Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
201803生態学会山北集会
Search
naru-T
March 19, 2018
Research
260
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
201803生態学会山北集会
naru-T
March 19, 2018
More Decks by naru-T
See All by naru-T
Naru Tsutsumida
narut
0
1.8k
Other Decks in Research
See All in Research
R&Dチームを起ち上げる
shibuiwilliam
1
270
AI Agentの精度改善に見るML開発との共通点 / commonalities in accuracy improvements in agentic era
shimacos
6
1.7k
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
630
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
270
The mathematics of transformers
gpeyre
0
320
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
450
FUSE-RSVLM: Feature Fusion Vision-Language Model for Remote Sensing
satai
3
860
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
3.8k
LOSの検討(λ Kansai 2026 in Winter)
motopu
0
140
NLP colloquium: AI Safety Survey
kanekomasahiro
0
550
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
170
Fukui Shibiten 39 - AI Art
butchi
0
120
Featured
See All Featured
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Designing for Performance
lara
611
70k
Side Projects
sachag
455
43k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
200
Why Our Code Smells
bkeepers
PRO
340
58k
Practical Orchestrator
shlominoach
191
11k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
390
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Speed Design
sergeychernyshev
33
1.8k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Transcript
大規模リモートセンシングデータをもちいた土地 被覆分類 堤田 成政 京都大学 地球環境学堂
内容 大規模リモートセンシングデータをもちいた土地被覆分類 ◦ 1.データが大きいので・・・ ▪ DL→分析前処理までが大変 ▪ 分析が大変 ◦ 2.教師データの収集が大変(教師付き分類)
▪ なんだかんだいって教師データにすべてがかかっている ◦ 3.精度評価の辛み ▪ 精度評価は評価サンプルにすべてがかかっている ▪ 精度評価の辛み ▪ 空間精度評価の試み ▪ 誤差を含んだ分類図利用 ▪ ポリゴンデータの精度評価 ◦ まとめ:ふるくてあたらしい土地被覆分類研究
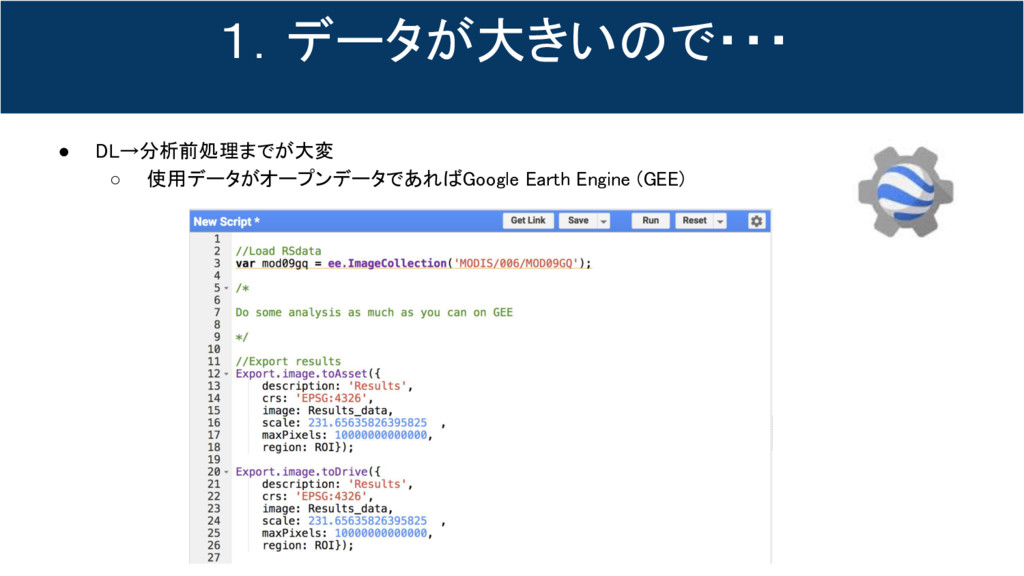
1.データが大きいので・・・ • DL→分析前処理までが大変 ◦ 使用データがオープンデータであればGoogle Earth Engine (GEE)
データが大きいので・・・ • 分析が大変 (Rを想定) ◦ nvblas (on nvidia GPU)を使う ◦ ラスターの使用RAMの上限を引き伸ばすrasterOptions(maxmemory
= 1e10) ◦ raster::clusterRを使う ◦ おそらくPythonでも一緒(numpy, rasterioまわりをいじる?) • これだけで数倍速! ◦ 個人的にはRもpythonも速度的には大した差がないのでは
分析例1(機械学習のためのGEE) • データ収集(AVHRR CDR. 1982-2016, Daily =(365.25×35=12783 mosaiced images), 5km
res.)(計約3.4TB分)) • 下処理 (QA処理、バンドごと平均・標準偏差(一年ごと)=(12バンド×35年) • 結果をGoogle Driveへ出力 (12 パラメータ×35年 = 約266MB/年 = 9.3GB)) • Google DriveからDL • RF + Logit・・・などで分析 (with nvblas, cluserR) • 注:単純な機械学習ならGEEで可
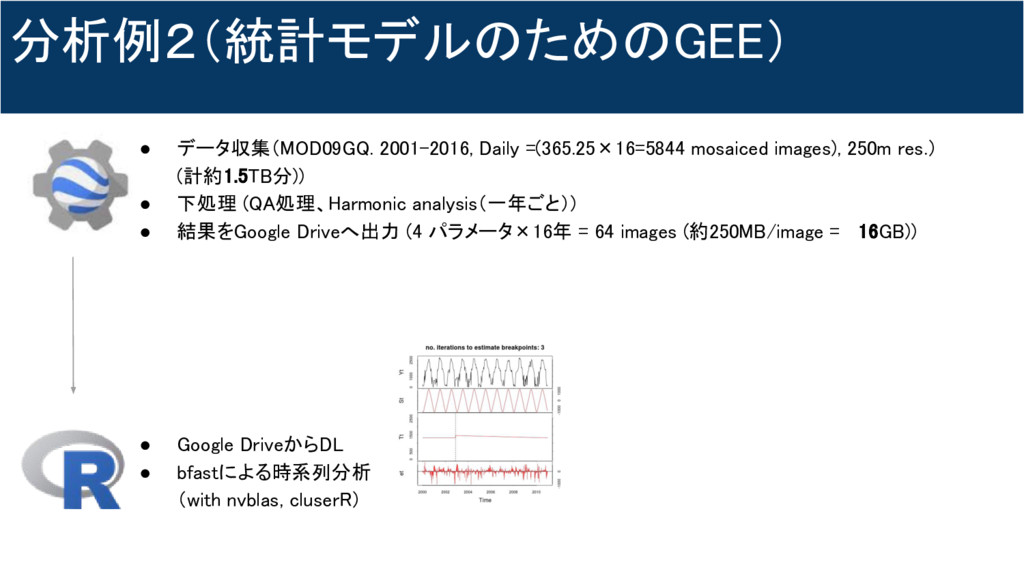
分析例2(統計モデルのためのGEE) • データ収集(MOD09GQ. 2001-2016, Daily =(365.25×16=5844 mosaiced images), 250m res.)
(計約1.5TB分)) • 下処理 (QA処理、Harmonic analysis(一年ごと)) • 結果をGoogle Driveへ出力 (4 パラメータ×16年 = 64 images (約250MB/image = 16GB)) • Google DriveからDL • bfastによる時系列分析 (with nvblas, cluserR)
2.教師データの収集が大変(教師付き分類) • なんだかんだいって教師データにすべてがかかっている ◦ よい教師データ→(モデル) →よい結果 ◦ 悪い教師データ→(どんなによいモデルでも)→わるい結果 • 教師データのオリジナリティがすべて ◦
分類クラス数・定義はデータ作成者次第 ◦ 分類図ユーザーの需要とマッチしない ▪ 誰のための分類図? • 自分で集める ◦ フィールドワーク ◦ Google Earth など • 教師データをシチズンサイエンスとして集める ◦ Geo-wiki ◦ SACLAJ など Geo-wiki. Fritz et al. (2017) in Scientific data SALCAJ
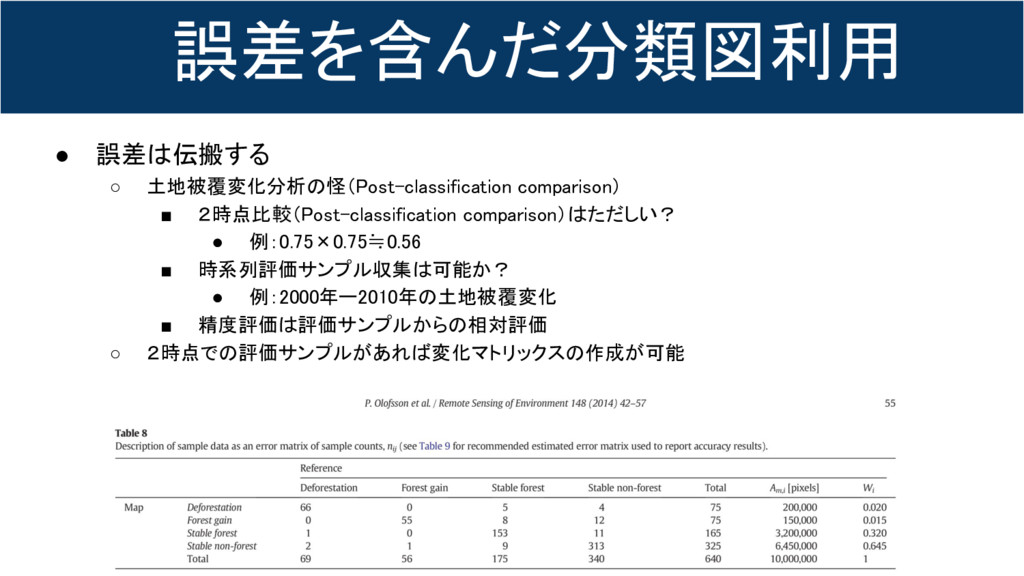
3. 精度評価の辛み • 精度評価は評価サンプルにすべてがかかっている ◦ 評価サンプルはランダムサンプリング?階層サンプリング? ◦ 精度評価は評価サンプルからの相対評価 ▪ 異なる評価サンプルによる精度評価は比較不能
▪ 評価サンプルの精度を検証すべき? ▪ 誤差は伝搬する • 精度評価の辛み ◦ 全体精度(Overall accuracy) ◦◦% = 全体誤差 100 - ◦◦% ◦ 精度(誤差)の空間的な偏り ▪ 空間データに適用した非空間分類モデルの誤差はランダムでない ▪ ランダムサンプリングされた評価サンプルをつかっても代表性があるとは限らない
誤差を含んだ分類図利用 • 誤差は伝搬する ◦ 土地被覆変化分析の怪(Post-classification comparison) ▪ 2時点比較(Post-classification comparison)はただしい? •
例:0.75×0.75≒0.56 ▪ 時系列評価サンプル収集は可能か? • 例:2000年ー2010年の土地被覆変化 ▪ 精度評価は評価サンプルからの相対評価 ◦ 2時点での評価サンプルがあれば変化マトリックスの作成が可能
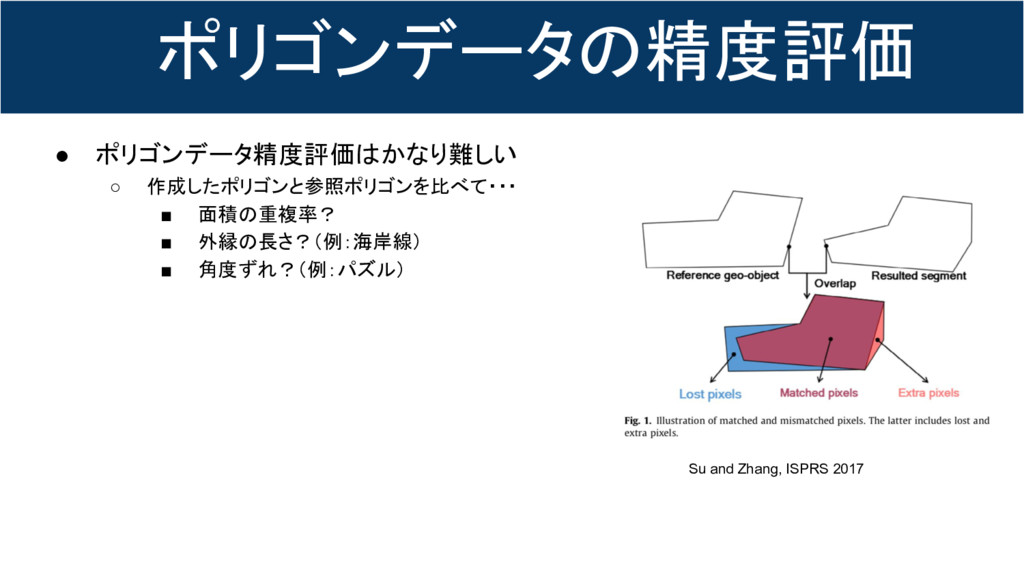
ポリゴンデータの精度評価 • ポリゴンデータ精度評価はかなり難しい ◦ 作成したポリゴンと参照ポリゴンを比べて・・・ ▪ 面積の重複率? ▪ 外縁の長さ?(例:海岸線) ▪
角度ずれ?(例:パズル) Su and Zhang, ISPRS 2017
まとめ:ふるくてあたらしい土地被覆分類研究 • 衛星・ドローン画像を分類する ◦ 使用データを決める(解像度) ▪ 使用データがおおすぎて決めれない ◦ 分類クラスを決める ▪
おれさま分類図はニーズにあわない • 人によって定義はバラバラ ▪ ユーザーがほしい分類図とは? ◦ 教師サンプルをつくる ▪ 多様なクラス組み合わせが可能な教師サンプル をどうつくる? ◦ モデルを組む ▪ 適切なモデル? ◦ 精度分析する ▪ 適切な参照データ? ▪ 適切な精度分析? ▪ 精度のばらつき • それ以外で分類する ◦ OSM ◦ Mapillary ◦ VR?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}