the near future, we deploy our apps on Docker fleets on IaaS (Google Container Engine, EC2 Container Service) • A container-based workflow requires us to adapt apps to new way • Heroku builds container-based workflow at Scale and the twelve-factor apps is written by Heroku co-founder from their experiences We can learn many things from Heroku
Dependencies Explicity, isolated 3. Config Store in environment vars 4. Backing Services Treat as attached resources 5. Build, release, run Strictly separated 6. Processes Execute as stateless 7. Port binding Export via port binding 8. Concurrency Scale out via process model 9. Disposability Robustness with fast startup and graceful shutdown 10. Dev/prod parity Keep as similar as possible 11. Logs Treat as event streams 12. Admin processes Run tasks as one-off processes
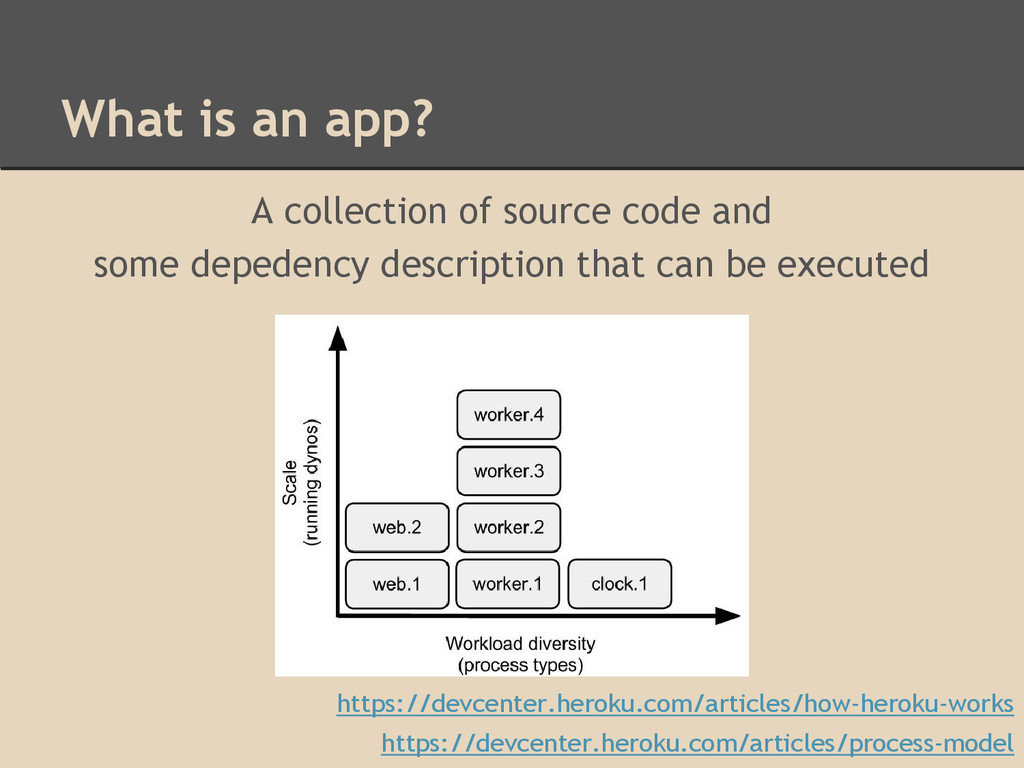
some depedency description that can be executed https://devcenter.heroku.com/articles/how-heroku-works https://devcenter.heroku.com/articles/process-model
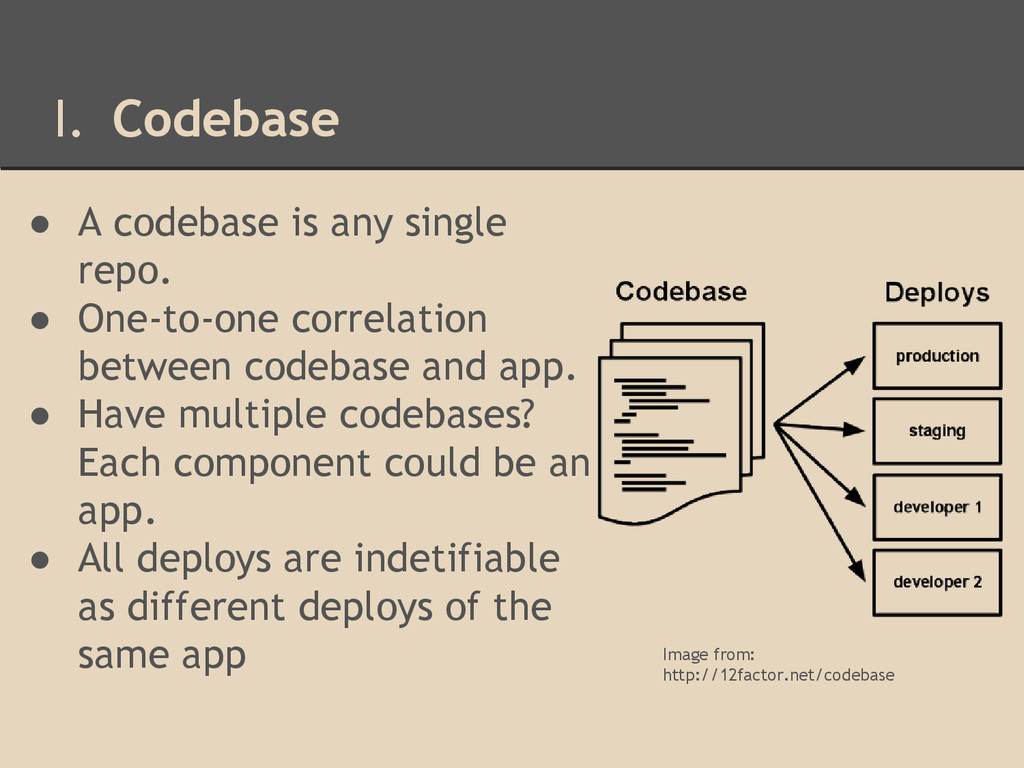
One-to-one correlation between codebase and app. • Have multiple codebases? Each component could be an app. • All deploys are indetifiable as different deploys of the same app Image from: http://12factor.net/codebase
wide packages and system cli tools. • Declare all dependencies, completely and exactly via manifest (rubygem, pip, godep, Dockerfile in the near future) • FYI, godep is by Heroku guys, Keith Rarick • Use depedency isolation tool to ensure that no implicit depedencies “leak in”. (bundle exec, static linking, dedicated $GOPATH) • Easy to setup, run with deterministic build
deploys (dev, staging, production, etc) ◦ backing services, credentials, canonical hostname, etc • Not include internal application config ◦ routing, timeout seconds, const, etc • Store config in environment variables • Idependently managed for each deploy • Env vars fits well with the process model • Scale up smoothly as the app naturally expands into more deploys (just spawn new process)
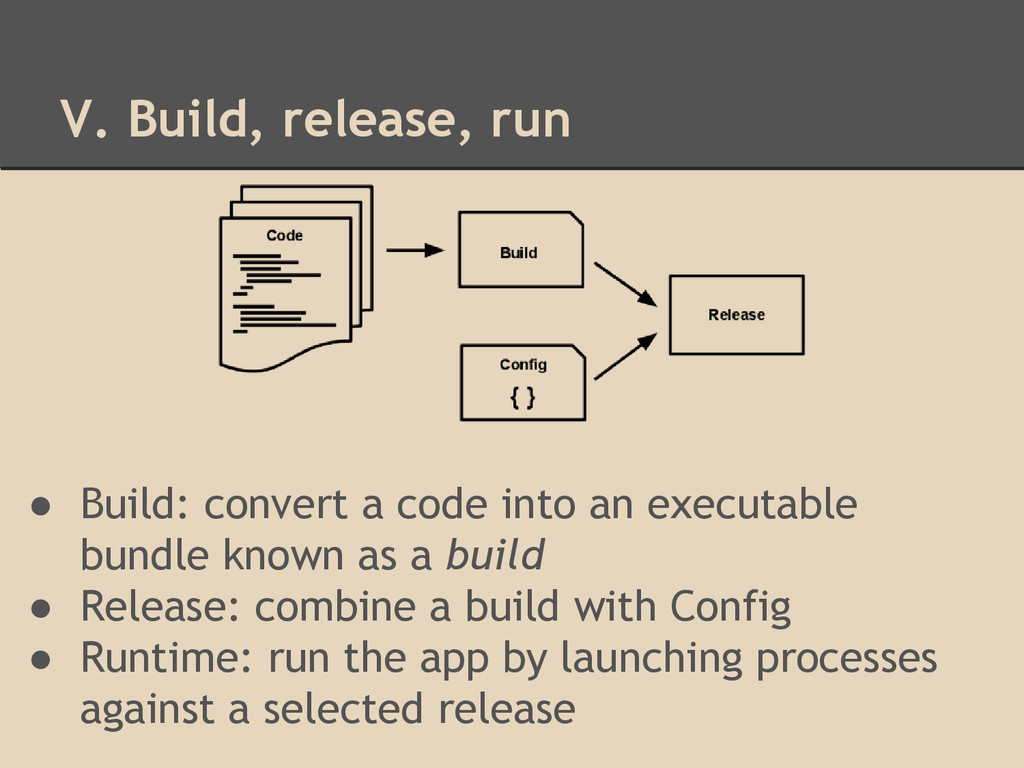
devs (e.g. by git push) ◦ errors are always in the foreground for devs • Runtime execution can happen automatically (e.g. reboot, crash recovery, autoscale) ◦ It could happen when no devs are on hand • If builds are initiated by runtime execution and if github is down at the time, ……. • It’s important to separate into build and release stage. • Of course, any change must create a new release
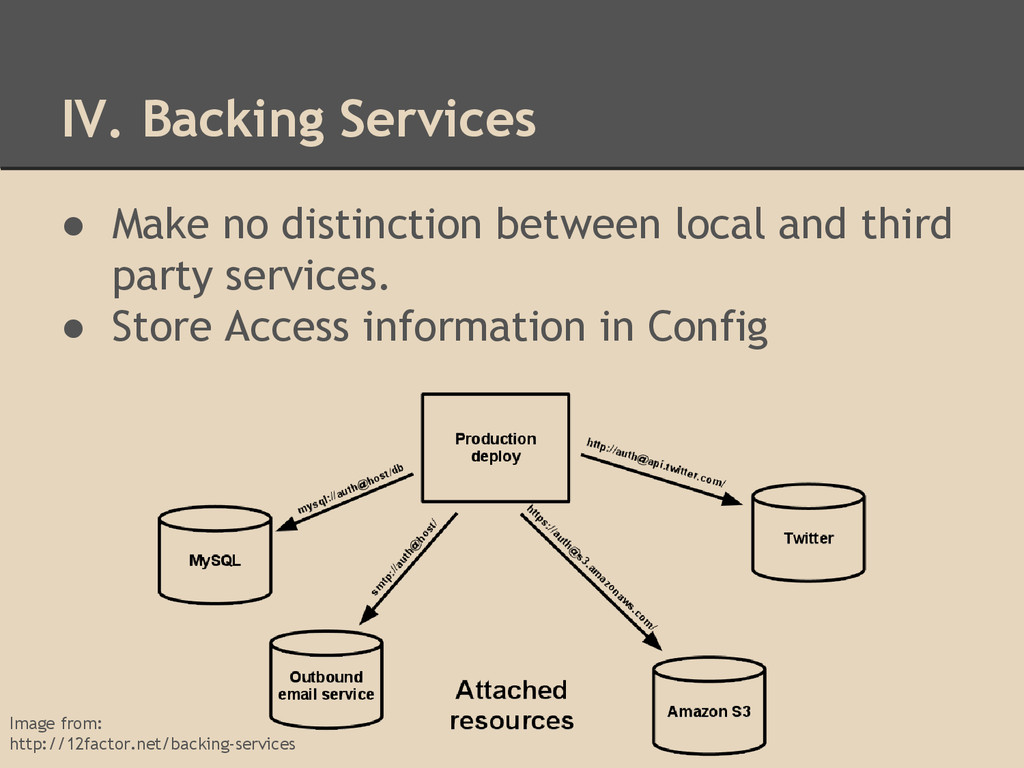
data needs to persist must be stored in a stateful backing service • Use filesystem or memory only for single- transaction cache • Never assume that anything cached in memory or on disk will be available on a future request • Prefer to do asset compiling during the build stage
a webserver to create a web-facing service ◦ e.g. PHP might run as a module inside Apache. Releases must have a code, Apache, PHP module and appropriate configuration inside. • Export HTTP as a service by binding to a port, and listening to requests • A port number to bind is Config provided by execution environment. $PORT will be used.
adding more concurrency is a simple and reliable operation because app is just a process. • Remember, Processes are stateless and shared-nothing! • Never daemonize or write PID files. • Rely on the process manager (upstart, systemd, foreman, etc) to manage output stream, respond to crashed process, and handle restarts and shutdowns
started or stopped at a moment’s notice. • Facilitate fast elastic scaling, rapid deployment of code or config changes, and robustness of deploys • It forces us to think how to be robust against sudden death
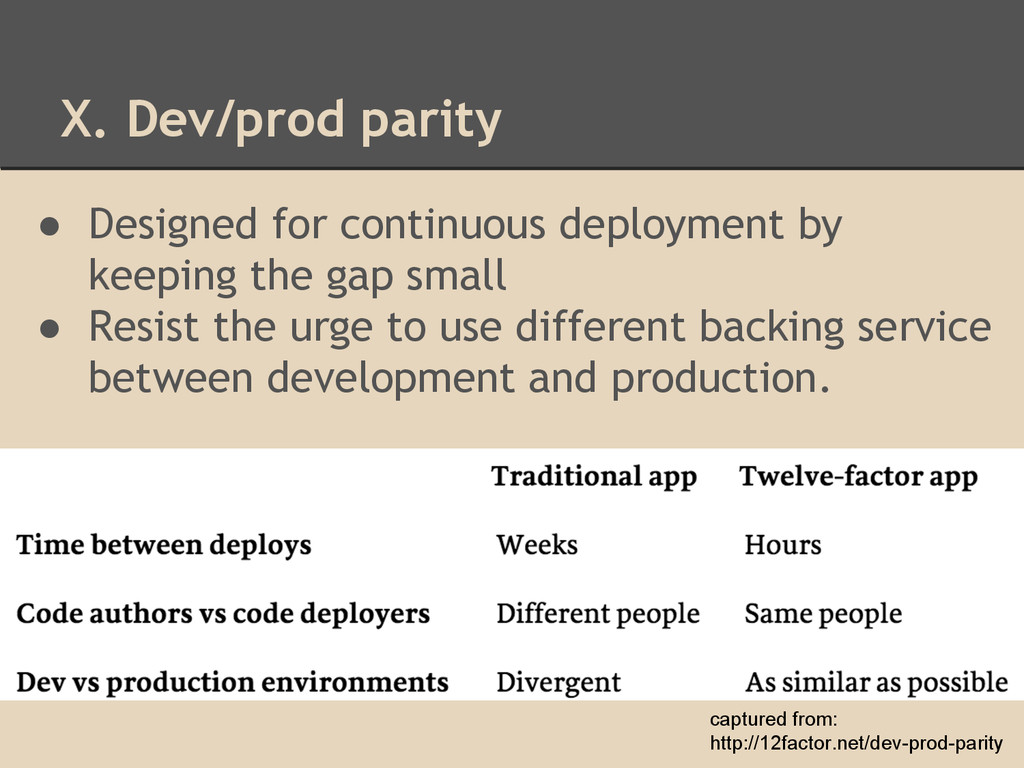
the gap small • Resist the urge to use different backing service between development and production. captured from: http://12factor.net/dev-prod-parity
ordered events • Collect from the output of all running processes • App never concerns itself with routing and storage of its output stream • Write event stream to STDOUT • Local: View stream in terminal • Prod: Capture stream by process manager and send to log collector (e.g. Fluent)
or maintenance tasks ◦ DB migration, Running a console to inspect the live database • Run in an idential environment as the regular running processes • Run against a release, using the same codebase and config • Admin code must ship with application code to avoid synchronization issues
◦ Encrypt credentials with public key? ◦ Use IAM in EC2 but how it works for other services ◦ How is Heroku/AWS dependable? • Codebase vs App ◦ TF apps is tightly coupled with a codebase since Heroku needs to build an image from the codebase ◦ In Docker, we can build an image by ourselves and put the image to the repository ◦ We can focus on container image and app.
to container image • Release is an image + config (Not image!) ◦ Because you don’t include credentials in the image • Docker Engine is a container execution engine ◦ does not manage an environment and a release ◦ (but it still provides an environment!) • Docker hub is an image repository as Git is an repository for codebase • Projects such as Kubernetes are very important because Docker does not mange environment and a release.
like the UNIX Processe • Use envvars for config varing across deploys • Export software as a service by binding a port • Launch new container to scale out • Not rely on local disk and memory • Fire logs to unbuffered STDOUT and forget • Run admin tasks in the same container and environment • Deploy app as {fast, many} as possible
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}