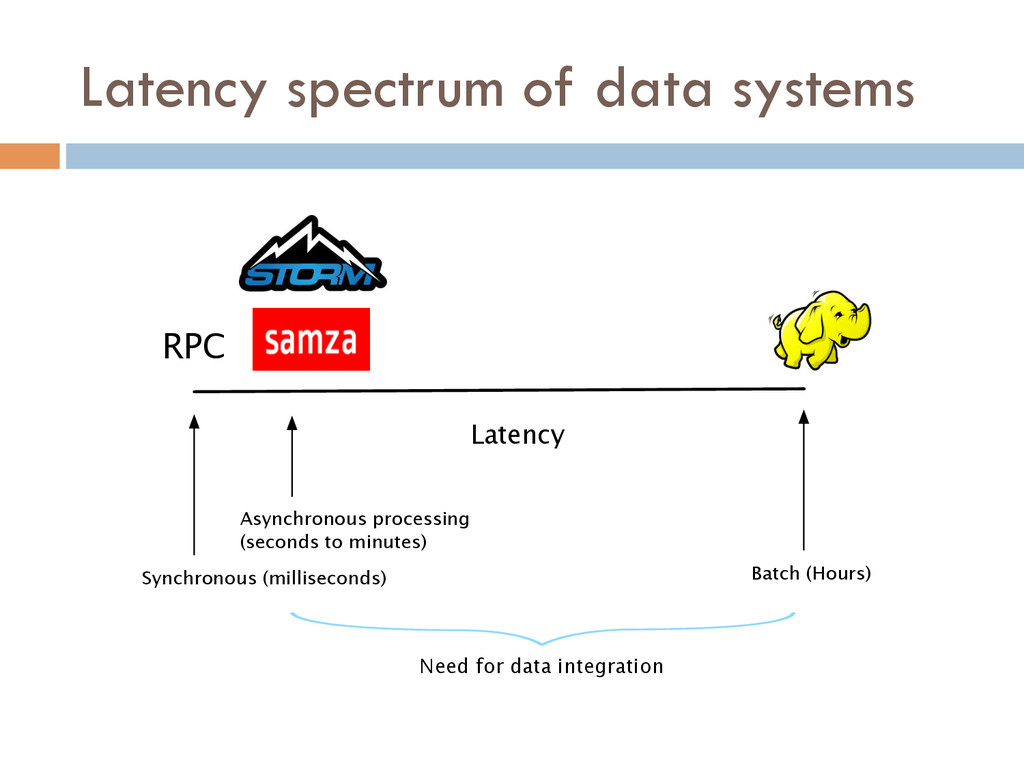
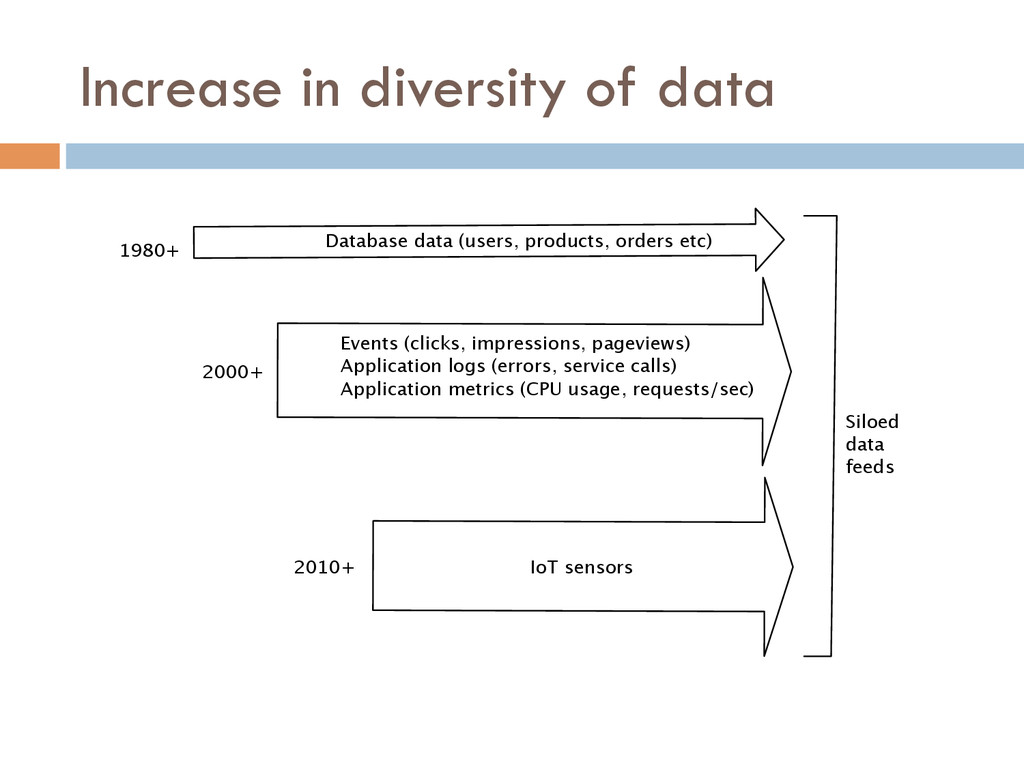
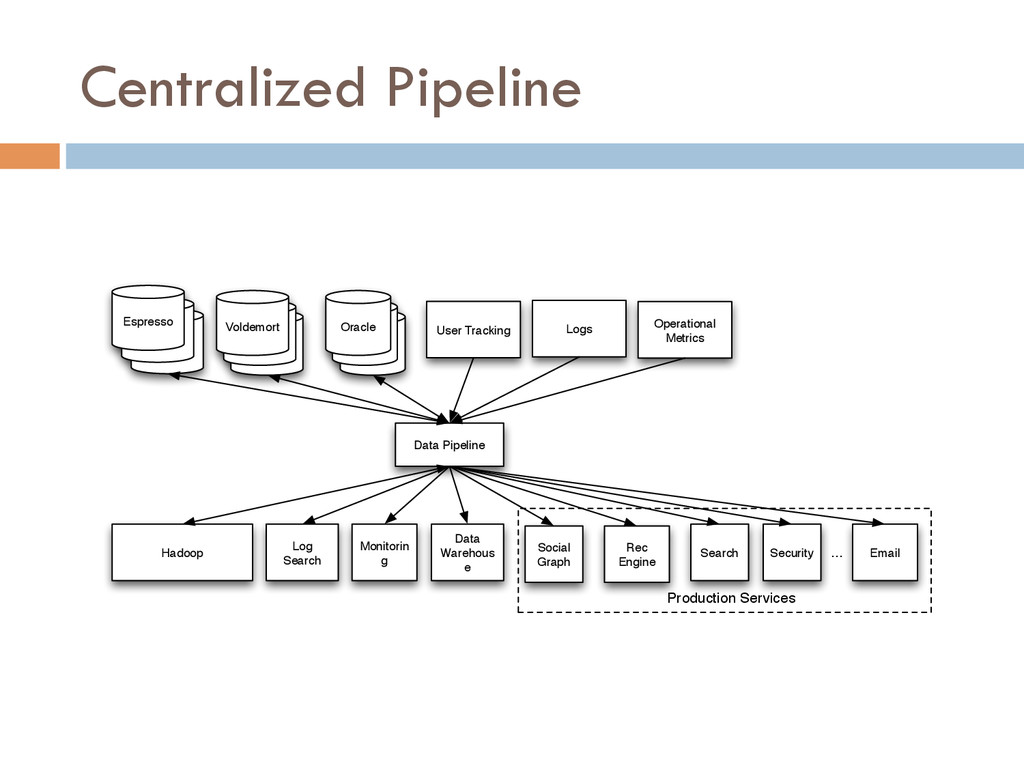
With more sophisticated data-parallel processing systems, the new bottleneck in data-intensive companies shifts from the back-end data systems to the data integration stack, which is responsible for the pre-processing of data for back-end applications. The use of back-end data systems with different access latencies and data in- tegration requirements poses new challenges that current data inte- gration stacks based on distributed file systems—proposed a decade ago for batch-oriented processing—cannot address.
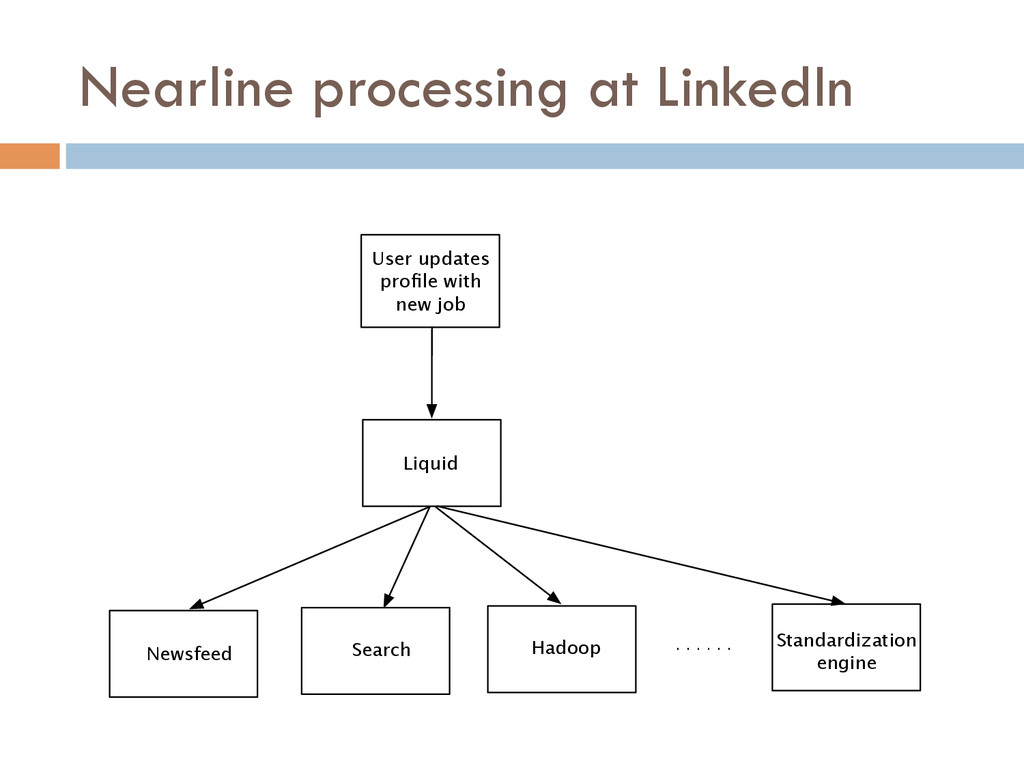
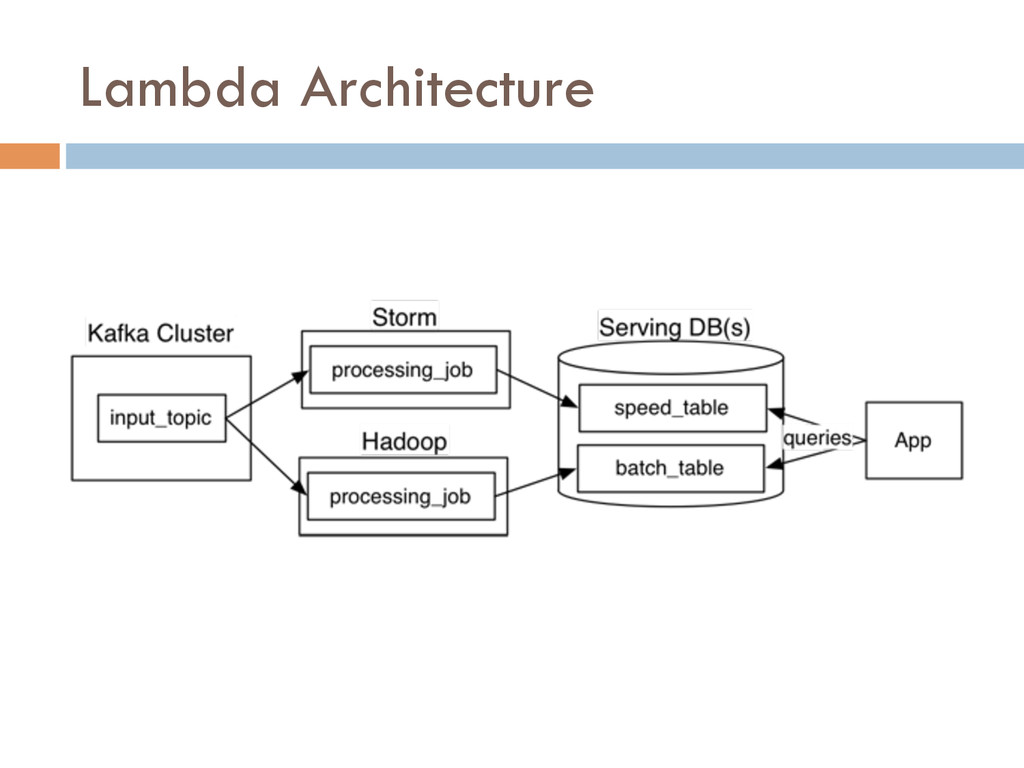
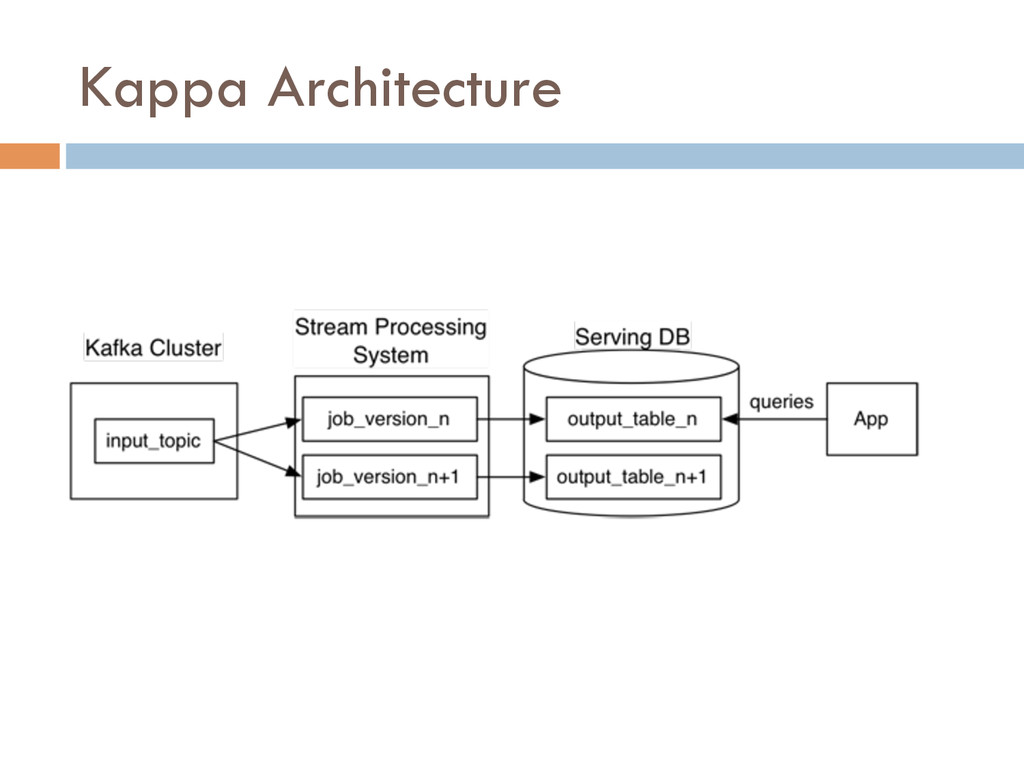
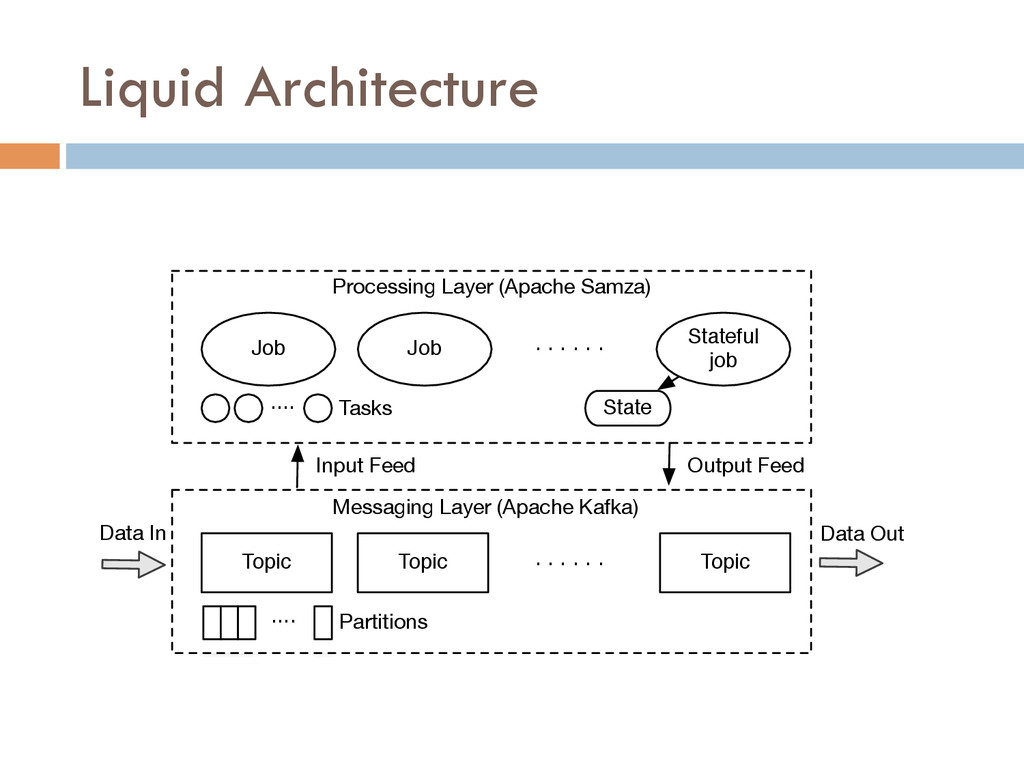
In this paper, we describe Liquid, a data integration stack that provides low latency data access to support near real-time in ad- dition to batch applications. It supports incremental processing, and is cost-efficient and highly available. Liquid has two layers: a processing layer based on a stateful stream processing model, and a messaging layer with a highly-available publish/subscribe sys- tem. We report our experience of a Liquid deployment with back- end data systems at LinkedIn, a data-intensive company with over 300 million users.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
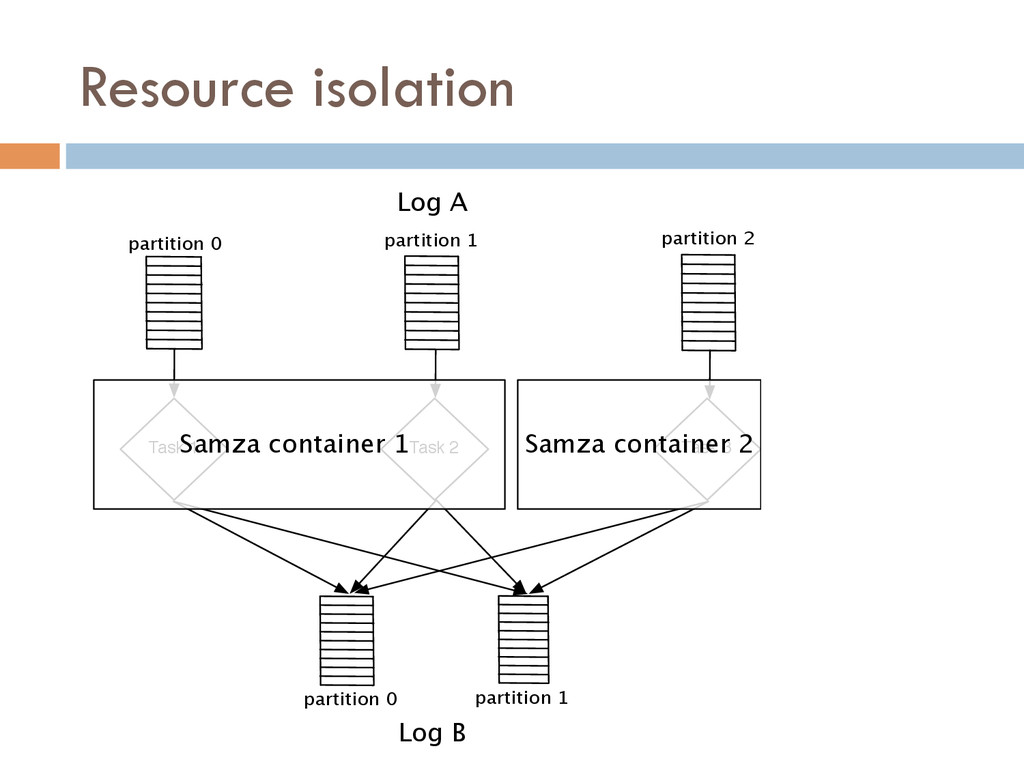{kind=link}
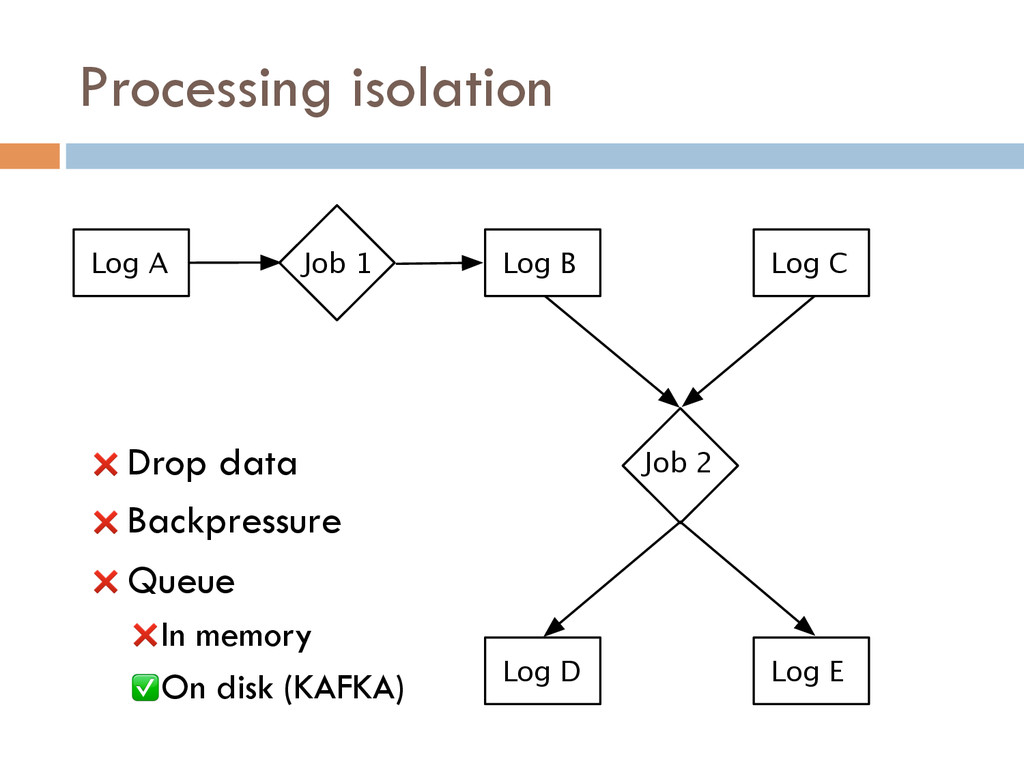{kind=link}
{kind=link}
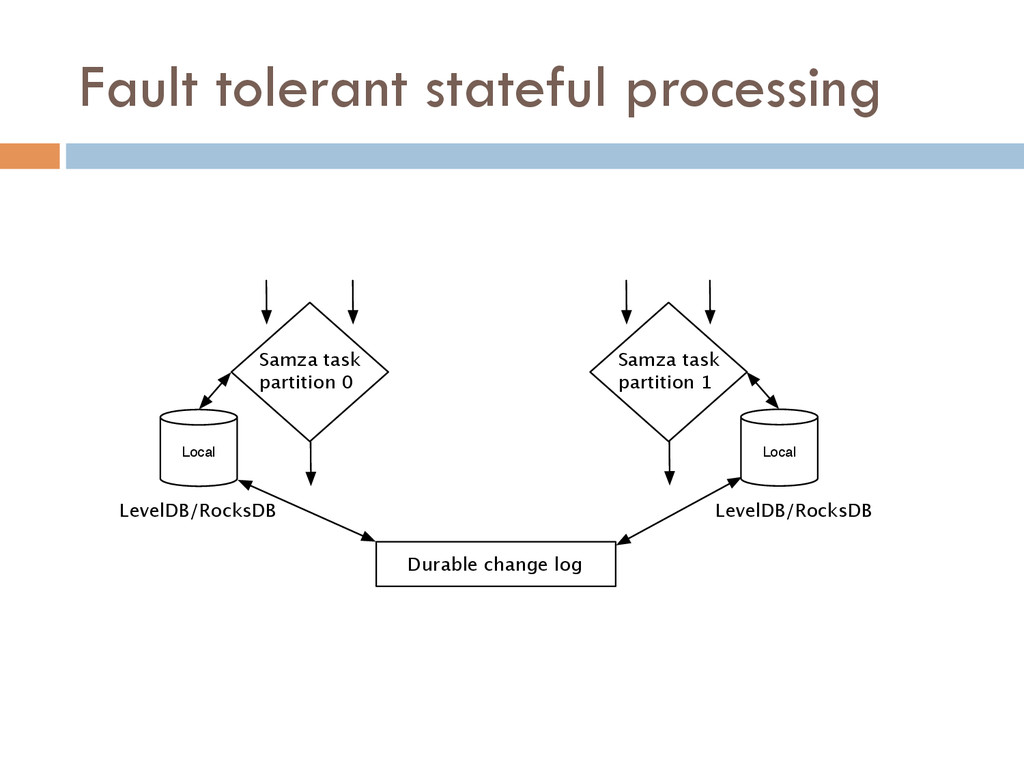{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
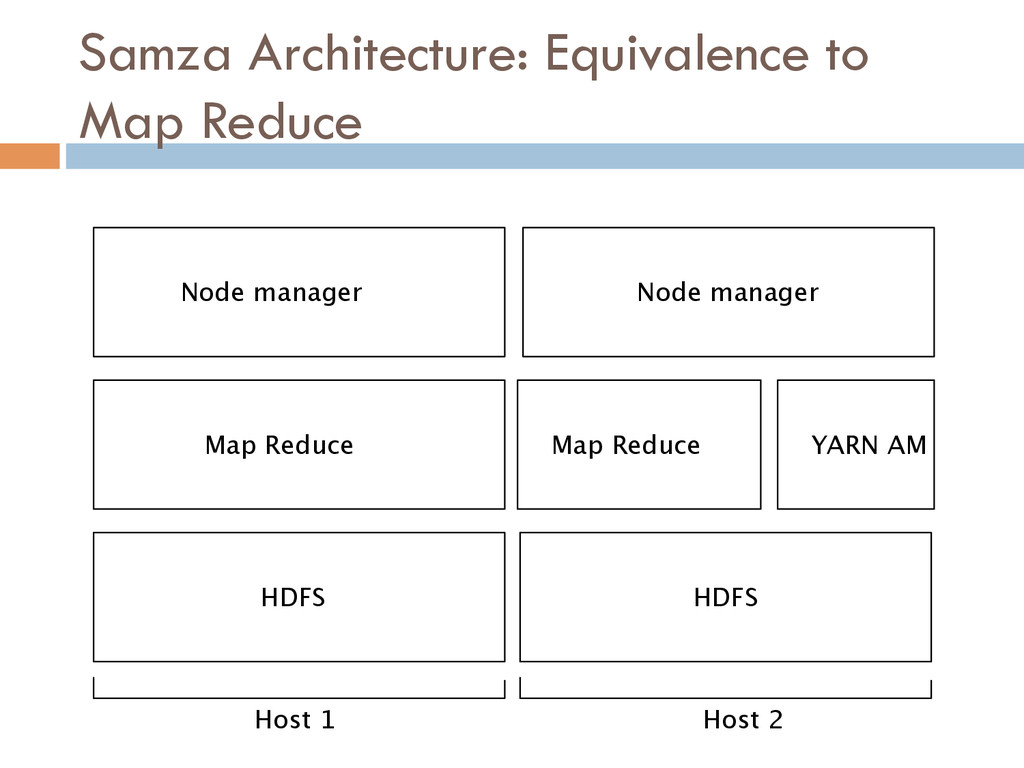{kind=link}