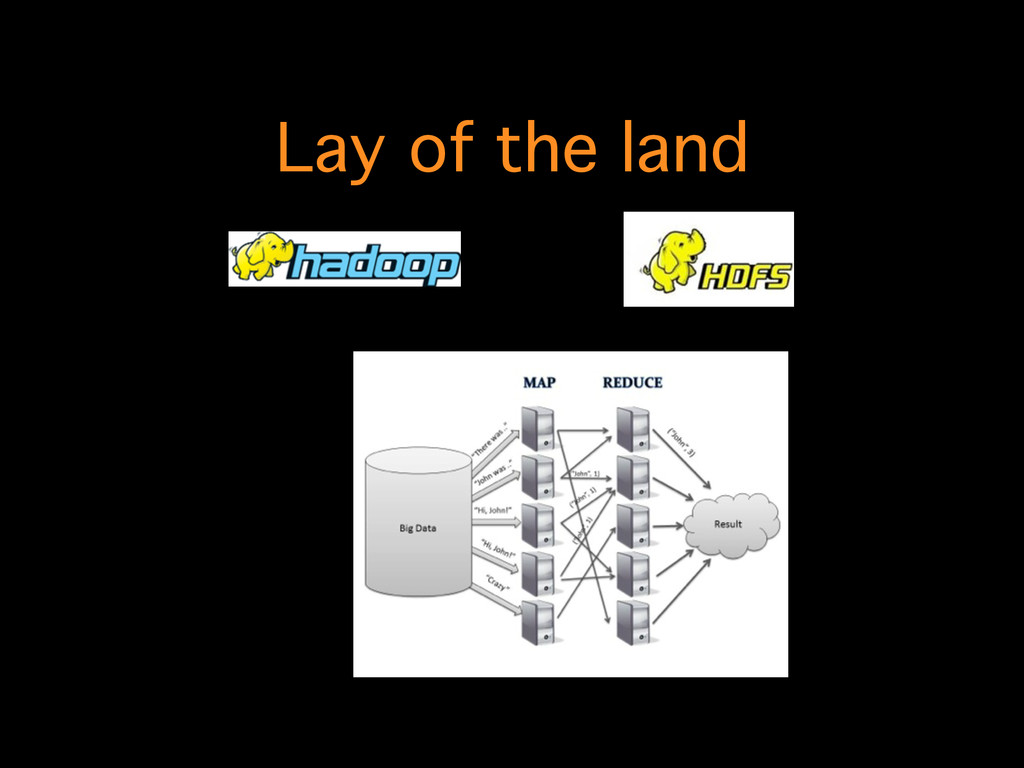
line.split(";")) // remove first line .filter(line -> !line[1].equals("ins_com")); ! lines.count(); ! // number per type of equipment order by alphabetical order lines.mapToPair(line -> new Tuple2<>(line[3], 1)) .reduceByKey((x, y) -> x + y) .sortByKey() .foreach(t -> System.out.println(t._1 + " -> " + t._2)); !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Create a RDD ! // from textile JavaRDD<String[]> lines =](https://files.speakerdeck.com/presentations/ba371a50e9d00131acc20e2a91d60c51/slide_11.jpg){kind=link}
![Operations on RDDs JavaRDD<String[]> lines = sc.textFile("ensemble-des-equipements- sportifs-de-lile-de-france.csv") .map(line ->](https://files.speakerdeck.com/presentations/ba371a50e9d00131acc20e2a91d60c51/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}