zero knowledge proof system,” in Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2023, pp. 340‒353. [2] B. Zhao, W. Huang, T. Li, and Y. Huang, “Bstmsm: A high-performance fpga-based multi-scalar multiplication hardware accelerator,” in 2023 International Conference on Field Programmable Technology (ICFPT). IEEE, 2023, pp. 35‒43. [3] K. Aasaraai, D. Beaver, E. Cesena, R. Maganti, N. Stalder, and J. Varela, “Fpga acceleration of multiscalar multiplication: Cyclonemsm,” Cryptology ePrint Archive, 2022. [4] J. Zhuang et al., “Charm: Composing heterogeneous accelerators for matrix multiply on versal acap architecture,” in Proceedings of the 2023 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, 2023, pp. 153‒164. [5] Z. Yang, J. Zhuang, J. Yin, C. Yu, A. K. Jones, and P. Zhou, “Aim: Accelerating arbitrary-precision integer multiplication on heterogeneous reconfigurable computing platform versal acap,” in 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 2023, pp. 1‒9. [6] H. Hisil, K. K.-H. Wong, G. Carter, and E. Dawson, “Twisted edwards curves revisited,” in International Conference on the Theory and Application of Cryptology and Information Security. Springer, 2008, pp. 326‒343. [7] M. Langhammer and B. Pasca, “Efficient fpga modular multiplication implementation,” in The 2021 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, 2021, pp. 217‒223. [8] GMP. The gnu mp bignum library. [Online] https://gmplib.org [9] Z. Ji, Z. Zhang, J. Xu, and L. Ju, “Accelerating multi-scalar multiplication for efficient zero knowledge proofs with multi-gpu systems,” in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2024, pp. 57‒70. 47
{kind=link}
{kind=link}
![Application • ゼロ知識証明 (ZKP): 命題が真実であることを、その情報‧根拠を明かさずに を証明する技術 • ZKPのproof generationにおいて、マルチスカラー倍算(MSM)は重い計算 [1]](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_2.jpg){kind=link}
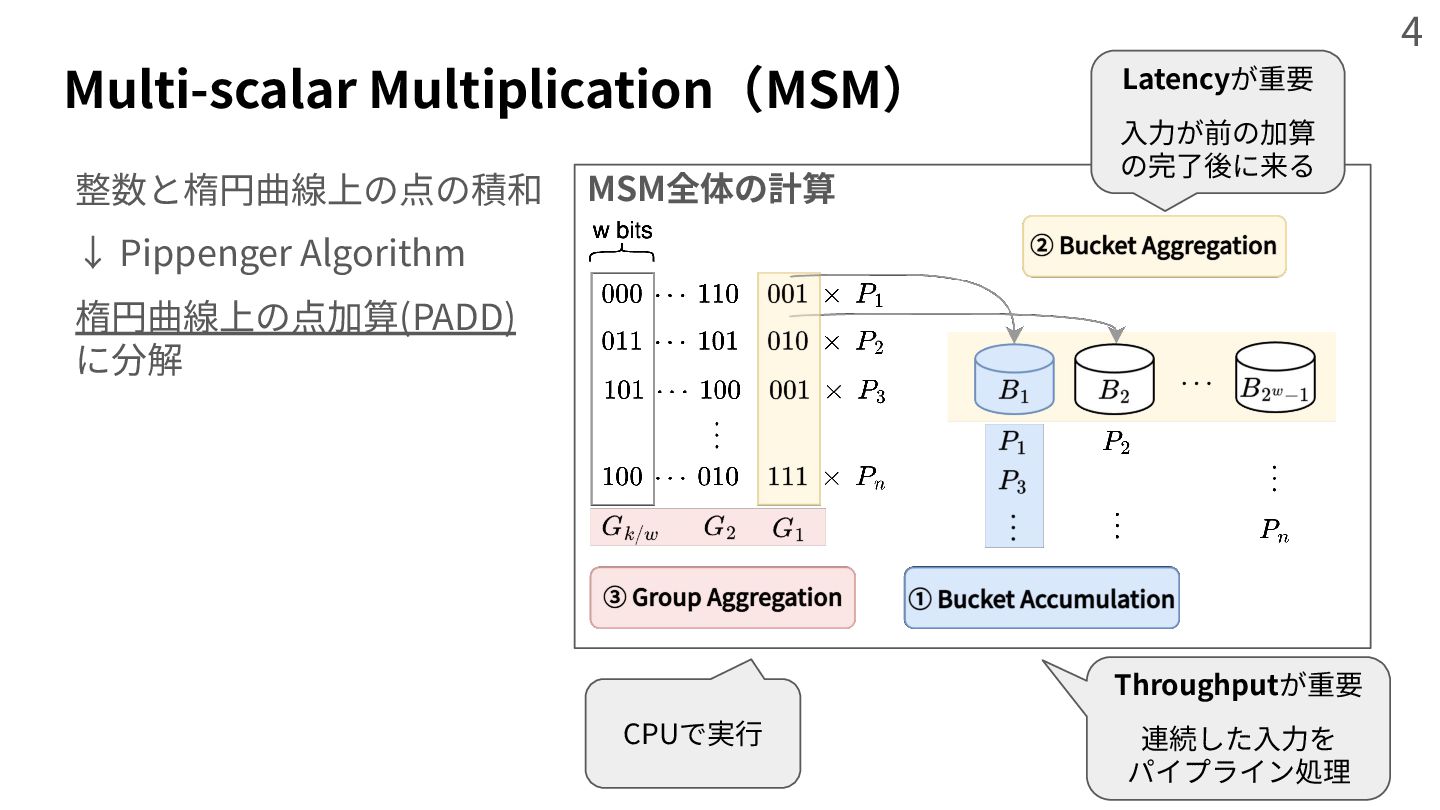{kind=link}
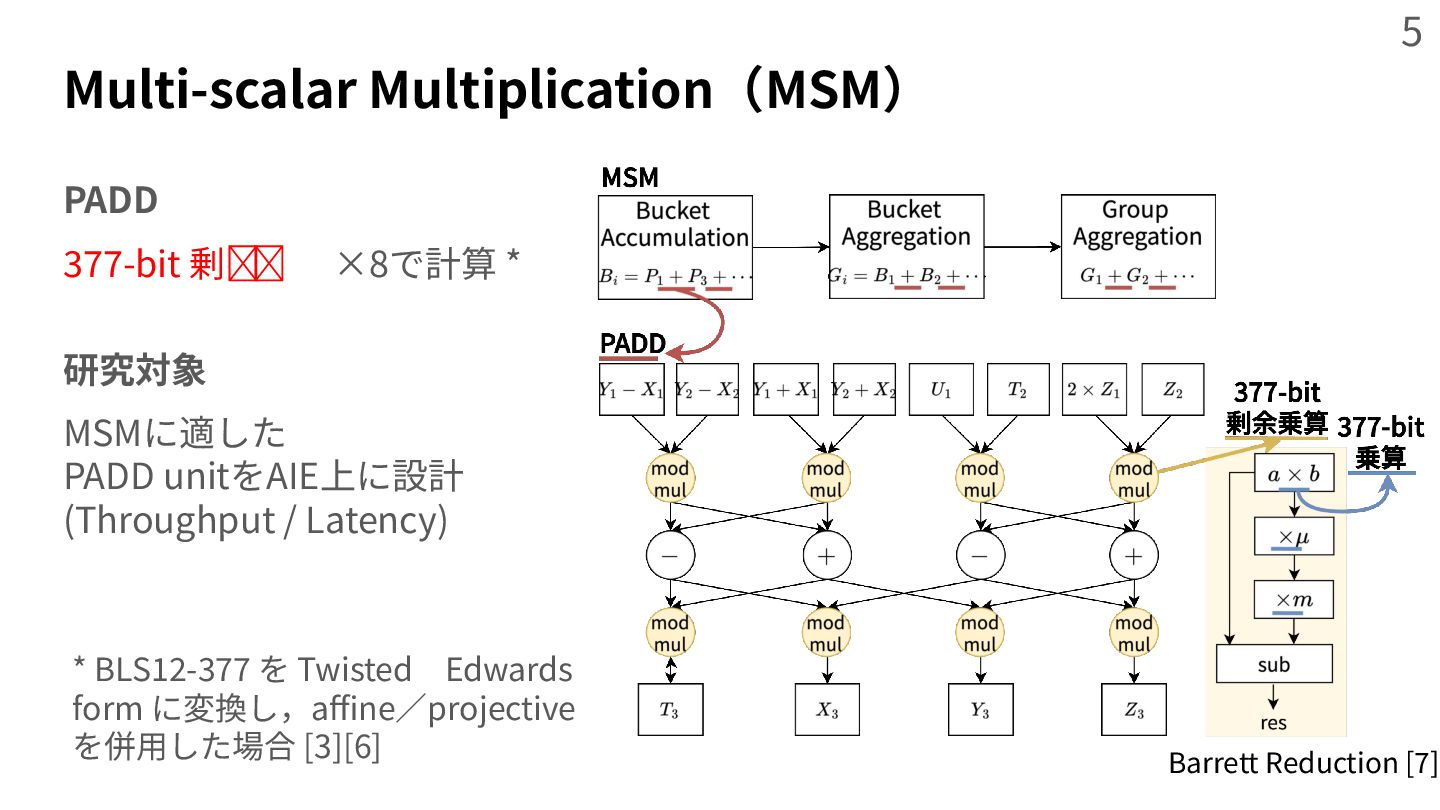{kind=link}
![Motivation 既存のMSMのAccelerator: GPU: 多数のコアに PADDを分散して高い並列性を実現 - ワークロードの偏り(bucket間の不均衡), エネルギー効率が課題 [1][9] FPGA:](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_5.jpg){kind=link}
{kind=link}
 基本演算(筆算) 8 ① v8acc80 += v16a[0:7] *](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_7.jpg){kind=link}
 全体構造 ‧筆算を分割してAIEに分配 ‧キャリー伝搬はPLで⾏う → 全桁の結果をPLに返す 問題点 ×](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_8.jpg){kind=link}
![Contribution 課題 A. Versal AI Engineの既存研究[4]は ⾏列積等の単純なアプリ B. 先⾏研究AIM[5]の乗算のままでは、 通信律速になる](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_9.jpg){kind=link}
{kind=link}
![AIEにおける剰余乗算の設計 12 377-bit筆算のブロック分割 剰余乗算 [7] (Barrett Reduction) 剰余乗算に筆算をマップ](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_11.jpg){kind=link}
![AIEにおける剰余乗算の設計 13 377-bit筆算のブロック分割 剰余乗算 [7] (Barrett Reduction) 剰余乗算に筆算をマップ](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_12.jpg){kind=link}
![14 INT32 MUL 377-bit筆算のブロック分割 剰余乗算 [7] (Barrett Reduction) AIEにおける剰余乗算の設計 剰余乗算に筆算をマップ](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_13.jpg){kind=link}
![15 INT32 MUL MUL in SIMD 377-bit筆算のブロック分割 剰余乗算 [7] (Barrett](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_14.jpg){kind=link}
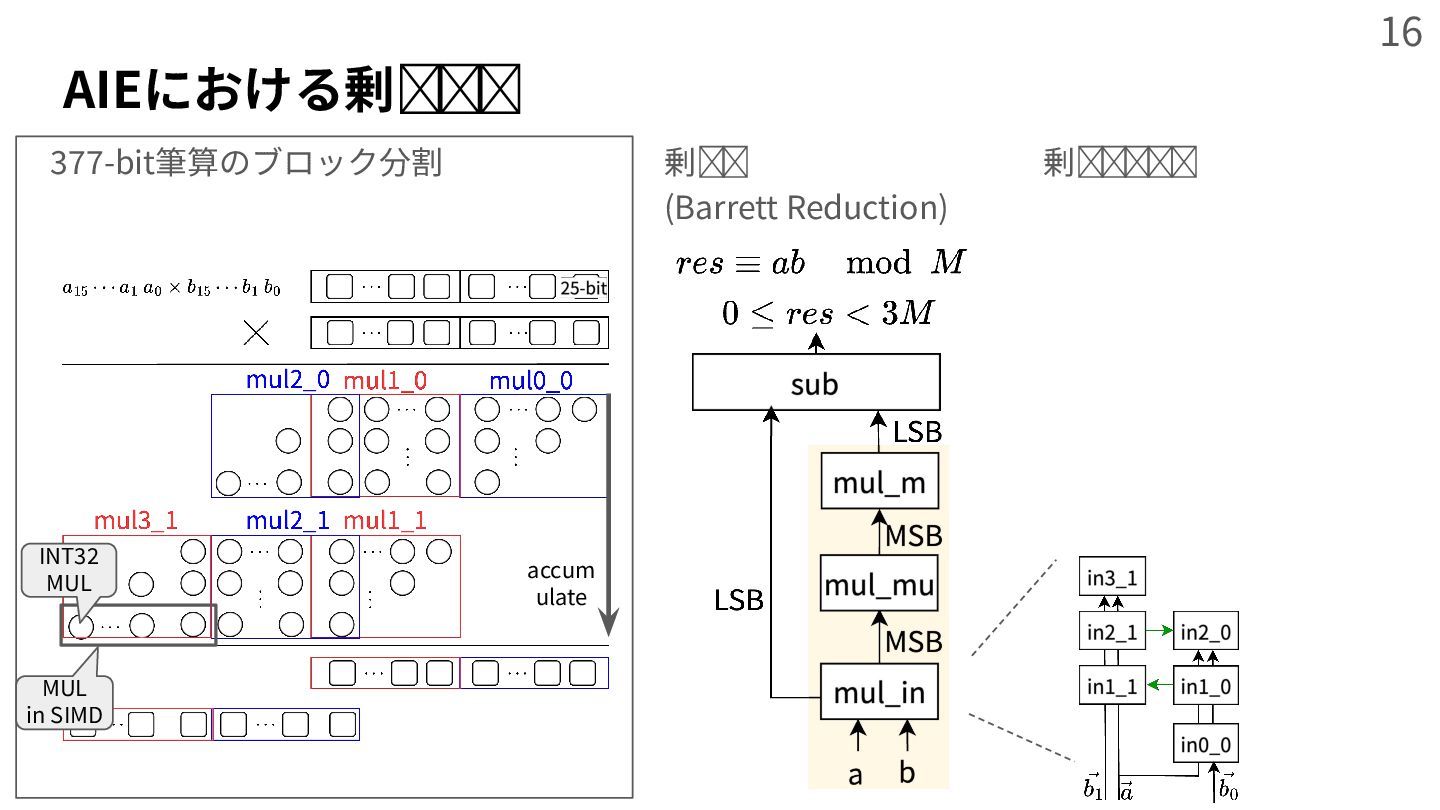{kind=link}
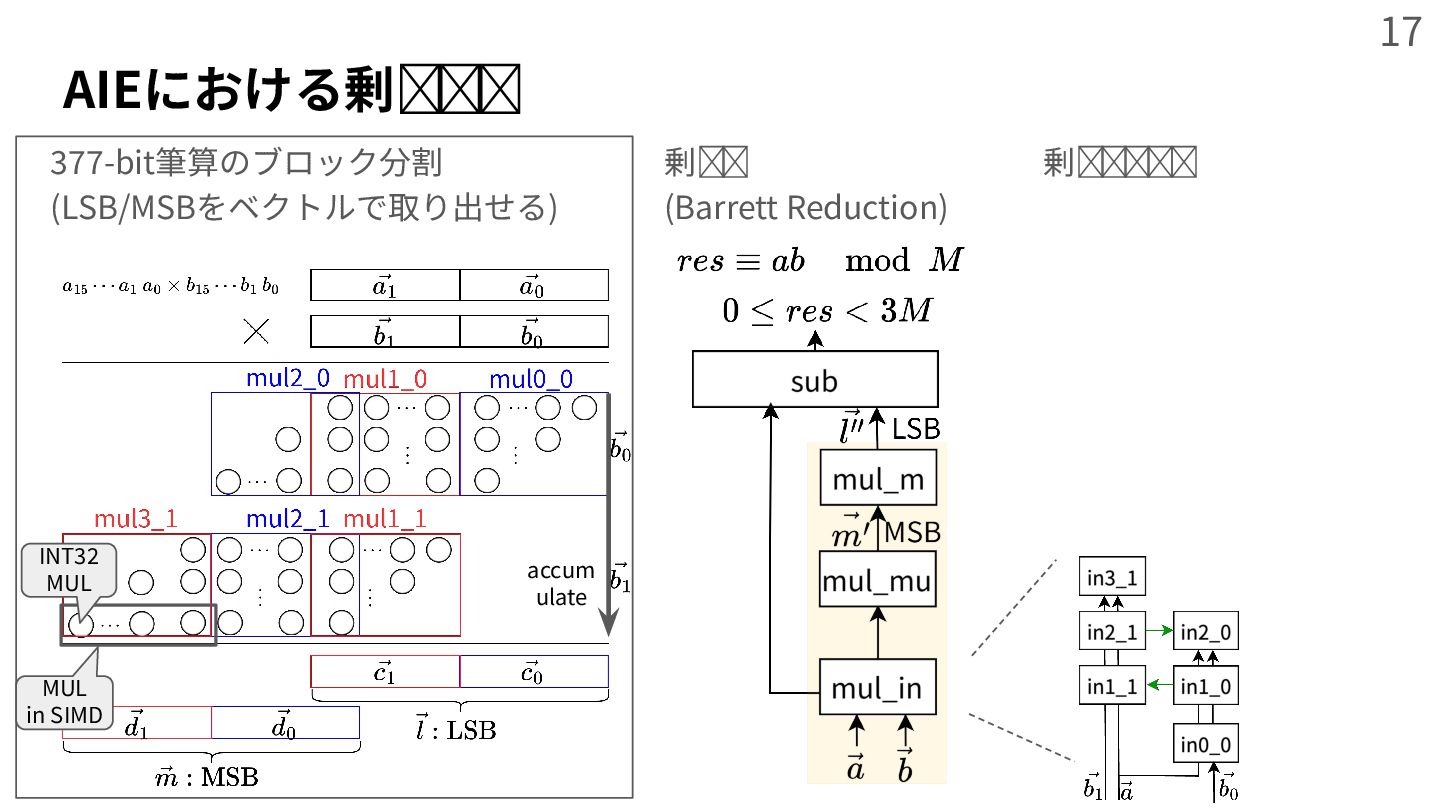{kind=link}
![18 右90°回転 accum ulate 377-bit筆算のブロック分割 (LSB/MSBをベクトルで取り出せる) 剰余乗算 [7] (Barrett Reduction)](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_17.jpg){kind=link}
![19 剰余乗算に筆算をマップ accum ulate 377-bit筆算のブロック分割 (LSB/MSBをベクトルで取り出せる) 剰余乗算 [7] (Barrett Reduction)](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_18.jpg){kind=link}
{kind=link}
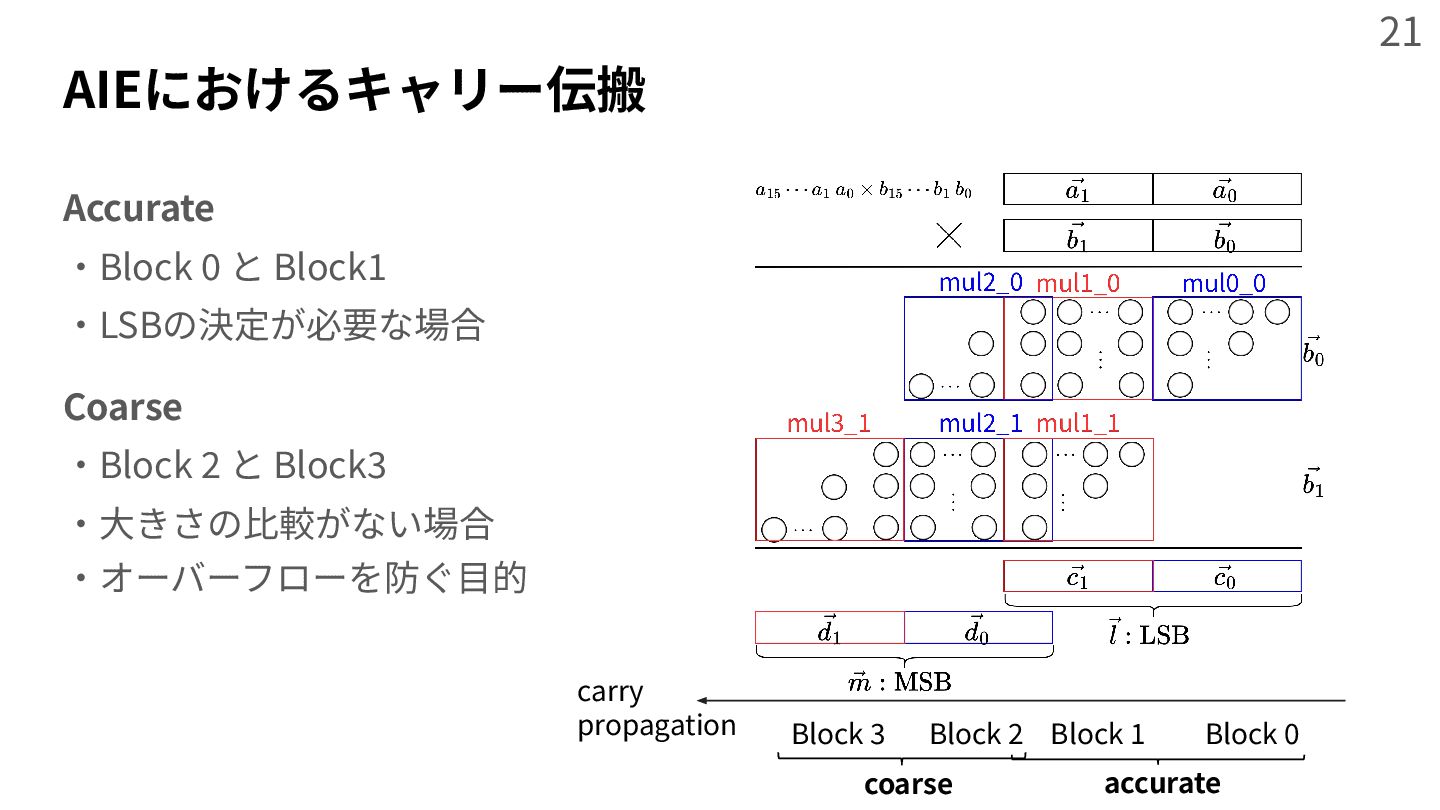{kind=link}
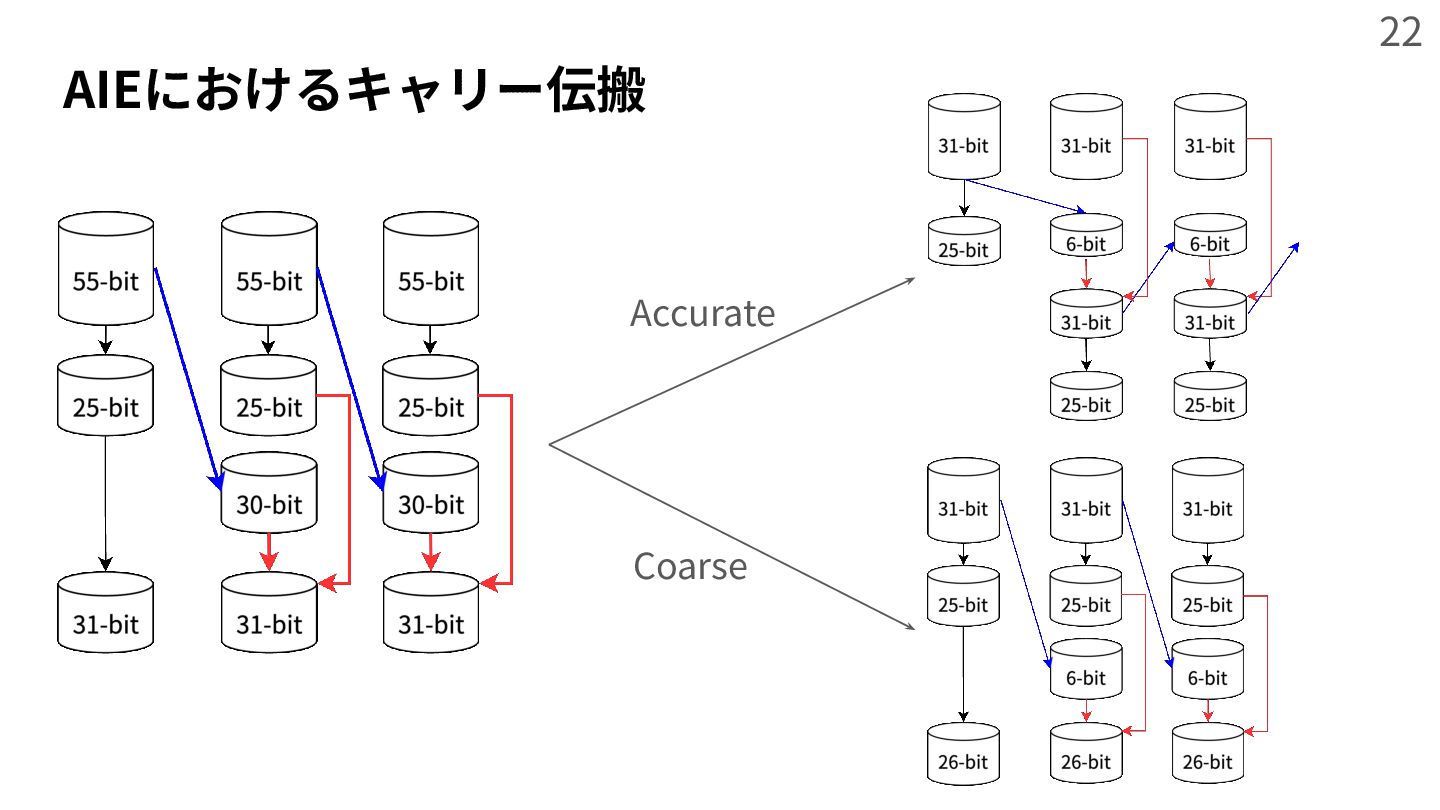{kind=link}
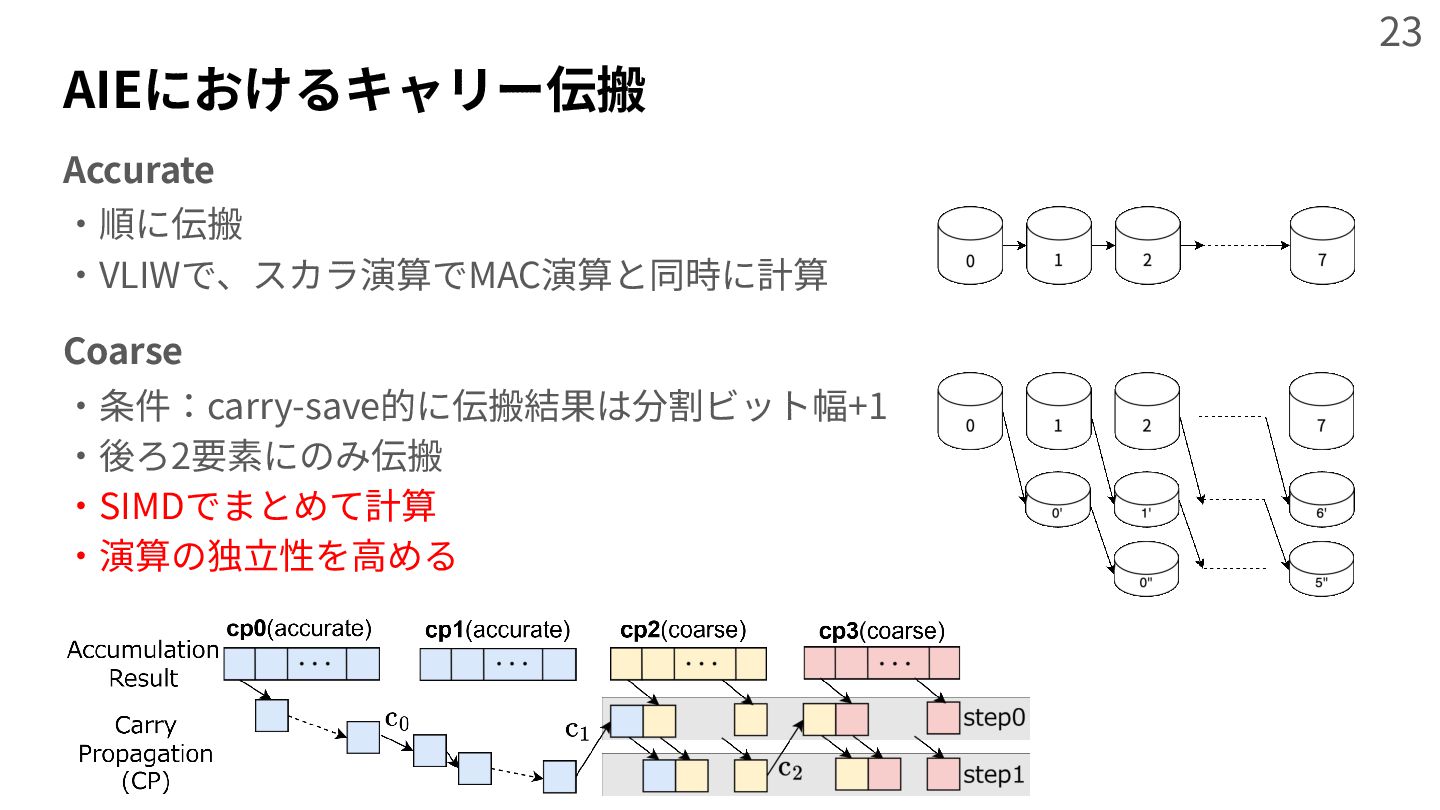{kind=link}
{kind=link}
{kind=link}
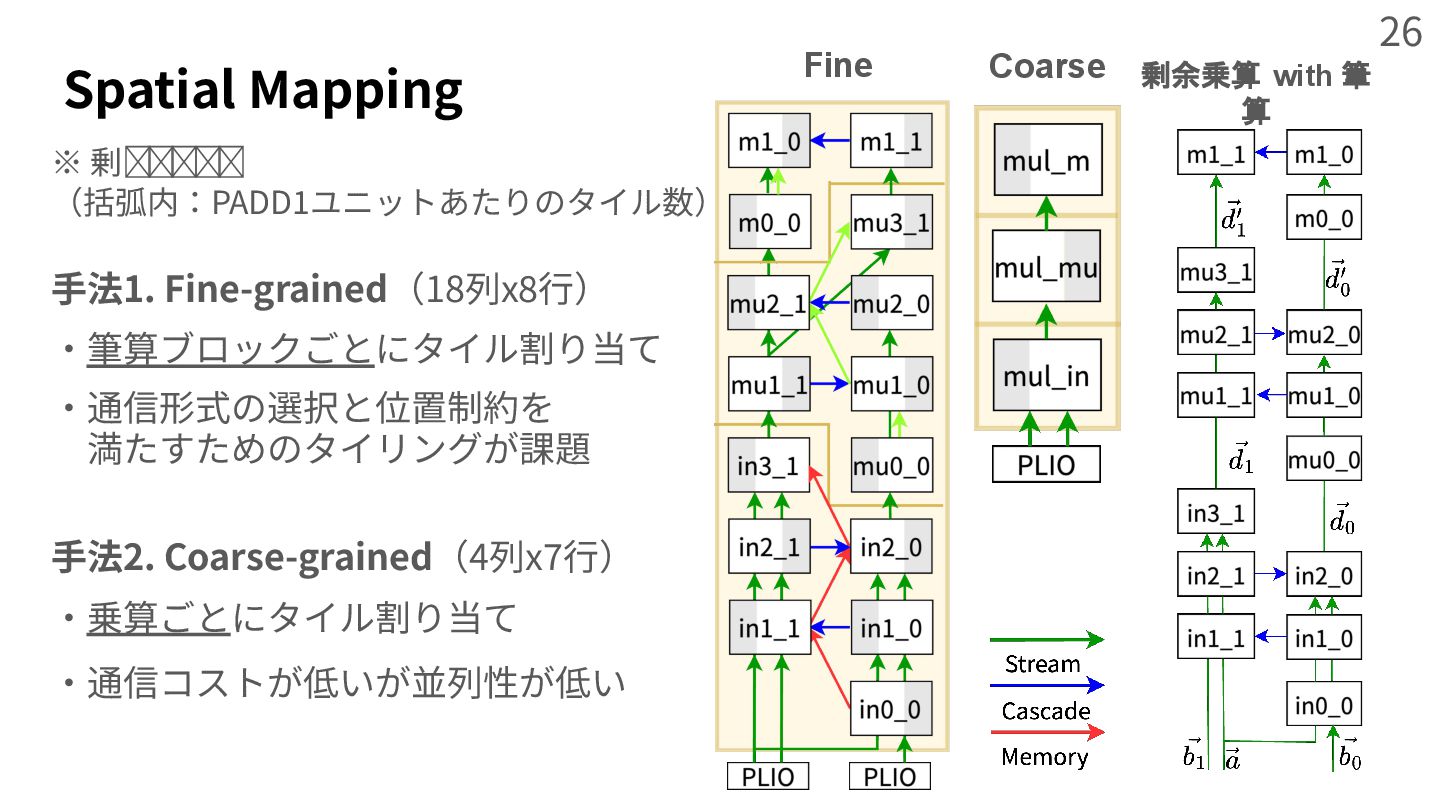{kind=link}
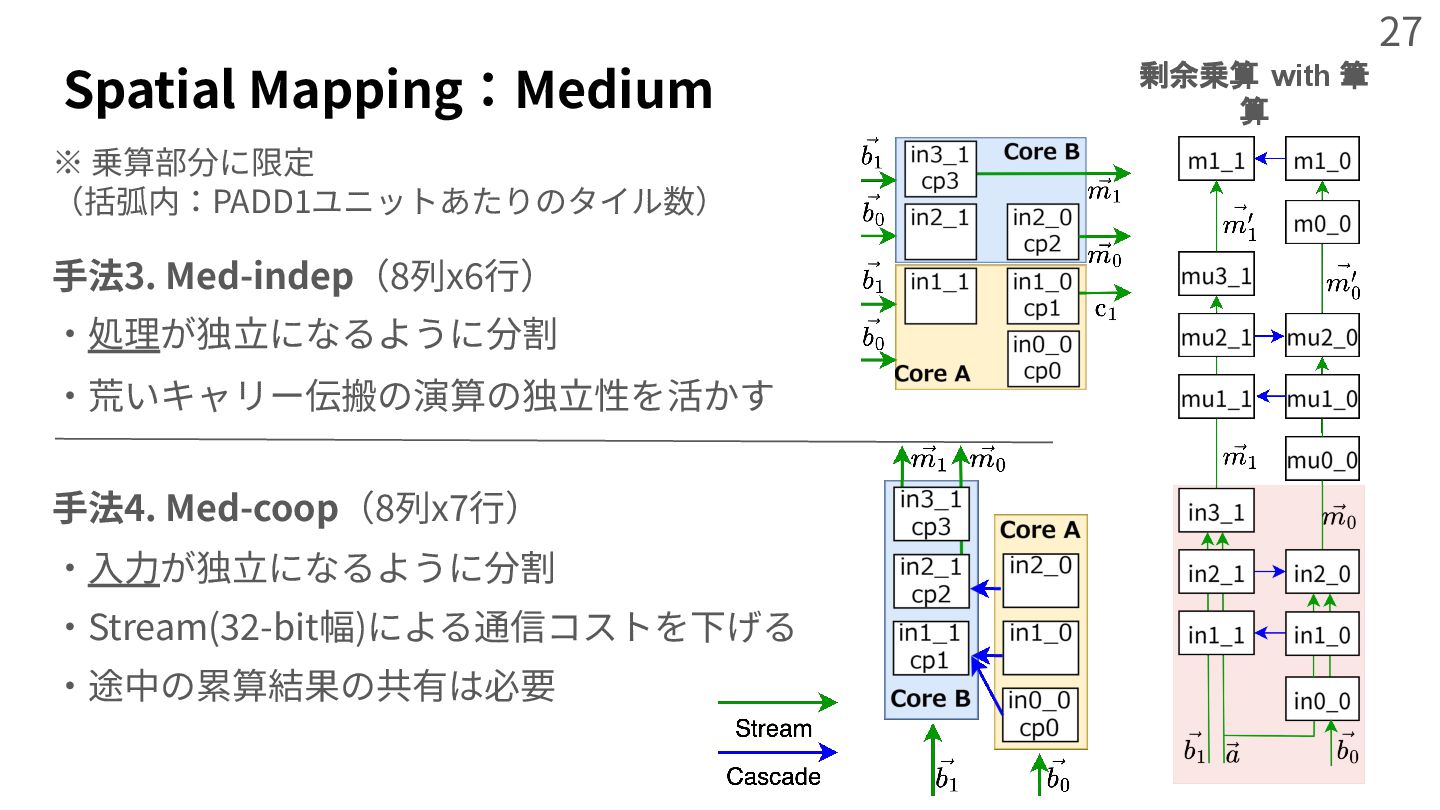{kind=link}
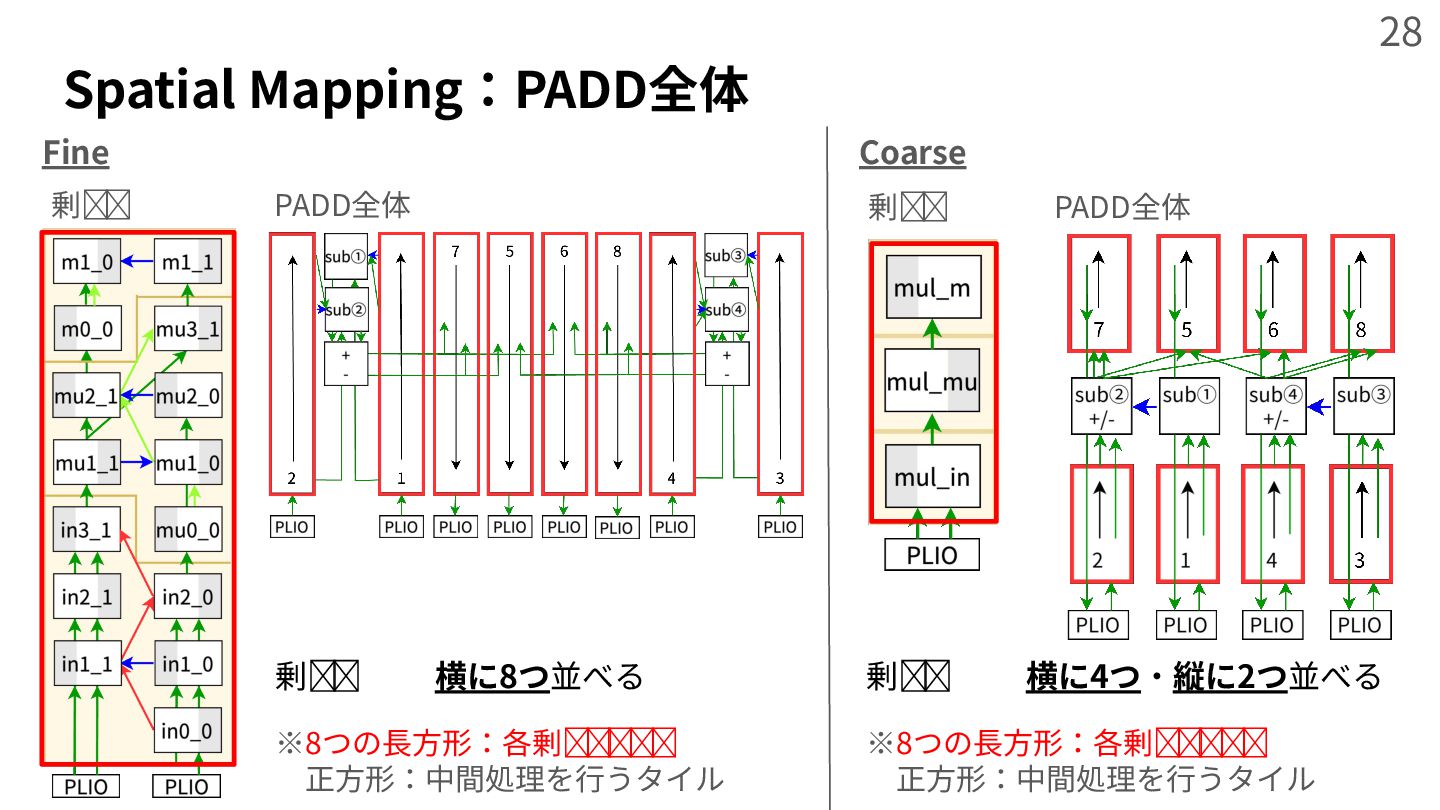{kind=link}
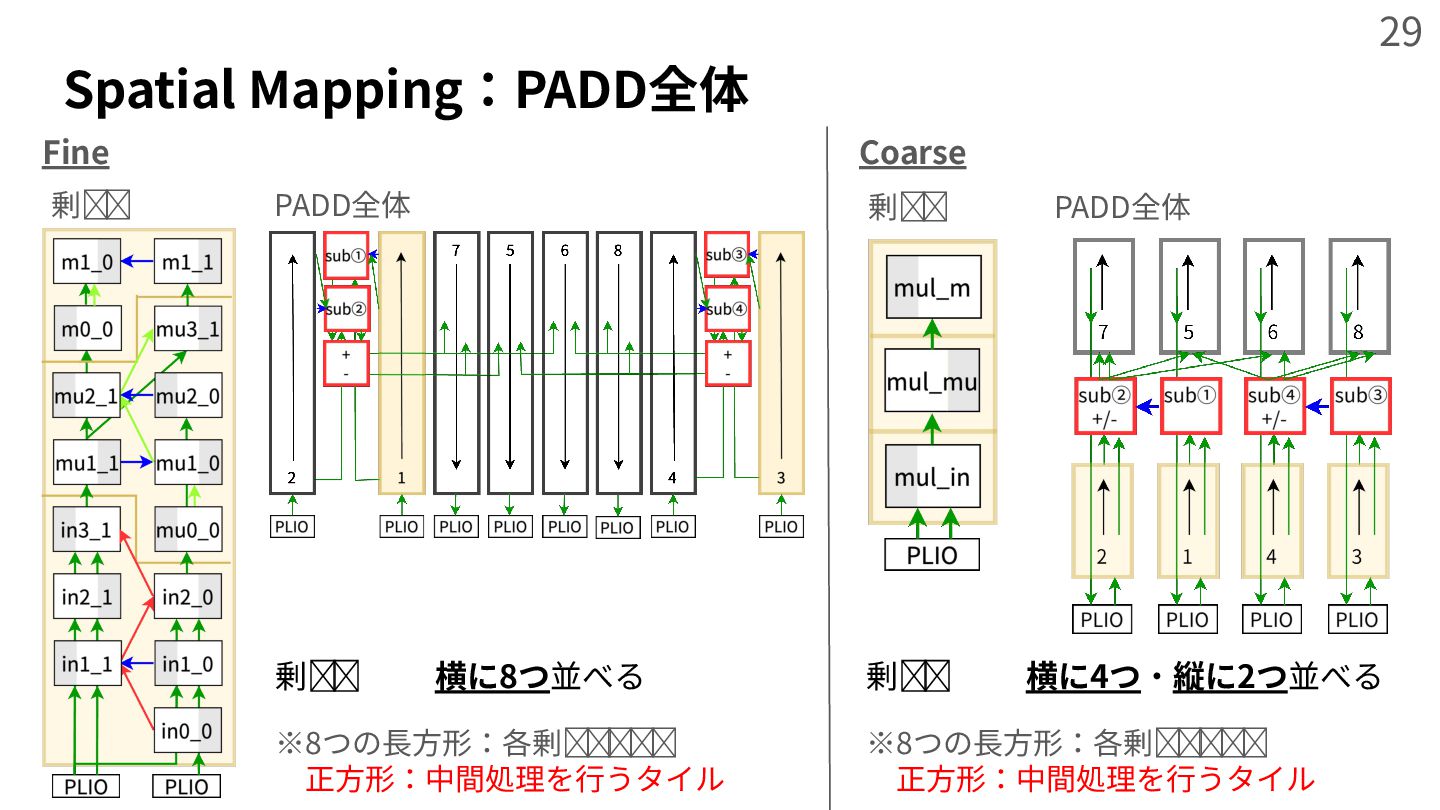{kind=link}
![[参考] 合成結果:Fine 30 剰余乗算 PADD 結果 薄緑のタイル:AIE Core ⻩緑の線:stream、cascade](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_29.jpg){kind=link}
![[参考] 合成結果:Coarse 31 剰余乗算 PADD 結果](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
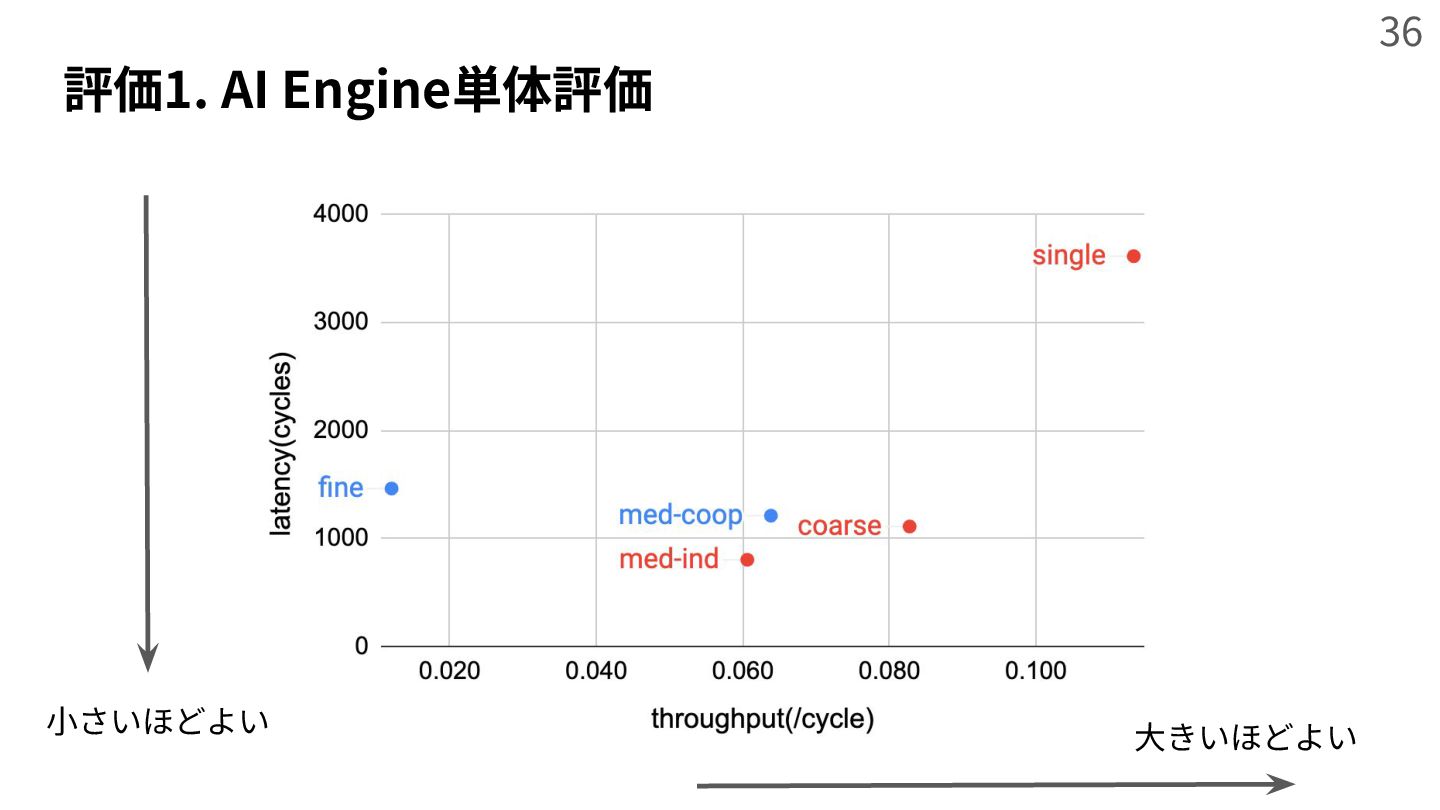{kind=link}
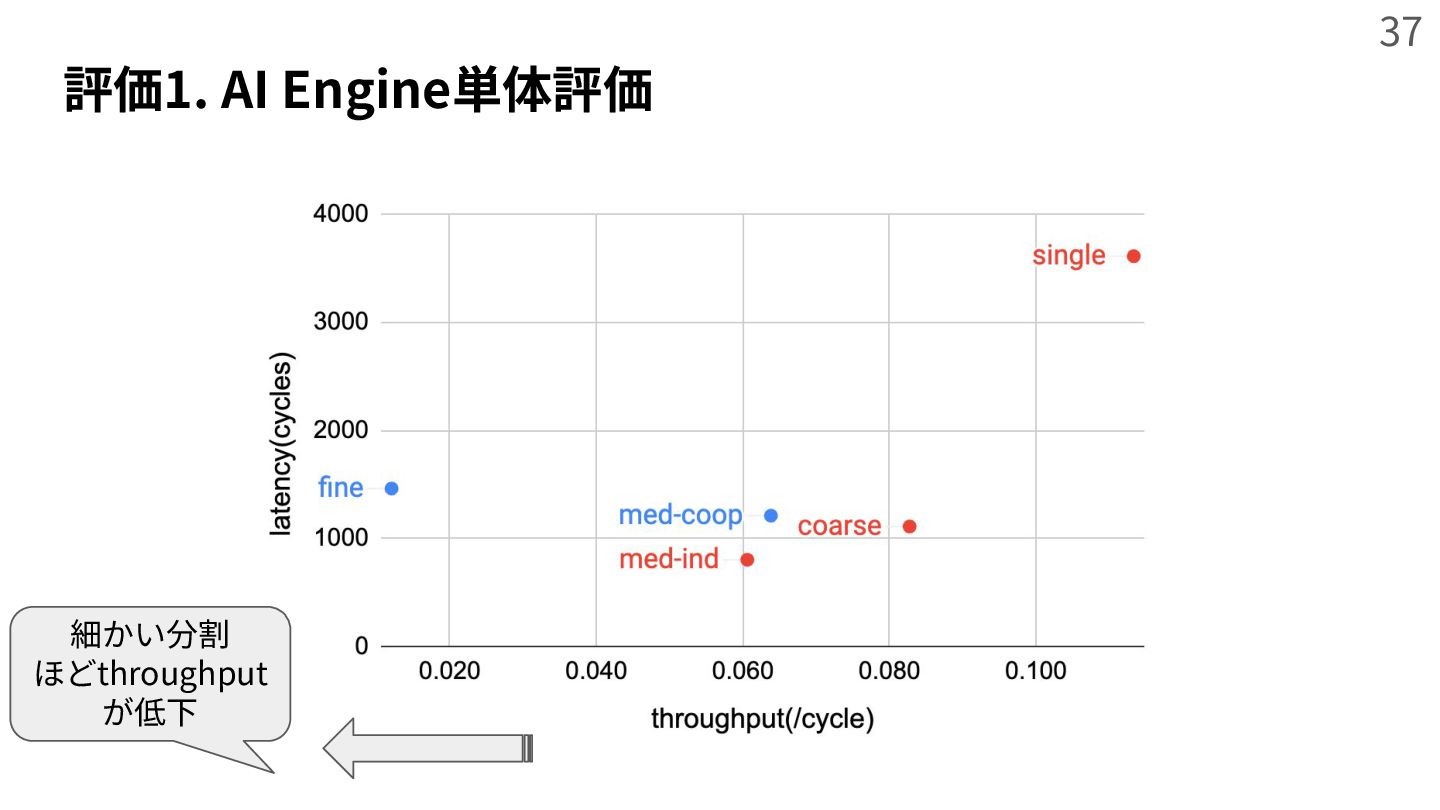{kind=link}
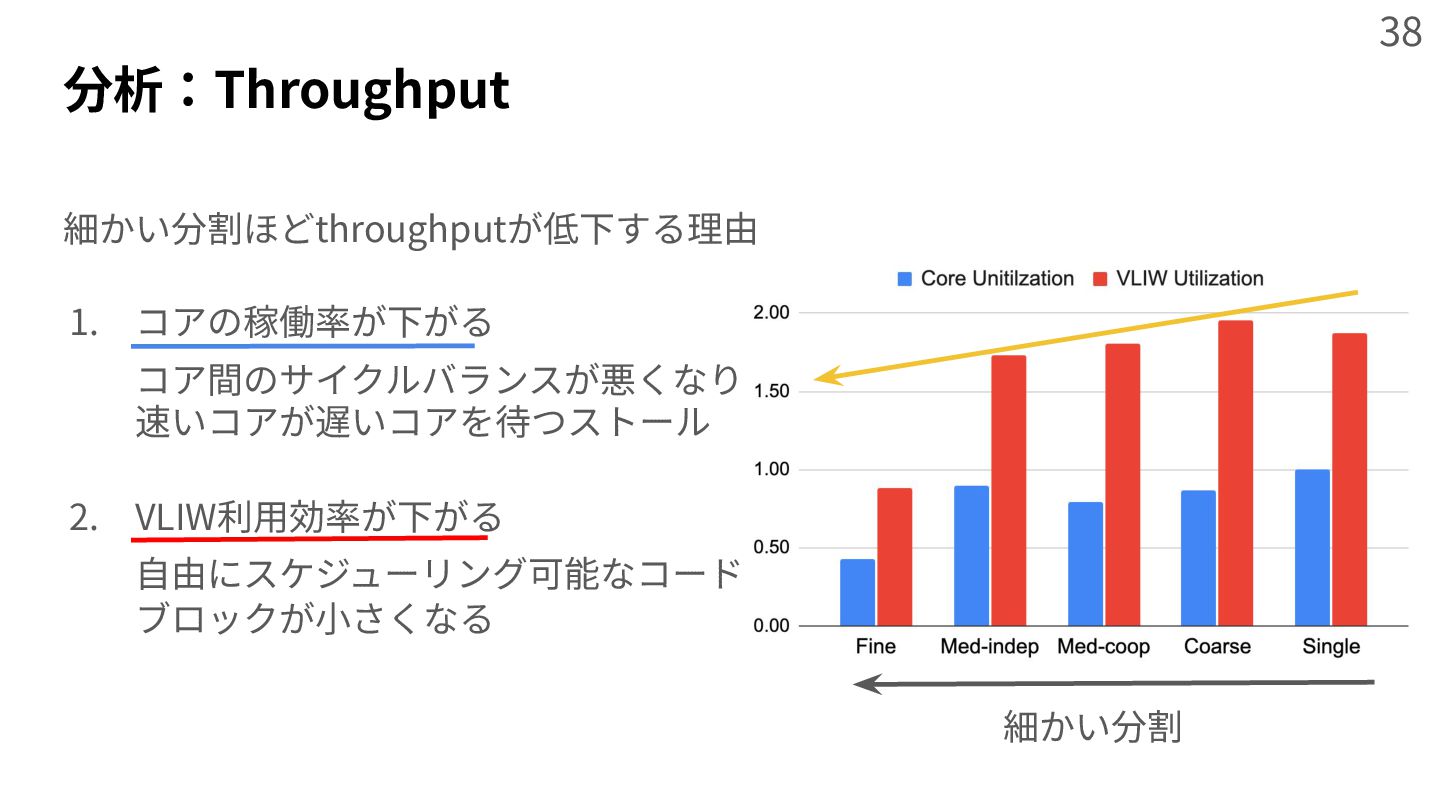{kind=link}
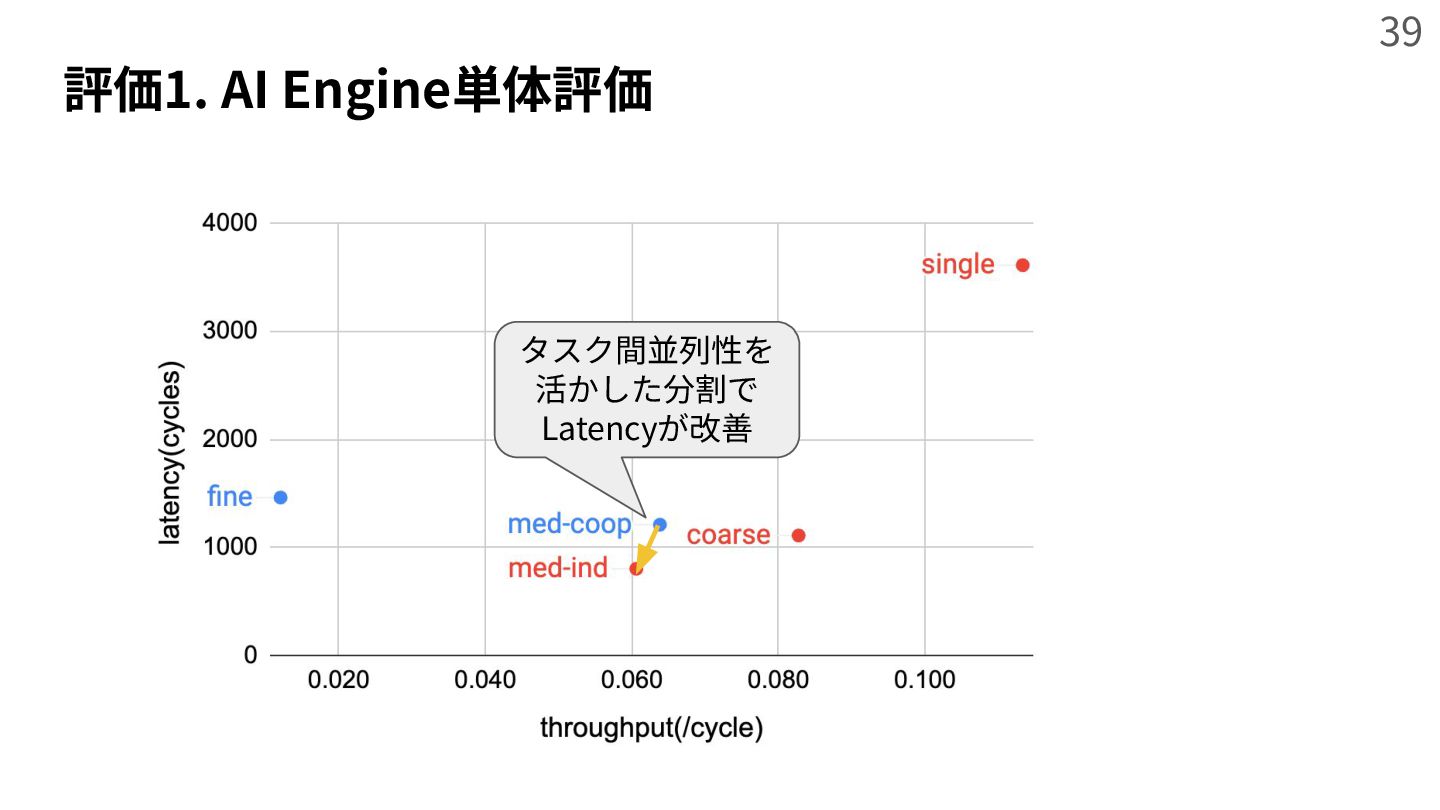{kind=link}
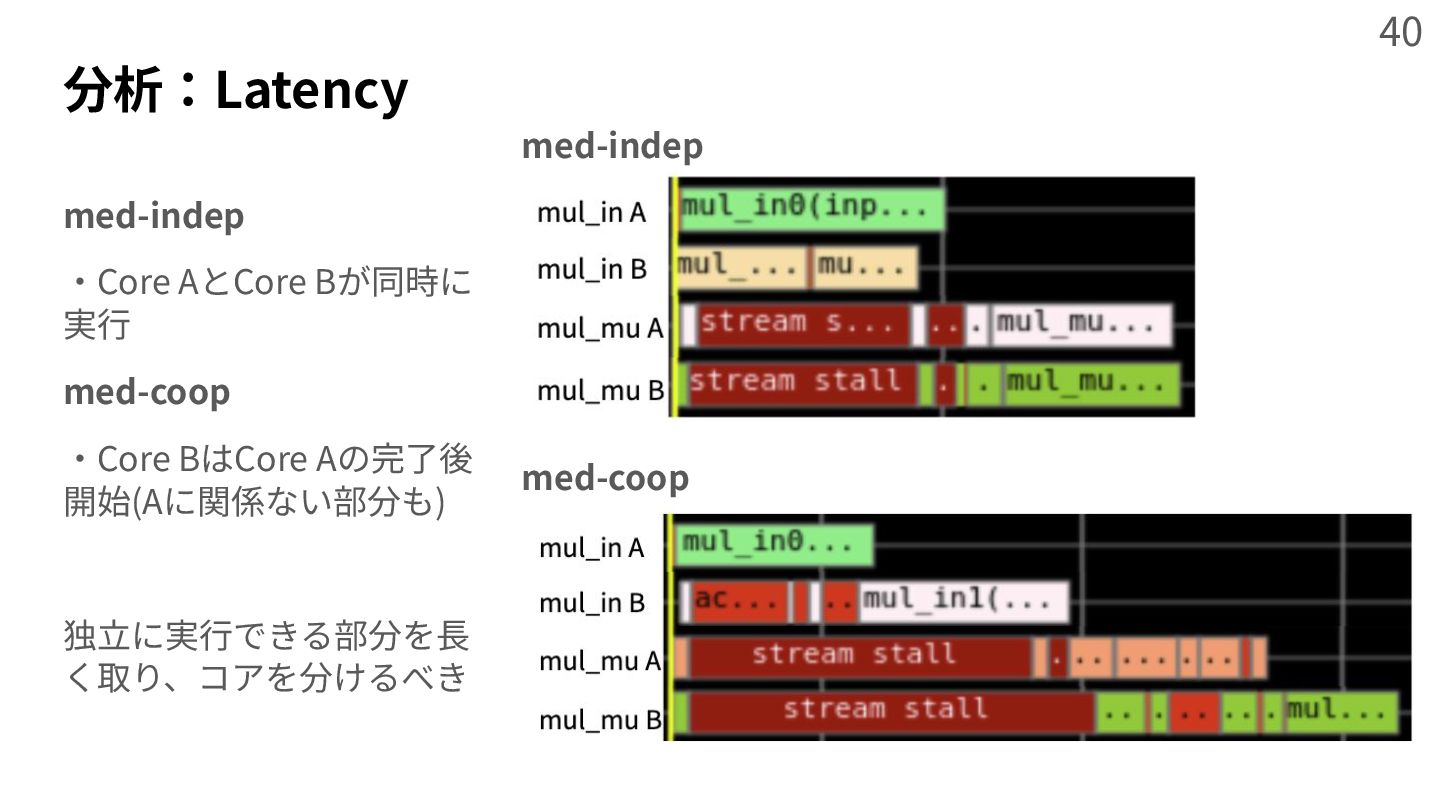{kind=link}
{kind=link}
{kind=link}
![評価2:実機評価 43 ‧同じボードのCPU*と⽐べ、569× ⾼速化 ‧FPGA(U250)上のアクセラレータBSTMSM[2]よりは遅い(次のスライドで説明) Throughput (coarse) (10並列) BSTMSMと⽐べ 1.22×倍増加したが,](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考⽂献 [1] W. Ma et al., “Gzkp: A gpu accelerated](https://files.speakerdeck.com/presentations/525037f0fd724a75934c14c150d4f298/slide_46.jpg){kind=link}