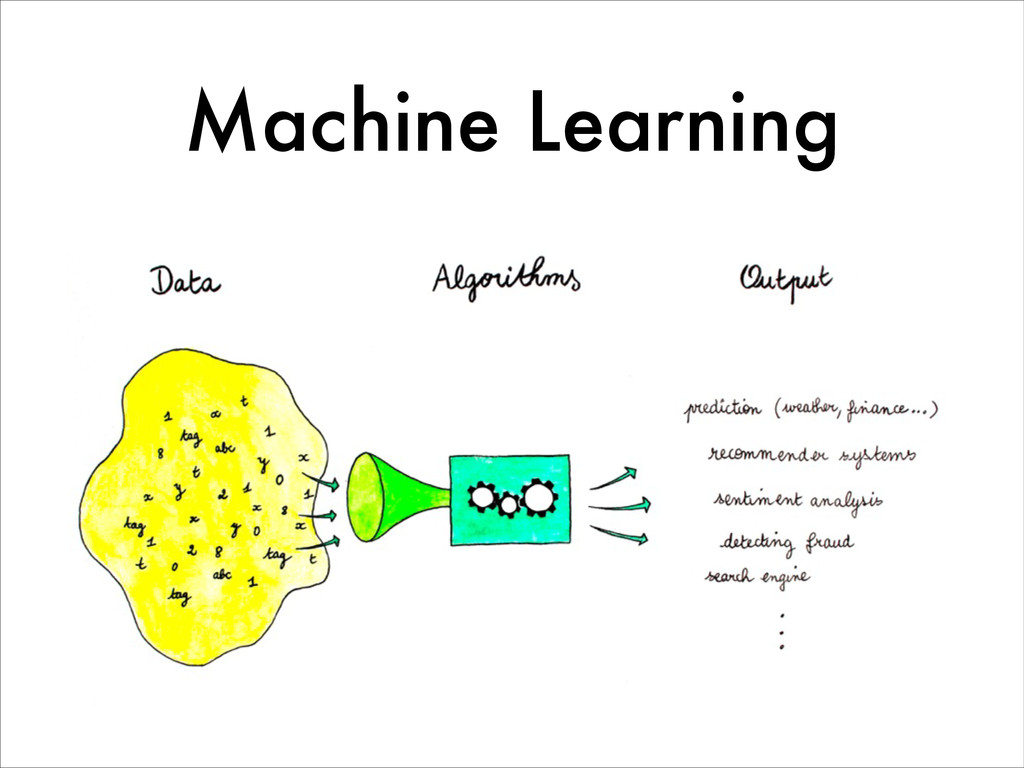
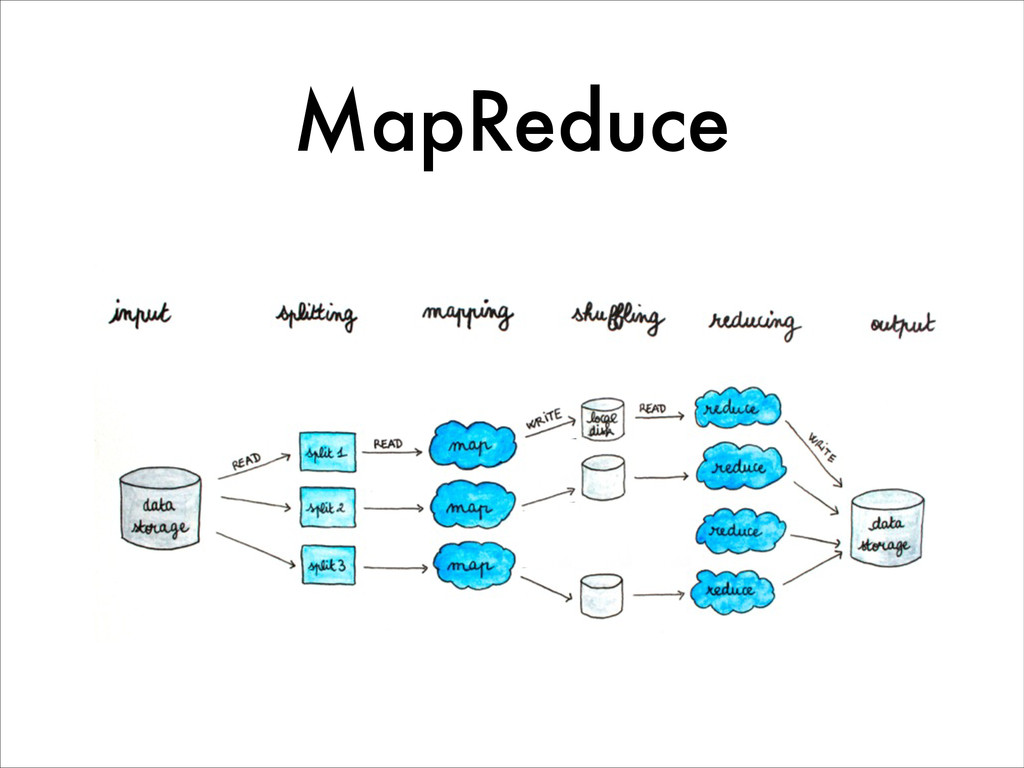
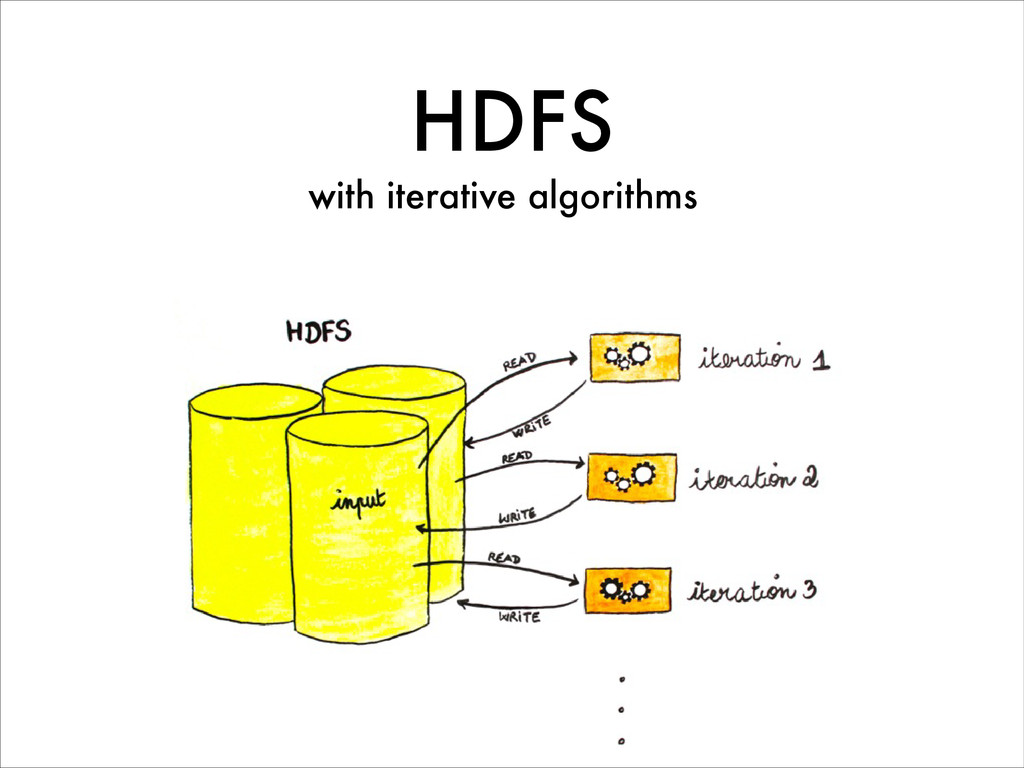
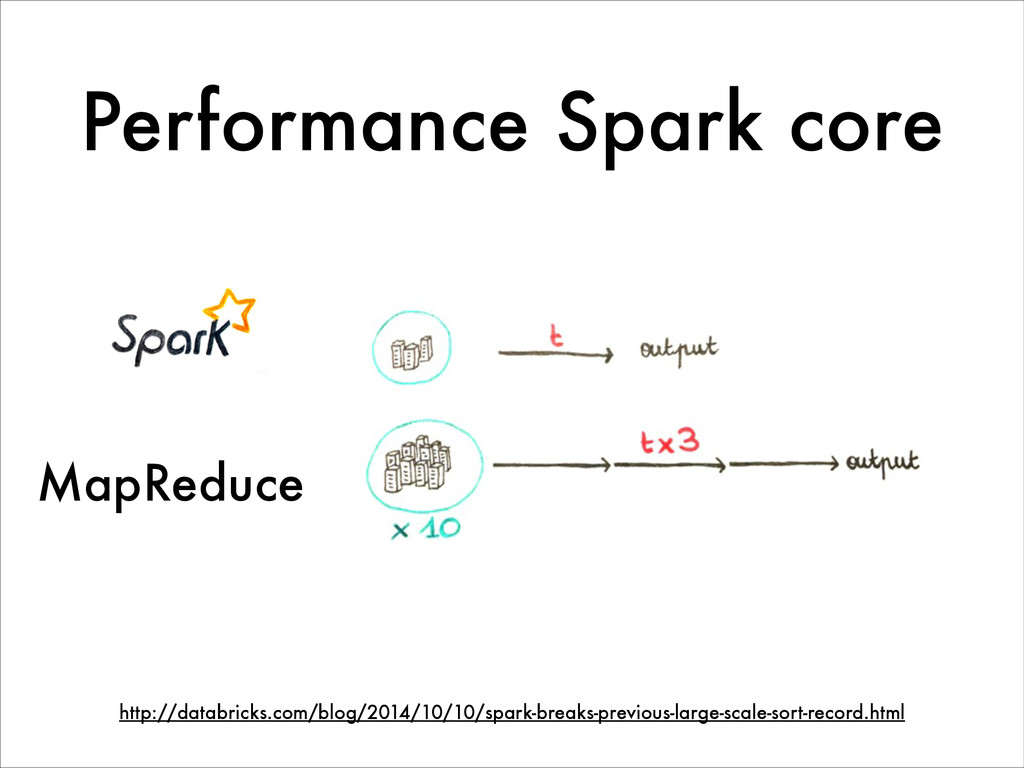
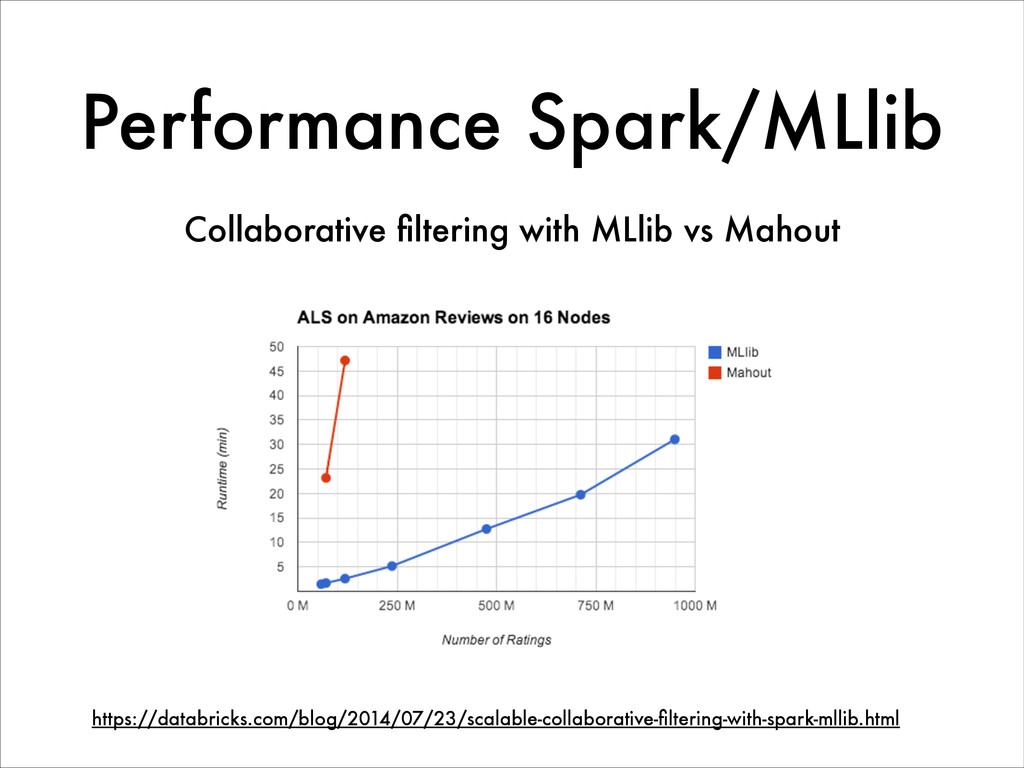
Today in the Big Data world, Hadoop and MapReduce are highly dominant for large scale data processing. However, the MapReduce model shows its limits for various types of treatment, especially for highly iterative algorithms like in Machine Learning. Spark is an in-memory data processing framework that, unlike Hadoop provides interactive and real-time analysis on large datasets. Furthermore Spark has a more flexible programming model and gives better performances than Hadoop.
This talk aims at introducing Spark and MLlib by showing off through a Machine Learning example how it differentiates itself from Hadoop, in regards to its API and performances. And as a closing note we will quickly explore the growing Spark ecosystem with projects like Spark streaming, MLlib, GraphX or Spark SQL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
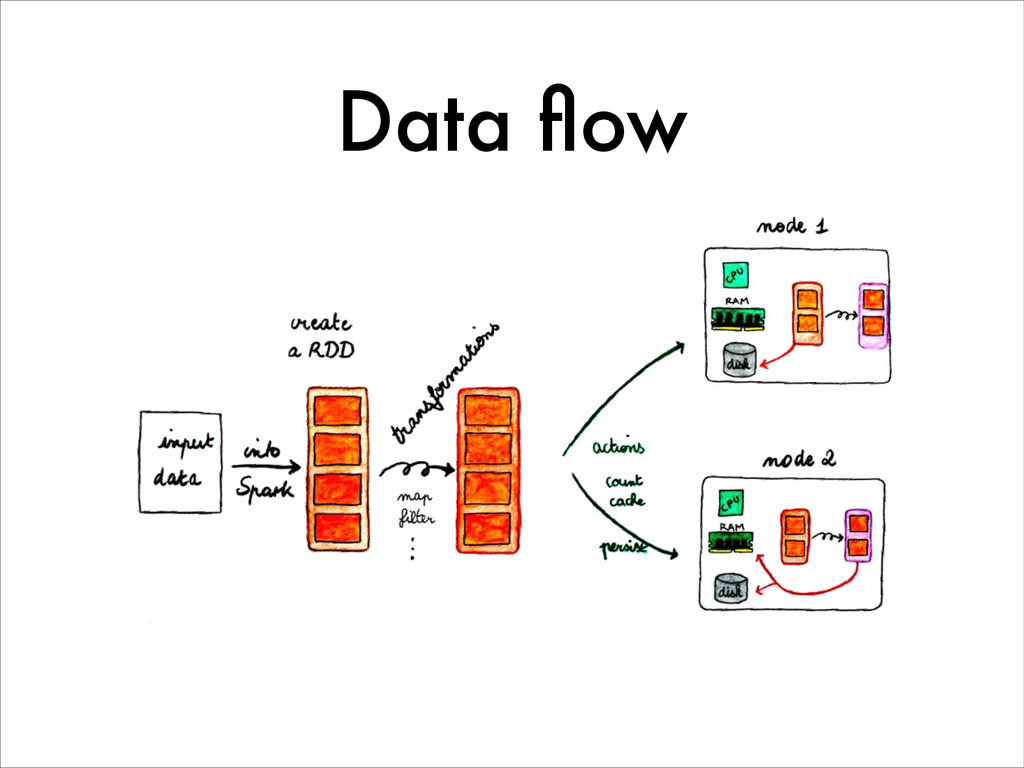{kind=link}
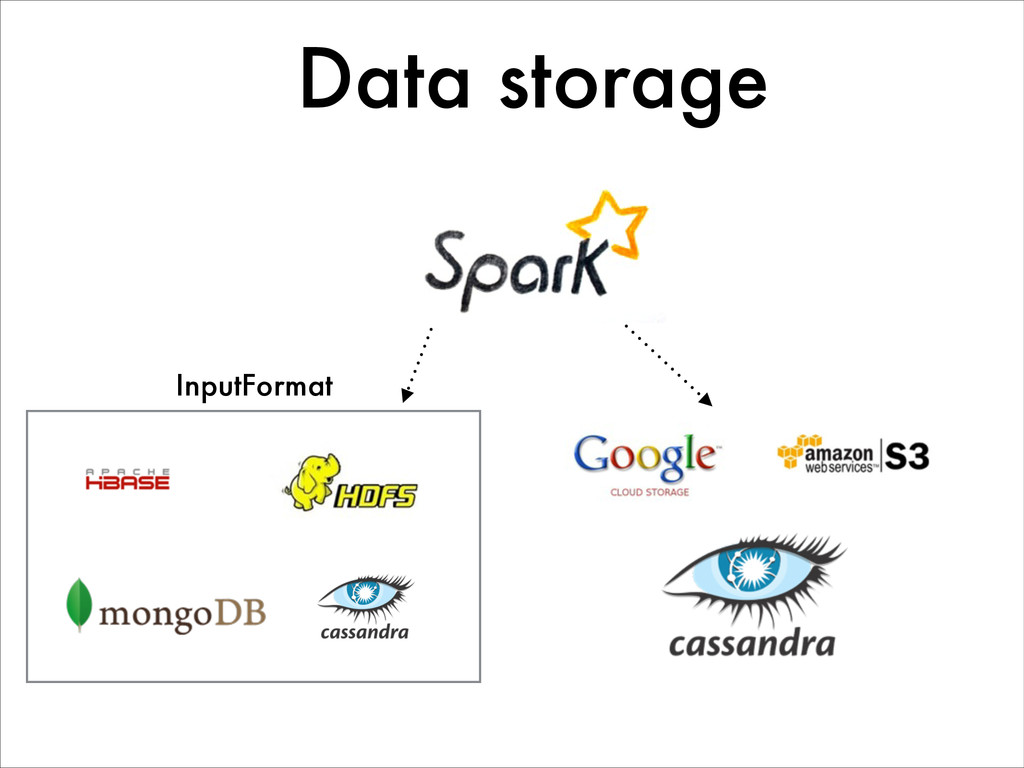{kind=link}
{kind=link}
{kind=link}
{kind=link}
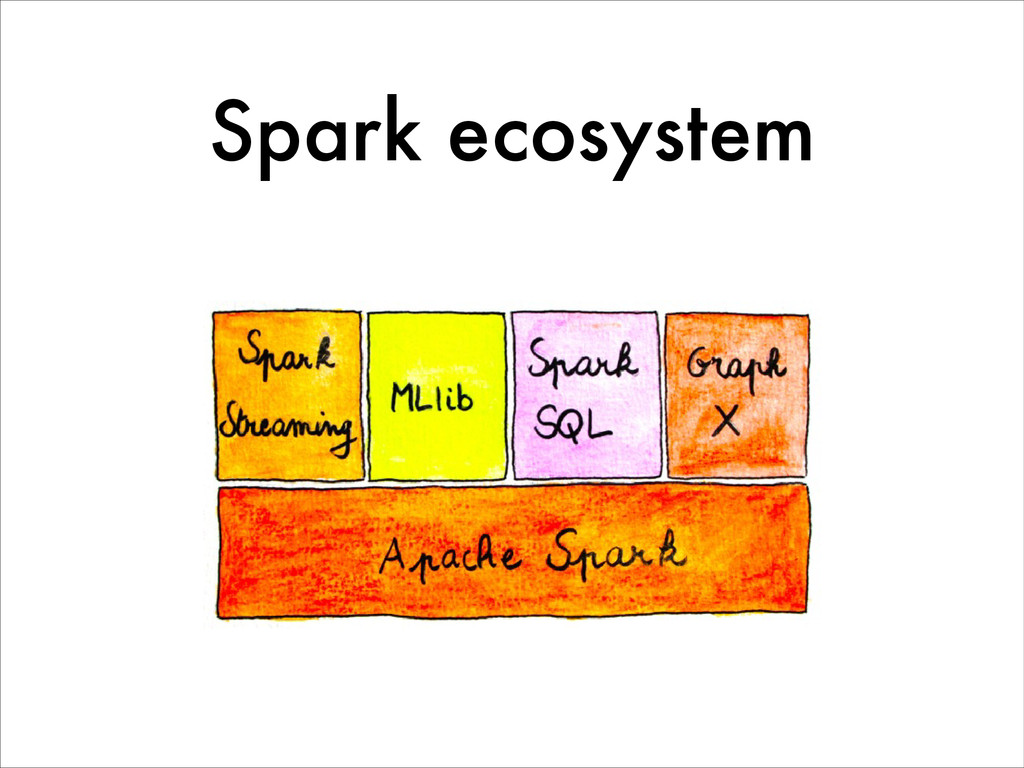{kind=link}
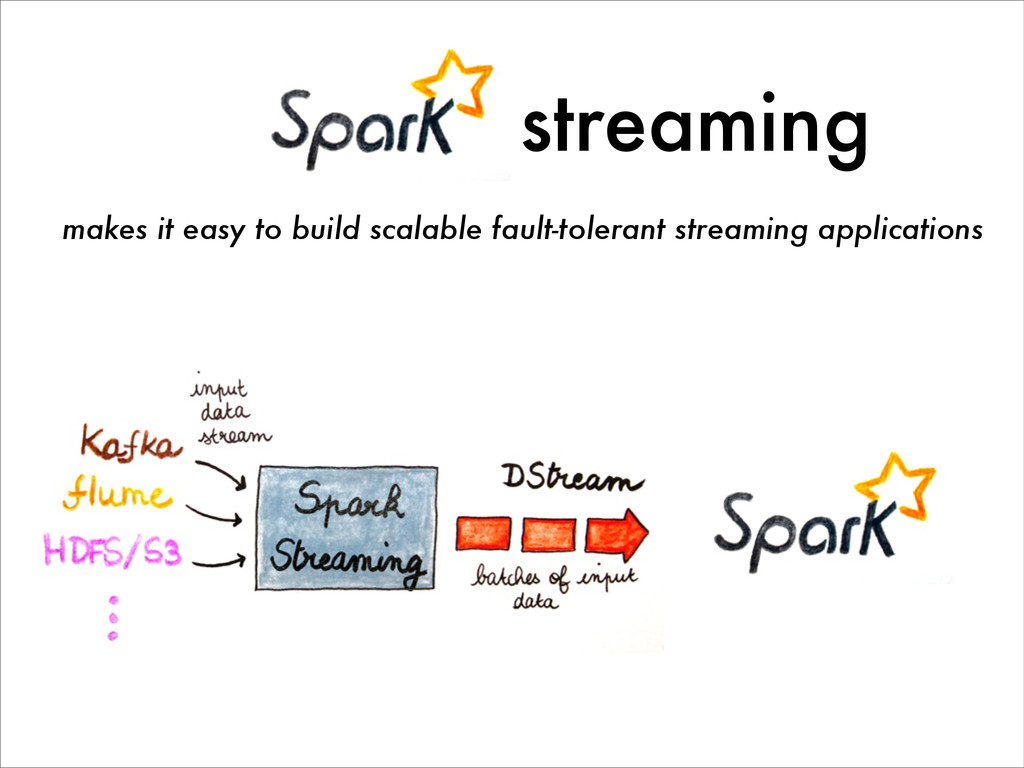{kind=link}
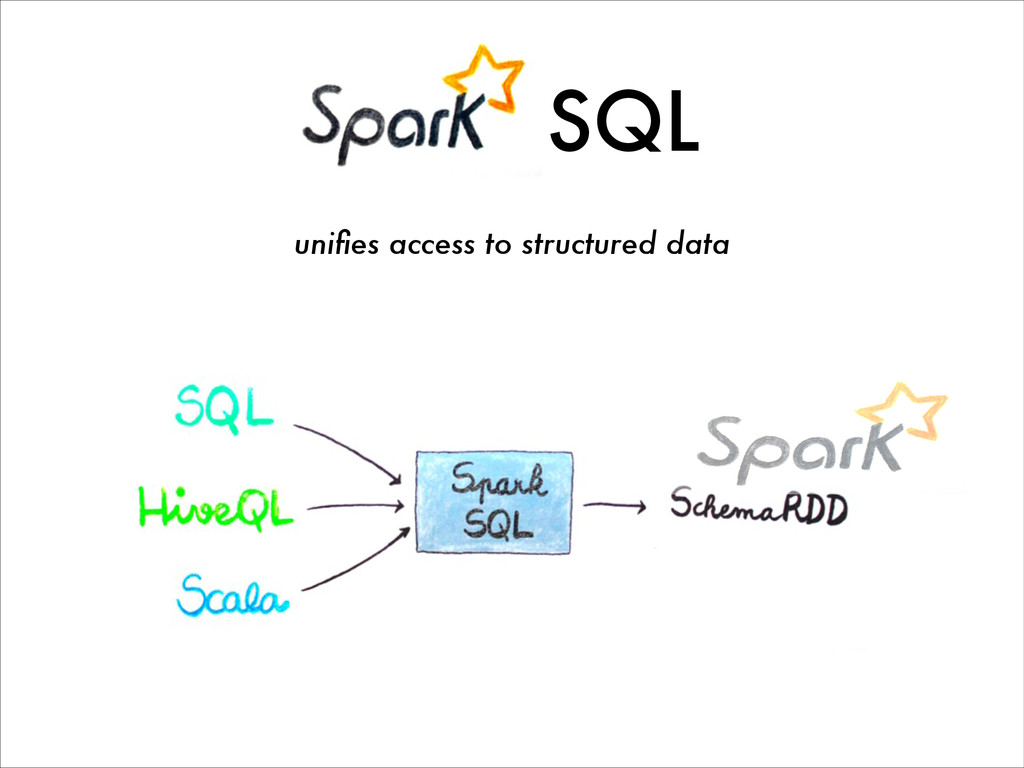{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
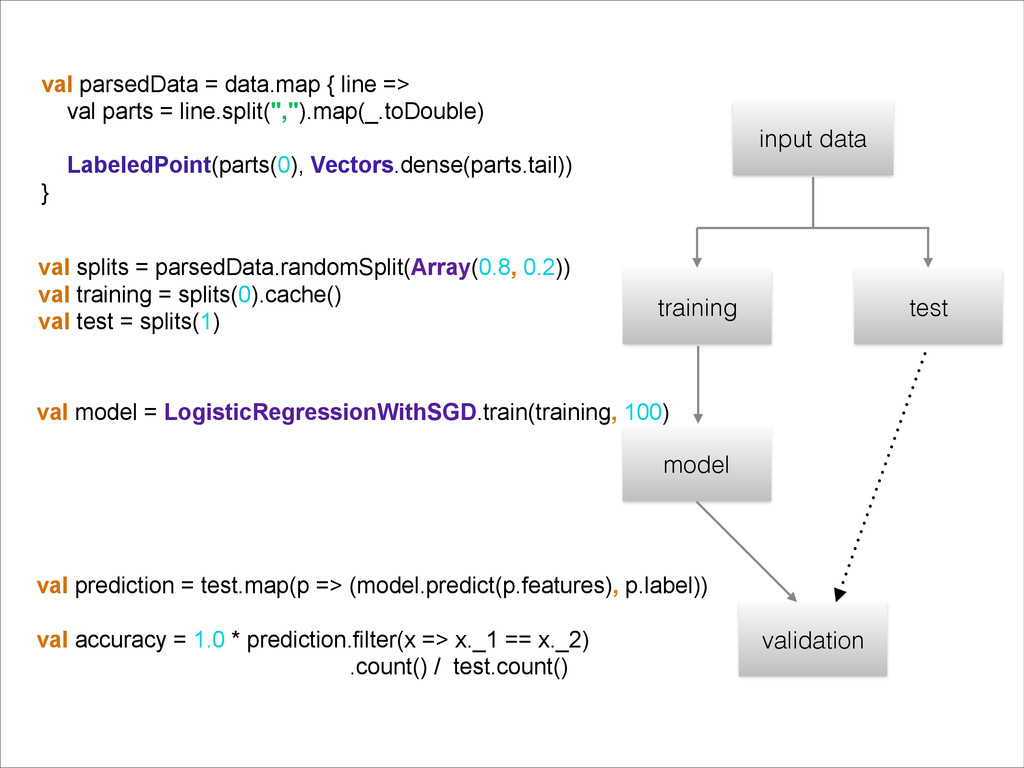{kind=link}
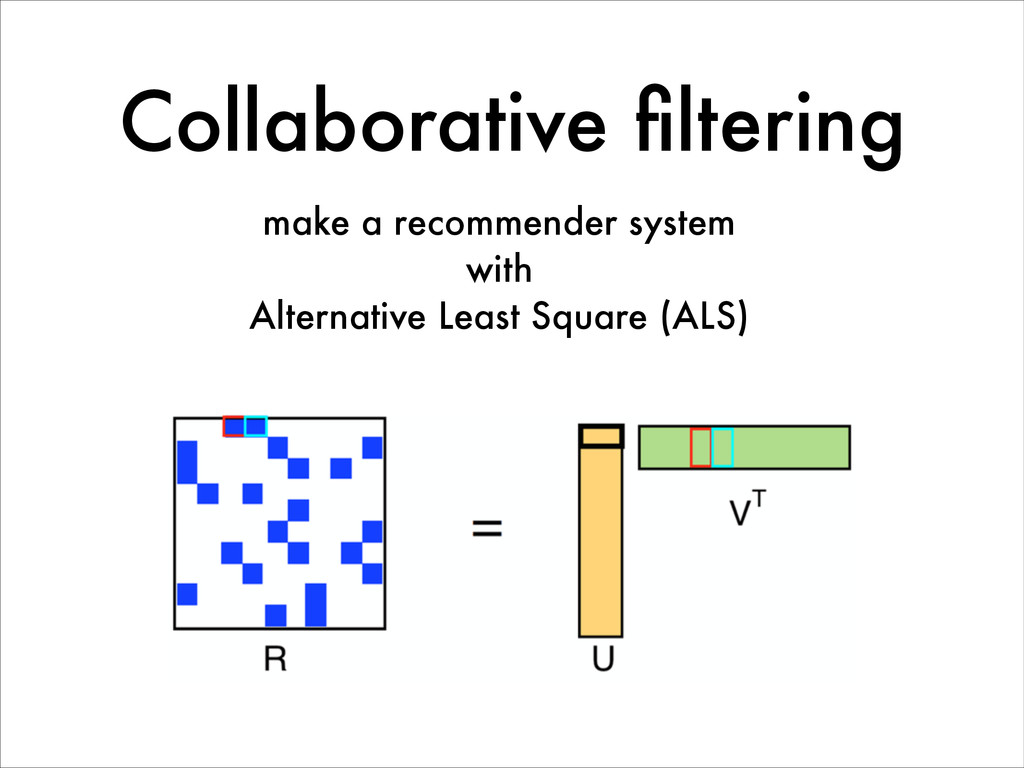{kind=link}
{kind=link}
{kind=link}
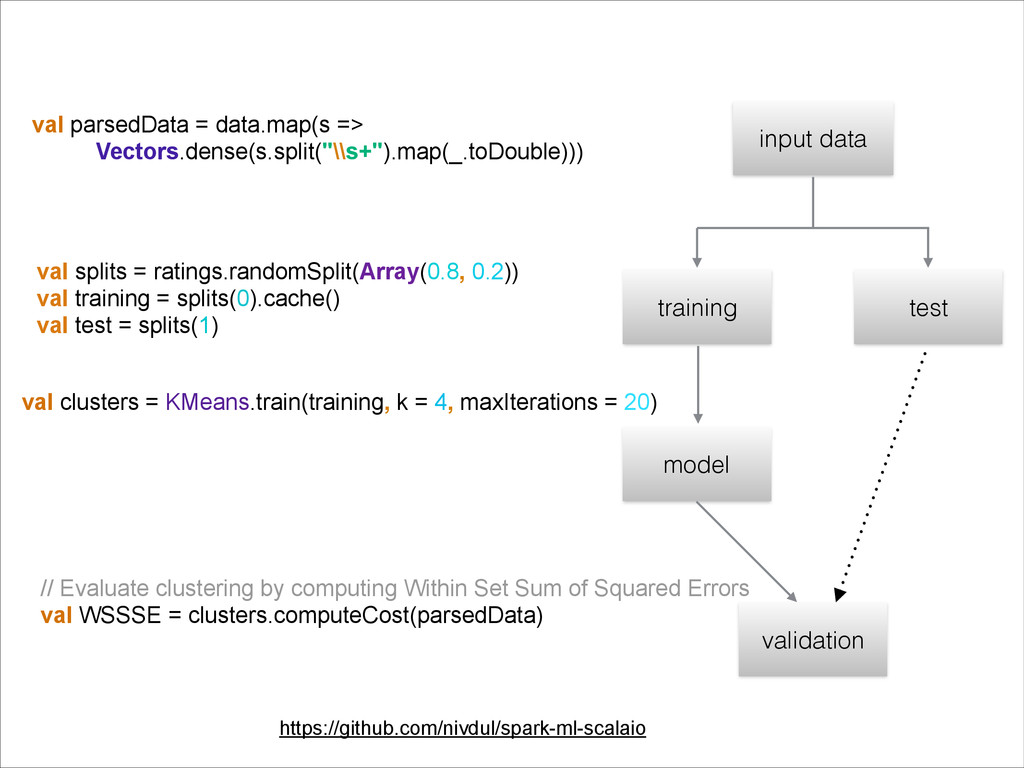{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}