×2 RMSE ×3 Multi RMSE ×1) Final Model (CatBoost) features features preprocess feature engineering Model (Bert base) pretrain features feature engineering テキストデータ ・タイトル ・タグ ・あらすじ その他のデータ ・掲載⽇時 ・ジャンル ・作者名など Step0 : データセットだけある.
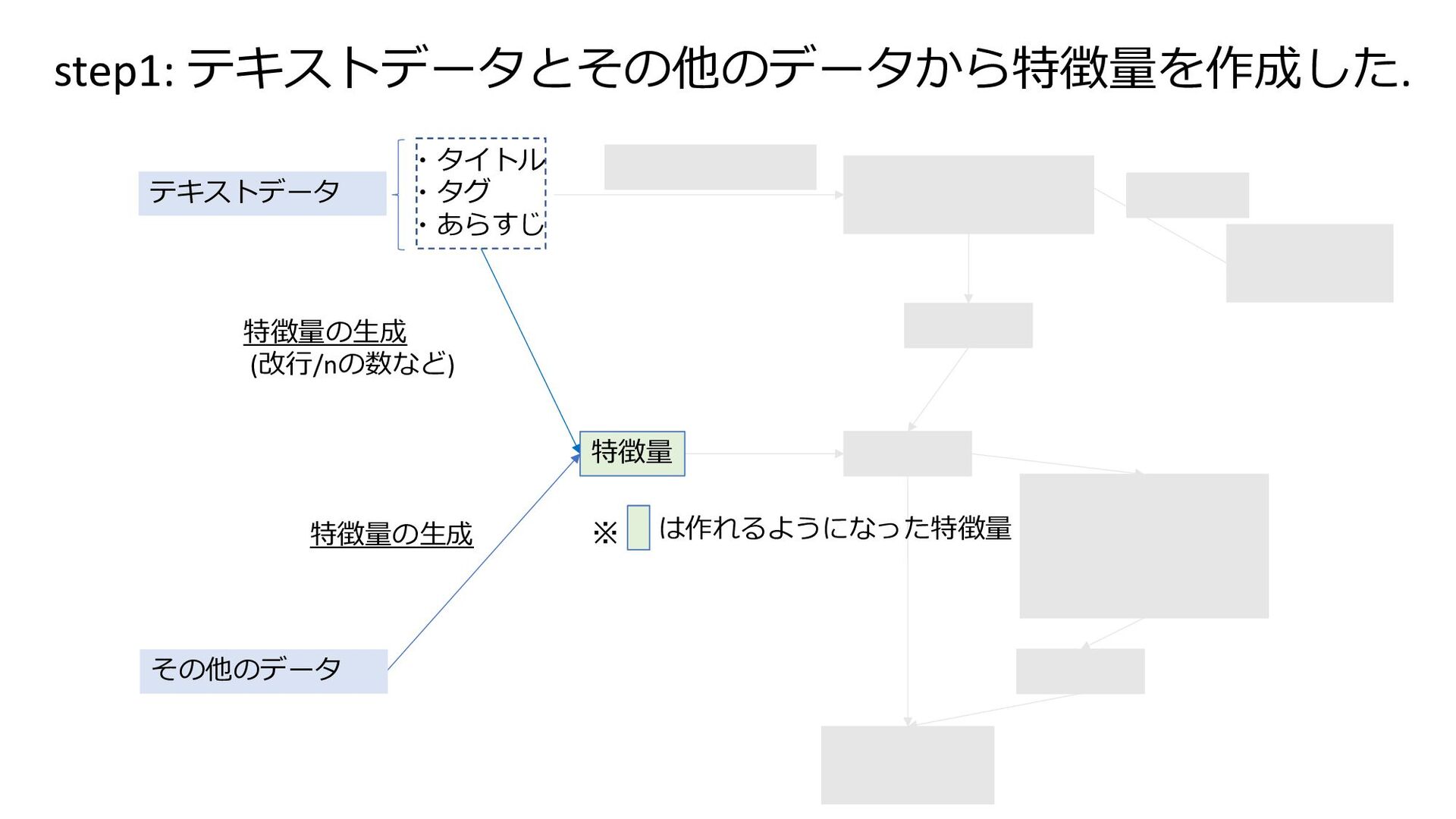
RMSE ×3 Multi RMSE ×1) Final Model (CatBoost) features features preprocess Model (Bert base) pretrain features は作れるようになった特徴量 ※ テキストデータ その他のデータ 特徴量の⽣成 (改⾏/nの数など) 特徴量の⽣成 ・タイトル ・タグ ・あらすじ 特徴量 step1: テキストデータとその他のデータから特徴量を作成した.
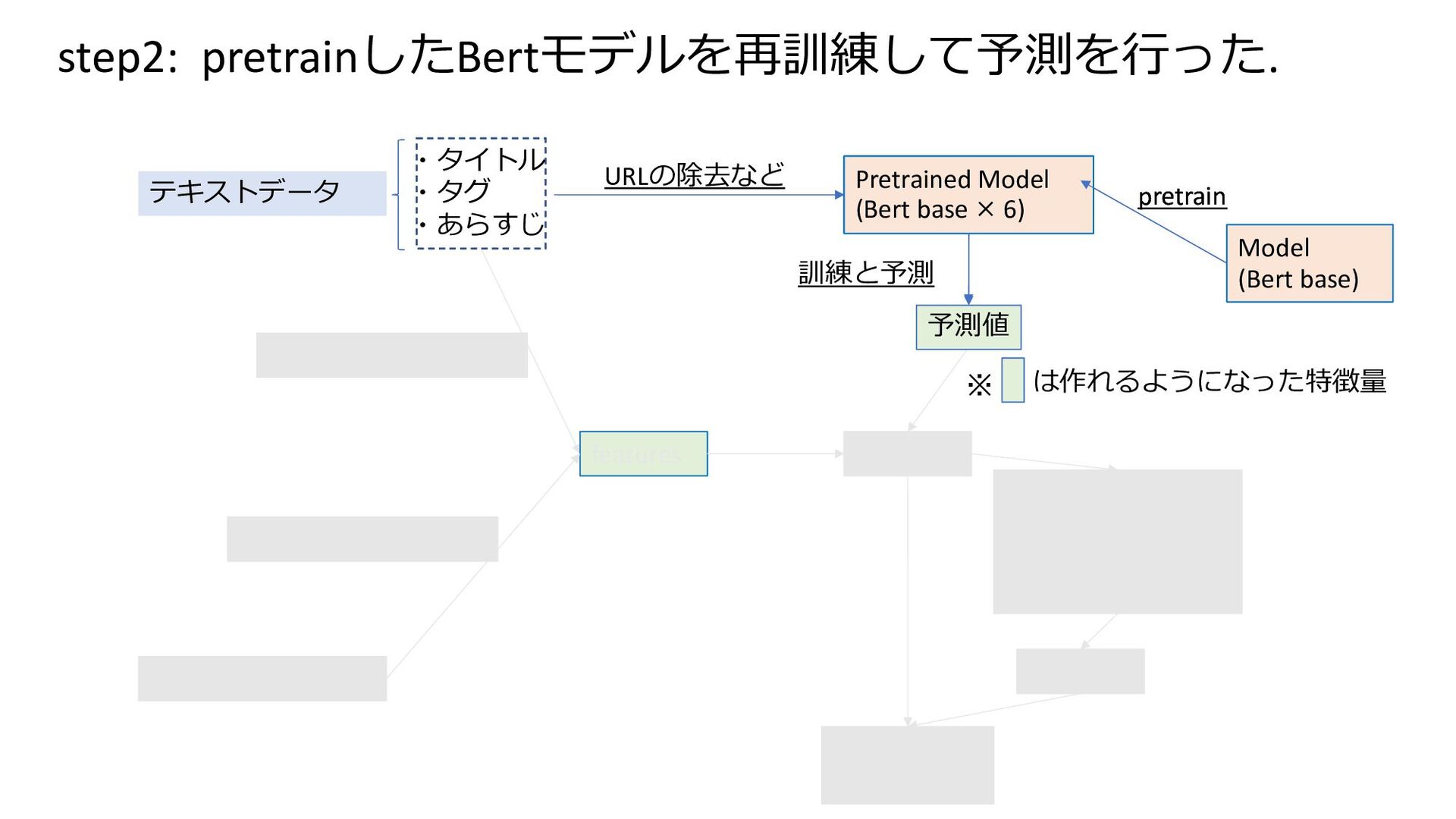
features Model (CatBoost) (Binary ×2 RMSE ×3 MulI RMSE ×1) Final Model (CatBoost) features features feature engineering Model (Bert base) pretrain feature engineering は作れるようになった特徴量 ※ テキストデータ ・タイトル ・タグ ・あらすじ Pretrained Model (Bert base × 6) Model (Bert base) pretrain 予測値 訓練と予測 URLの除去など step2: pretrainしたBertモデルを再訓練して予測を⾏った.
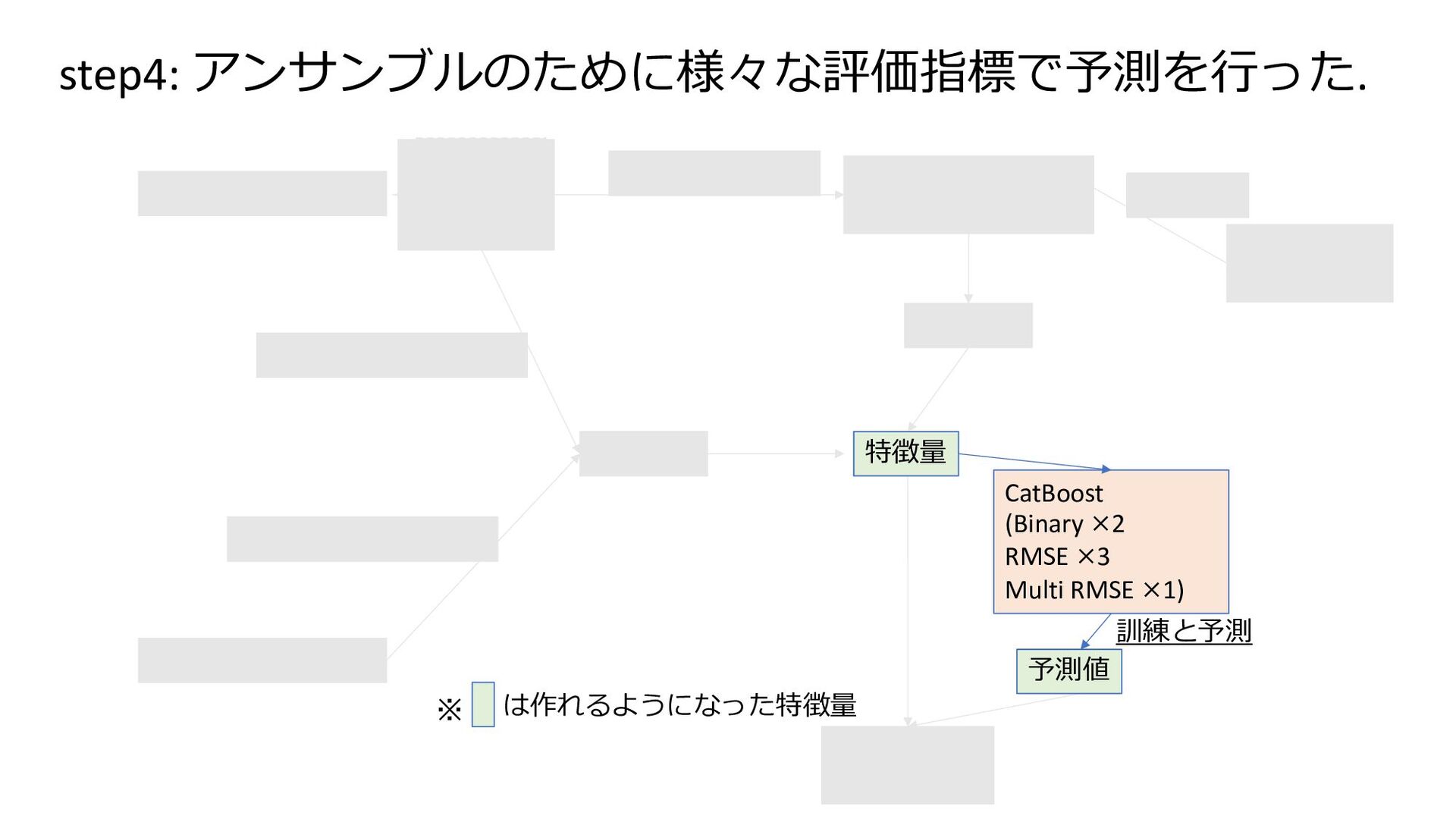
base × 6) features CatBoost (Binary ×2 RMSE ×3 Multi RMSE ×1) Final Model (CatBoost) preprocess feature engineering Model (Bert base) pretrain features feature engineering は作れるようになった特徴量 ※ 特徴量 訓練と予測 予測値 step4: アンサンブルのために様々な評価指標で予測を⾏った.
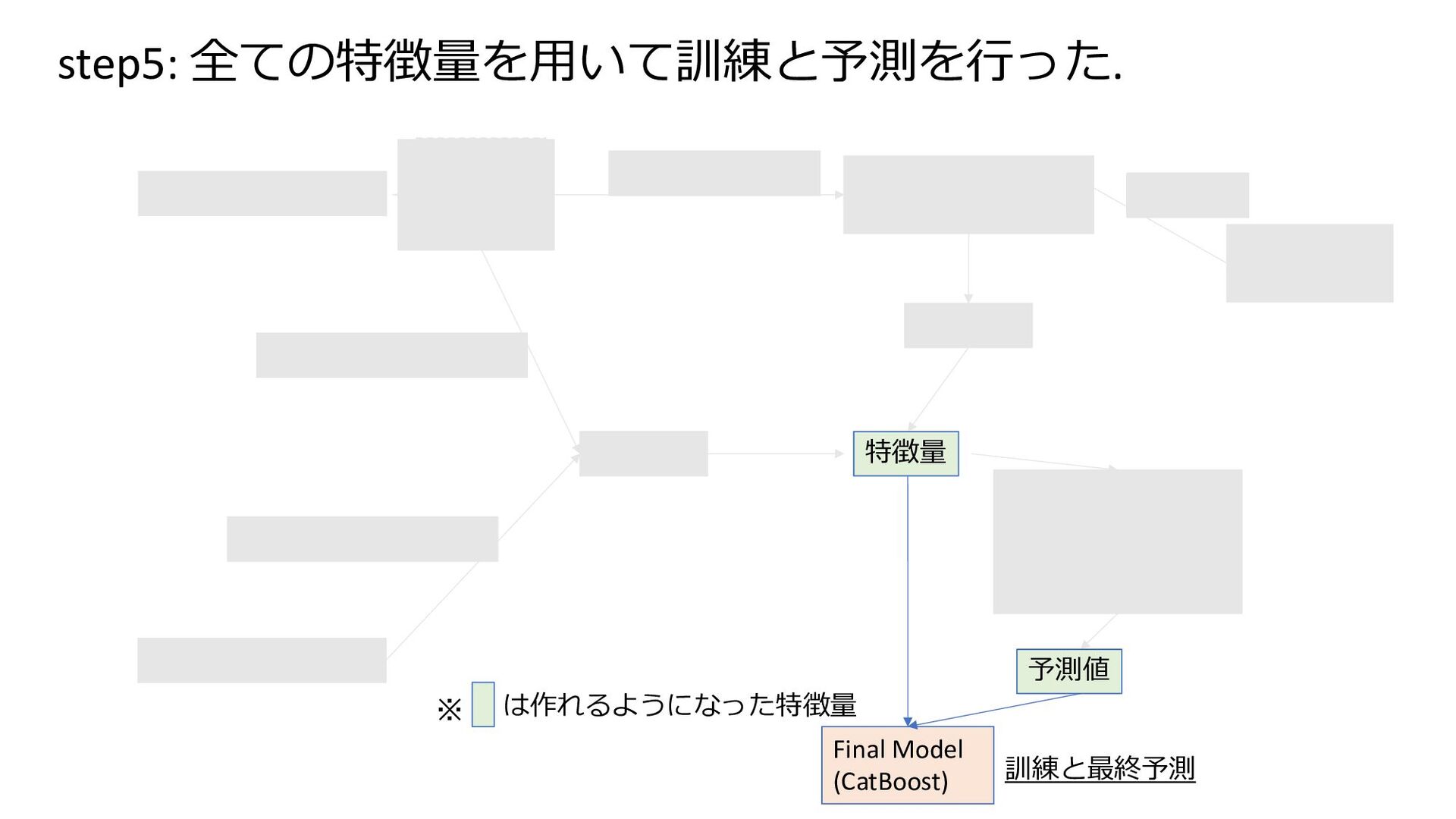
base × 6) features Model (CatBoost) (Binary ×2 RMSE ×3 Multi RMSE ×1) Final Model (CatBoost) preprocess feature engineering Model (Bert base) pretrain features feature engineering は作れるようになった特徴量 ※ 予測値 特徴量 訓練と最終予測 step5: 全ての特徴量を⽤いて訓練と予測を⾏った.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}