Production-quality Mesos frameworks must be able to continue managing tasks despite unreliable networks and faulty computers. Mesos provides tools to help developers do fault-tolerant task management, but putting these tools together effectively remains something of a black art. This talk will offer practical guidance to framework developers to help them understand how Mesos deals with failures and the tools it provides to enable fault tolerant frameworks. The talk will also cover new Mesos features that allow framework developers to control how partitioned tasks should be handled. Mesos operators will also benefit from a discussion of exactly how Mesos behaves during network partitions and other failure scenarios.
{kind=link}
{kind=link}
{kind=link}
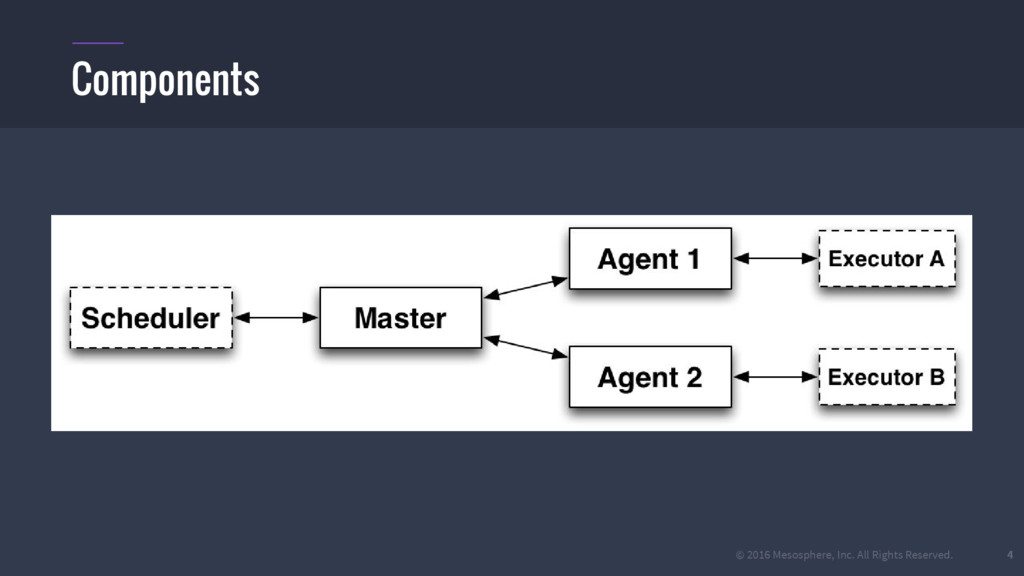{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
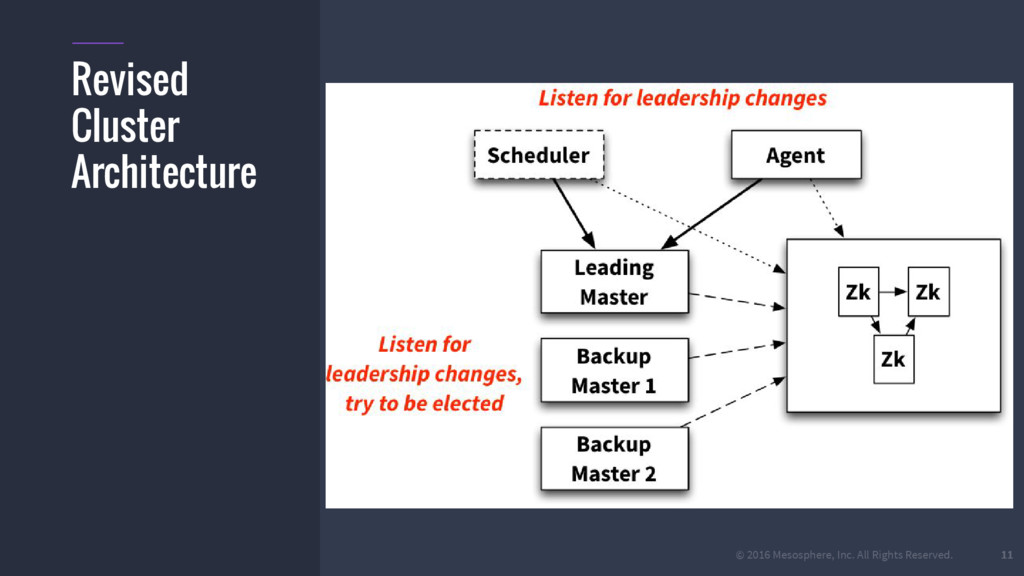{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
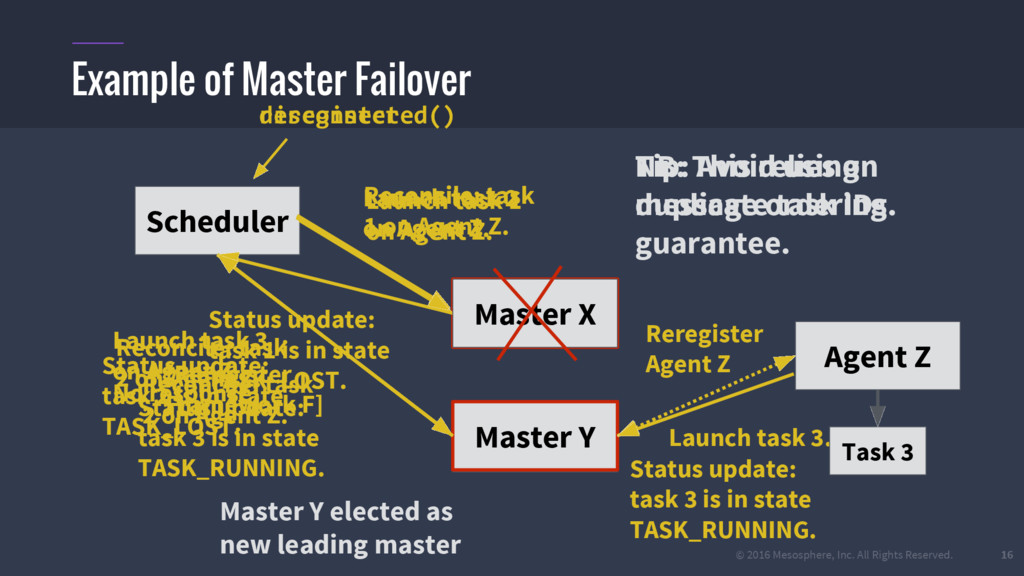{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
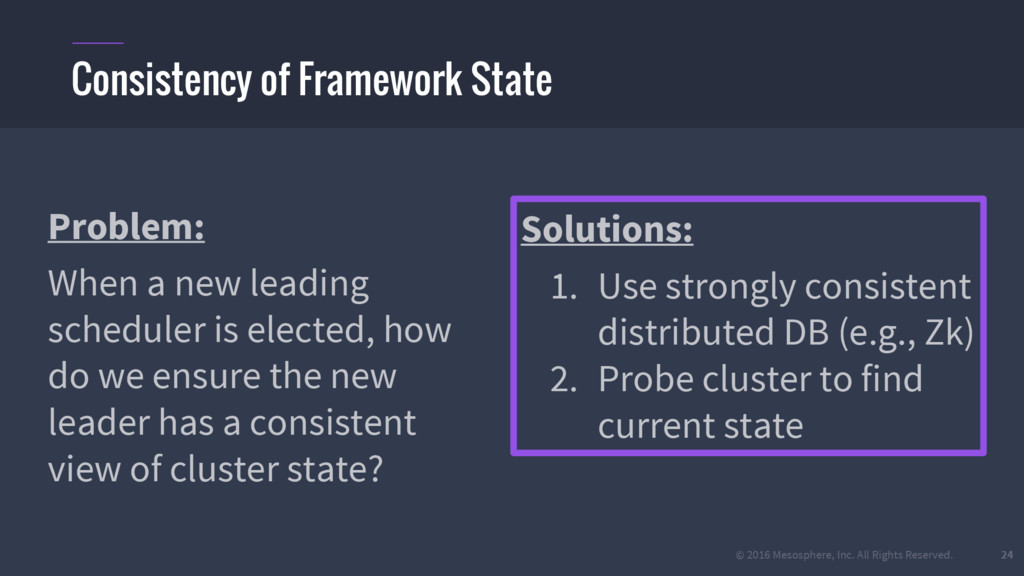{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}