The presentation starts by introduce the concepts of IoT illustrated of some examples.
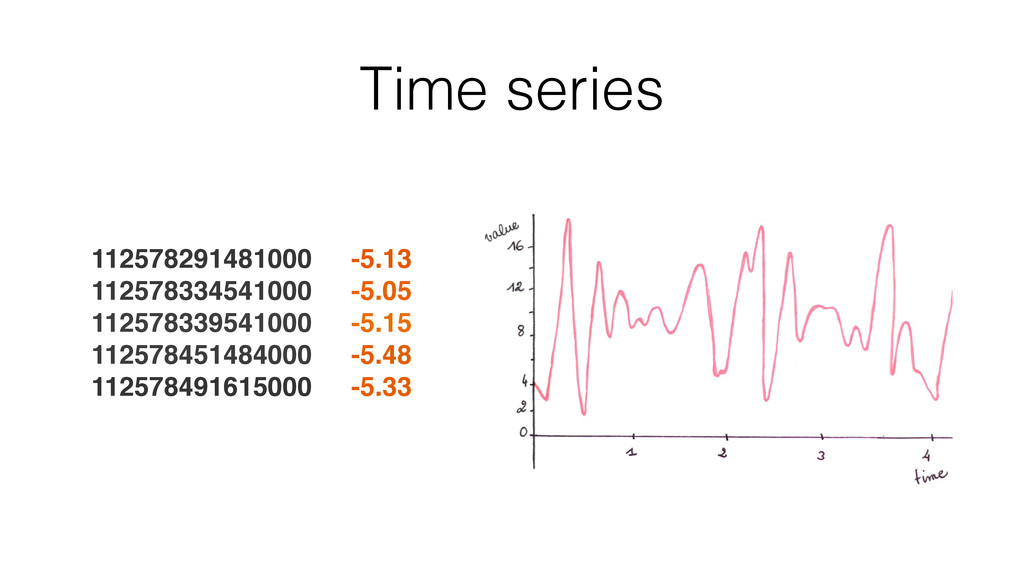
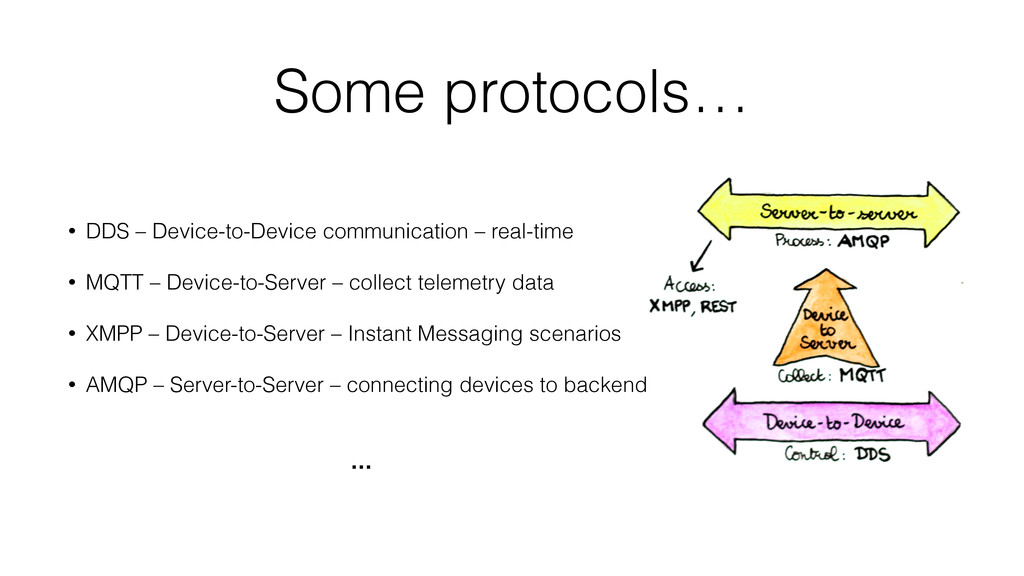
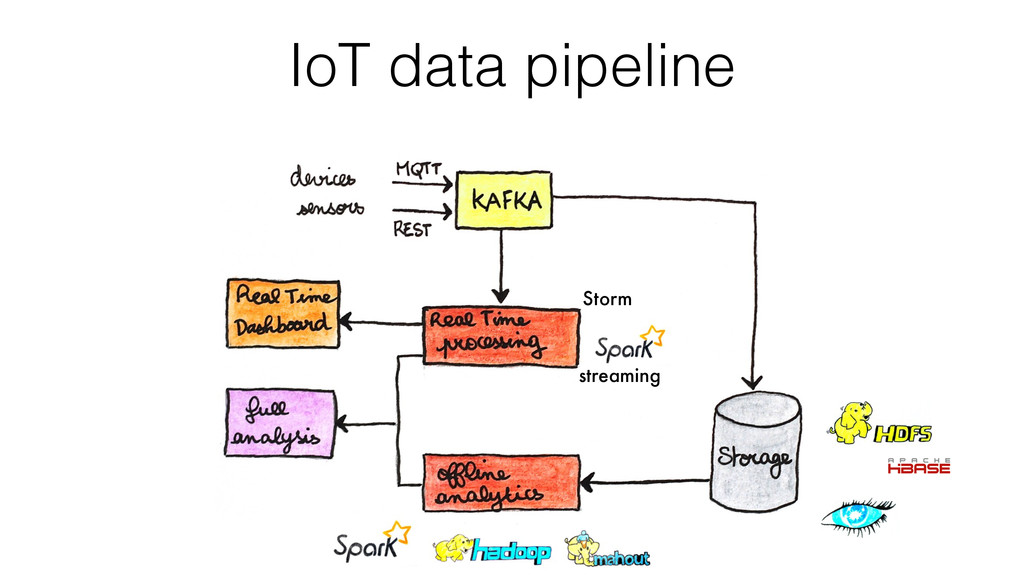
Following this we quickly see how to collect and store the data from connected devices.
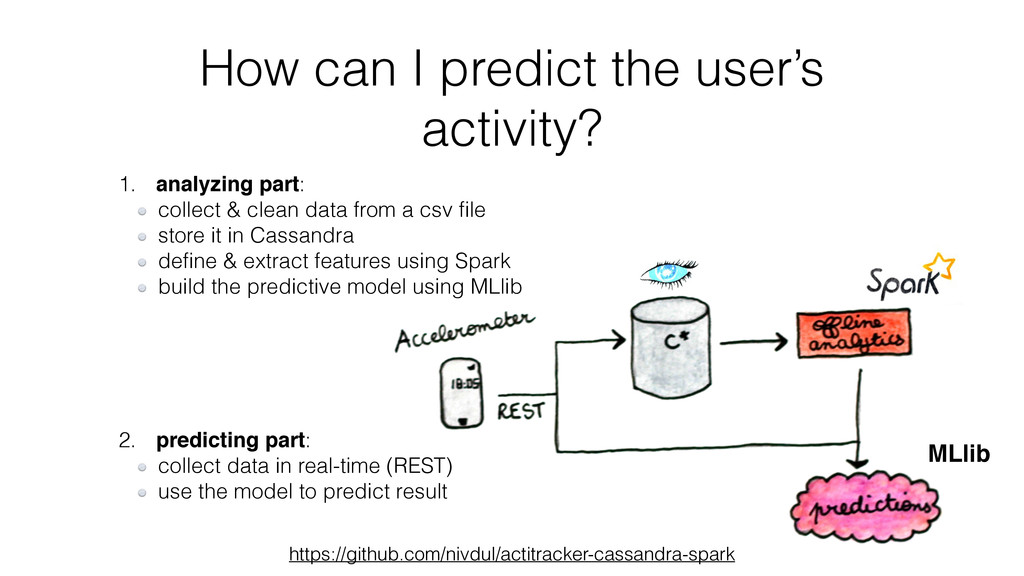
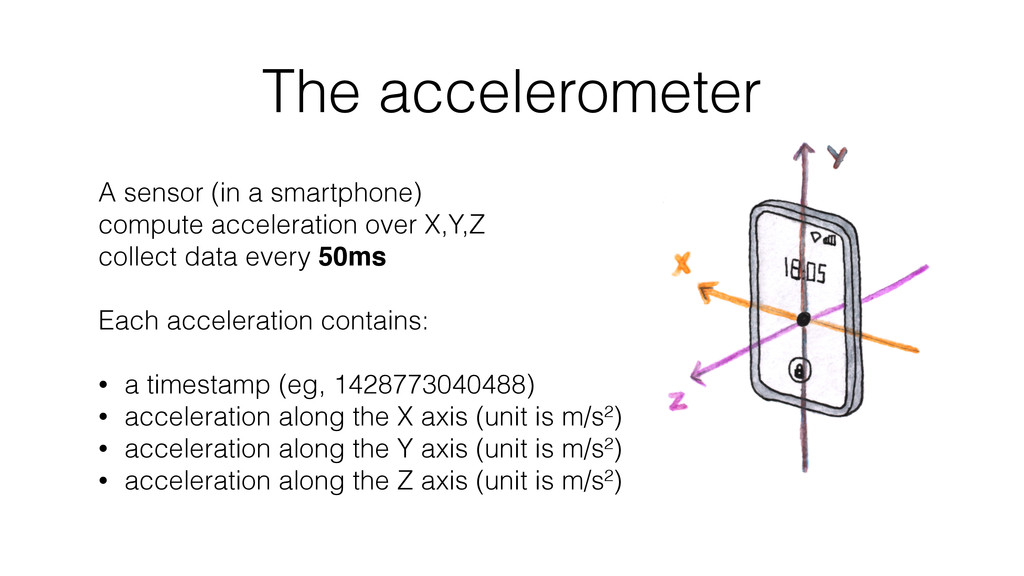
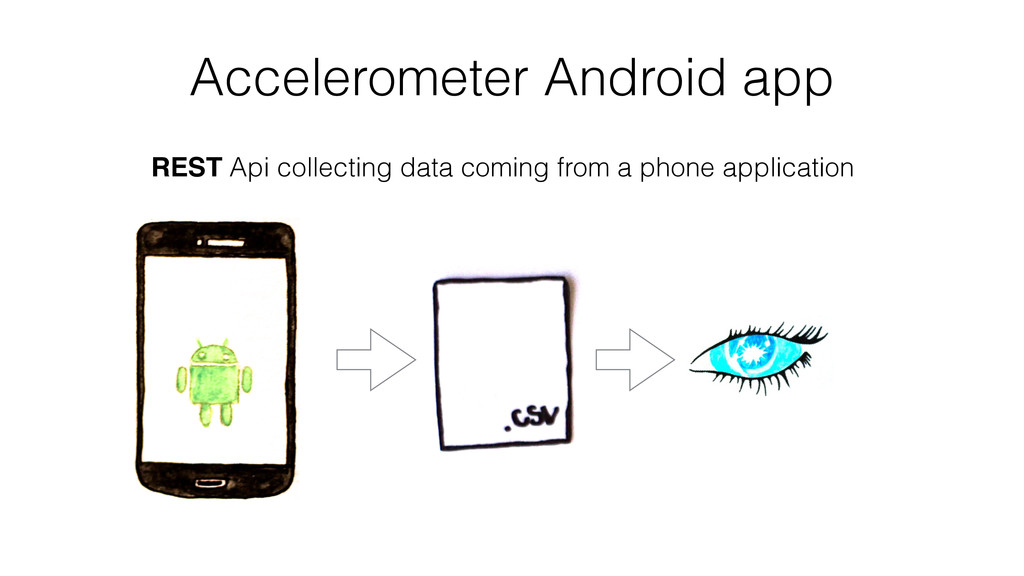
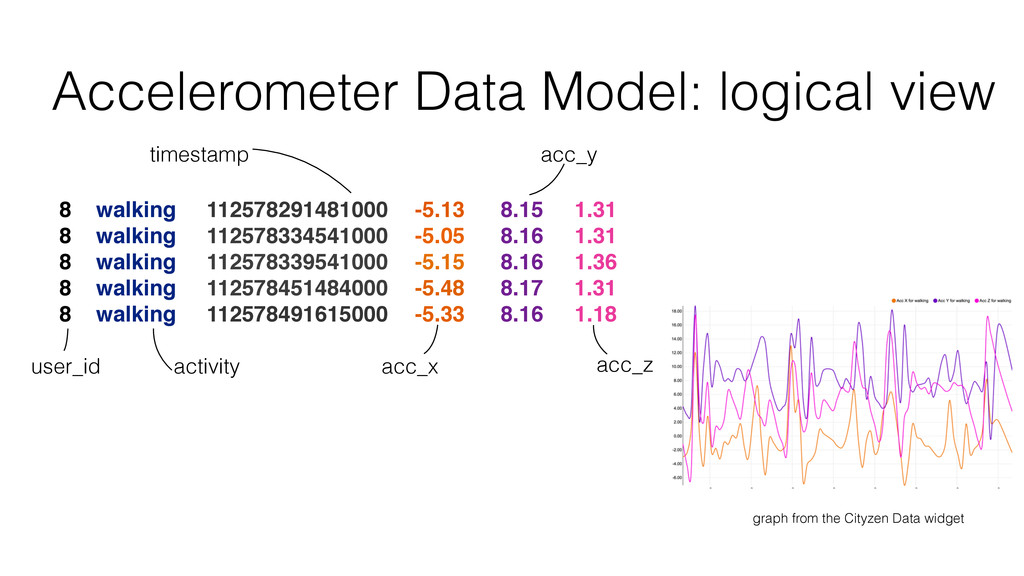
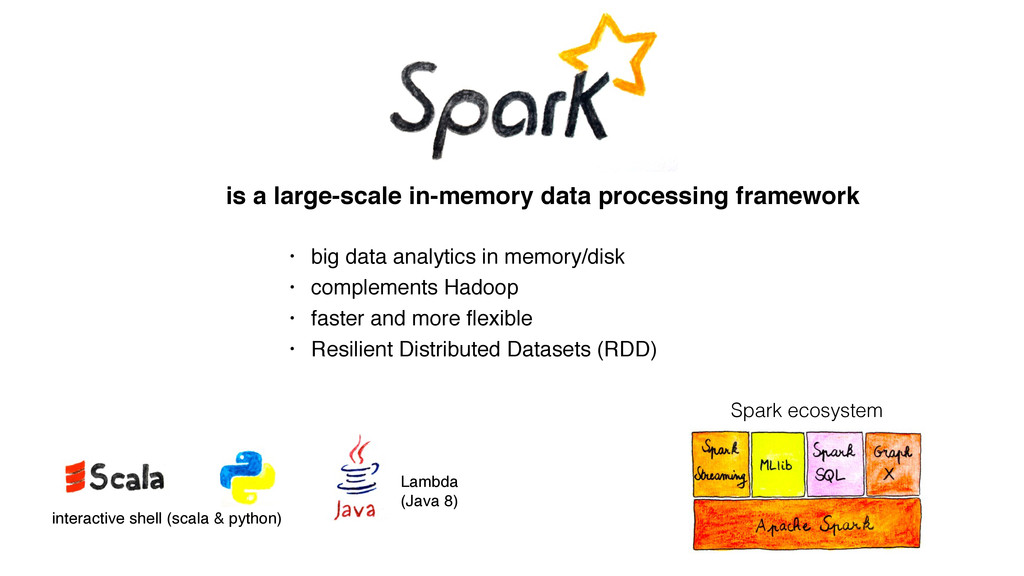
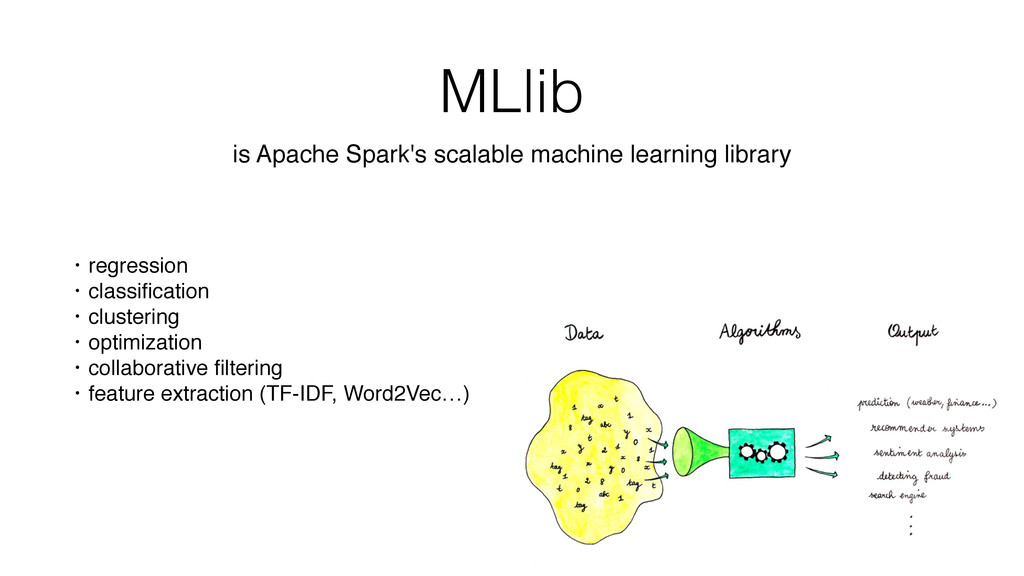
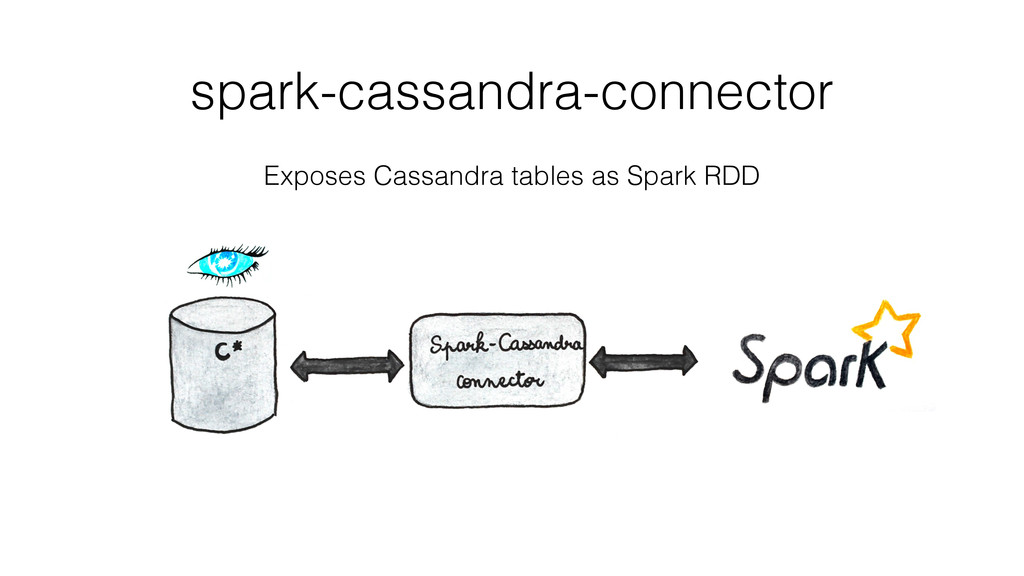
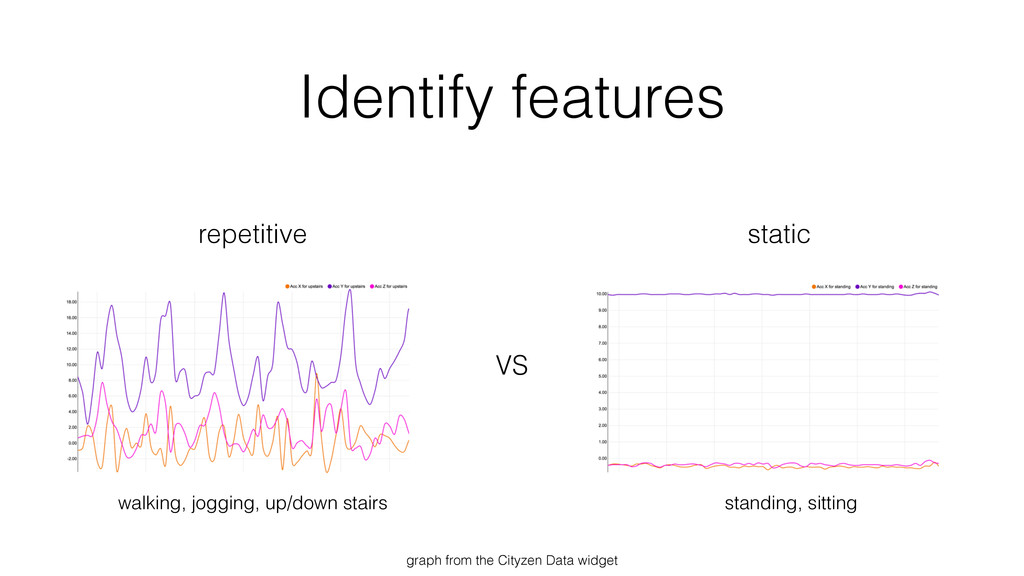
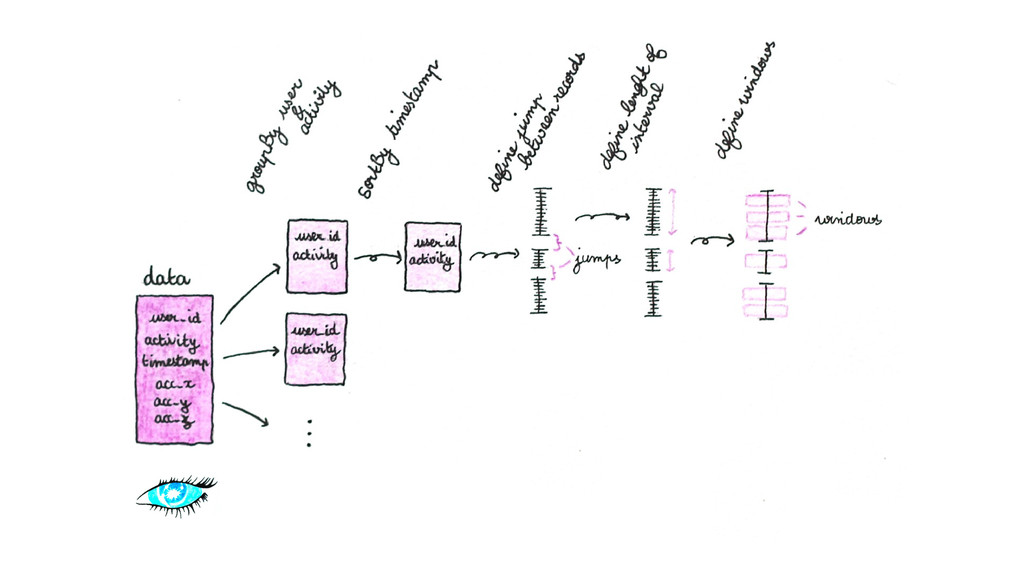
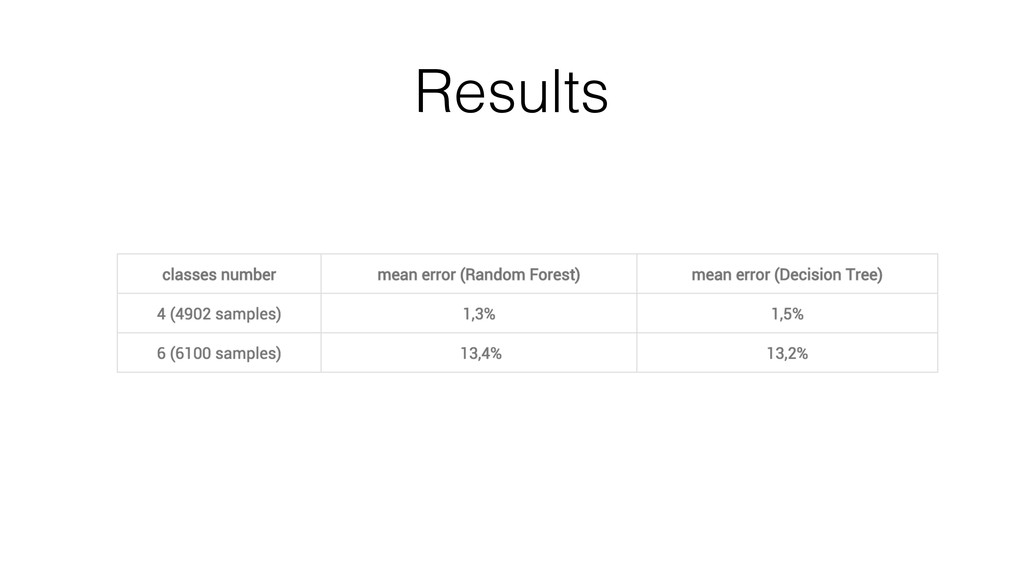
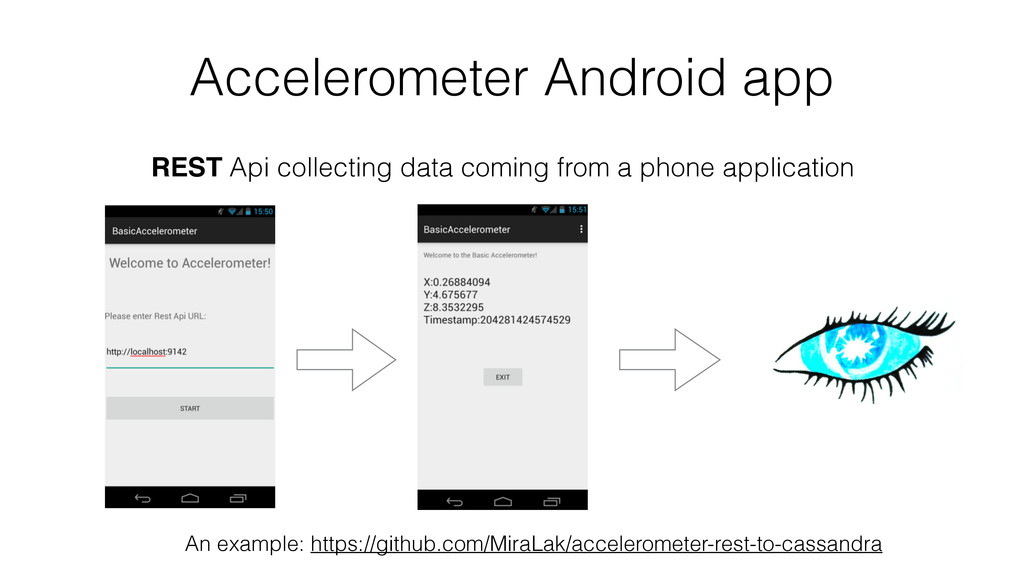
Finally, and this is the bigger part, thanks to a concrete example, I show how I have collected, stored and analyzed data from an accelerometer using Spark, Cassandra and MLlib.
This example is inspired of this study: WISDM Lab’s study.
And the code is available on my github account: https://github.com/nivdul/actitracker-cassandra-spark
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
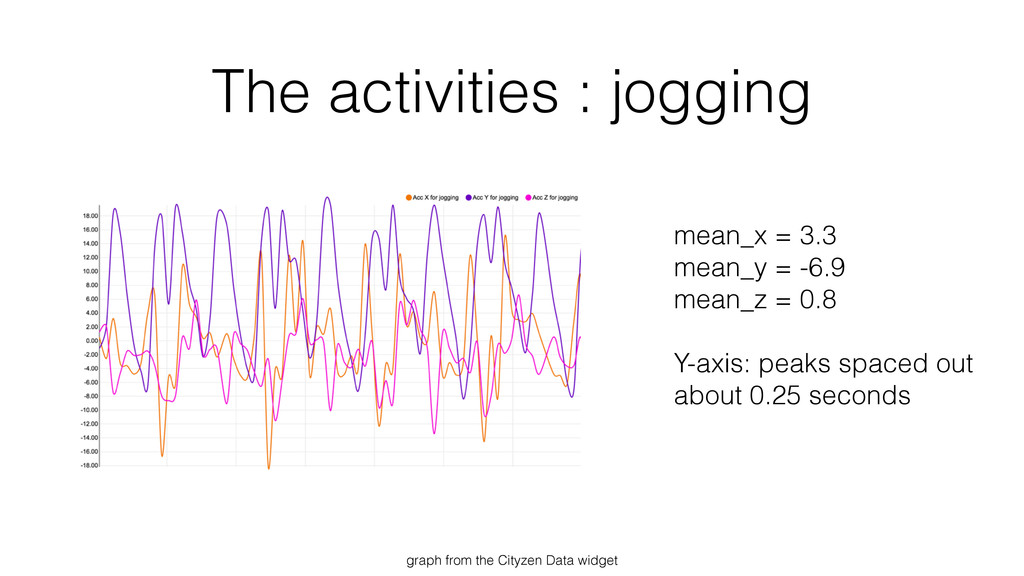{kind=link}
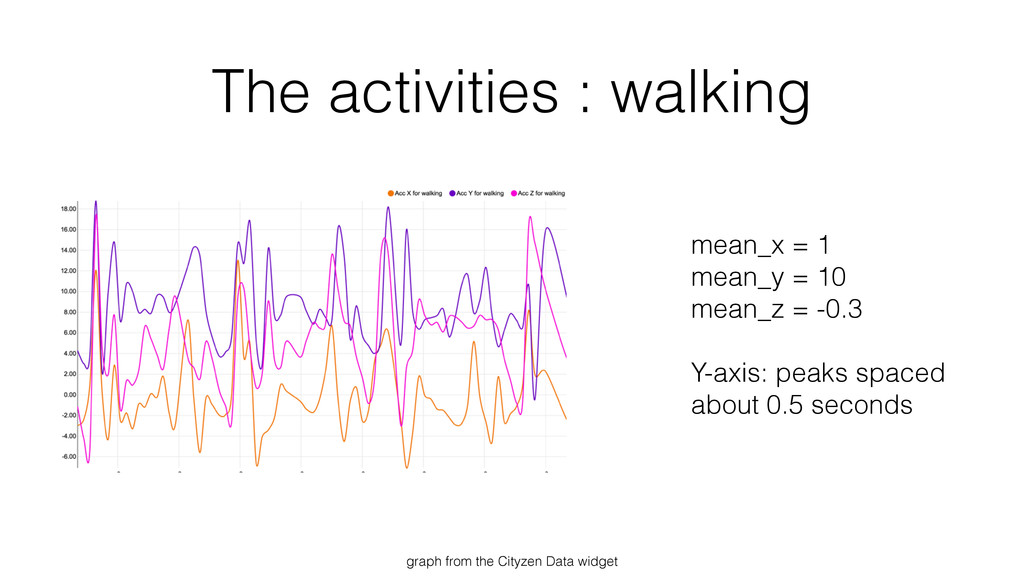{kind=link}
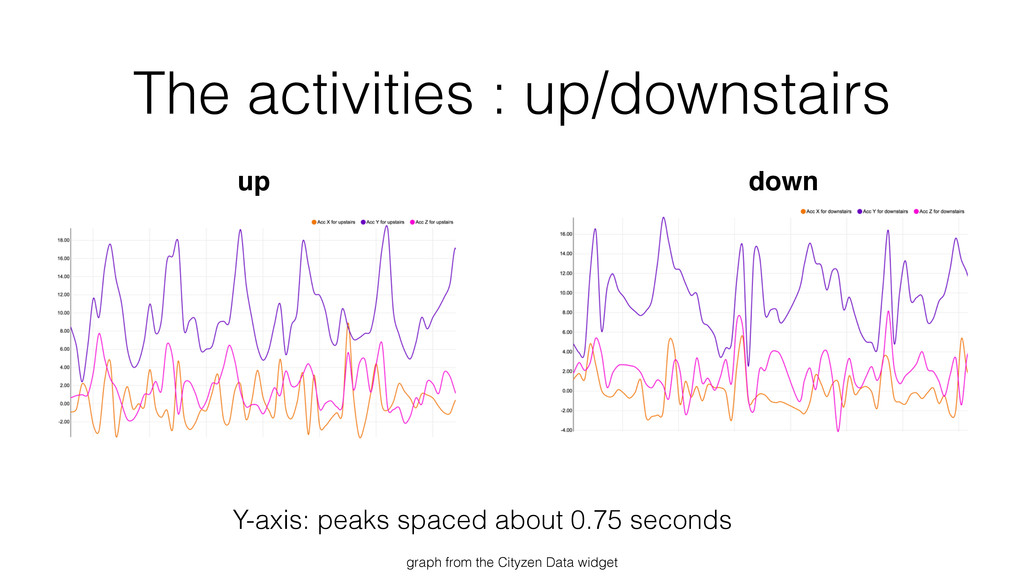{kind=link}
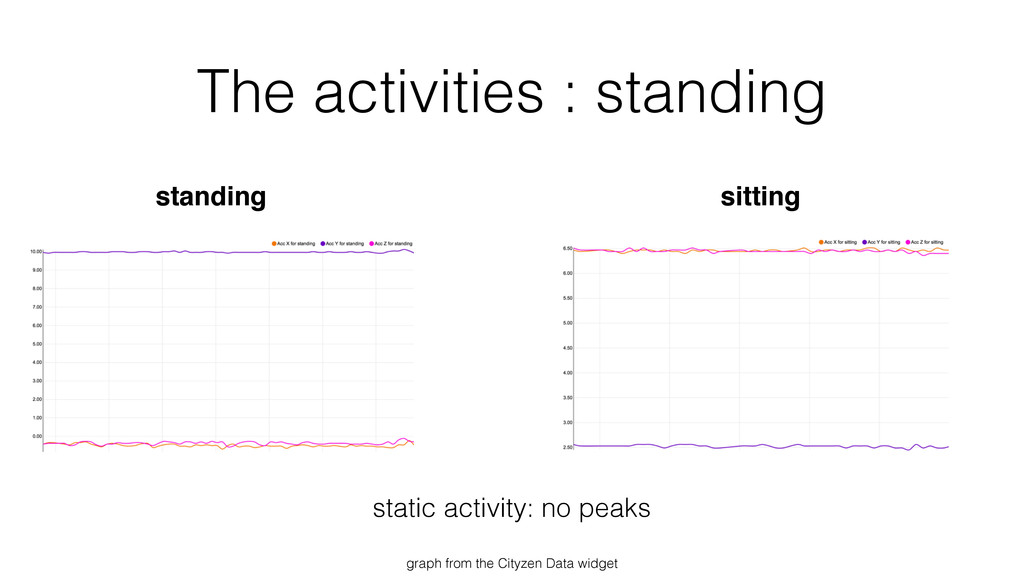{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}