mayah / 株式会社ナレッジワーク CTO
※2025/12/23開催「Encraft #22 AIプロダクトを支えるアーキテクチャ設計 ー理論と実践」での登壇資料です。
https://knowledgework.connpass.com/event/372086/
セッション概要:
Knowledge Work は初期は AI を利用しない SaaS プロダクトでした。しかし、AI の利用が盛んになるにつれ、AI を動かすための基盤、AI がデータを取得するための基盤などを整えてきました。本日はその基盤の概略と行ってきた基盤整備についてお話しします。
登壇者プロフィール:
2006年、東京大学大学院情報理工学系研究科コンピュータ科学専攻修士課程修了。日本IBM東京基礎研究所では研究者として入社。2011年、Googleにソフトウェアエンジニアとして入社。Chrome browserの開発に関わった。2020年4月、株式会社ナレッジワークを共同創業。「王様達のヴァイキング」(週刊ビッグコミックスピリッツ)技術監修。X: @mayahjp
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
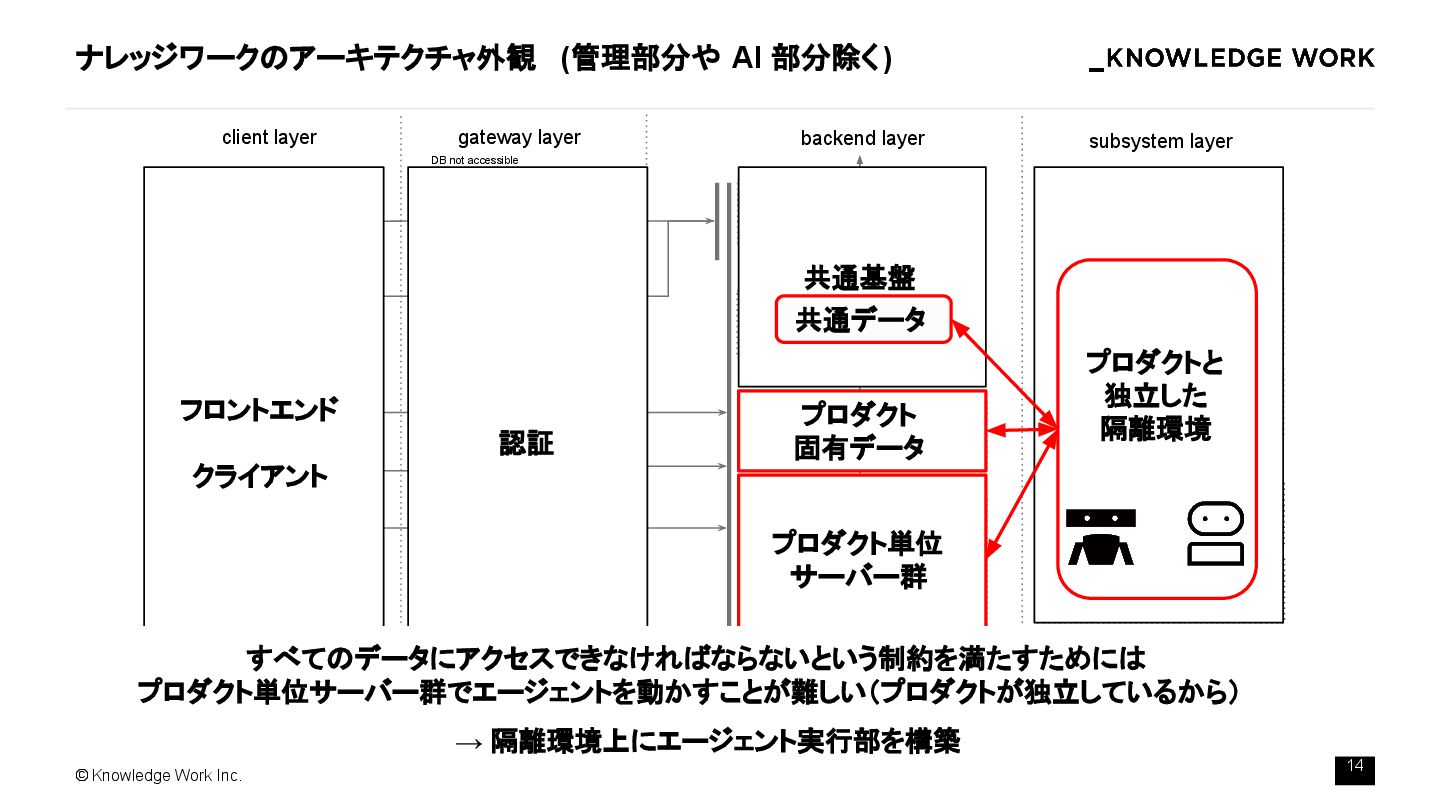{kind=link}
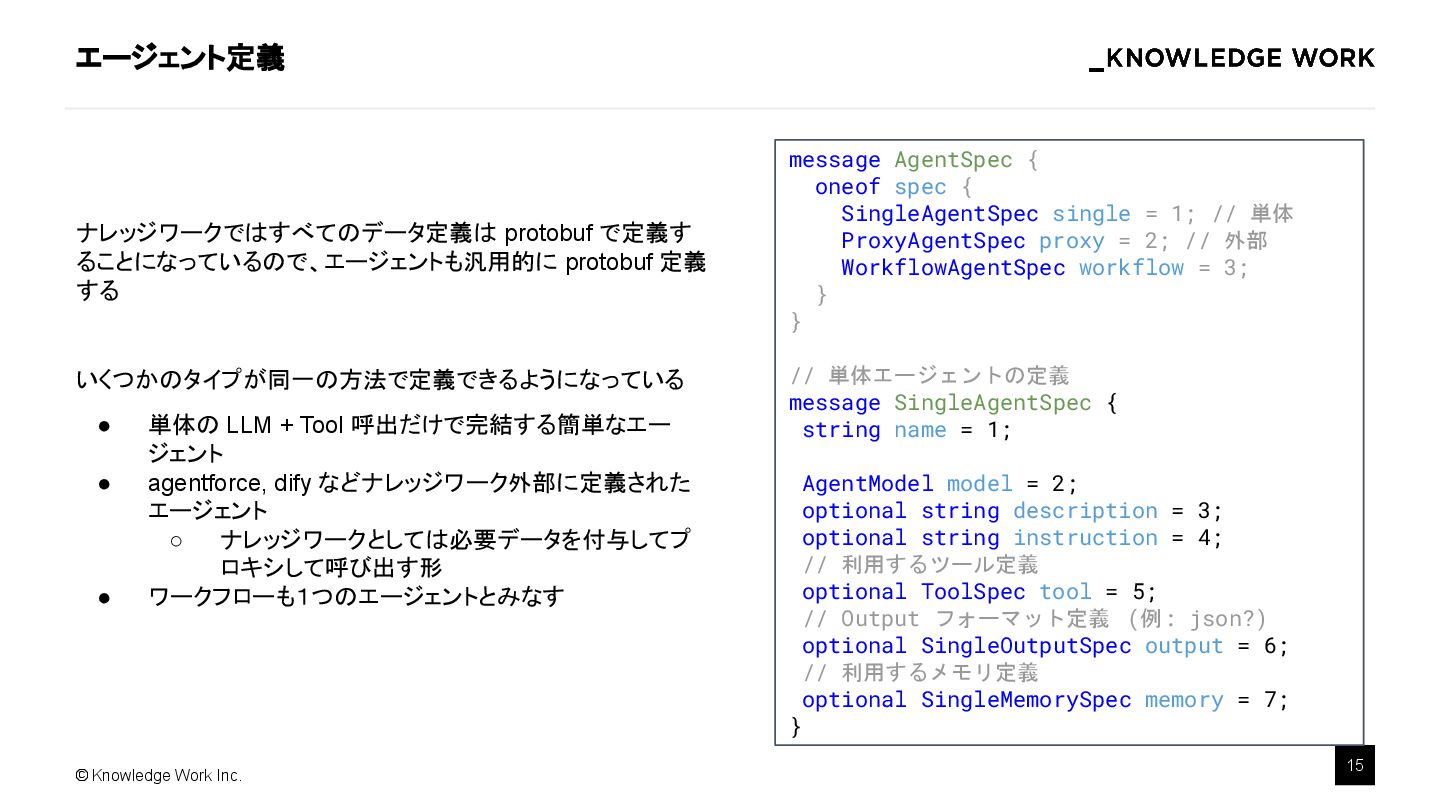{kind=link}
{kind=link}
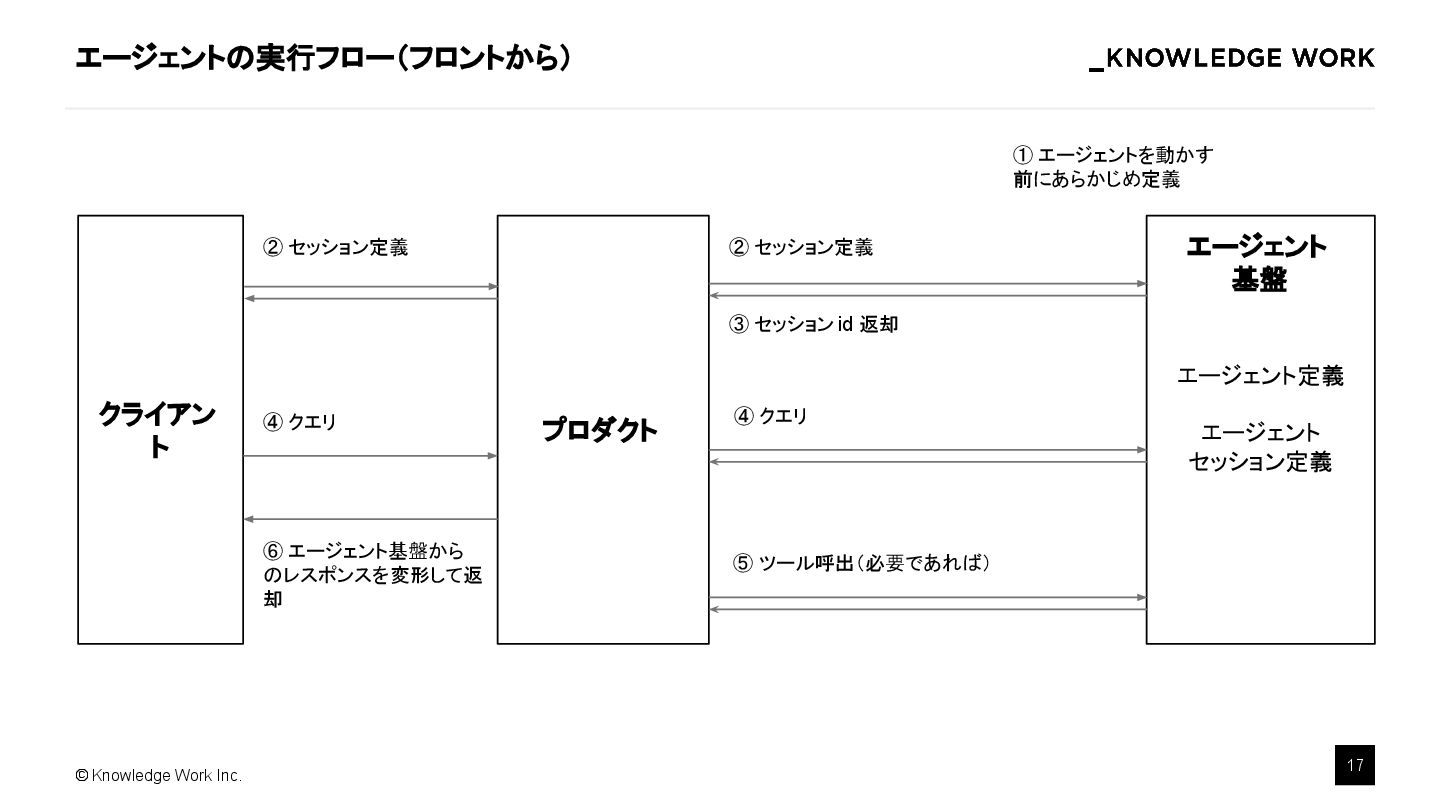{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}