Chat, HTML, Images, Jupyter Notebook, Markdown, Microsoft PowerPoint, Pnadas DataFrame, PDF, URL, Selenium URL Loader, - Public dataset or service loaders - Arxiv, Bilibili, HuggingFace dataset, YouTube transcripts - Proprietary dataset or service loaders - AWS S3 File, ChatGPT Data, Discord, Figma, GitBook, Git, Google BigQuery, Notion DB, Reddit, Slack, Stripe, Twitter - Llama Hub - ChatGPT Plugin Loader(ChatGPT Retrieval Plugin), elasticsearch, faiss, json, gmail, github_repo, jira, metal, mongo, notion, trello, knowledge_base, readability_web, rss, simple_web, unstructured_web, wikipedia, wordpress
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![トークンの出現確率に対するペナルティ計算 - トークンの出現確率(正確にはロジット = 正規化前の対数確率)の計算 - mu[j] -> mu[j] -](https://files.speakerdeck.com/presentations/10a73da266c944aeadfe31581ae22c24/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
![その他のOptionalパラメータ - stream:ChatGPTのWeb UIのように生成結果を逐次的に受け取る設定 - boolean - stop:特定の文字列が生成される前に自動的にストップする設定 - string[]](https://files.speakerdeck.com/presentations/10a73da266c944aeadfe31581ae22c24/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
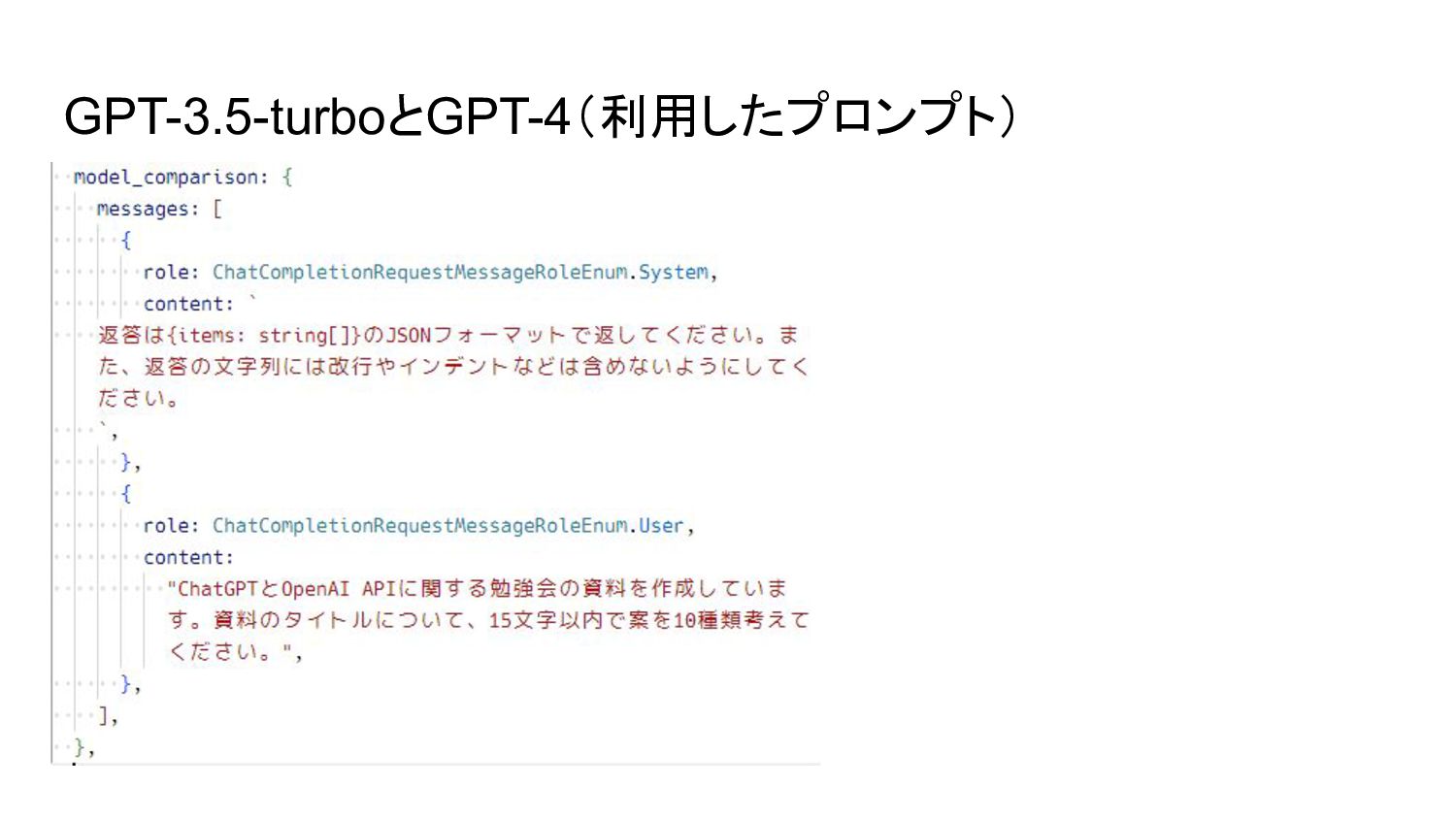{kind=link}
{kind=link}
{kind=link}
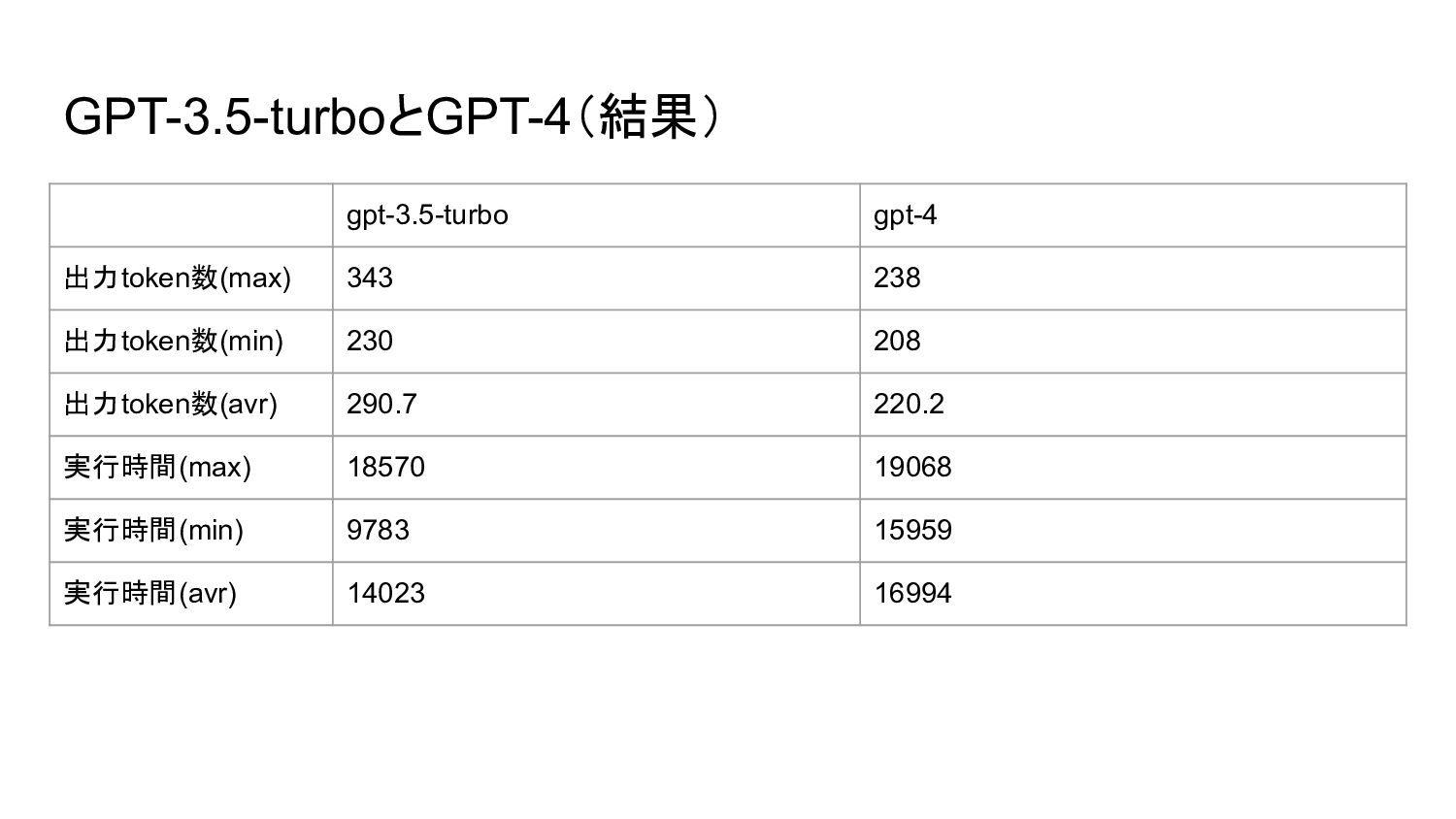{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
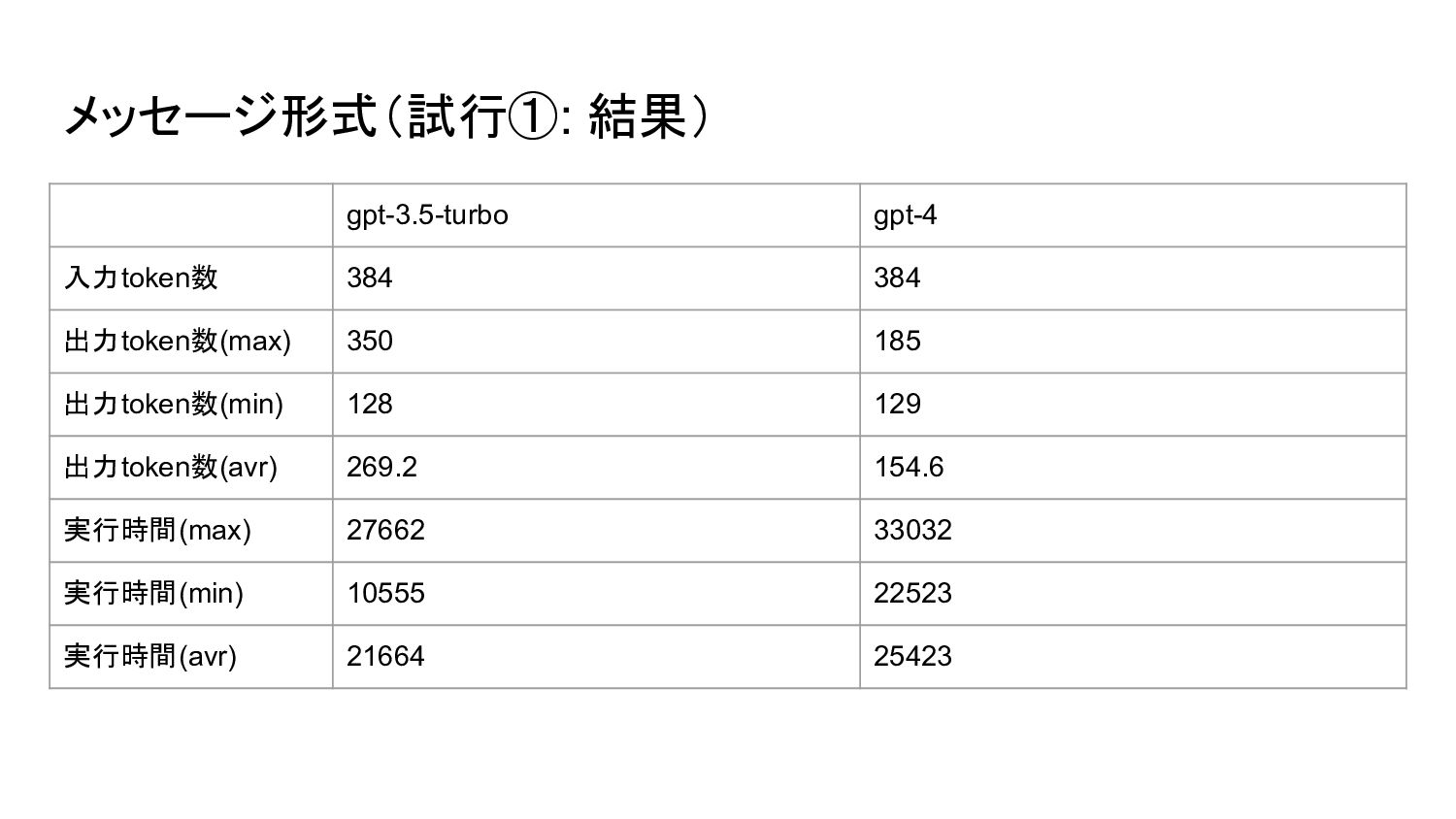{kind=link}
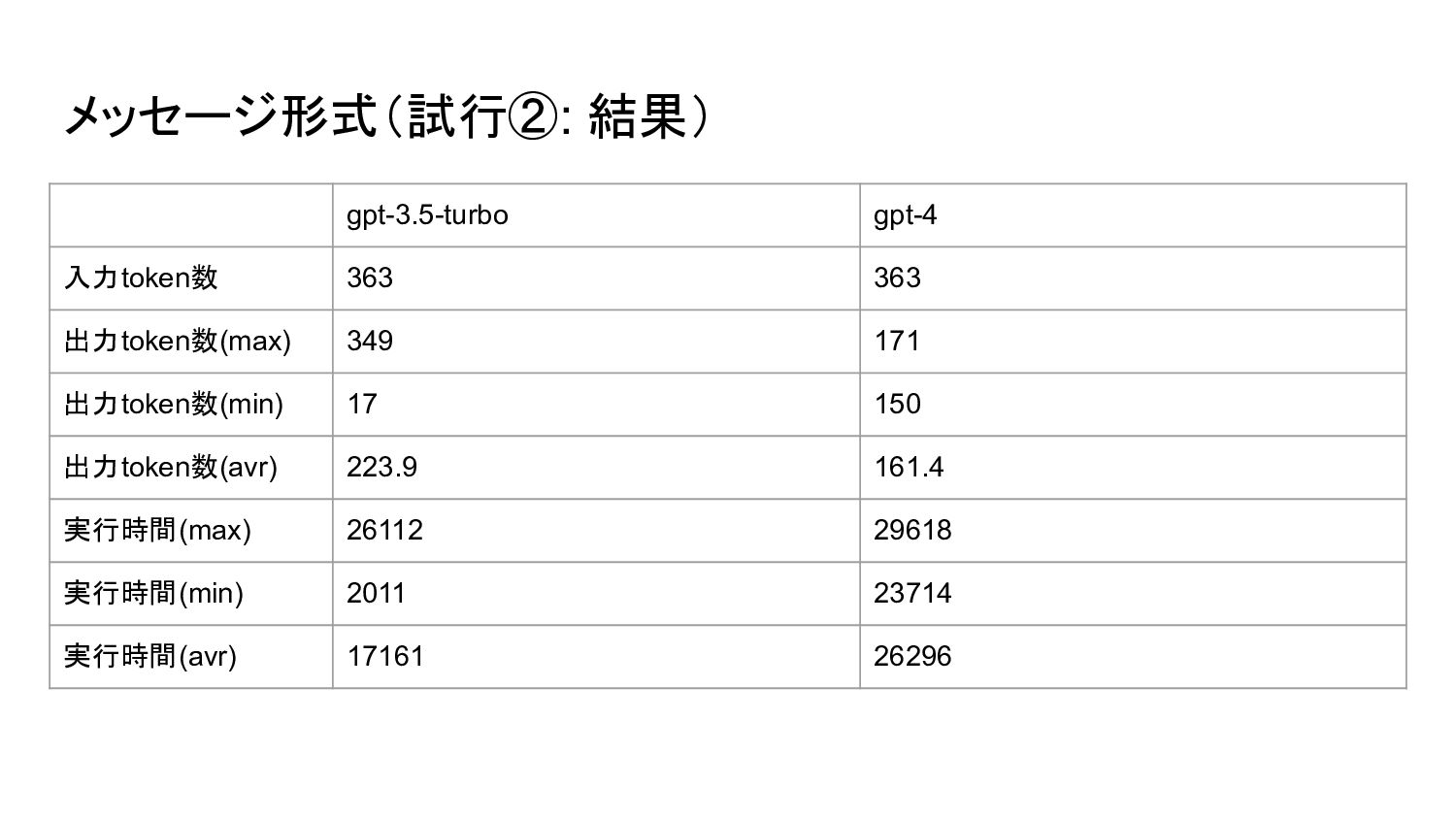{kind=link}
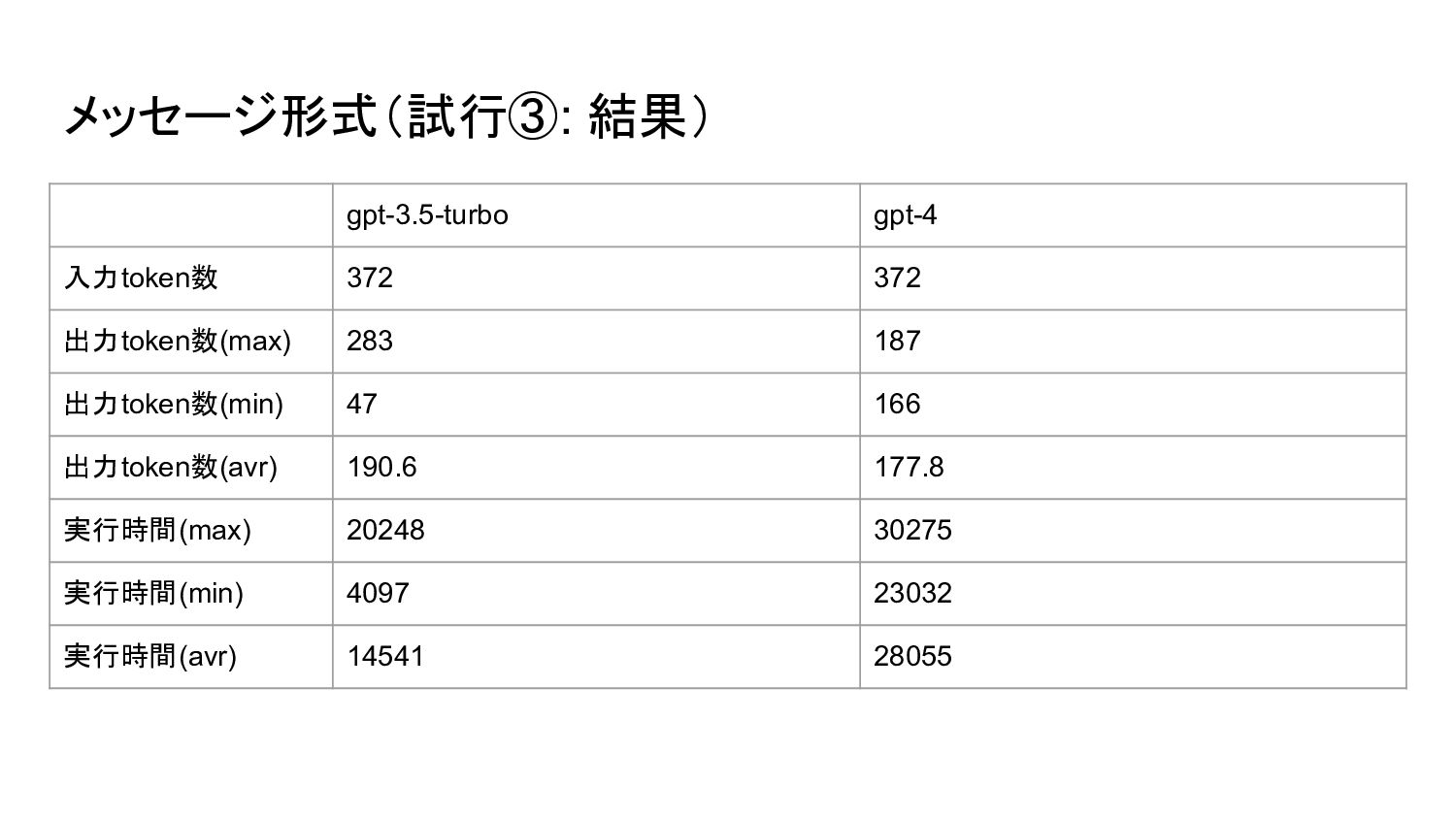{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
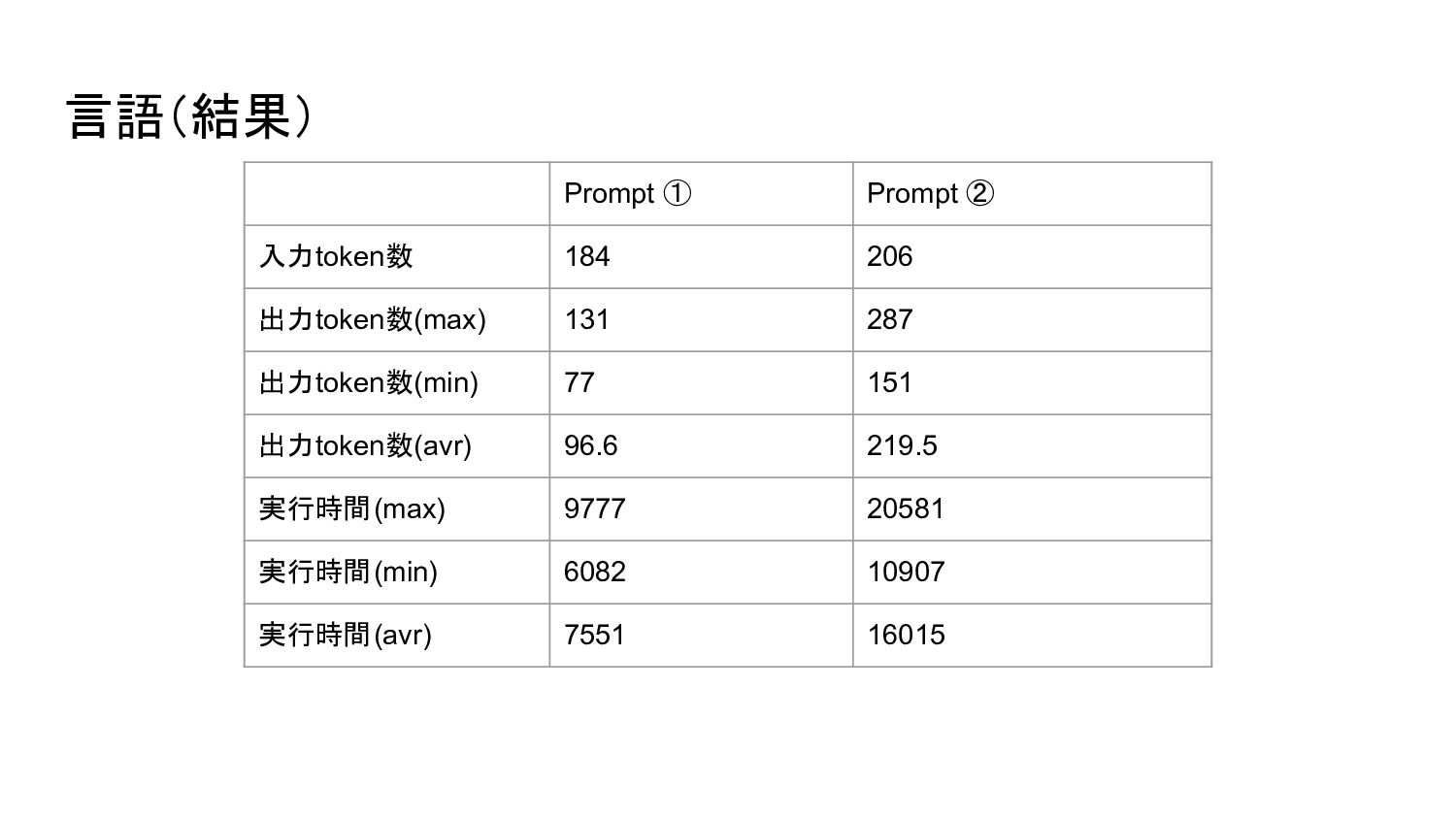{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
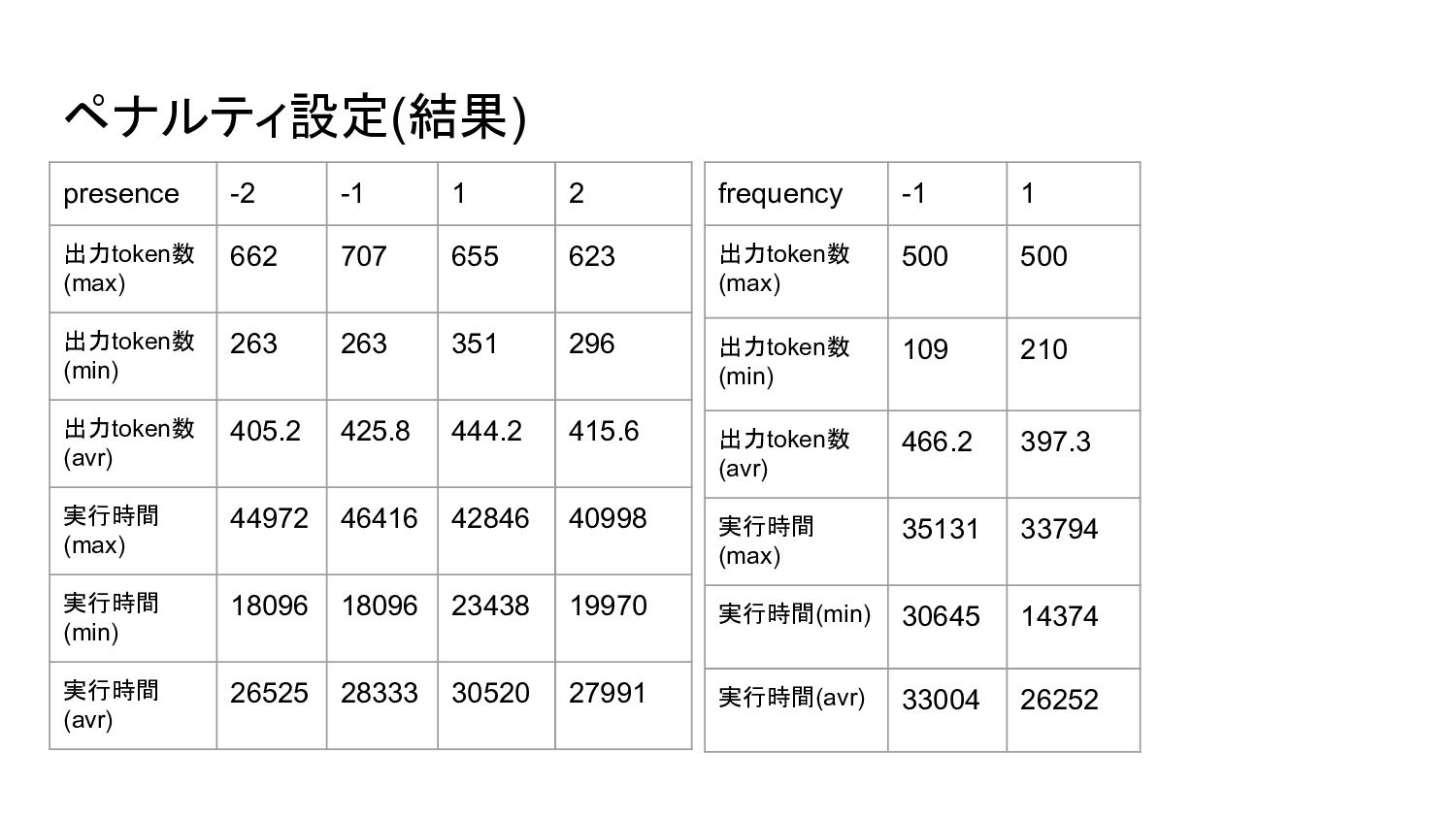{kind=link}
{kind=link}
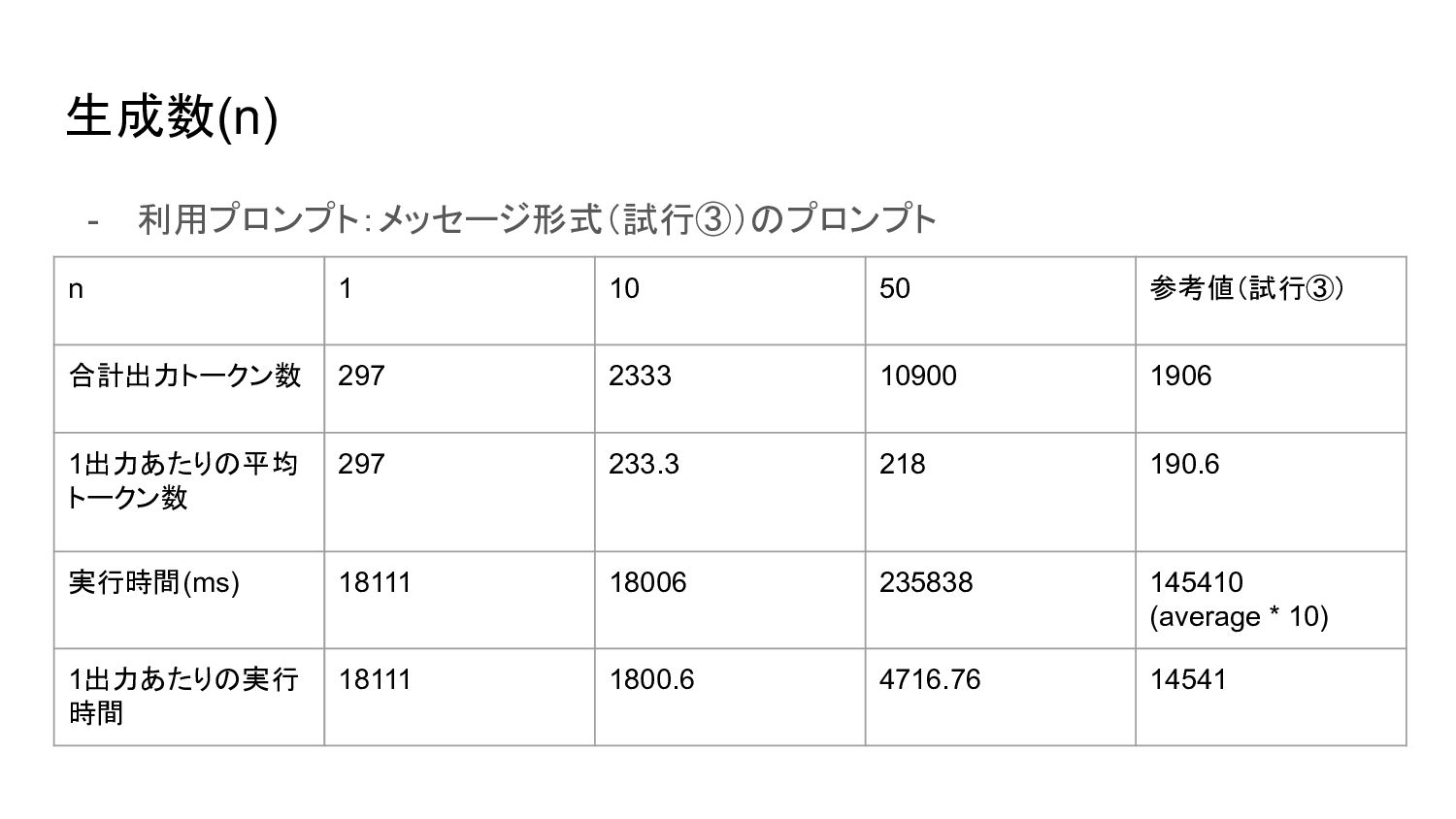{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}