Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Optimisation of short memory strategies in the ...
Search
Nikoleta
June 04, 2017
Science
59
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Optimisation of short memory strategies in the Iterated Prisoners Dilemma
Wales Mathematics Colloquium 2017.
Nikoleta
June 04, 2017
More Decks by Nikoleta
See All by Nikoleta
A trip to earth science with python as a companion
nikoletav3
0
54
Arcas: Using Python to access open research literature
nikoletav3
1
180
Testing Research Software
nikoletav3
0
340
Arcas
nikoletav3
0
510
SSI Selection Day
nikoletav3
0
420
SWORDS-03-10-2016
nikoletav3
0
53
PyCon UK 2016
nikoletav3
0
170
Other Decks in Science
See All in Science
大黒市で発生した大規模インシデント の ポストモーテムから読み解く、 記憶媒体消去の大切さ
shucho0103
0
210
HajimetenoLT vol.17
hashimoto_kei
1
250
機械学習 - 授業概要
trycycle
PRO
0
570
データベース15: ビッグデータ時代のデータベース
trycycle
PRO
1
520
ハミルトン・ヤコビ方程式の解の性質と物理的意味
enakai00
0
840
やるべきときにMLをやる AIエージェント開発
fufufukakaka
2
1.5k
Van Dare naar Durf
voginip
0
270
Tensor Factorization Meets Deformed Information Geometry: Convex Relaxation under Deformed Algebra
gkazunii
0
120
共生概念の整理と AIアライメントの構想
hiroakihamada
0
240
生成AIが科学とRAにもたらしていること:メタサイエンスの視点から
rmaruy
0
110
ダメな自分の育て方―性格タイプの「劣等機能」から理解するニガテ克服術
ppillc
0
250
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
PRO
0
1.6k
Featured
See All Featured
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
It's Worth the Effort
3n
188
29k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.4k
AI: The stuff that nobody shows you
jnunemaker
PRO
9
850
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.5k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
200
Documentation Writing (for coders)
carmenintech
77
5.4k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Ruling the World: When Life Gets Gamed
codingconduct
0
290
Transcript
Optimisation of short memory strategies in the Iterated Prisoners Dilemma
Nikoleta E. Glynatsi Supervised by: Dr. Vincent Knight Dr. Jonathan Gillard
(3, 3) (0, 5) (5, 0) (1, 1)
(3, 3) (0, 5) (5, 0) (1, 1) (R, P,
S, T) = (3, 1, 0, 5)
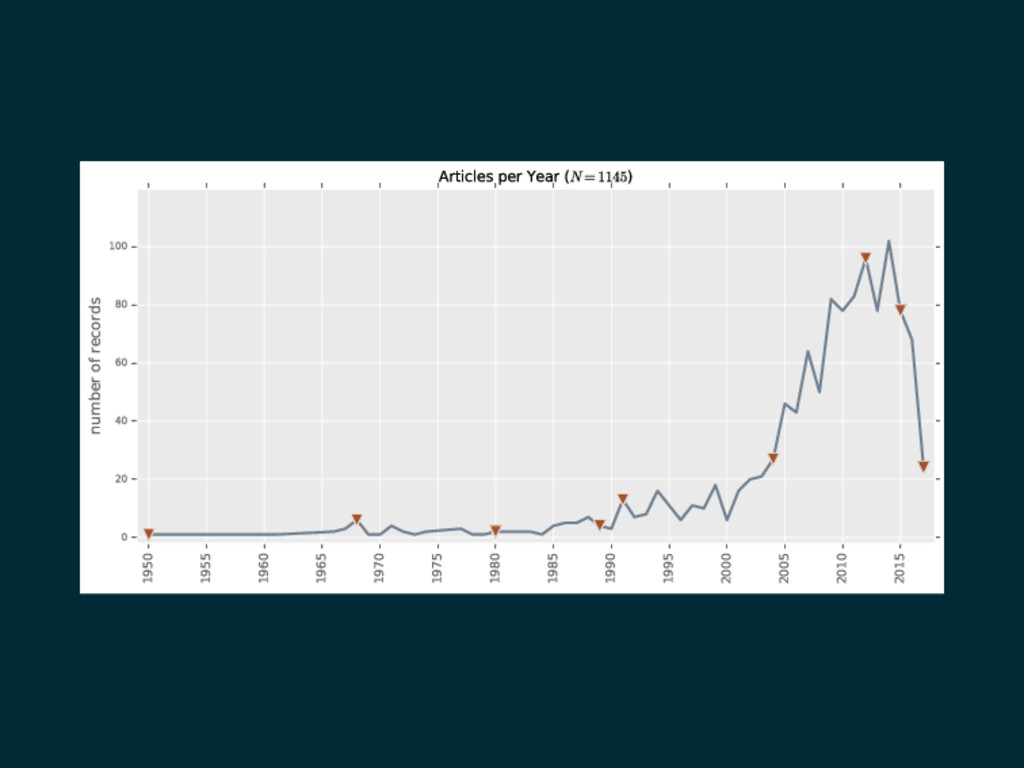
1950 1955 1960 1965 1970 1975 1980 1985 1990 1995
2000 2005 2010 2015 0 20 40 60 80 100 number of records Articles per Year (N=1145)
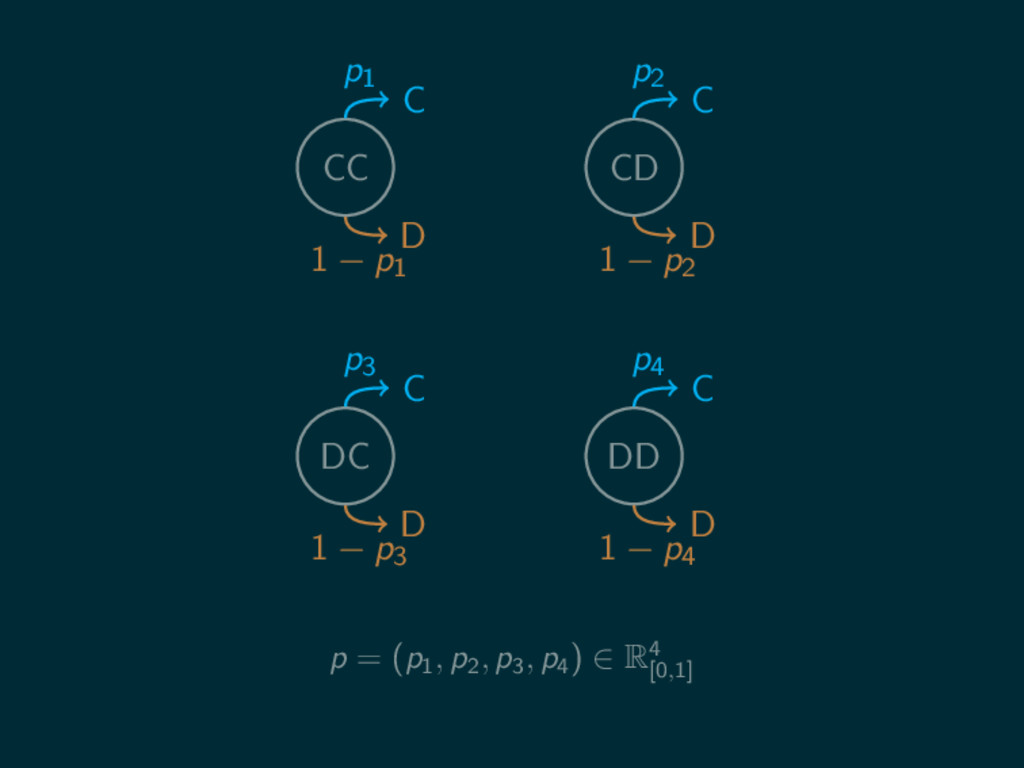
CC CD DC DD C D C D C D
C D p1 1 − p1 p2 1 − p2 p3 1 − p3 p4 1 − p4 p = (p1 , p2 , p3 , p4 ) ∈ R4 [0,1]
Christopher Lee, Marc Harper, and Dashiell Fryer. The art of
war: Beyond memory-one strategies in population games. 2015.
How good are memory one strategies ?
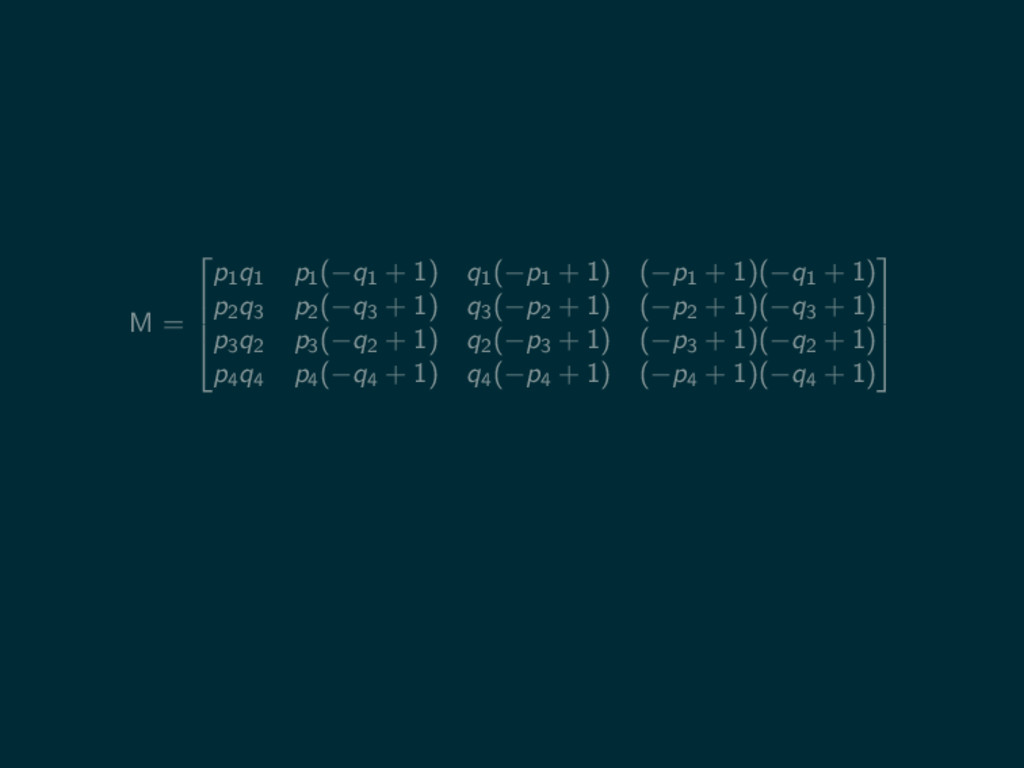
CC CD DC DD
M = p1 q1 p1 (−q1
+ 1) q1 (−p1 + 1) (−p1 + 1)(−q1 + 1) p2 q3 p2 (−q3 + 1) q3 (−p2 + 1) (−p2 + 1)(−q3 + 1) p3 q2 p3 (−q2 + 1) q2 (−p3 + 1) (−p3 + 1)(−q2 + 1) p4 q4 p4 (−q4 + 1) q4 (−p4 + 1) (−p4 + 1)(−q4 + 1)
maxp uq (p) such that p ∈ R4 [0,1]
Lemma uq(p) = 1 2 pQpT + cT p +
a 1 2 p ¯ QpT + ¯ cT p + ¯ a Q, ¯ Q ∈ R4×4 c, ¯ c ∈ R4×1 a, ¯ a ∈ R
maxp uq (p) such that p ∈ R4 [0,1]
maxp uq (p) such that p ∈ R4 [0,1] subject
to p1 = p2 = p3 = p4 = p
Lemma uq(p) = n2p2 + n1p + n0 d1p +
d0 n2 = −(q1 − q2 − 2q3 + 2q4) n1 = −q1 + 2q2 + 5q3 − 7q4 − 1 n0 = q2 − 5q4 − 1 d1 = q1 − q2 − q3 + q4 d0 = q2 − q4 − 1
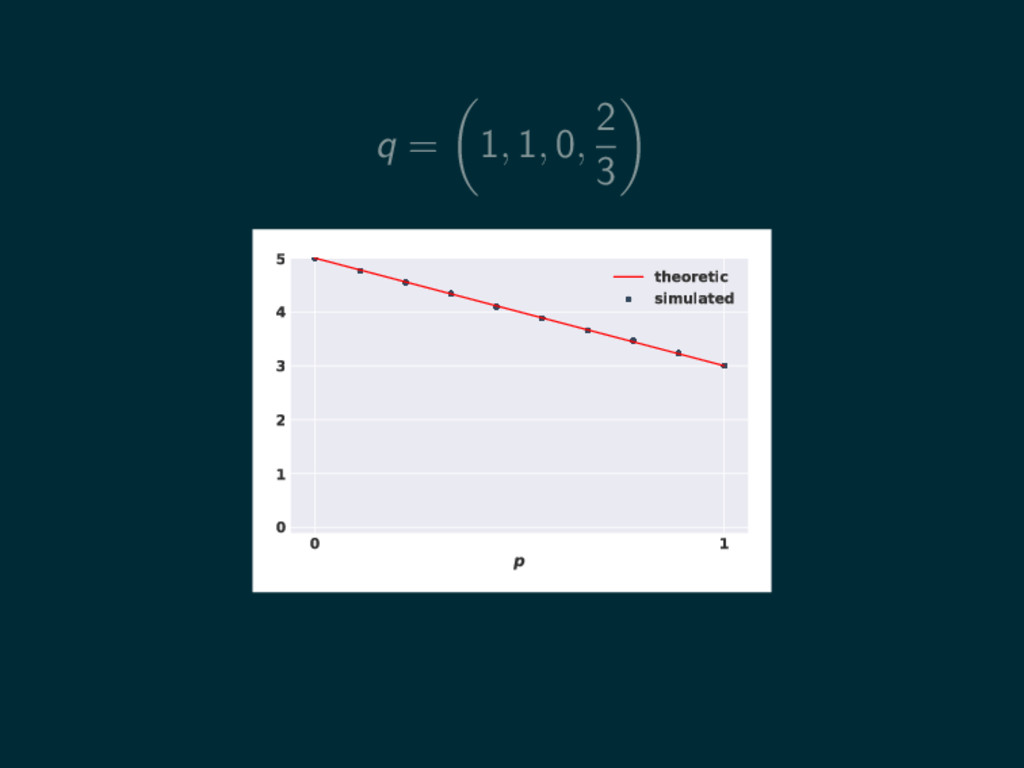
q = 1, 1, 0, 2 3 0 1 p
0 1 2 3 4 5 theoretic simulated
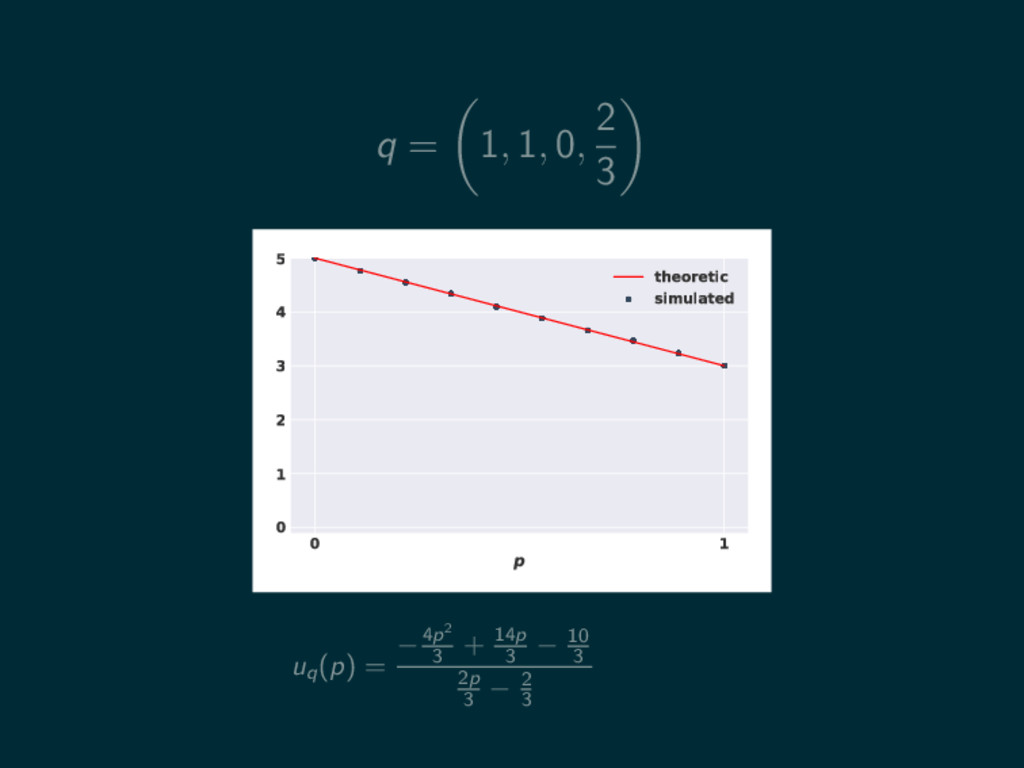
q = 1, 1, 0, 2 3 0 1 p
0 1 2 3 4 5 theoretic simulated uq (p) = −4p2 3 + 14p 3 − 10 3 2p 3 − 2 3
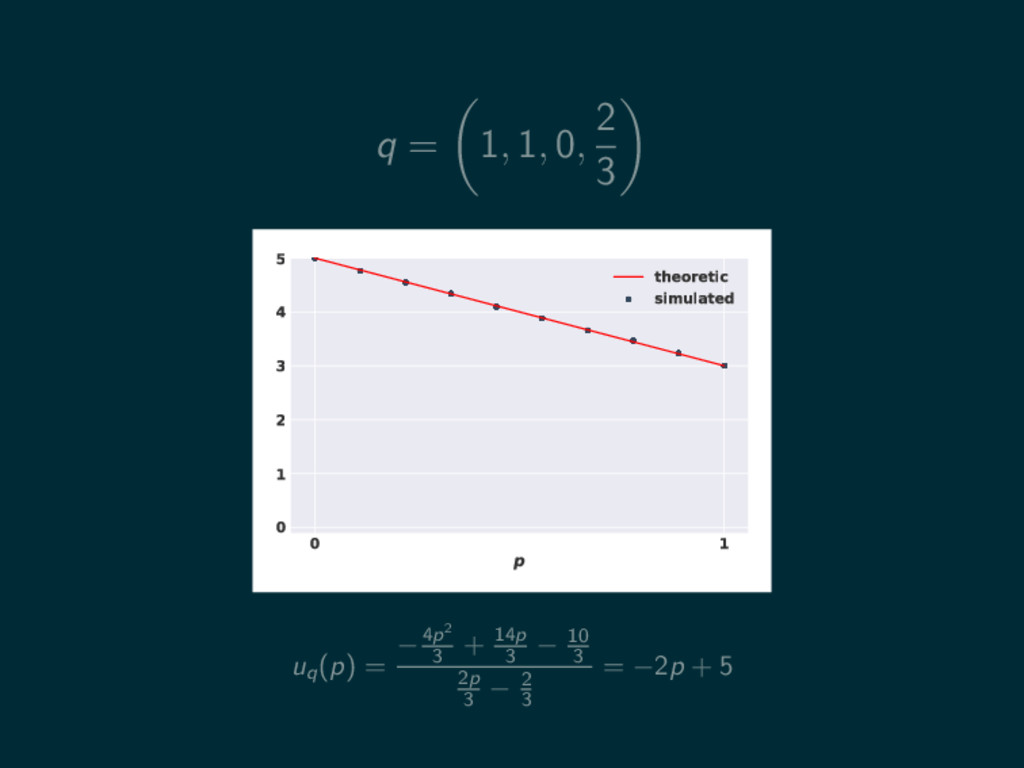
q = 1, 1, 0, 2 3 0 1 p
0 1 2 3 4 5 theoretic simulated uq (p) = −4p2 3 + 14p 3 − 10 3 2p 3 − 2 3 = −2p + 5
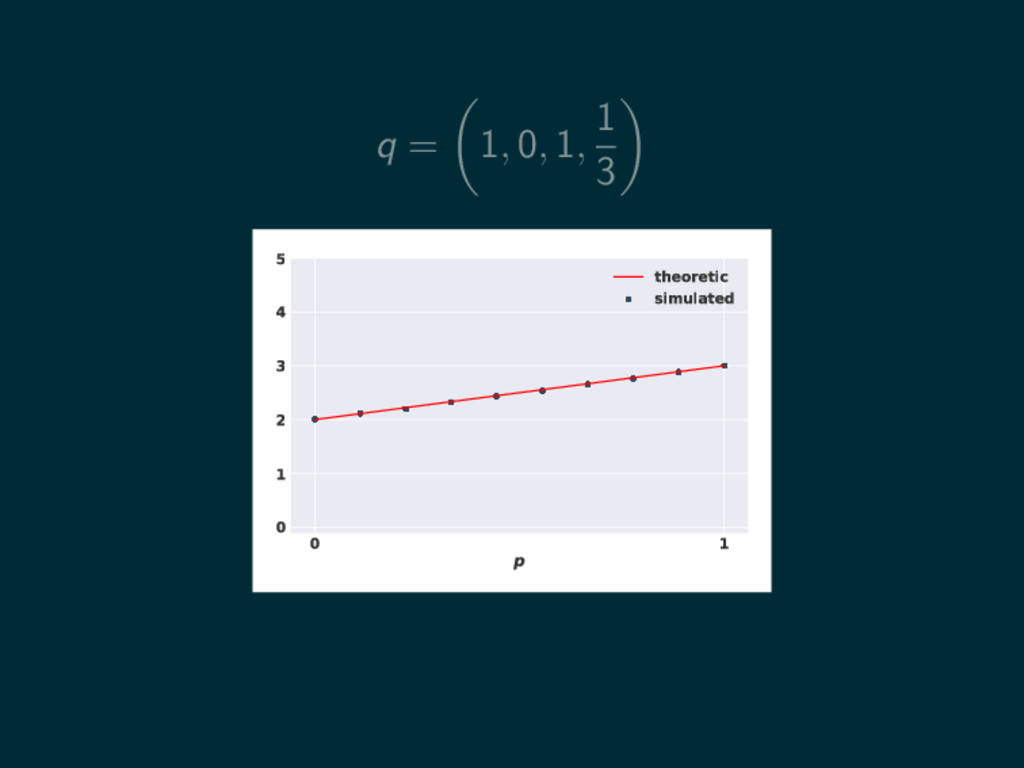
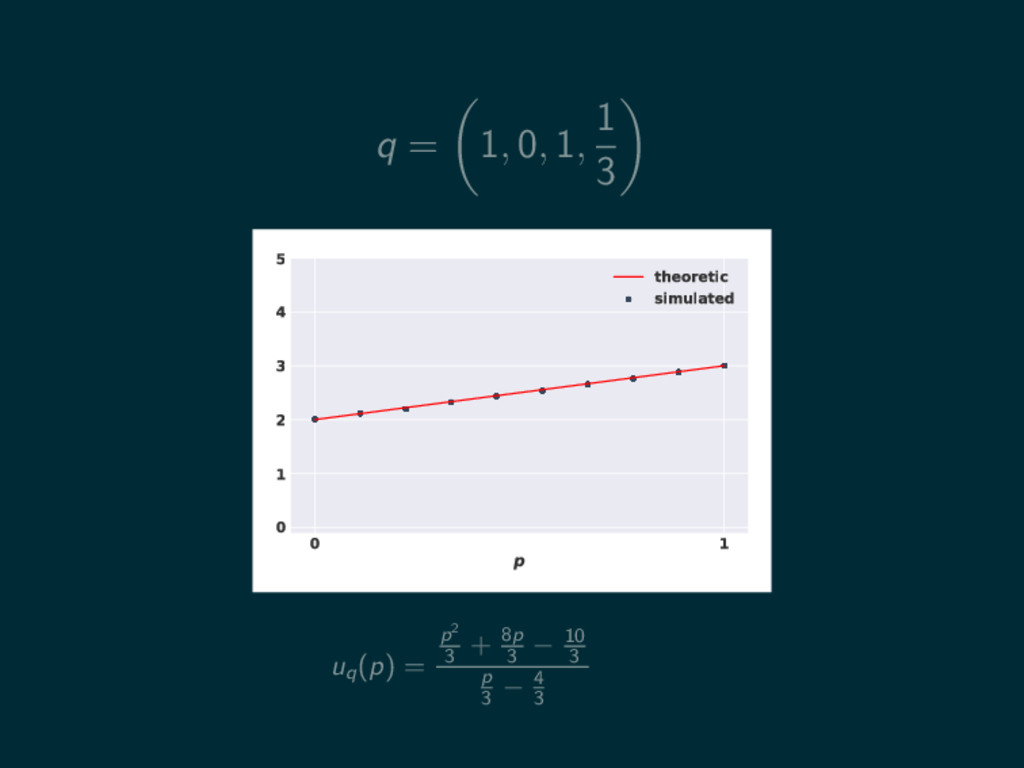
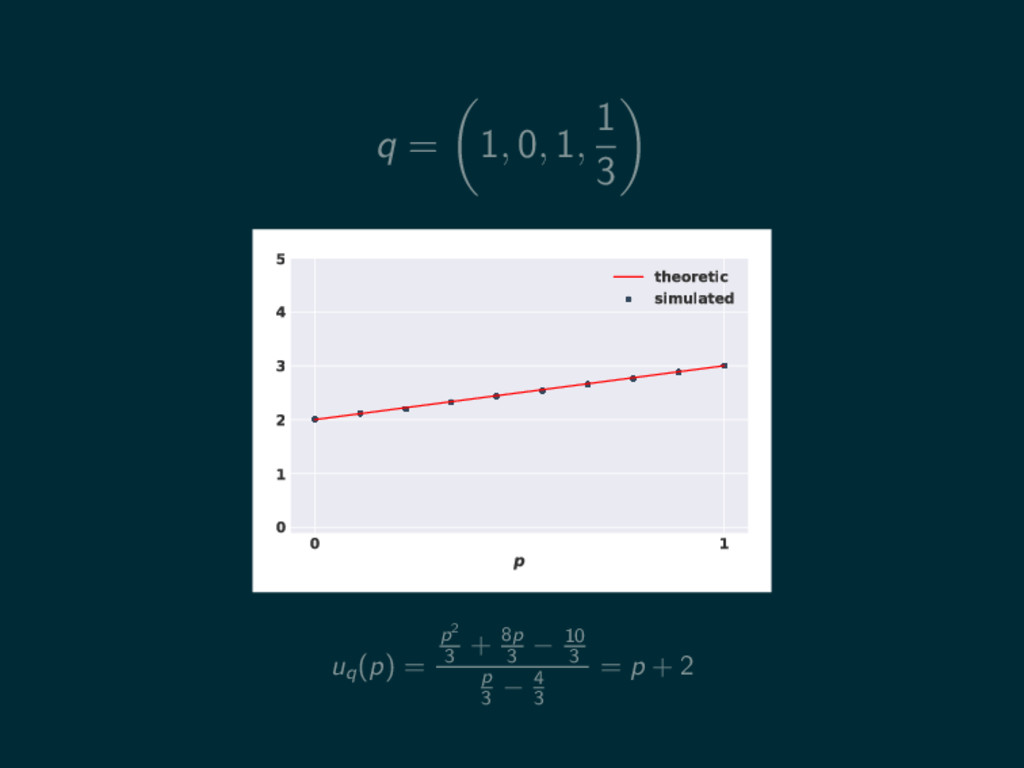
q = 1, 0, 1, 1 3 0 1 p
0 1 2 3 4 5 theoretic simulated
q = 1, 0, 1, 1 3 0 1 p
0 1 2 3 4 5 theoretic simulated uq (p) = p2 3 + 8p 3 − 10 3 p 3 − 4 3
q = 1, 0, 1, 1 3 0 1 p
0 1 2 3 4 5 theoretic simulated uq (p) = p2 3 + 8p 3 − 10 3 p 3 − 4 3 = p + 2
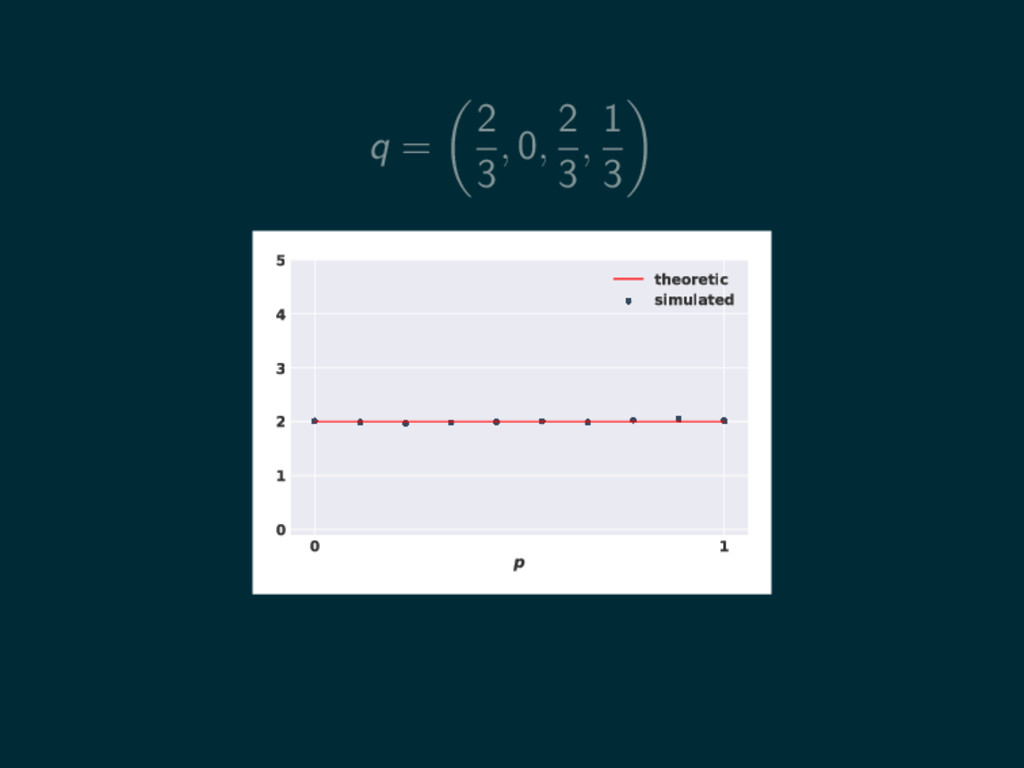
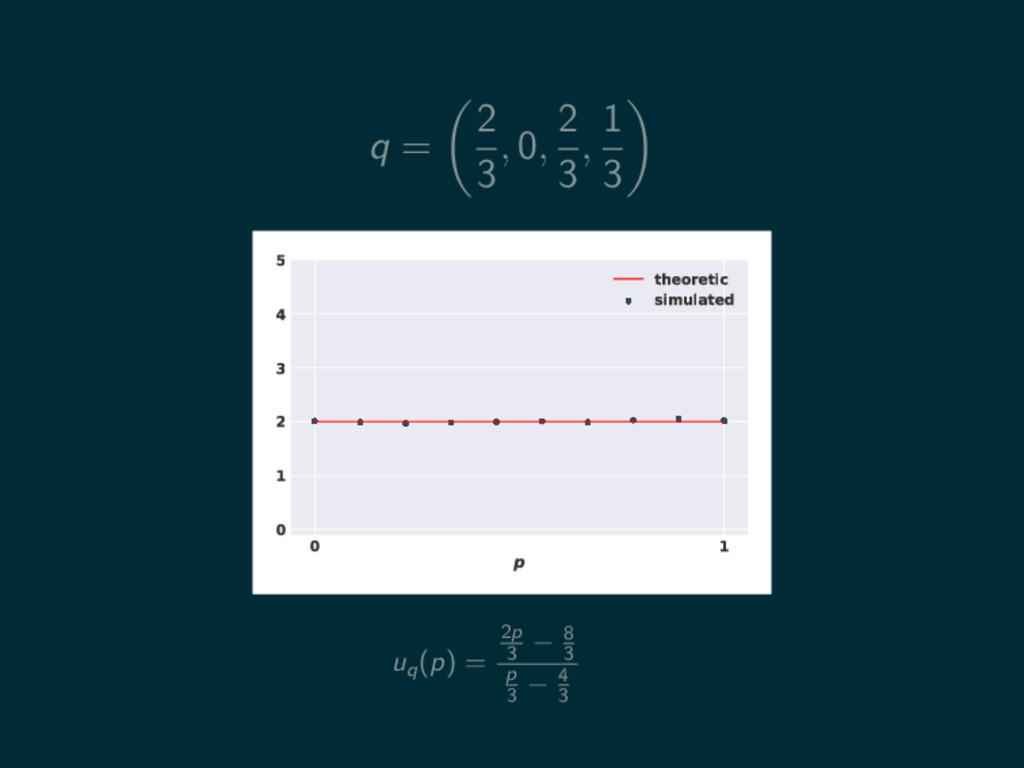
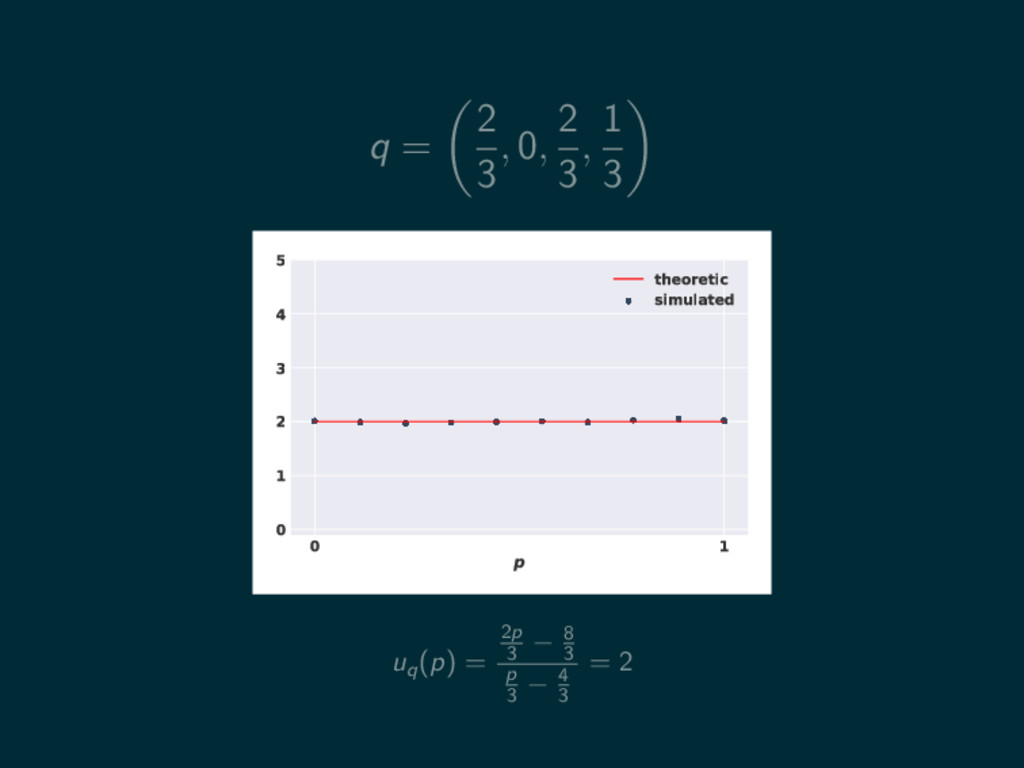
q = 2 3 , 0, 2 3 , 1
3 0 1 p 0 1 2 3 4 5 theoretic simulated
q = 2 3 , 0, 2 3 , 1
3 0 1 p 0 1 2 3 4 5 theoretic simulated uq (p) = 2p 3 − 8 3 p 3 − 4 3
q = 2 3 , 0, 2 3 , 1
3 0 1 p 0 1 2 3 4 5 theoretic simulated uq (p) = 2p 3 − 8 3 p 3 − 4 3 = 2
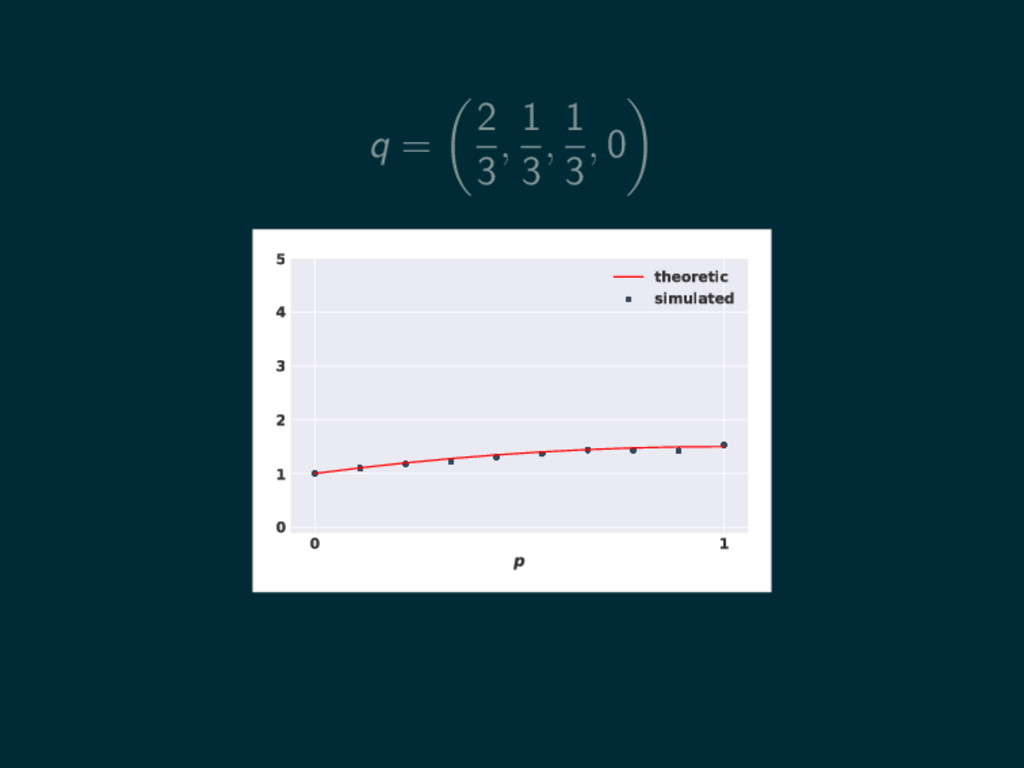
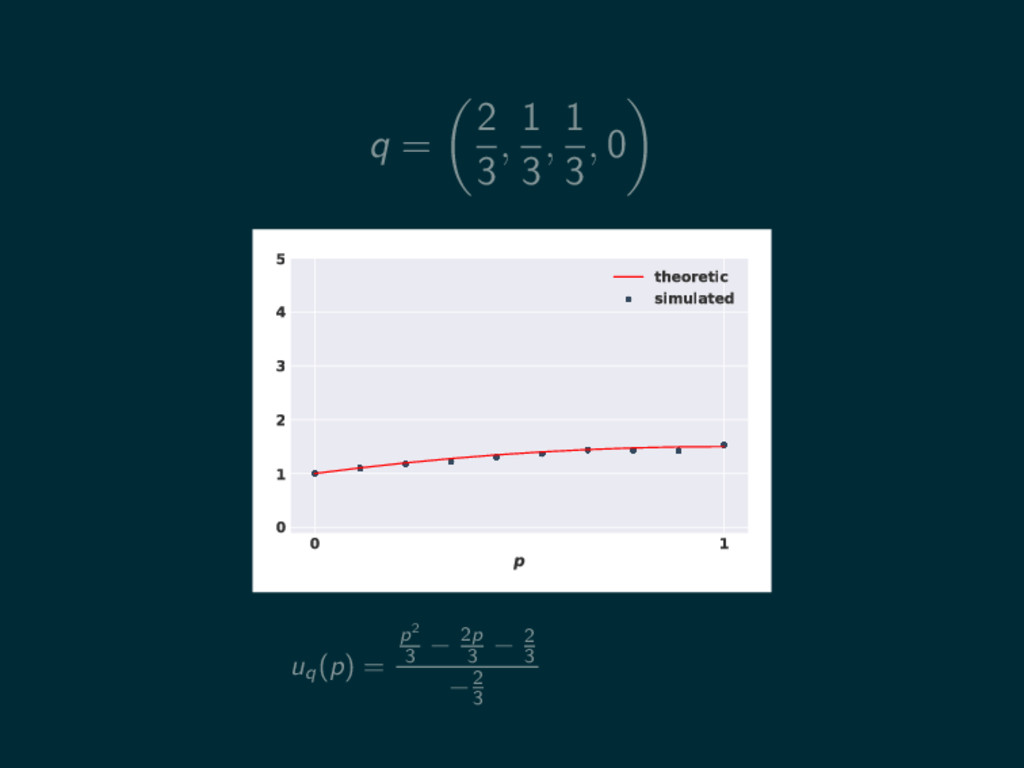
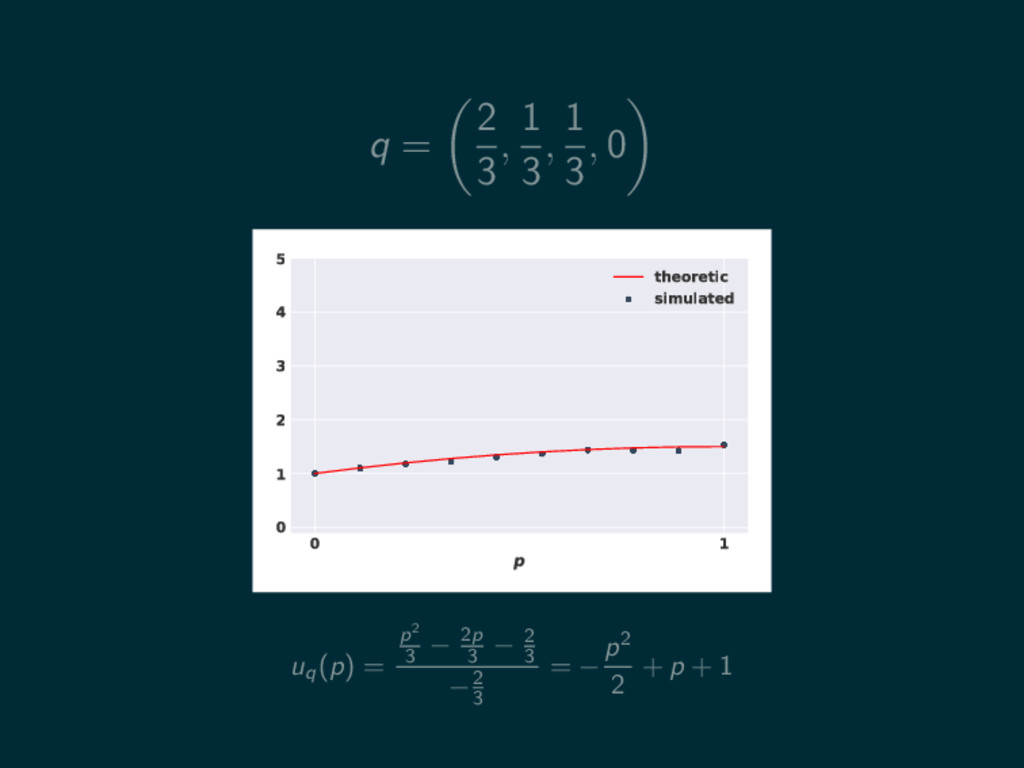
q = 2 3 , 1 3 , 1 3
, 0 0 1 p 0 1 2 3 4 5 theoretic simulated
q = 2 3 , 1 3 , 1 3
, 0 0 1 p 0 1 2 3 4 5 theoretic simulated uq (p) = p2 3 − 2p 3 − 2 3 −2 3
q = 2 3 , 1 3 , 1 3
, 0 0 1 p 0 1 2 3 4 5 theoretic simulated uq (p) = p2 3 − 2p 3 − 2 3 −2 3 = − p2 2 + p + 1
Lemma (Indifferent) −q1 + q2 + 2q3 − 2q4 =
0 and (q2 − q4 − 1)(q1 − 2q2 − 5q3 + 7q4 + 1) − (q2 − 5q4 − 1)(q1 − q2 − q3 + q4 ) = 0. Proof. uq (p) = n2 p2 + n1 p + n0 d1 p + d0 = a0 n2 p2 + n1 p + n0 = a0 d1 p + a0 d0 n2 = 0 n1 d0 = d1 n0
Lemma (Linear) (q1 q4 − q2 q3 + q3 −
q4 )(4q1 − 3q2 − 4q3 + 3q4 − 1) = 0 Proof. uq (p) = n2 p2 + n1 p + n0 d1 p + d0 = a1 p + a0 n2 p2 + n1 p + n0 = a1 d1 p2 + (d1 a0 + a1 d0 )p + a0 d0 n2 = d1 a1 n1 d0 = d1 n0 + a1 d0
Lemma (Quadratic) (q1 − q2 − q3 + q4 )
= 0, (q1 q4 − q2 q3 + q3 − q4 )(4q1 − 3q2 − 4q3 + 3q4 − 1) = 0 and q2 − q4 − 1 = 0 Proof. uq (p) = n2 p2 + n1 p + n0 d1 p + d0 = a2 p2 + a1 p + a0 n2 p2 + n1 p + n0 = d1 a2 p3 + (a1 d1 + d0 a2 )p2 + (d1 a0 + a1 d0 )p + a0 d0 a1 d1 = 0 n2 = d1 a1 + d0 an2 n1 d0 = d1 n0 + a1 d0
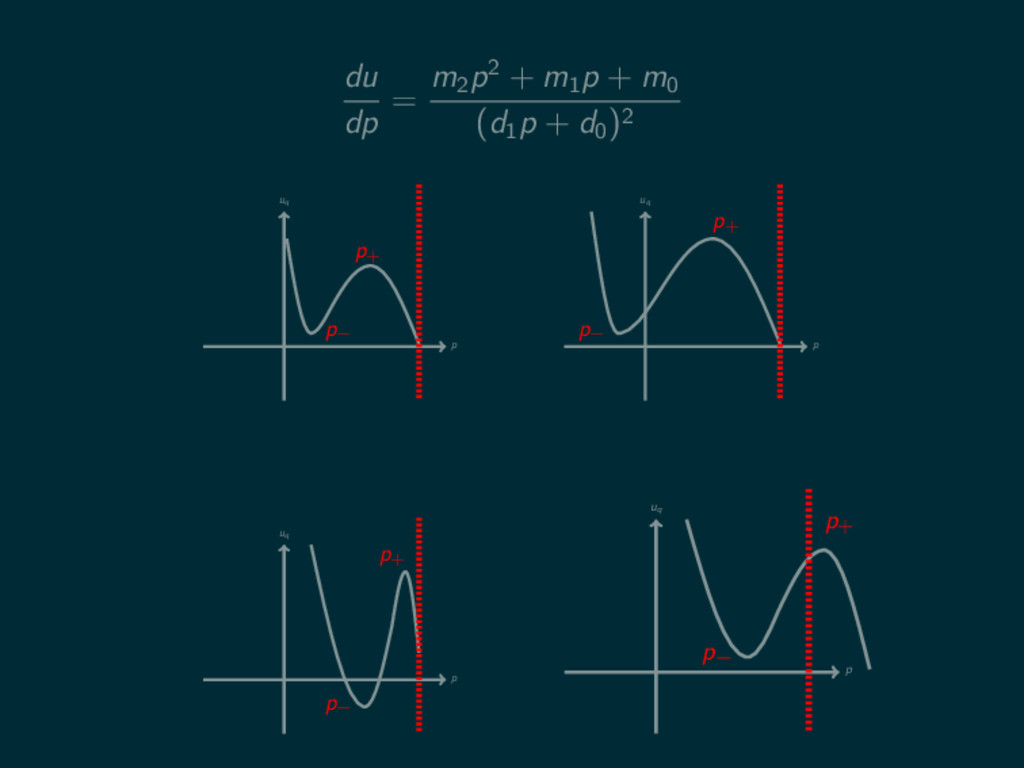
du dp = m2 p2 + m1 p + m0
(d1 p + d0 )2 p uq p− p+ p uq p− p+ p uq p− p+ p uq p− p+
Theorem (Optimization of purely random player) Sq = 0, p±
, 1 0 < p± < 1, p± = −d0 d1 p∗ = argmax p∈Sq uq (p)
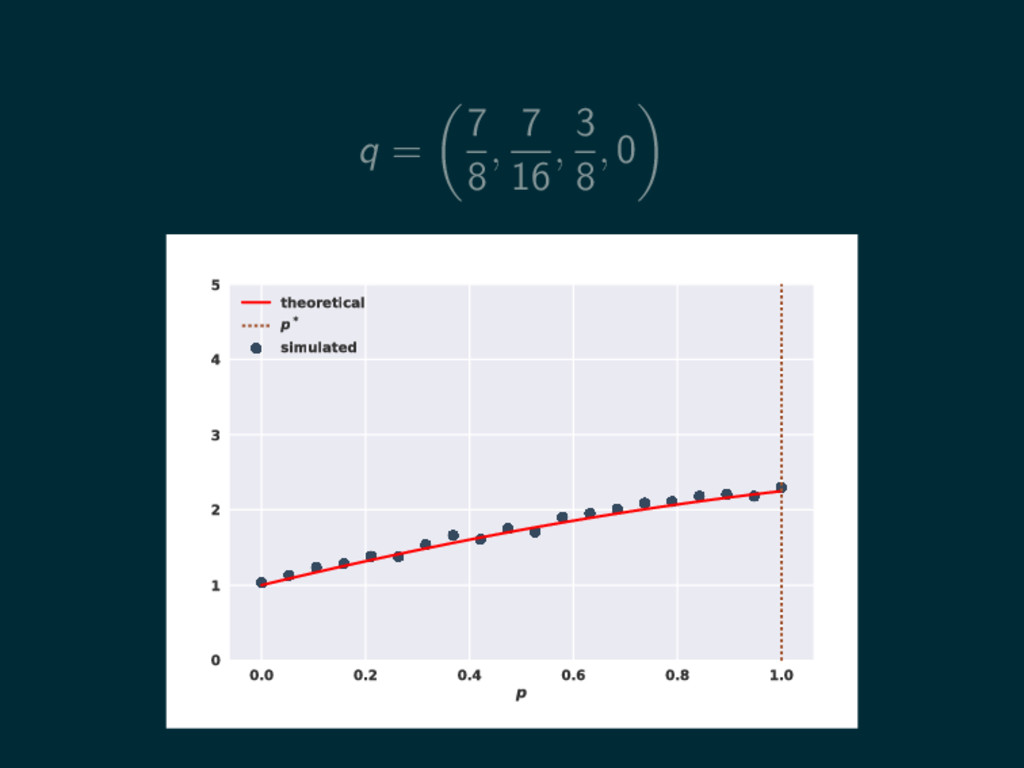
q = 7 8 , 7 16 , 3 8
, 0 0.0 0.2 0.4 0.6 0.8 1.0 p 0 1 2 3 4 5 theoretical p* simulated
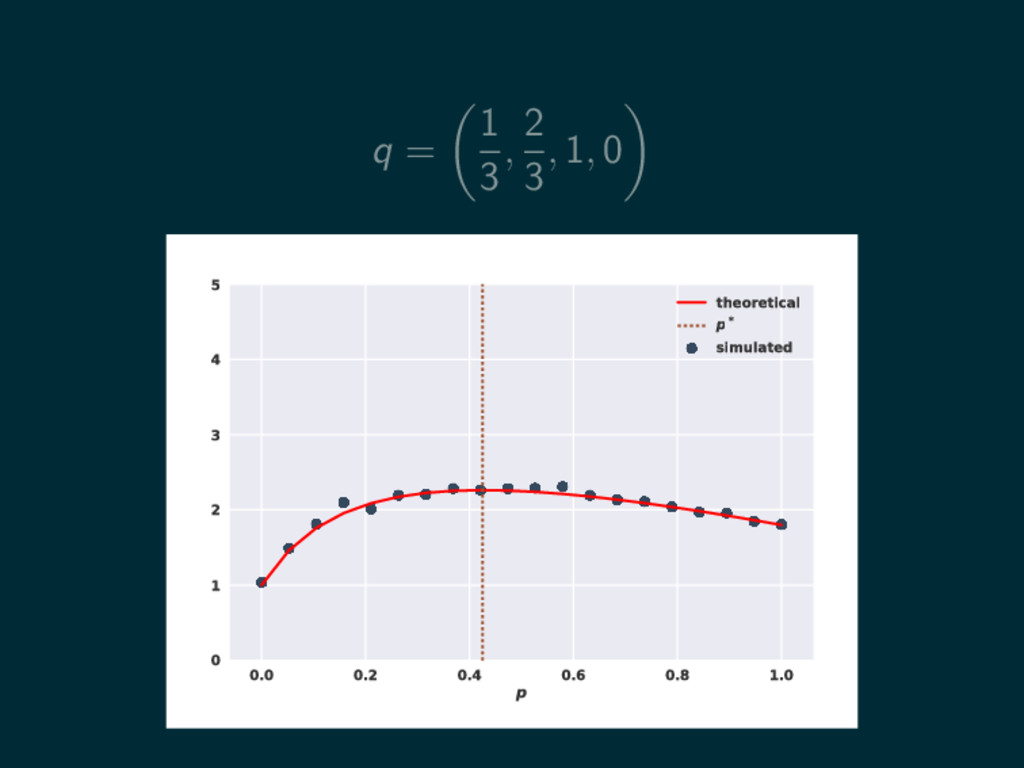
q = 1 3 , 2 3 , 1, 0
0.0 0.2 0.4 0.6 0.8 1.0 p 0 1 2 3 4 5 theoretical p* simulated
q(1), q(2), q(3) . . . q(N) max p 1
N N i=1 uq (i)(p)
q(1), q(2), q(3) . . . q(N) max p 1
N N i=1 uq (i)(p) max p u 1 N N i=1 q(i) (p)
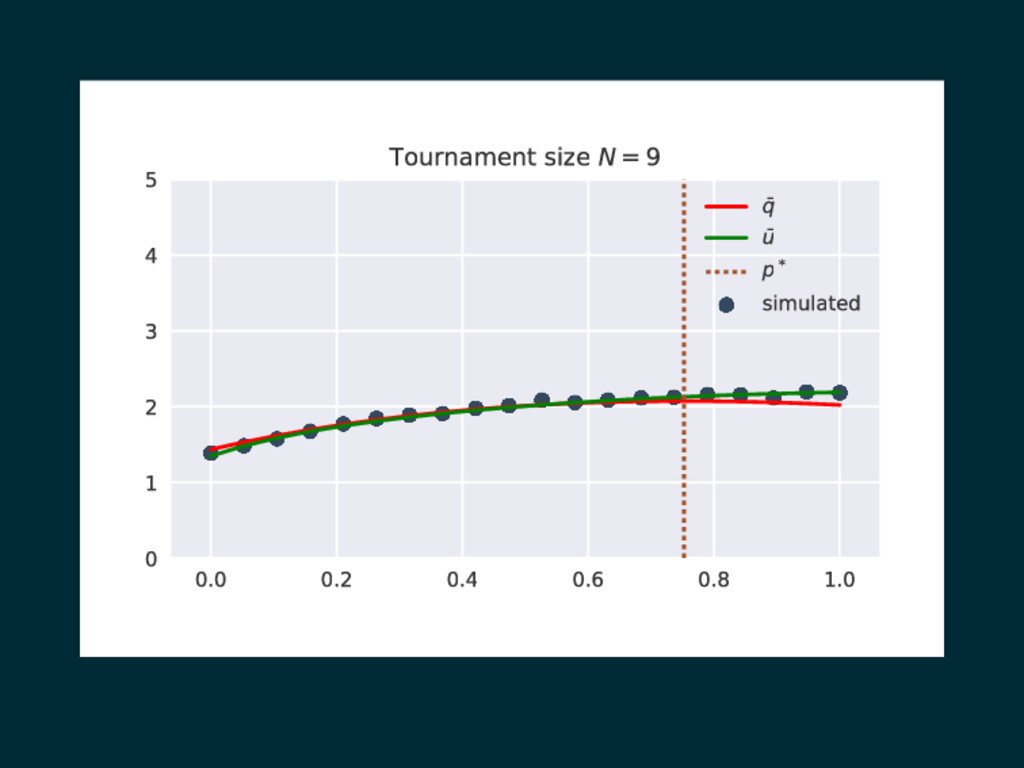
0.0 0.2 0.4 0.6 0.8 1.0 0 1 2 3
4 5 Tournament size N=9 q u p* simulated
p∗ = argmaxS q(1),...,q(n) u(p) where, | Sq(1),...,q(n) |≤ 2N
+ 2
p∗ = argmaxS q(1),...,q(n) u(p) where, | Sq(1),...,q(n) |≤ 2N
+ 2 @NikoletaGlyn https://github.com/Nikoleta-v3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![maxp uq (p) such that p ∈ R4 [0,1]](https://files.speakerdeck.com/presentations/84e46362bcf04b4986f2fe38c3ec3e52/slide_9.jpg){kind=link}
{kind=link}
![maxp uq (p) such that p ∈ R4 [0,1]](https://files.speakerdeck.com/presentations/84e46362bcf04b4986f2fe38c3ec3e52/slide_11.jpg){kind=link}
![maxp uq (p) such that p ∈ R4 [0,1] subject](https://files.speakerdeck.com/presentations/84e46362bcf04b4986f2fe38c3ec3e52/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
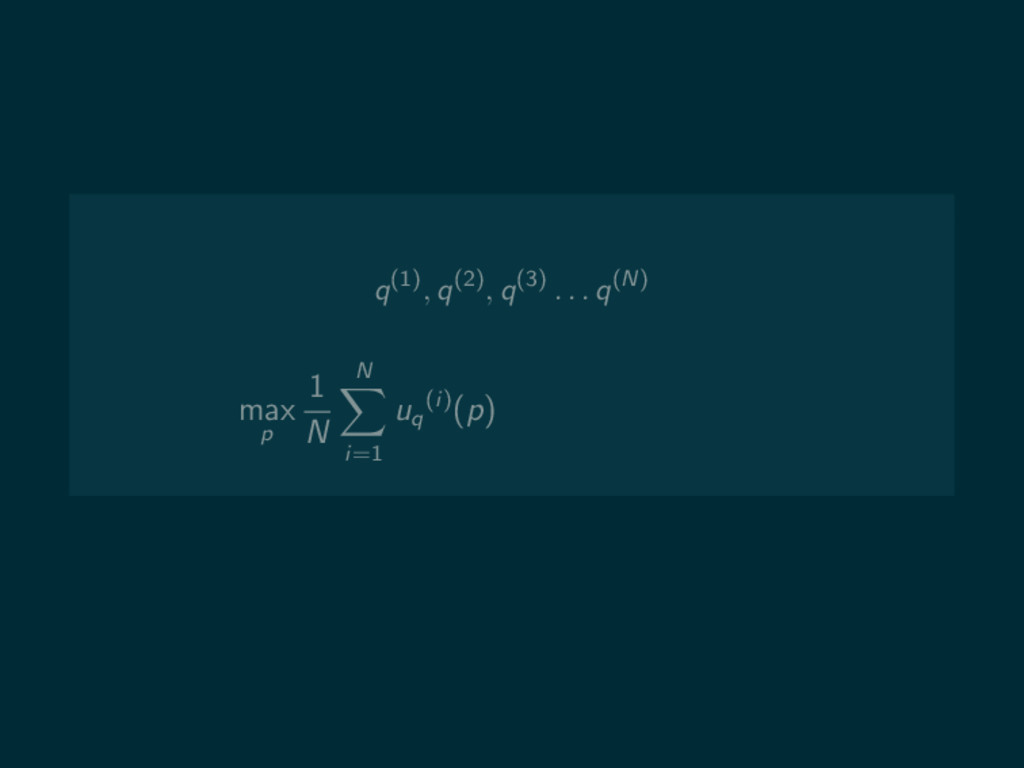{kind=link}
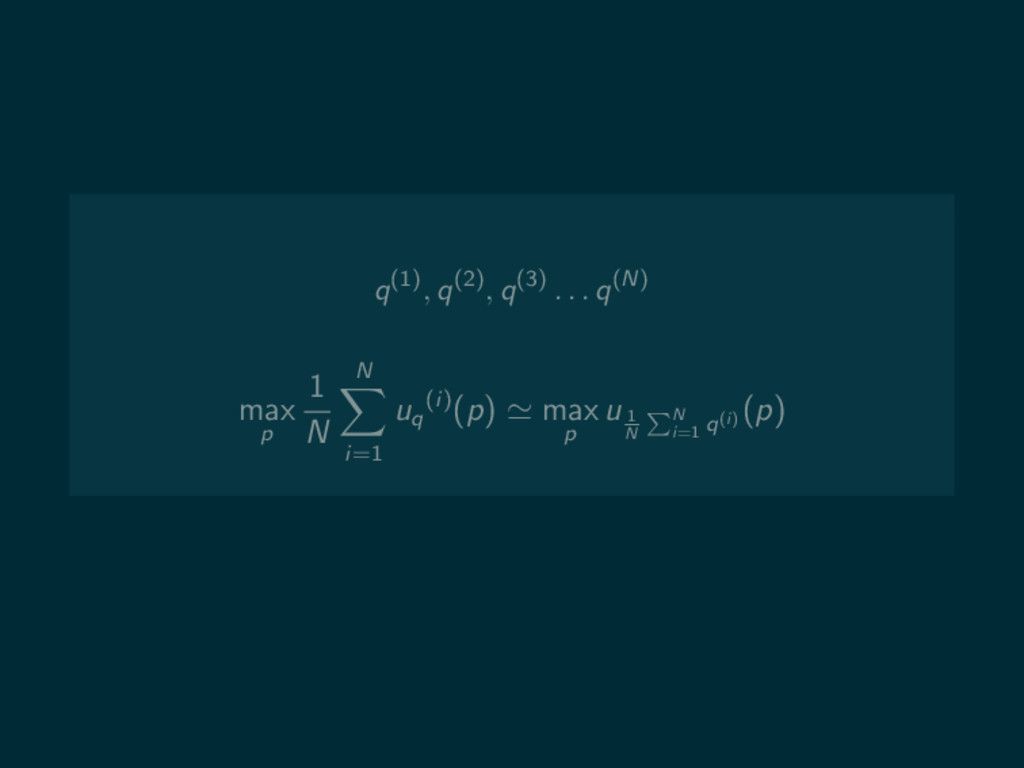{kind=link}
{kind=link}
{kind=link}
{kind=link}