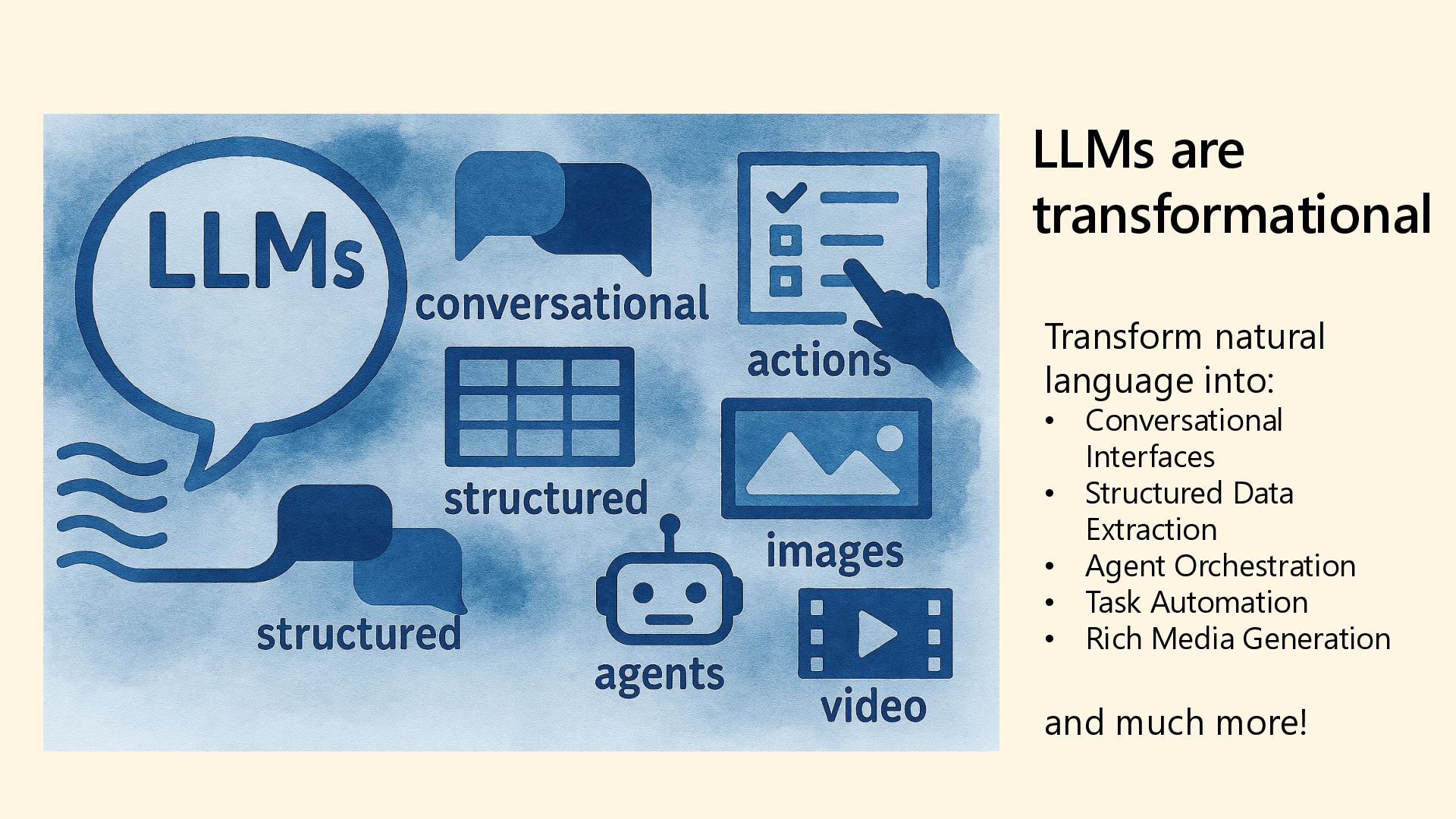
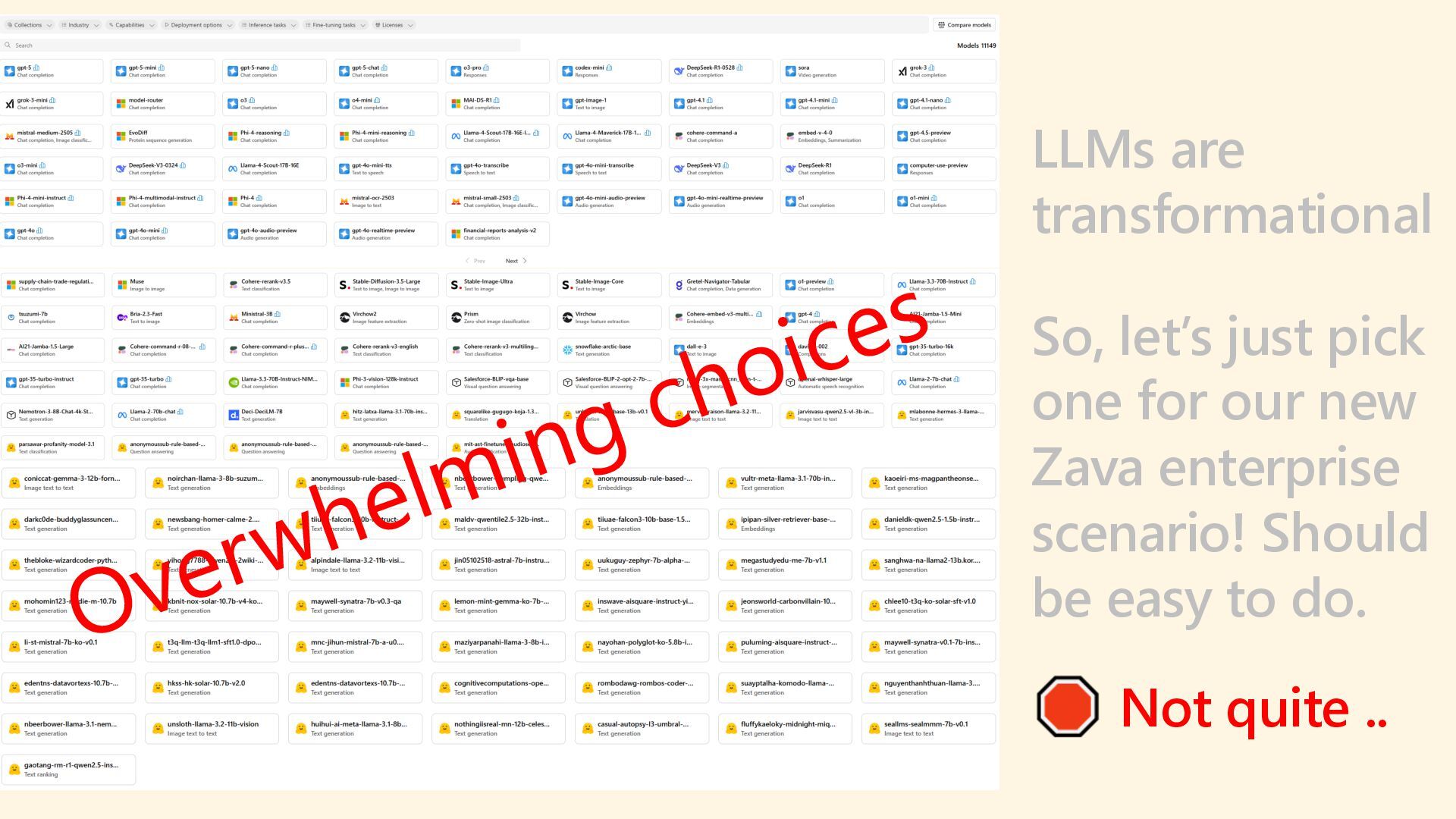
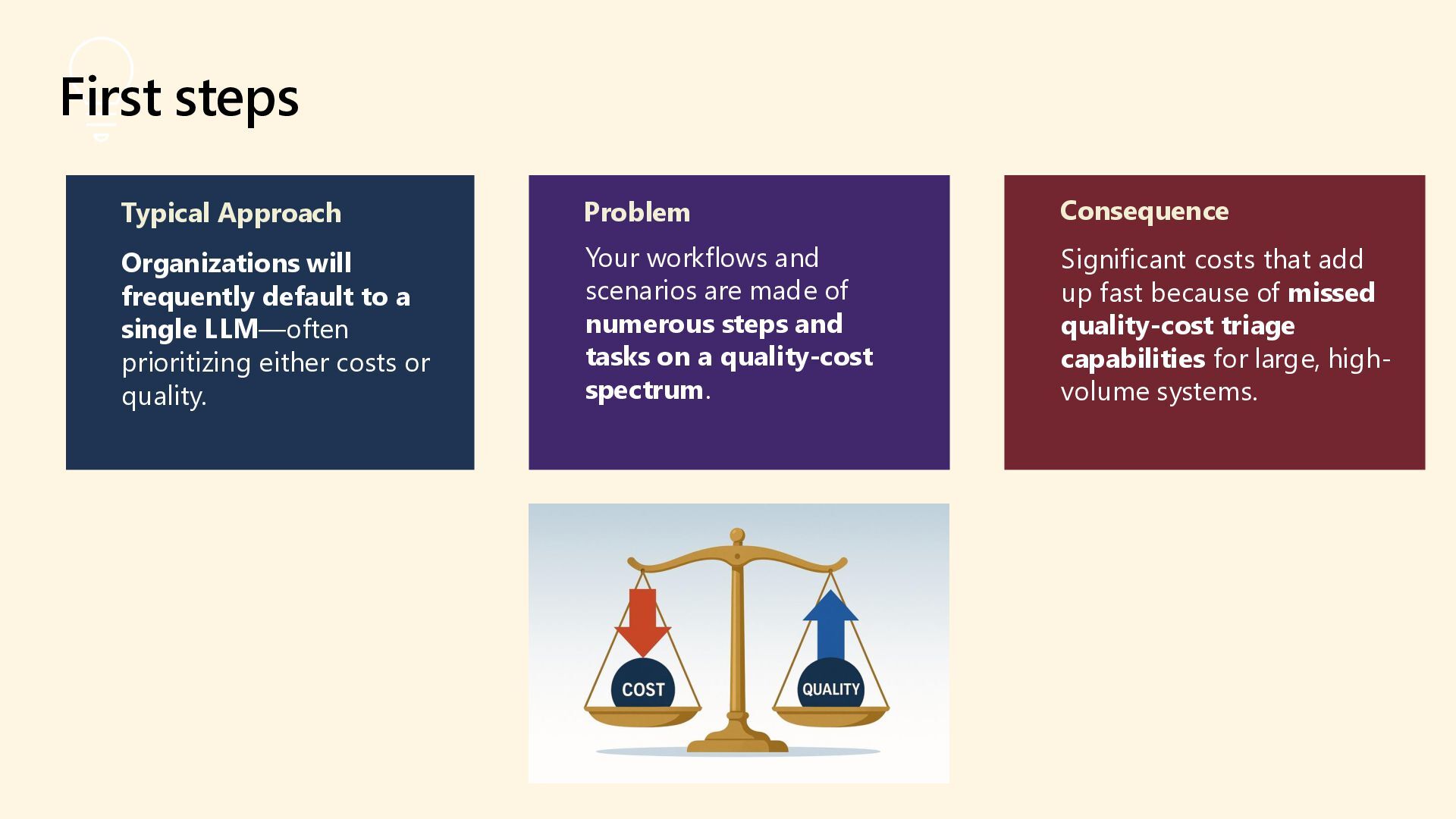
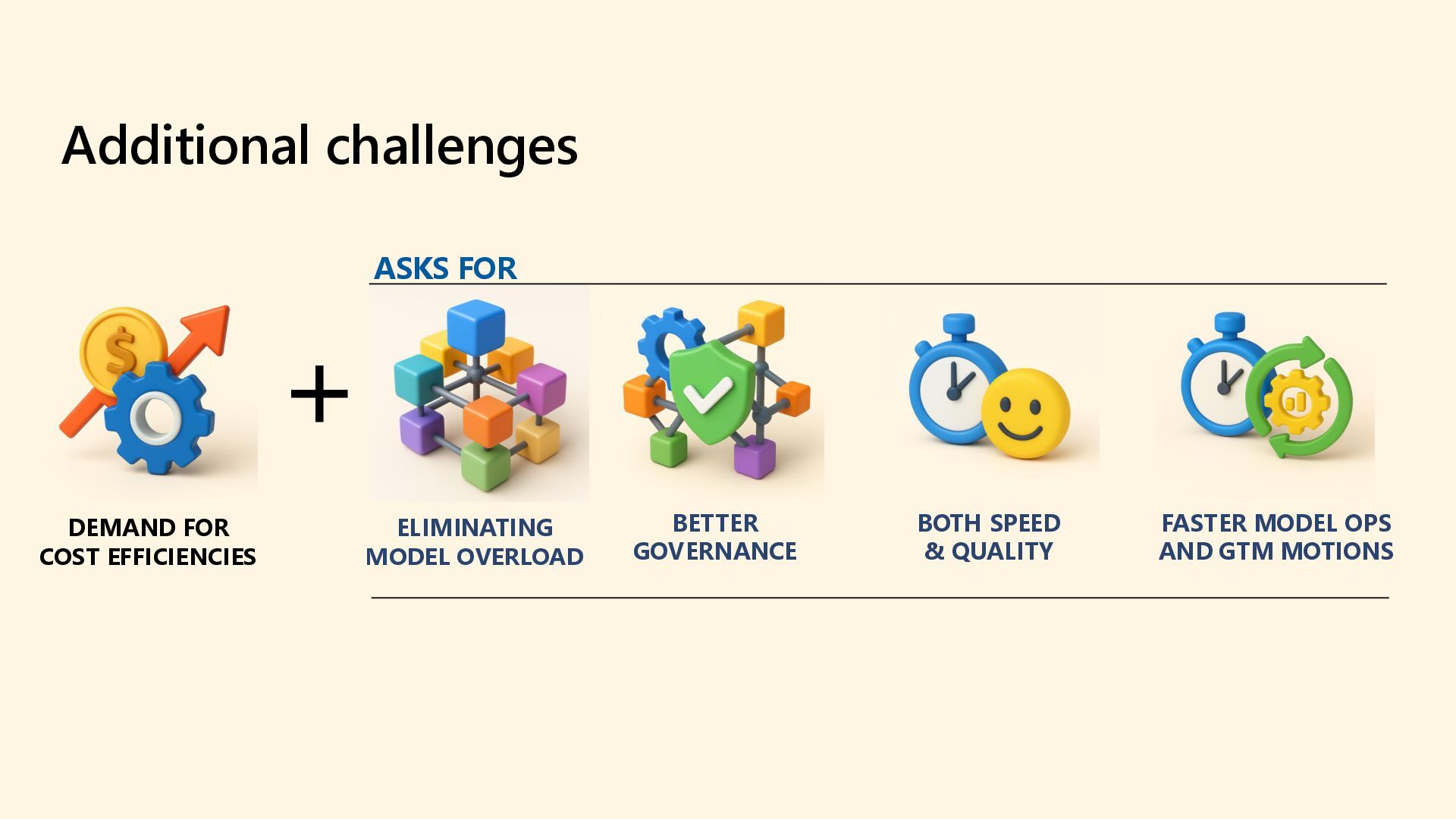
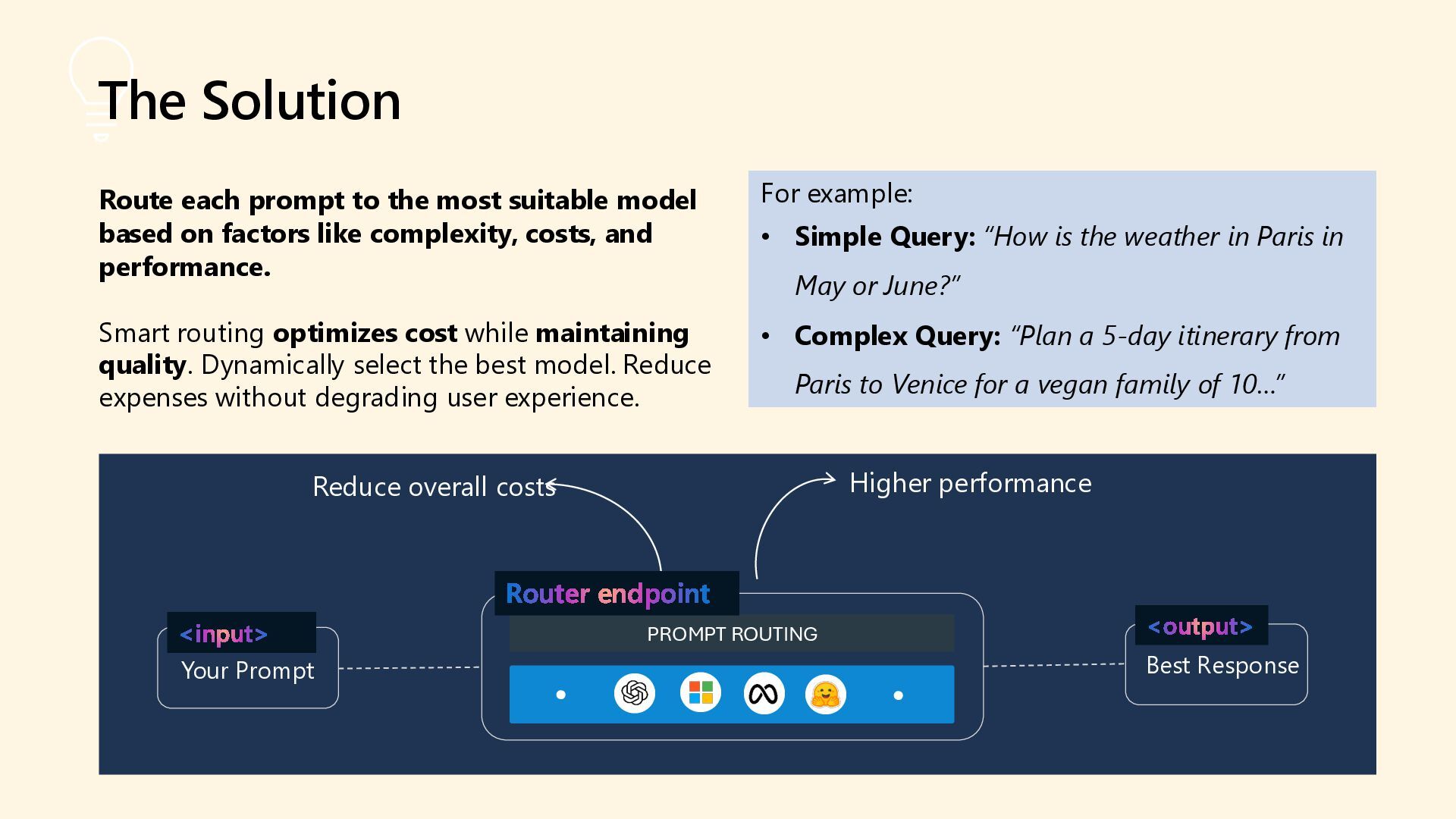
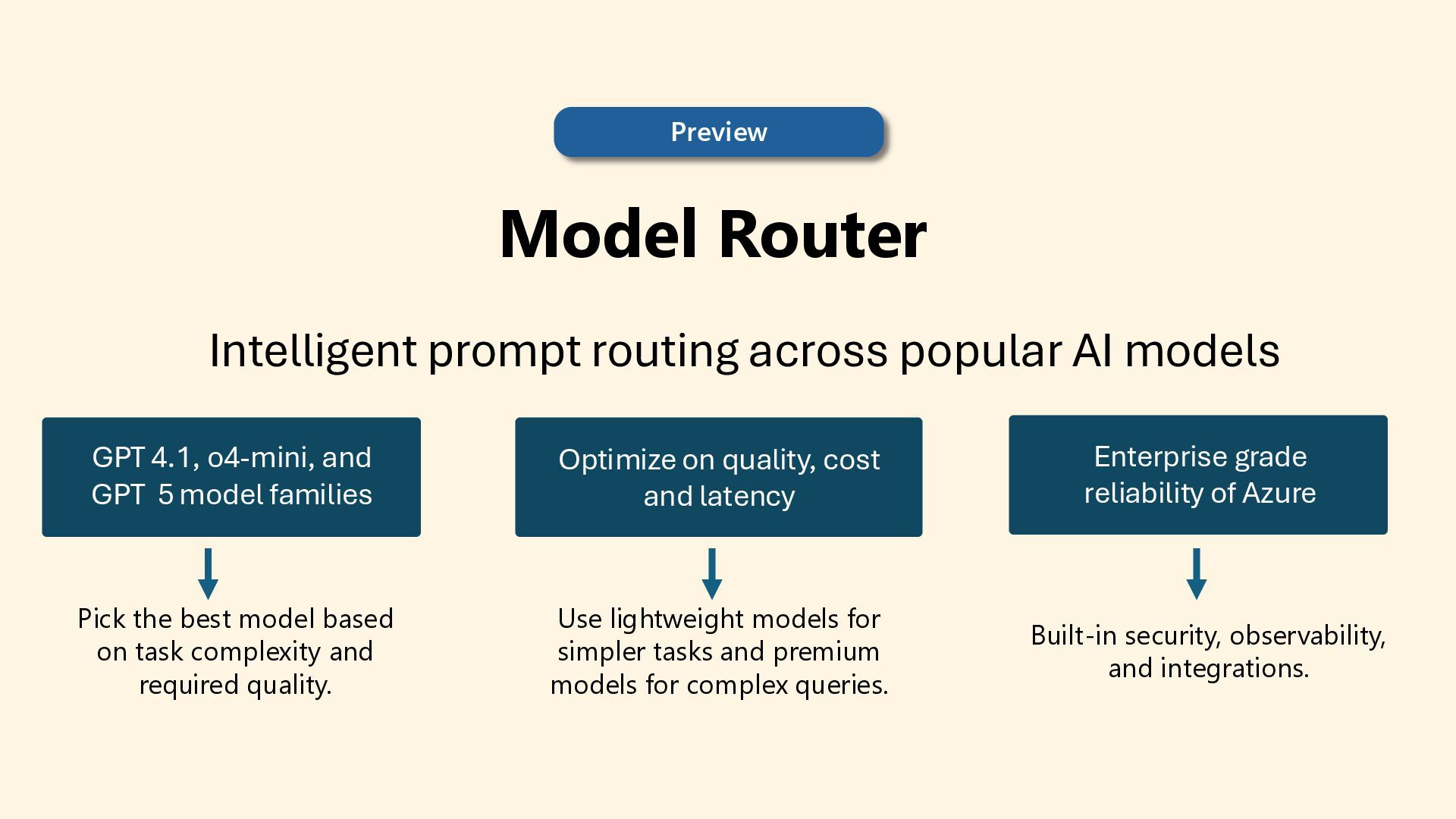
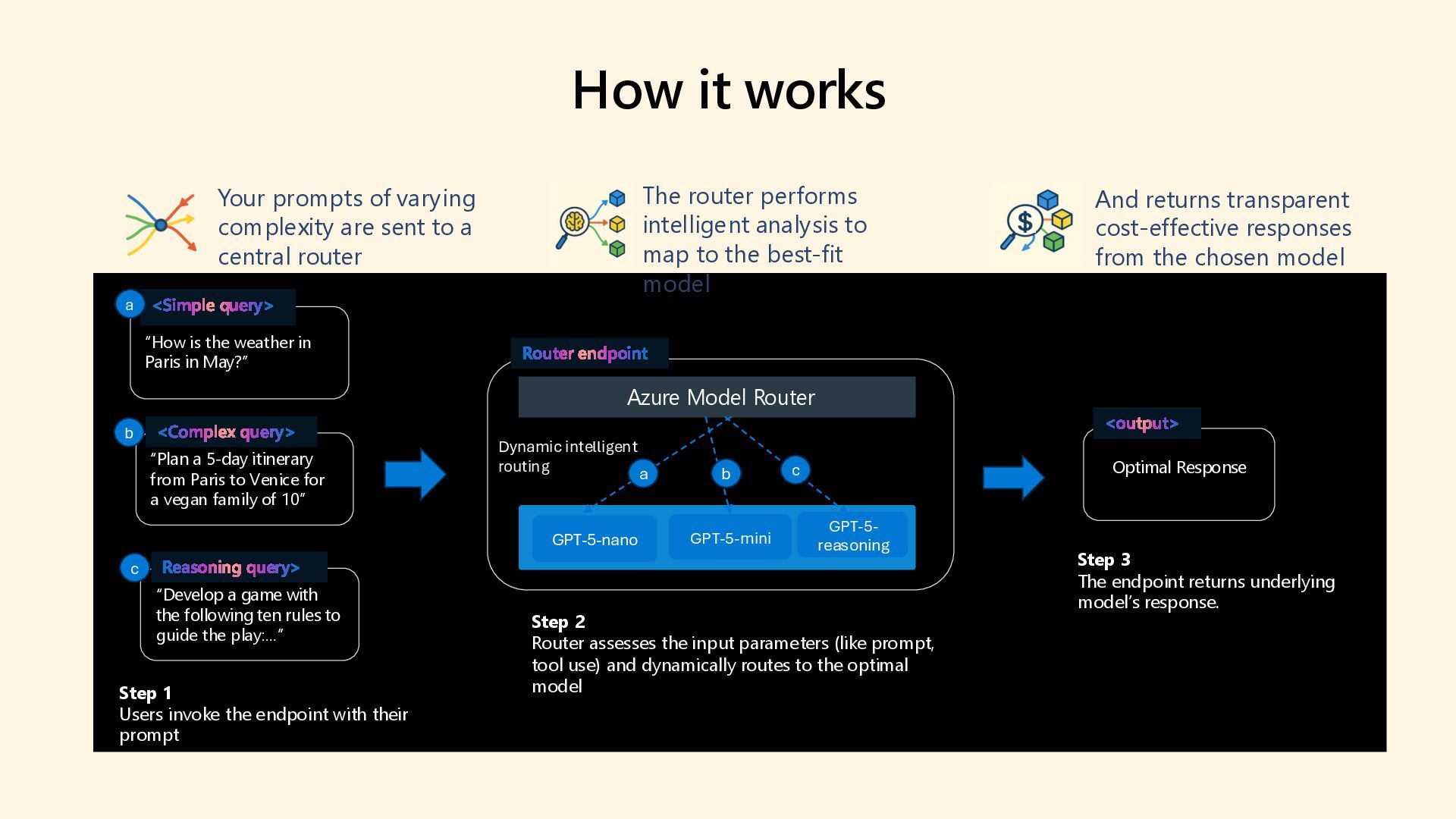
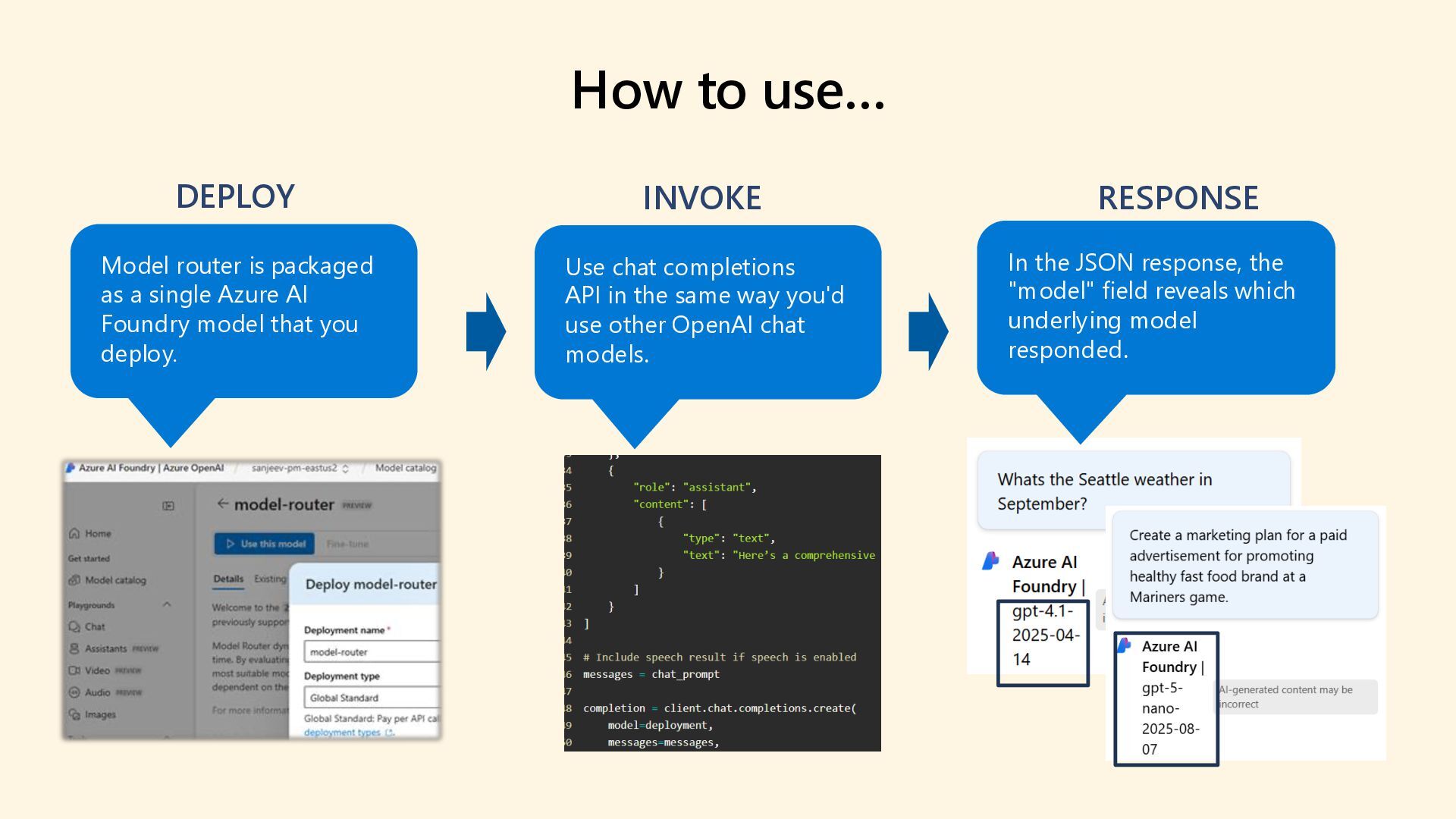
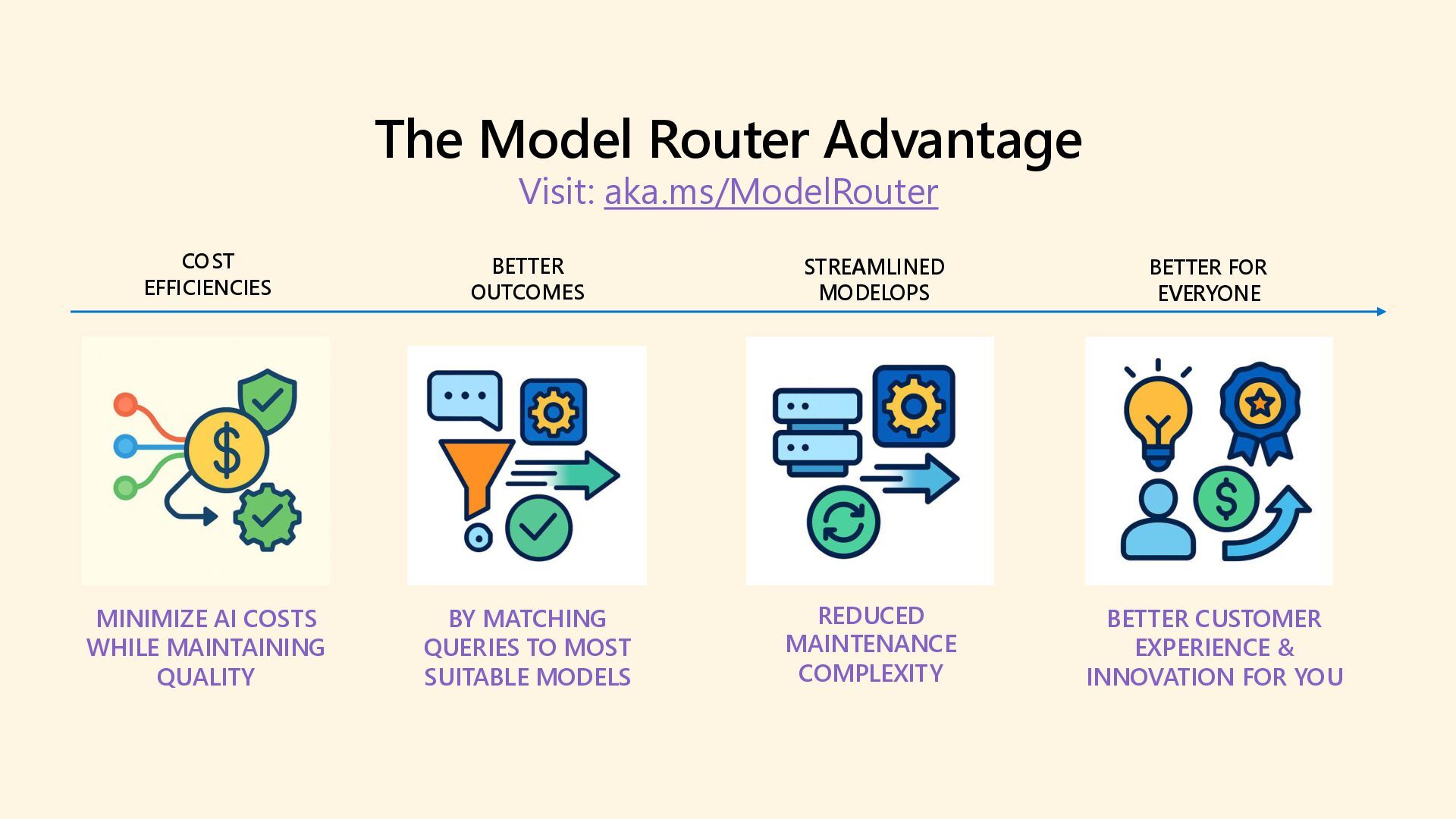
As 85% of enterprises embrace multi-model AI strategies, developers face growing complexity in selecting, deploying, and managing the right models for each task. Discover how the model router in Azure AI Foundry intelligently automates model selection based on performance, cost, and latency. This intelligent orchestration layer reduces operational overhead, accelerates deployment, and unlocks scalable AI operations across your organization. Say goodbye to model fatigue and let the router do the strategic lifting.
Location: Toronto
Date: Oct 1, 2025
Session: https://aitour.microsoft.com/flow/microsoft/toronto26/sessioncatalog/page/sessioncatalog/session/1755310350425001jaaD
Visit the Repo:
https://github.com/microsoft/aitour26-LTG153-automate-model-selection-and-ai-app-design-with-azure-ai-foundry
Join the Discord:
https://aka.ms/model-mondays/discord
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}