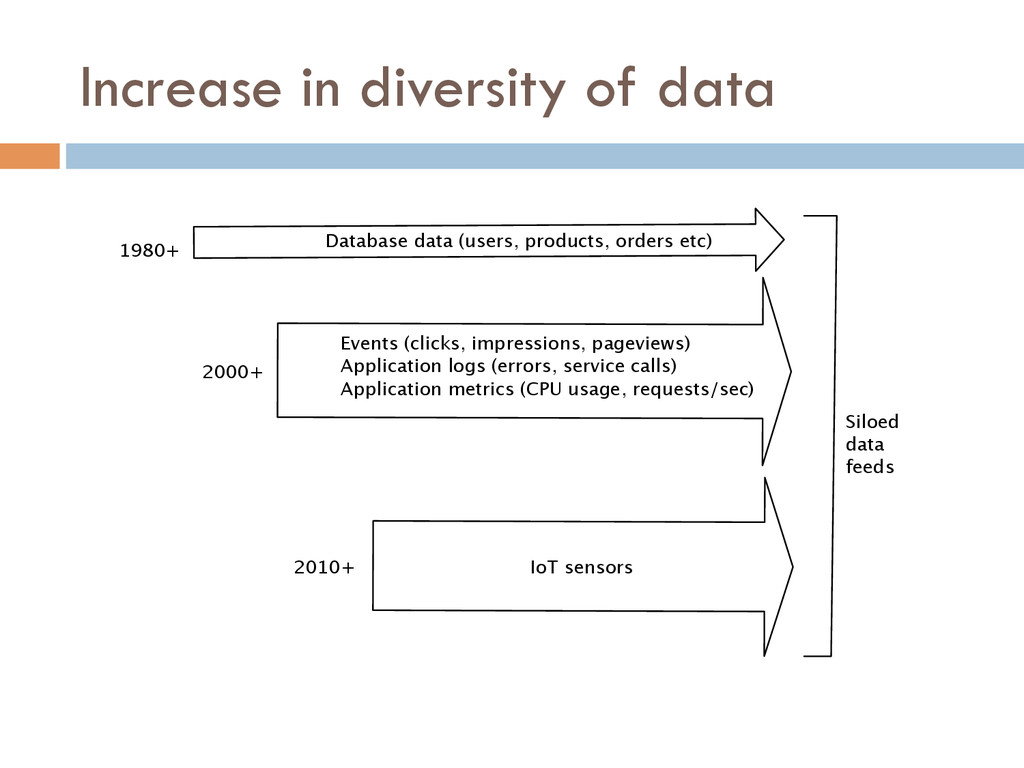
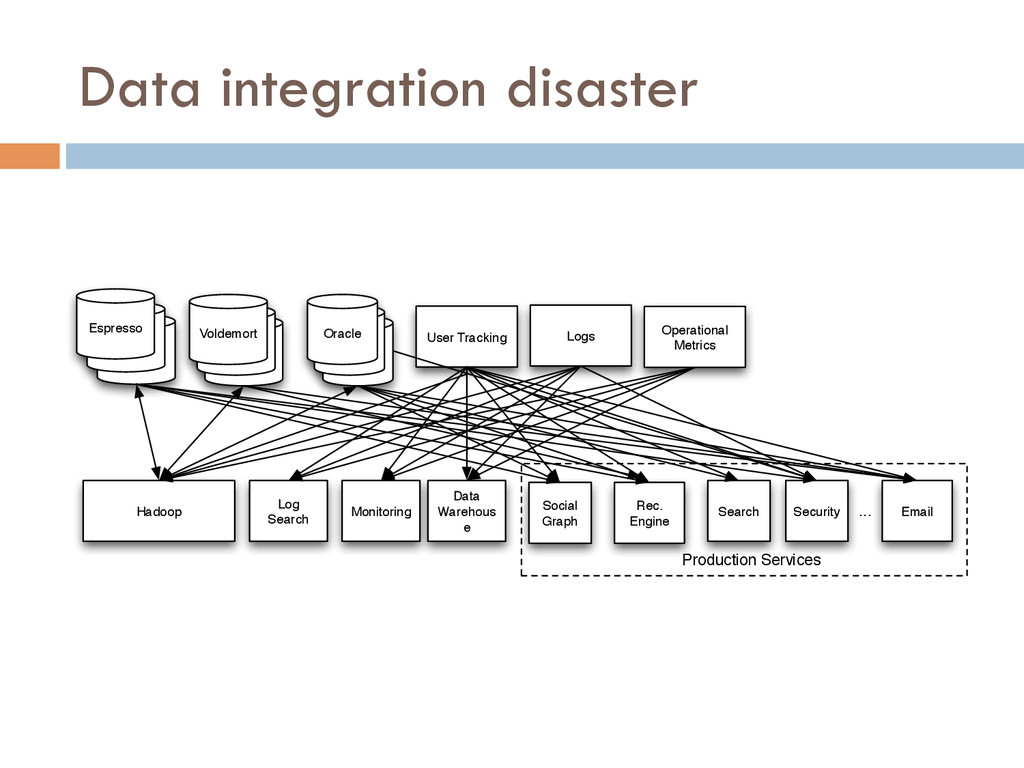
We are enjoying something of a renaissance in data infrastructure. The old workhorses like MySQL and Oracle still exist but they are complemented by new specialized distributed data systems like Cassandra, Redis, Druid, and Hadoop. At the same time what we consider data has changed too--user activity, monitoring, logging and other event data are becoming first class citizens for data driven companies. Taking full advantage of all these systems and the relevant data creates a massive data integration problem. This problem is important to solve as these specialized systems are not very useful in the absence of a complete and reliable data flow.
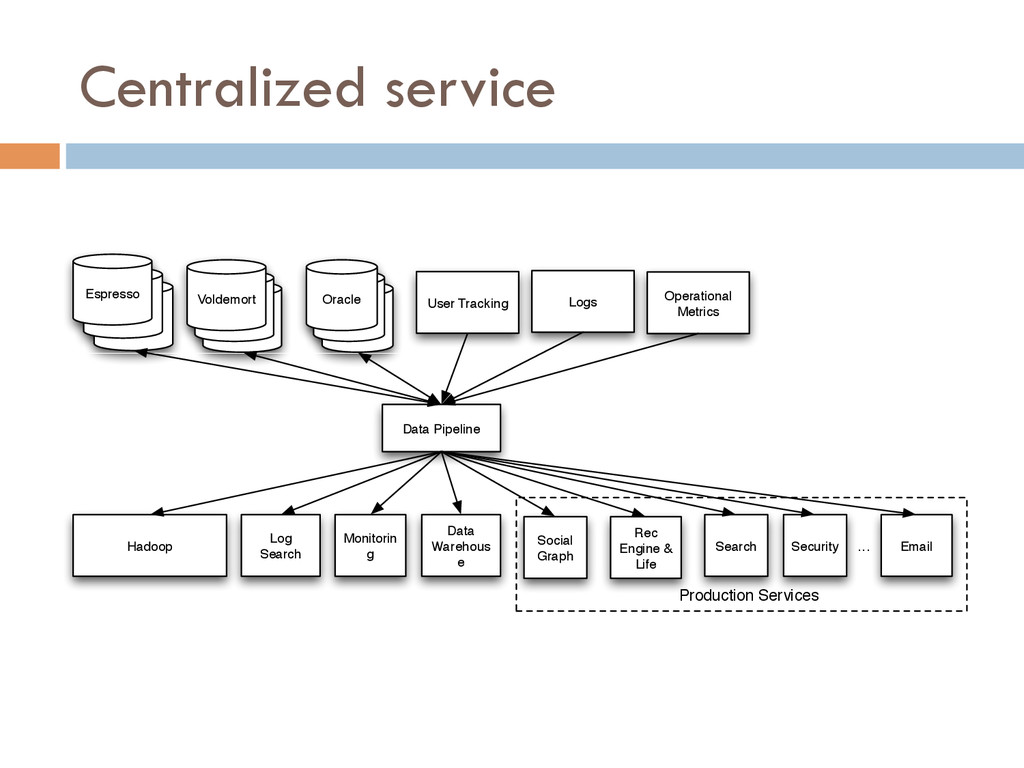
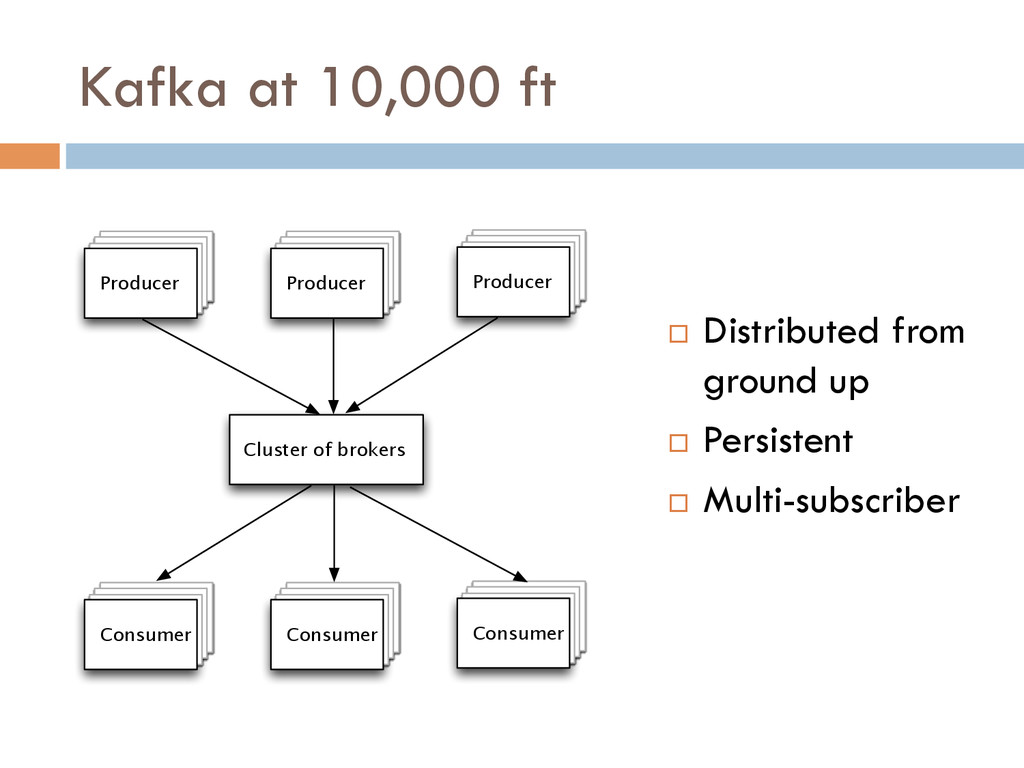
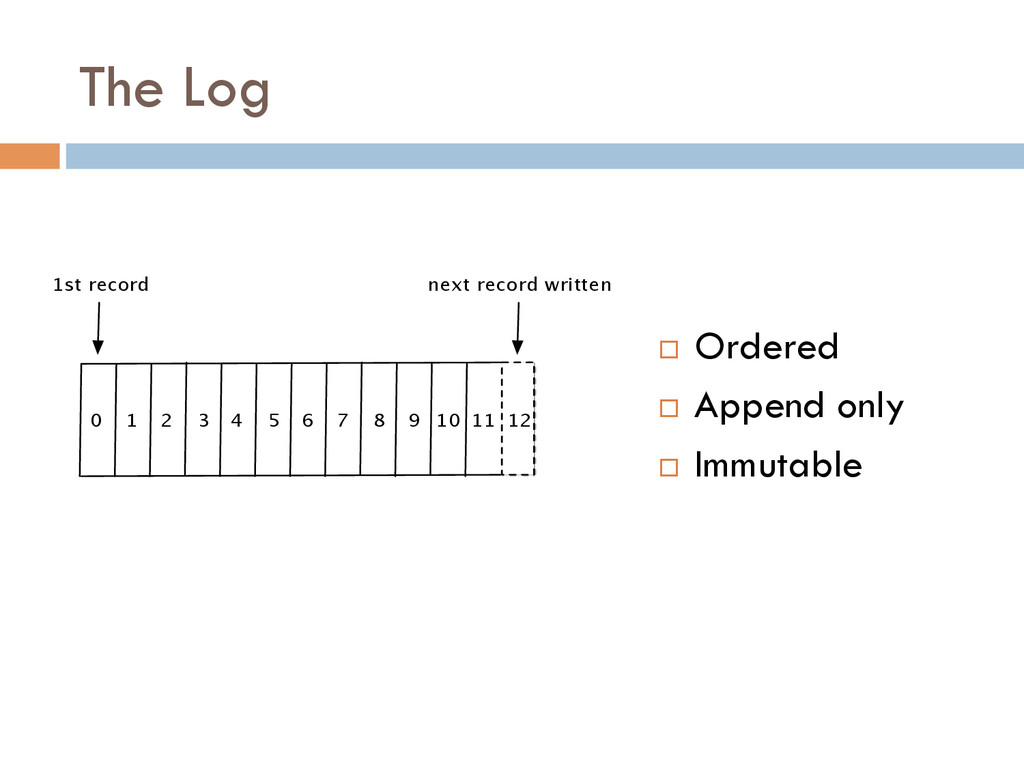
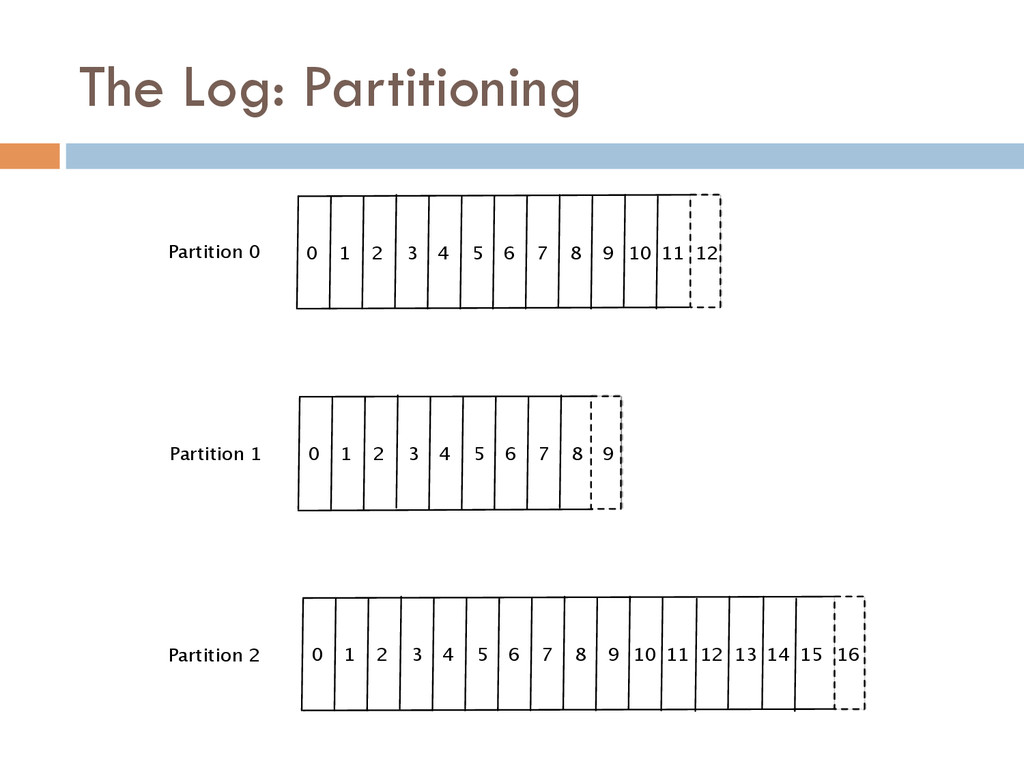
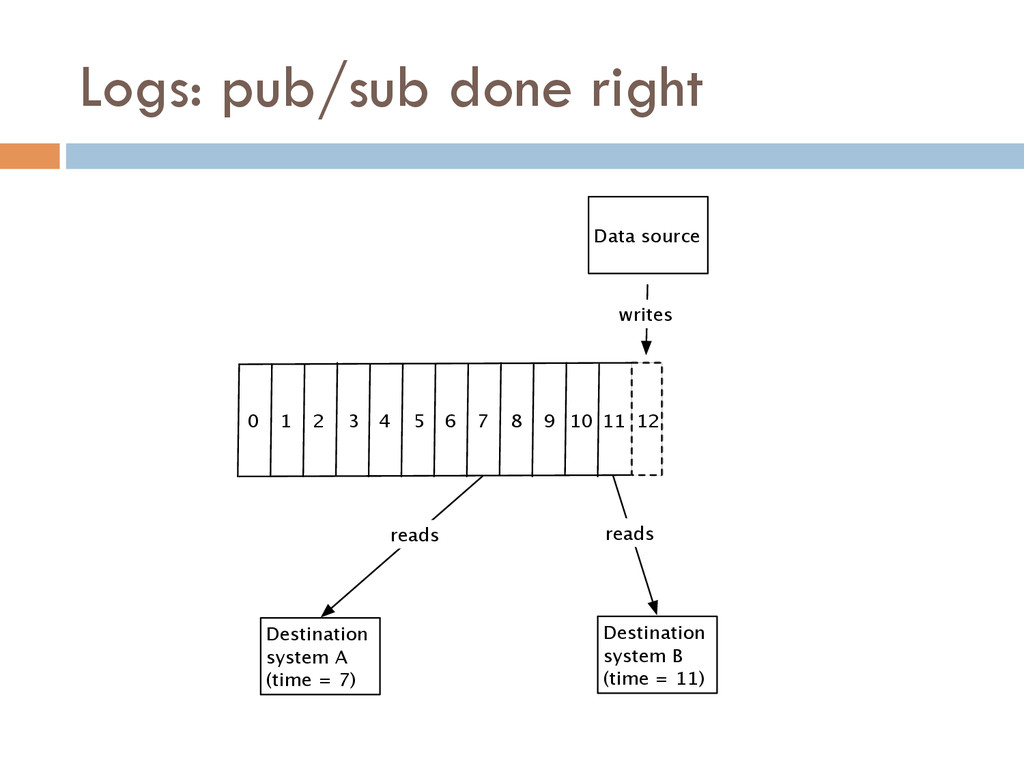
One of the most powerful ways of solving this data integration problem is by restructuring your digital business logic around a centralized firehose of immutable events.
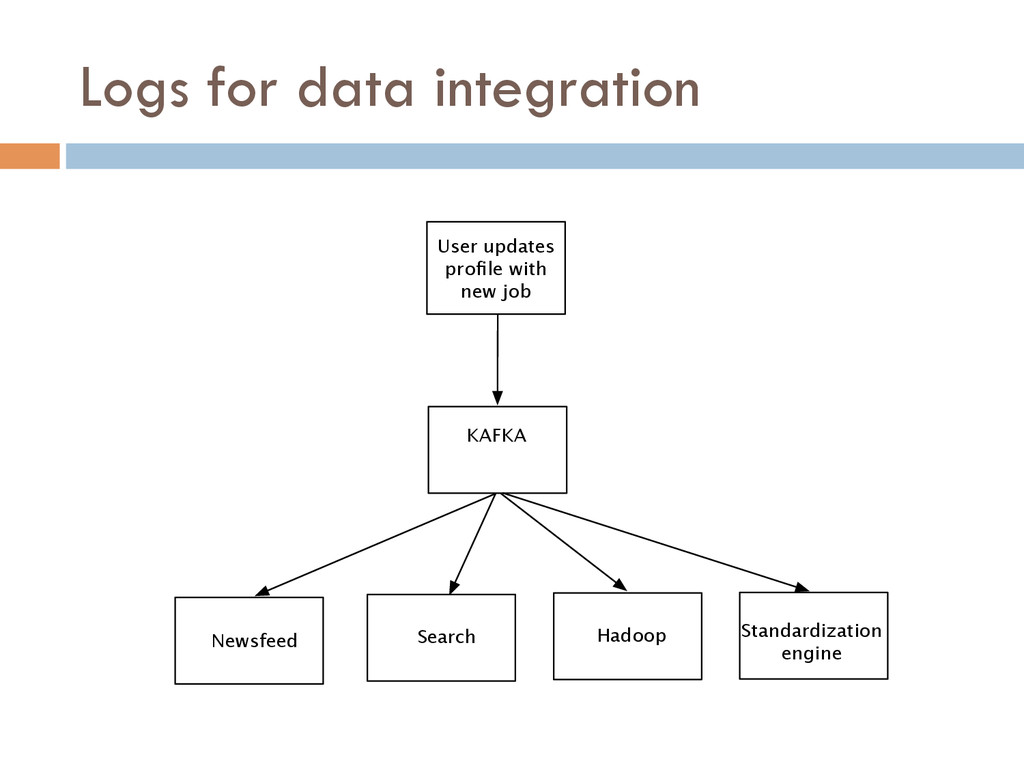
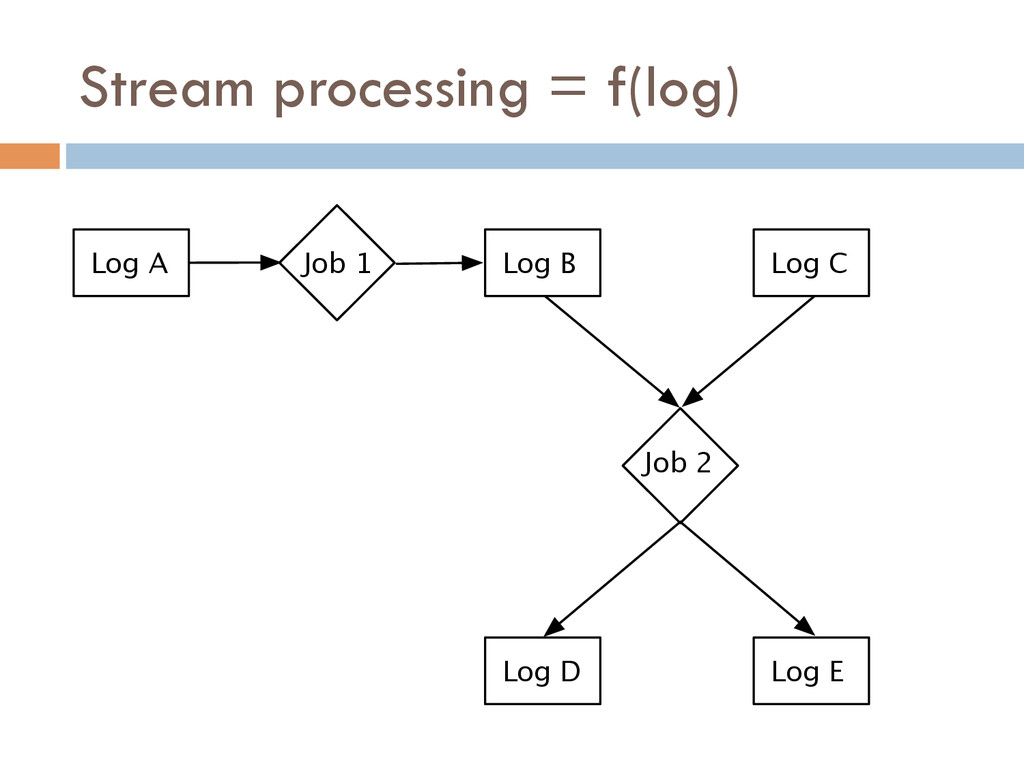
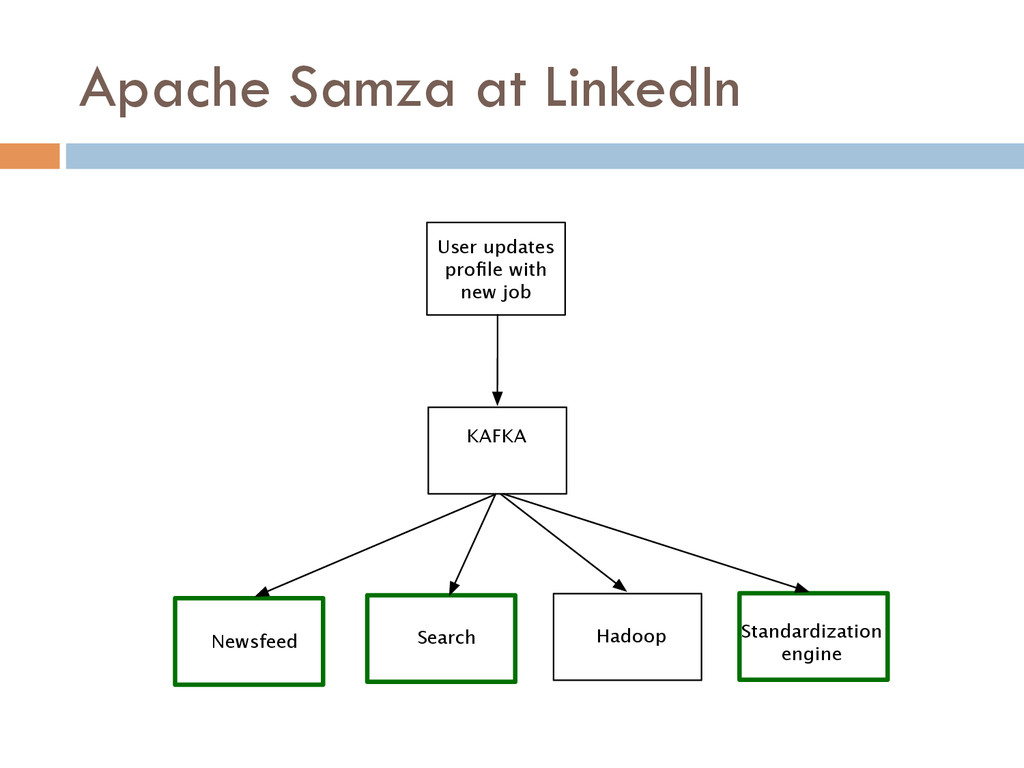
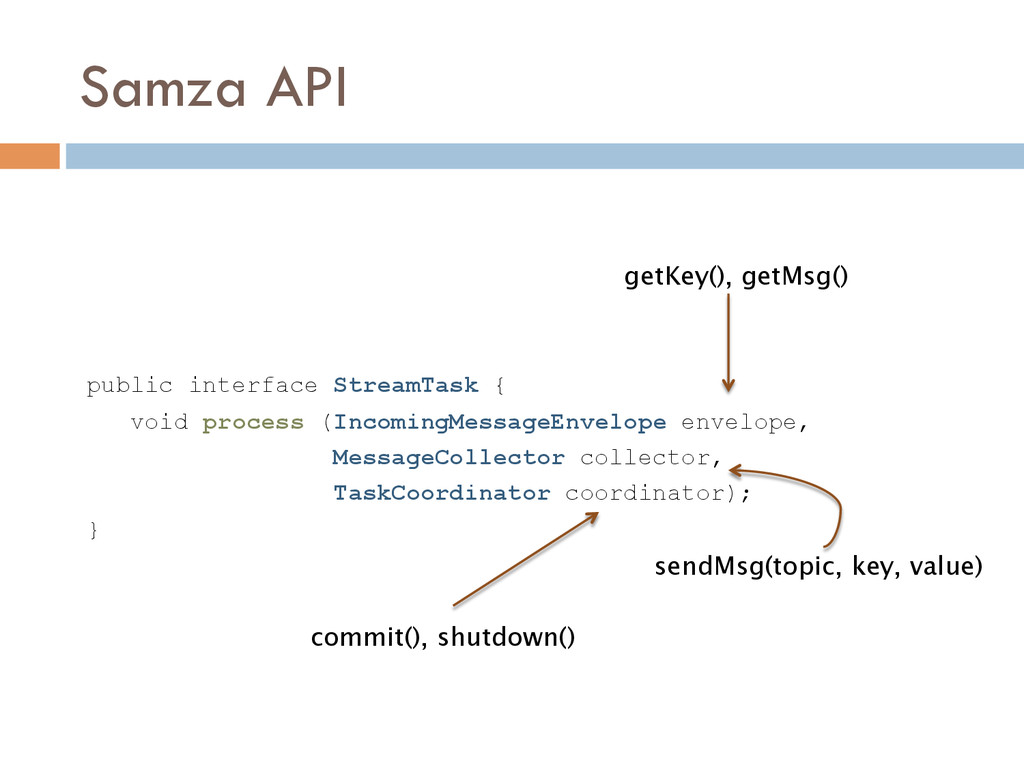
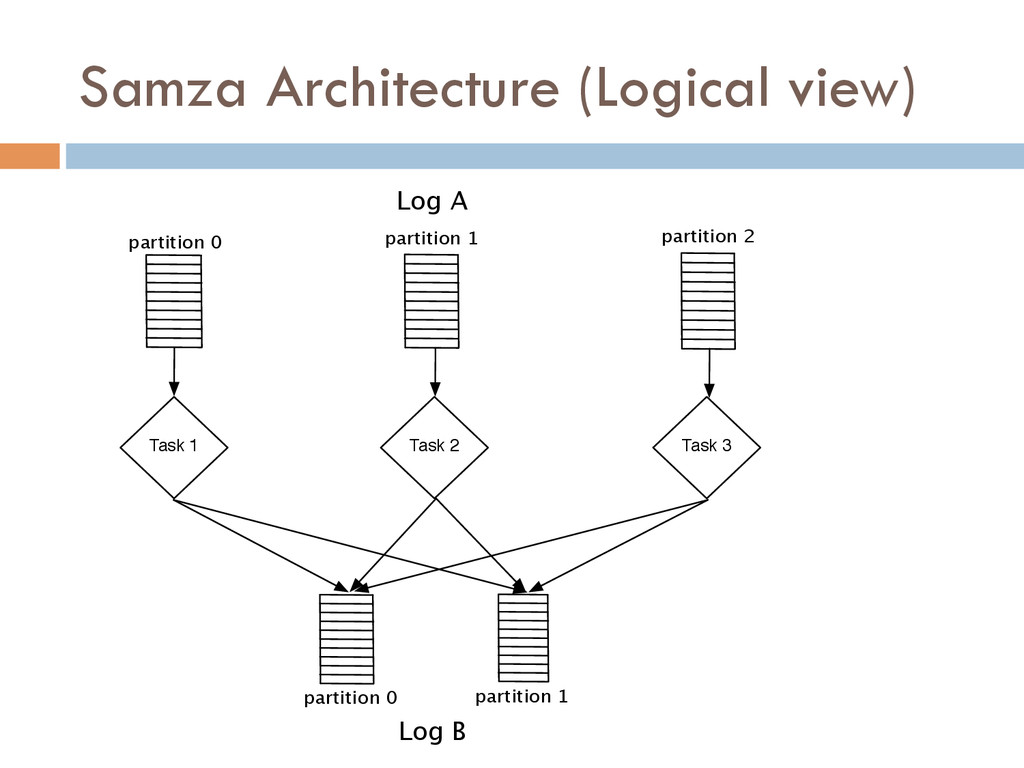
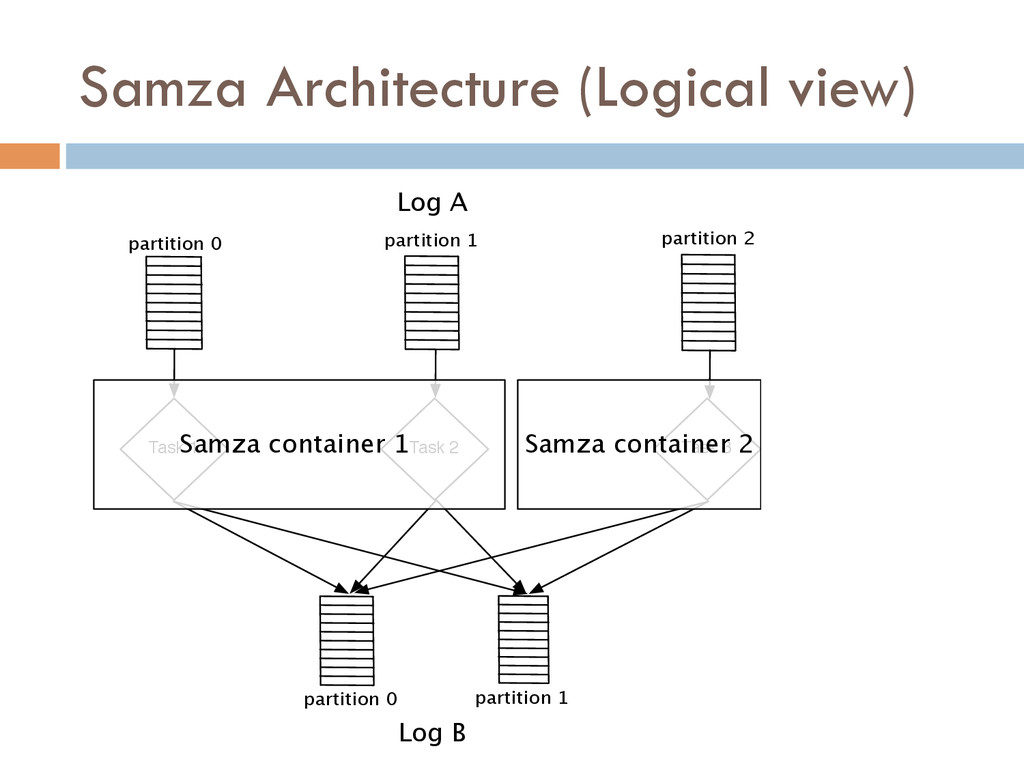
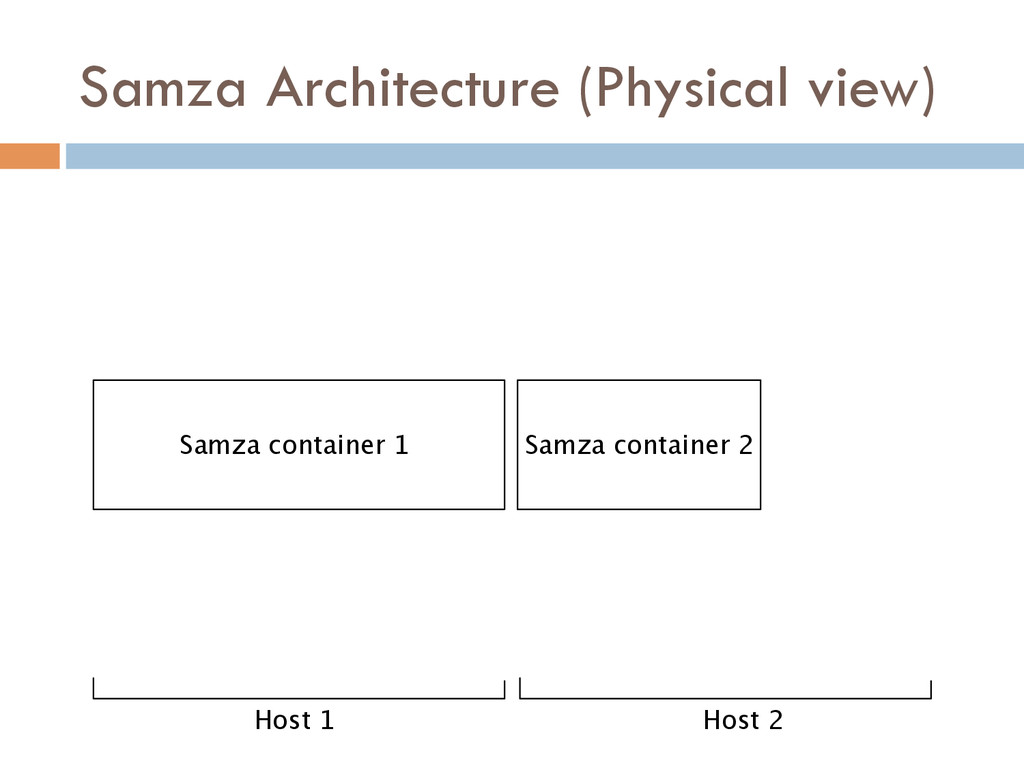
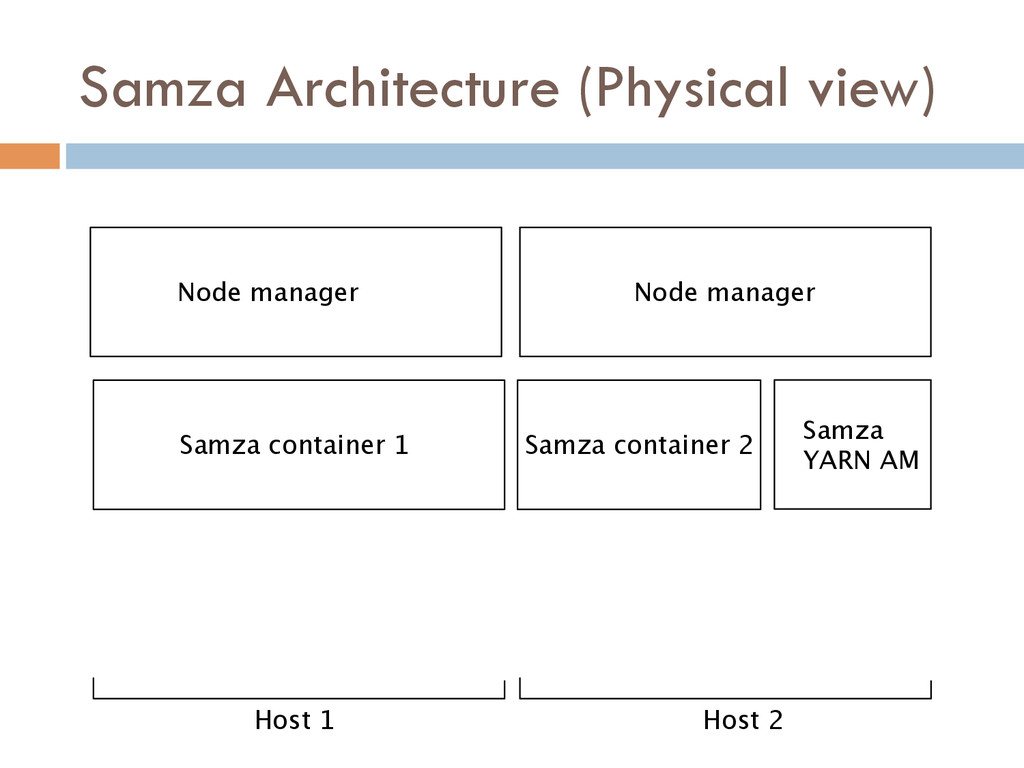
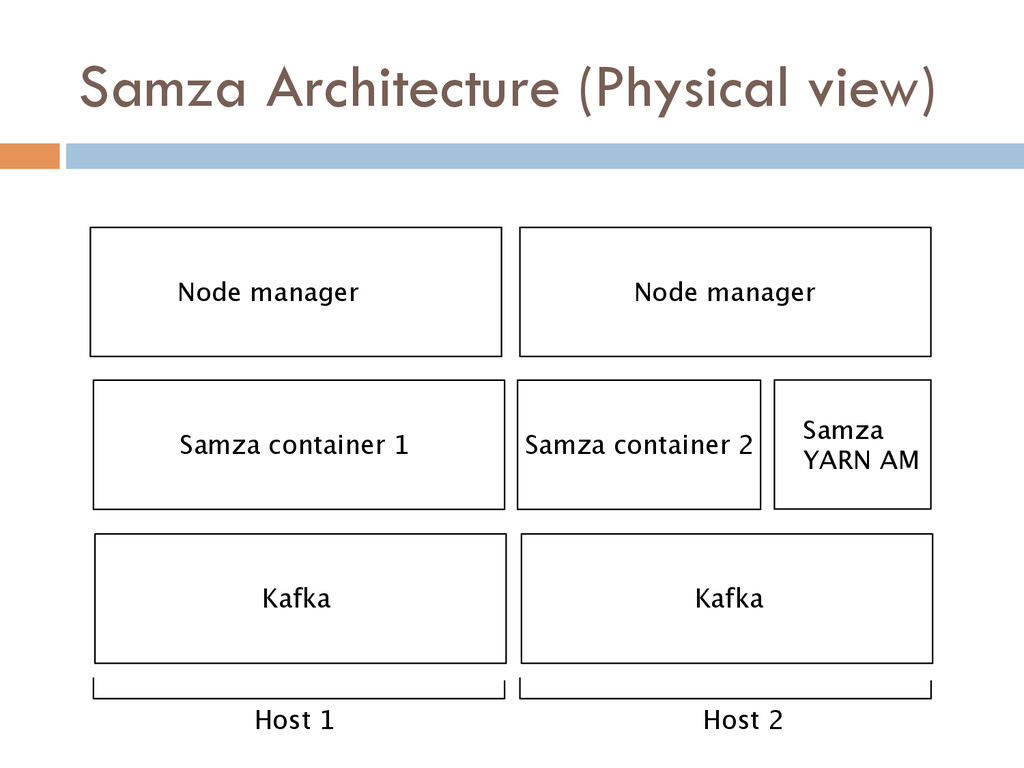
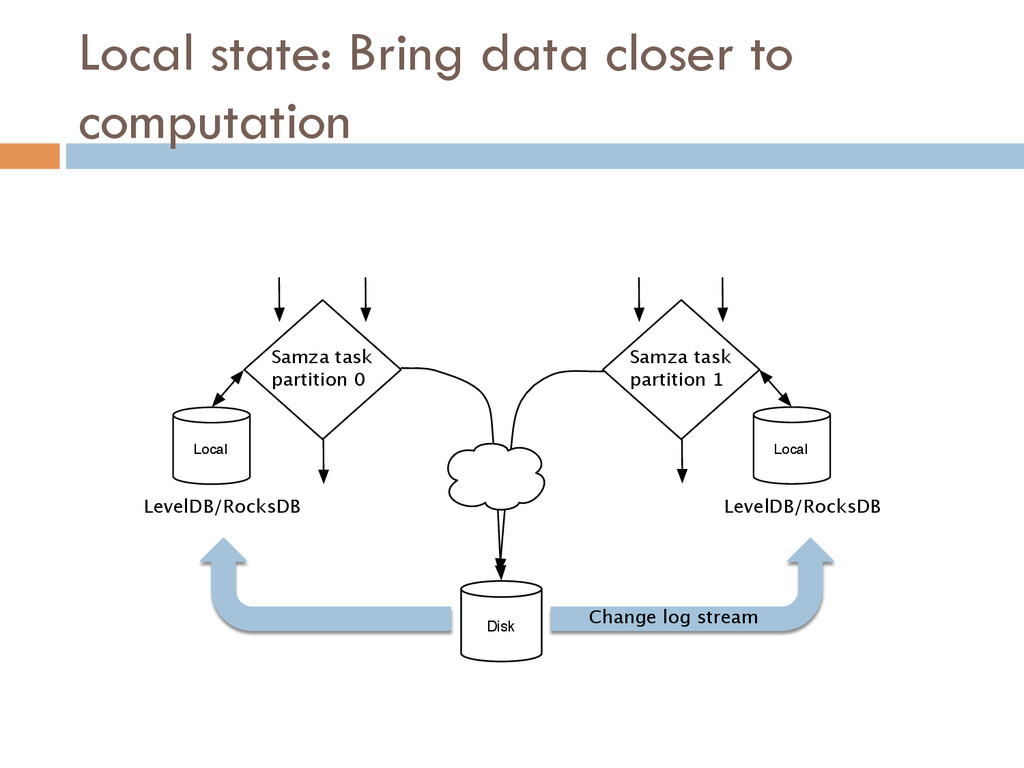
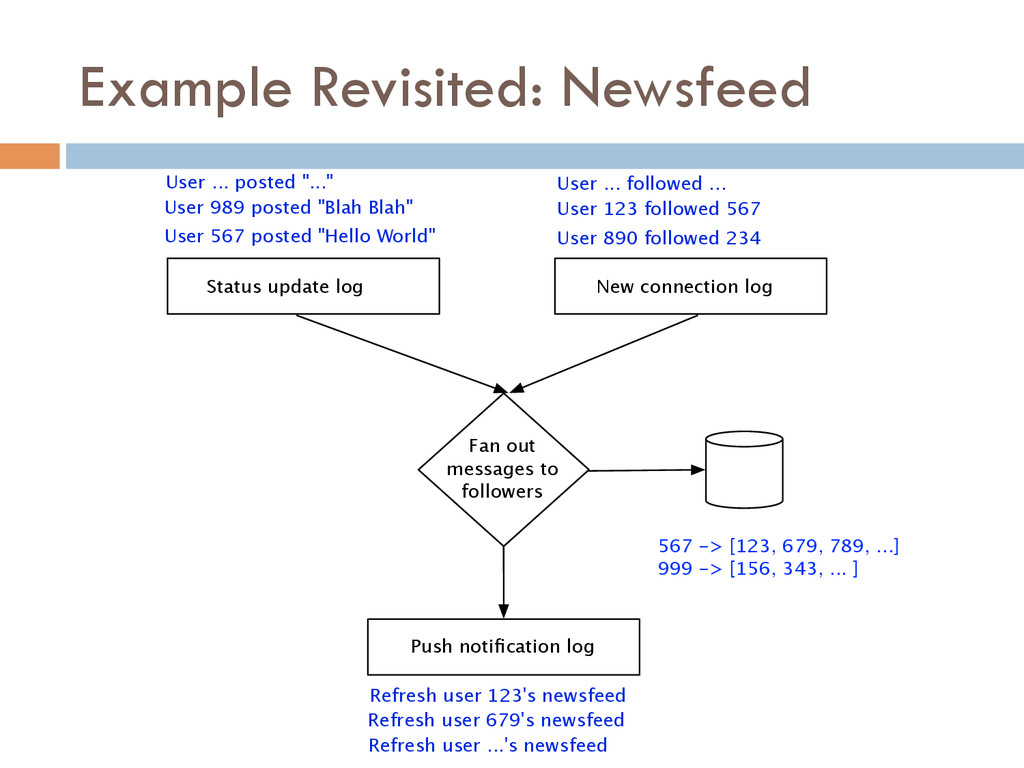
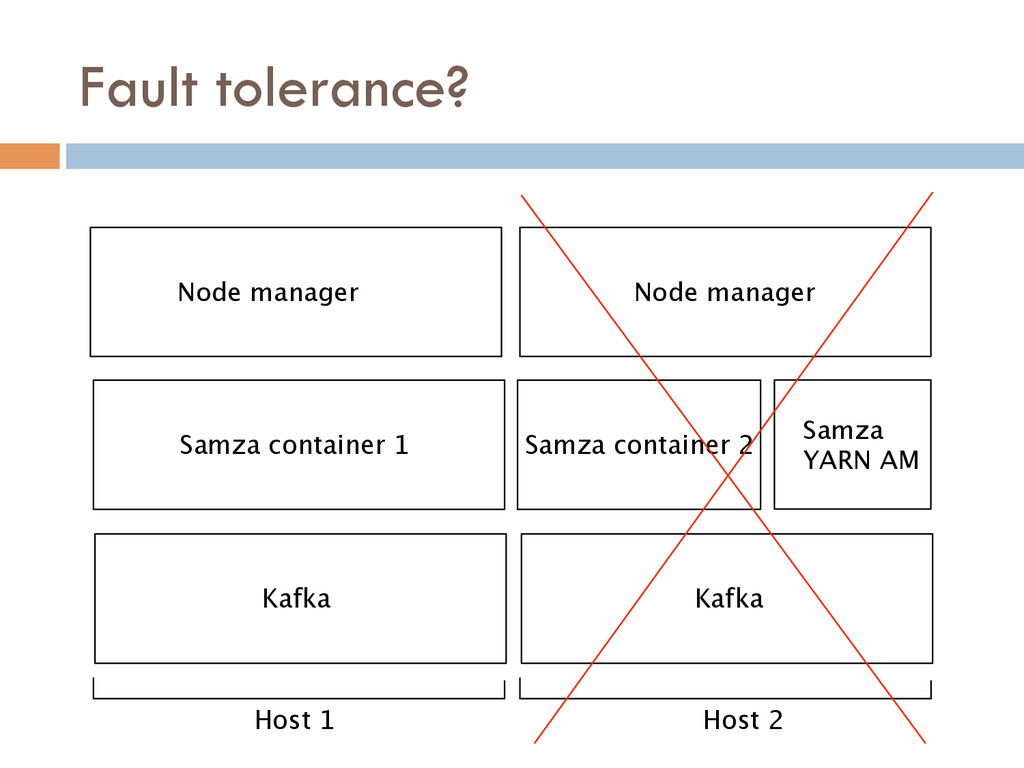
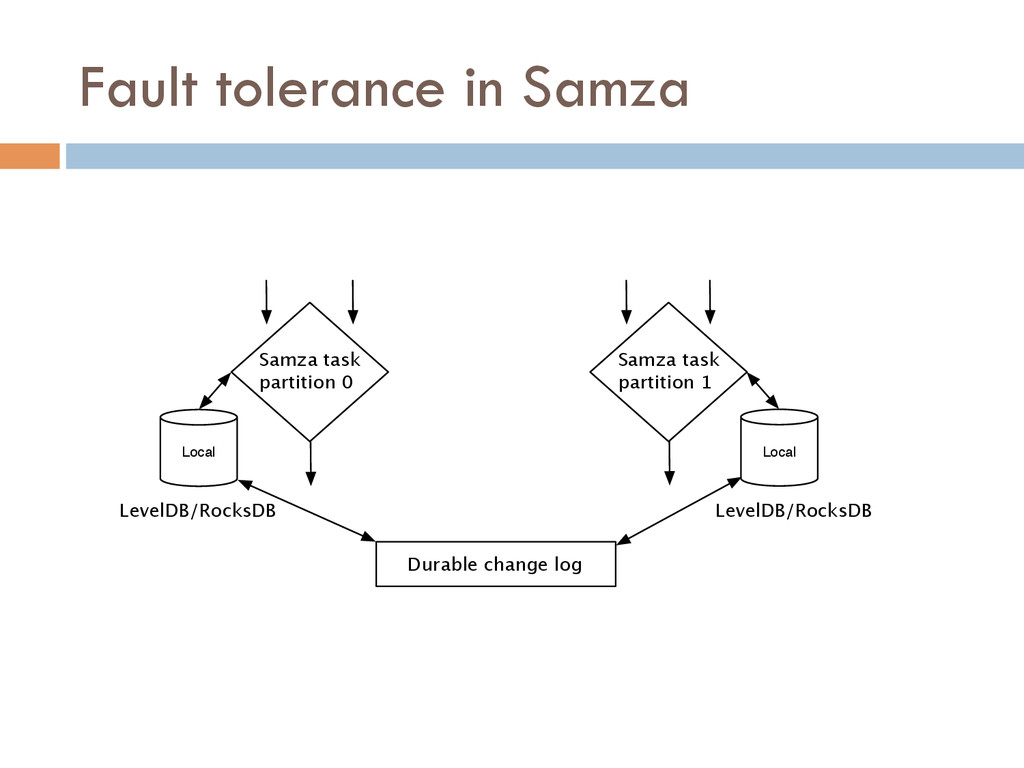
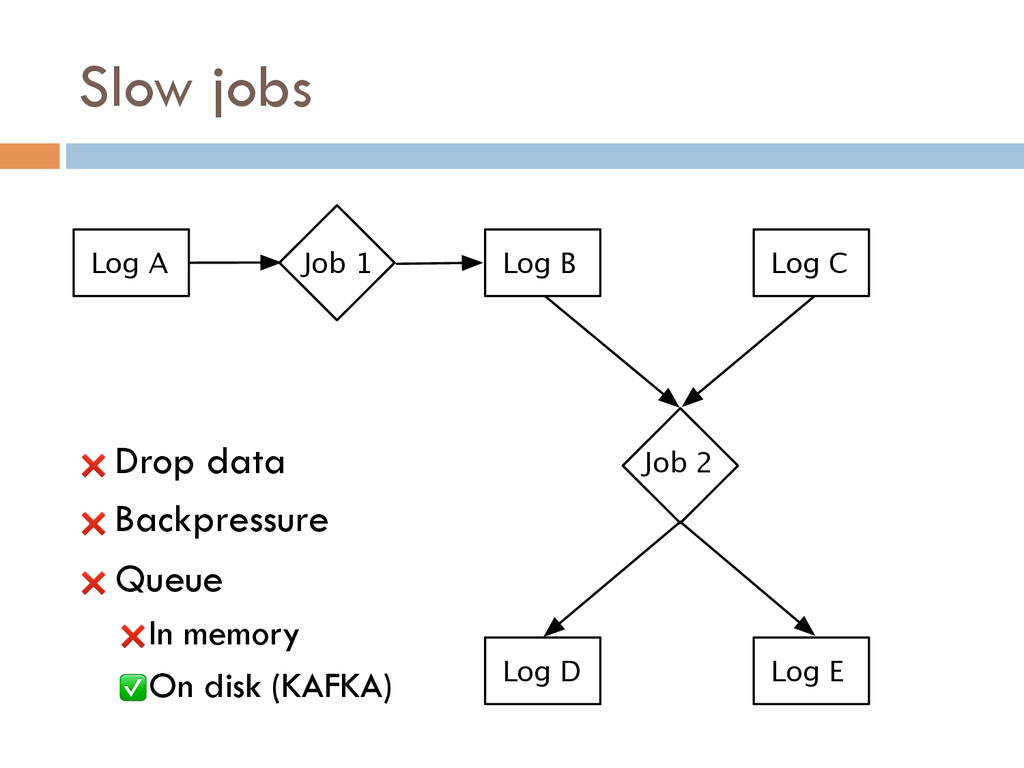
Once your data is captured in real-time and available as real-time subscriptions, you can start to compute new data sets in real-time, off these feeds. This style of stream processing is seen as something of a niche today but the model is extremely powerful and general. Much of what people compute offline in systems like Hadoop can also be done in real-time as data arrives using a stream-processing model. On top of these real-time data feeds, we can run continual processing and transformations to derive new data feeds (which are themselves logs) and publish these in the same way. We have open sourced our stream processing layer, Apache Samza[http://samza.incubator.apache.org/], which does this.
In this talk, I will share our experience of successfully building LinkedIn’s data pipeline infrastructure around Kafka and Samza. These lessons are hugely relevant to anyone building a data driven company.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
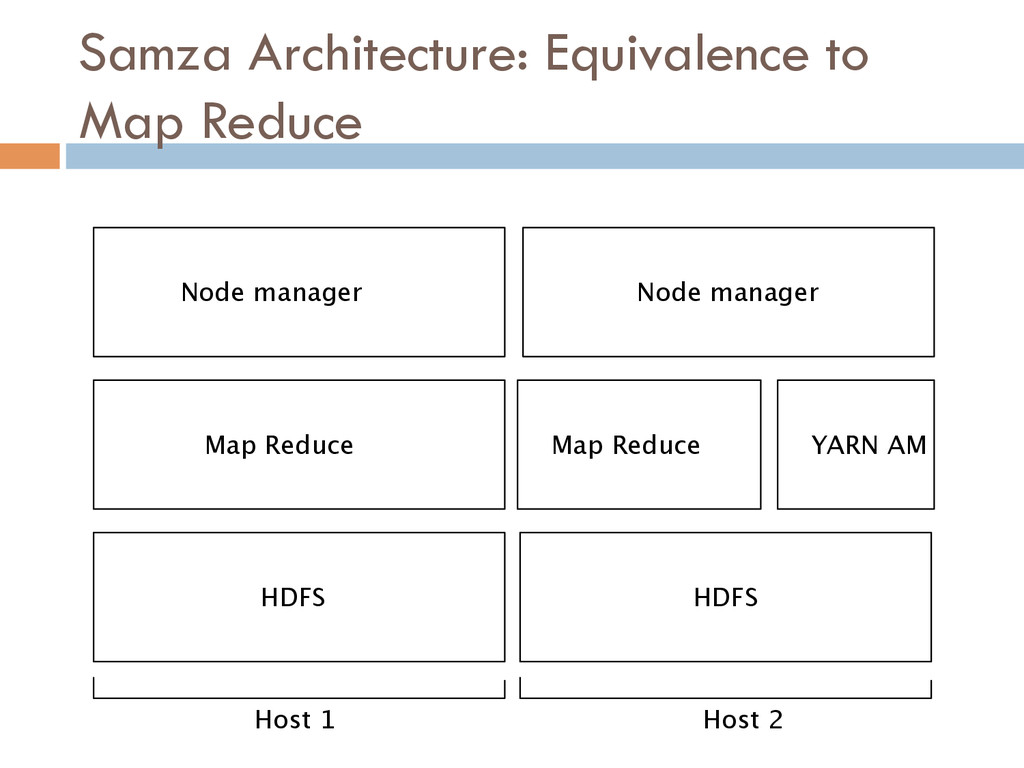{kind=link}
{kind=link}
{kind=link}
{kind=link}
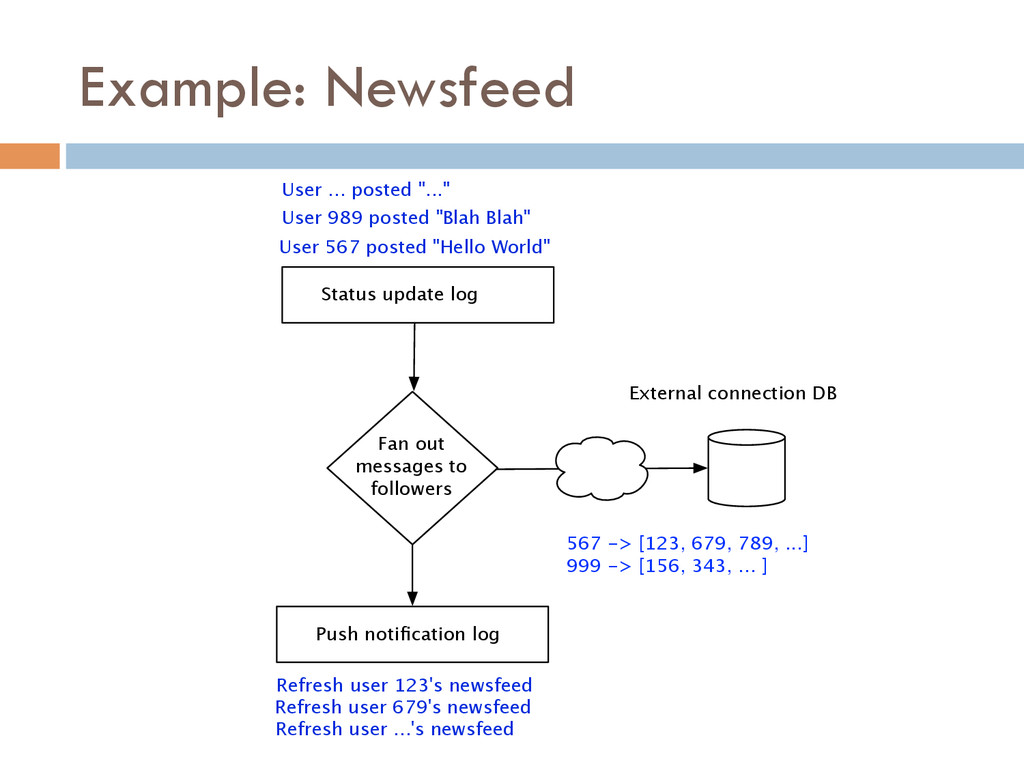{kind=link}
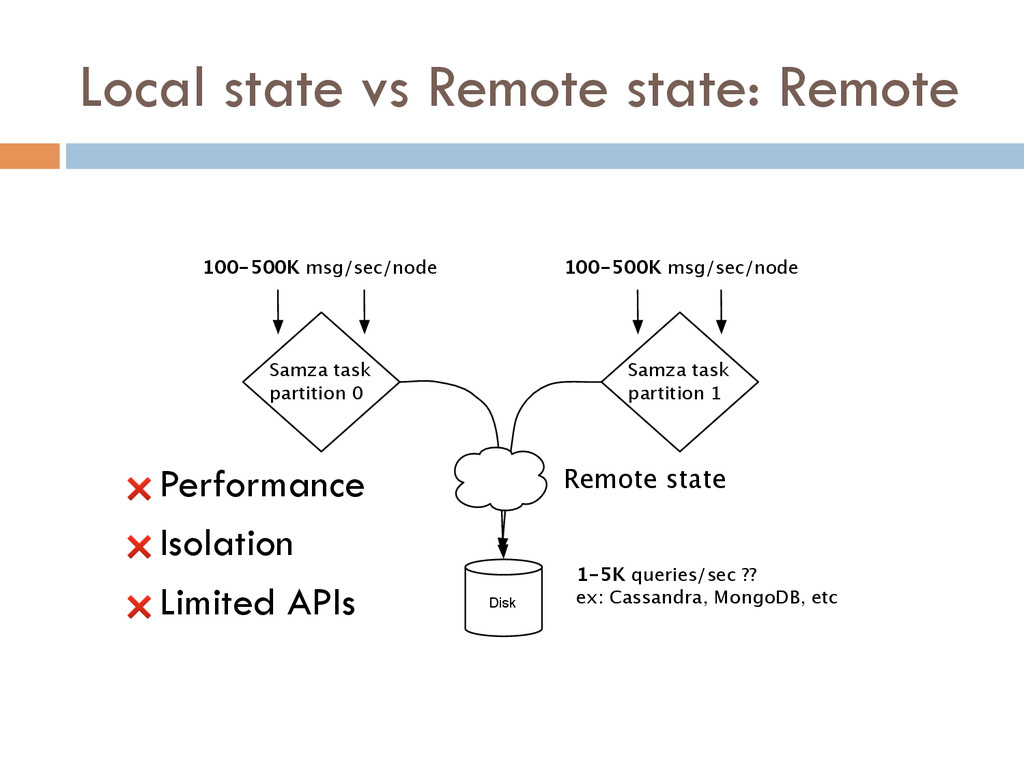{kind=link}
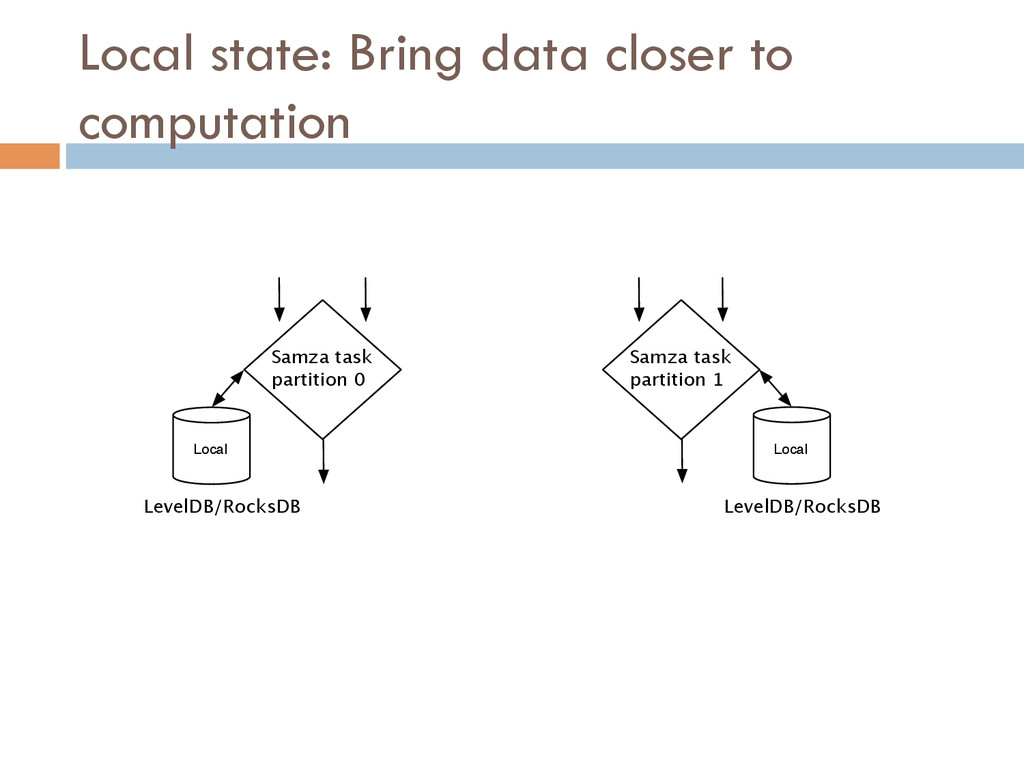{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}