Alon Halevy, Chris Olston, Alkis, Avery Ching Hazy Research Group Ce, Sen, Feiran, Alex, Theo, Ivan, Michael FitzPatrick, Henry, Jason, Steve, Stephen, Matteo, Chris Aberger & De Sa Nobu, Masayuki, Yuichi TOSHIBA Gill Bejerano, Johannes, and all DeepDive users Feng, Zifei, Raphael, Xiao LATTICE Reading & Oral Committee Parag Mallick Peter Bailis Kunle Olukotun InfoLab Jure, Jeff, Gio, Rok, Semih, Vikesh, Steven, Hyunjung, Akash, Manas, Saint, Vasilis, Asif, Andrej Mike Cafarella Hector Jennifer Andreas
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
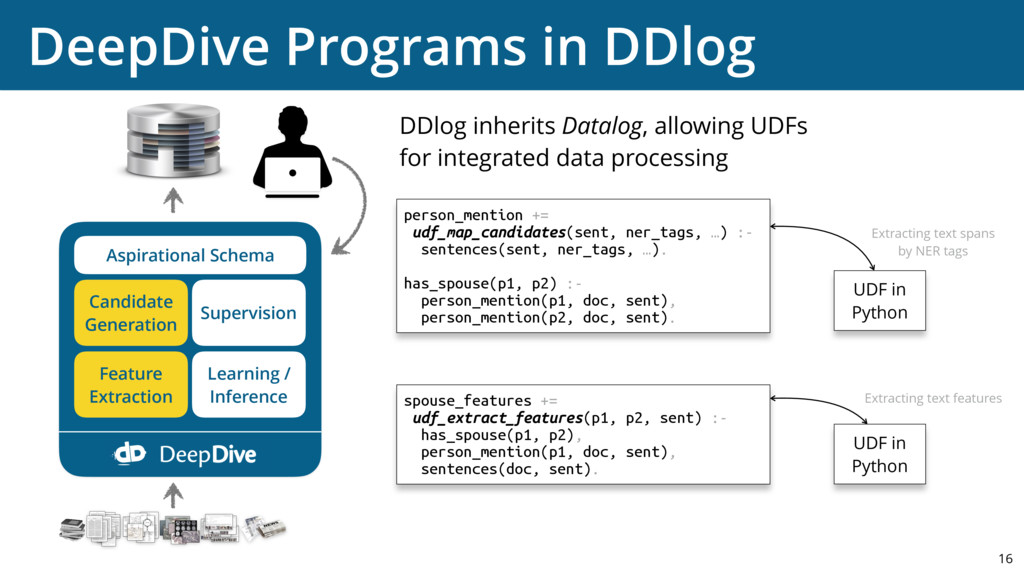{kind=link}
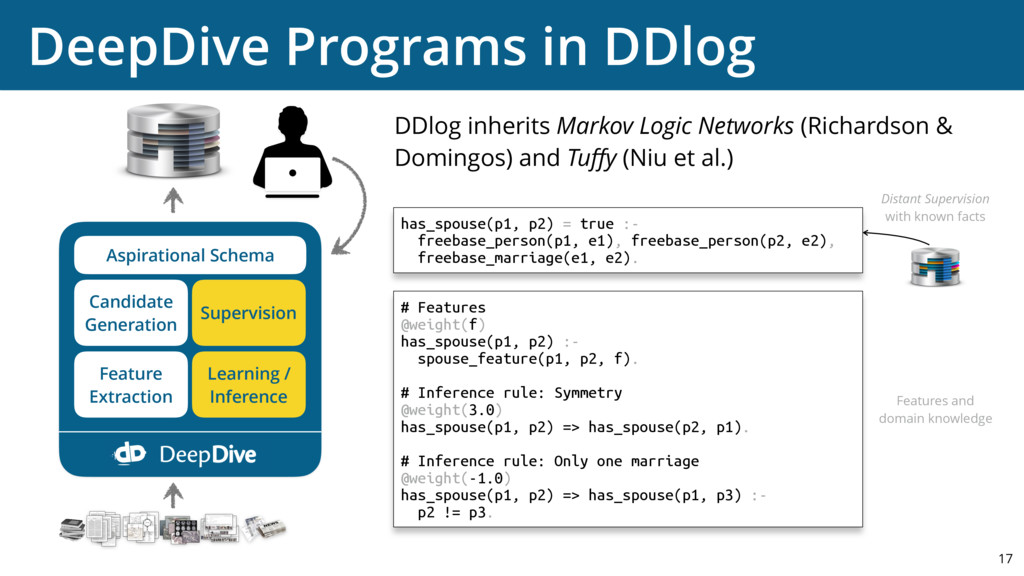{kind=link}
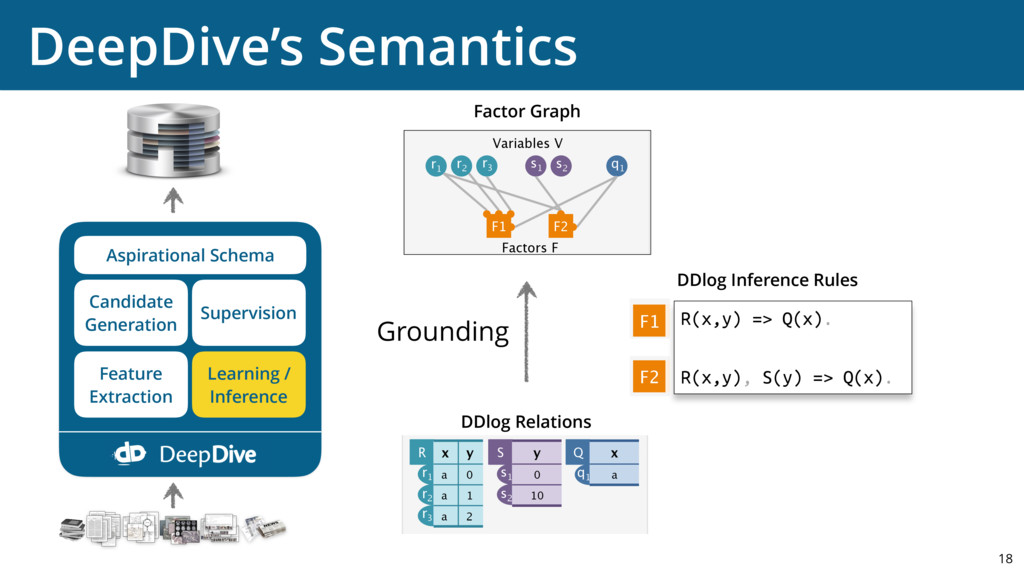{kind=link}
{kind=link}
{kind=link}
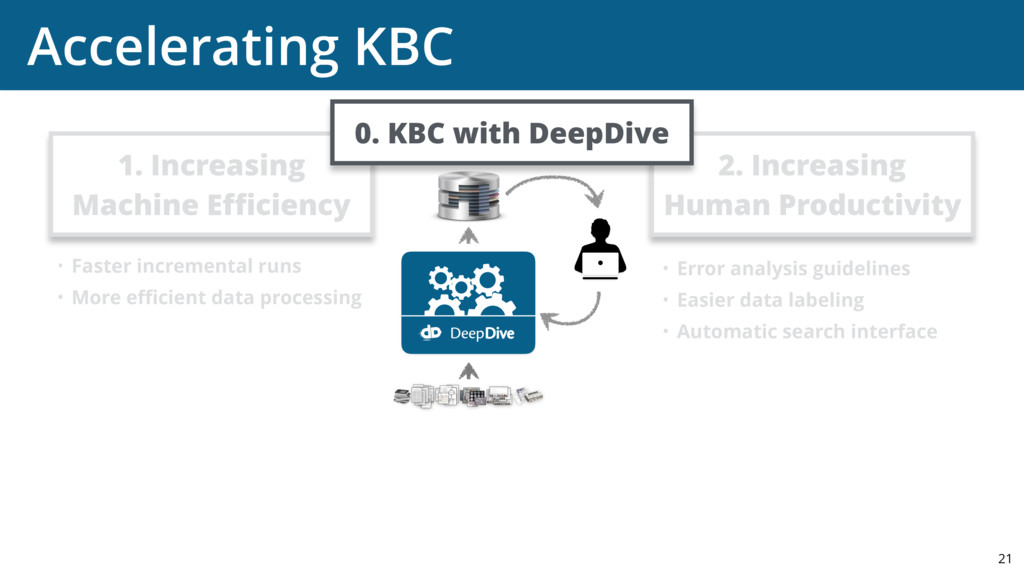{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
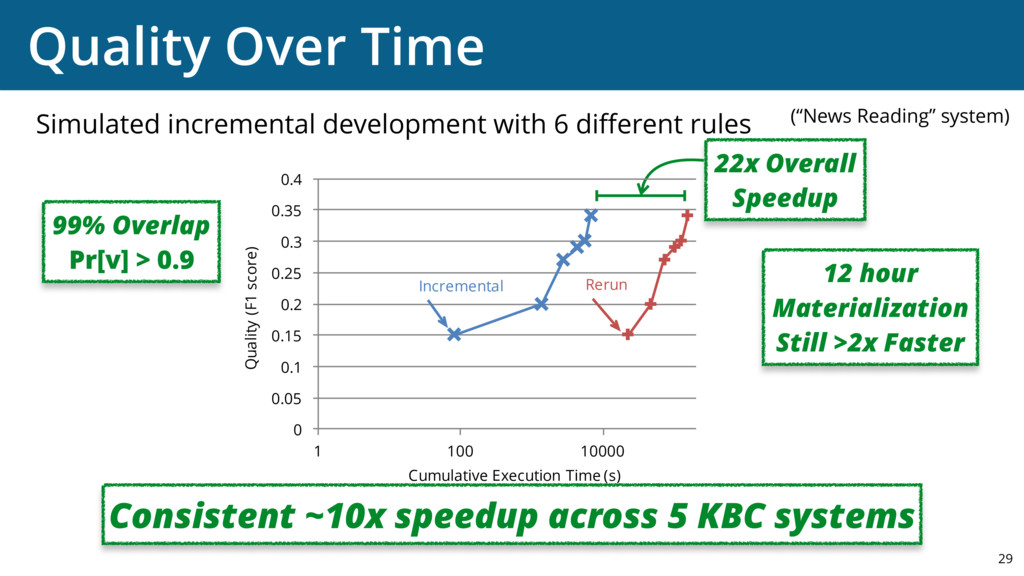{kind=link}
{kind=link}
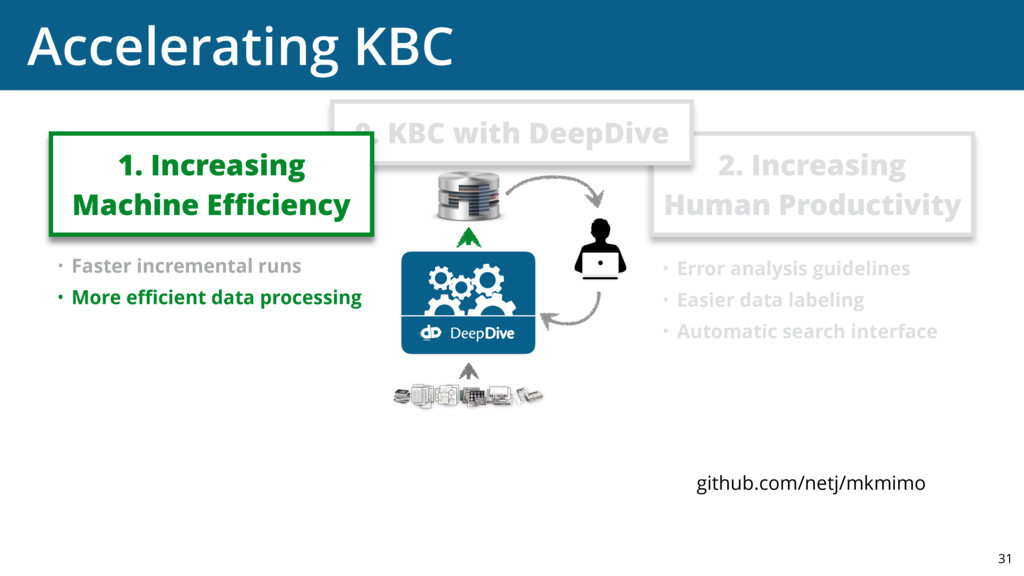{kind=link}
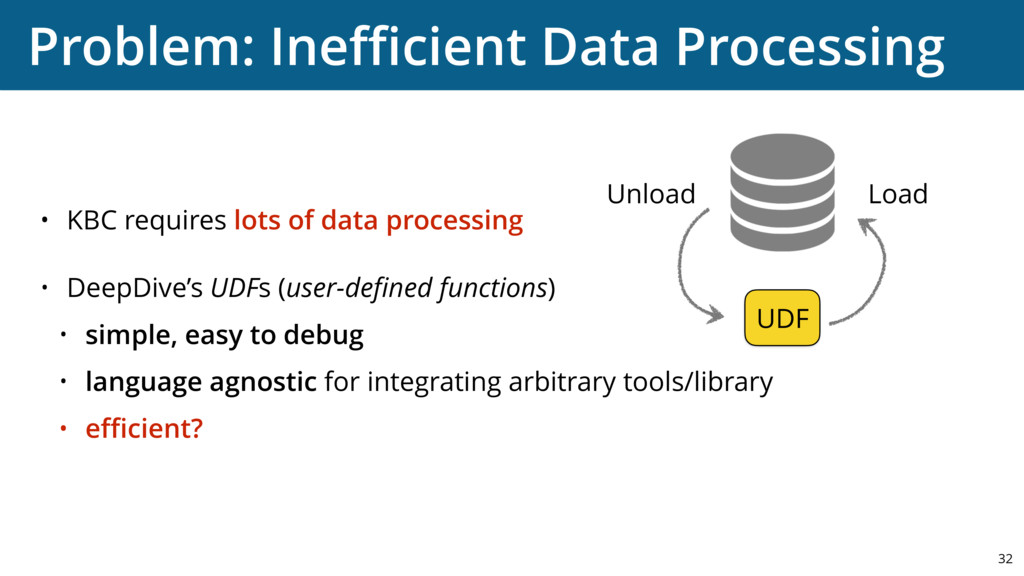{kind=link}
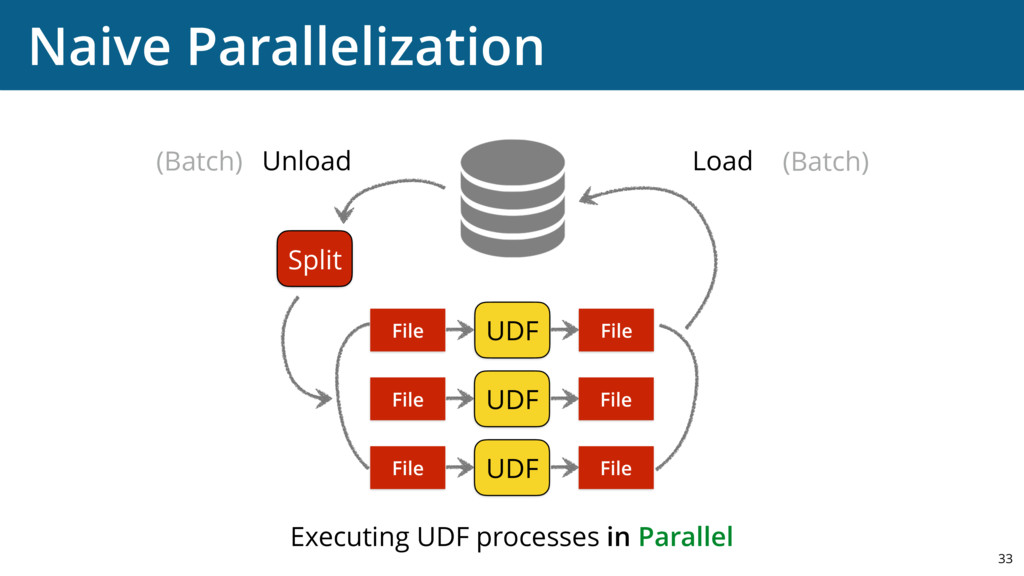{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
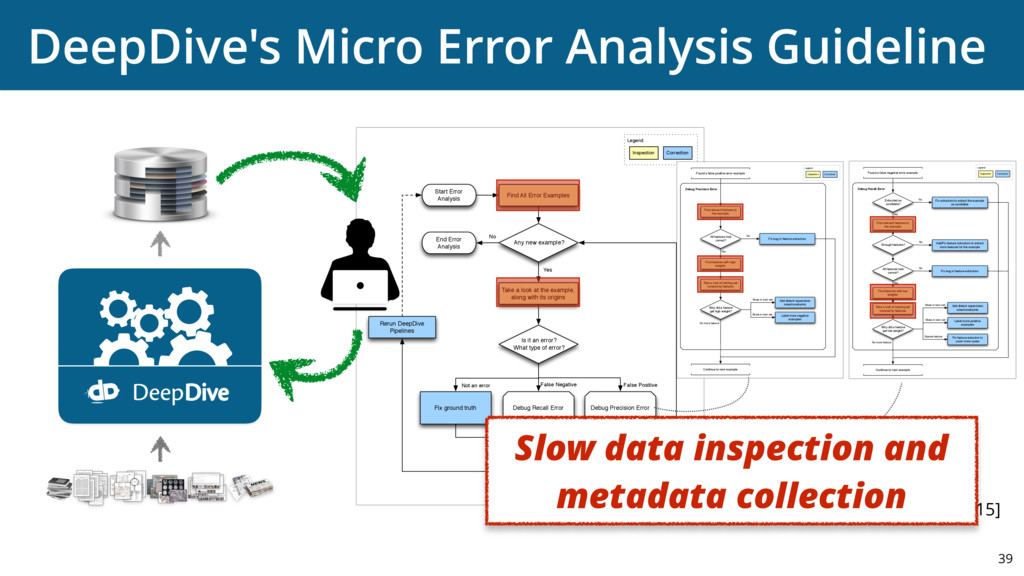{kind=link}
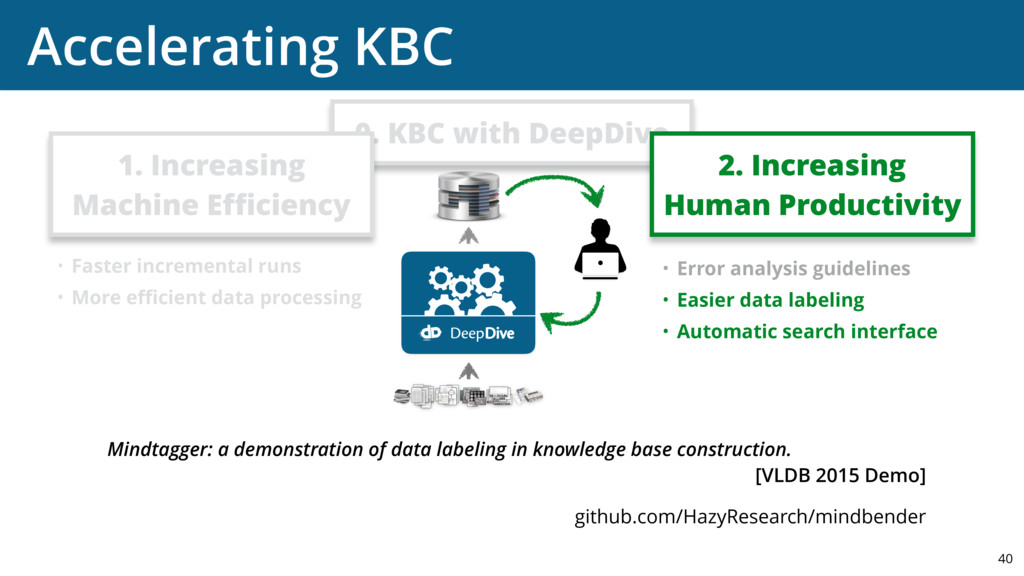{kind=link}
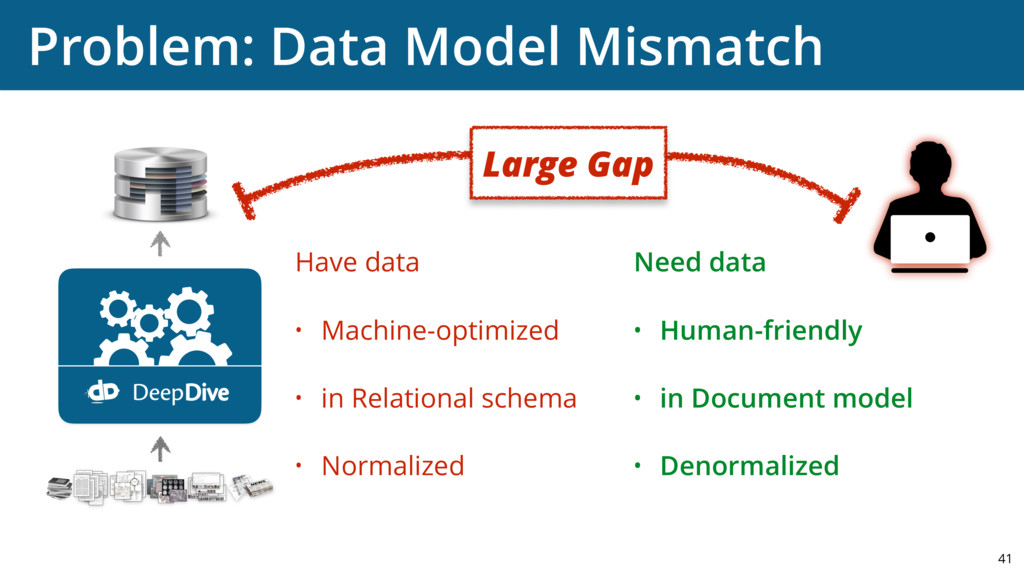{kind=link}
{kind=link}
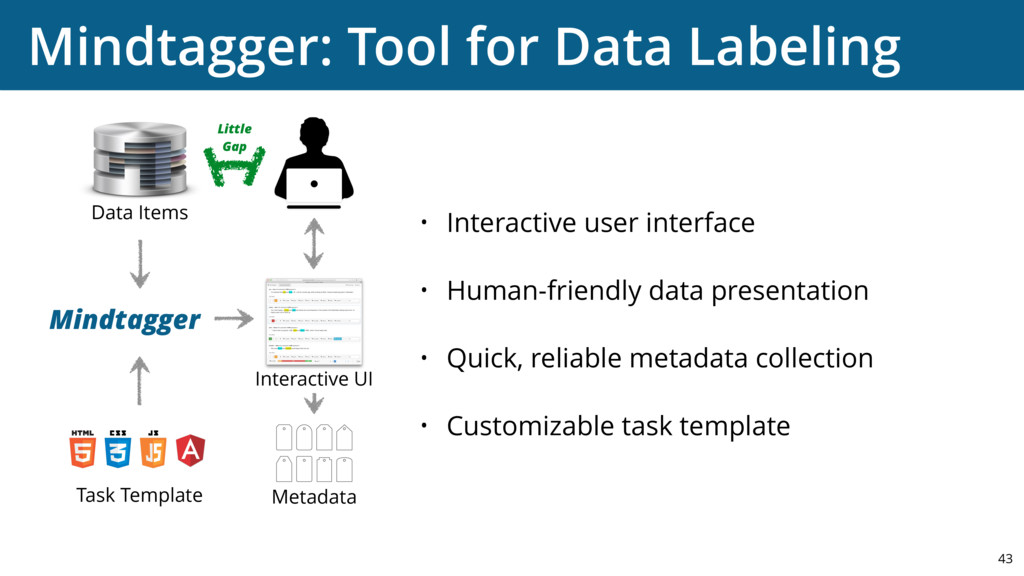{kind=link}
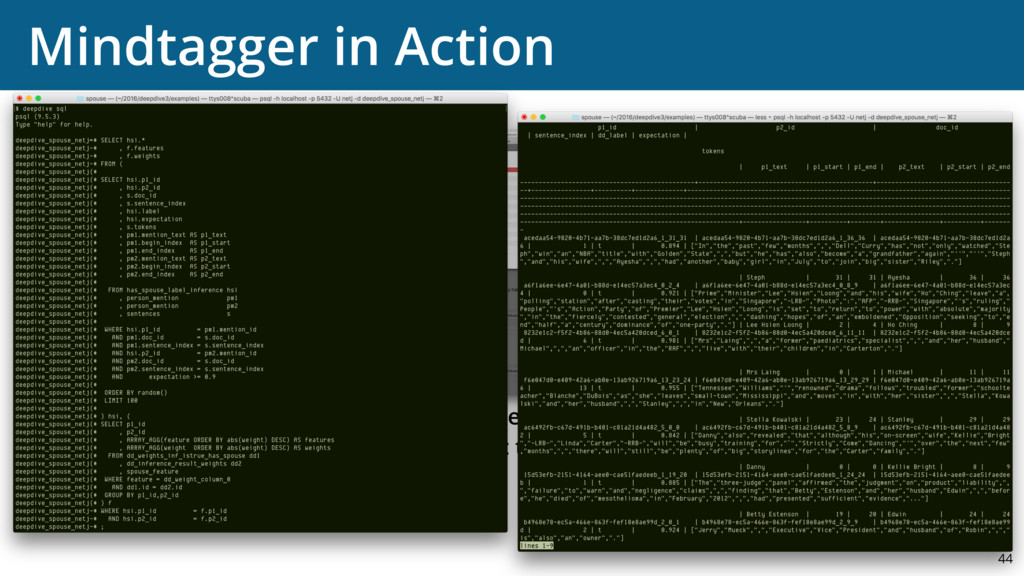{kind=link}
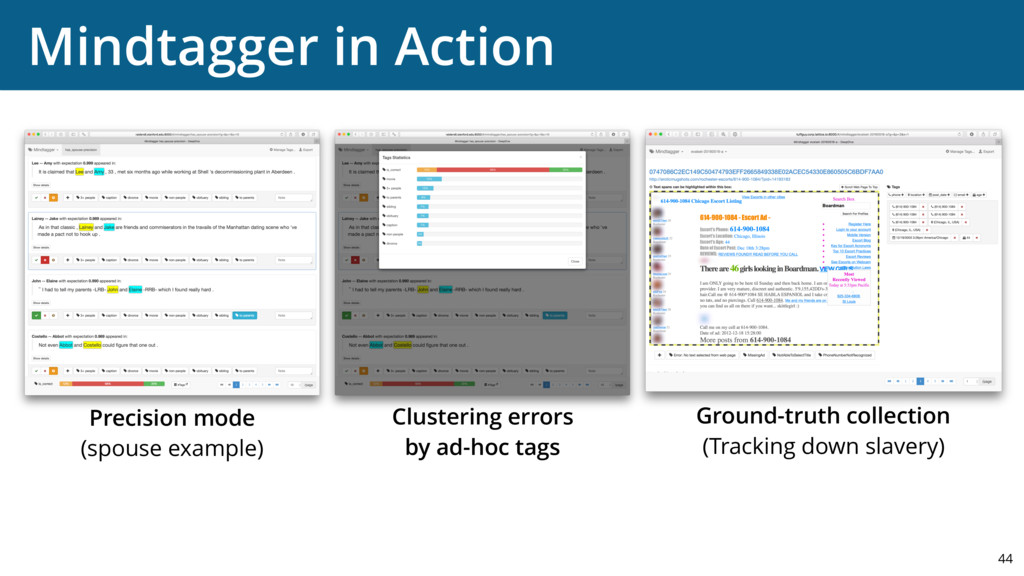{kind=link}
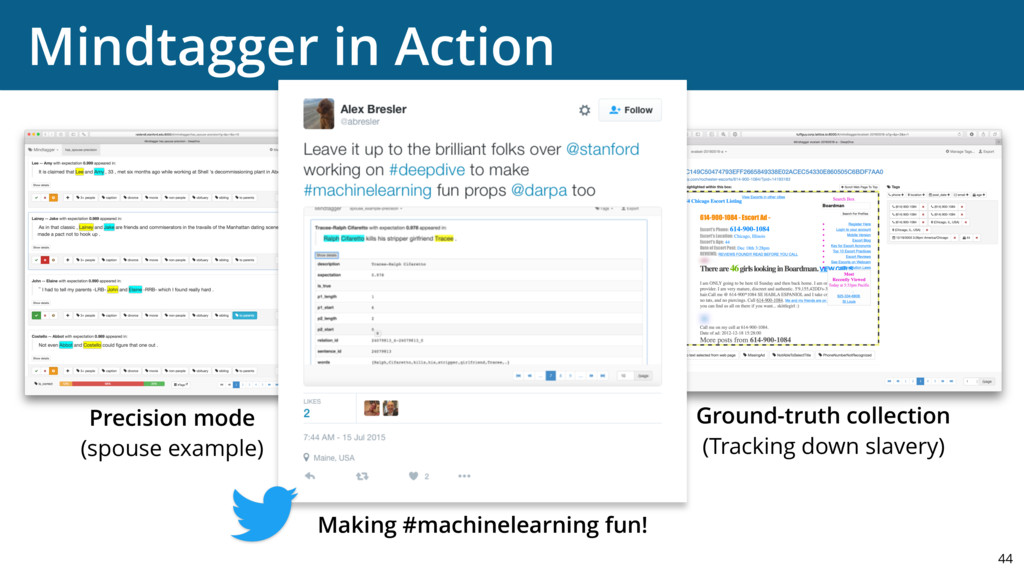{kind=link}
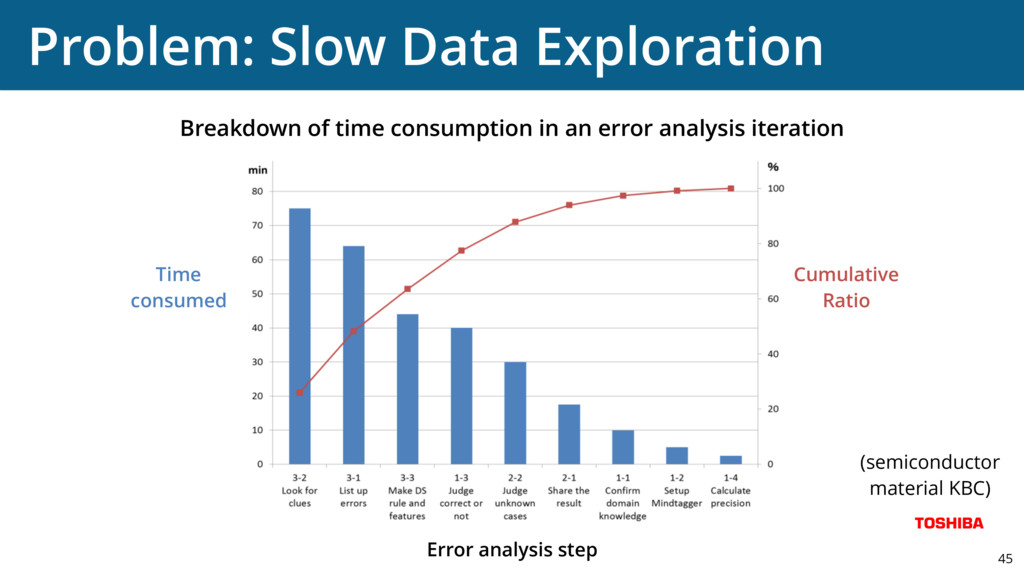{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}