Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
_初級_中級者向け__ゾーン冗長を考慮したAzure仮想マシン上にSQL_Server_Alw...
Search
Nobushiro Takahara
November 28, 2020
Design
1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
_初級_中級者向け__ゾーン冗長を考慮したAzure仮想マシン上にSQL_Server_Always_On可用性グループの構築について.pdf
Nobushiro Takahara
November 28, 2020
More Decks by Nobushiro Takahara
See All by Nobushiro Takahara
クエリ パフォーマンスが著しく低下した場合の一時的な対処方法
nobtak
0
400
【初級・中級者向け】 Azure Database for PostgreSQL 基本
nobtak
0
530
【初級・中級者向け】 Logic Apps を使用した Azure SQL Databaseの自動スケールアップ
nobtak
0
710
Azure SQL Database への接続アーキテクチャおよび Azure内部/外部から接続する際のファイアウォール設定に関する注意点について
nobtak
0
1.2k
Other Decks in Design
See All in Design
デザインとフロントエンドの境界が融ける Claude Code × Figma
littlebusters
2
3.2k
1000人規模の組織でデザインハーネスを導入するための第一歩
pkshadeck
PRO
2
2.6k
体験負債を資産に変える組織的アプローチ
hikarutakase
0
1.6k
富山デザイン勉強会_デザイントレンド2026.pdf
keita_yoshikawa
3
270
セブンデックス プロジェクト事例 / innovation Scenes
sevendex
1
1.4k
Техники структурирования беседы с собой, заказчиком и командо
ashapiro
0
200
「おすすめ」はなぜ信用されないのか - 信頼を築くUI/UX設計
ryu1013
0
180
デザイナーが主導権を握る、AI協業の本音と実践
satosio
7
3.4k
大企業インハウスデザイン組織における DesignOps改革の現在地 / DesignOps at Scale: Navigating Transformation in Large Enterprises
nttcom
0
780
Claudeもくもく会、はじめませんか?
yusukeiyoda
0
130
JBUG大阪#9_登壇資料_引き継ぎで困らないためのBacklogWikiの整え方_ミスと属人化を防ぐために、 “次の人が動ける状態”をどう残すか
webnaut
1
200
全員がアウトプットを出せる時代、 誰を採用する?
nishame
0
620
Featured
See All Featured
Site-Speed That Sticks
csswizardry
13
1.3k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Utilizing Notion as your number one productivity tool
mfonobong
4
440
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Designing for Performance
lara
611
70k
Typedesign – Prime Four
hannesfritz
42
3.1k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
The Cost Of JavaScript in 2023
addyosmani
55
10k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Transcript
【初級・中級者向け】 ゾーン冗長を考慮したAzure仮想マシン上にSQL Server Always On可用性グループの構築について
1. ゾーン冗長を考慮したSQL Server 可用性グループ 構成図 (例) 2. 考慮ポイント 3. 最後に
4. 参考情報 5. Q/A
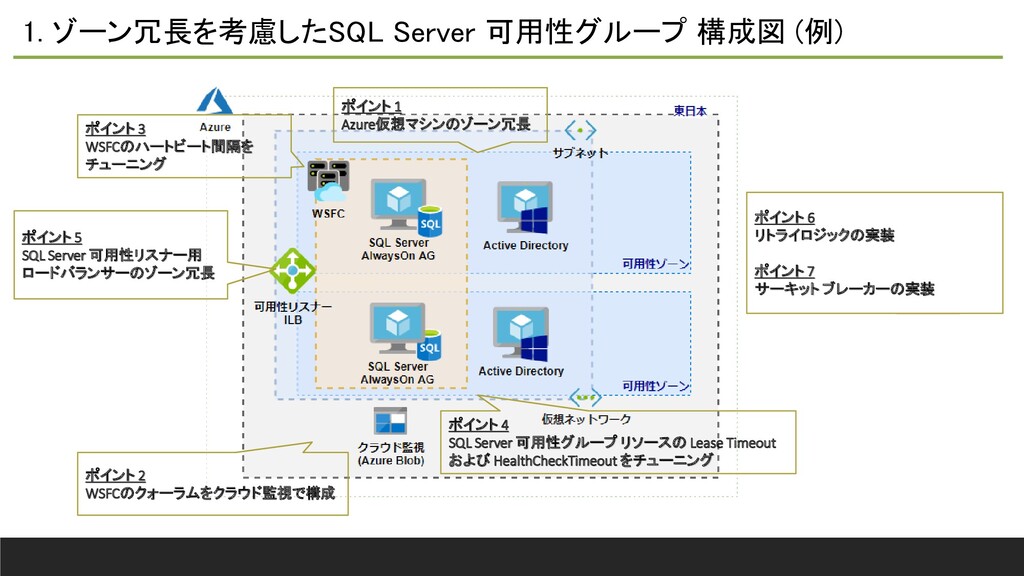
1. ゾーン冗長を考慮したSQL Server 可用性グループ 構成図 (例) ポイント 5 SQL Server
可用性リスナー用 ロードバランサーのゾーン冗長 ポイント 1 Azure仮想マシンのゾーン冗長 ポイント 2 WSFCのクォーラムをクラウド監視で構成 ポイント 3 WSFCのハートビート間隔を チューニング ポイント 4 SQL Server 可用性グループ リソースの Lease Timeout および HealthCheckTimeout をチューニング ポイント 6 リトライロジックの実装 ポイント 7 サーキット ブレーカーの実装
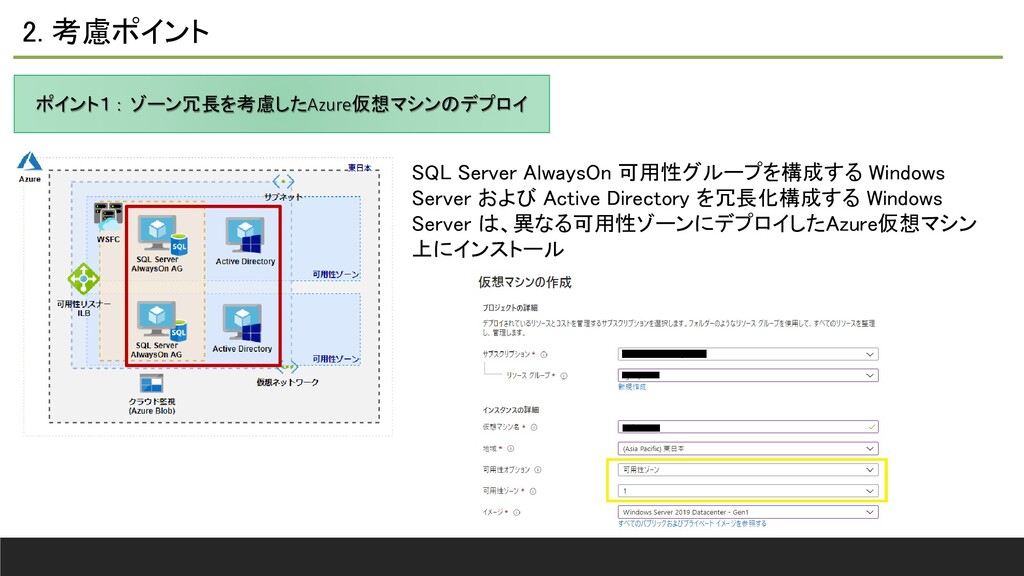
2. 考慮ポイント ポイント1 : ゾーン冗長を考慮したAzure仮想マシンのデプロイ SQL Server AlwaysOn 可用性グループを構成する Windows
Server および Active Directory を冗長化構成する Windows Server は、異なる可用性ゾーンにデプロイしたAzure仮想マシン 上にインストール
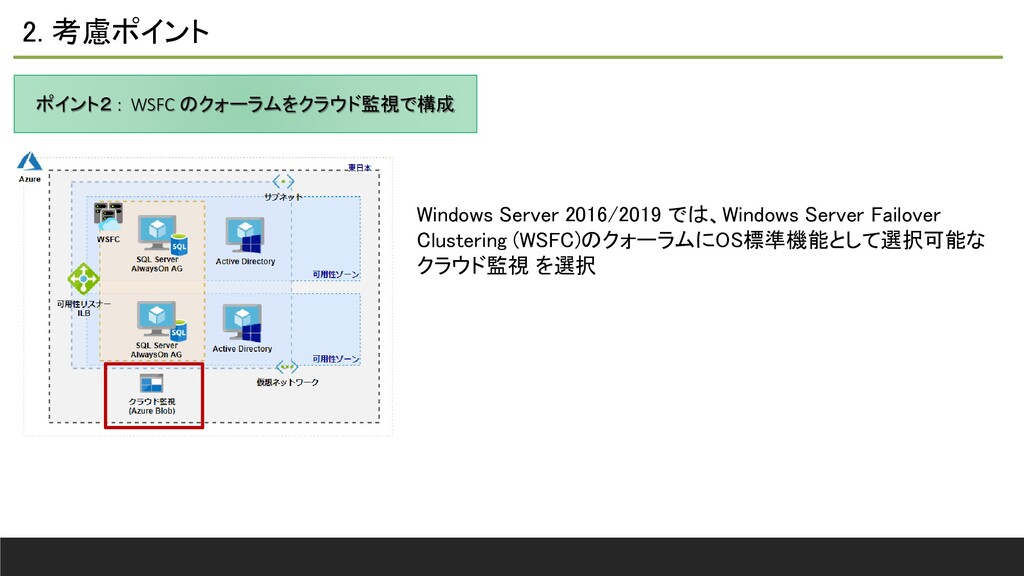
2. 考慮ポイント ポイント2 : WSFC のクォーラムをクラウド監視で構成 Windows Server 2016/2019 では、Windows
Server Failover Clustering (WSFC)のクォーラムにOS標準機能として選択可能な クラウド監視 を選択
2. 考慮ポイント ポイント3 : WSFC のハートビート間隔設定を30秒(30000 ミリ秒)以上に設定 WSFC のハートビート間隔設定で SameSubnetDelay
(単位:ミリ秒) * SameSubnetThreshold (単位:回数) の値が、30秒 (30000 ミリ秒) 以上に なるようにパラメータ値を変更
2. 考慮ポイント ポイント4 : SQL Server AlwaysOn 可用性グループ リソースの Lease
Timeout および HealthCheckTimeout の値を30秒(30000 ミリ秒)以上に設定 1) Lease Timeout 値を 30秒 (30000ミリ秒) 以上に設定する。(既定値: 20秒 : 20000ミリ秒) Lease Timeout * 1/2 の値は、WSFCのハートビート間隔 (SameSubnetDelay (単位:ミリ秒) * SameSubnetThreshold (単位:回数) ) の値よりも小さい必要がある 2) HealthCheckTimeout 値をLease Timeout 値に指定した値よりも長く設 定する。(既定値: 30秒 : 30000ミリ秒) HealthCheckTimeout 値は、Lease Timeout 値よりも長く設定する必要が あるため、Lease Timeout 値を変更した場合は、HealthCheckTimeout 値 も長く設定
2. 考慮ポイント ポイント5 : SQL Server AlwaysOn 可用性リスナーに紐づけるロードバランサー(ILB) のSKUをStandardおよびゾーン冗長に設定 SQL
Server Always On 可用性グループに接続するロードバラン サーについても、 ロードバランサー(ILB) 作成時、種類:「内部」、 SKU :「Standard」、可用性ゾーン : 「ゾーン冗長」を選択して作成
2. 考慮ポイント ポイント6 : Azure上の高可用性のサービス(データベースなど)に接続するアプリ ケーションでは、リトライ処理を実装し、エラーハンドリングできる状態にする。 パブリッククラウドサービスのSLAは100%ではなく、高可用性を維持する ために、内部的にフェールオーバーなどが実施されています。 そのため、クラウドサービス(特にデータベースなど)へ接続するアプリ ケーションでは、フェールオーバーに伴い、実行中の処理が失敗したり、
該当のサービスに接続できないなどの問題に対処するため、アプリケー ション側でエラーをハンドリングし、リトライ処理を実装することが推奨され ている。 ※ リトライ処理を実装する場合、リトライ間隔、リトライ回数も重要な要素 となり、リトライ間隔については、数秒 (5秒など) 以上に設定する。 Exponential back off (徐々にリトライ間隔を延ばしていくロジック) も有効。
2. 考慮ポイント ポイント7 : サーキット ブレーカーの実装を検討する。 ポイント6でリトライ処理の実装を推奨するという内容を記載しましたが、 即座に解決しない問題が発生した場合、複数のプロセスで同時に大量の リトライ処理が実行されることで、 急激なトラフィックの増加に伴い、障害
範囲が拡大する可能性もあります。 そのため、リトライ処理を何回か実行したとしても現象が解消しない場合 においては、失敗を処理するロジックを追加するといった実装 サーキット ブレーカー パターン サーキット ブレーカー パターンを実装する
3. 最後に 今回紹介したゾーン冗長を考慮したAzure仮想マシン上にSQL Server Always On可用 性グループの構築については、以下のブログでも紹介しています。 Azure仮想マシン上にゾーン冗長を考慮したSQL Server AlwaysOn可用性グループを構築する場合の勘所について
また、SQL Serverの 基本+α の内容についてもブログにまとめていますので、是非 ご 参照ください。 (現在 第1回から11回まで公開中) 【第1回】基本から始める SQL Server【システム データベース】
4. 参考情報 ゾーン冗長を考慮した WSFC クラスタークォーラム設定(クラウド監視) [Azure/WSFC] フェールオーバー クラスターのクラウド監視を展開する Azure 上でフェールオーバー
クラスターを構築する際の留意事項について 再起動を必要としないメンテナンス リースのタイムアウト 正常性チェックの値 ゾーン冗長を考慮した SQL Server 可用性グループ + 可用性リスナー(内部)の構築 [Azure/WSFC/SQL Server]
Q&A
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![4. 参考情報 ゾーン冗長を考慮した WSFC クラスタークォーラム設定(クラウド監視) [Azure/WSFC] フェールオーバー クラスターのクラウド監視を展開する Azure 上でフェールオーバー](https://files.speakerdeck.com/presentations/11425a296e1541a08898ae3f8c2430c3/slide_11.jpg){kind=link}
{kind=link}