Slide deck from the ASEAN Cloud Summit meetup on 27 January 2022. The session cover the following topics
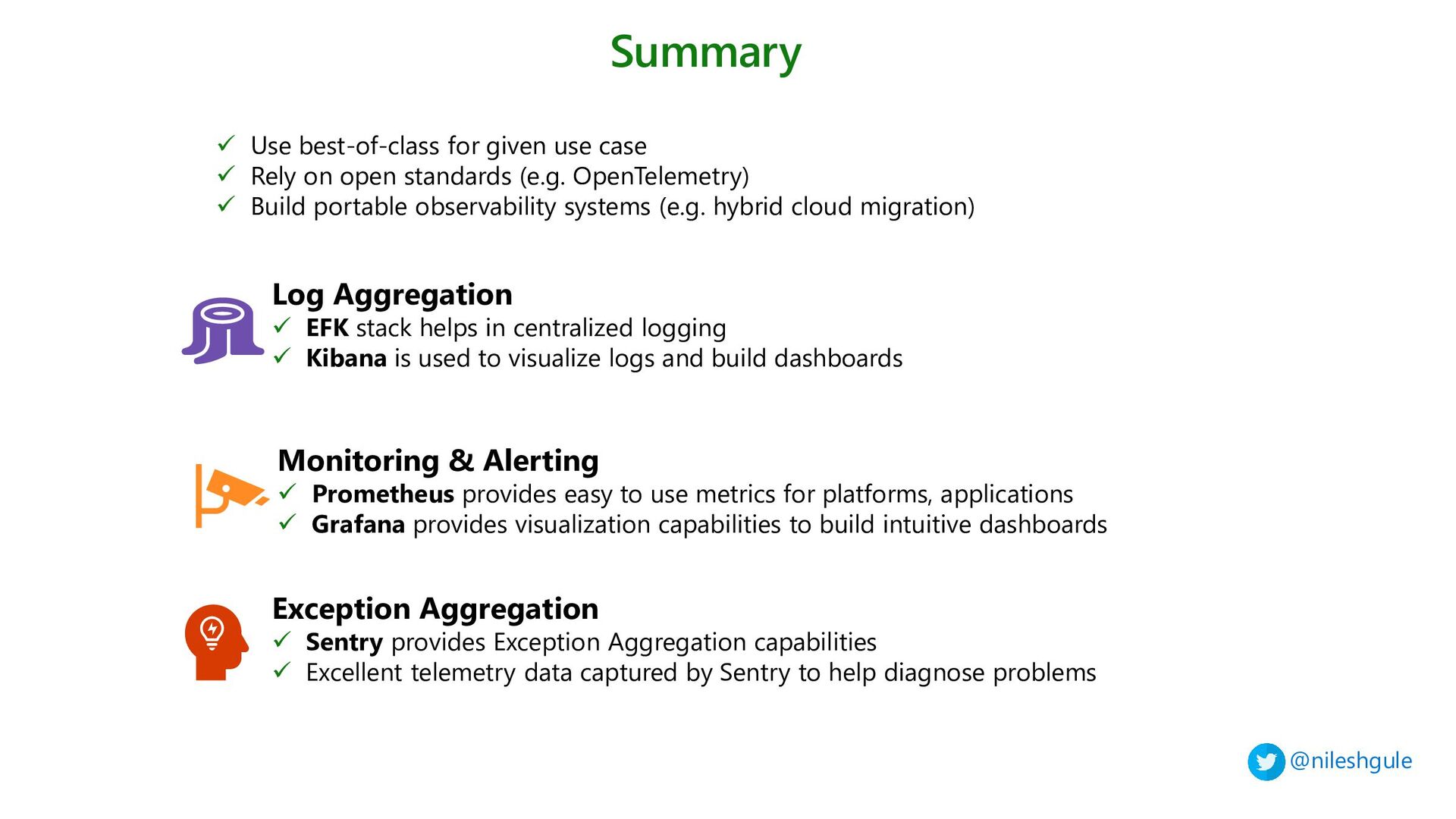
1 - Centralized Loggin with Elasticsearch, Fluentbit and Kibana
2 - Monitoring and Alerting with Prometheus and Grafana
3 - Exception aggregation with Sentry
The live demo showcased these aspects using Azure Kubernetes Service (AKS)
{kind=link}
{kind=link}
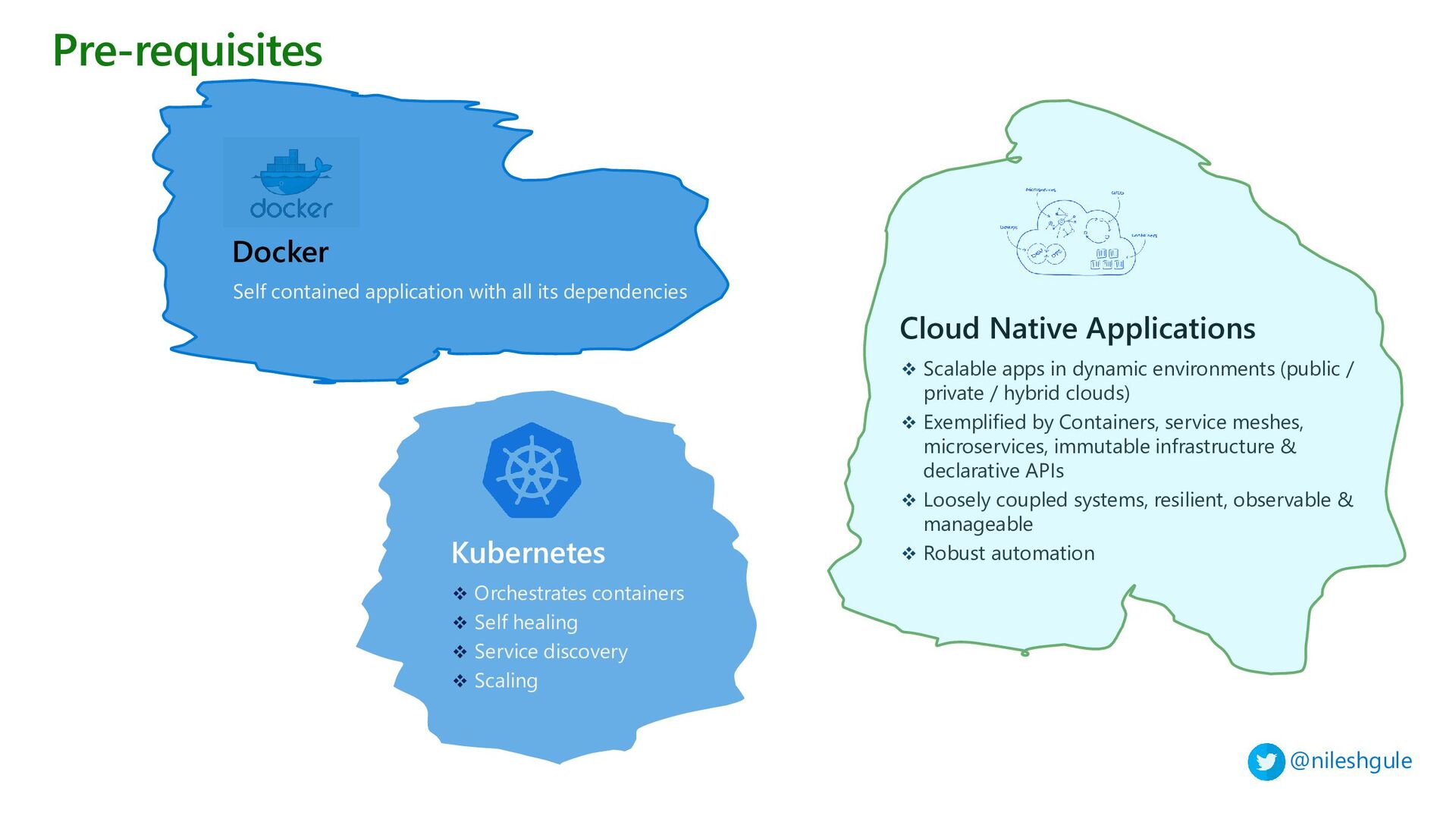{kind=link}
{kind=link}
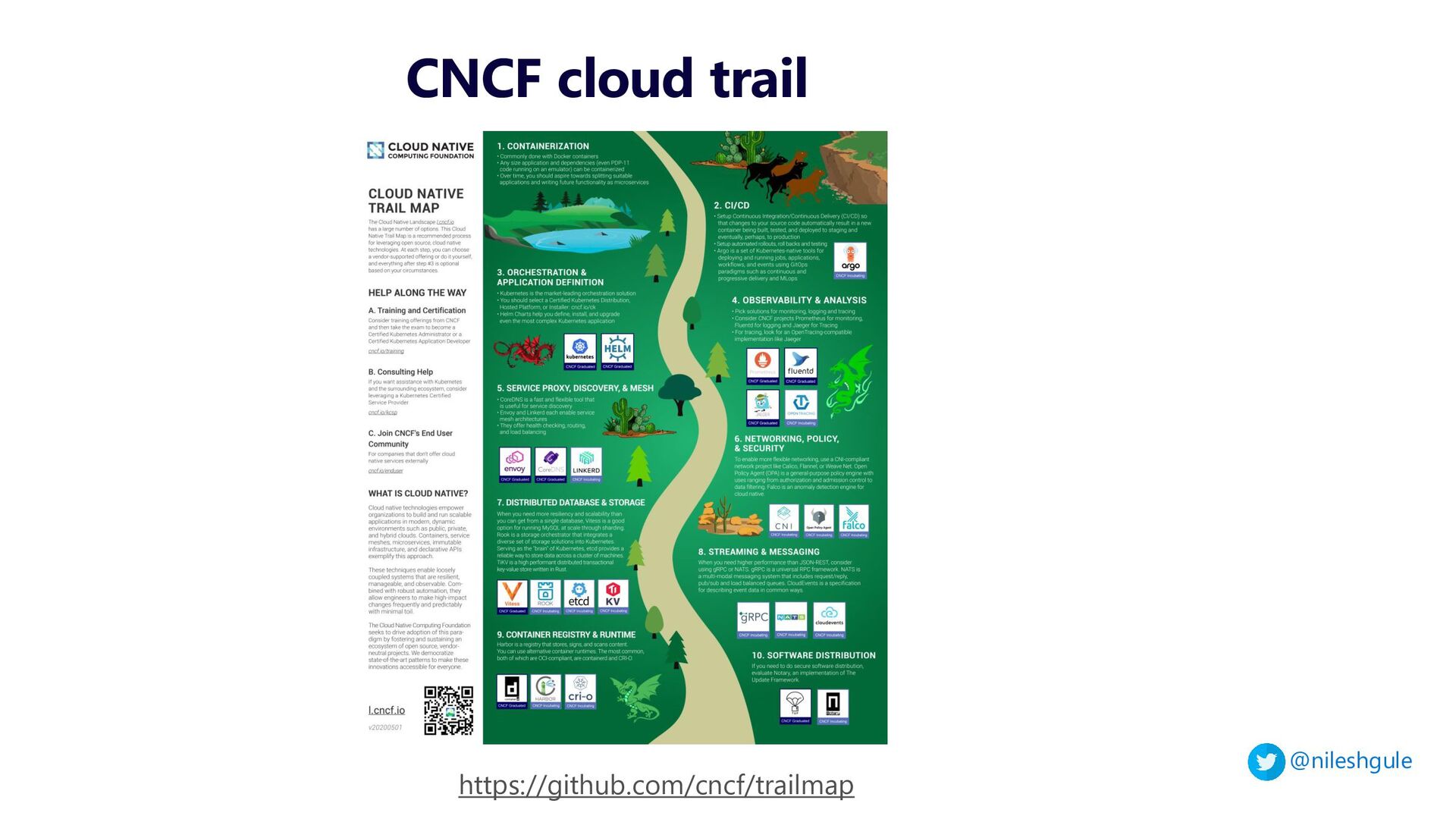{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
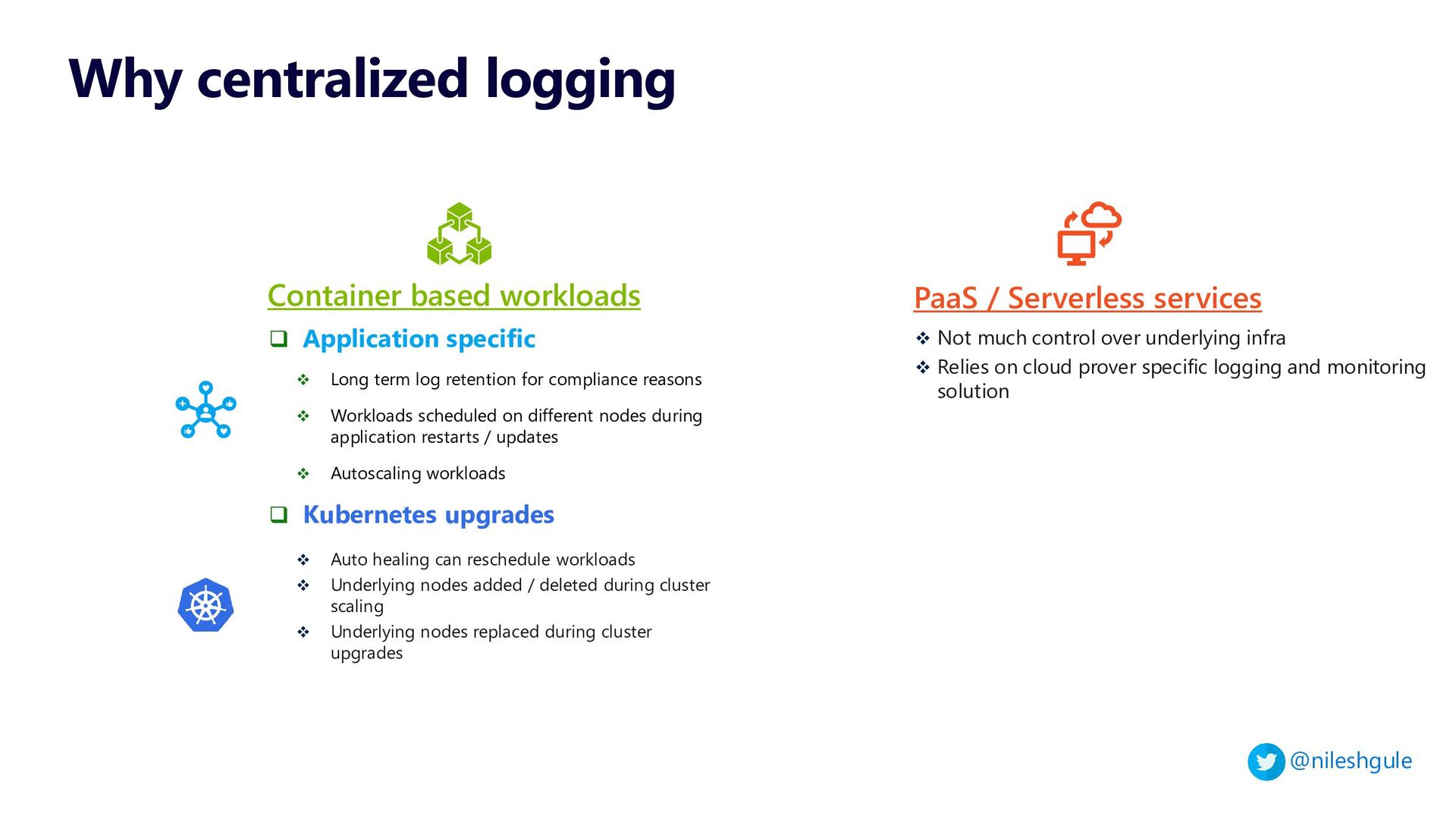{kind=link}
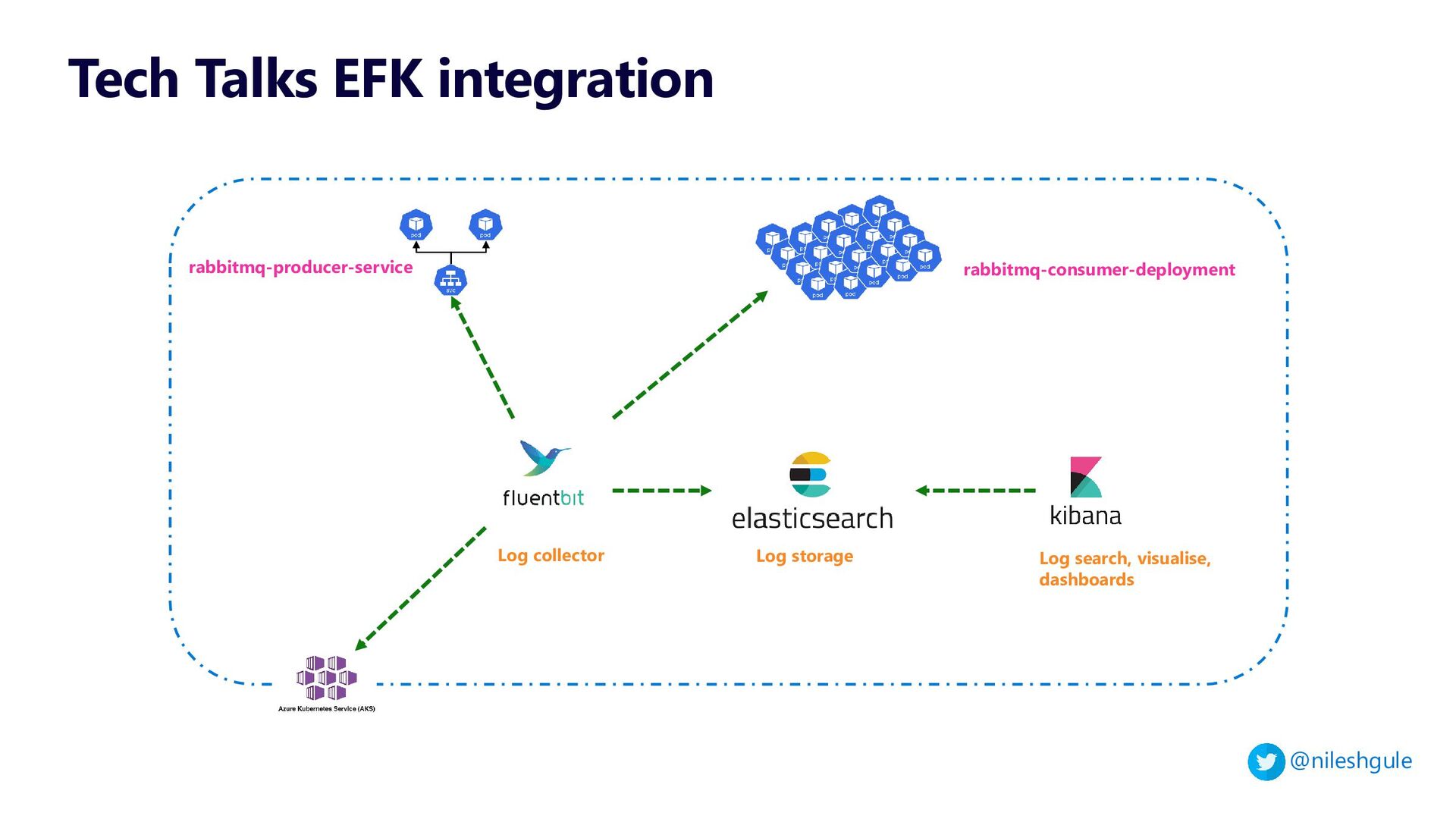{kind=link}
{kind=link}
{kind=link}
{kind=link}
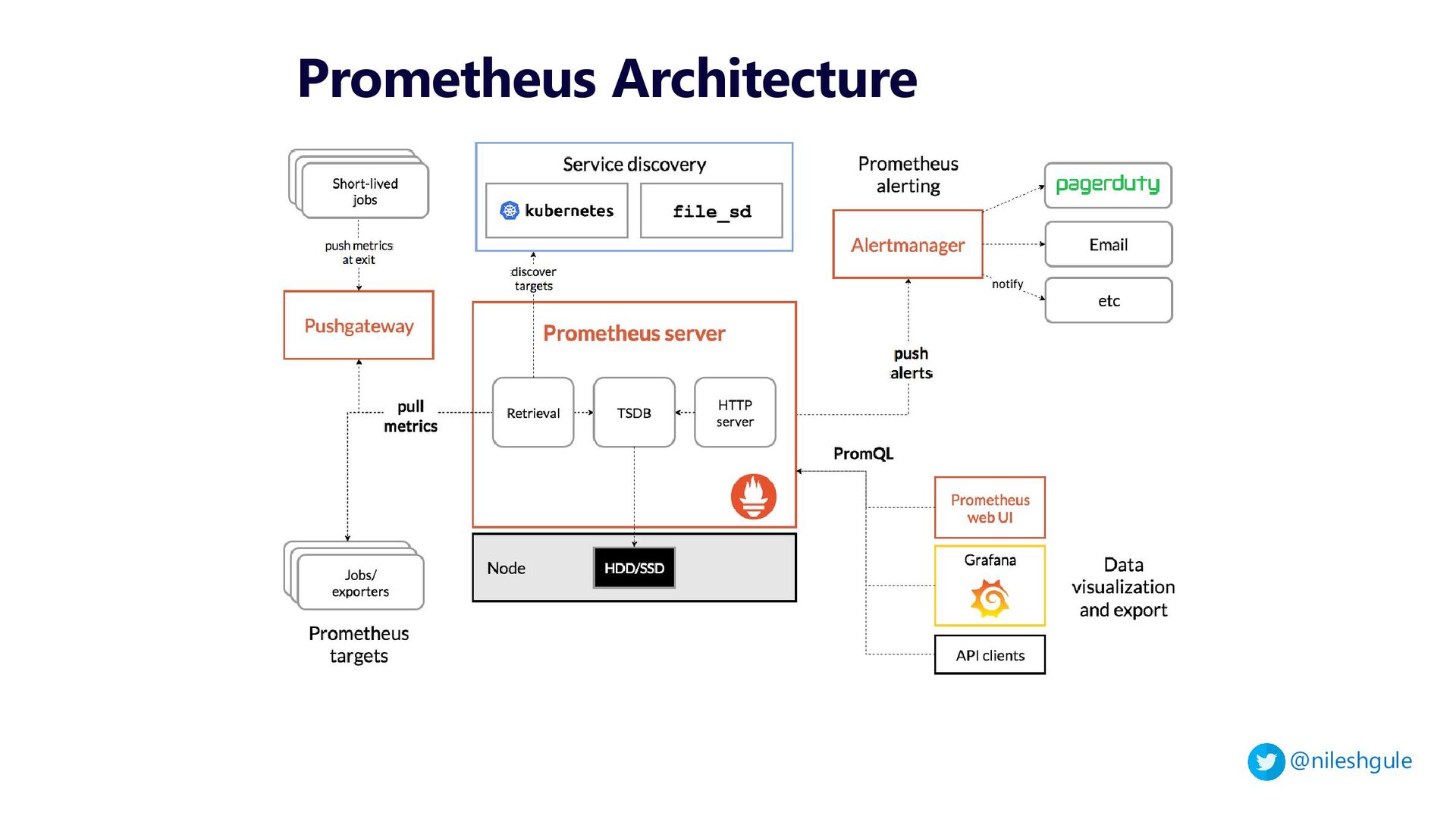{kind=link}
{kind=link}
{kind=link}
{kind=link}
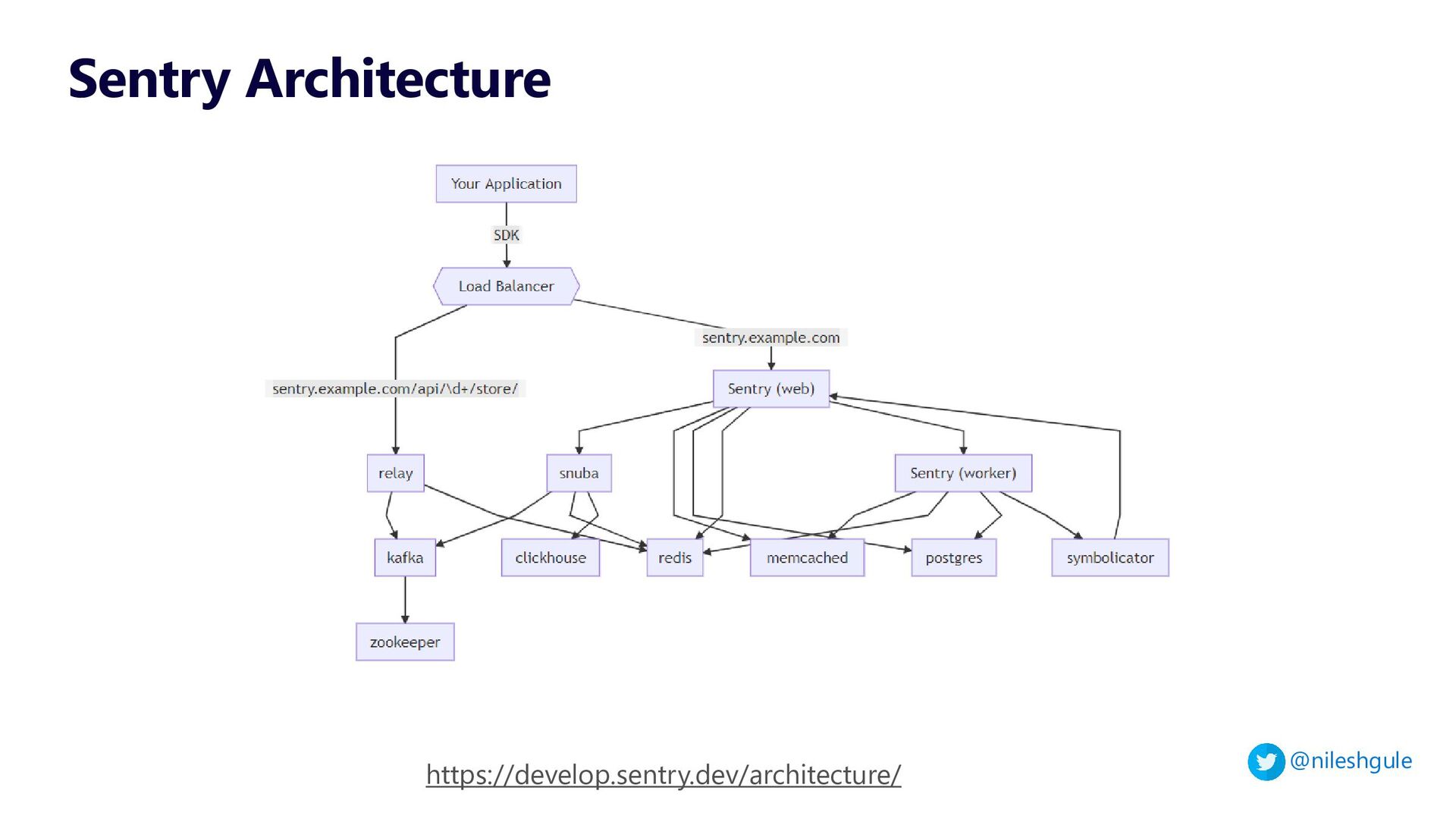{kind=link}
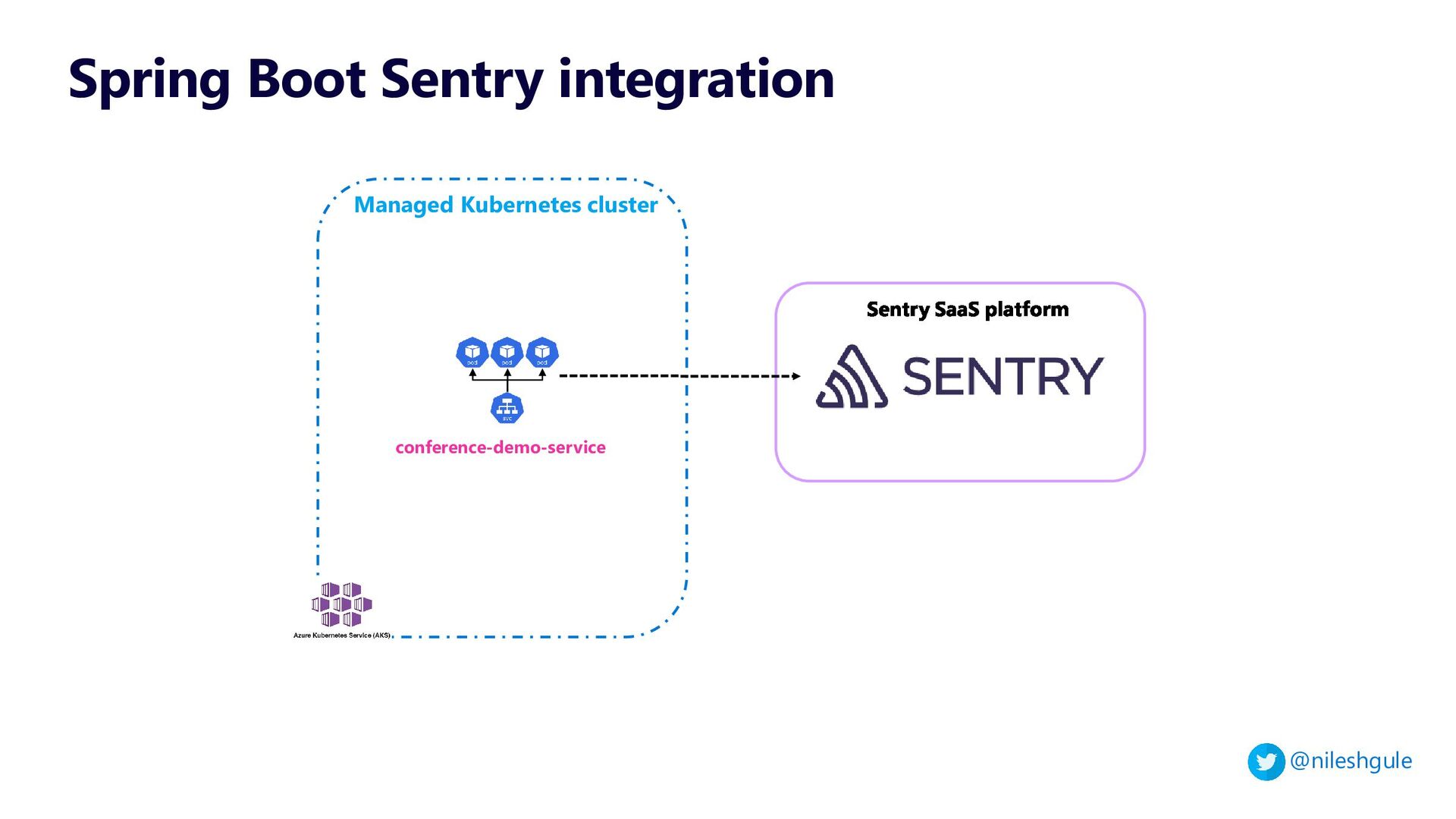{kind=link}
{kind=link}
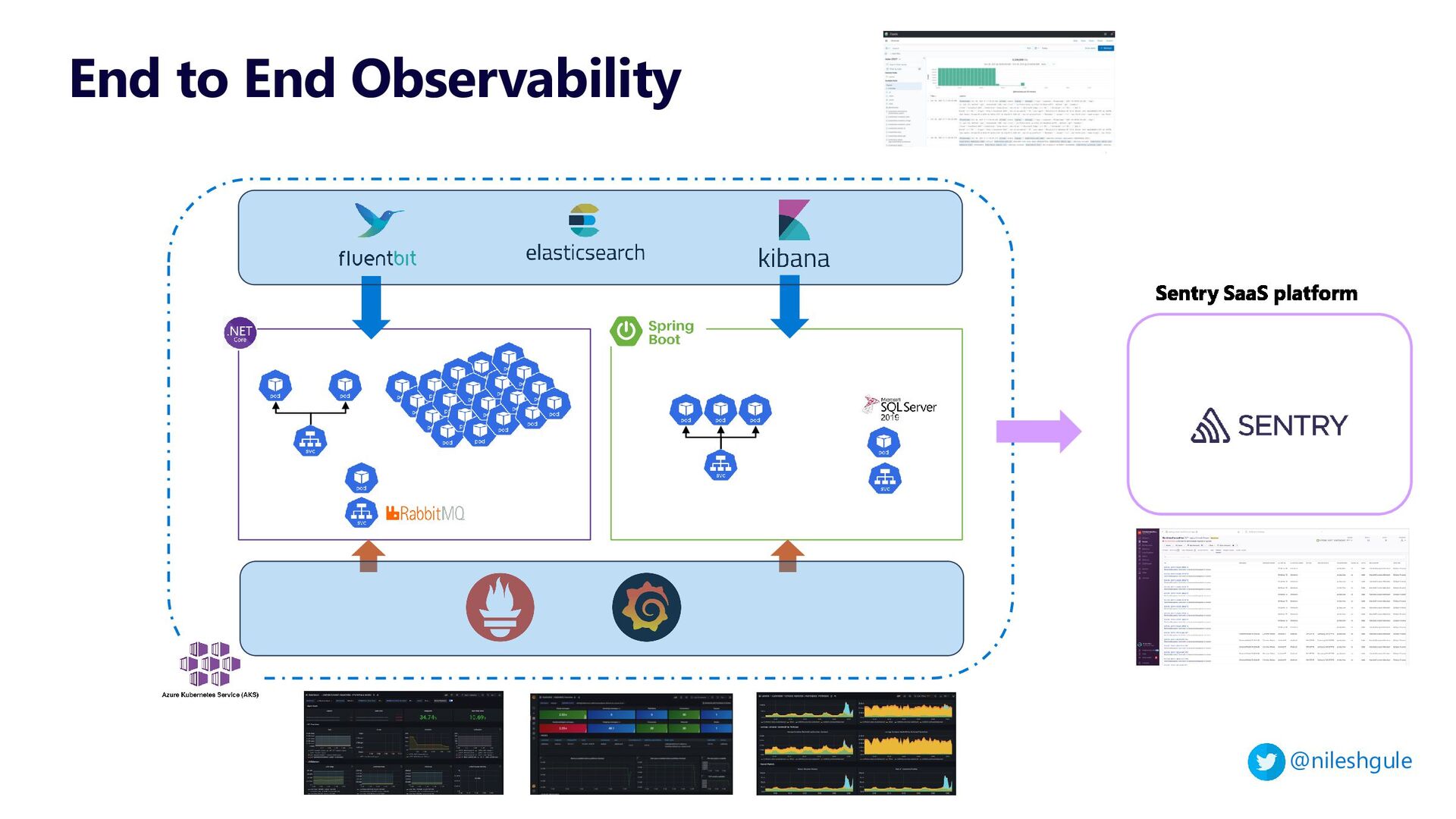{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}