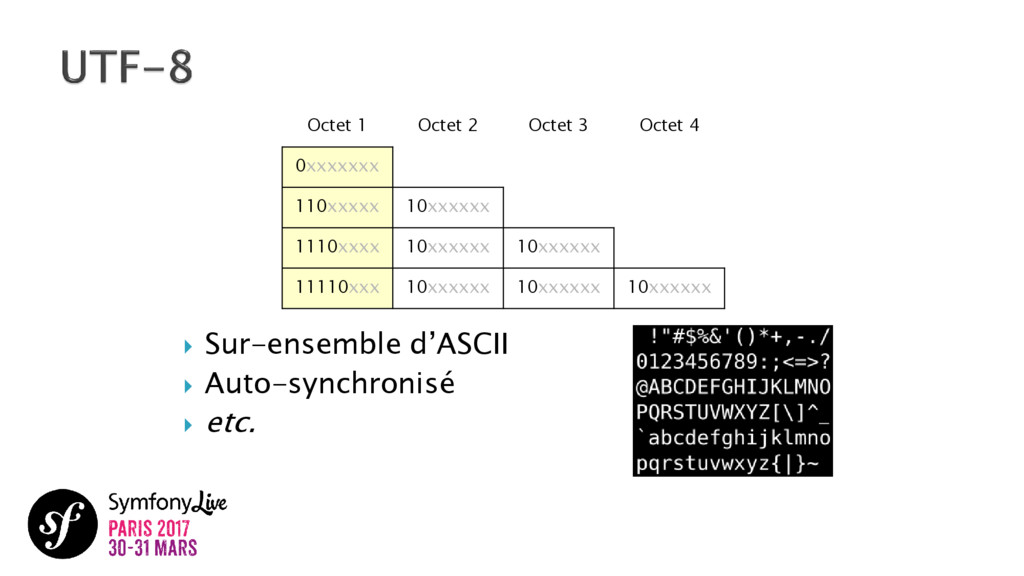
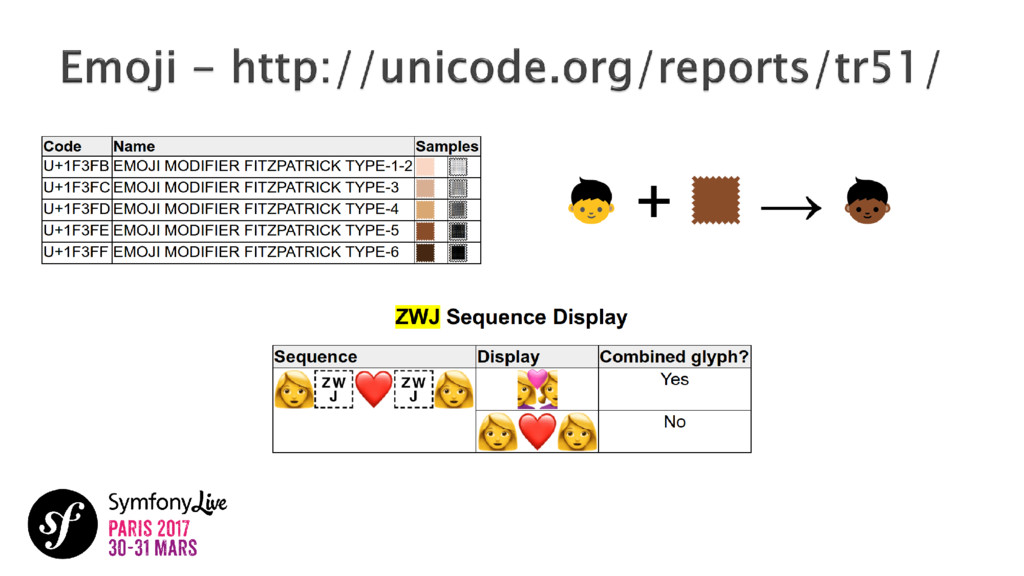
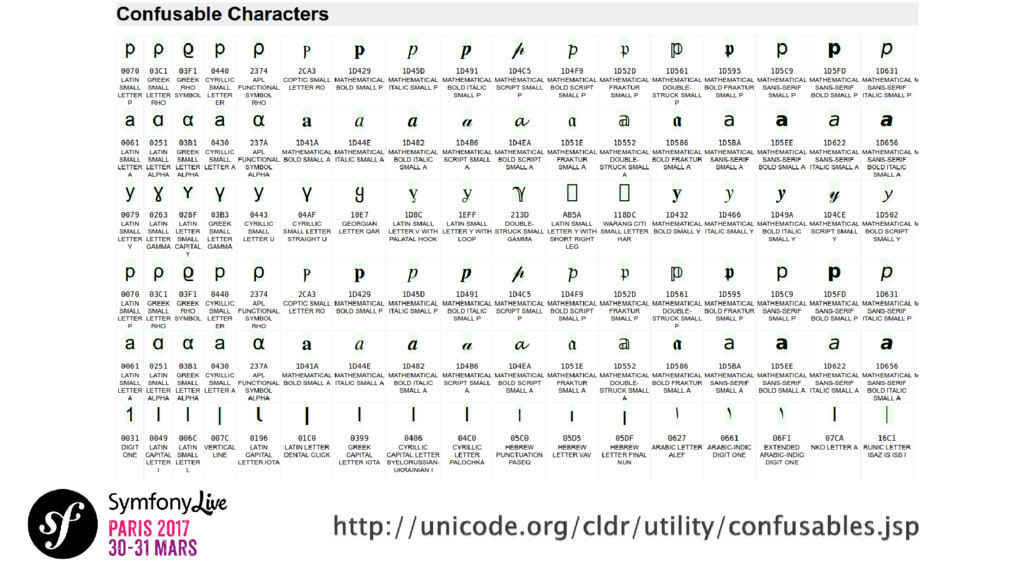
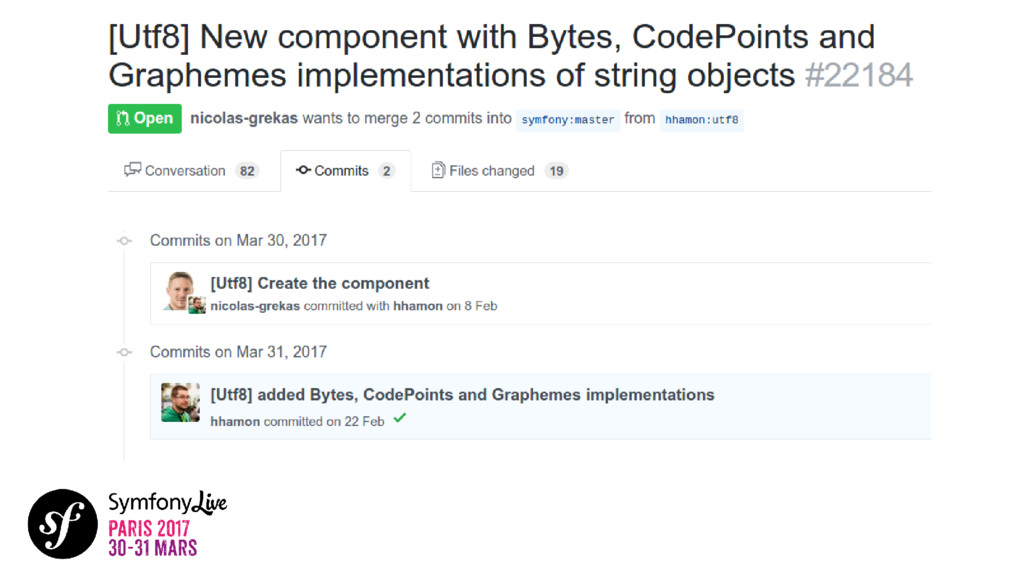
UTF-8, charsets, points de code, glyphes, CLDR, etc. Tout le monde connaît quelques mots des vocabulaires Unicode. Cette norme mondiale rassemble presque toutes les langues écrites sur Terre. Je vous propose de plonger dans ce fantastique projet qui organise tout ces éléments linguistiques et culturels importants de notre époque. Voyons comment nous, les développeurs, avons le privilège de jouer avec ces derniers au niveau technique. Comment cela marche-t-il? Comment cela s'applique-t-il aux applications que nous créons? Avez-vous entendu parler de collations ? Translitérations ? Grapheme Clusters ? NFC ? Laissez-vous guider.
{kind=link}
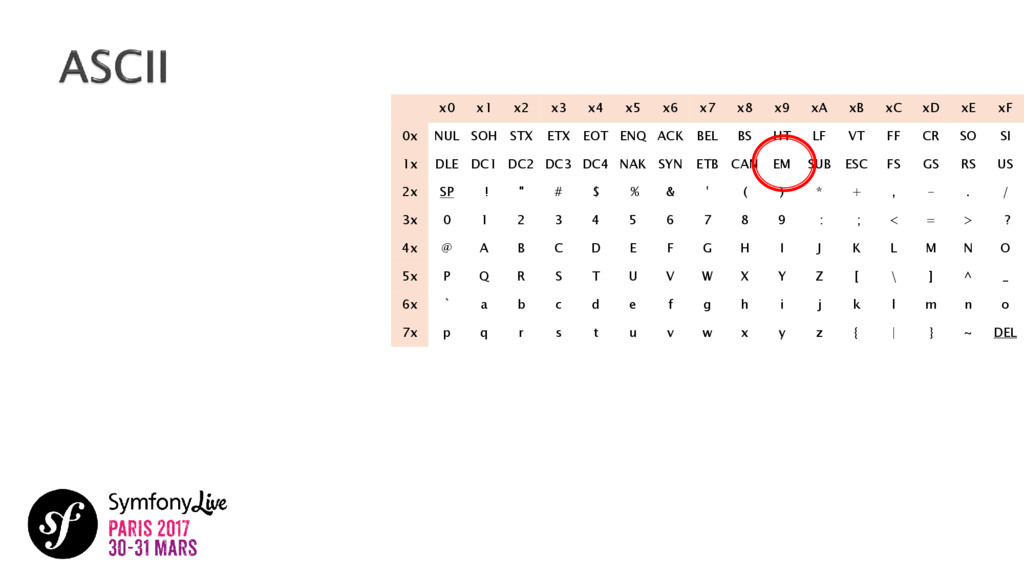{kind=link}
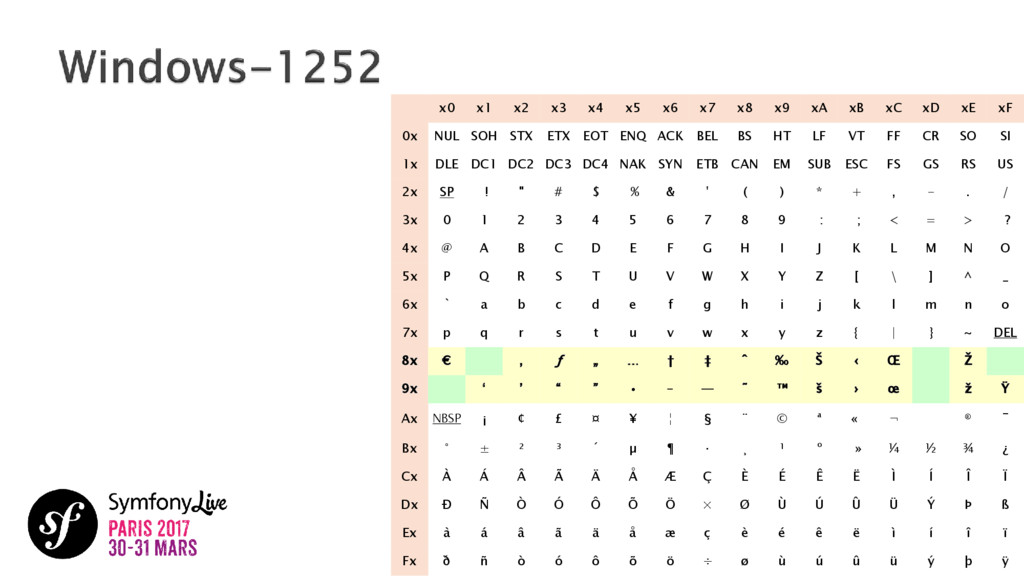{kind=link}
{kind=link}
{kind=link}
{kind=link}
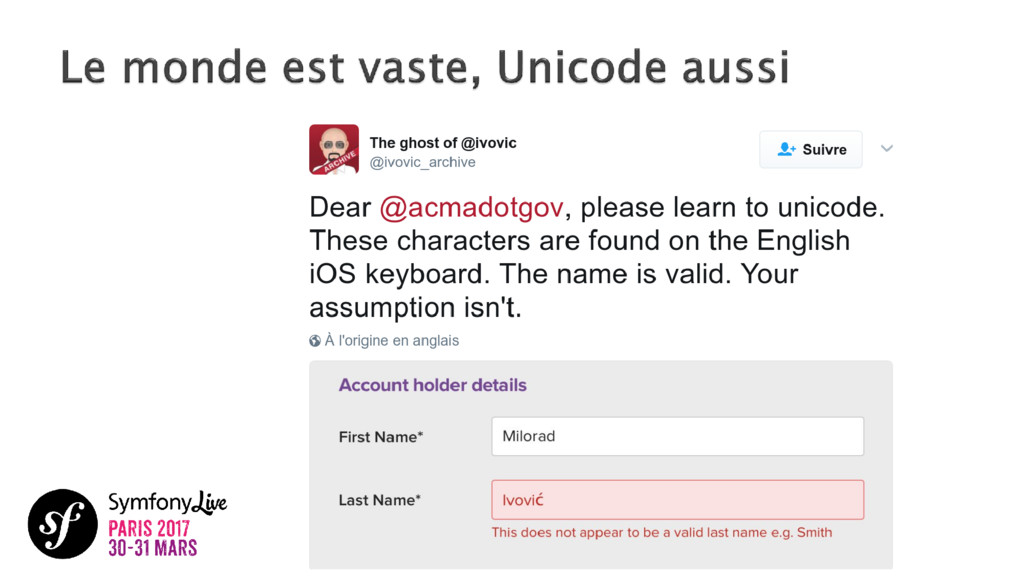{kind=link}
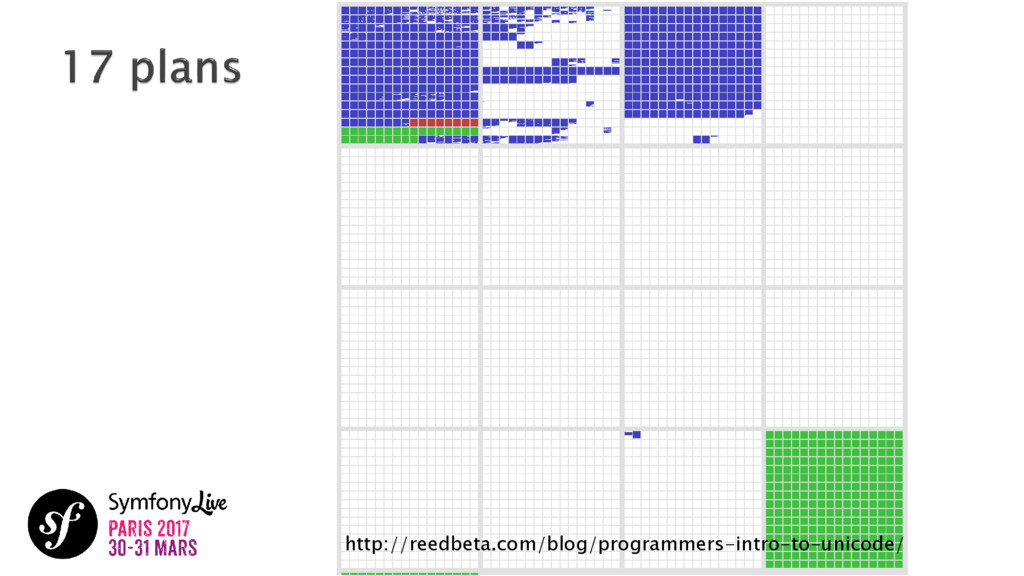{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}