Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Write an embedded time-series database in Go
Search
nakabonne
November 13, 2021
Programming
770
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Write an embedded time-series database in Go
nakabonne
November 13, 2021
More Decks by nakabonne
See All by nakabonne
Want to quickly put dbg! into external crates?
nakabonne
0
73
モジュールの深さについて / depth of module
nakabonne
0
180
Web API × Clean Architecture / CleanArchitecture Go
nakabonne
3
18k
Other Decks in Programming
See All in Programming
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
580
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
120
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
100
自作OSでスライド発表する
uyuki234
1
3.8k
フィードバックで育てるAI開発
kotaminato
1
110
例外の正しい扱い方 そのエラー try-catchして大丈夫?
jinwatanabe
0
360
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.4k
AI 輔助遺留系統現代化的經驗分享
jame2408
1
1.2k
【やさしく解説 設計編 #1】「ドメイン駆動」と「実装駆動」ってなに? 〜設計の考え方を、たとえ話で学ぼう〜
panda728
PRO
1
110
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
2
260
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
100
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
250
Featured
See All Featured
Marketing to machines
jonoalderson
1
5.6k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Ruling the World: When Life Gets Gamed
codingconduct
0
280
Believing is Seeing
oripsolob
1
170
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Design in an AI World
tapps
1
260
Skip the Path - Find Your Career Trail
mkilby
1
170
ラッコキーワード サービス紹介資料
rakko
1
3.9M
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
The Cult of Friendly URLs
andyhume
79
6.9k
Transcript
Write an embedded time-series database in Go @GoCon 2021 Autumn
Ryo Nakao (@nakabonne)
自己紹介 • 中尾 涼 (@nakabonne) • 株式会社サイバーエージェント • PipeCD フルタイム開発
Agenda • 時系列データの特徴 • tstorageの設計 • Goでの実装について
Write an embedded time-series database in Go Ryo Nakao (@nakabonne)
Write an embedded time-series database in Go Ryo Nakao (@nakabonne)
Embedded database • ライブラリとして提供されている埋め込み可能なデータベース • 有名なものでLevelDBやRocksDBなどがある
モチベーション 00
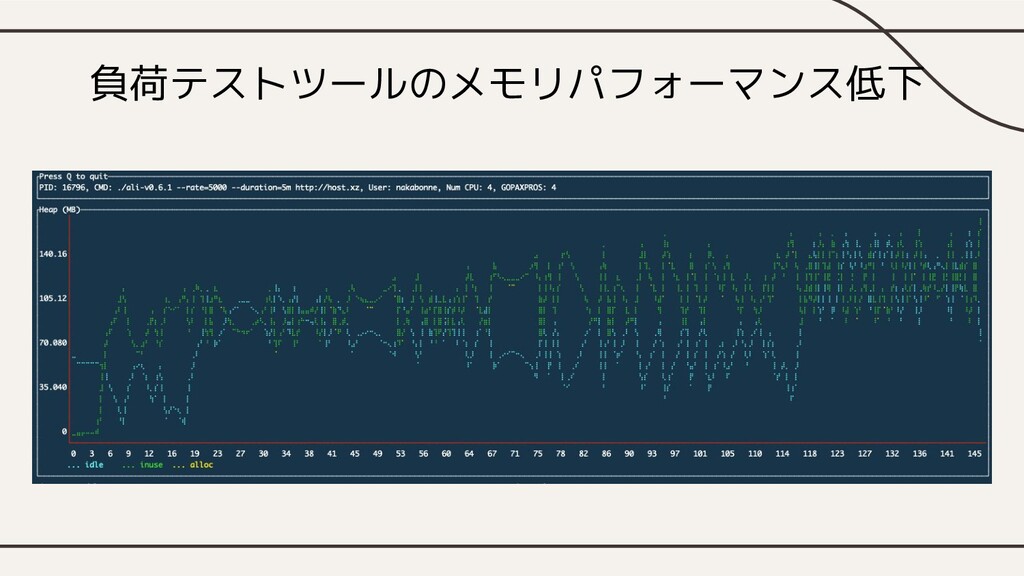
負荷テストツールのメモリパフォーマンス低下
負荷テストツールのメモリパフォーマンス低下 • 計測結果をSliceにappendしていくだけだった • ディスクも活用したストレージエンジンが欲しい • Go言語からEmbedded databaseとして利用できるものが無い • →
作るしかない
tstorage
時系列データの特徴 01
時系列データ • タイムスタンプ順に並んだ値(データ ポイントと呼ぶ)の集まり • 時間の経過とともにデータがどう変化 するかを見るために使われる • e.g. システムメトリクス、株価データ
時系列データの特徴(一部) • データ量が膨大 • 直近のデータを読み出す • 期間指定して一括で読み出す
データ量が膨大 • 一定間隔おきに、永続的にデータが取り込まれる • データ量は線形的に増えていく
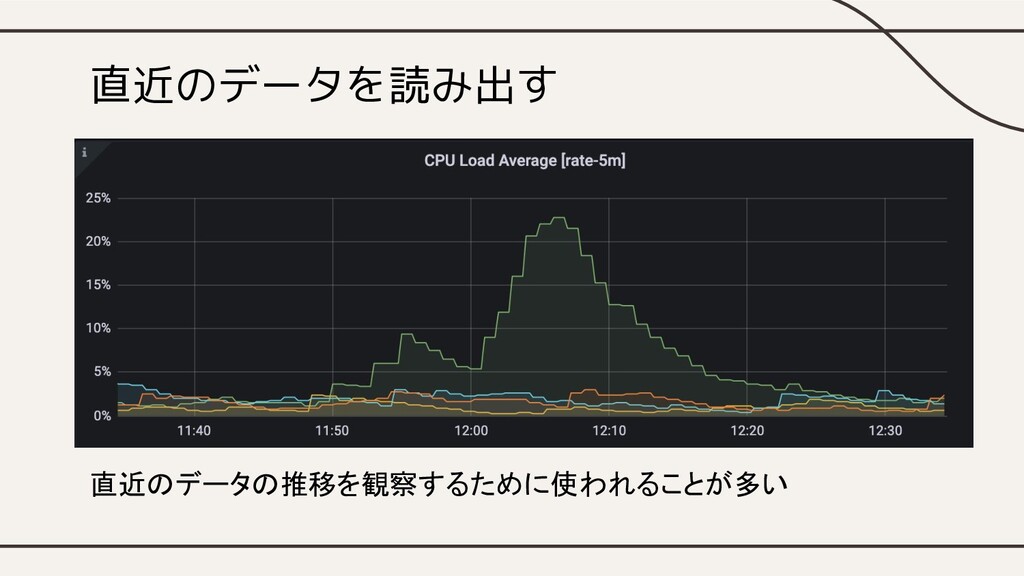
直近のデータを読み出す 直近のデータの推移を観察するために使われることが多い
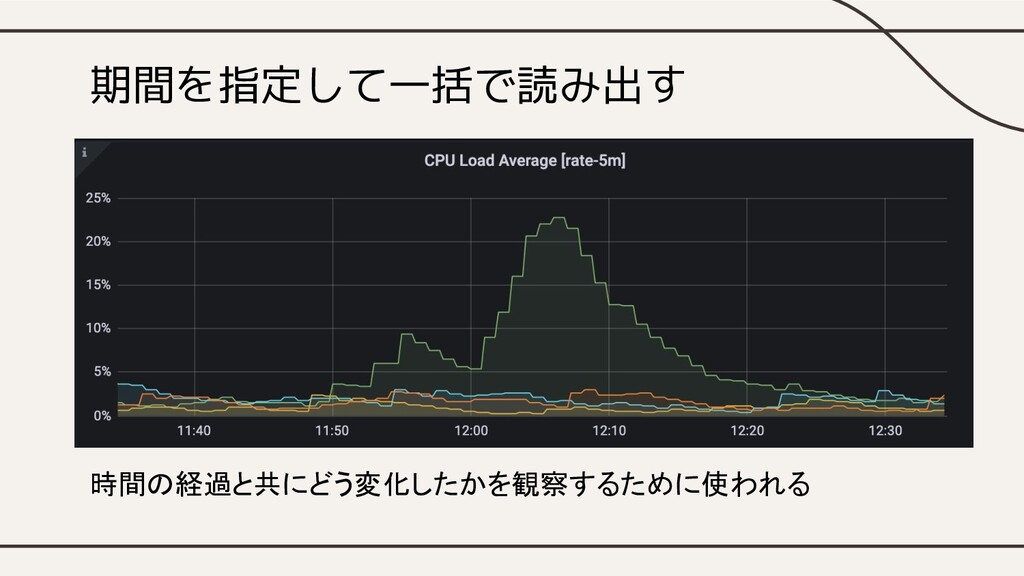
期間を指定して一括で読み出す 時間の経過と共にどう変化したかを観察するために使われる
速く書いて 速く読みたい こういった特徴がある中で なるべく多くのケースで
できるだけDRAMを使おう
データモデル 02
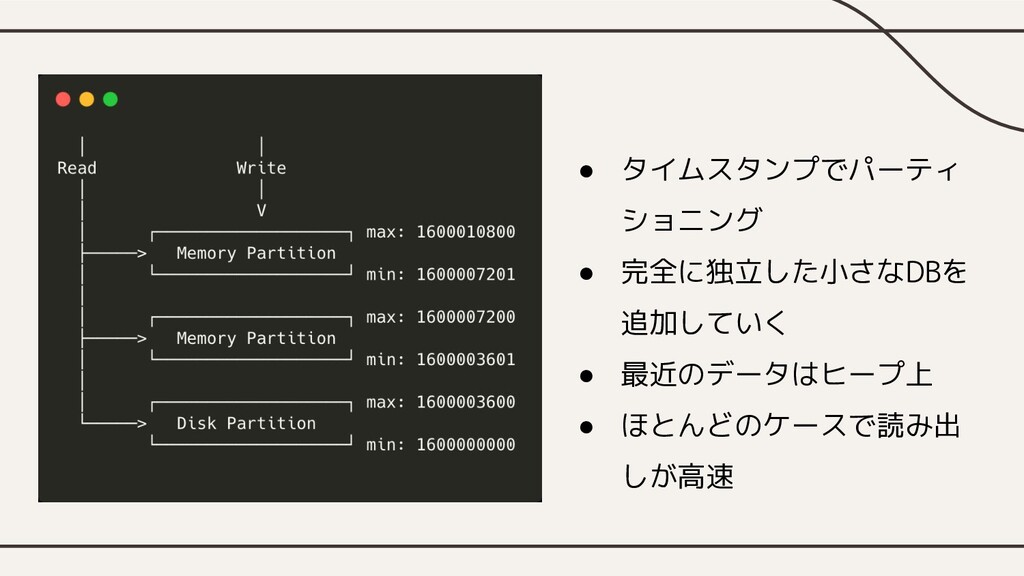
• タイムスタンプでパーティ ショニング • 完全に独立した小さなDBを 追加していく • 最近のデータはヒープ上 • ほとんどのケースで読み出
しが高速
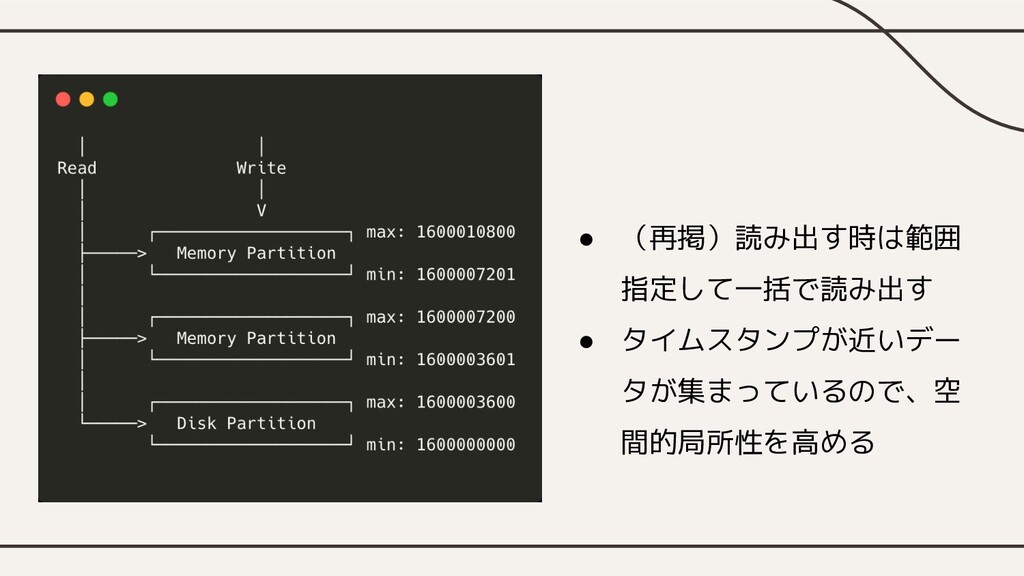
• (再掲)読み出す時は範囲 指定して一括で読み出す • タイムスタンプが近いデー タが集まっているので、空 間的局所性を高める
Memory Partitionと Disk Partition に分ける とりあえず
実装 ~ Memory Partition 03
Memory Partition • インメモリDB • データロスを防ぐために Write Ahead Logに書き 込む
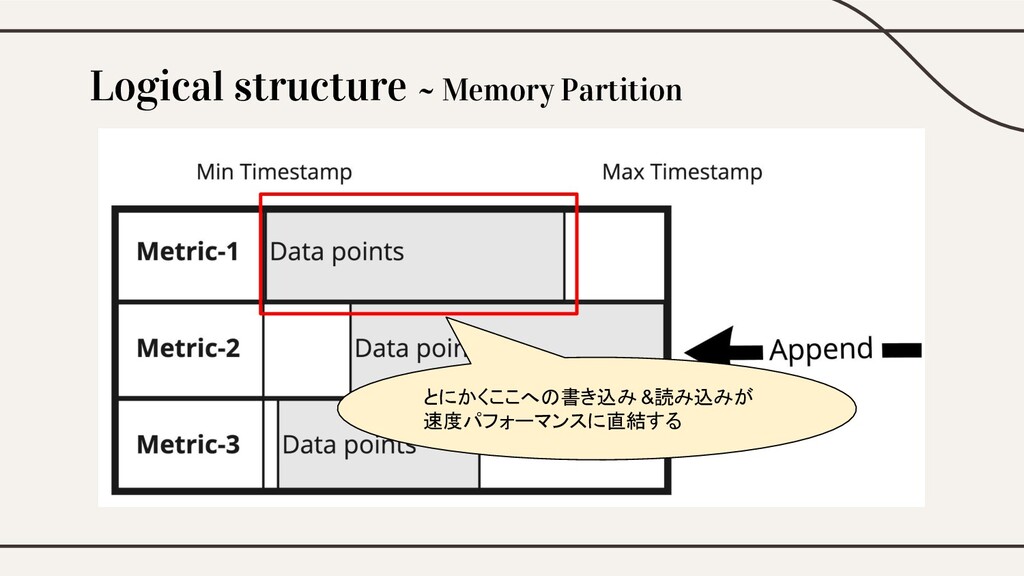
Logical structure ~ Memory Partition
Logical structure ~ Memory Partition とにかくここへの書き込み &読み込みが 速度パフォーマンスに直結する
How to represent data points • Sliceは基底配列に基づいている • 要素数がcapacityを超えると自動的に基底配列のメモリコピーが 発生
• 際限なくデータが取り込まれるケースでは理論的には要素の追加 をO(1)で行えるLinked-listベースのデータ構造が良さそう
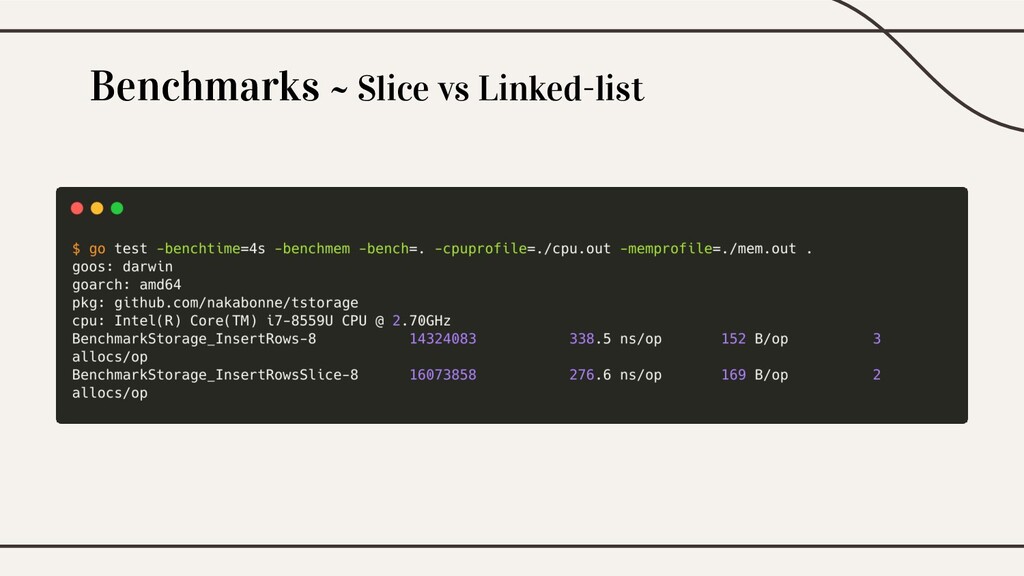
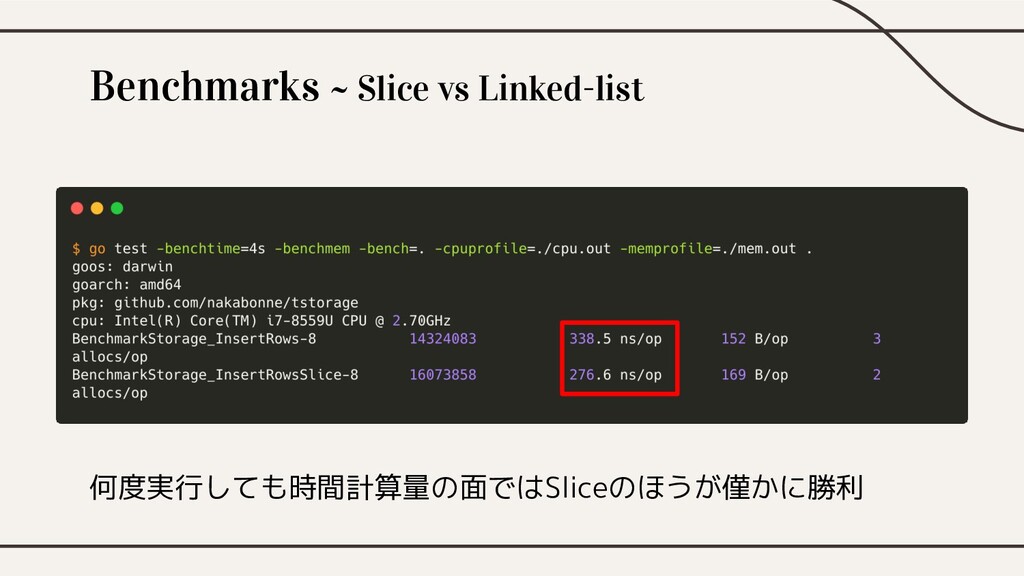
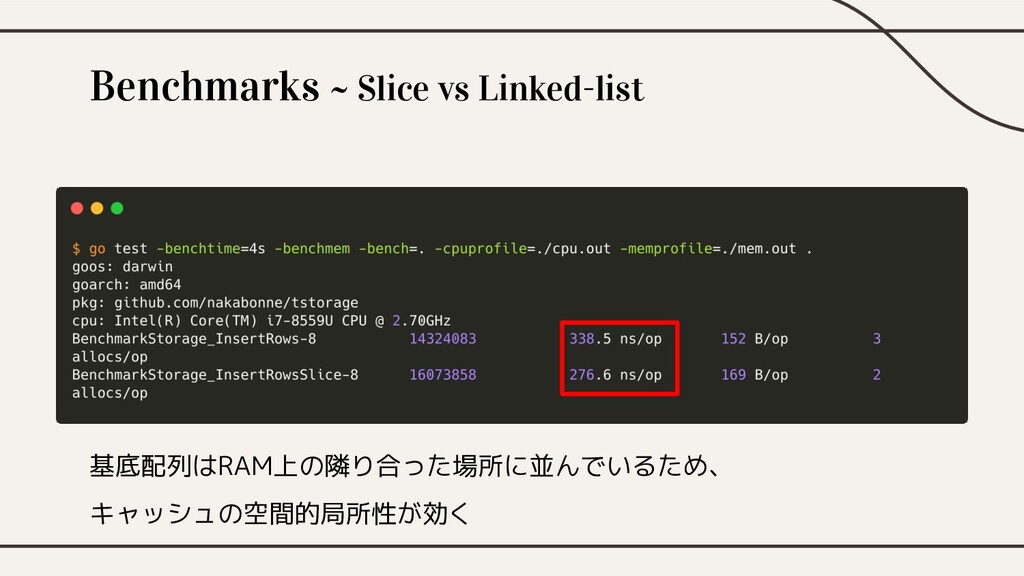
Benchmarks ~ Slice vs Linked-list
Benchmarks ~ Slice vs Linked-list 何度実行しても時間計算量の面ではSliceのほうが僅かに勝利
Benchmarks ~ Slice vs Linked-list 基底配列はRAM上の隣り合った場所に並んでいるため、 キャッシュの空間的局所性が効く
https://groups.google.com/g/golang-nuts/c/mPKCoYNwsoU/m/OSVy4gbCWwMJ
速く書くのはいいけど... • メモリパーティションは揮発性ストレージ上で動作 • 突然のクラッシュに対応したい
Write Ahead Log (WAL) • 書き込みに先行して操作ログをディスクへ書き込む • リカバリ可能な形式で、なるべく小さくエンコード
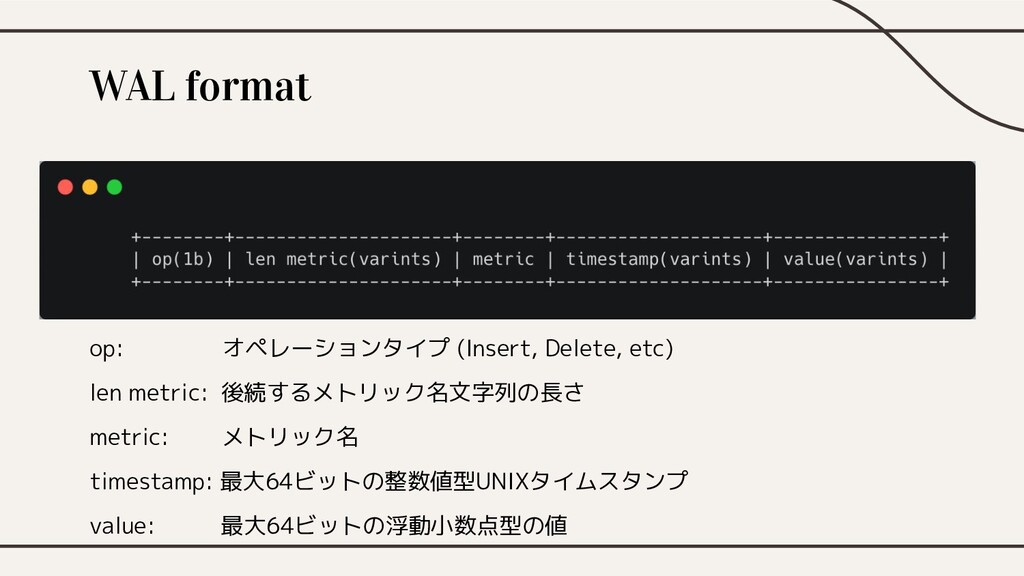
WAL format op: オペレーションタイプ (Insert, Delete, etc) len metric: 後続するメトリック名文字列の長さ
metric: メトリック名 timestamp: 最大64ビットの整数値型UNIXタイムスタンプ value: 最大64ビットの浮動小数点型の値
WAL format op: オペレーションタイプ (Insert, Delete, etc) len metric: 後続するメトリック名文字列の長さ
metric: メトリック名 timestamp: 最大64ビットの整数値型UNIXタイムスタンプ value: 最大64ビットの浮動小数点型の値
Varints (Variable integers) • Protocol Bufferが内部で使用している可変長エンコーディン グ手法 • 数値の大きさに応じて消費サイズが変わる •
Goでは binary.PutVarint が担当
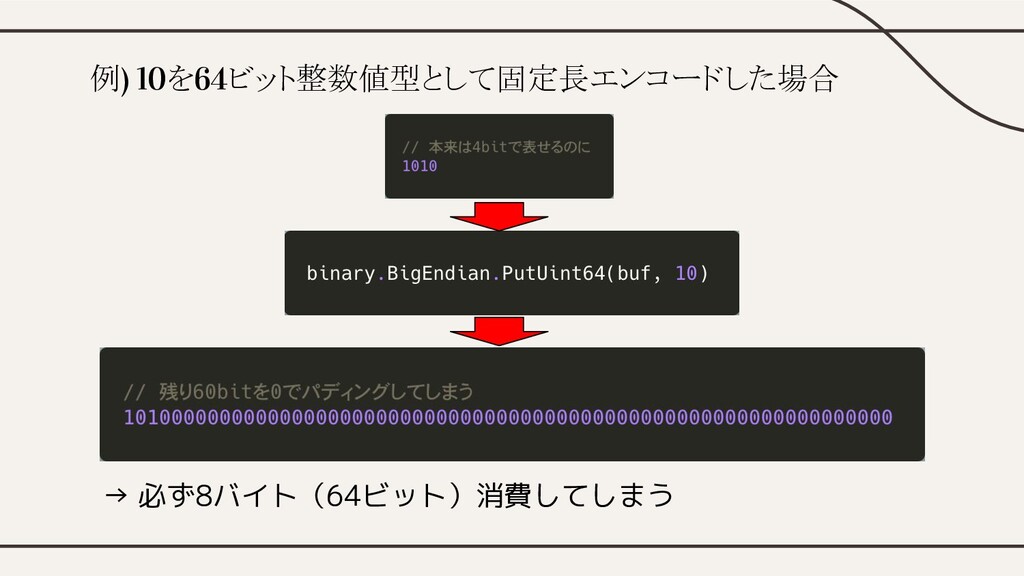
例) 10を64ビット整数値型として固定長エンコードした場合 → 必ず8バイト(64ビット)消費してしまう
例) Varintsで可変長エンコードした場合 → 1バイト(8ビット)で収まる
適切な位置で読み出しを終了 どのように終了位置を特定しているのか?
Varints の仕組み 先頭ビットが0であればそのバイトで読み出しを停止する
Varints (Variable integers) 数値型の値に関してはこのように Varints を用いて書き込んでいく
実装 ~ Disk Partition 04
Disk Partition • オンディスクDB • 1つのファイルに書き込ま れる
File format • 時系列データは不変で、範囲指定 して一括で読み込むケースがほと んど • Metric 毎にデータポイントをまと めて圧縮することで局所性↑
• mmapによって透過的にキャッ シュ
Memory-mapped data • マップされたファイルは []byte としてアクセス可能 • なんらかのインデックス構造がないと非効率
Metadata file • パーティション毎にjson形式の メタデータファイル • メトリック毎のファイル内バイ トオフセットやサイズが保存さ れている •
ヒープに乗るのはこのメタデー タのみ
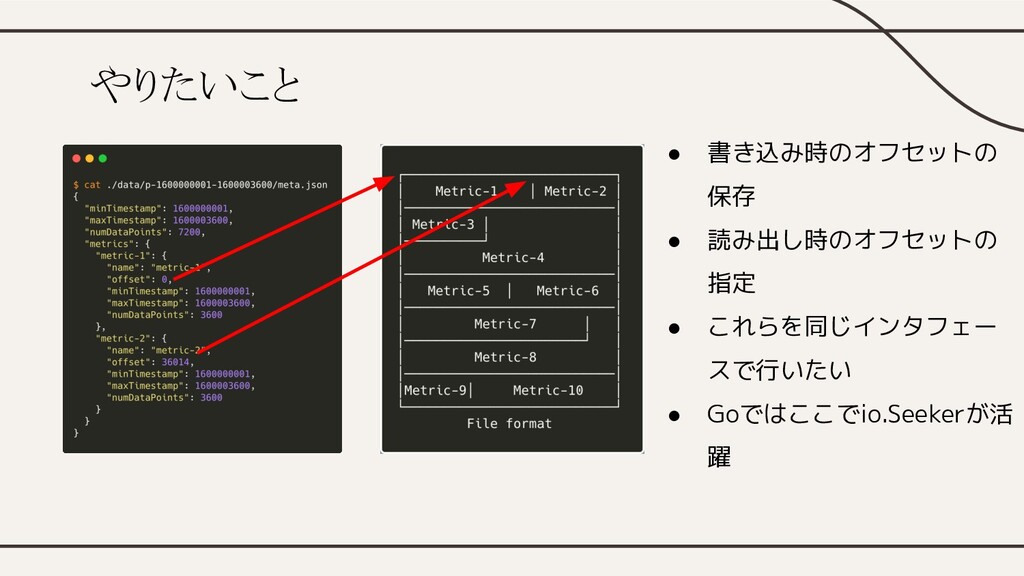
やりたいこと • 書き込み時のオフセットの 保存 • 読み出し時のオフセットの 指定 • これらを同じインタフェー スで行いたい
• Goではここでio.Seekerが活 躍
io.Seeker • 次に読み書きする位置を指定する • 現在のオフセットを返してくれるの で、取得も指定もこれ一つで可能 • ランダムアクセスを許容するバイト 列であれば基本何でもOK
When flushing • ディスクへ書き込む際に各メトリッ クのオフセットを保存する必要 • io.Seekerを満たす *os.File を利用 •
メトリックの書き込みを開始するタ イミングでSeek(0, io.SeekCurrent) を呼ぶ
When reading • []byte の指定したオフセットから読 み出したい • io.ReadSeekerを満たす *bytes.Reader を利用
高速に読み出せるようになっ たけど...
(再掲)データ量が膨大 • Varintsでもかなり圧縮されるが、最低でも1バイト必要 • 時系列データの特徴に注目して1バイト未満に圧縮できないか
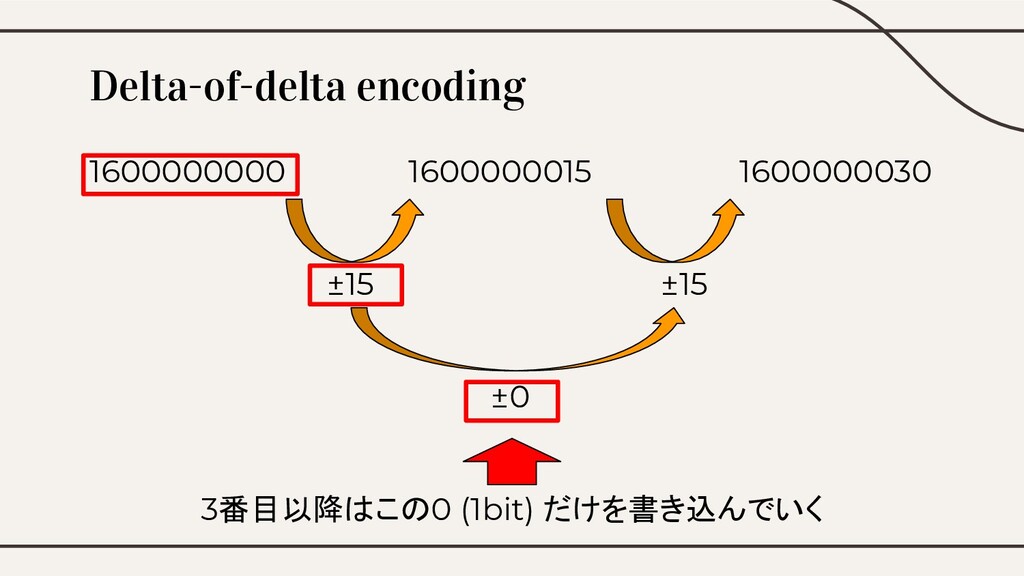
Encoding • タイムスタンプは単調増加する傾向にある • 差分の差分だけ書き込めば良いのでは? • → Delta-of-delta encoding
Delta-of-delta encoding 1600000000 1600000015 1600000030
Delta-of-delta encoding 1600000000 1600000015 1600000030 ±15 ±15
Delta-of-delta encoding 1600000000 1600000015 1600000030 ±15 ±15 ±0
Delta-of-delta encoding 1600000000 1600000015 1600000030 ±15 ±15 ±0 3番目以降はこの0 (1bit)
だけを書き込んでいく
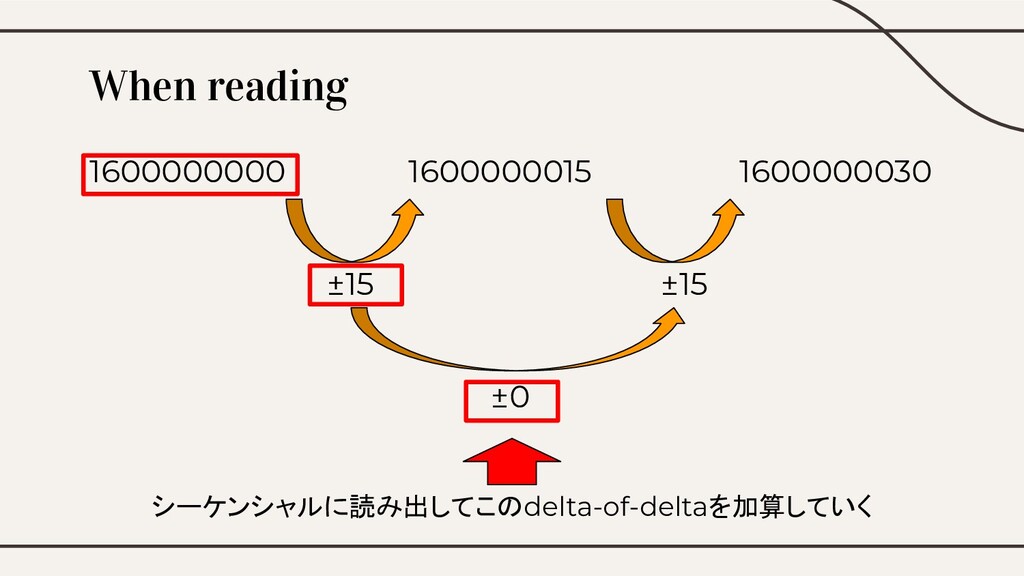
When reading 1600000000 1600000015 1600000030 ±15 ±15 ±0 シーケンシャルに読み出してこのdelta-of-deltaを加算していく
Bit単位でストリームに読み書きする • Goの標準ioパッケージの読み書き最小単位はbyte • bit単位で読み書きするためにはビット演算する必要
Bit単位でストリームに読み書きする 0001000 1 00010001 io.Writer.Write() byte完成!
Bit単位でストリームに読み書きする • bitはboolで表現
Bit単位でストリームに読み書きする
Bit単位でストリームに読み書きする • 0で敷き詰められた8bitsを 用意
Bit単位でストリームに読み書きする • 1を書き込む場合は末尾の0 と1のビット和を取る • そして必要な分だけ左シフ トする
負荷テストツールのパフォーマンスが改善
• (ja) ゼロから作る時系列データベースエンジン : https://zenn.dev/nakabonne/articles/d300838a1500c7 • (en) Write a time-series
database engine from scratch: https://nakabonne.dev/posts/write-tsdb-from-scratch • Repo: https://github.com/nakabonne/tstorage More...
Thanks Any questions? @nakabonne
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Memory-mapped data • マップされたファイルは []byte としてアクセス可能 • なんらかのインデックス構造がないと非効率](https://files.speakerdeck.com/presentations/38f615a590ea4a5f904ecda7f21dc36c/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![When reading • []byte の指定したオフセットから読 み出したい • io.ReadSeekerを満たす *bytes.Reader を利用](https://files.speakerdeck.com/presentations/38f615a590ea4a5f904ecda7f21dc36c/slide_49.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}