Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLM時代の基礎となるコンテキストエンジニアリング入門
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
oga_aiichiro
March 13, 2026
Technology
53
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLM時代の基礎となるコンテキストエンジニアリング入門
コンテキストについての理解を深めて、コンテキストエンジニアリングに入門しよう!
X: @oga_aiichiro
oga_aiichiro
March 13, 2026
More Decks by oga_aiichiro
See All by oga_aiichiro
AIがUIを作る時代に、フロントエンドエンジニアは何を設計するのか
nanaism
0
110
PJのドキュメントを全部Git管理にしたら、一番喜んだのはAIだった
nanaism
0
410
エンジニアとして長く走るために気づいた2つのこと_大賀愛一郎
nanaism
1
370
ローカルLLM × MCP連携で実現する、原文エビデンス付きドキュメントQAシステム
nanaism
0
120
Findy社のAgent活用成功要因と開発基盤の詳細分析
nanaism
0
120
Other Decks in Technology
See All in Technology
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
230
マルチアカウント環境でSecurity Hubの運用、その後どうなった? / SRE NEXT 2026 miniLT会
genda
0
100
公式ドキュメントの歩き方etc
coco_se
1
120
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
320
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
290
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
2
130
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
220
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
550
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
160
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
1
390
世界、断片、モデル。そして理解
ardbeg1958
1
130
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
270
Featured
See All Featured
WCS-LA-2024
lcolladotor
0
710
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
Un-Boring Meetings
codingconduct
0
350
Google's AI Overviews - The New Search
badams
0
1.1k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Designing Powerful Visuals for Engaging Learning
tmiket
1
450
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
For a Future-Friendly Web
brad_frost
183
10k
Transcript
2 0 2 6 / 0 3 / 1 3
大 賀 愛 一 郎 ( @ o g a _ a i i c h i r o ) LLM時代の基礎となる コンテキストエンジニアリング入門
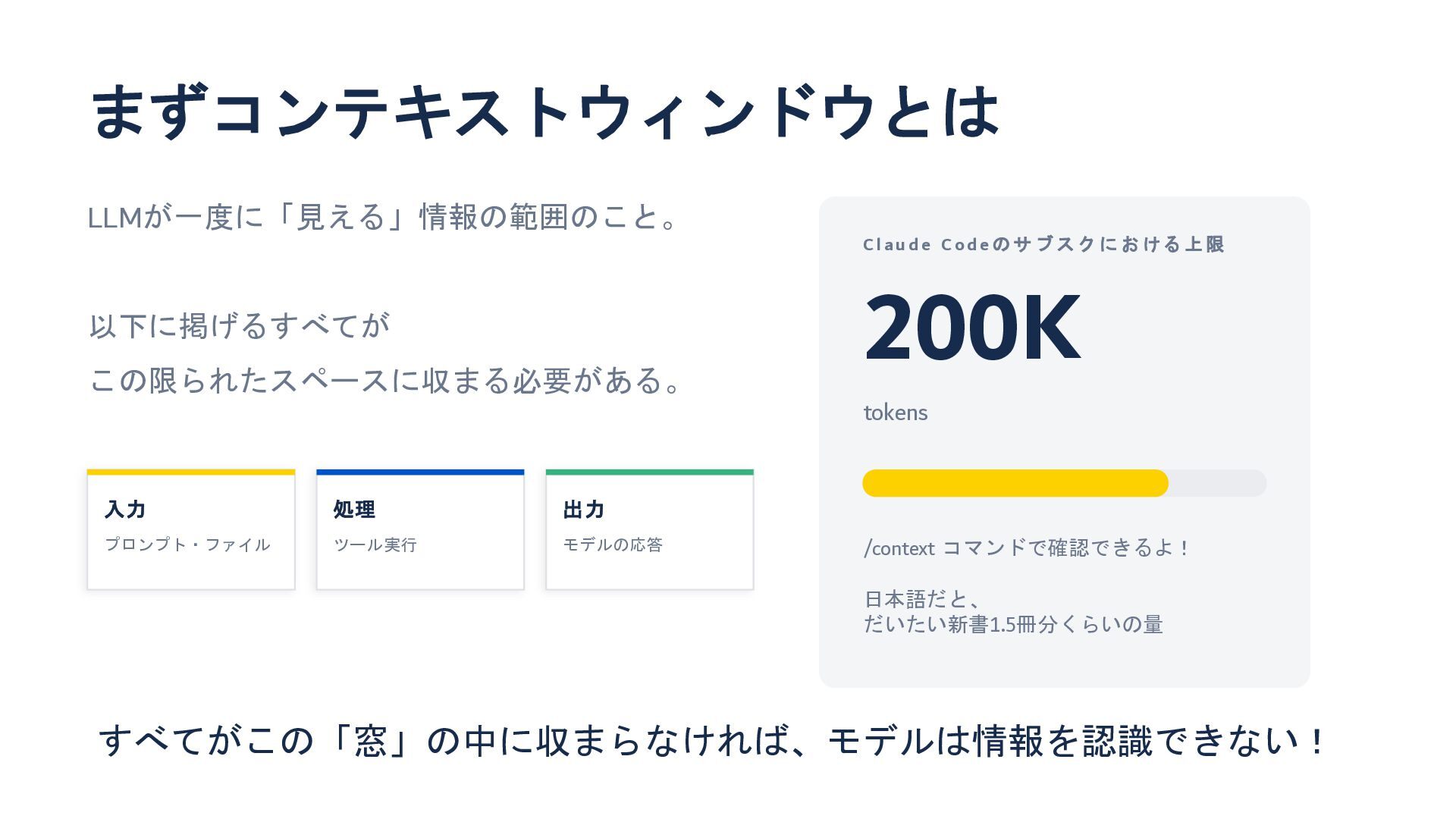
まずコンテキストウィンドウとは LLMが一度に「見える」情報の範囲のこと。 以下に掲げるすべてが この限られたスペースに収まる必要がある。 C l a u d e
C o d e の サ ブ ス ク に お け る 上 限 200K tokens /context コマンドで確認できるよ! 日本語だと、 だいたい新書1.5冊分くらいの量 入力 プロンプト・ファイル 処理 ツール実行 出力 モデルの応答 すべてがこの「窓」の中に収まらなければ、モデルは情報を認識できない!
「モデルはCPU、 コンテキストウィンドウはRAM」 ── Andrej Karpathy(OpenAI 創設メンバー) https://x.com/slow_developer/status/1808482202746834944 RAMに載っていないデータ → CPUが処理できない
= コンテキストにない情報 → LLMが使えない
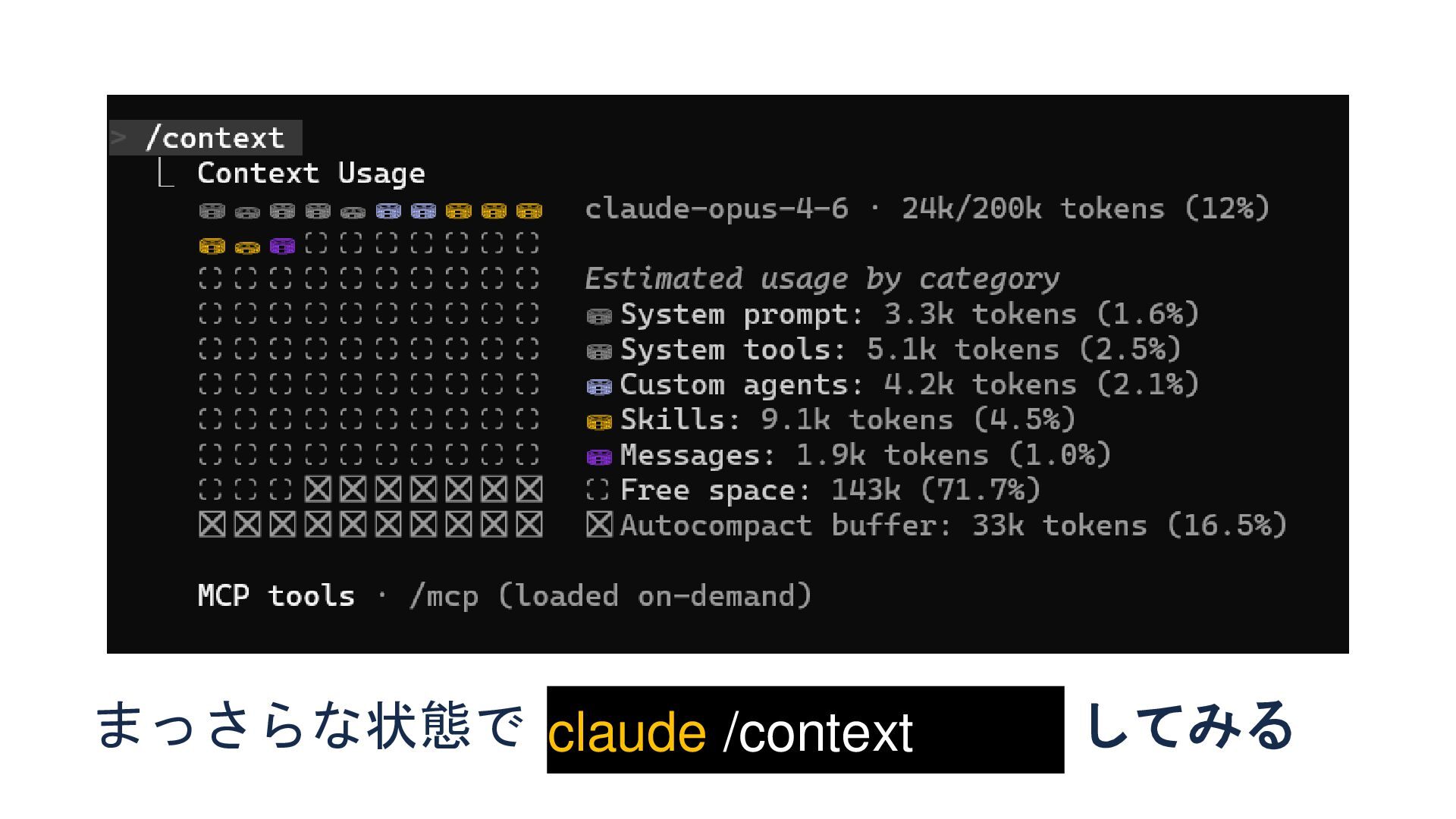
デモ みなさんもお手元で試してみてください
claude /context してみる まっさらな状態で
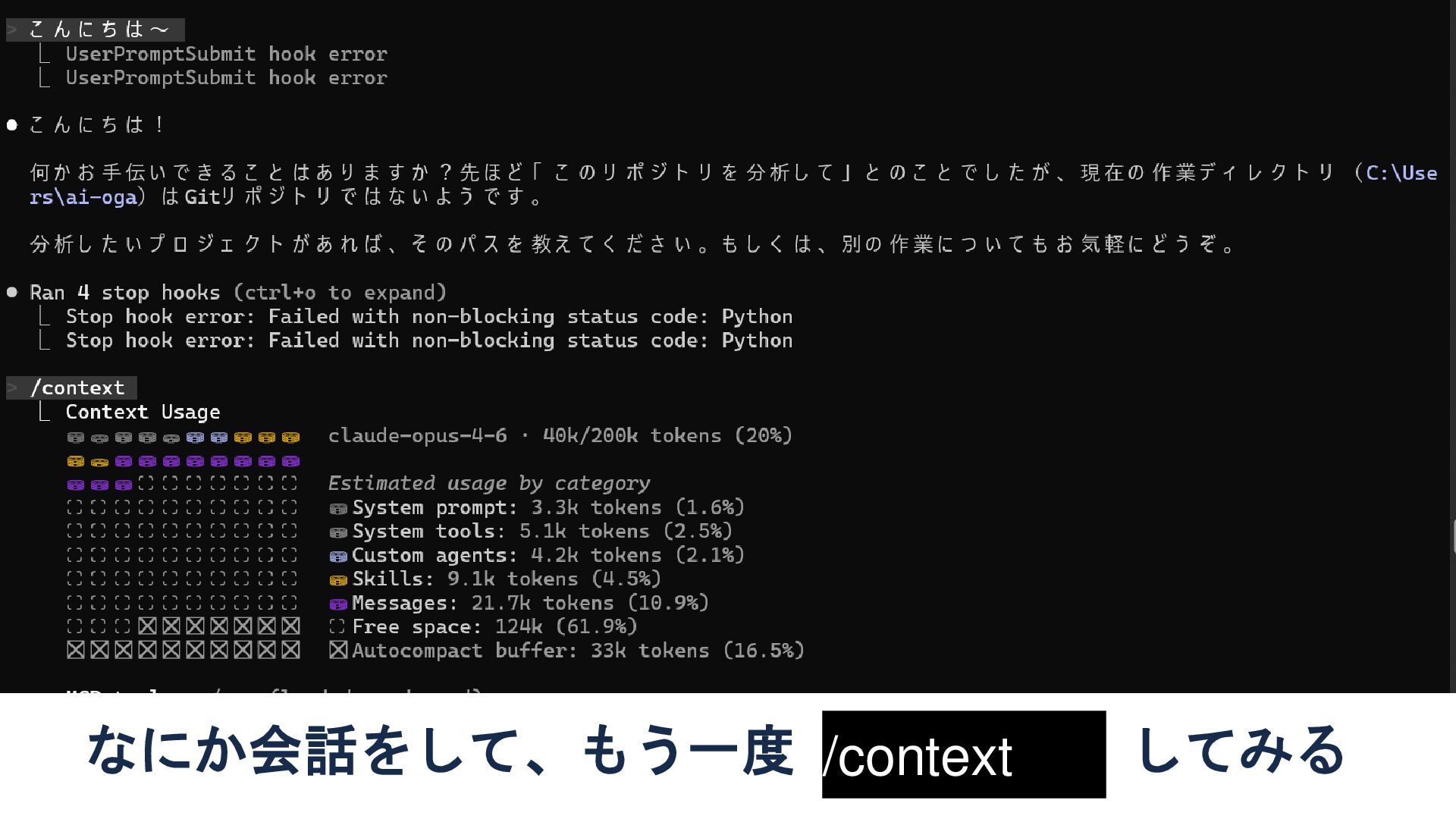
/context してみる なにか会話をして、もう一度
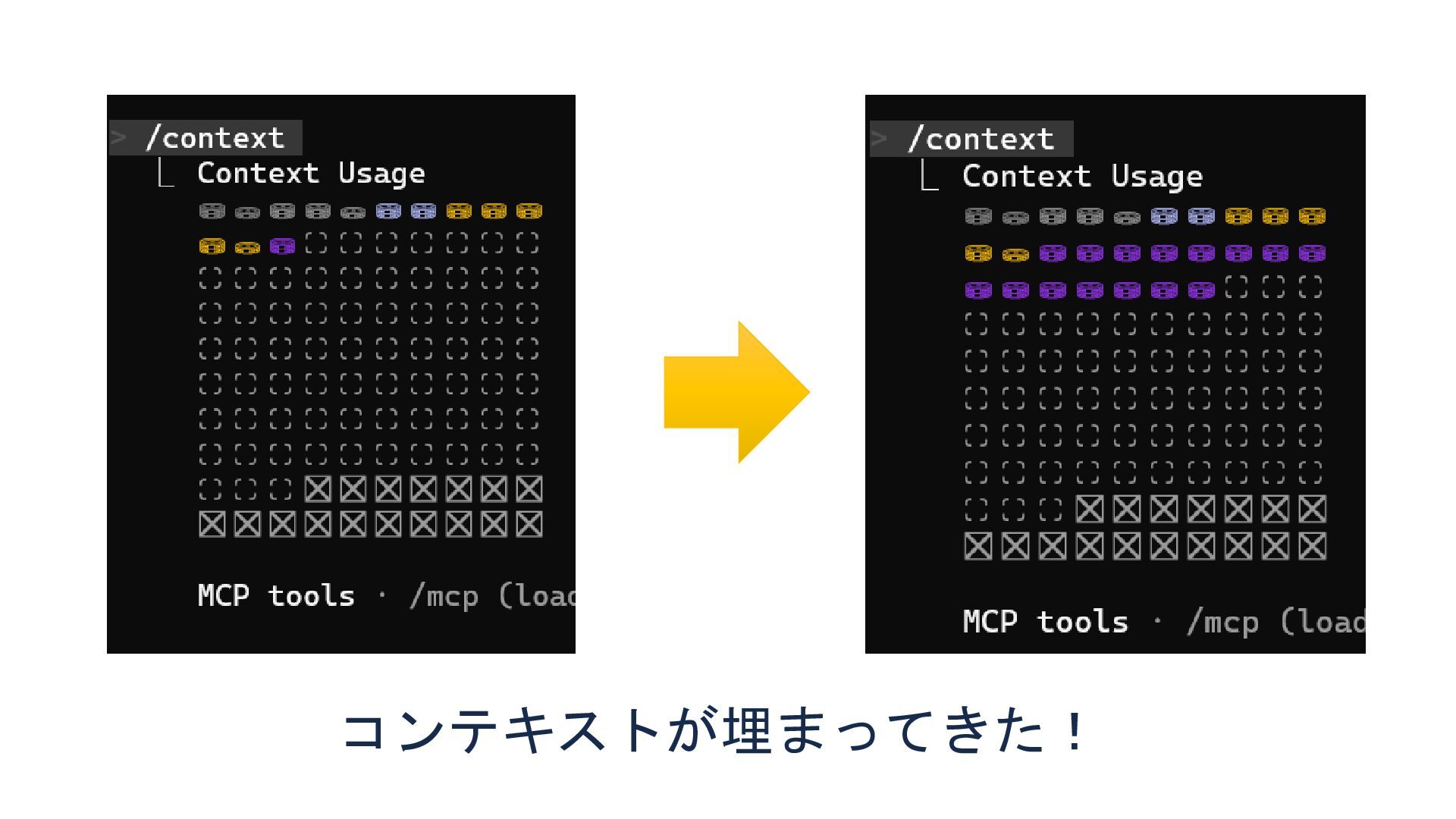
コンテキストが埋まってきた!
M E C H A N I S M LLMは毎ターン、雪だるま式に全履歴を再送信している
LLMには「記憶」がない。会話を続けるには、毎回すべてのやりとりを入力として送り直す必要がある。 1回目 System Q1 → A1 2回目 System Q1 A1 Q2 → A2 3回目 System Q1 A1 Q2 A2 Q3 → A3 4回目 System Q1 A1 Q2 A2 Q3 A3 Q4 → A4 5回目 System Q1 A1 Q2 A2 Q3 A3 Q4 A4 Q5 → A5 System Prompt 過去の質問 今回の質問 過去の応答 今回の応答
D E E P D I V E Context Windowの仕組み
200Kトークンの中で、何がどう配置されているのか
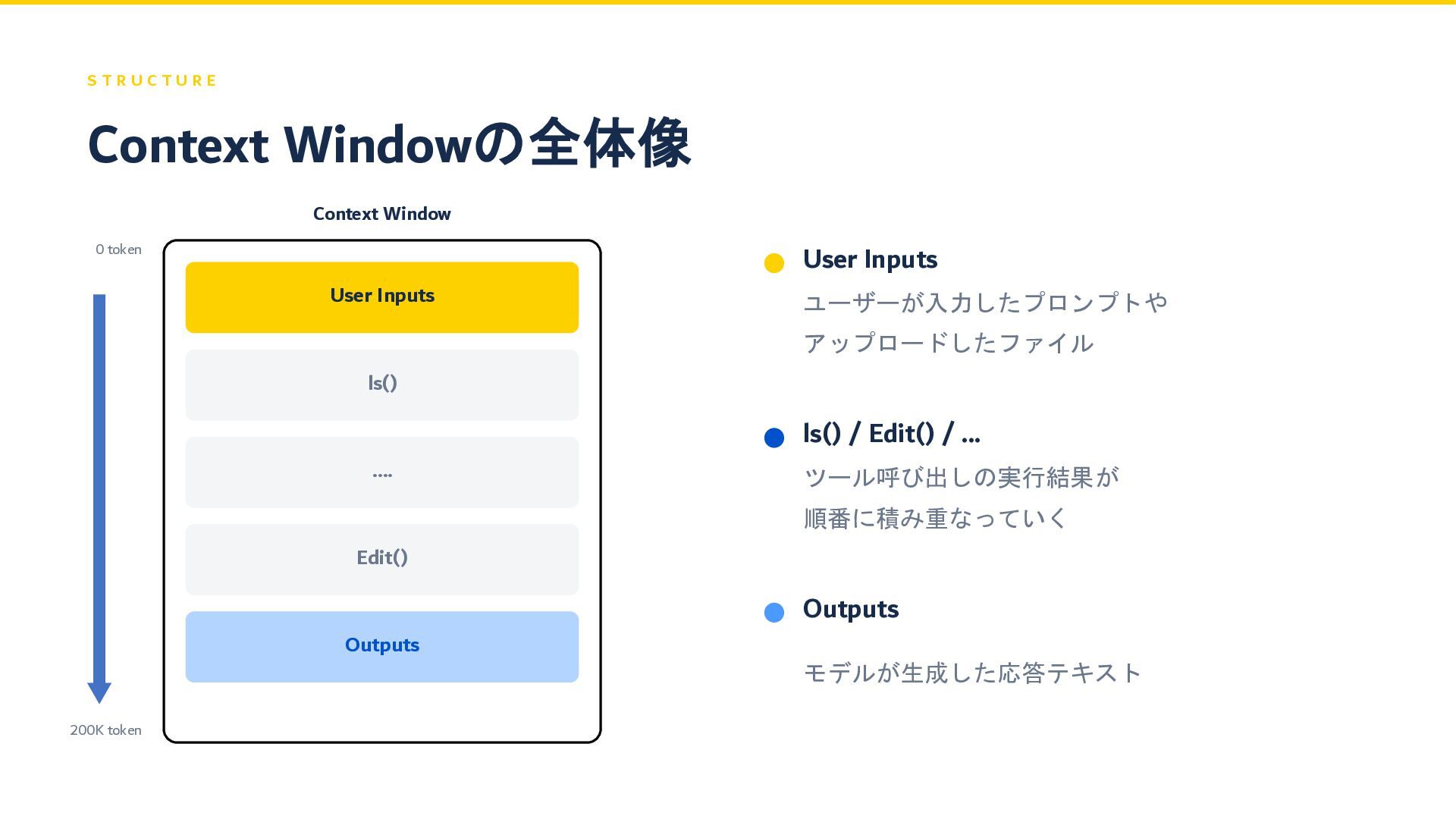
S T R U C T U R E Context
Windowの全体像 Context Window 0 token 200K token User Inputs ls() .... Edit() Outputs User Inputs ユーザーが入力したプロンプトや アップロードしたファイル ls() / Edit() / ... ツール呼び出しの実行結果が 順番に積み重なっていく Outputs モデルが生成した応答テキスト
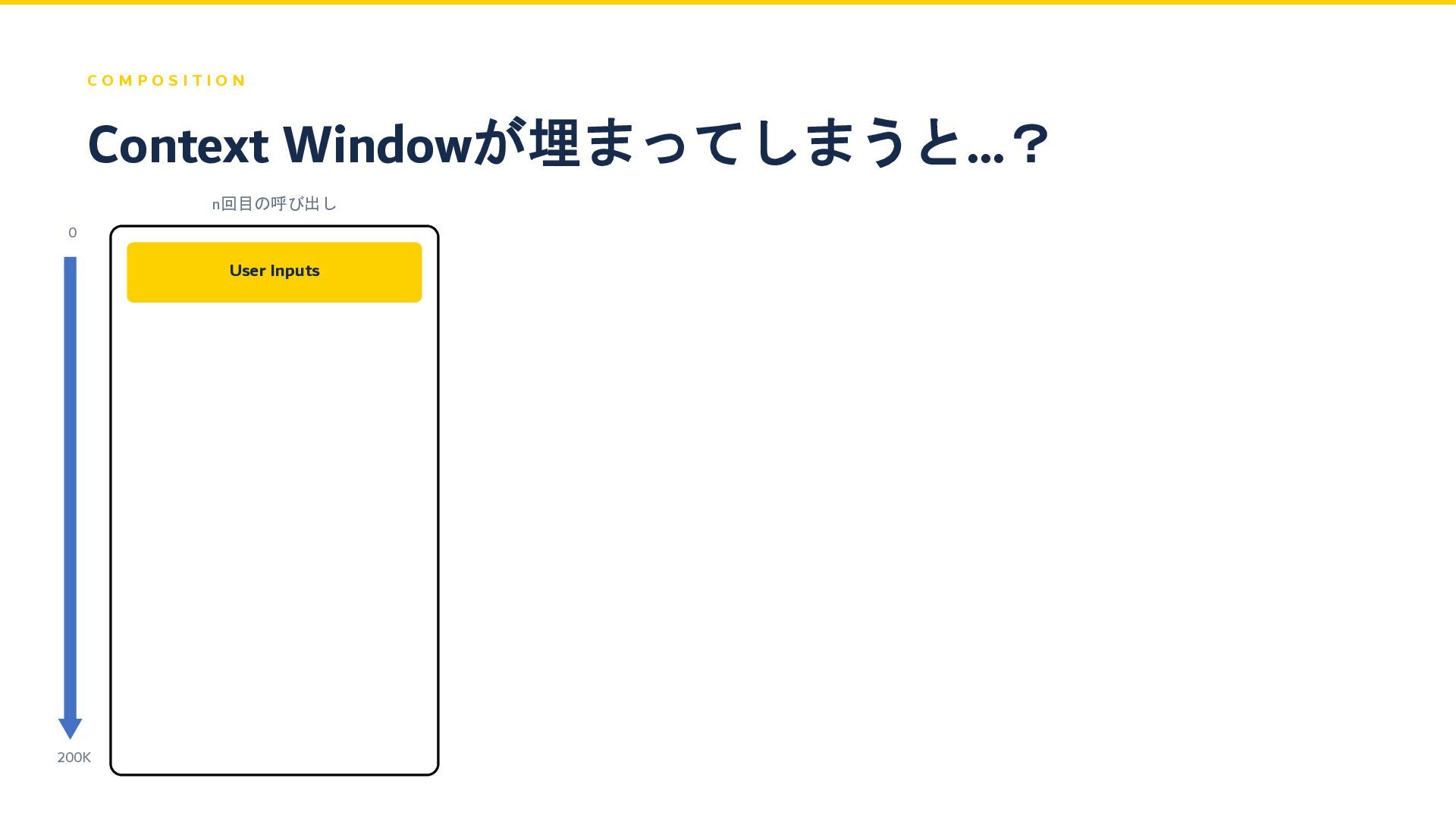
C O M P O S I T I O
N n回目の呼び出し Context Windowが埋まってしまうと…? User Inputs 0 200K
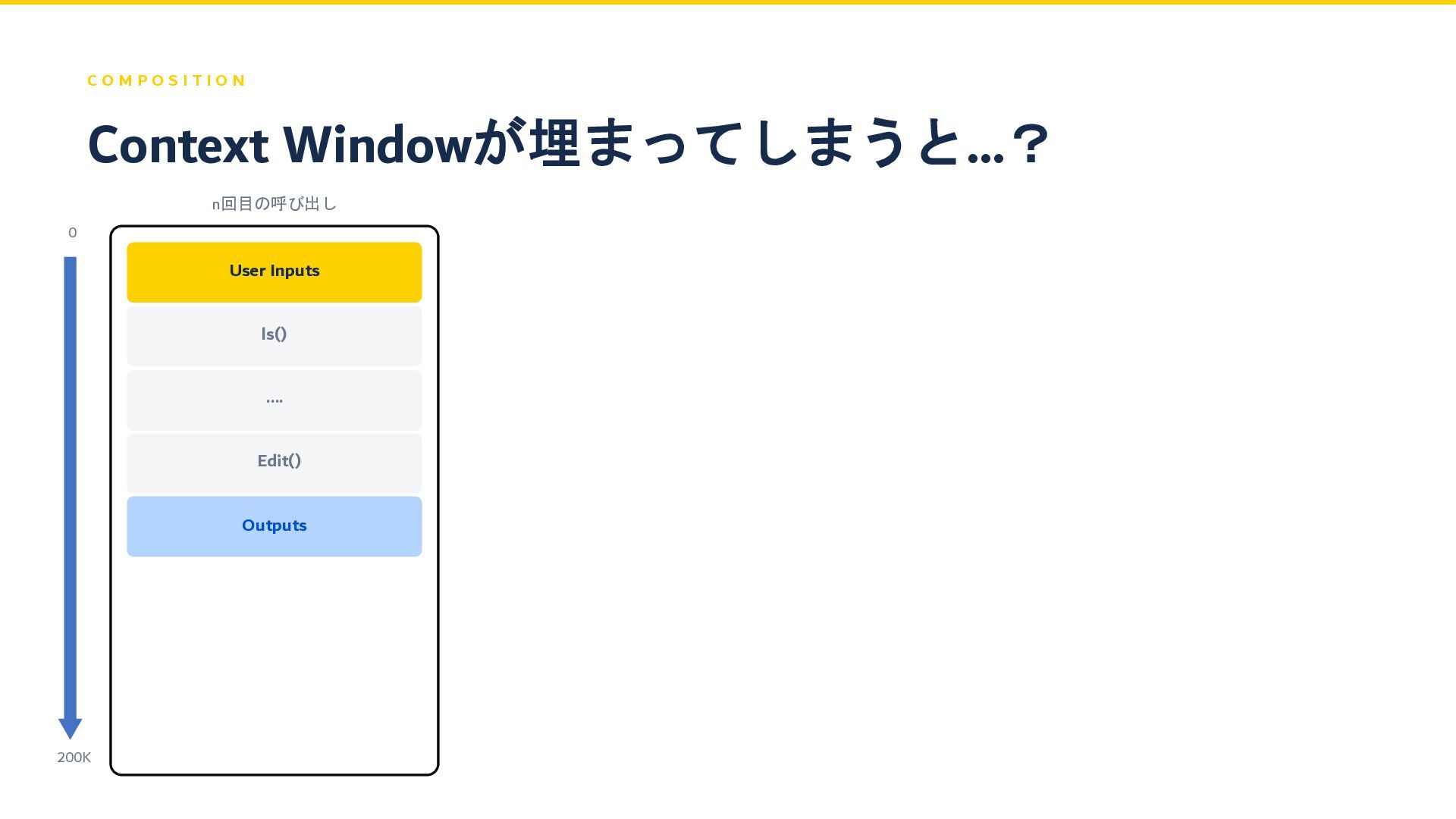
C O M P O S I T I O
N n回目の呼び出し 過去のInputs Context Windowが埋まってしまうと…? User Inputs ls() .... Edit() Outputs 0 200K
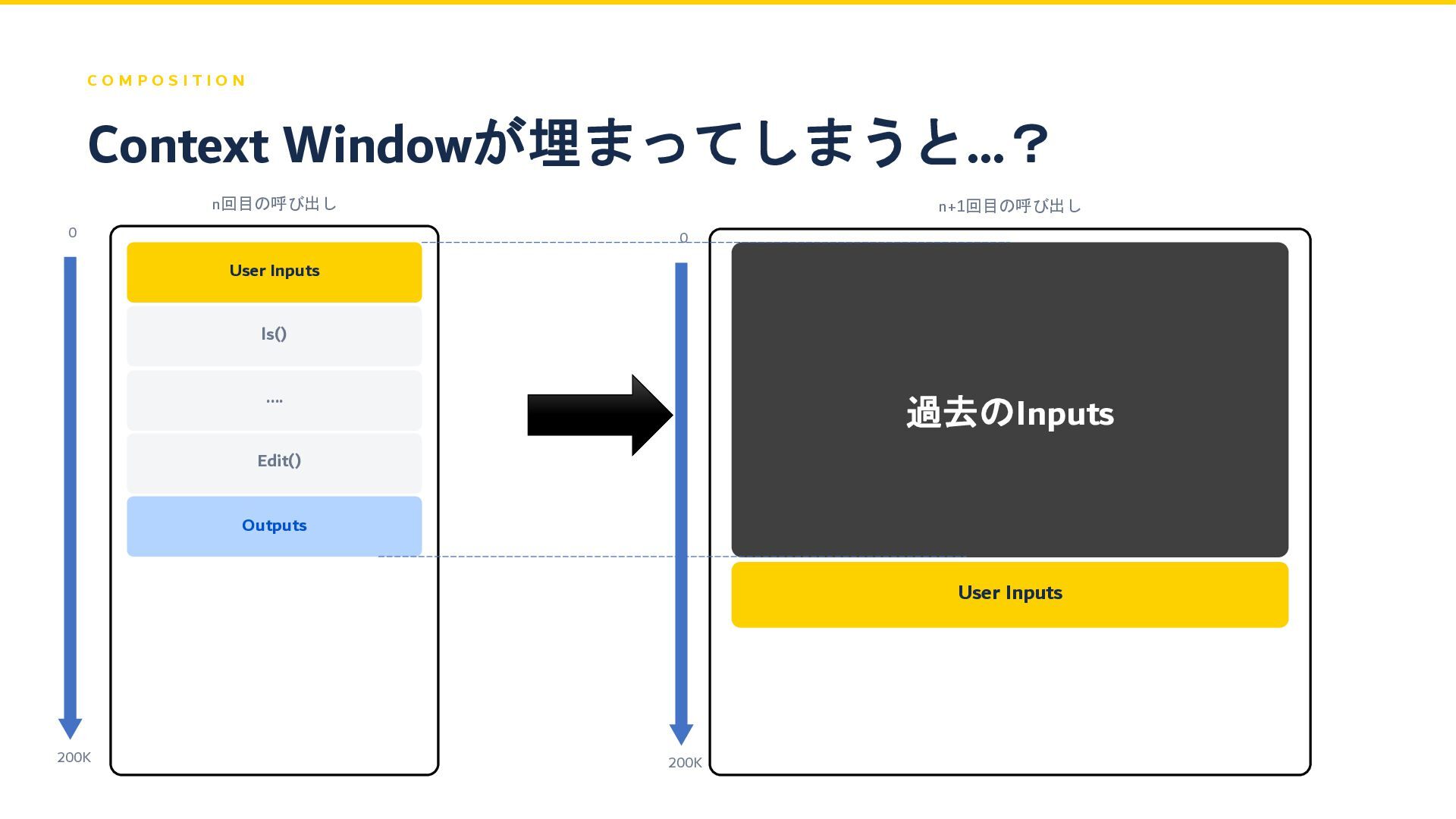
C O M P O S I T I O
N n回目の呼び出し User Inputs ls() .... Edit() Outputs n+1回目の呼び出し 過去のInputs Context Windowが埋まってしまうと…? User Inputs 0 200K 0 200K
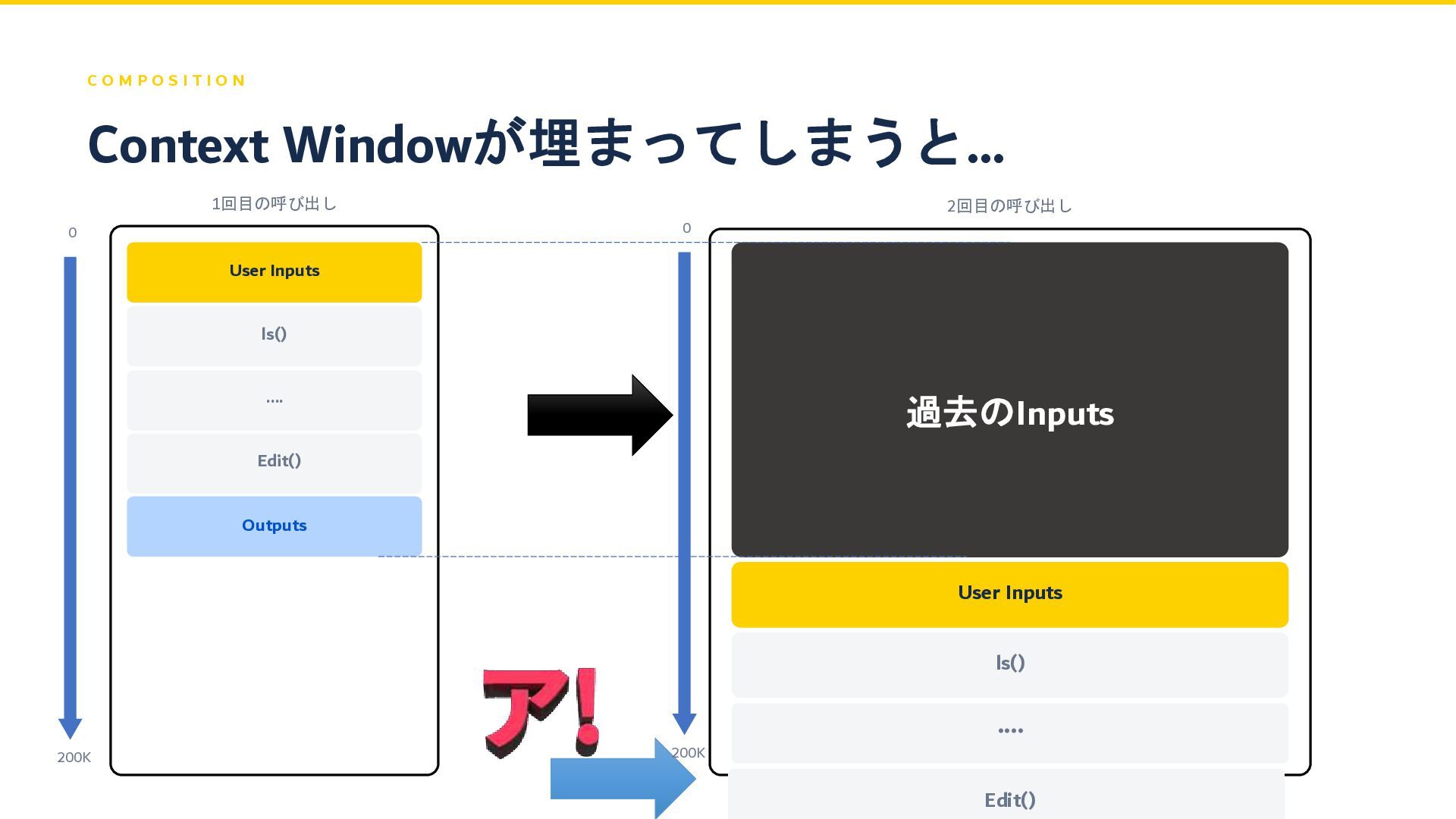
C O M P O S I T I O
N 1回目の呼び出し User Inputs ls() .... Edit() Outputs 2回目の呼び出し 過去のInputs Context Windowが埋まってしまうと… User Inputs ls() .... Edit() 0 200K 0 200K
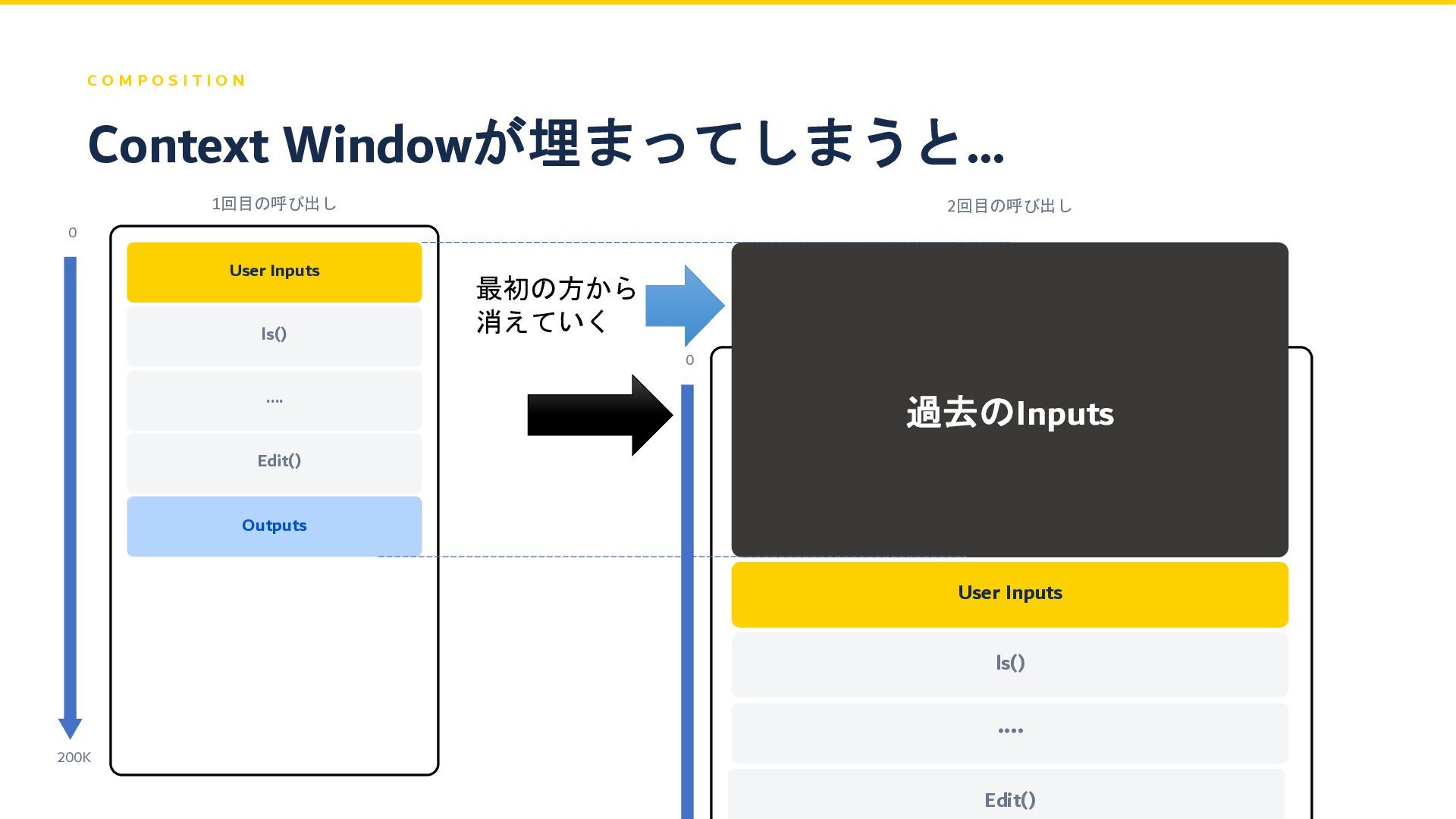
C O M P O S I T I O
N 1回目の呼び出し User Inputs ls() .... Edit() Outputs 2回目の呼び出し 過去のInputs Context Windowが埋まってしまうと… User Inputs ls() .... Edit() 最初の方から 消えていく 0 200K 0
多すぎたらダメな理由は他にもある 汚染 ハルシネーションが履歴に残り、 以降ずっと「事実」として参照され続ける 注意散漫 情報量が多すぎて、本当に重要な部分に 注意を向けられなくなる 混乱 タスクに関係ない情報が 回答に影響を与えてしまう
矛盾 コンテキスト内の情報同士が食い違い、 どちらを信じるか不安定になる 長いセッションで「途中からなんか頭悪くなってきたな」と感じる場合、 これらの問題が実際に起きている 10 / 18 R E A S O N
つまり、モデルを最新版に入れ替えるよりも、 コンテキストの質を上げるほうが 効果が大きい 同じモデルでも、コンテキストの渡し方を改善するだけで 劇的に信頼性が上がるケースが多い
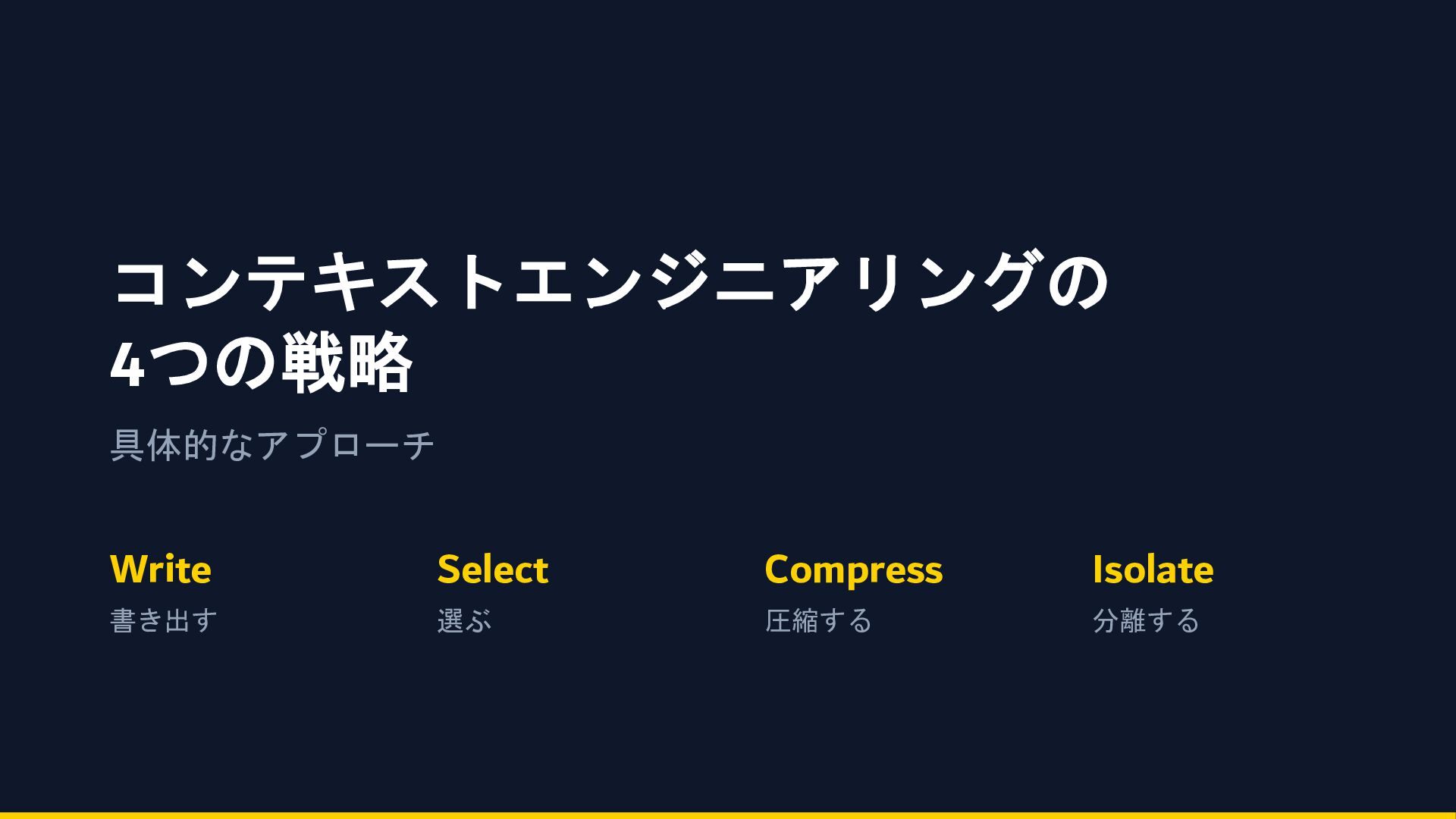
コンテキストエンジニアリングの 4つの戦略 具体的なアプローチ Write 書き出す Select 選ぶ Compress 圧縮する Isolate
分離する
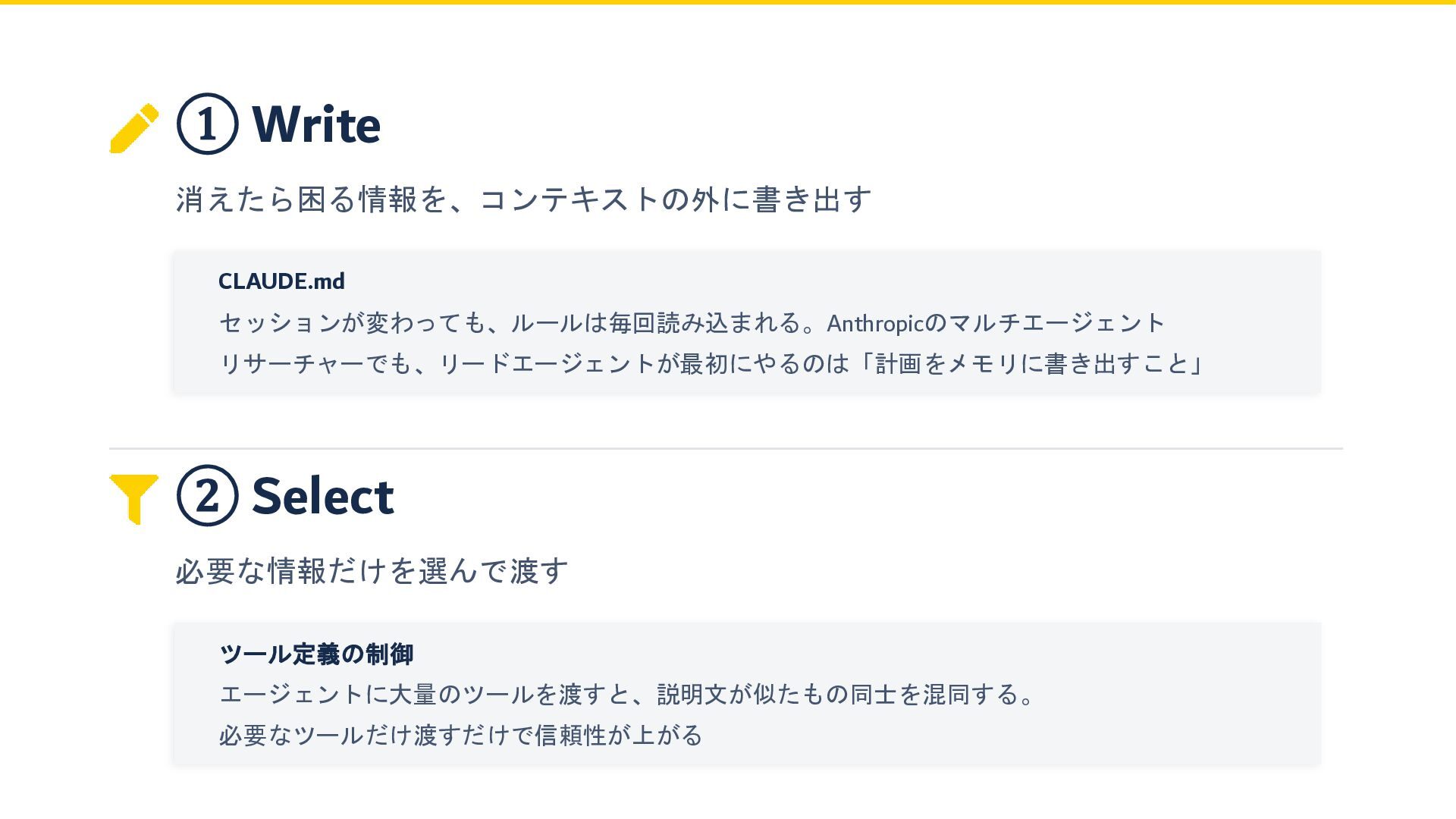
① Write 消えたら困る情報を、コンテキストの外に書き出す CLAUDE.md セッションが変わっても、ルールは毎回読み込まれる。Anthropicのマルチエージェント リサーチャーでも、リードエージェントが最初にやるのは「計画をメモリに書き出すこと」 ② Select 必要な情報だけを選んで渡す ツール定義の制御
エージェントに大量のツールを渡すと、説明文が似たもの同士を混同する。 必要なツールだけ渡すだけで信頼性が上がる
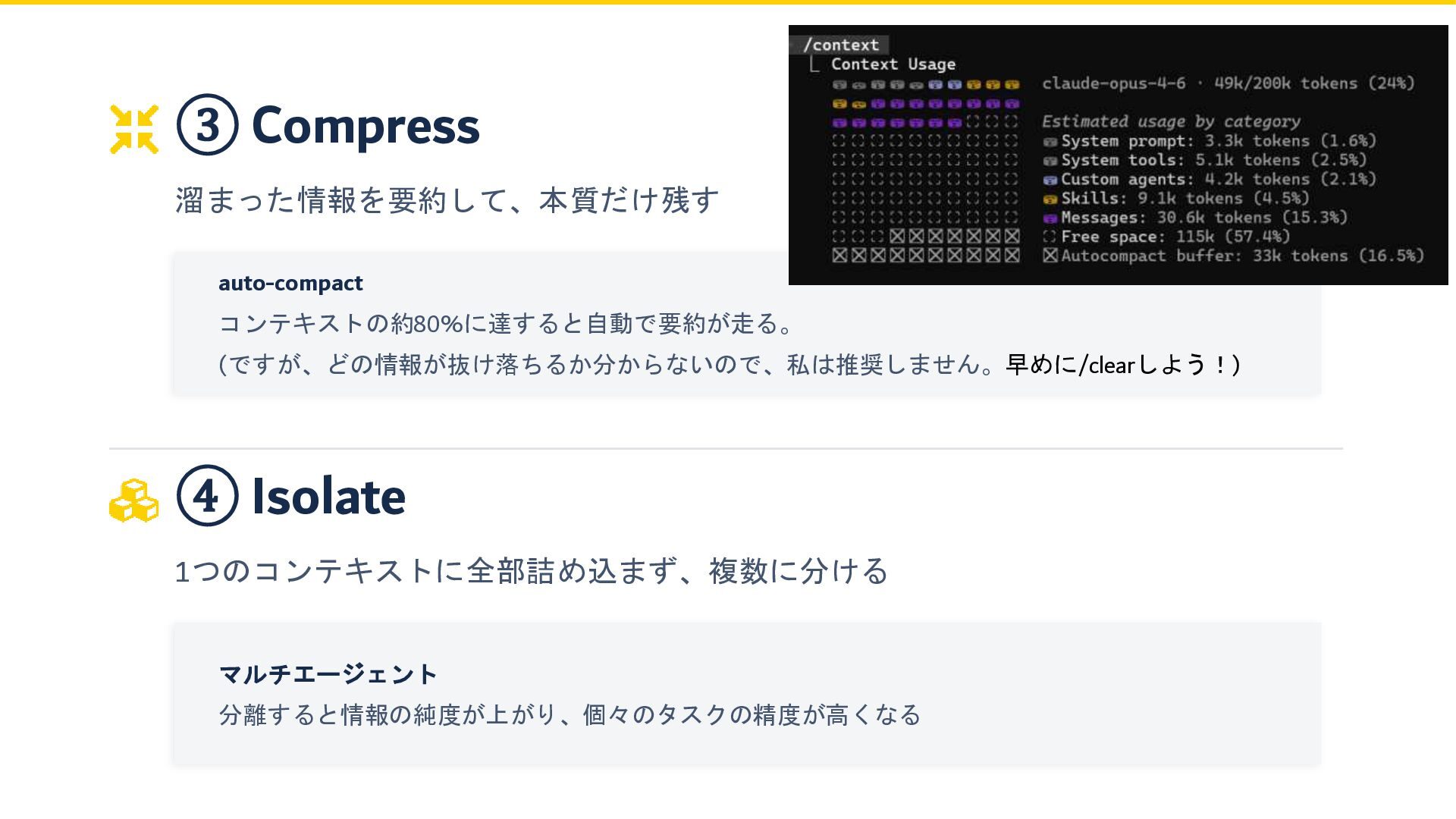
③ Compress 溜まった情報を要約して、本質だけ残す auto-compact コンテキストの約80%に達すると自動で要約が走る。 (ですが、どの情報が抜け落ちるか分からないので、私は推奨しません。早めに/clearしよう!) ④ Isolate 1つのコンテキストに全部詰め込まず、複数に分ける マルチエージェント
分離すると情報の純度が上がり、個々のタスクの精度が高くなる
結論 エージェントが失敗する本当の理由 「エージェントが失敗するとき、原因は2つ。 モデルの能力不足か、適切なコンテキストが渡されていないか。 そしてほとんどの場合、原因は後者だ」 ── LangChain Docs モデルの性能が足りないのではなく、「見せ方」が悪いだけ!
ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}