Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Chat Completions APIにおける実行時間の検証
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
natsuume
July 28, 2023
Technology
480
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Chat Completions APIにおける実行時間の検証
第2回 AI/ML Tech Night発表資料
https://opt.connpass.com/event/287568/
natsuume
July 28, 2023
More Decks by natsuume
See All by natsuume
Prompt-Based Hooksの罠
natsuume
0
360
線で考える画面構成
natsuume
1
980
5W1H ~LLM活用プロジェクトを推進するうえで考えるべきこと~
natsuume
0
930
LLM API活用における業務要件の検討
natsuume
0
270
自然言語処理基礎の基礎
natsuume
0
300
5分ですこしわかった気になる Deep Learning概要
natsuume
0
110
ChatGPT / OpenAI API実用入門
natsuume
0
300
Other Decks in Technology
See All in Technology
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
160
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
110
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
290
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
370
CIで使うClaude
iwatatomoya
0
230
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
3.2k
SRE Next 2026 何でも屋からの脱却
bto
0
480
生成AIの活用/high_school2026
okana2ki
0
120
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
600
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
210
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
830
ADDF - ループエンジニアリングするフレームワークを作ったら/I Didn't Set Out to Build Loop Engineering, But ADDF Did
fruitriin
0
110
Featured
See All Featured
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
Visualization
eitanlees
152
17k
Prompt Engineering for Job Search
mfonobong
0
370
First, design no harm
axbom
PRO
2
1.2k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
So, you think you're a good person
axbom
PRO
2
2.1k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Fireside Chat
paigeccino
42
4k
We Have a Design System, Now What?
morganepeng
55
8.2k
Product Roadmaps are Hard
iamctodd
55
12k
Transcript
Chat Completions API における実行時間の検証 2023/07/28 第2回 AI/ML Tech Night
自己紹介 natsuume (Twitter: @_natsuume) 所属:株式会社オプト - NLPer → LLM・アプリケーションエンジニア -
最近やっていること: https://tech-magazine.opt.ne.jp/entry/2023/06/23/144625
Function Calling - GPT-3.5-turbo-0613, GPT-4-0613モデルから利用可能になった機能 - 事前に定義したJSONスキーマの形式で返答が返ってくる機能 - 従来よりも簡単に出力の制御が可能になった -
色々な検証にも使える Function Callingを使って実行時間の検証してみる
検証方法 例(入力トークン数と実行時間の検証) - 右のようなFunctionを用いて、入力テキストに 関わらず出力内容を固定 - 他の実験でも同様
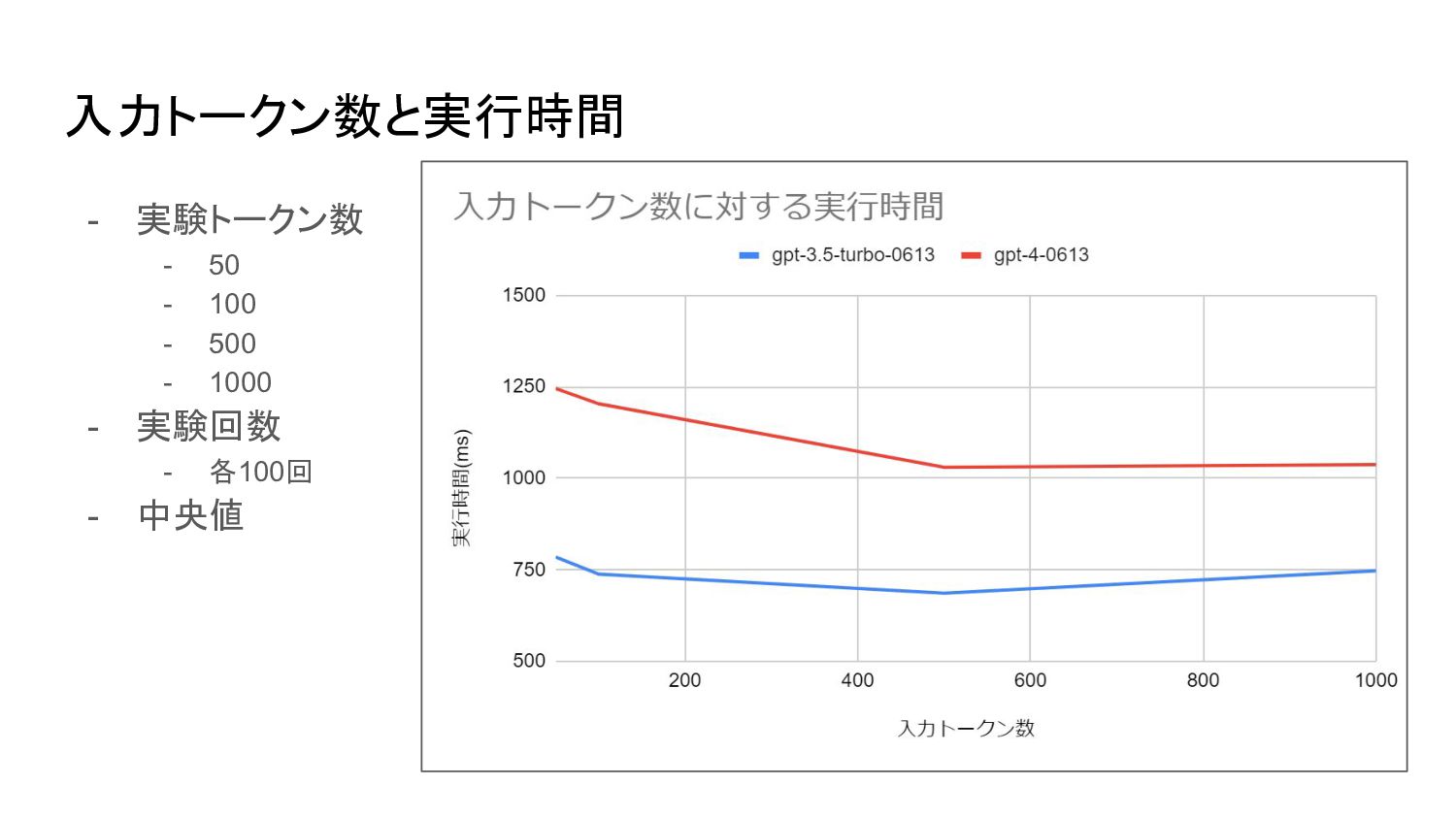
入力トークン数と実行時間 - 実験トークン数 - 50 - 100 - 500 -
1000 - 実験回数 - 各100回 - 中央値
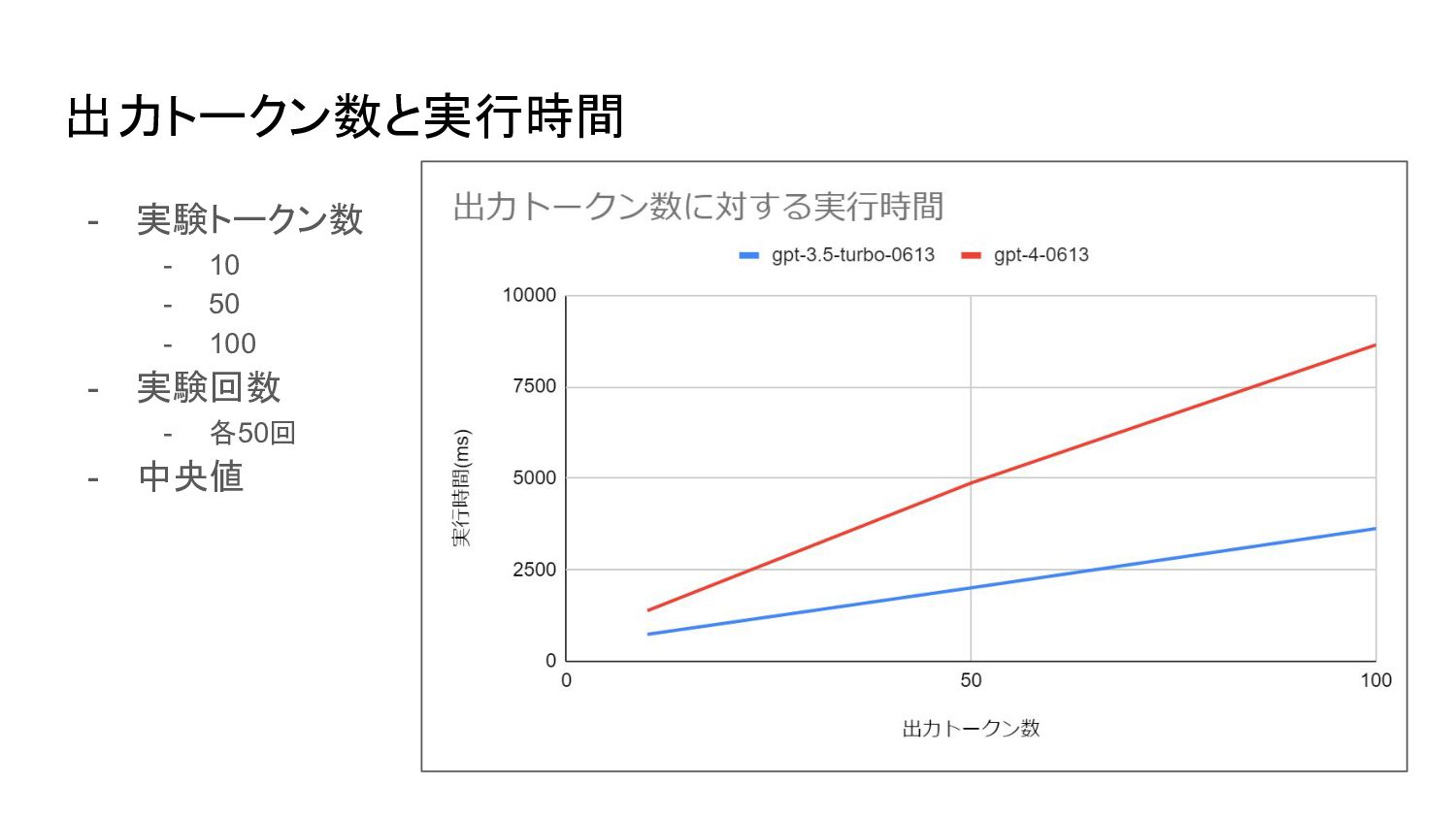
出力トークン数と実行時間 - 実験トークン数 - 10 - 50 - 100 -
実験回数 - 各50回 - 中央値
出力数nと実行時間 - 出力トークン数を固定し、nを変化させたときの実行時間の変化 - 例:出力トークン数: 100 - n=1(100×1) - n=2(50×2)
- n=10(10×10) - n=1における単位出力トークンは先程の実験と同様に10, 50, 100の3パターン - 合計の出力トークン数は次の4パターン - 50(10×5, 50×1) - 100(10×10, 50×2, 100×1) - 500(10×50, 50×10, 100×5) - 1000(10×100, 50×20, 100×10) - 試行回数はn=1の場合は前述の実験データを利用、それ以外は各10回
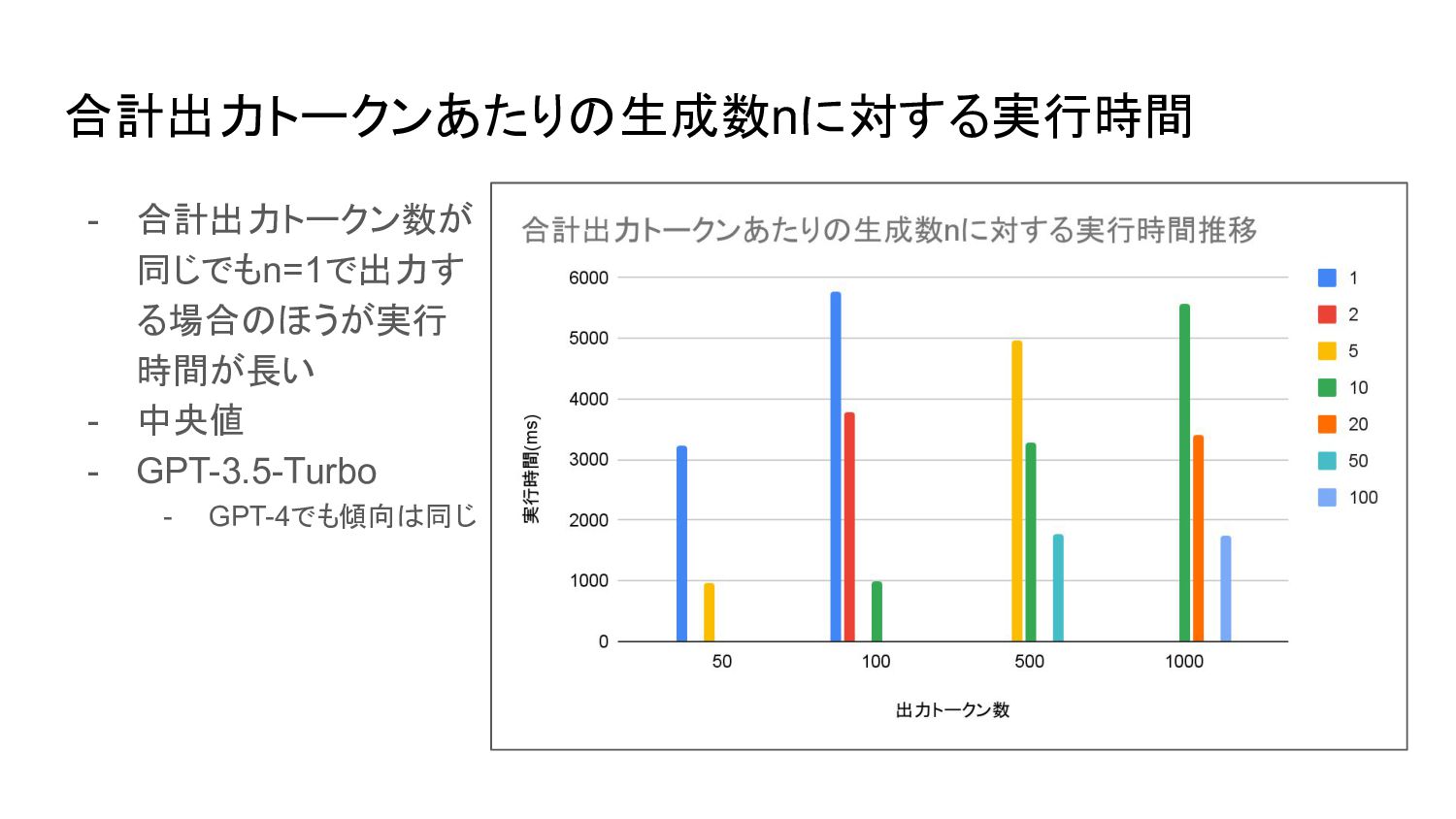
合計出力トークンあたりの生成数nに対する実行時間 - 合計出力トークン数が 同じでもn=1で出力す る場合のほうが実行 時間が長い - 中央値 - GPT-3.5-Turbo
- GPT-4でも傾向は同じ
nに対する実行時間の推移 - nを増やしても実行時 間は変化なし~微増 - 中央値 - GPT-3.5-Turbo - GPT-4でも傾向は同じ
検証を通して気づいたFunction Callingの所感 - Function Callingとはいえ、本質的にはGPTアーキテクチャのモデル - 100%完全に出力を制御できるわけではない - 心なしかGPT-3.5-TurboよりもGPT-4のほうがFunction Callingの結果壊れやすい
感じがある - 定型文を返すfunction定義などGPT-3.5-Turboは愚直に定義した内容を返してくれることが多い が、GPT-4はdescriptionをよろしく解釈してしまうので壊れることがある印象 - プロンプトインジェクションの余地がある - Function Callingだから、と油断して出力をチェックせずに DB等に流すのは危険
まとめ - 入力トークン - 実行時間への影響はなさそう - 出力トークン - トークン数に応じて(おおよそ)線形に実行時間が増加する -
トークン数あたりの増加量は GPT-3.5-Turboに対してGPT-4は2~2.5倍程度 - 生成数N - 出力トークン数の合計が同じでも単位生成あたりのトークン数が少ない方が高速 - 例:実行時間は 1000 × 1 > 100 × 10 > 10 × 100 の関係 - 複数候補を生成するような用途の場合、生成数 nパラメータの利用を積極的に検討する価値があり そう
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}