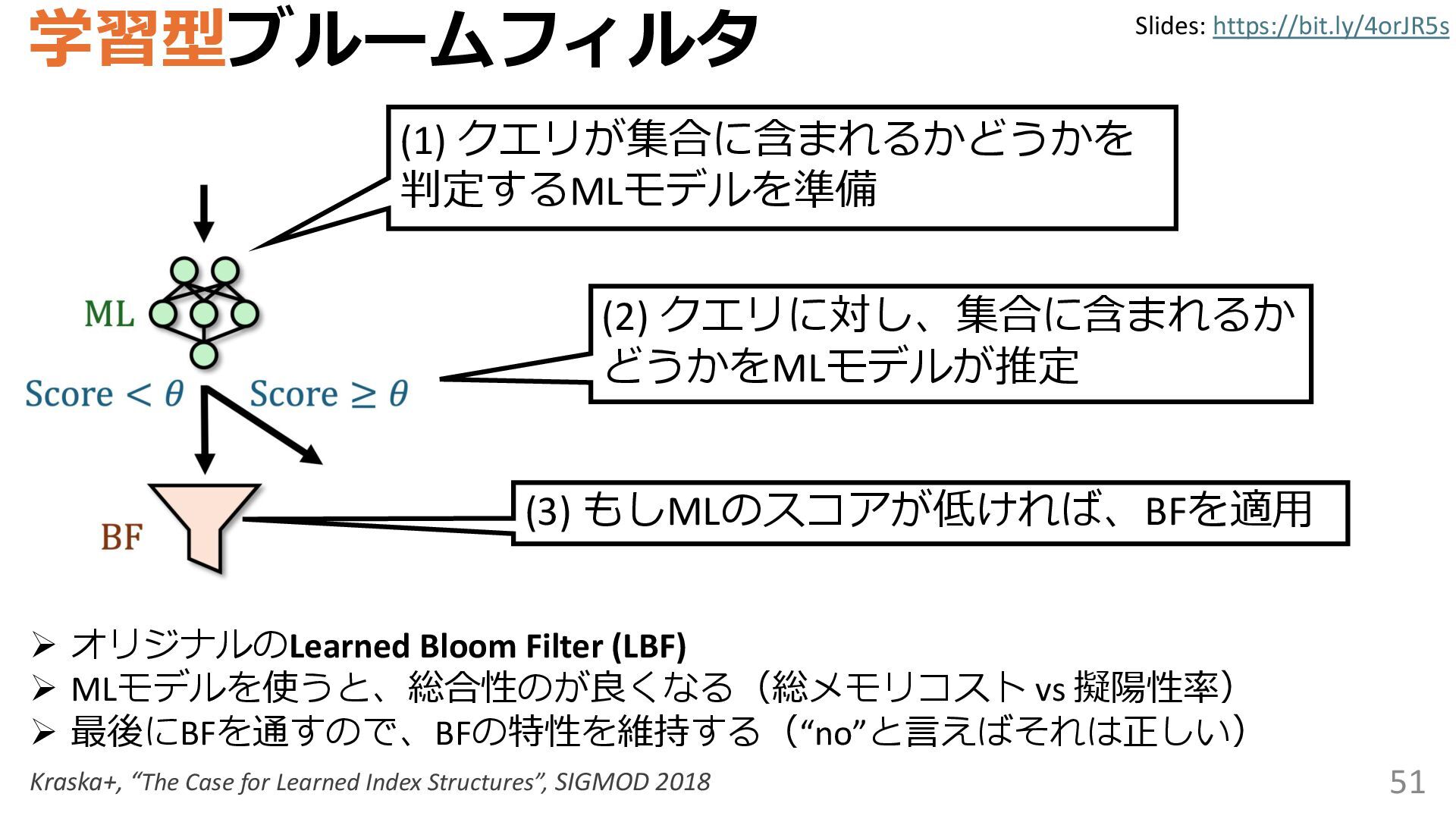
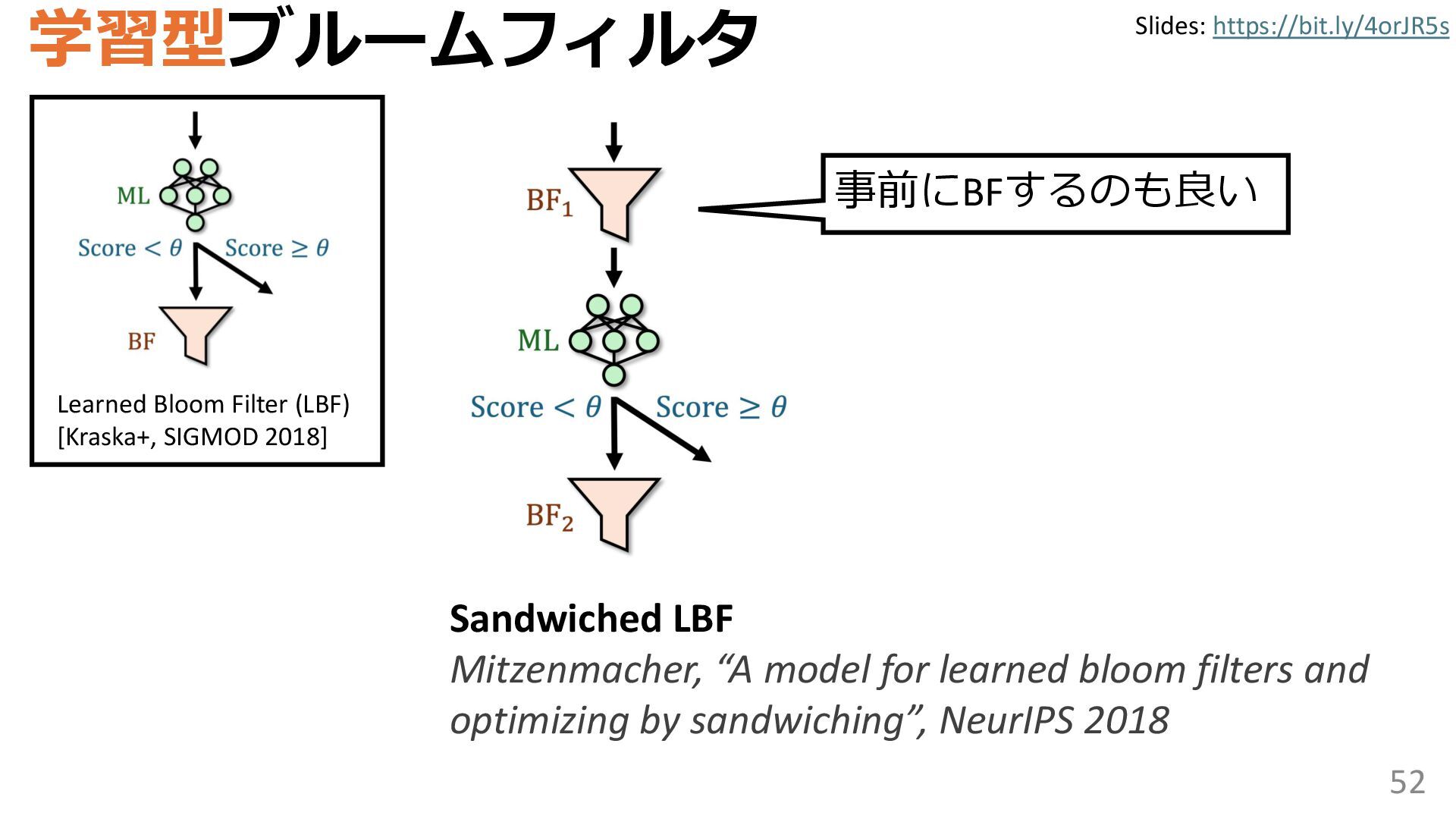
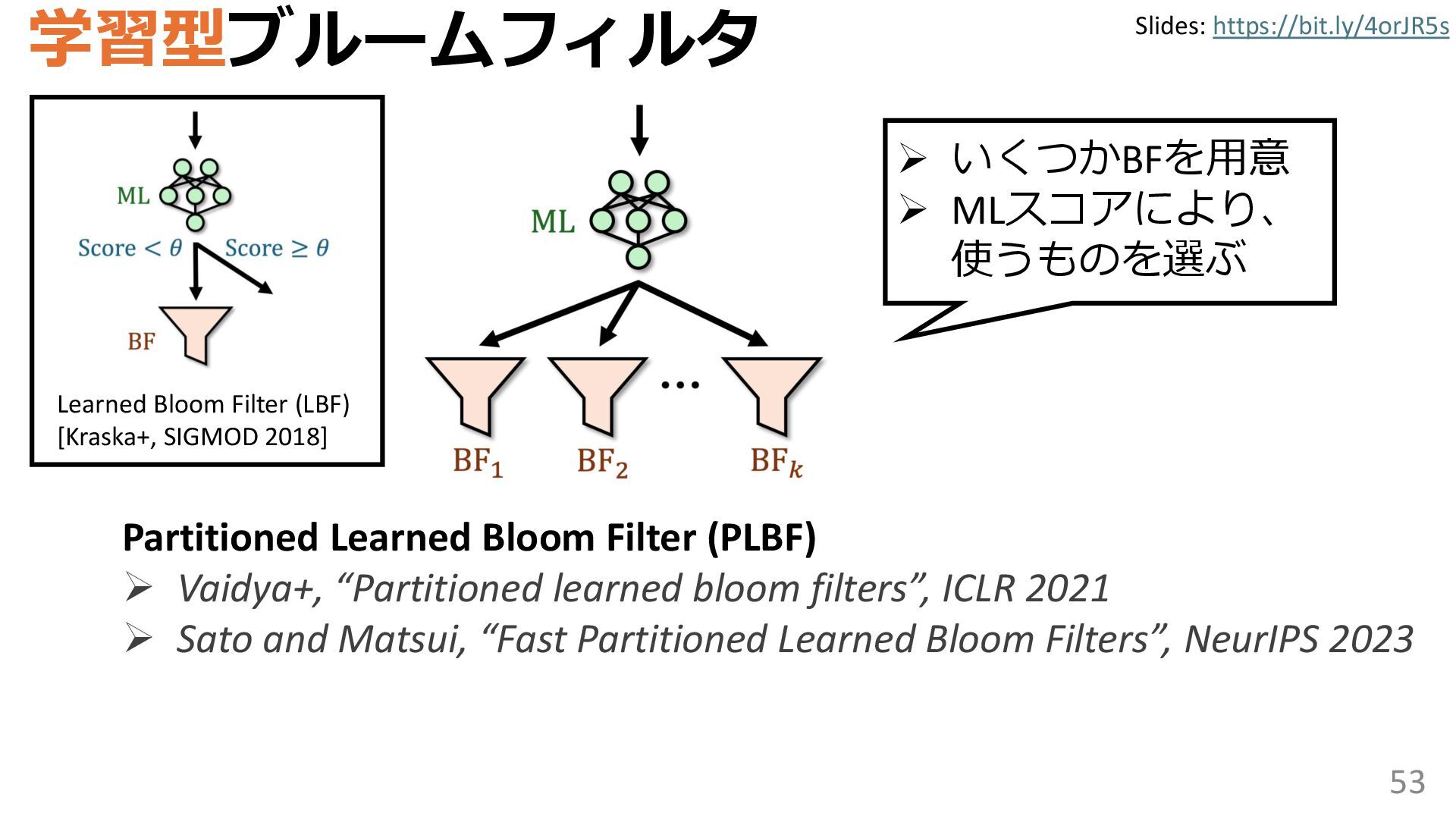
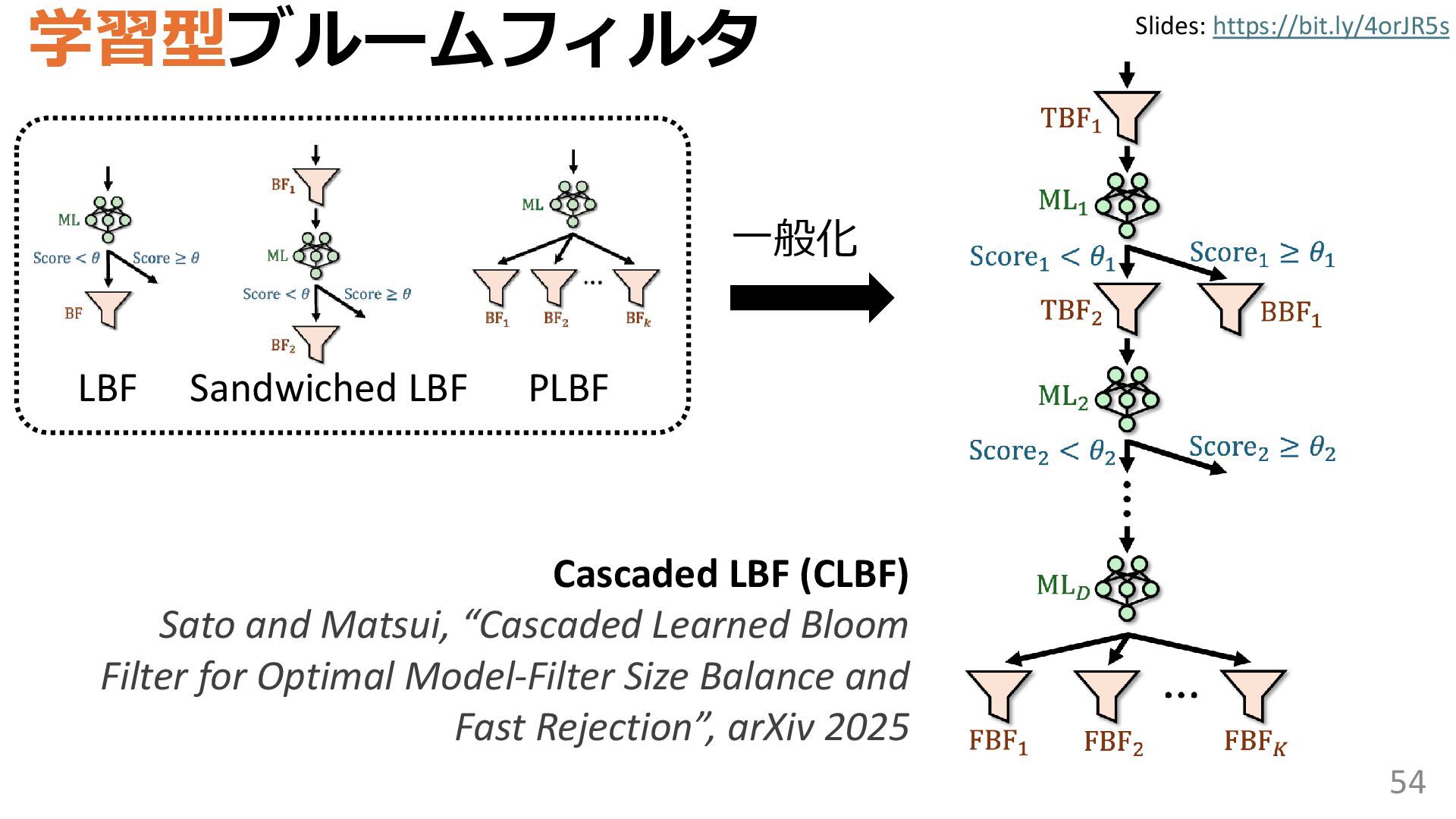
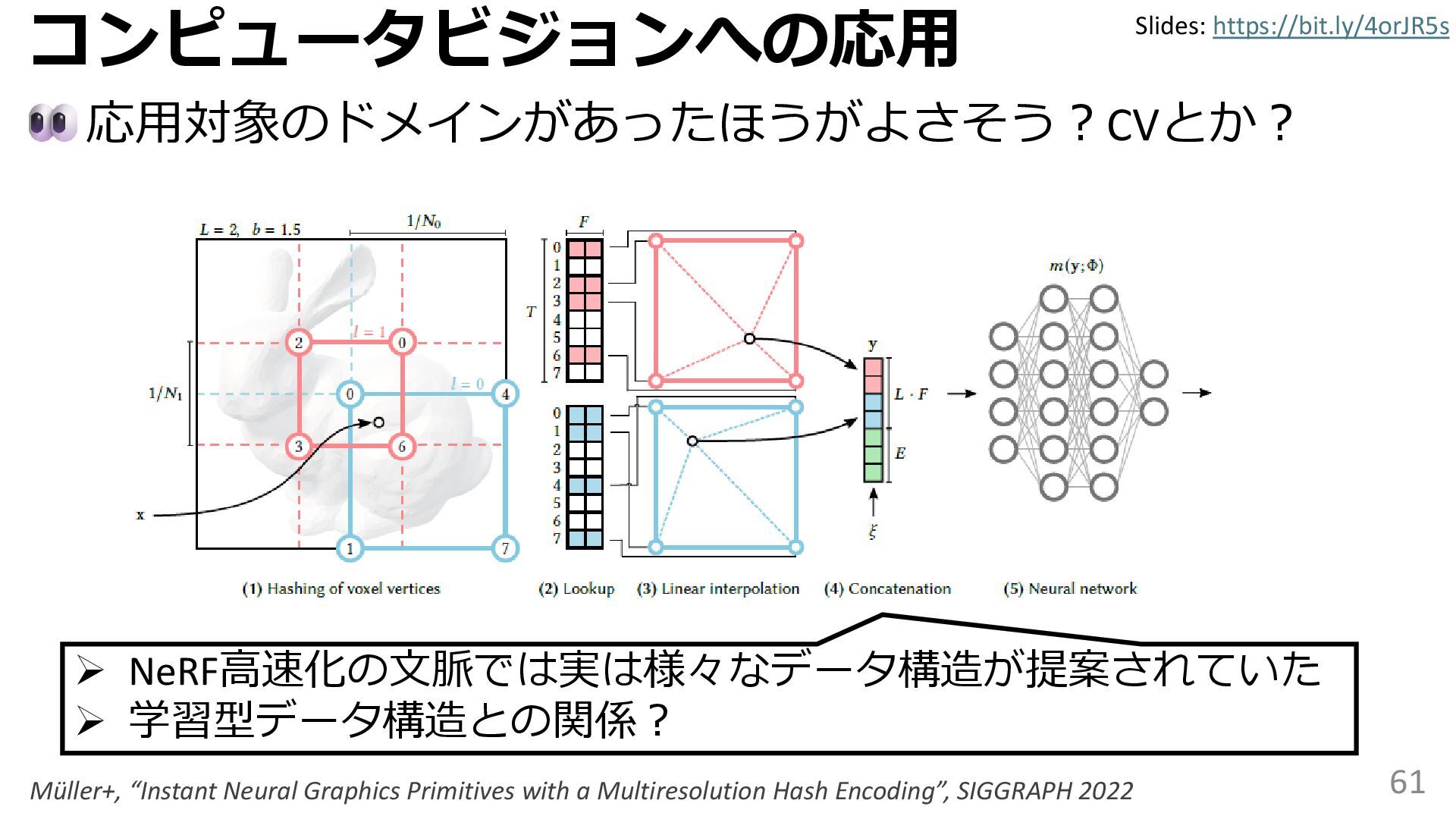
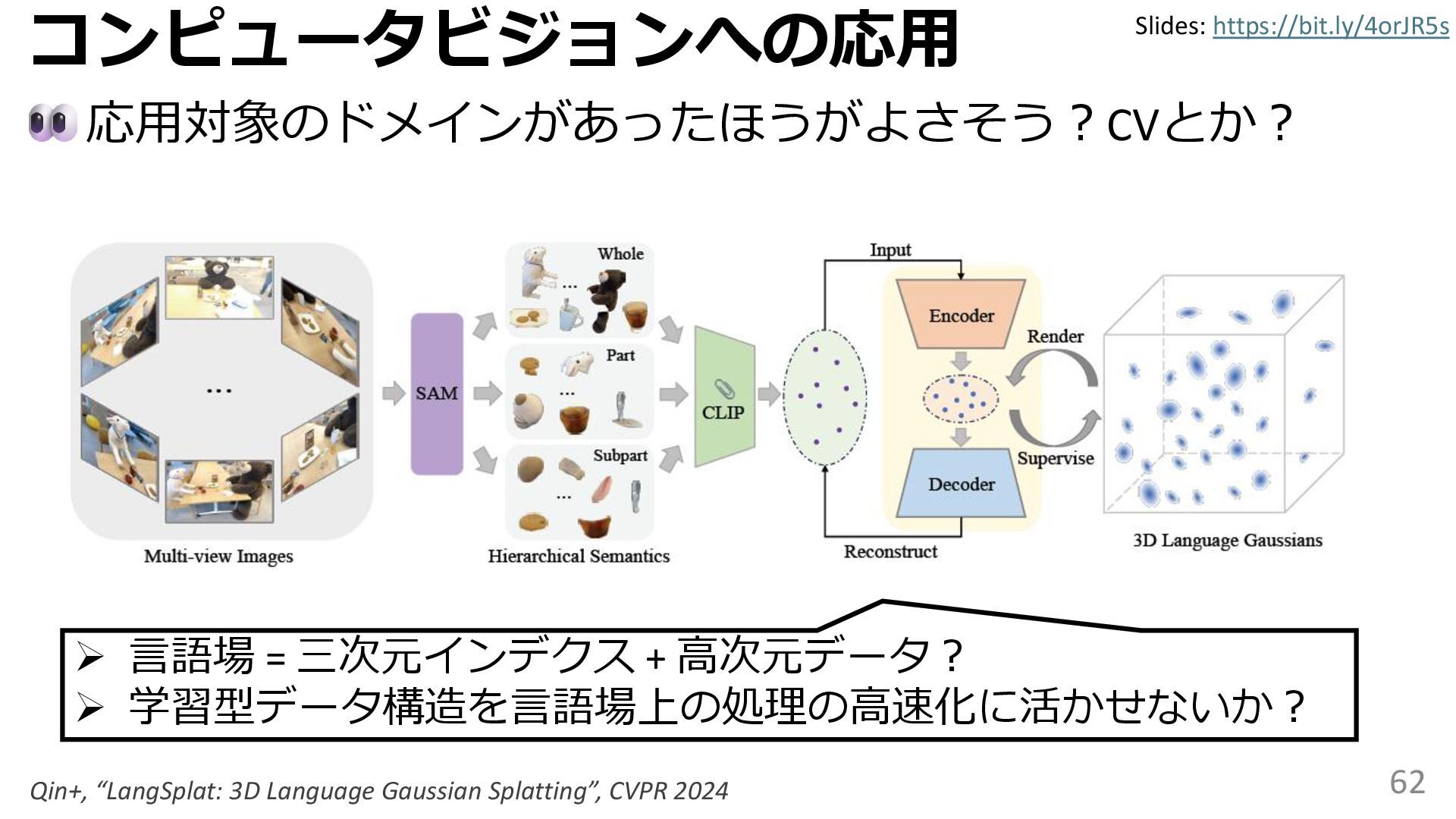
学習型データ構造とは、B-treeやブルームフィルタといった古典的なデータ構造に対し小さな機械学習モジュールを組み合わせることで性能を向上させる、新しいデータ構造である。例えばブルームフィルタは集合を表現する確率的データ構造であり、要素が集合に含まれるか近似的に判定するが、学習型ブルームフィルタはまず小さな機械学習モジュールで要素が集合に属するかざっくり判定し、その後に小さなブルームフィルタを適用する。このような構成は、最終的なメモリ・精度トレードオフに優れると報告されている。本講演では、近年発展を遂げている学習型データ構造の外観を示し、それが大規模言語モデルやコンピュータビジョンといった応用先にどのように用いられる可能性があるかを議論する。
{kind=link}
{kind=link}
![https://bit.ly/4orJR5s Slides: https://bit.ly/4orJR5s 3 三次元復元 [1] [1] Wang+, “VGGT: Visual](https://files.speakerdeck.com/presentations/9dc63e5e8fb14c1392e128ffe1cfb102/slide_2.jpg){kind=link}
![https://bit.ly/4orJR5s Slides: https://bit.ly/4orJR5s 4 三次元復元 [1] [1] Wang+, “VGGT: Visual](https://files.speakerdeck.com/presentations/9dc63e5e8fb14c1392e128ffe1cfb102/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
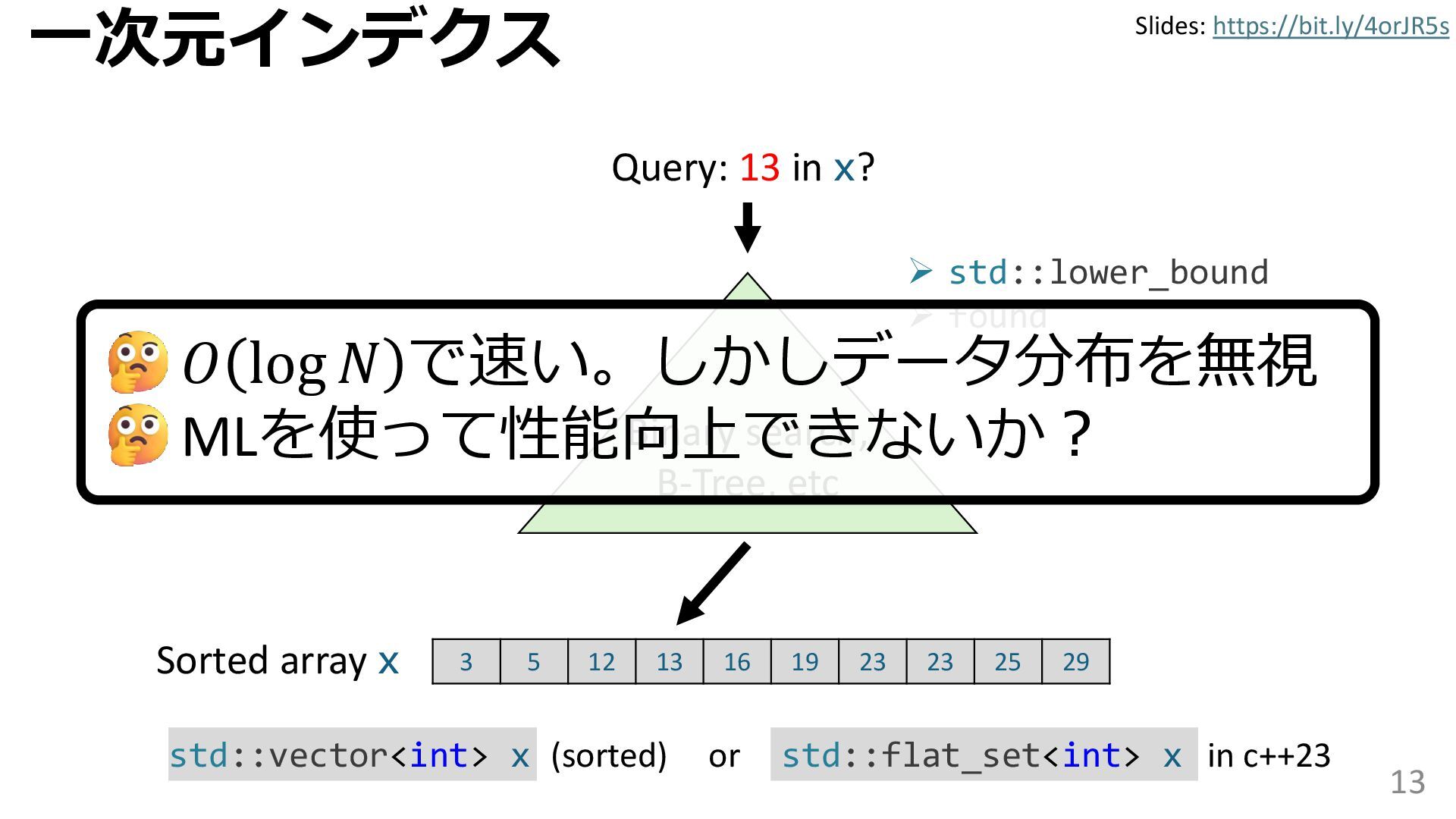{kind=link}
{kind=link}
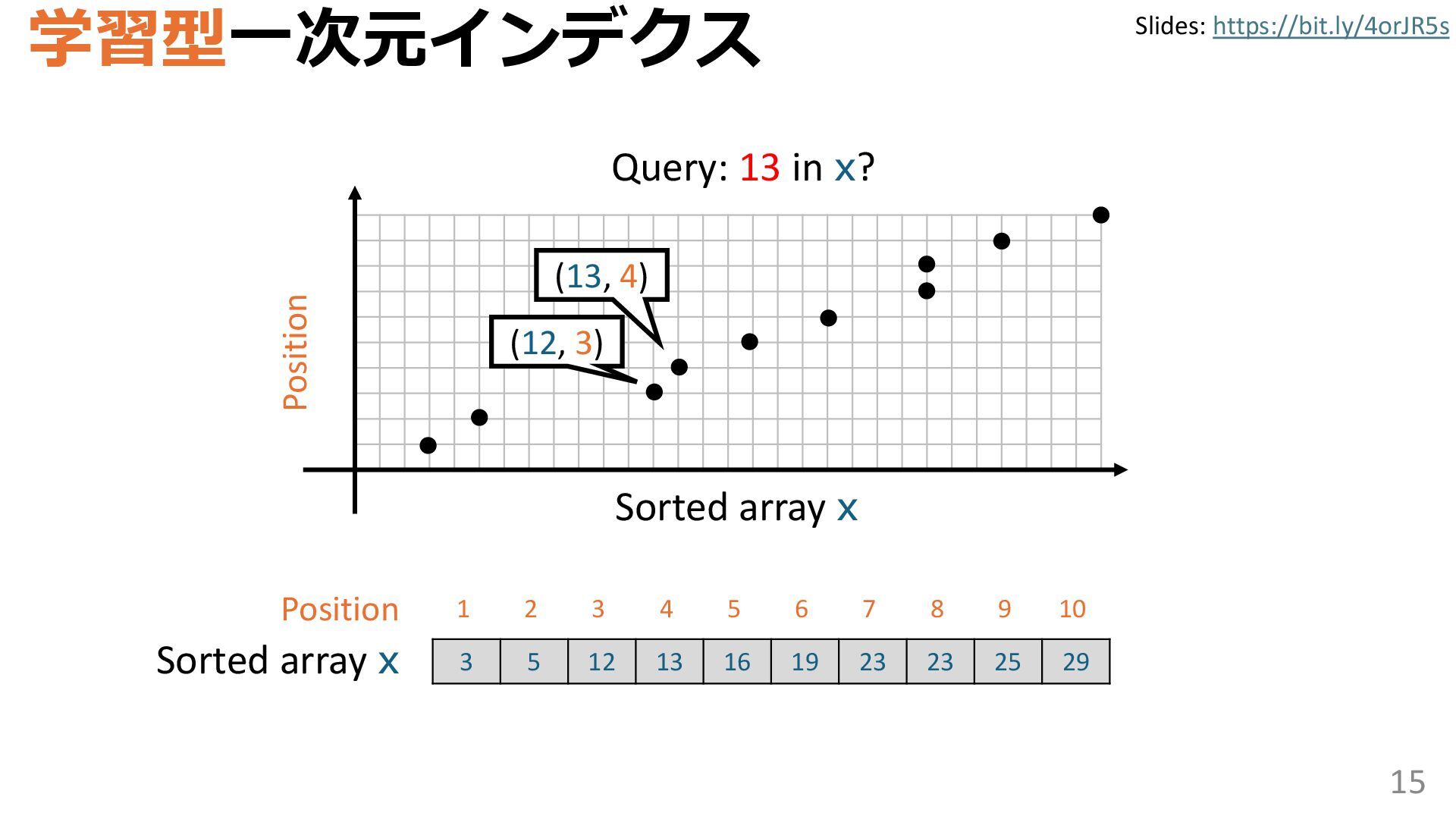{kind=link}
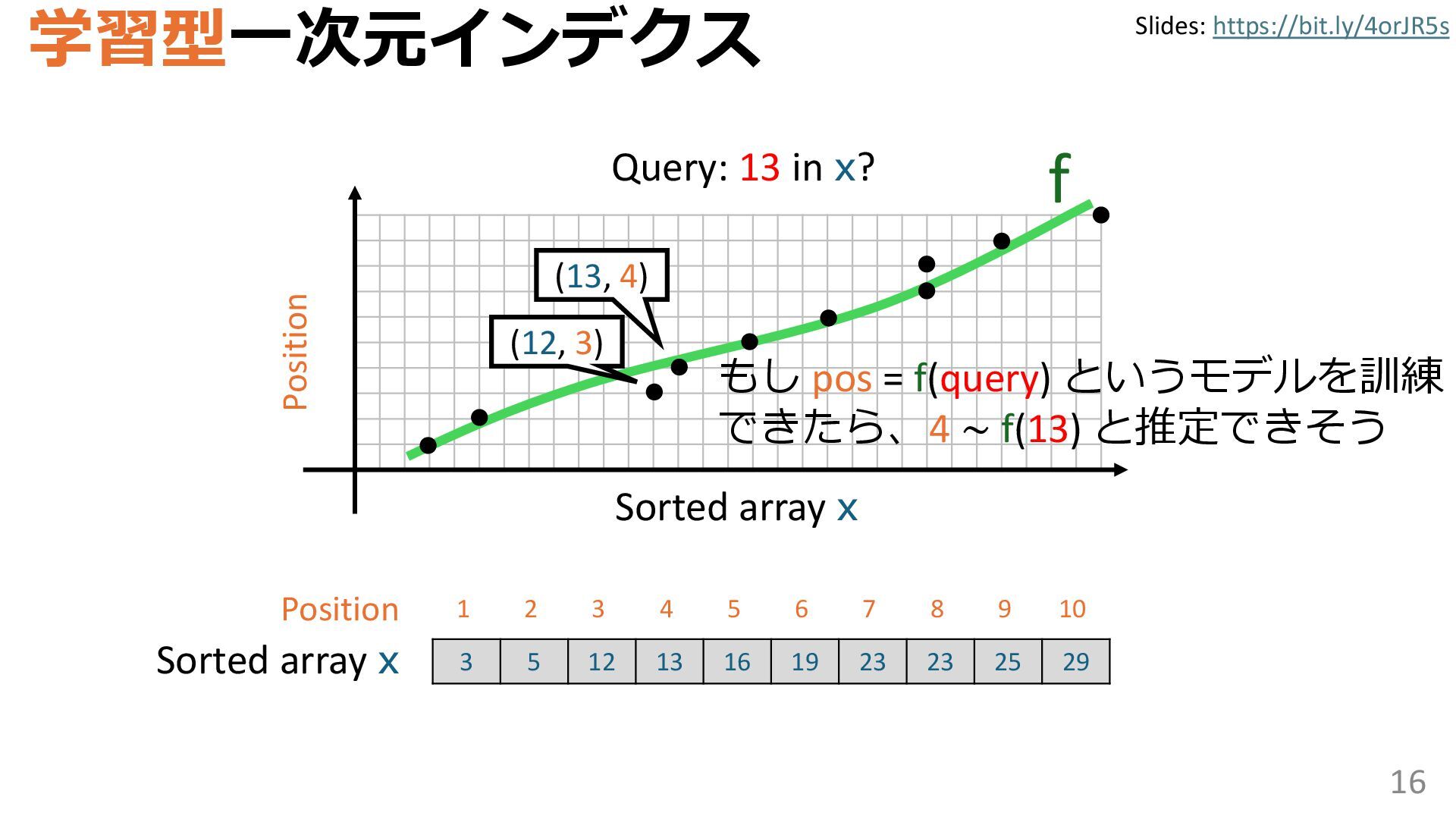{kind=link}
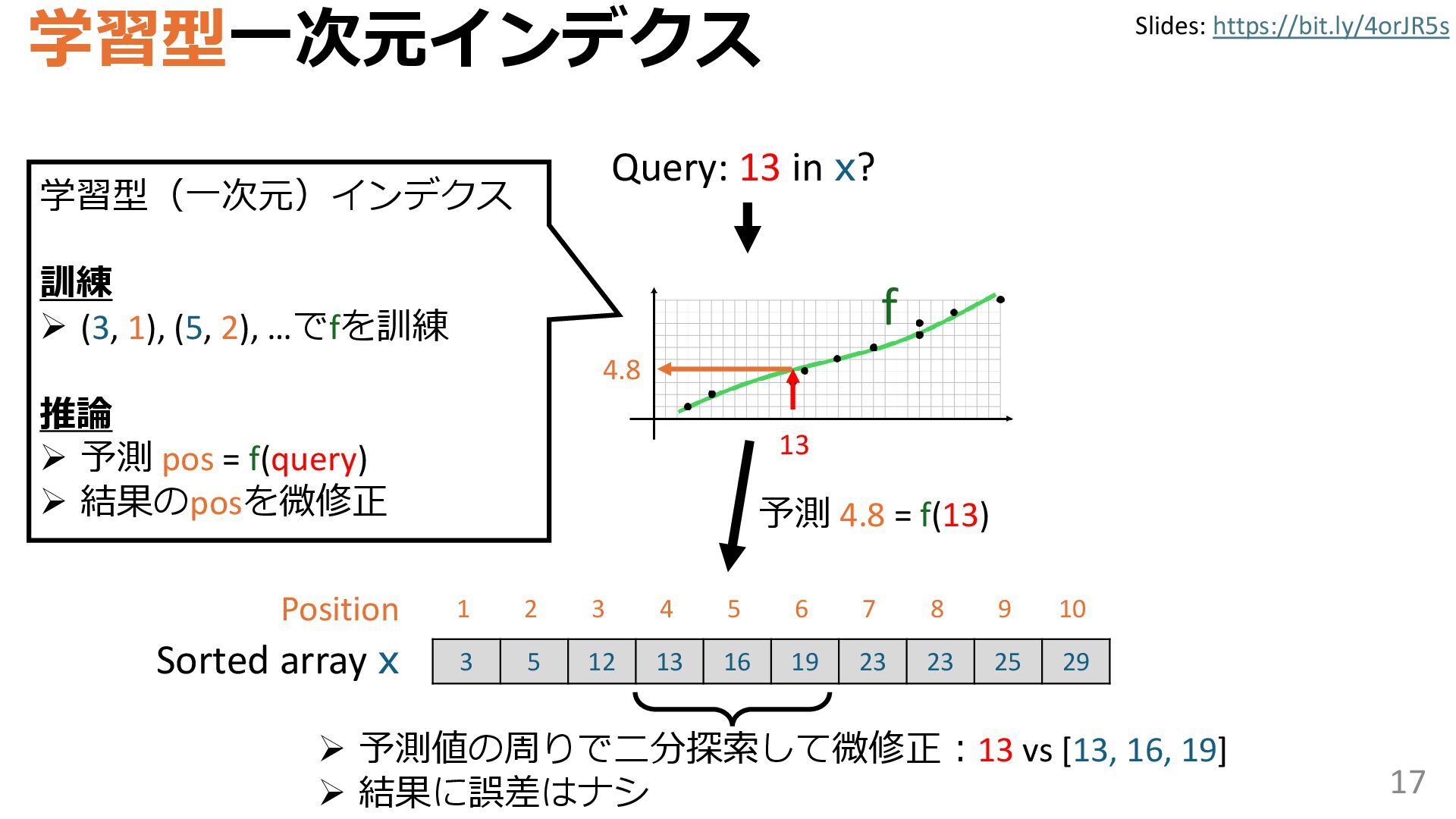{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
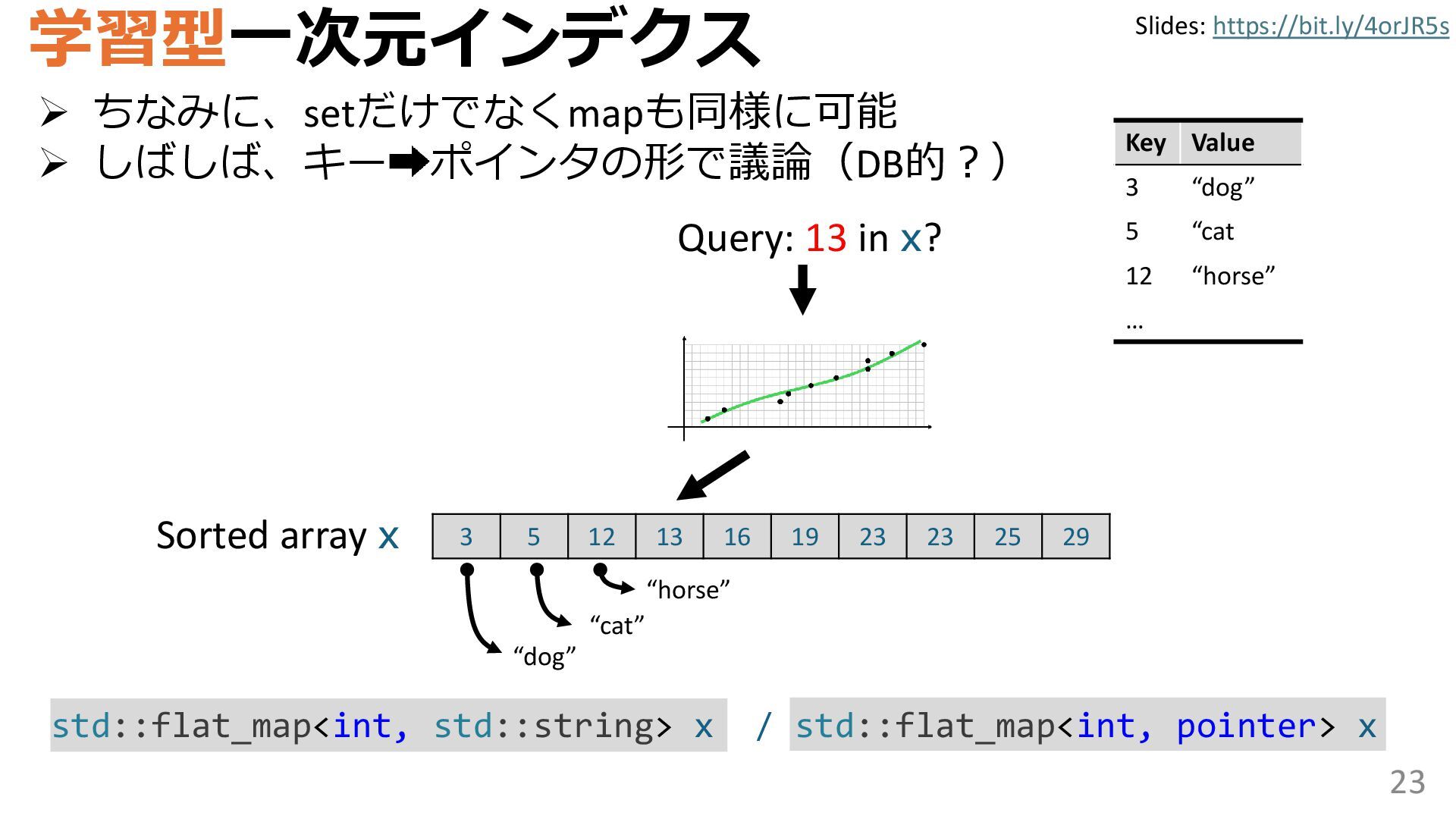{kind=link}
{kind=link}
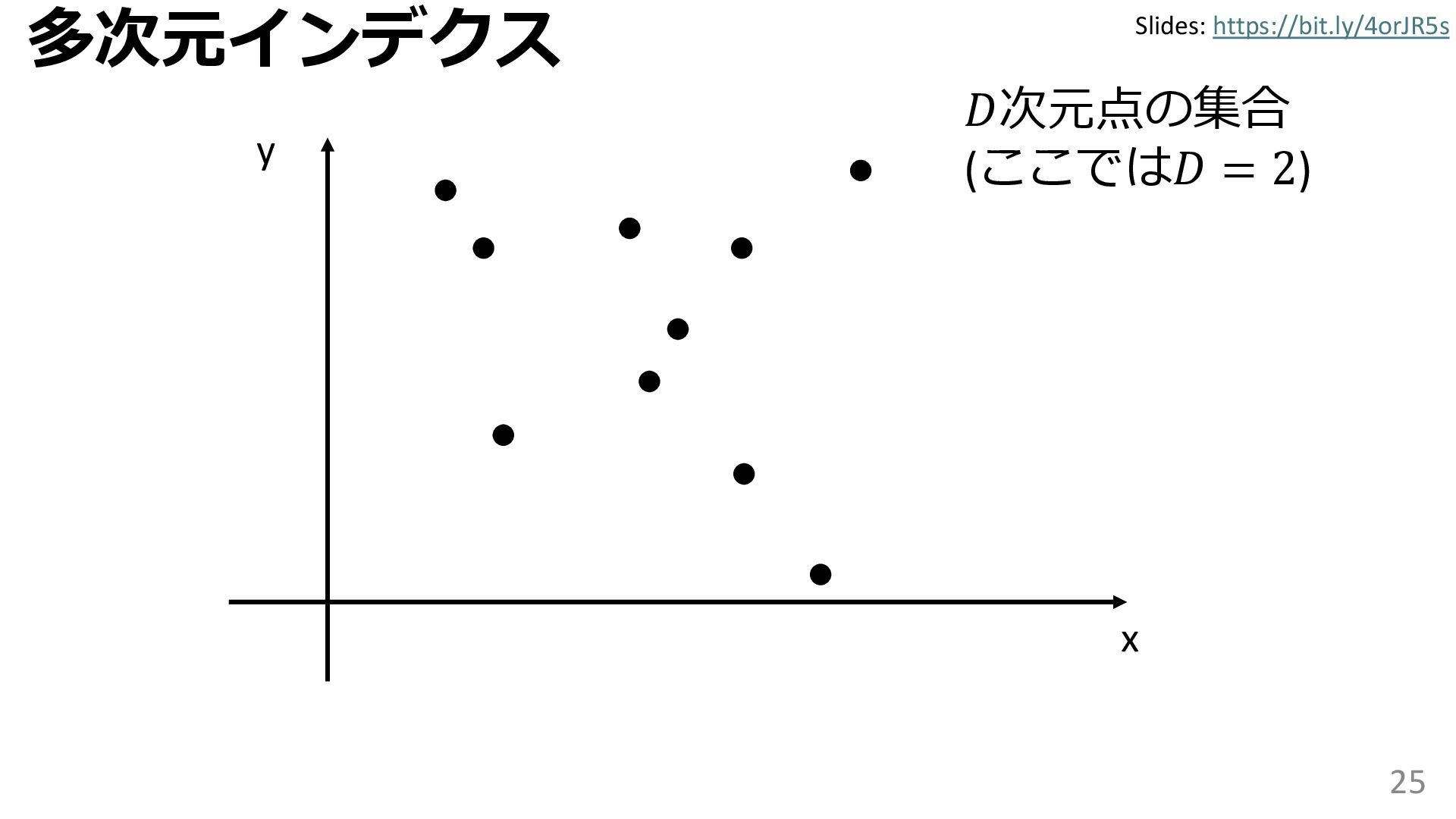{kind=link}
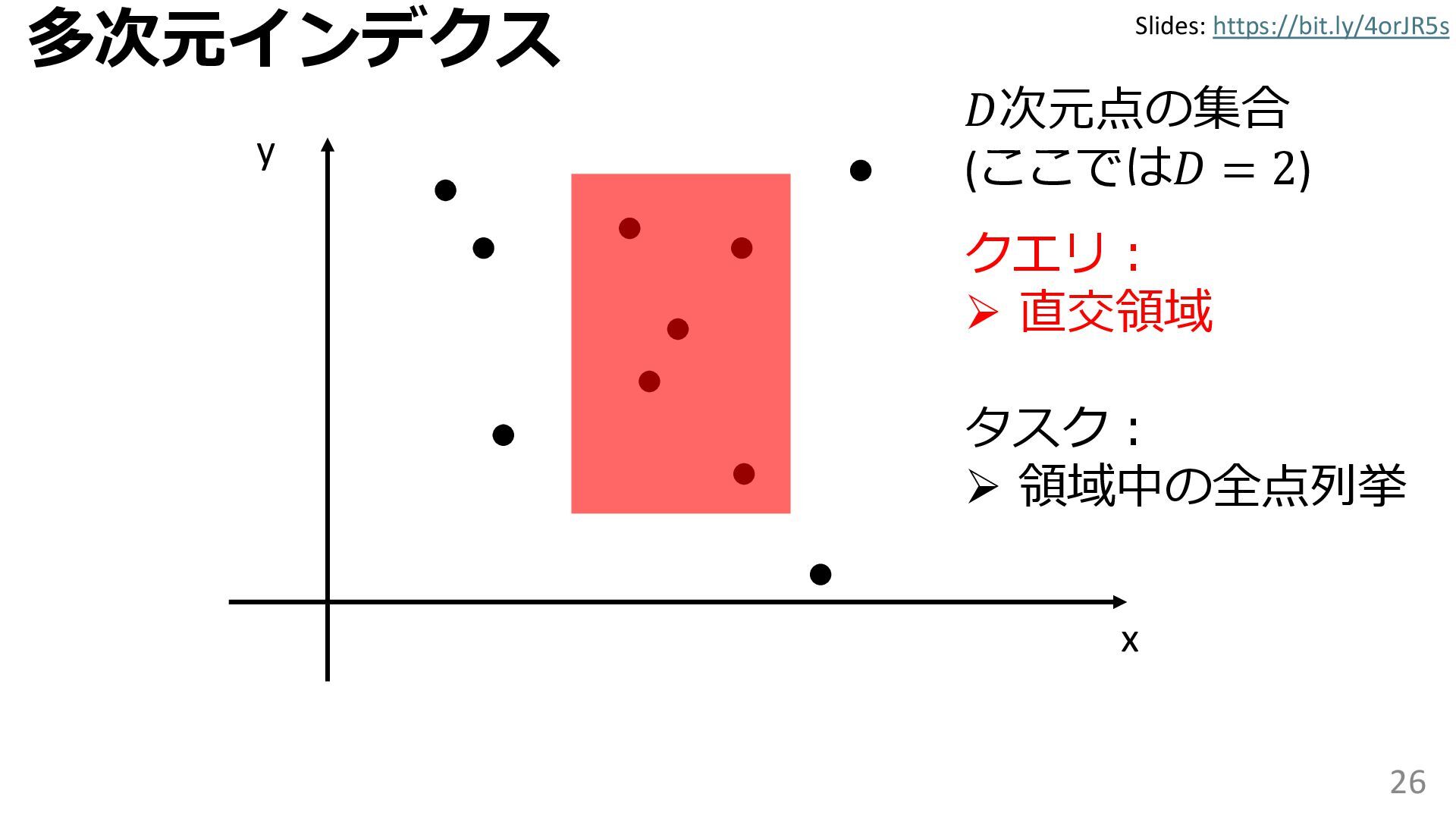{kind=link}
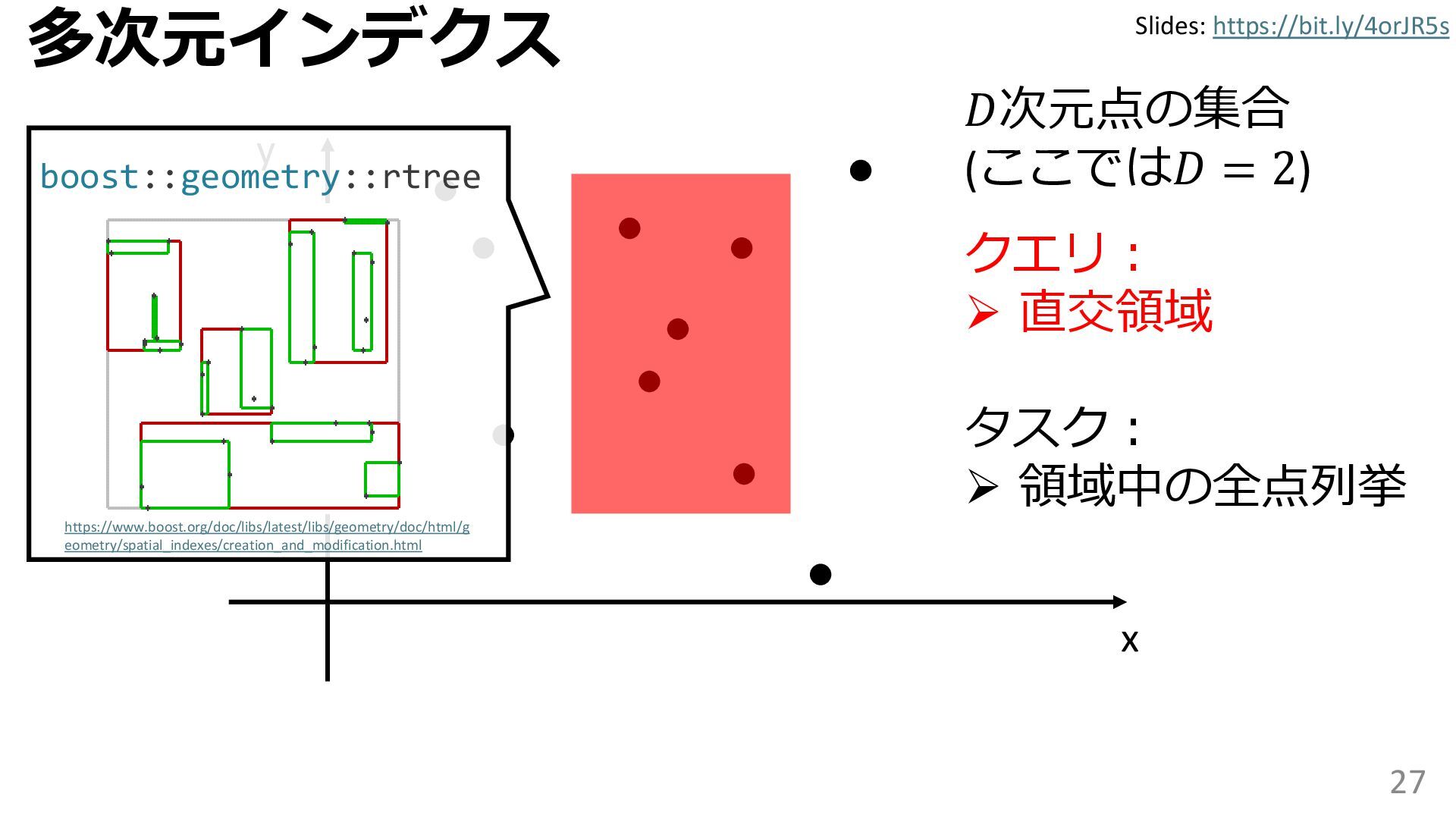{kind=link}
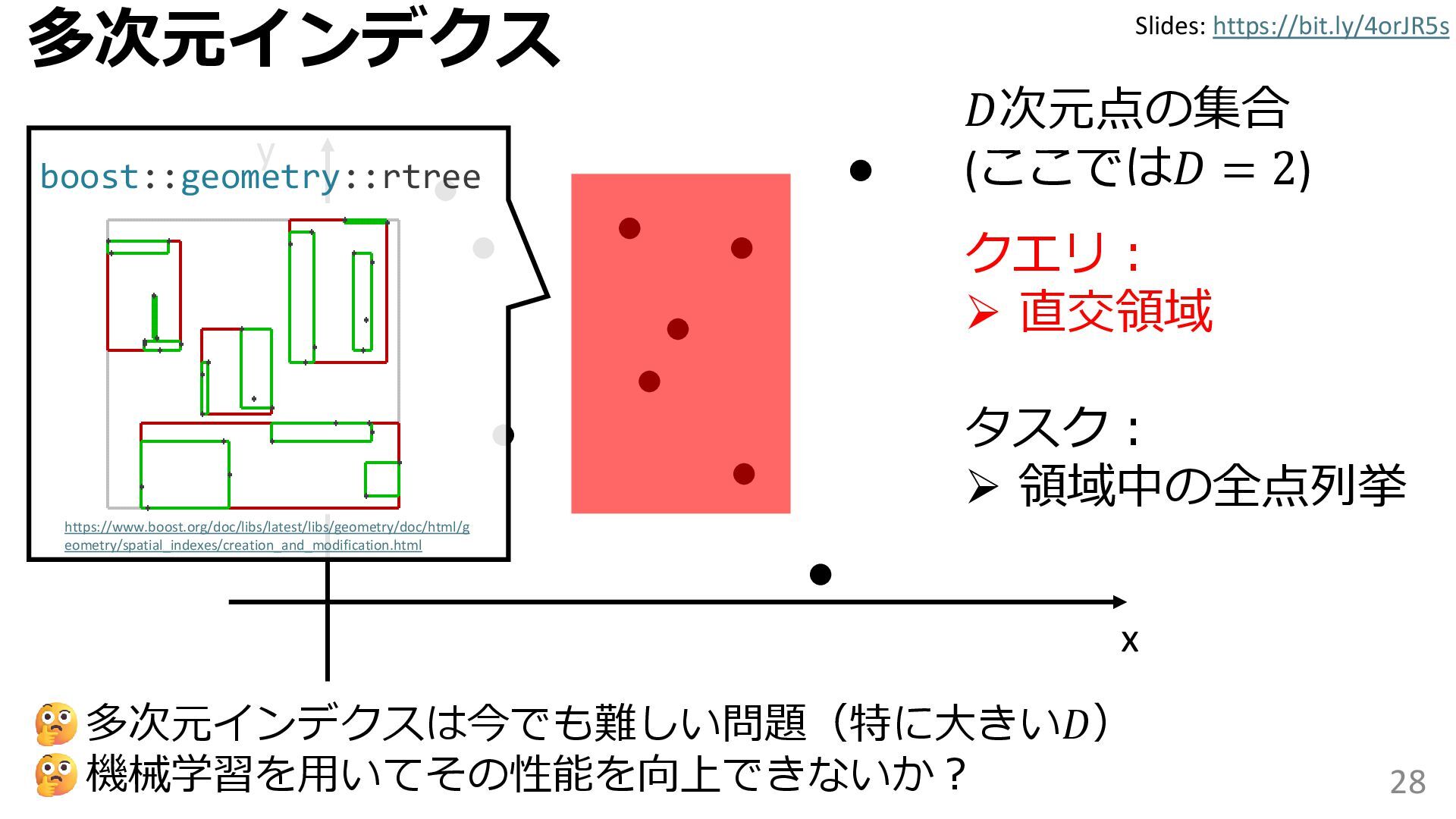{kind=link}
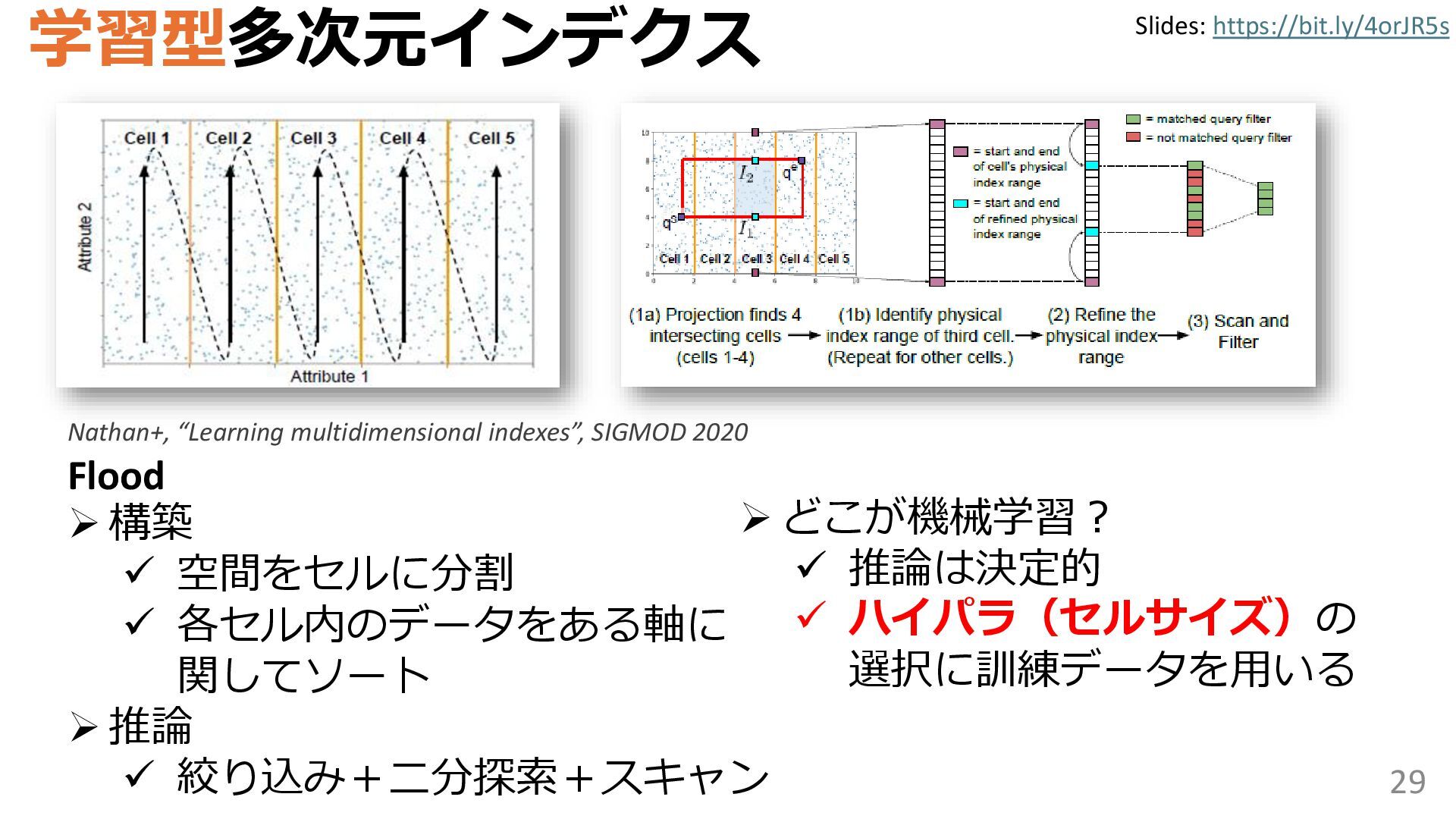{kind=link}
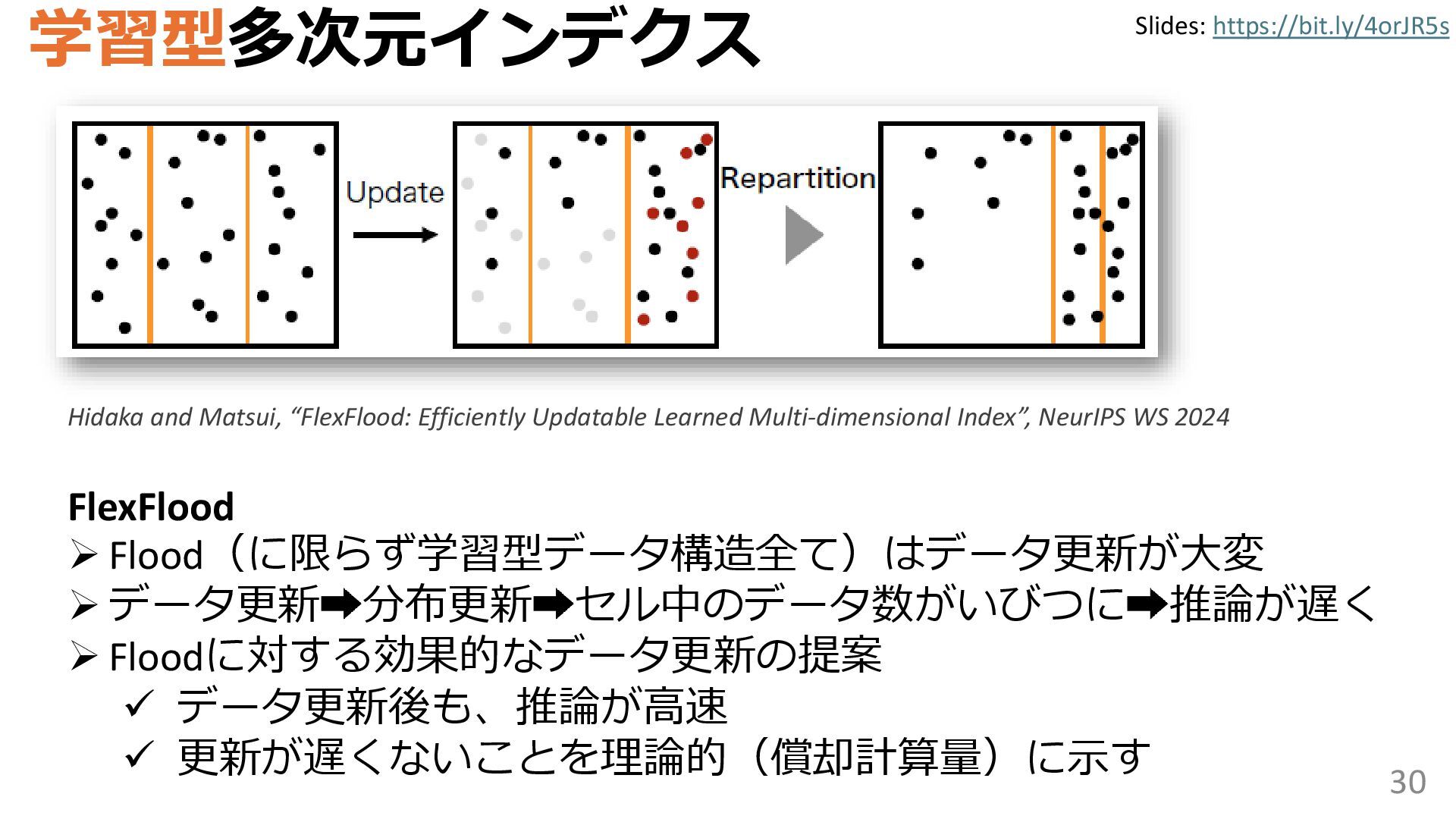{kind=link}
{kind=link}
{kind=link}
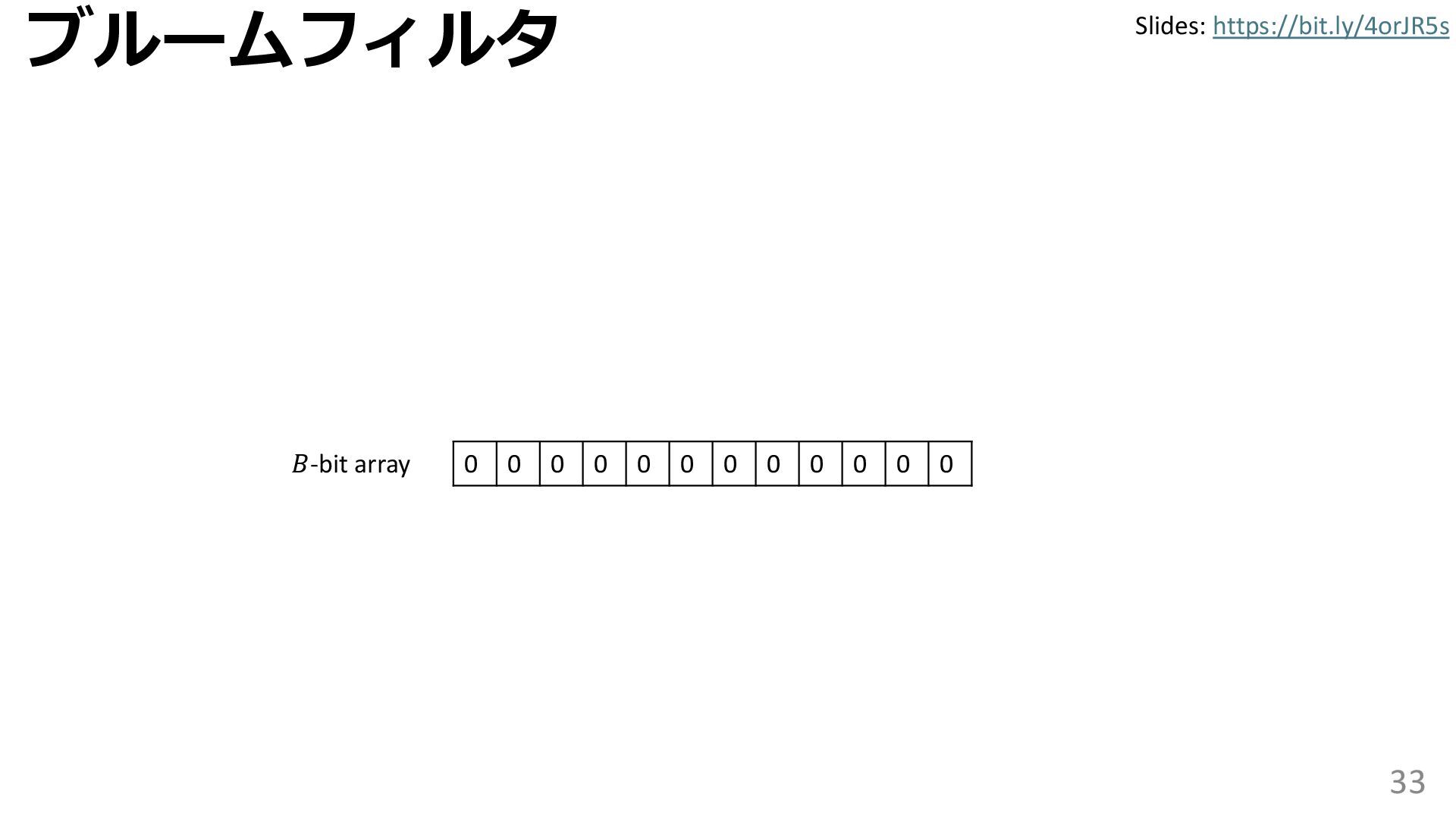{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
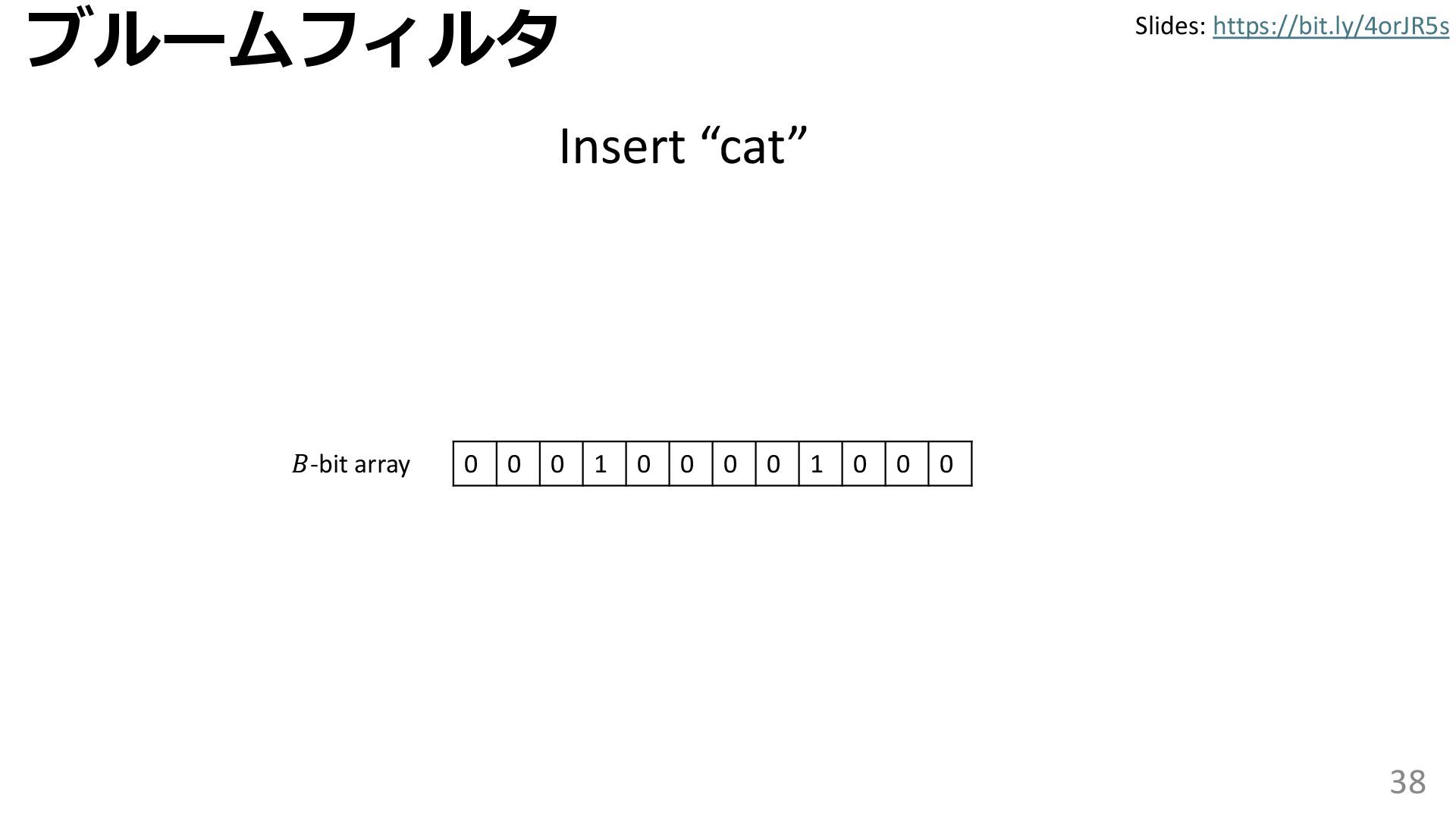{kind=link}
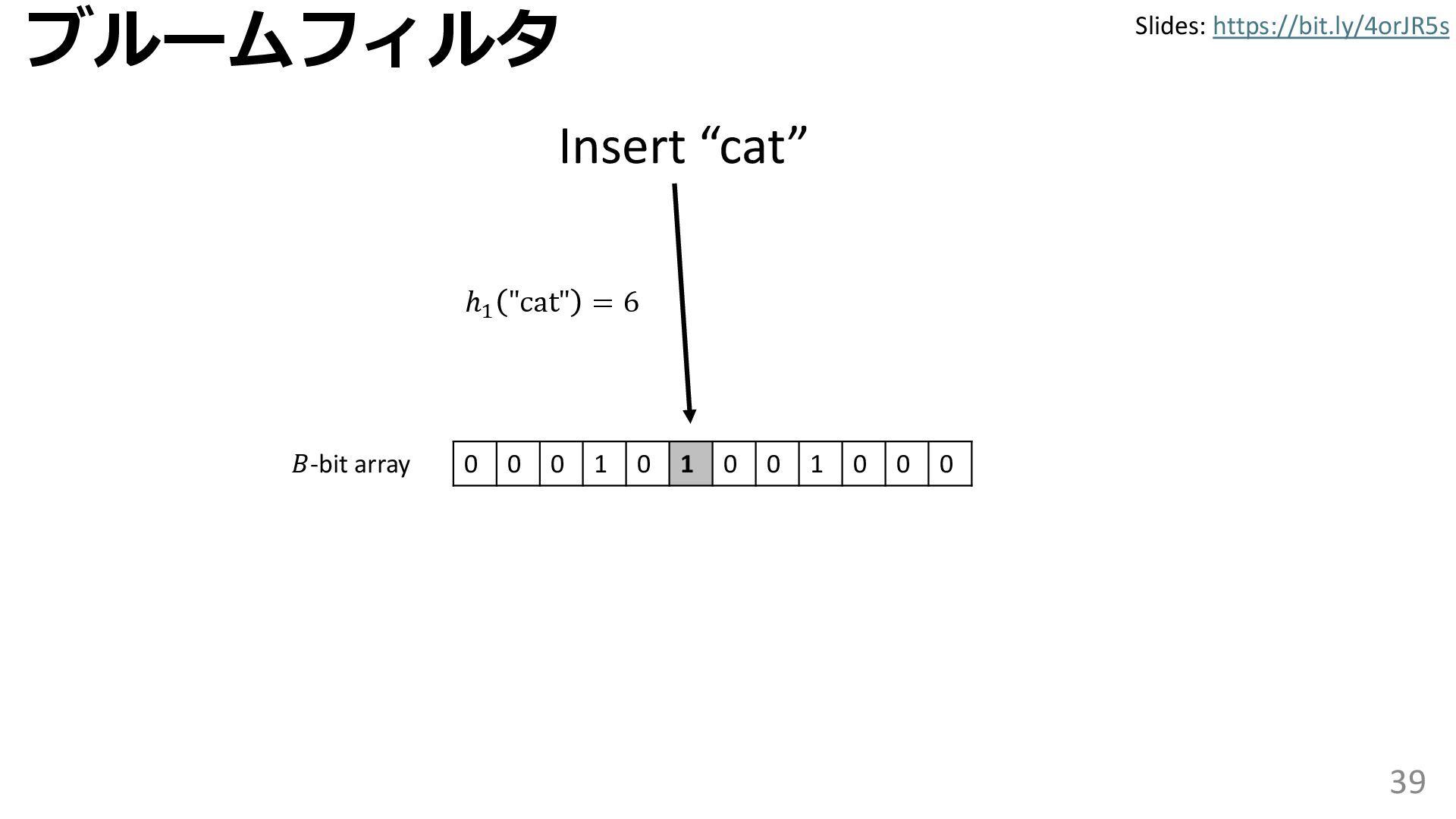{kind=link}
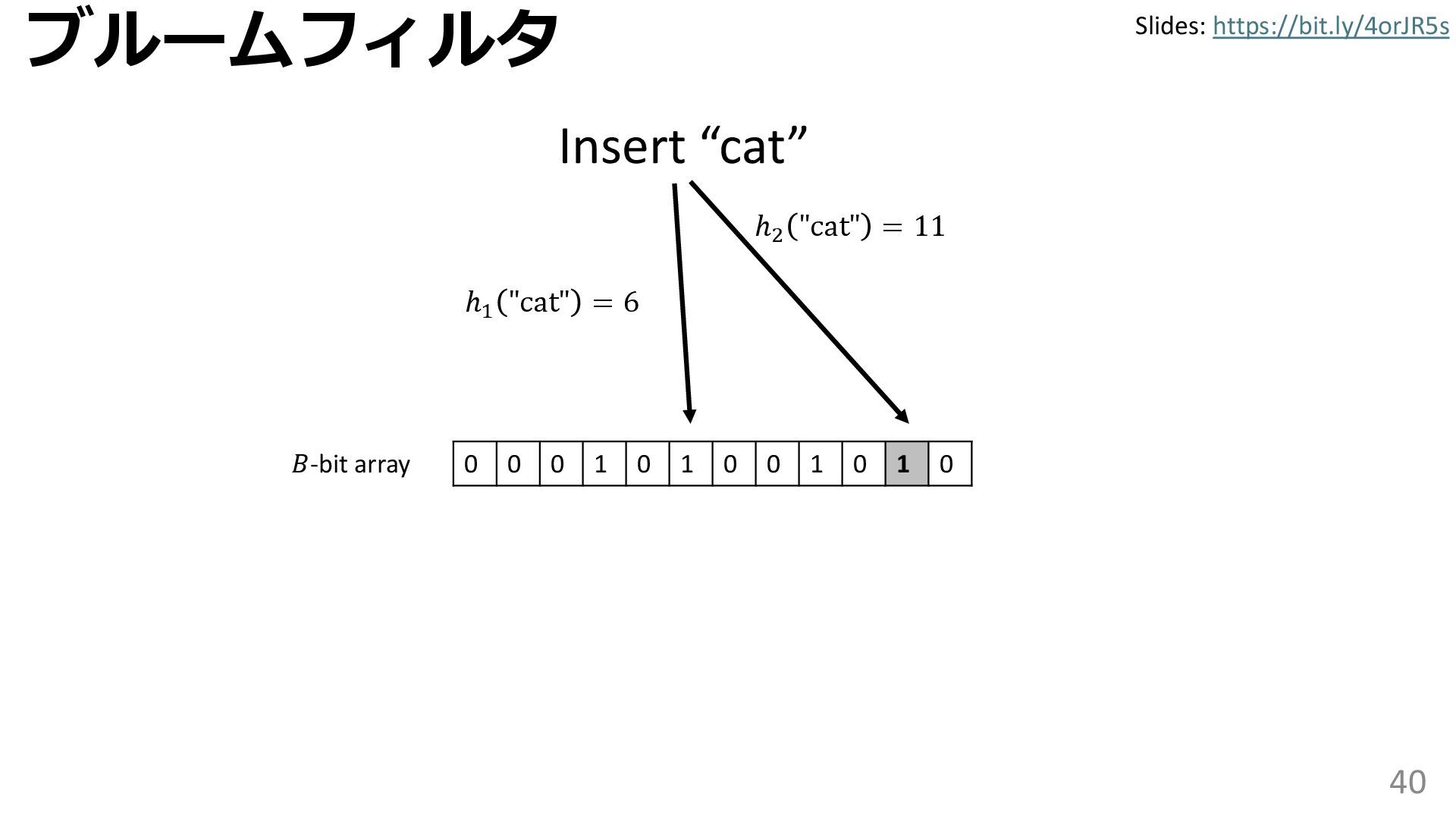{kind=link}
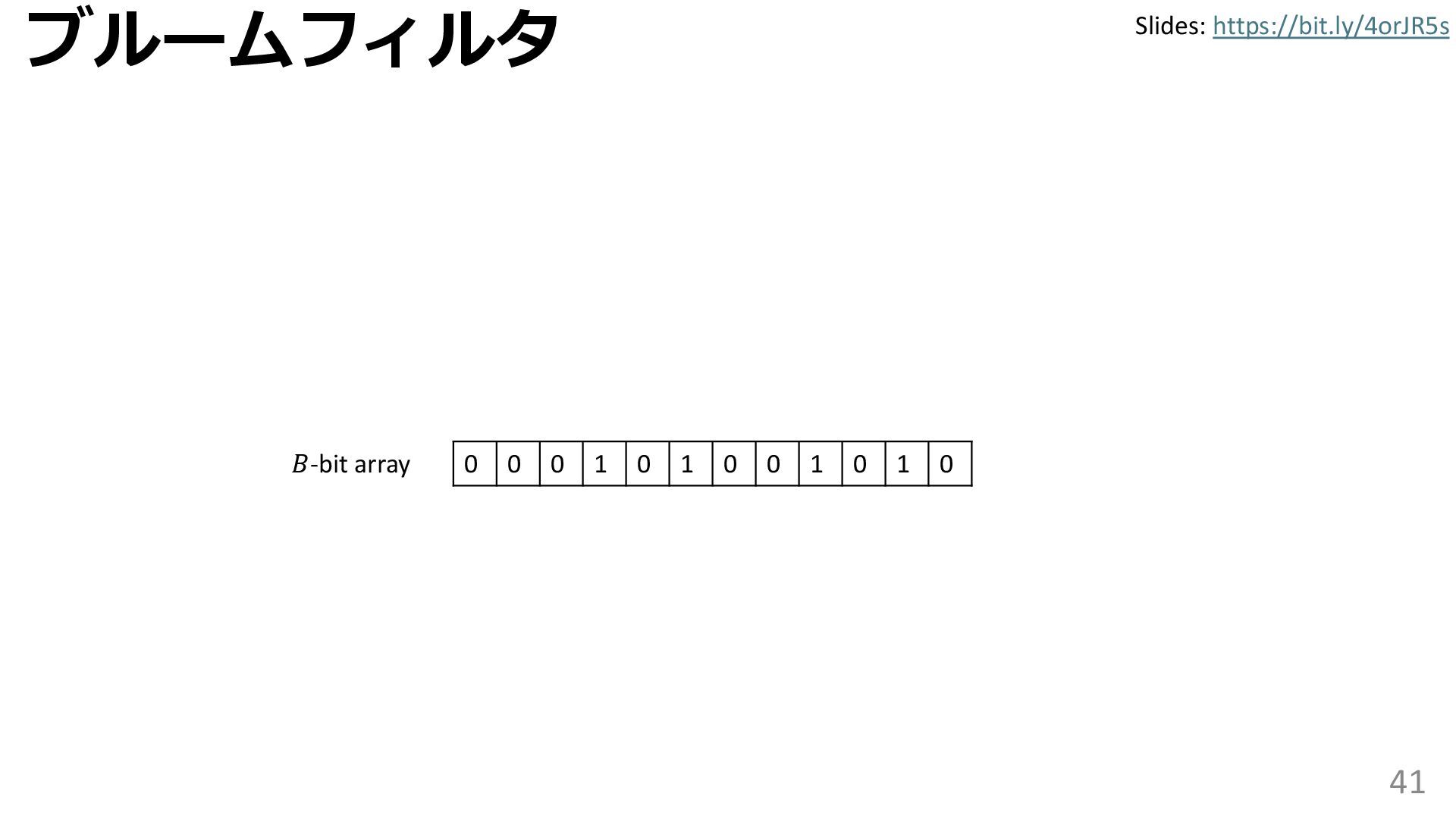{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
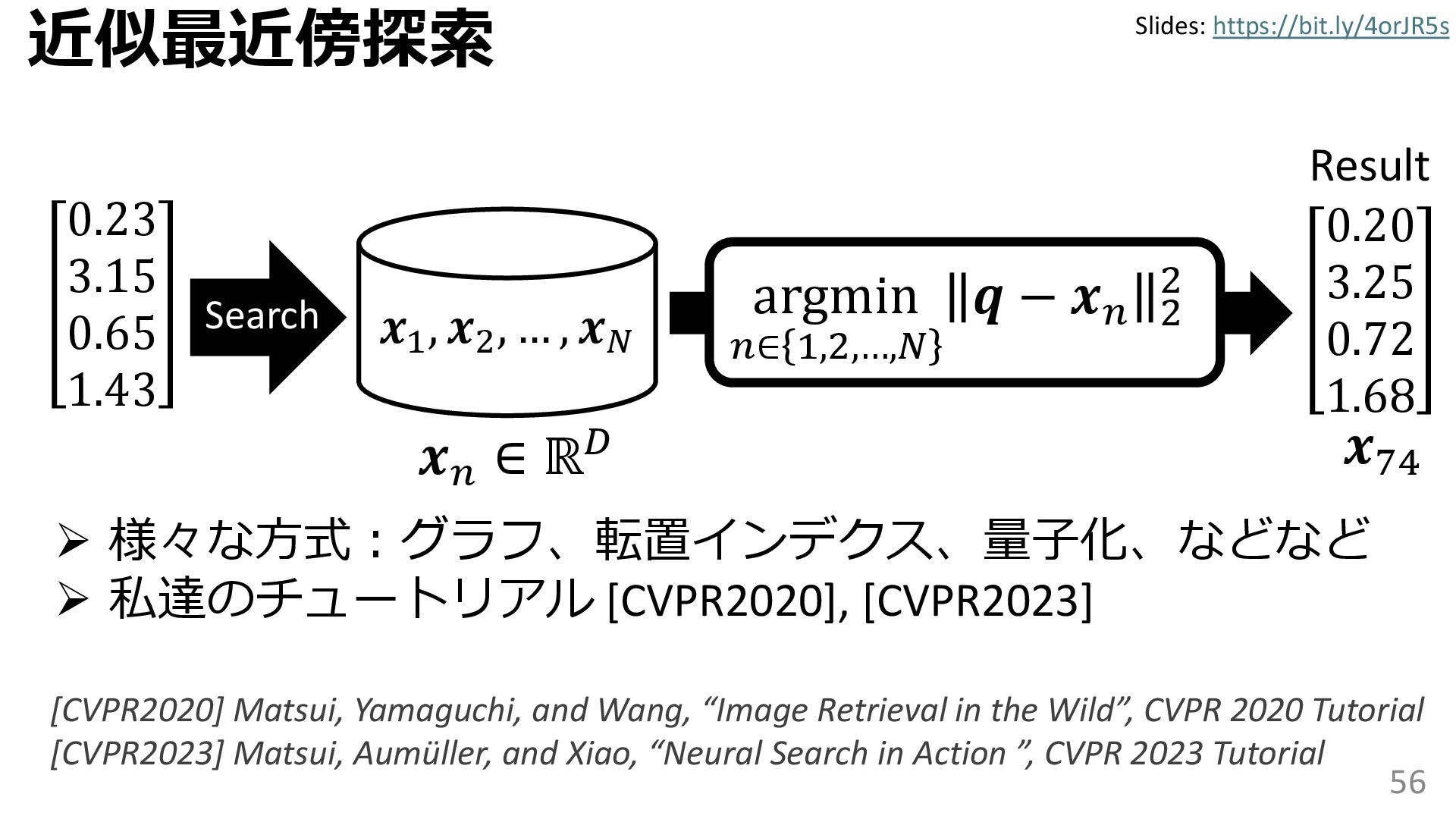{kind=link}
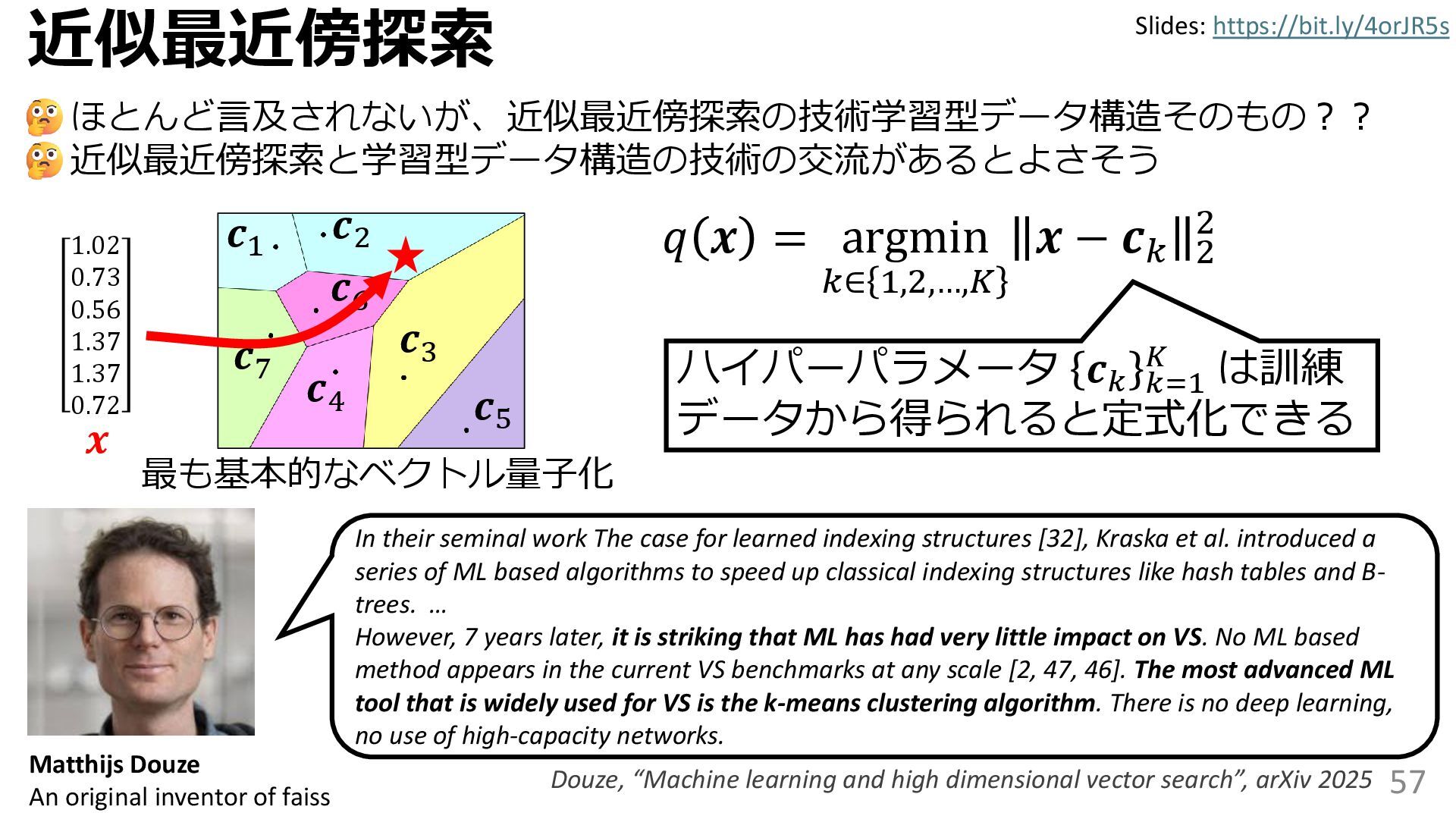{kind=link}
{kind=link}
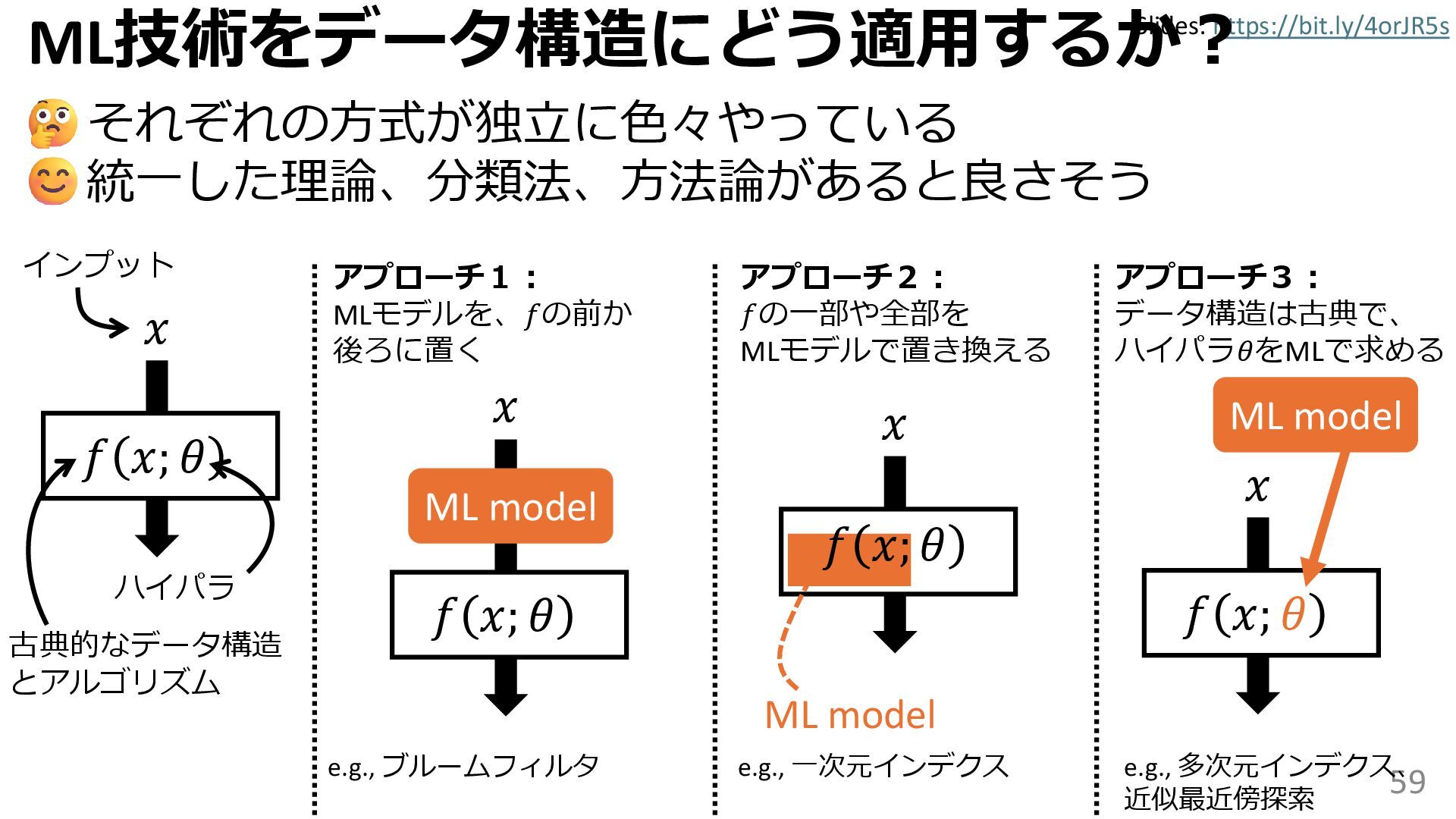{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}