Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Lightning-fast Machine Learning with Spark
Search
Probst Ludwine
November 11, 2014
Programming
1k
6
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Lightning-fast Machine Learning with Spark
Probst Ludwine
November 11, 2014
More Decks by Probst Ludwine
See All by Probst Ludwine
Tech Beyond Borders
nivdul
0
210
Tech Beyond Borders
nivdul
0
89
Analytics in the age of the Internet of Things
nivdul
1
220
Lightning-fast Machine Learning with Spark
nivdul
15
5.4k
Introduction to Spark
nivdul
4
650
Other Decks in Programming
See All in Programming
Developing with AI Agents — Codex, Claude Code & Cowork Practical Guide
x5gtrn
PRO
0
1.3k
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
5.5k
Hatena Engineer Seminar #37「言語モデルの活用に関する研究」
slashnephy
0
500
Performance Engineering for Everyone
elenatanasoiu
0
270
Language Server 使ってる? 〜VSCode と Zed の場合〜 / Are you using a Language Server? ~For VS Code and Zed~
handlename
0
840
Observability in Practice:Grafana 與 Edge Device SRE 的那些事
blueswen
0
190
自作OSでスライド発表する
uyuki234
1
3.7k
過去最大のMCPアップデート! 2026-07-28 RC版の謎に迫る
licux
6
460
その問い、本当に正しいですか?AI時代のエンジニアに必要な哲学と認知科学 / ai-philosophy-cognitive-science
minodriven
14
6.8k
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
140
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
0
180
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
190
Featured
See All Featured
Paper Plane
katiecoart
PRO
2
52k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Designing for Timeless Needs
cassininazir
1
290
The SEO identity crisis: Don't let AI make you average
varn
0
510
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
Claude Code のすすめ
schroneko
67
230k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Documentation Writing (for coders)
carmenintech
77
5.4k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Transcript
@nivdul #DV14 #MLwithSpark Lightning fast Machine Learning with Spark Ludwine
Probst
@nivdul #Devoxx #MLwithSpark me Data engineer at Leader of Duchess
France
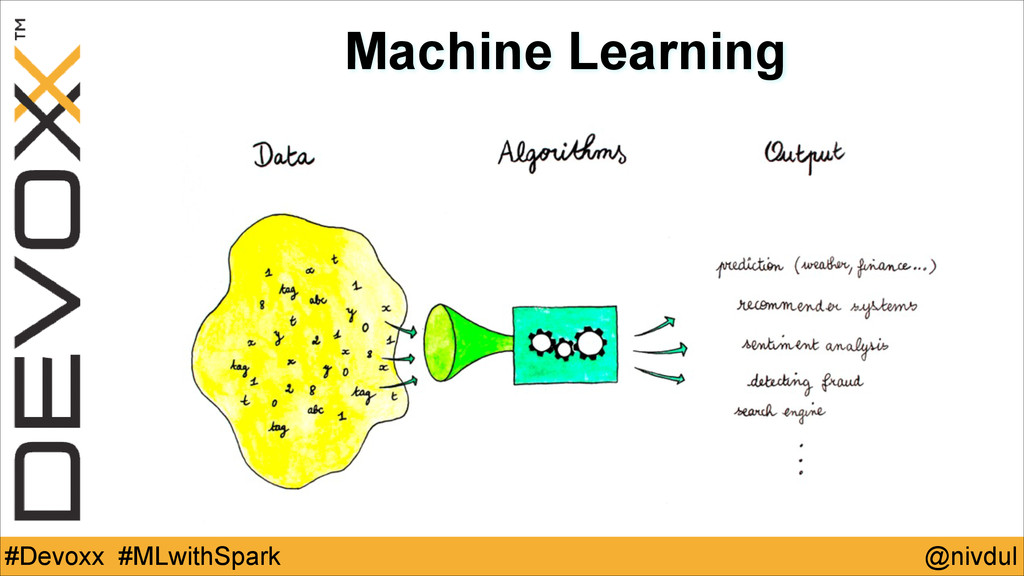
@nivdul #Devoxx #MLwithSpark Machine Learning
@nivdul #DV14 #MLwithSpark MapReduce Lay of the land
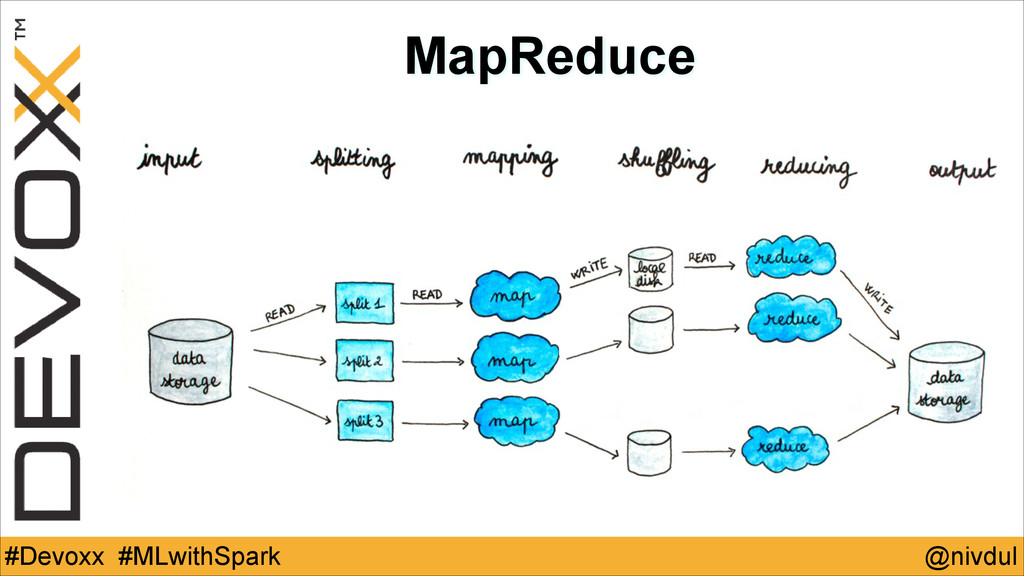
@nivdul #Devoxx #MLwithSpark MapReduce
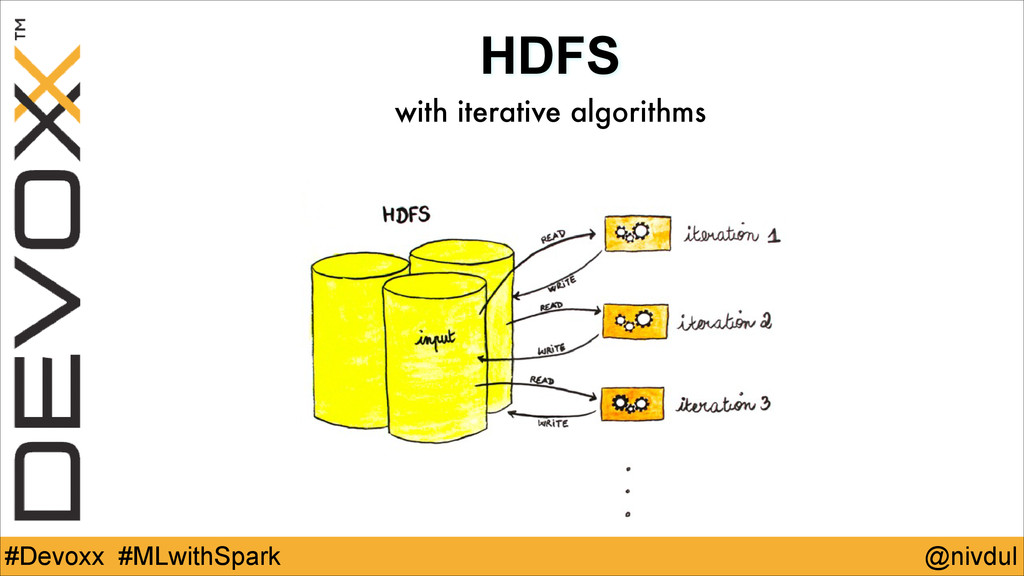
@nivdul #Devoxx #MLwithSpark HDFS with iterative algorithms
@nivdul #Devoxx #MLwithSpark
@nivdul #Devoxx #MLwithSpark is a fast and general engine for
large-scale data processing
@nivdul #DV14 #MLwithSpark •big data analytics in memory/disk •complements Hadoop
•fast and more flexible •Resilient Distributed Datasets (RDD) •shared variables
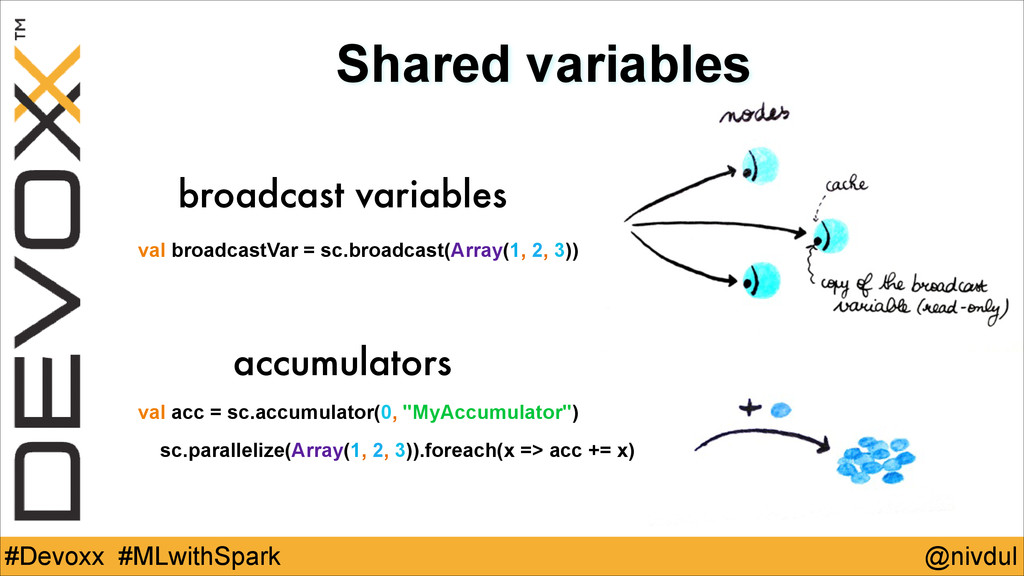
@nivdul #Devoxx #MLwithSpark Shared variables broadcast variables accumulators val broadcastVar
= sc.broadcast(Array(1, 2, 3)) val acc = sc.accumulator(0, "MyAccumulator") sc.parallelize(Array(1, 2, 3)).foreach(x => acc += x)
@nivdul #DV14 #MLwithSpark RDD (Resilient Distributed Datasets) •process in parallel
•controllable persistence (memory, disk…) •higher-level operations (transformation & actions) •rebuilt automatically using lineage
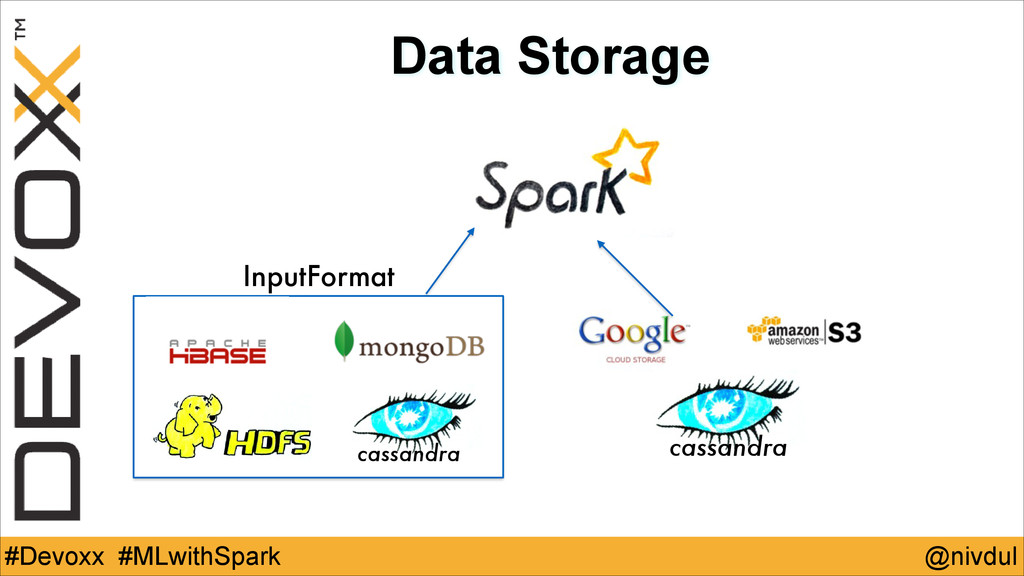
@nivdul #Devoxx #MLwithSpark Data Storage InputFormat cassandra cassandra
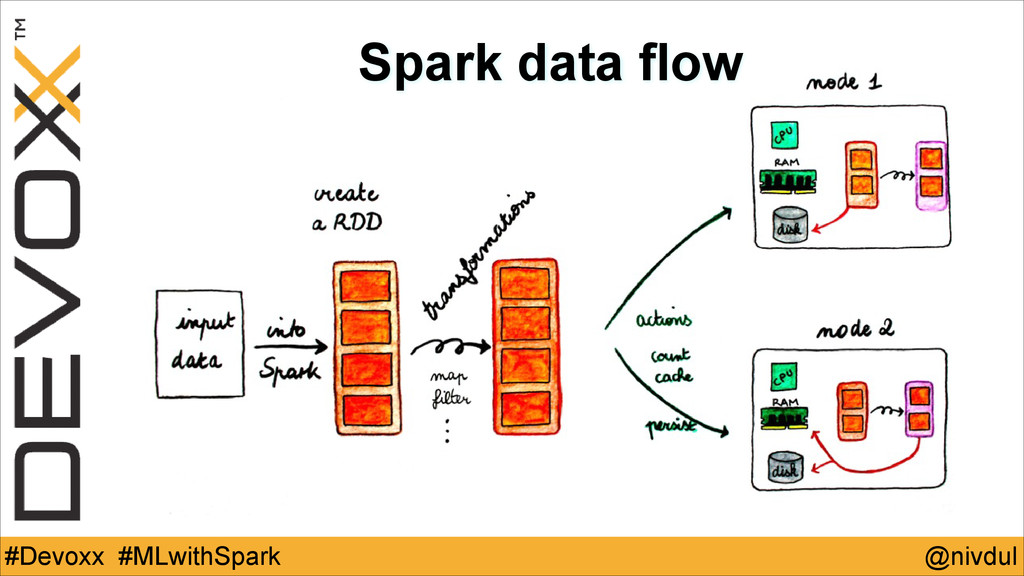
@nivdul #Devoxx #MLwithSpark Spark data flow
@nivdul #Devoxx #MLwithSpark Languages interactive shell (scala & python) Lambda
(Java 8)
@nivdul #Devoxx #MLwithSpark val conf = new SparkConf() .setAppName("Spark word
count") .setMaster("local") ! val sc = new SparkContext(conf) WordCount example (scala)
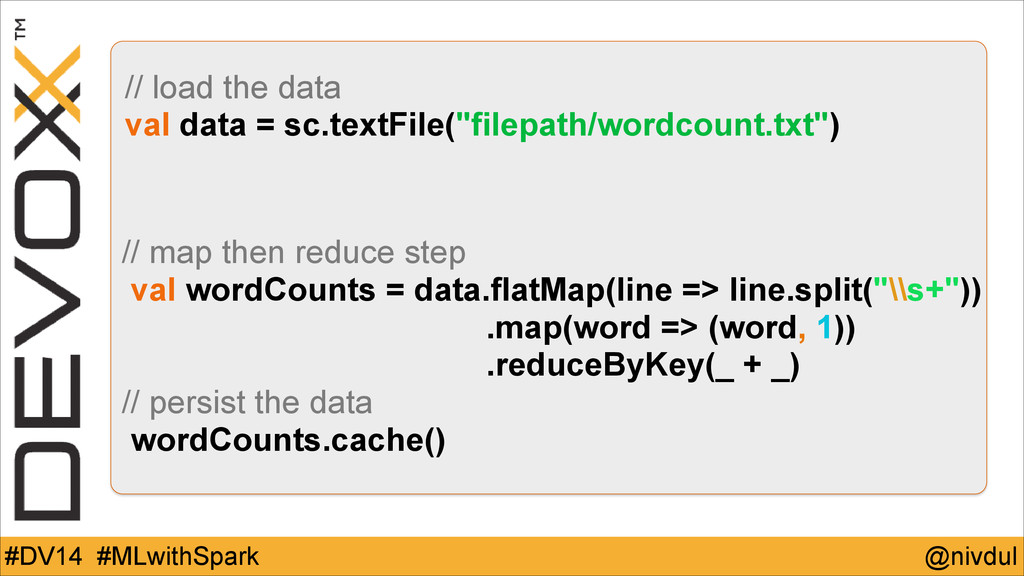
@nivdul #DV14 #MLwithSpark // load the data val data =
sc.textFile("filepath/wordcount.txt") // map then reduce step val wordCounts = data.flatMap(line => line.split("\\s+")) .map(word => (word, 1)) .reduceByKey(_ + _) // persist the data wordCounts.cache()
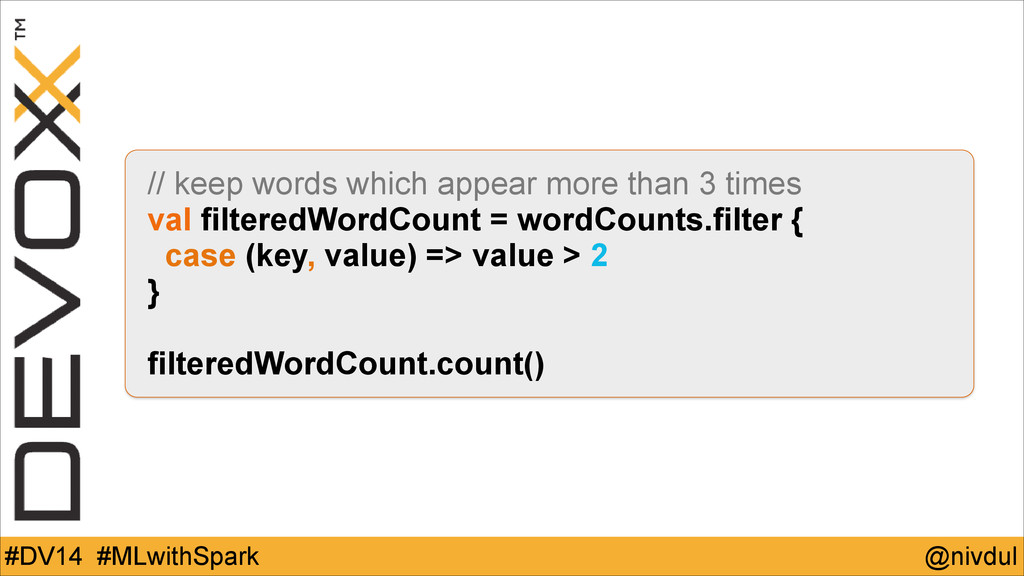
@nivdul #DV14 #MLwithSpark // keep words which appear more than
3 times val filteredWordCount = wordCounts.filter { case (key, value) => value > 2 } ! filteredWordCount.count()
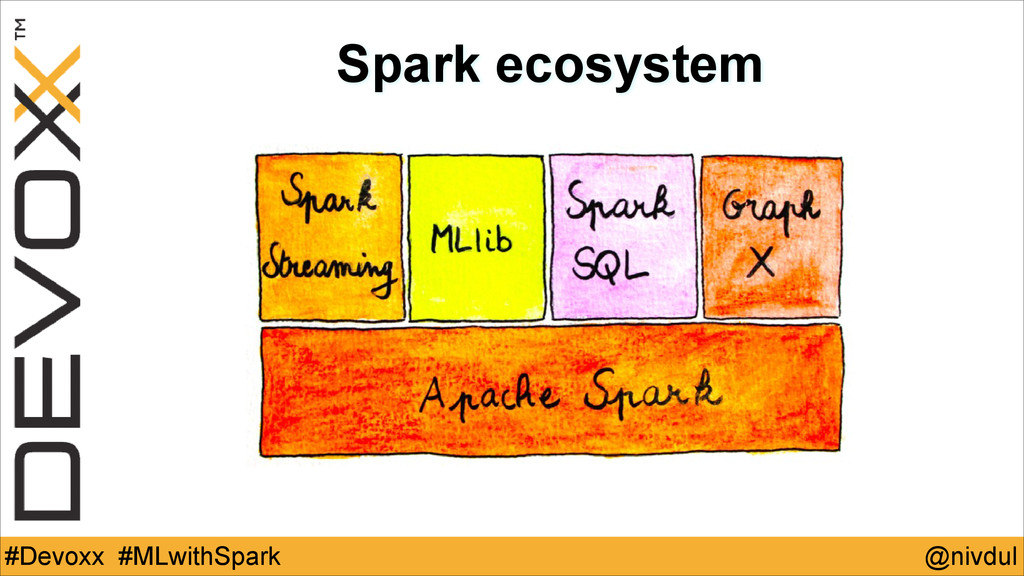
@nivdul #Devoxx #MLwithSpark Spark ecosystem
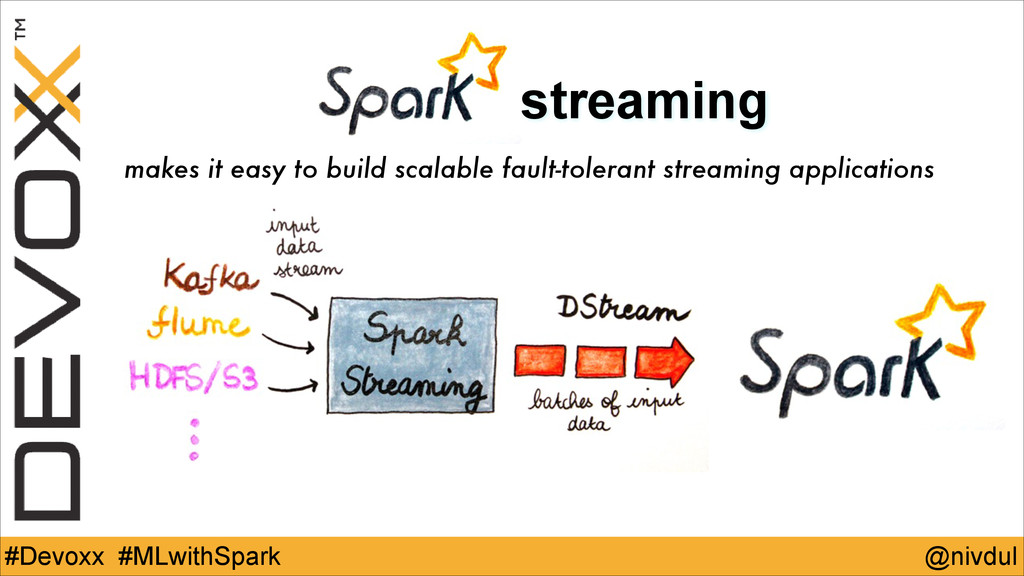
@nivdul #Devoxx #MLwithSpark streaming makes it easy to build scalable
fault-tolerant streaming applications
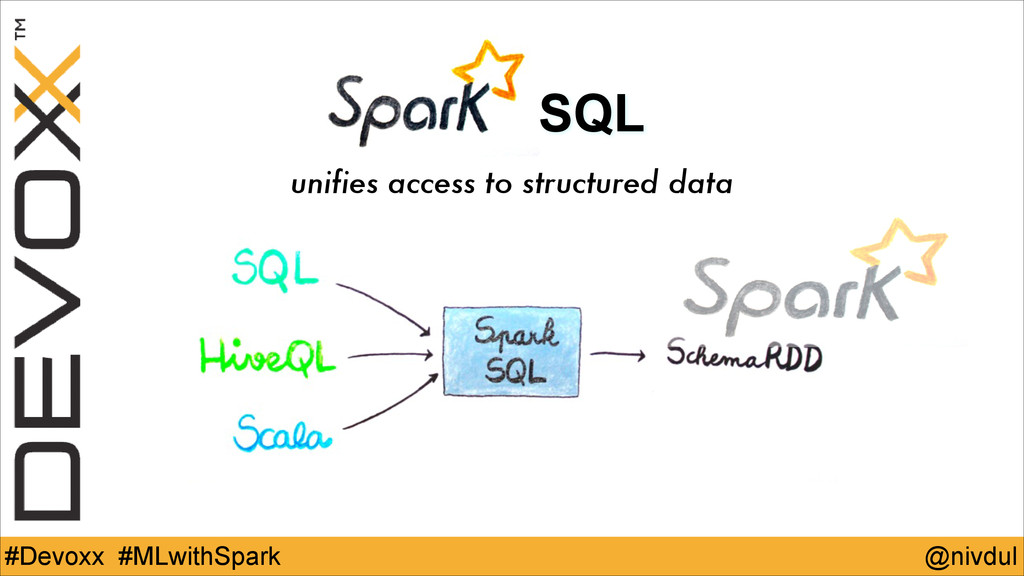
@nivdul #Devoxx #MLwithSpark SQL unifies access to structured data
@nivdul #Devoxx #MLwithSpark is Apache Spark's API for graphs and
graph-parallel computation
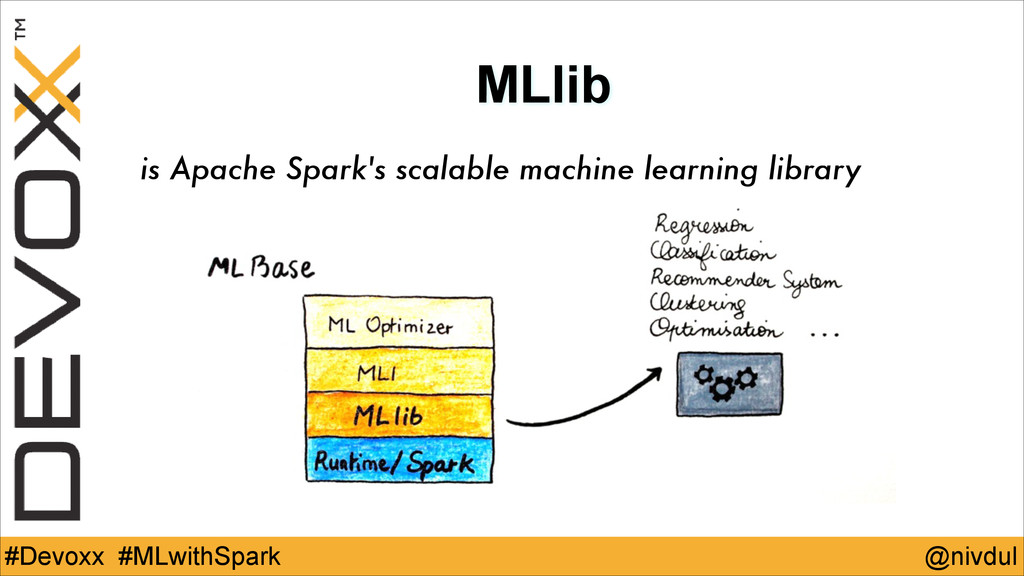
@nivdul #Devoxx #MLwithSpark MLlib is Apache Spark's scalable machine learning
library
@nivdul #Devoxx #MLwithSpark Machine learning with Spark / MLlib
@nivdul #Devoxx #MLwithSpark Machine learning libraries scikit
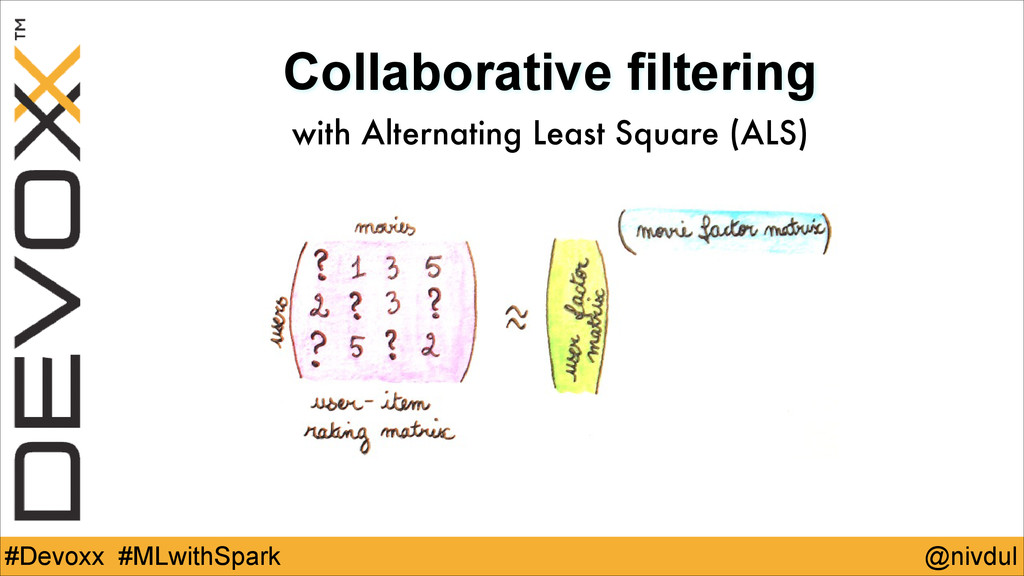
@nivdul #Devoxx #MLwithSpark Example make a movies recommender system
@nivdul #Devoxx #MLwithSpark Collaborative filtering with Alternating Least Square (ALS)
@nivdul #DV14 #MLwithSpark 1 3 5 1 28 4 2
18 3 2 5 5 userID movieID rating
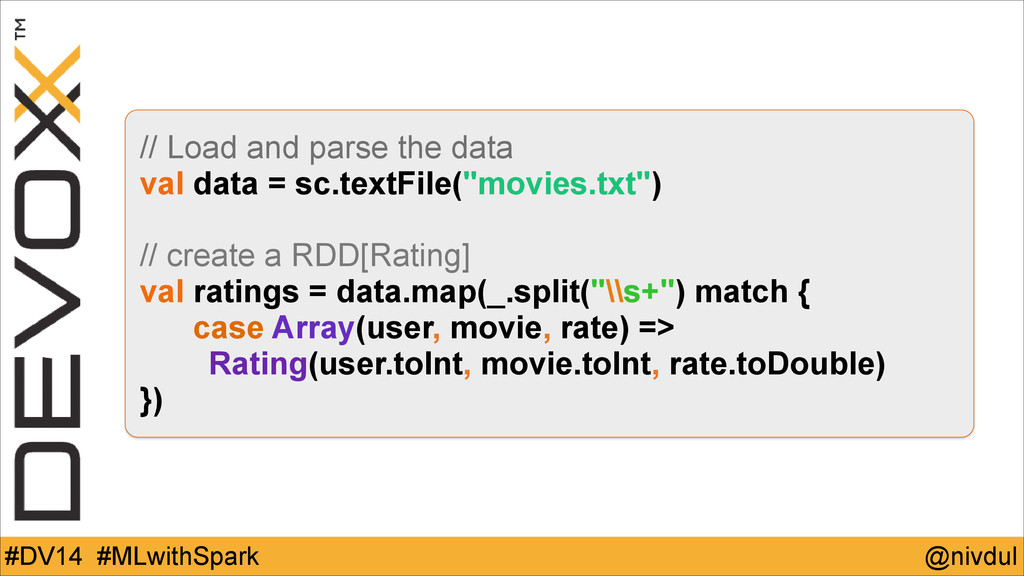
@nivdul #DV14 #MLwithSpark // Load and parse the data val
data = sc.textFile("movies.txt") ! // create a RDD[Rating] val ratings = data.map(_.split("\\s+") match { case Array(user, movie, rate) => Rating(user.toInt, movie.toInt, rate.toDouble) })
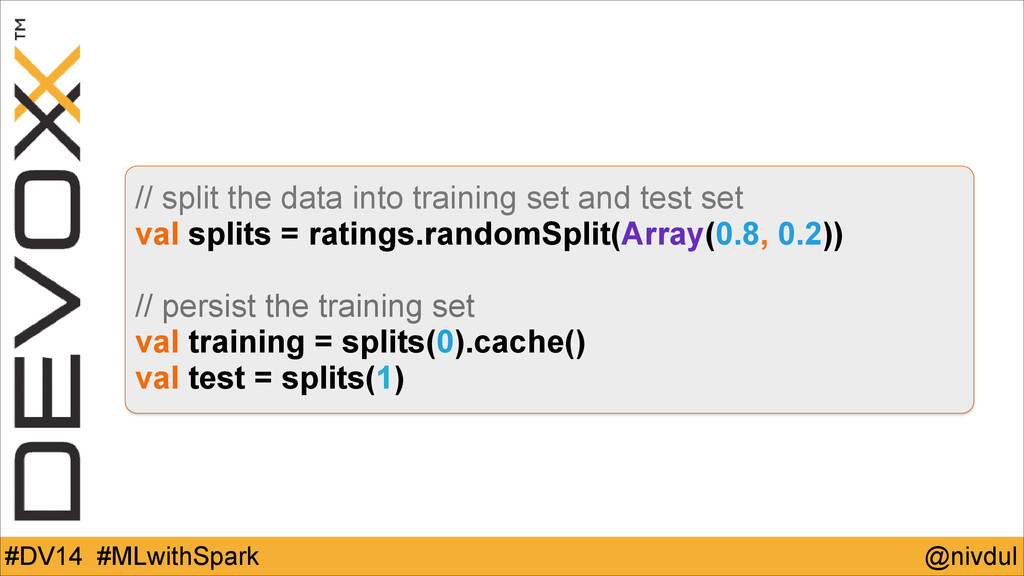
@nivdul #DV14 #MLwithSpark // split the data into training set
and test set val splits = ratings.randomSplit(Array(0.8, 0.2)) ! // persist the training set val training = splits(0).cache() val test = splits(1)
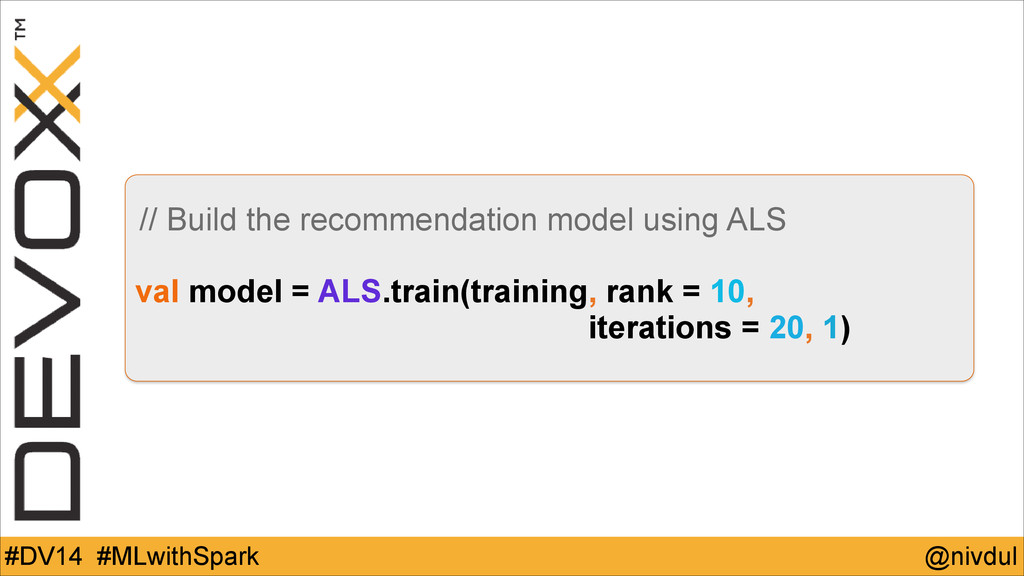
@nivdul #DV14 #MLwithSpark // Build the recommendation model using ALS
! val model = ALS.train(training, rank = 10, iterations = 20, 1)
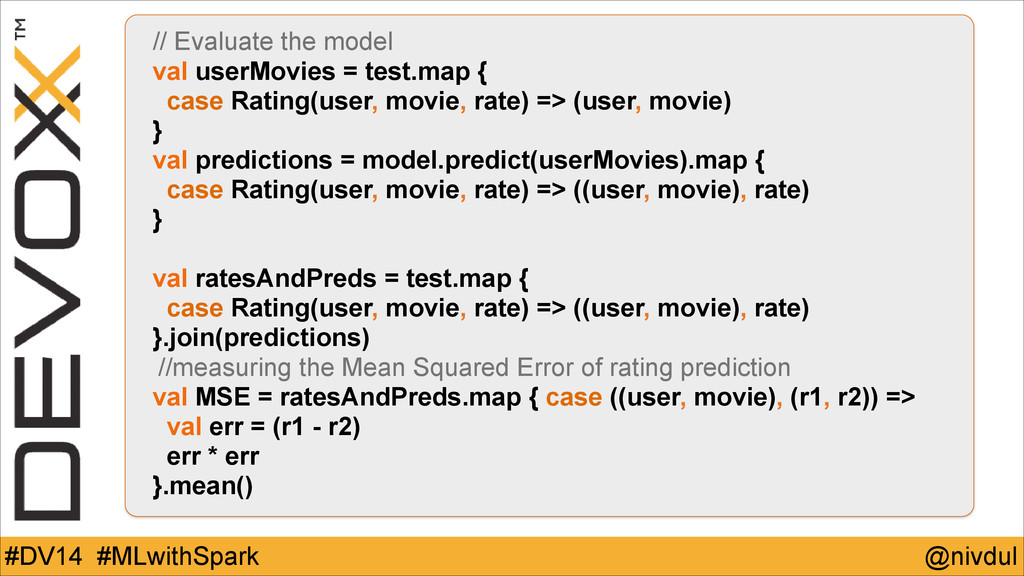
@nivdul #DV14 #MLwithSpark // Evaluate the model val userMovies =
test.map { case Rating(user, movie, rate) => (user, movie) } val predictions = model.predict(userMovies).map { case Rating(user, movie, rate) => ((user, movie), rate) } ! val ratesAndPreds = test.map { case Rating(user, movie, rate) => ((user, movie), rate) }.join(predictions) //measuring the Mean Squared Error of rating prediction val MSE = ratesAndPreds.map { case ((user, movie), (r1, r2)) => val err = (r1 - r2) err * err }.mean()
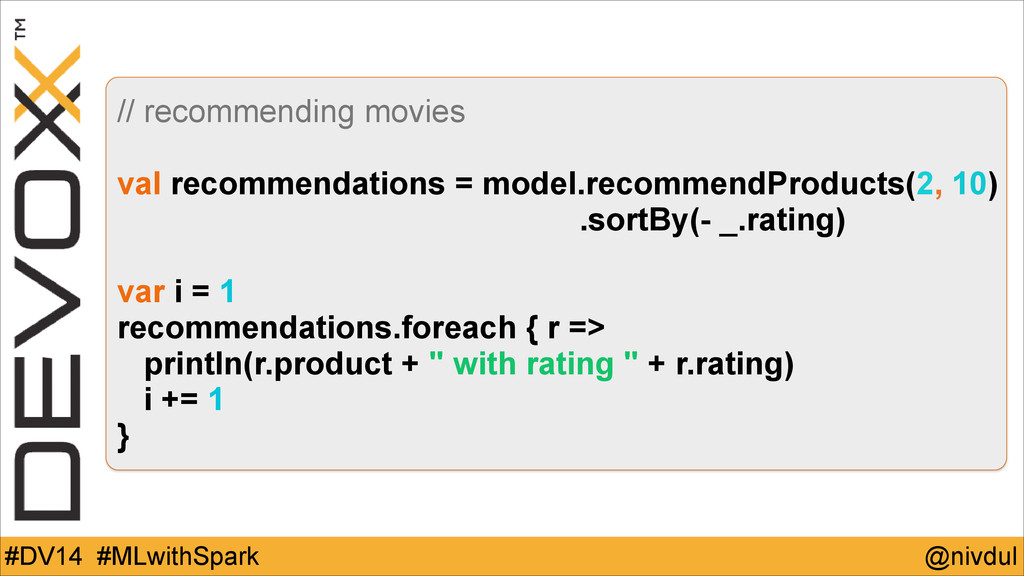
@nivdul #DV14 #MLwithSpark // recommending movies ! val recommendations =
model.recommendProducts(2, 10) .sortBy(- _.rating) ! var i = 1 recommendations.foreach { r => println(r.product + " with rating " + r.rating) i += 1 }
@nivdul #Devoxx #MLwithSpark Performance Spark core Hadoop MapReduce http://databricks.com/blog/2014/10/10/spark-breaks-previous-large-scale-sort-record.html How
fast a system can sort 100 TB of data on disk ?
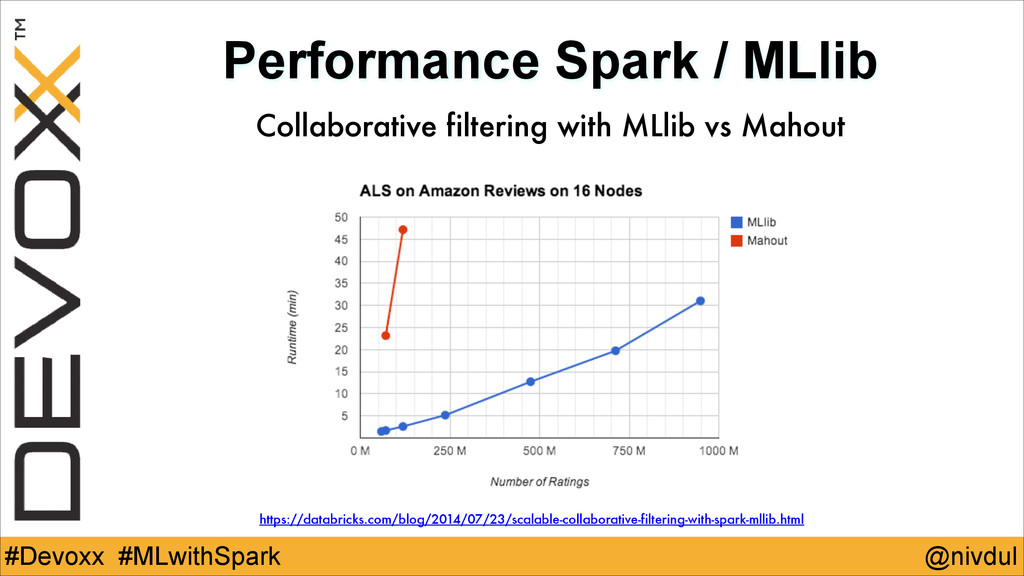
@nivdul #Devoxx #MLwithSpark Performance Spark / MLlib Collaborative filtering with
MLlib vs Mahout https://databricks.com/blog/2014/07/23/scalable-collaborative-filtering-with-spark-mllib.html
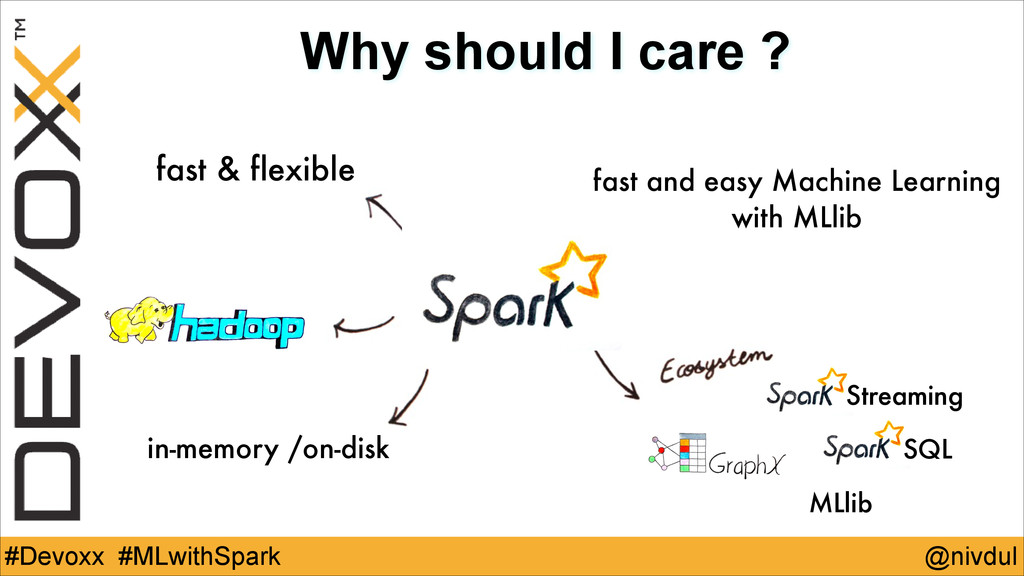
@nivdul #Devoxx #MLwithSpark Why should I care ? fast and
easy Machine Learning with MLlib fast & flexible in-memory /on-disk SQL Streaming MLlib
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
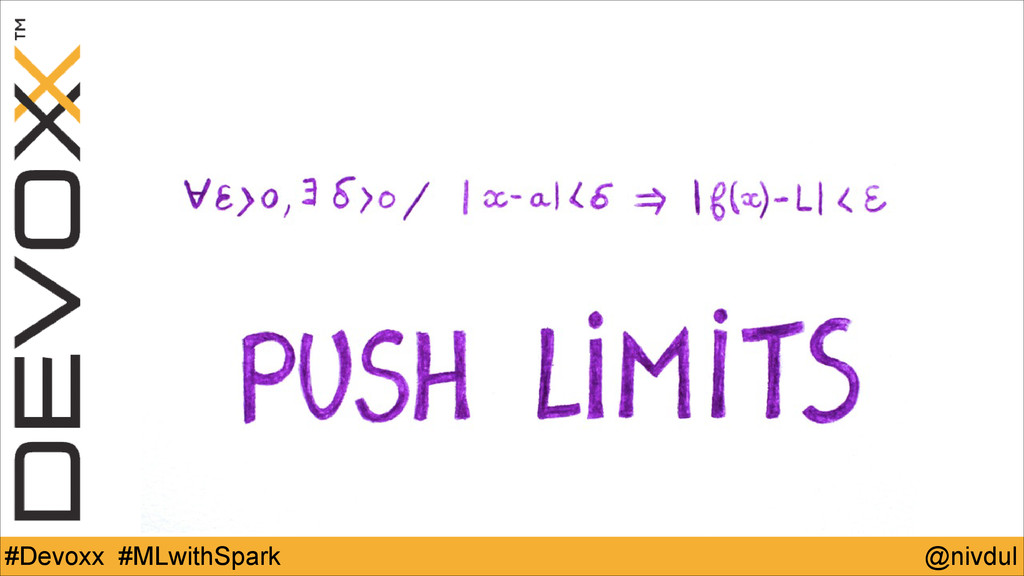{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}