trên các tập văn bản Cho biết xác suất của 1 câu (hoặc 1 cụm từ) thuộc 1 ngôn ngữ là bao nhiêu Mô hình ngôn ngữ tốt sẽ đáng giá đúng các câu đúng ngữ pháp, trôi chảy hơn các từ có thứ tự ngẫu nhiên. vd: P(“hôm nay trời nắng”) > P(“trời nắng nay hôm”)
hình ngôn ngữ là cho biết xác suất của 1 câu 1 2 3 … là bao nhiêu. Theo công thức của Bayes: P(AB) = P(B|A)*P(A) Ta có: P(1 2 3 … ) = P(1 )*P(2 |1 )*P(3 |1 2 )*… *P( |1 2 3 … −1 ) (1)
lớn để lưu hết xác suất của chuỗi có độ dài nhỏ hơn m. Khi m là độ dài của các văn bản ngôn ngữ tự nhiên (m có thể tiến đến vô cùng) Ta sử dụng chuỗi Markov bậc n
thể xây dựng mô hình ngôn ngữ dựa trên việc thống kê các cụm có ít hơn n+1 từ. Mô hình này gọi là mô hình ngôn ngữ N-gram Một cụm N-gram là 1 dãy con gồm n phần tử liên tiếp của 1 dãy các phần tử cho trước.
kí tự, ta có thông tin về tần suất xuất hiên nhiều nhất của các chữ cái. n=2, bigram, ví dụ với những chữ cái tiếng Anh, “th”, “he”, “in”, “an”, “er” là các cặp kí tự hay xuất hiện. n=3, trigram.
thưa, nhiều cụm n-gram không xuất hiện hoặc số lần xuất hiện ít. Với V là kích thước bộ từ vựng, ta có cụm n-gram có thể sinh ra từ bộ từ vựng. Nhưng, thực tế số cụm n-gram có nghĩa thường chiếm rất ít. Tiếng Việt có khoảng 5000 âm tiết khác nhau ta có tống số cụm 3-gram: 50003 = 125.000.000.000
nghĩa thống kê được chỉ xấp xỉ 1.500.000. Như vậy có rất nhiều cụm 3-gram không xuất hiện. Khi tính toán sẽ có rất nhiều cụm n-gram chưa xuất hiện trong dữ liêu huấn luyện, điều này làm xác suất của cả câu bắng 0. Khắc phục tình trạng này ta dùng 1 số phương pháp làm mịn.
nghĩa thống kê được chỉ xấp xỉ 1.500.000. Như vậy có rất nhiều cụm 3-gram không xuất hiện. Khi tính toán sẽ có rất nhiều cụm n-gram chưa xuất hiện trong dữ liêu huấn luyện, điều này làm xác suất của cả câu bắng 0. Khắc phục tình trạng này ta dùng 1 số phương pháp làm mịn.
xác suất của câu bằng 0, người ta đưa ra các phương pháp làm mịn kết quả thống kê. Các phương pháp này đánh giá lại xác suất của các cụm n-gram bằng cách: - Gán cho các cụm n-gram có xác suất bằng 0 một giá trị khác 0. - Thay đổi giá trị các cụm n-gram khác 0 thành 1 giá trị phù hợp.
giảm xác suất của các cụm n-gram có xác suất lớn hơn 0 để bù cho các cụm n- gram có xác suất bằng 0. Truy hồi (Back-off): tính toán xác suất các cụm n-gram không xuất hiện dựa vào các cụm n-gram ngắn hơn có xác suất lớn hơn 0. Nội suy(Interpolation): tính toán xác suất của các cụm n- gram dựa vào xác suất của các cụm n-gram ngắn hơn.
phương pháp này là làm giảm xác suất của các cụm n-gram có xác suất lớn hơn 0. Có 3 thuật toán chiết khấu phổ biến: - Thuật toán Add-one. - Thuật toán Witten-Bell. - Thuật toán Good-Turing.
them 1 vào tần số xuất hiên của mỗi cụm unigram thì tổng cụm xuất hiện: M’ = M + V - M là tổng cụm unigram đã xuất hiên. - V là kích thước toàn bộ từ vựng. Để bảo toàn tổng số cụm unigram vẫn bằng M thì tần số mới của các cụm unigram được tính lại:
các cụm n-gram với n >1, thay M bằng C −+1 −+2 … −1 thì xác suất cụm −+1 −+2 … −1 được tính: ∗( |−+1 −+2 … −1 ) = C −+1 −+2 … −1 + 1 C −+1 −+2 … −1 + (6)
phương pháp này là khi gặp những cụm n-gram có tần số xuất hiện bằng 0, thì coi đây là lần đầu tiên cụm từ này xuất hiện. Như vậy xác suất của cụm n-gram có tần số bằng 0 có thể tính dựa vào xác suất gặp 1 cụm n-gram đầu tiên.
gặp cụm n-gram lần đầu tiên (hay tồng xác suất của các cụm unigram chưa xuất hiện lần nào). + - T là số cụm unigram khác nhau đã xuất hiện - M là tống số các cụm unigram đã thống kê. (7)
chưa xuất hiện lần nào Z: Z = V- T - T là số cụm unigram khác nhau đã xuất hiện - V là kích thước toàn bộ từ vựng. Xác suất của cụm unigram chưa xuất hiện lần nào: ∗ = ( + ) (8) (9)
với các cụm n-gram với n >1, thay M bằng C −+1 −+2 … −1 thì xác suất cụm −+1 −+2 … −1 với C(−+1 −+2 … −1 ) > 0 được tính: P( |−+1 −+2 … −1 ) = C −+1 −+2 … −1 C −+1 −+2 … −1 + −+1 −+2 … −1 (12)
dựa trên việc tính toán Nc- số cụm n-gram xuất hiện c lần. N0 là số cụm n-gram xuất hiện 0 lần. N1 là số cụm n-gram xuất hiện 1 lần. ….. Nc có thể được tính : Nc = : = 1 (13)
toán Good-turing sẽ thay thế tần số c bằng 1 tần số c* ∗ = + 1 ∗ +1 Xác suất cúa 1 cụm n-gram được tính lại như sau: () = ∗ = 0 ∞ = 0 ∞ ∗= 0 ∞ ( + 1) (16) (17)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
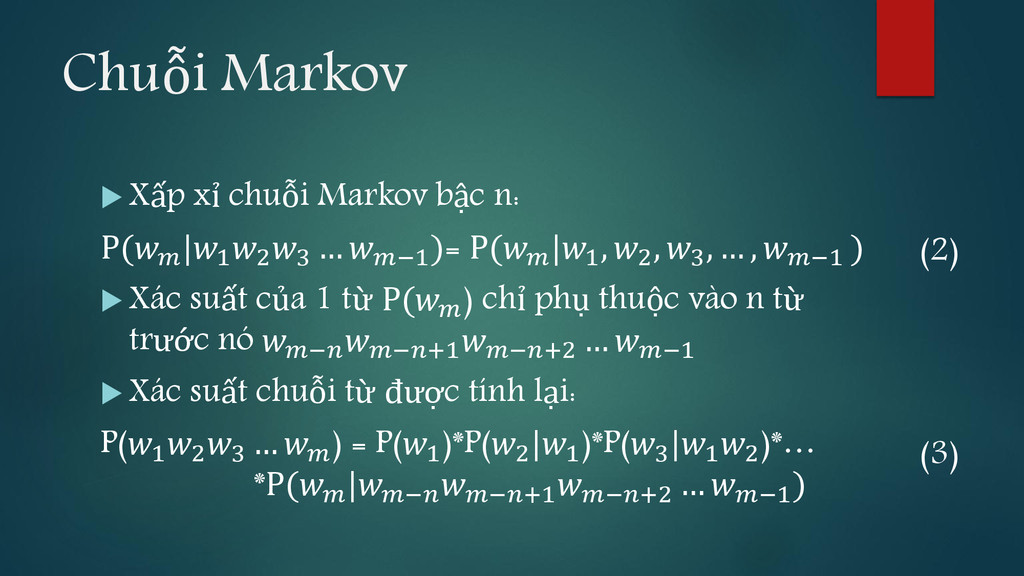{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}