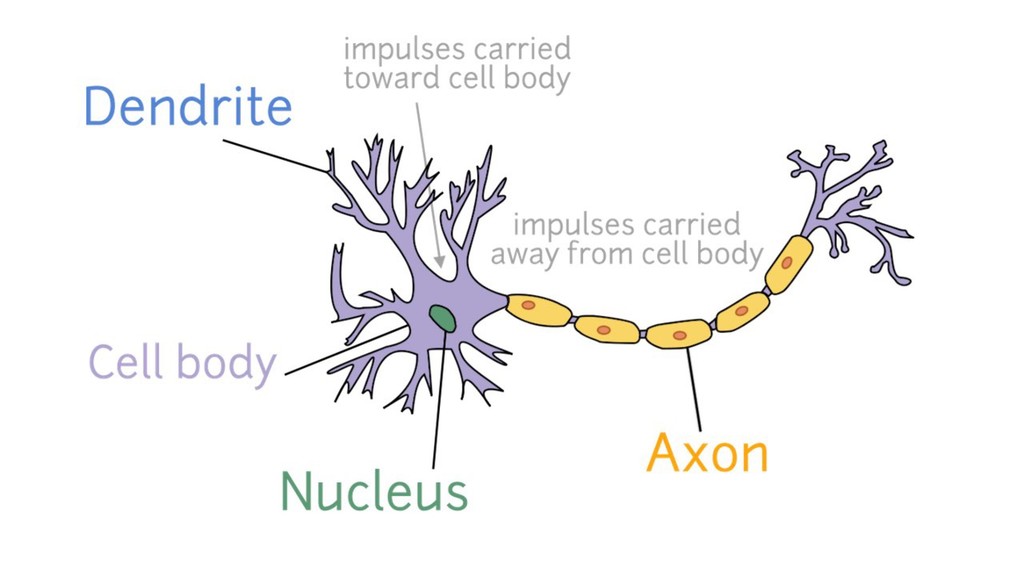
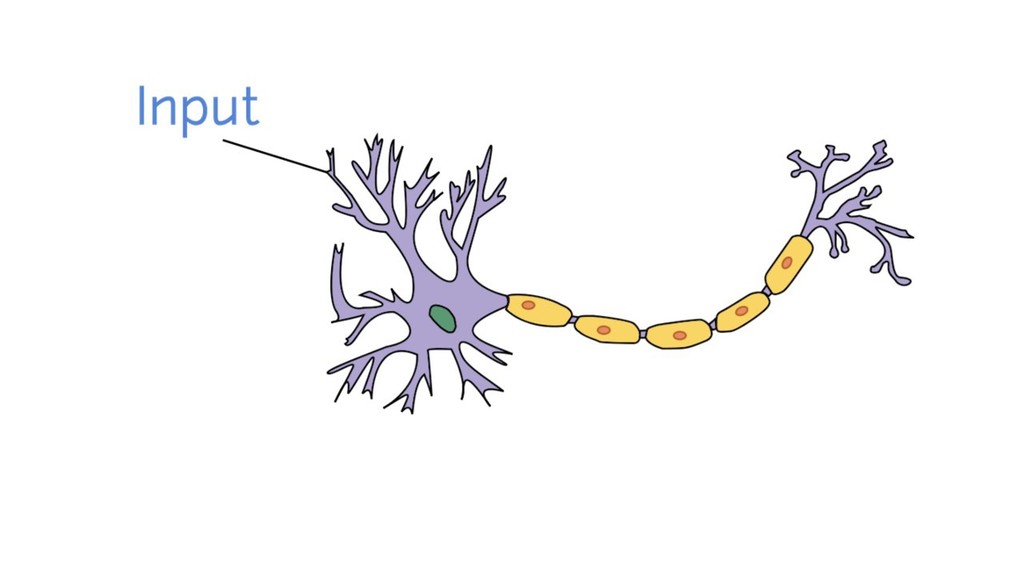
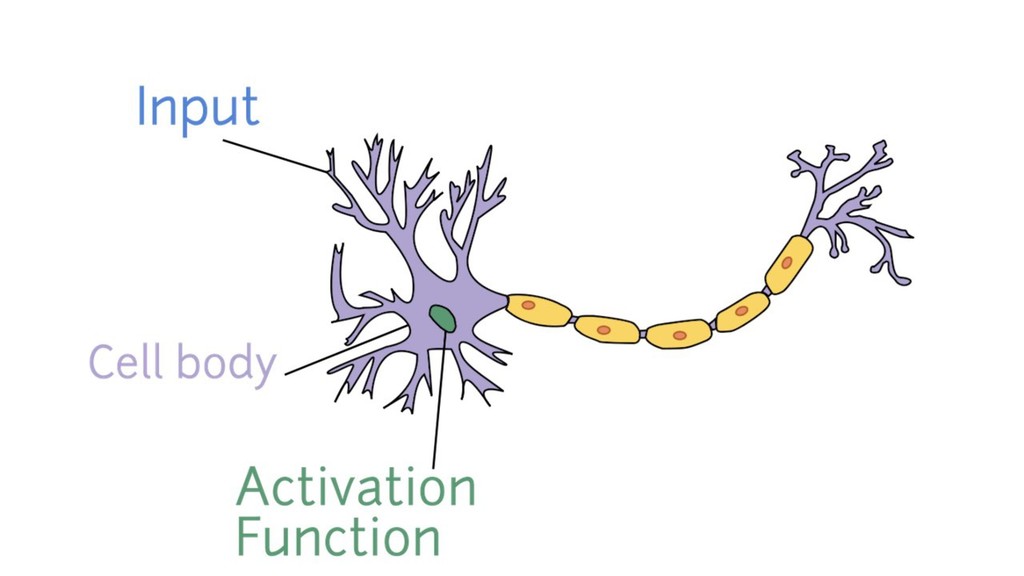
Curious about all the hype around Machine Learning and Artificial Intelligence? Heard of "Neural Networks" and "Deep Learning" but confused about what it really means?
In this talk, you'll see what Artificial Neural Networks (ANN) look like and how they can "learn". And along the way, you'll discover how you can build your own ANN, with PHP of course!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
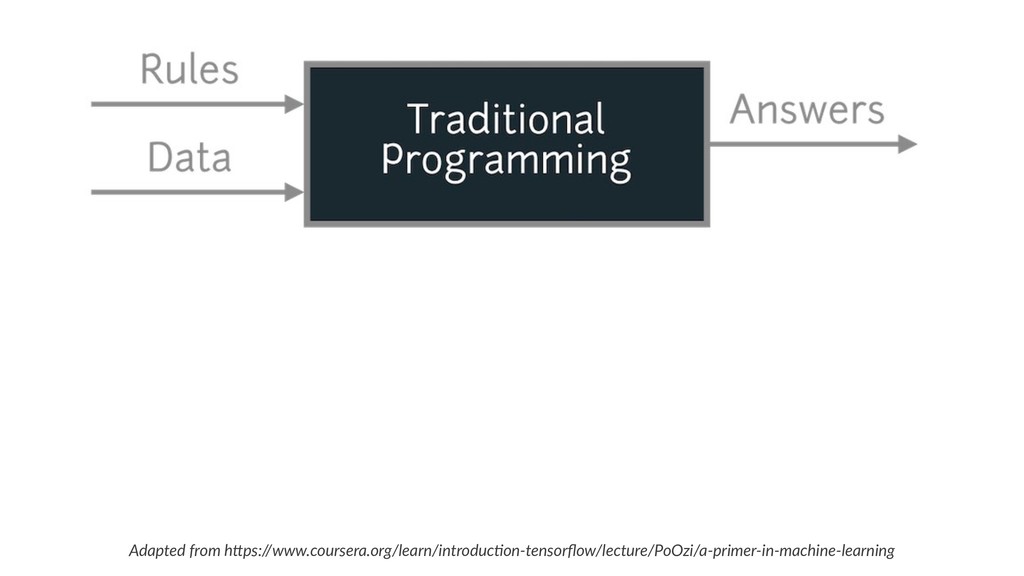{kind=link}
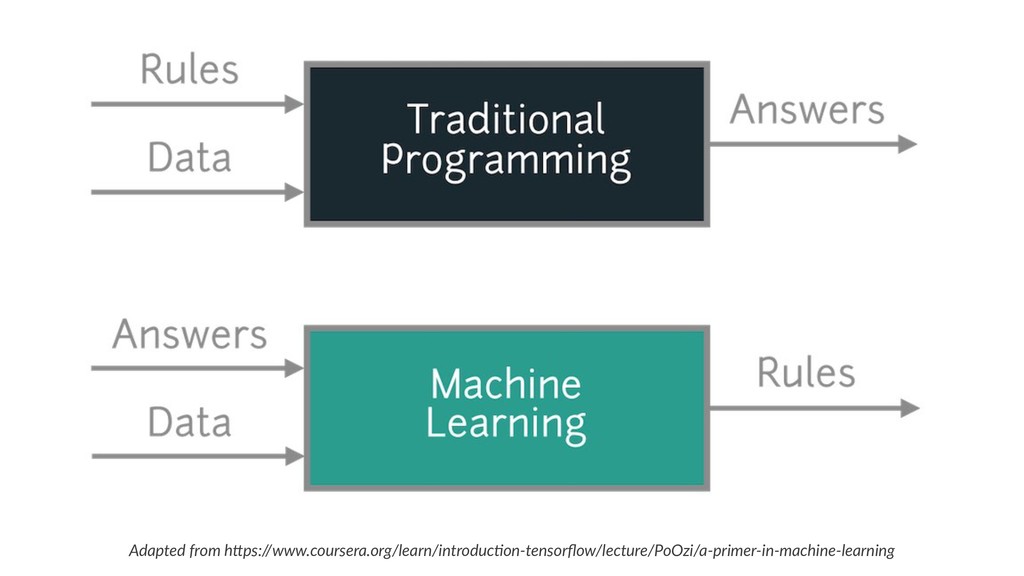{kind=link}
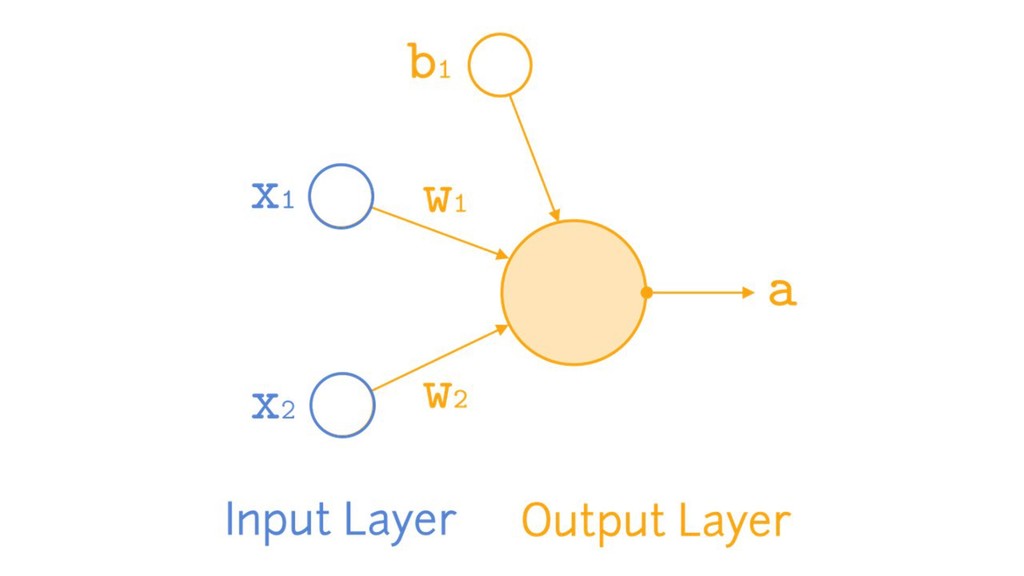{kind=link}
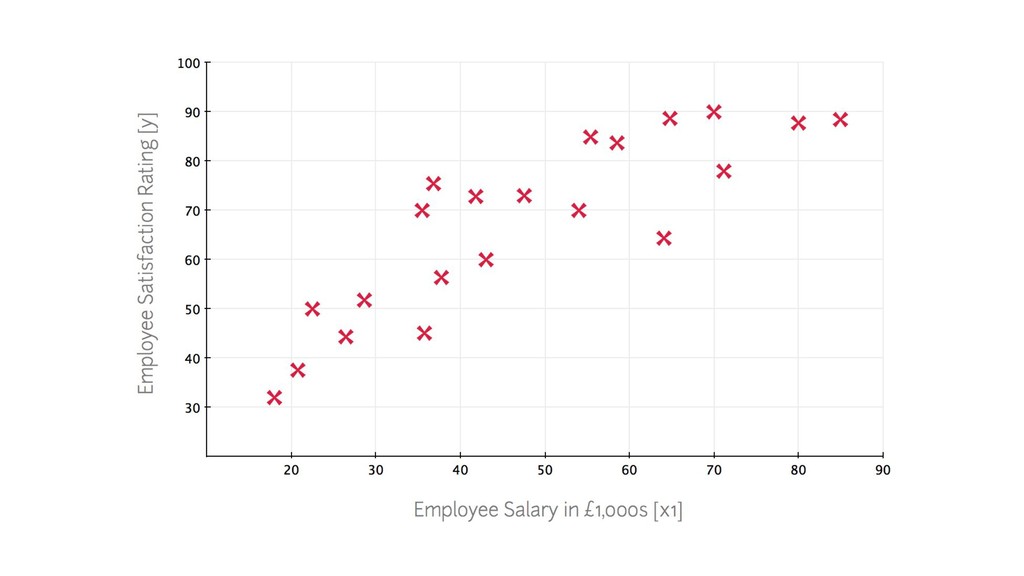{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
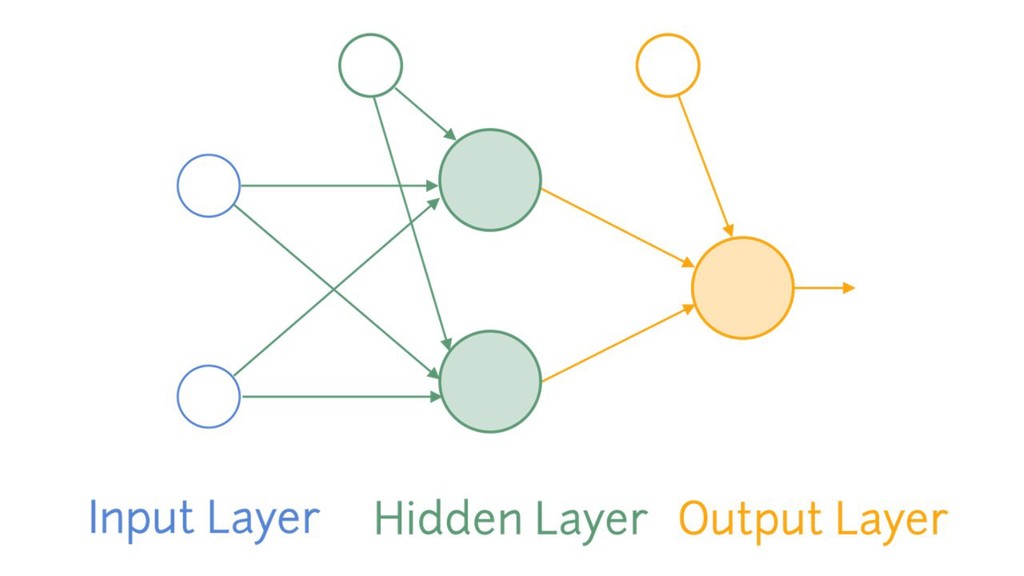{kind=link}
{kind=link}
{kind=link}
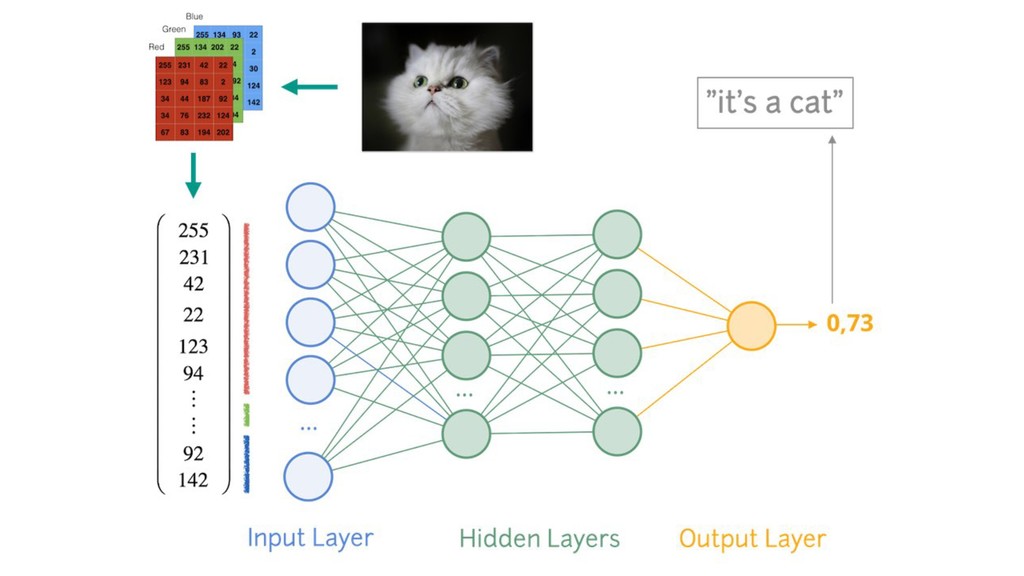{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
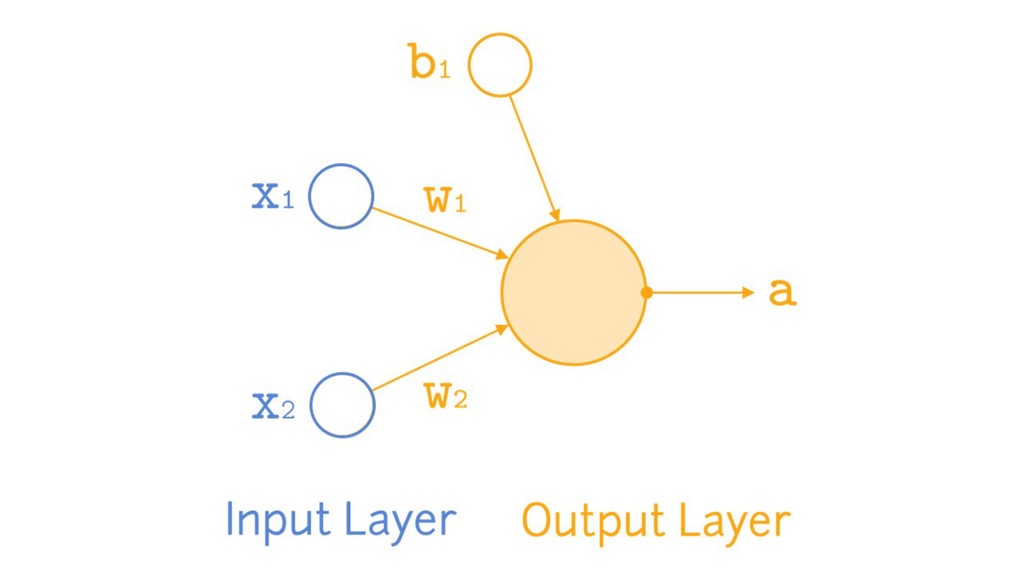{kind=link}
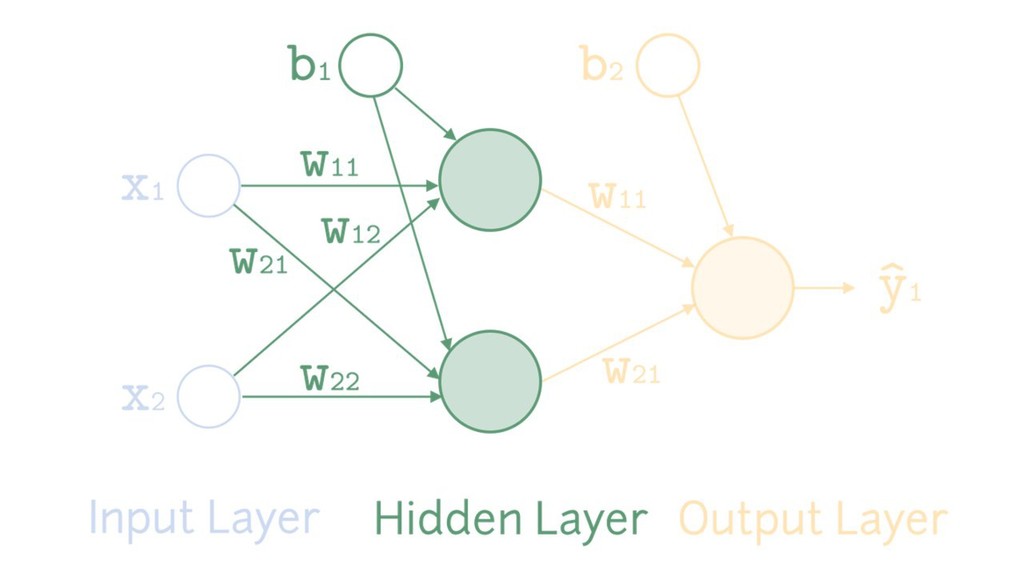{kind=link}
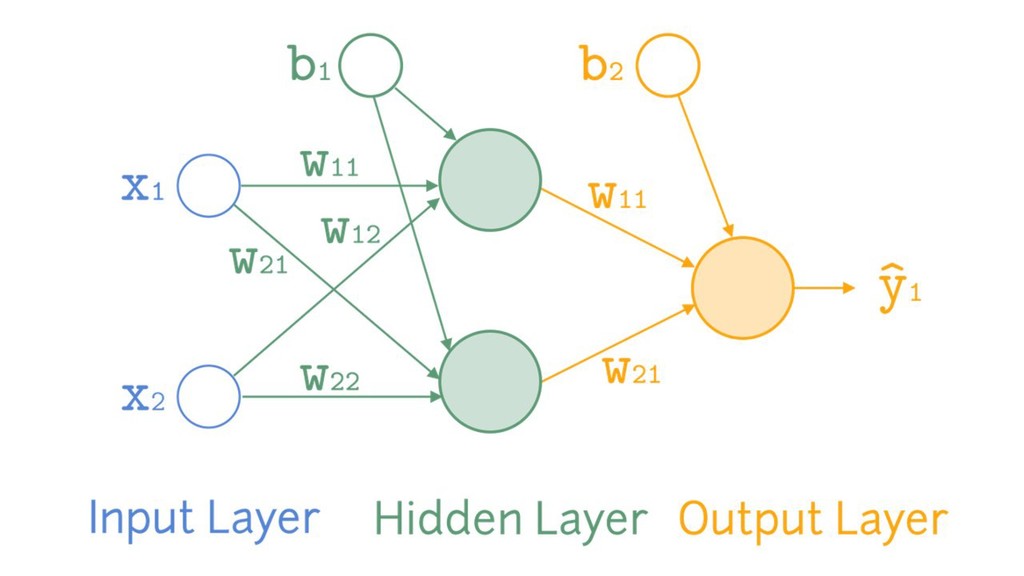{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![// › examples/xor.php $inputs = [ [0, 0], // 0](https://files.speakerdeck.com/presentations/4078addbc1454327a6f14d8e871369e7/slide_74.jpg){kind=link}
![// › examples/xor.php $inputs = [ [0, 0], // 0](https://files.speakerdeck.com/presentations/4078addbc1454327a6f14d8e871369e7/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
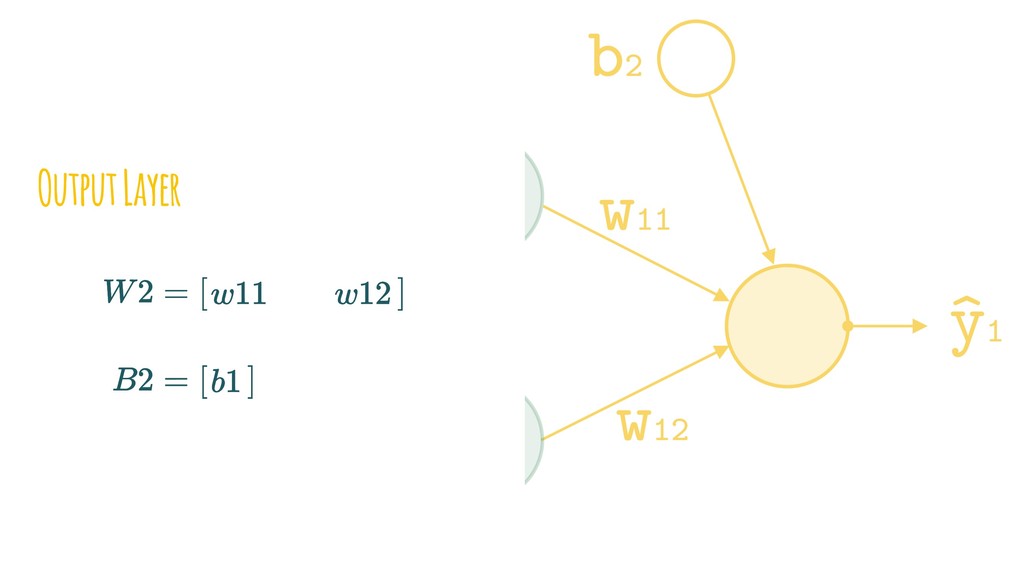{kind=link}
{kind=link}
![use MathPHP\LinearAlgebra\Matrix; use MathPHP\LinearAlgebra\MatrixFactory; $matrix = [ [1, 2, 3],](https://files.speakerdeck.com/presentations/4078addbc1454327a6f14d8e871369e7/slide_85.jpg){kind=link}
![use MathPHP\LinearAlgebra\Matrix; use MathPHP\LinearAlgebra\MatrixFactory; $matrix = [ [1, 2, 3],](https://files.speakerdeck.com/presentations/4078addbc1454327a6f14d8e871369e7/slide_86.jpg){kind=link}
![use MathPHP\LinearAlgebra\Matrix; use MathPHP\LinearAlgebra\MatrixFactory; $matrix = [ [1, 2, 3],](https://files.speakerdeck.com/presentations/4078addbc1454327a6f14d8e871369e7/slide_87.jpg){kind=link}
![use MathPHP\LinearAlgebra\Matrix; use MathPHP\LinearAlgebra\MatrixFactory; $matrix = [ [1, 2, 3],](https://files.speakerdeck.com/presentations/4078addbc1454327a6f14d8e871369e7/slide_88.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
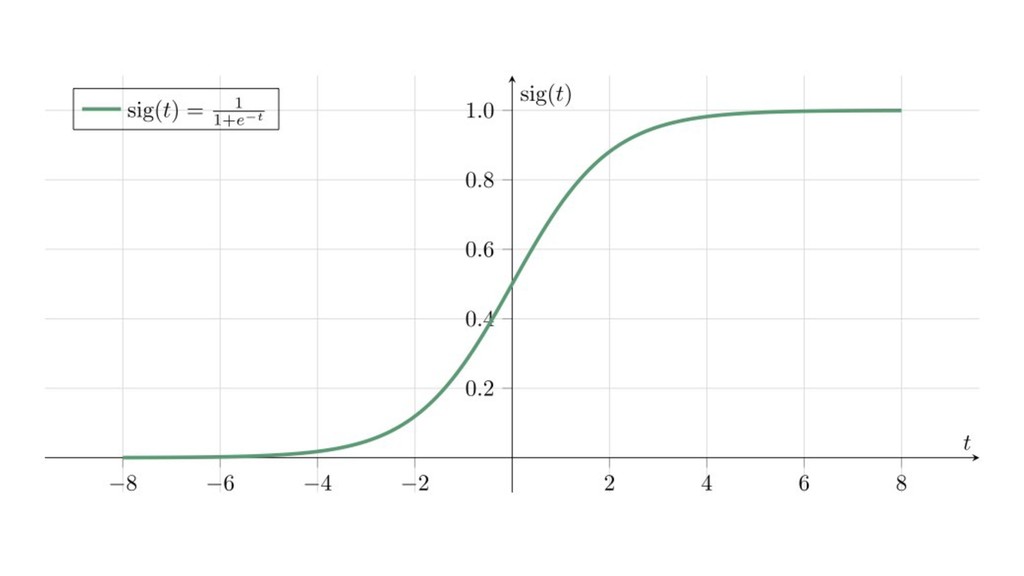{kind=link}
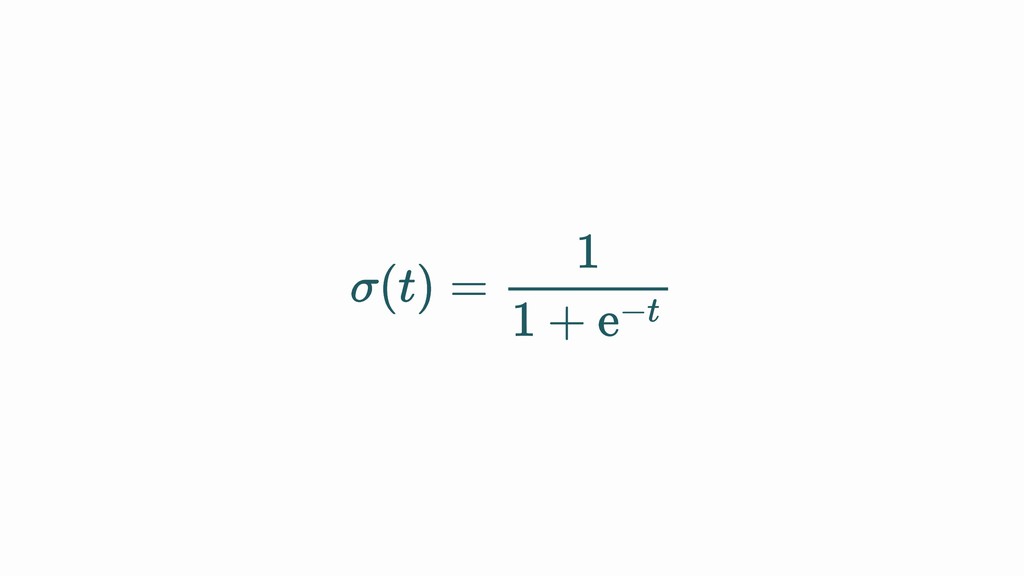{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
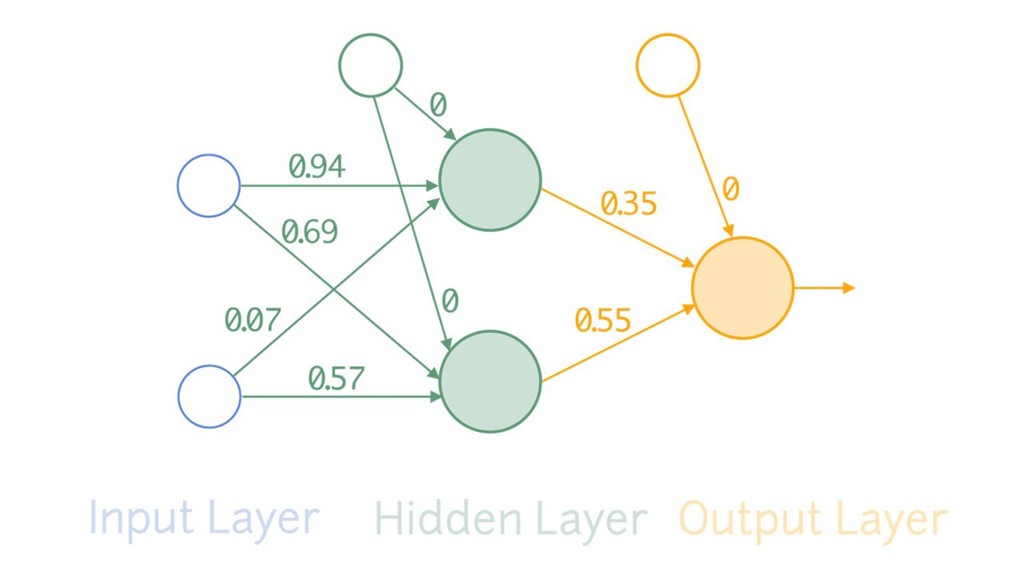{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
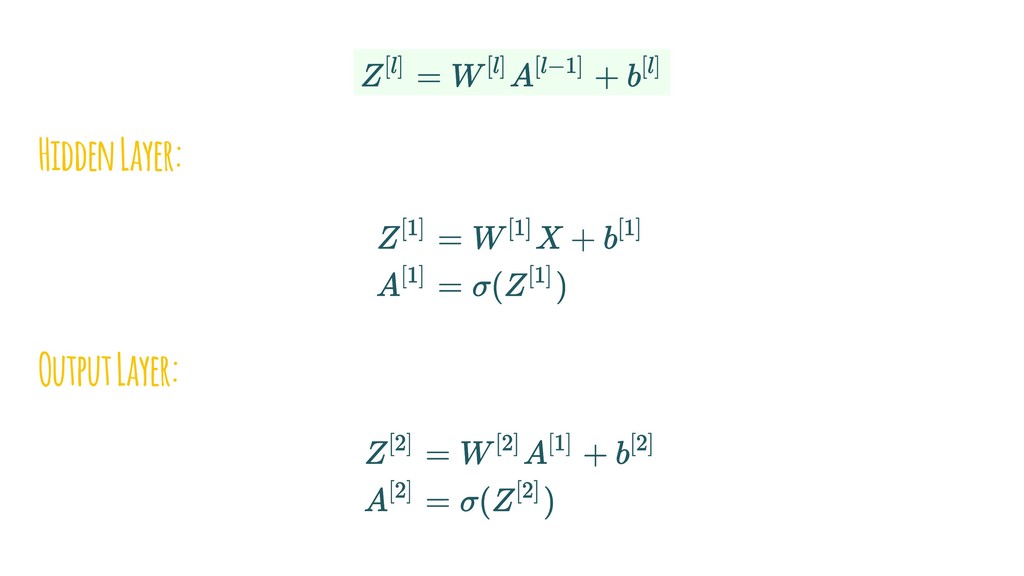{kind=link}
{kind=link}
{kind=link}
{kind=link}
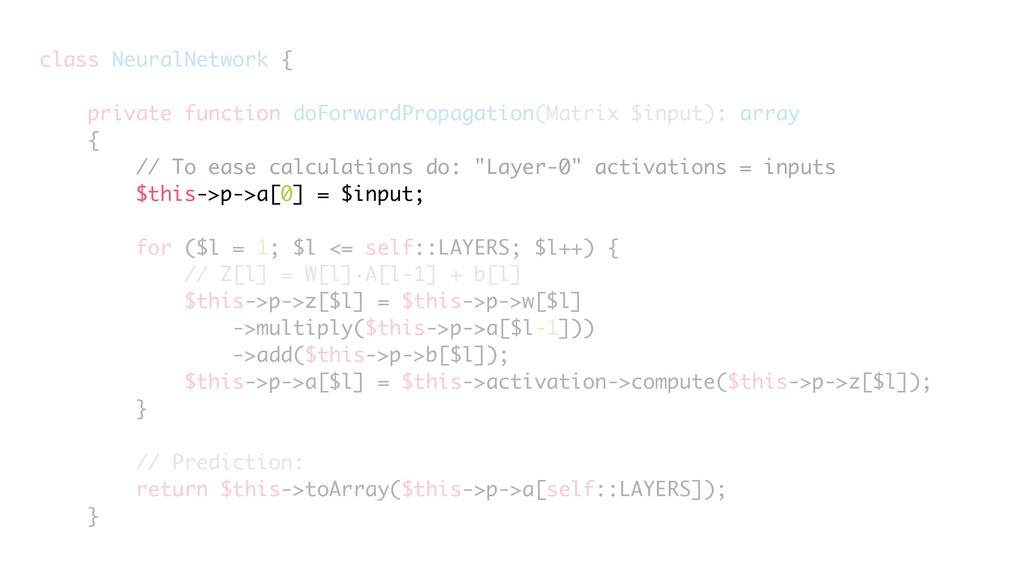{kind=link}
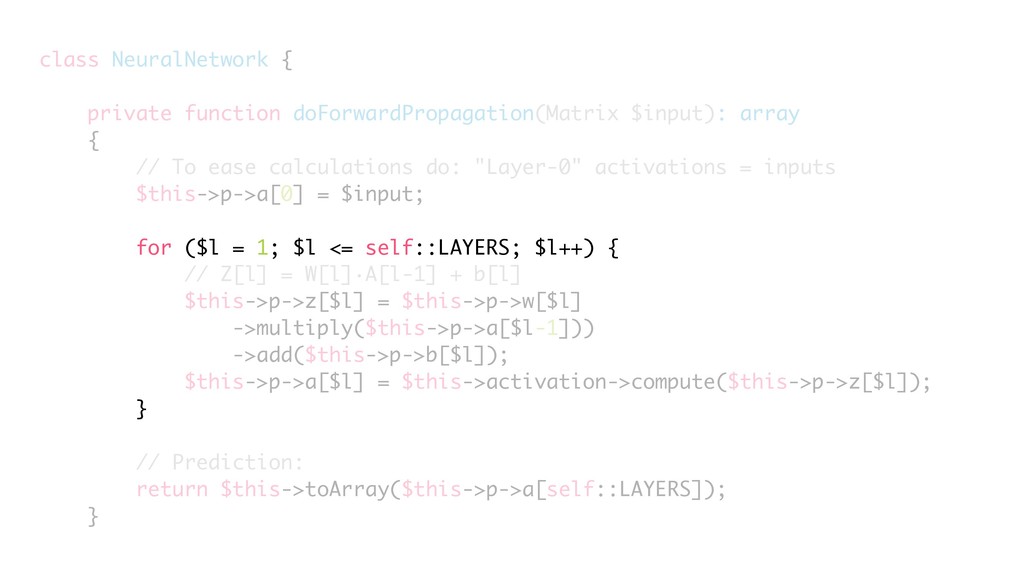{kind=link}
{kind=link}
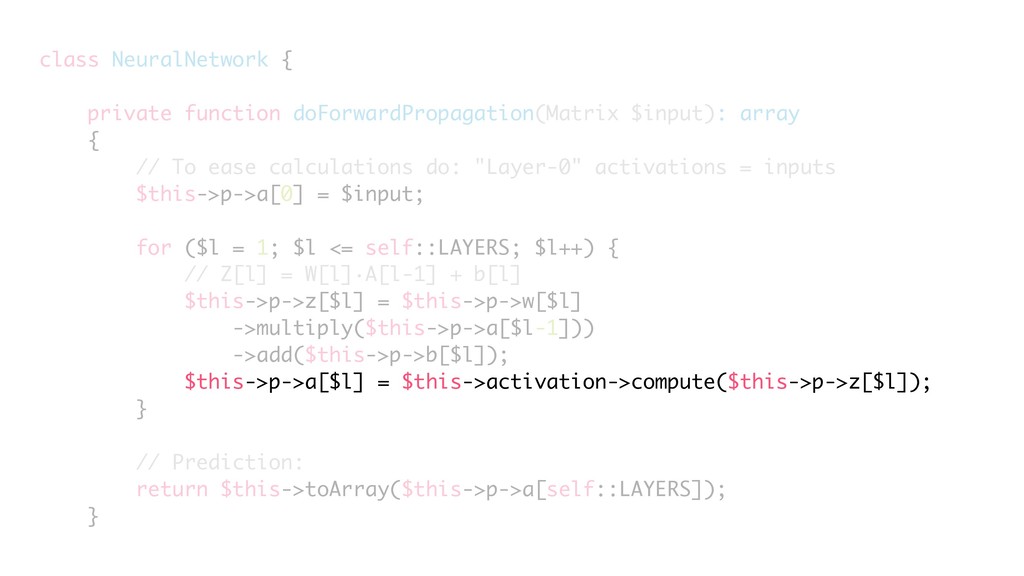{kind=link}
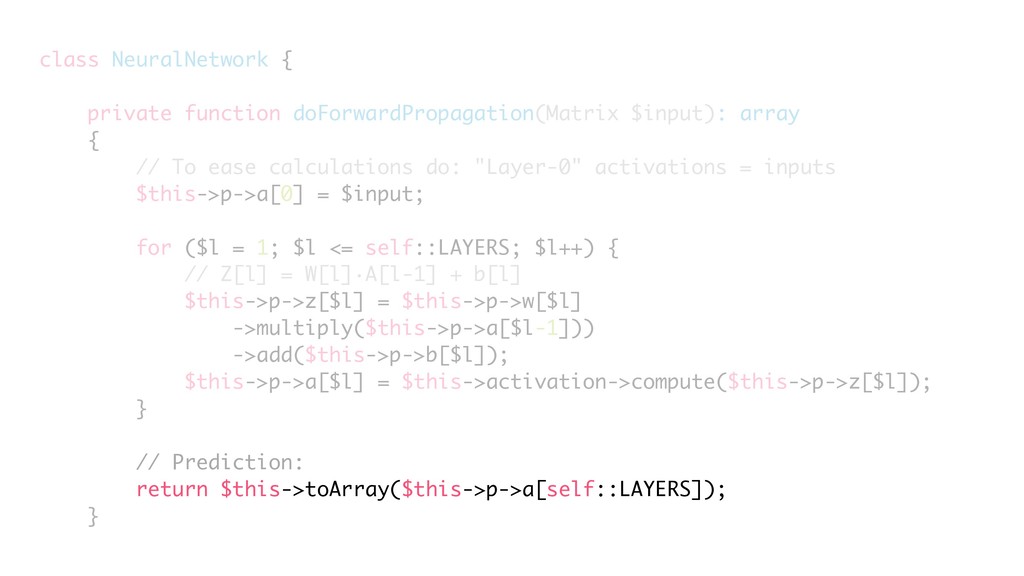{kind=link}
{kind=link}
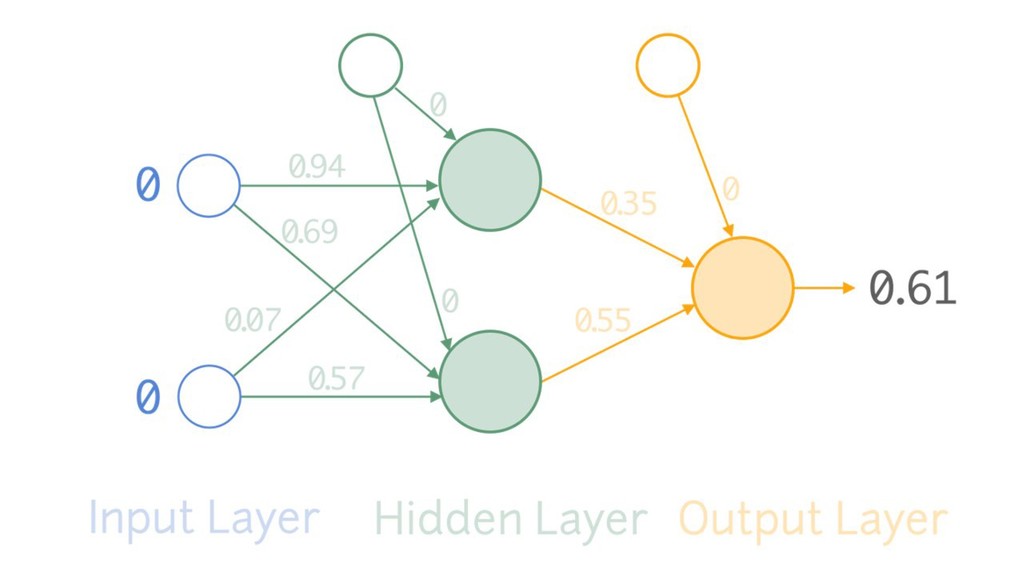{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
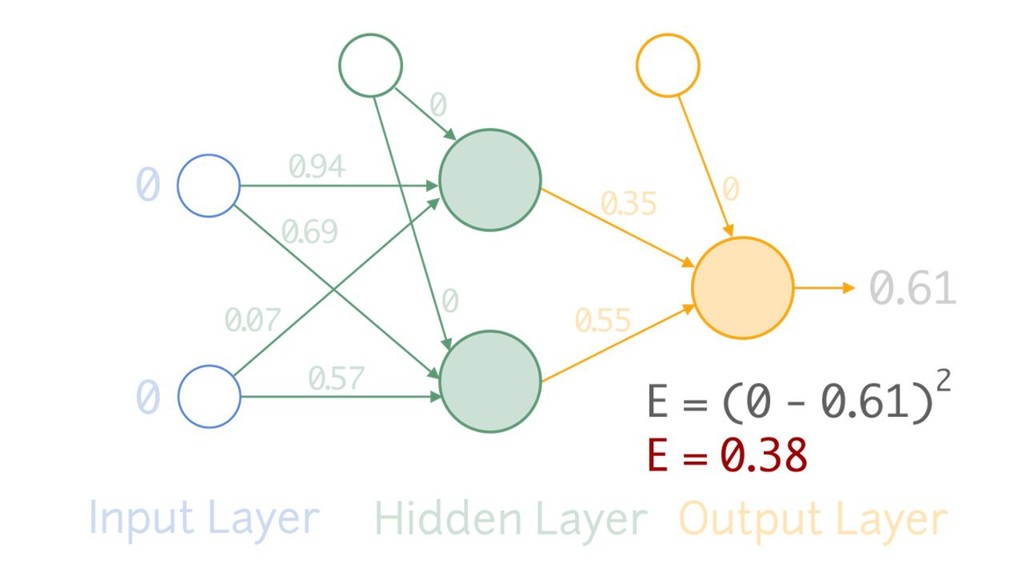{kind=link}
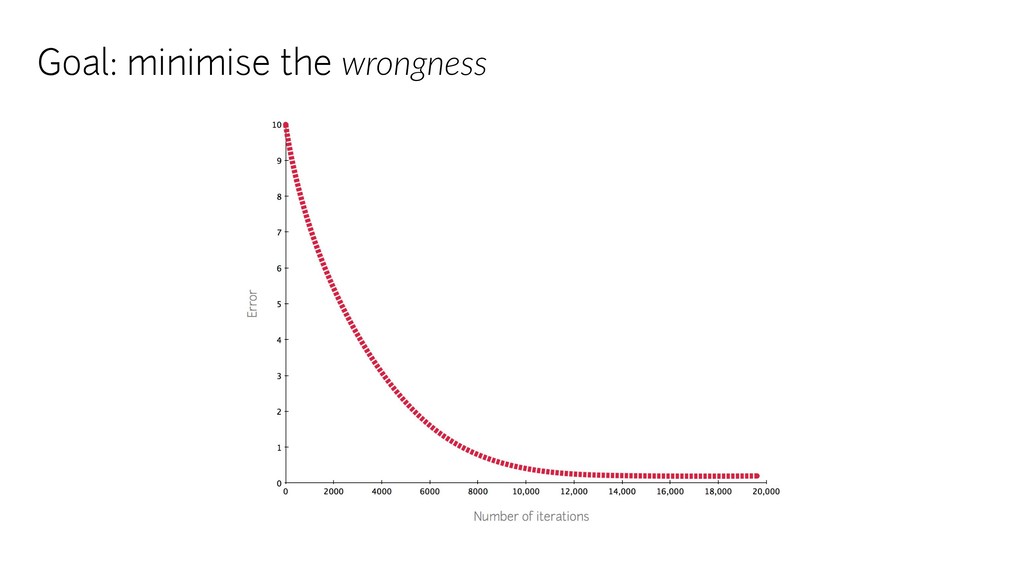{kind=link}
{kind=link}
{kind=link}
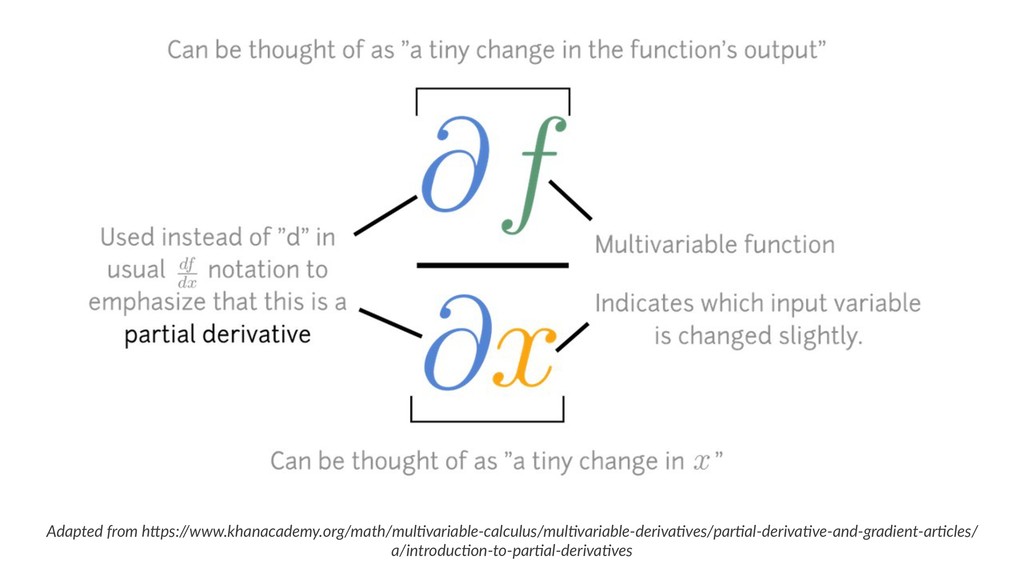{kind=link}
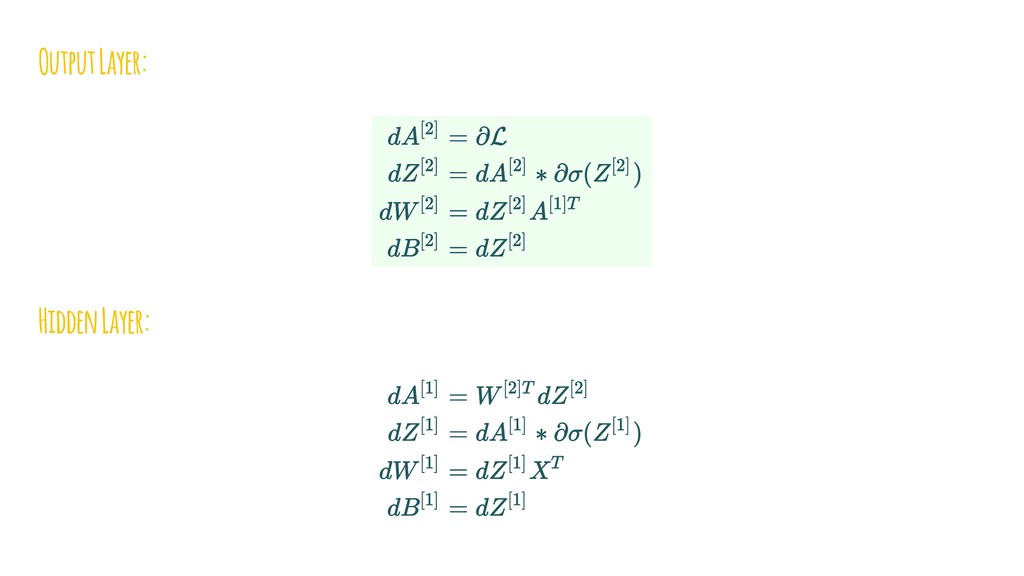{kind=link}
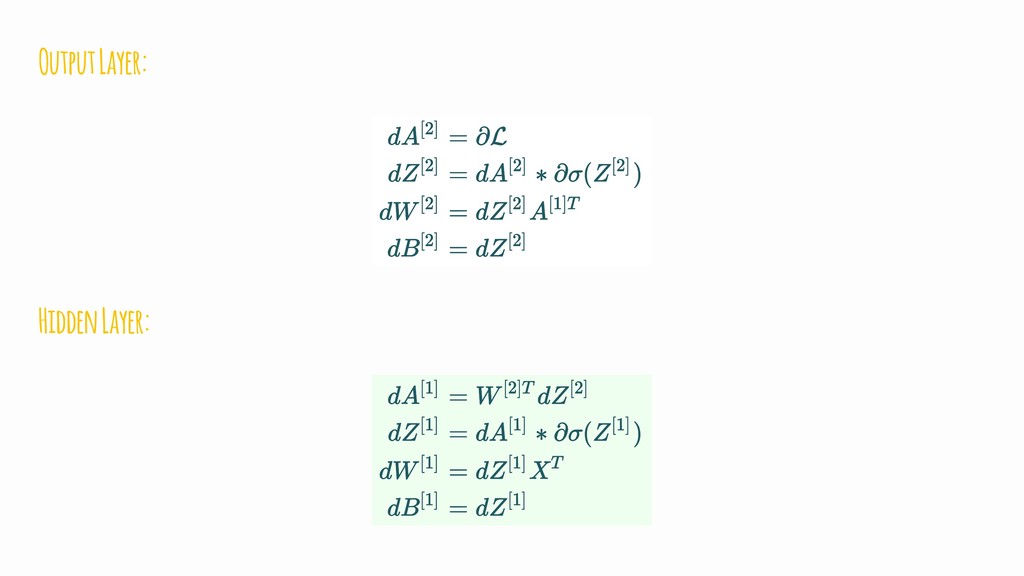{kind=link}
{kind=link}
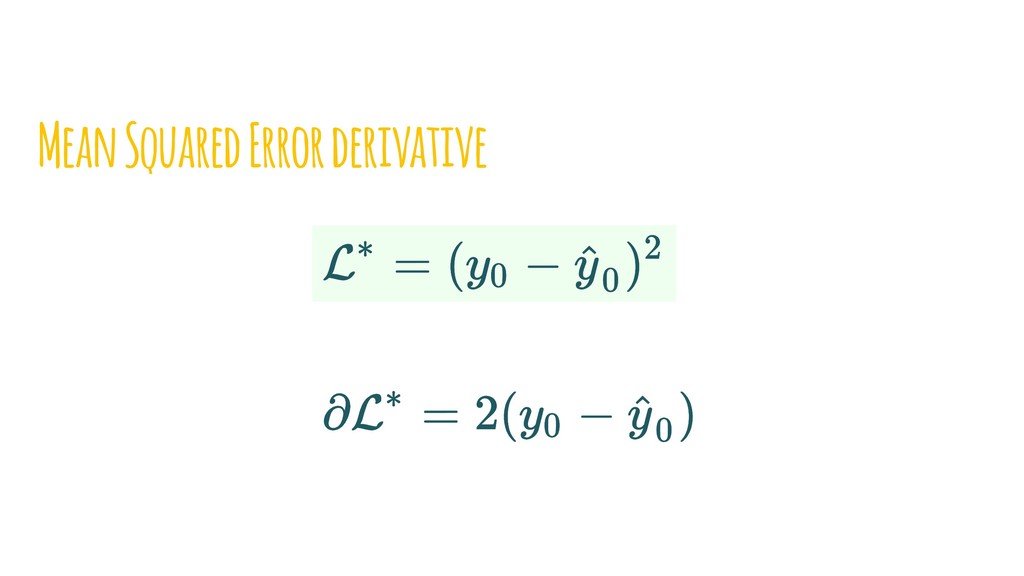{kind=link}
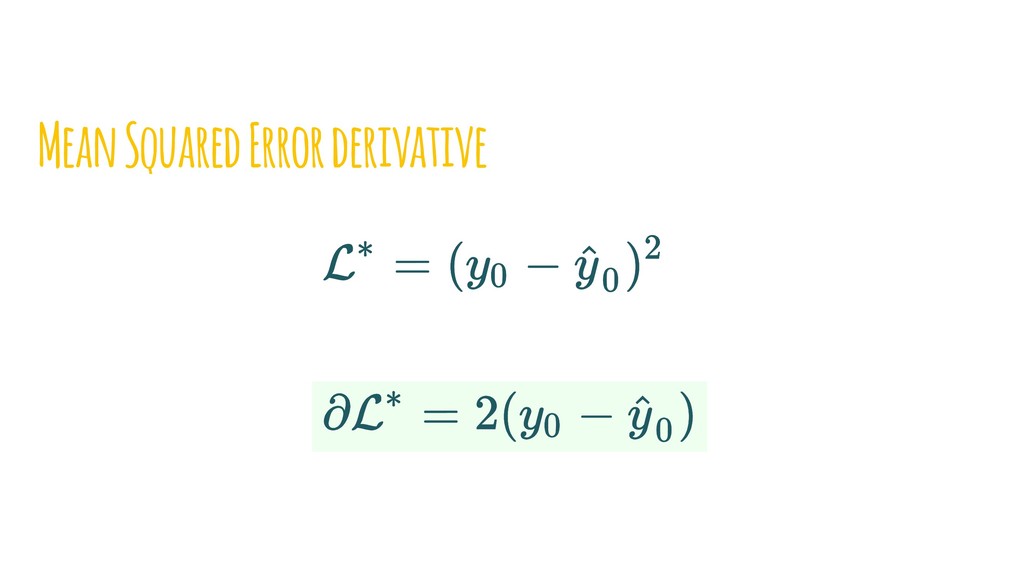{kind=link}
{kind=link}
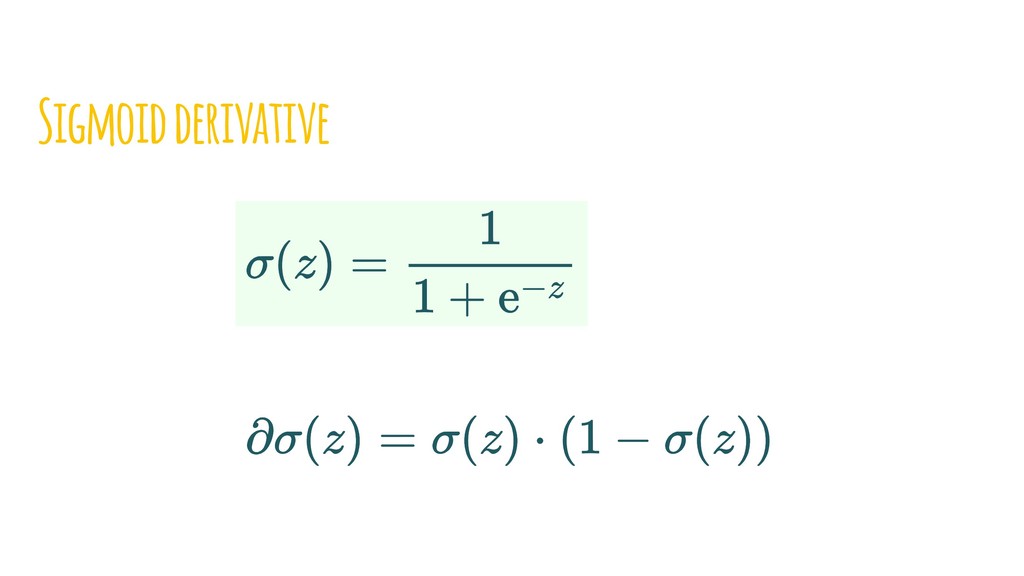{kind=link}
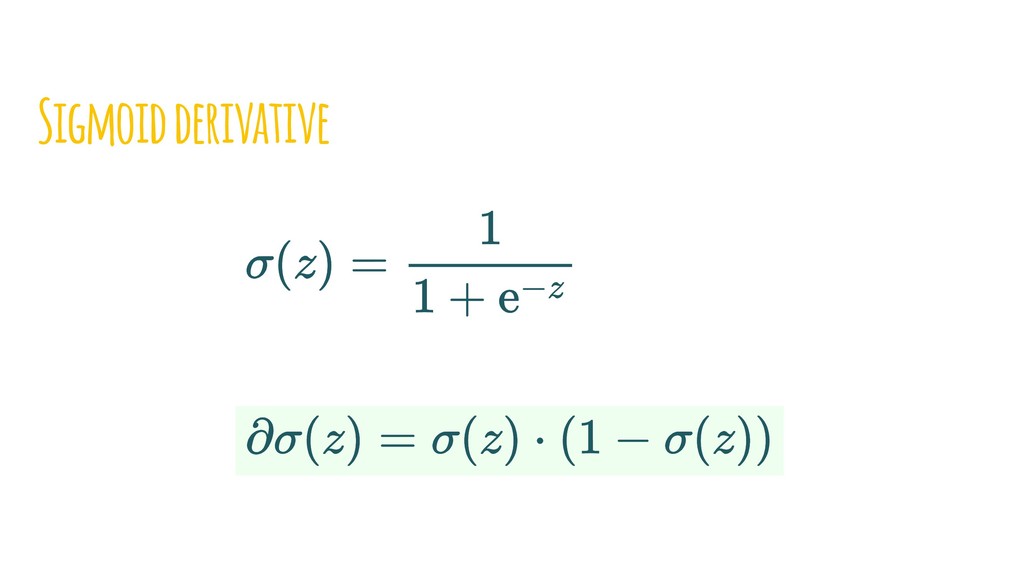{kind=link}
{kind=link}
{kind=link}
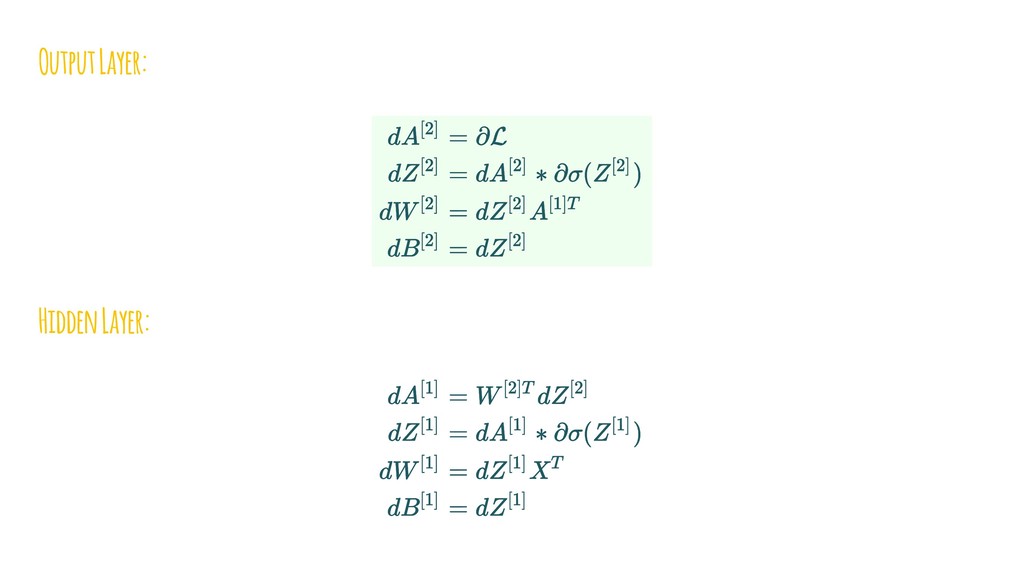{kind=link}
{kind=link}
{kind=link}
{kind=link}
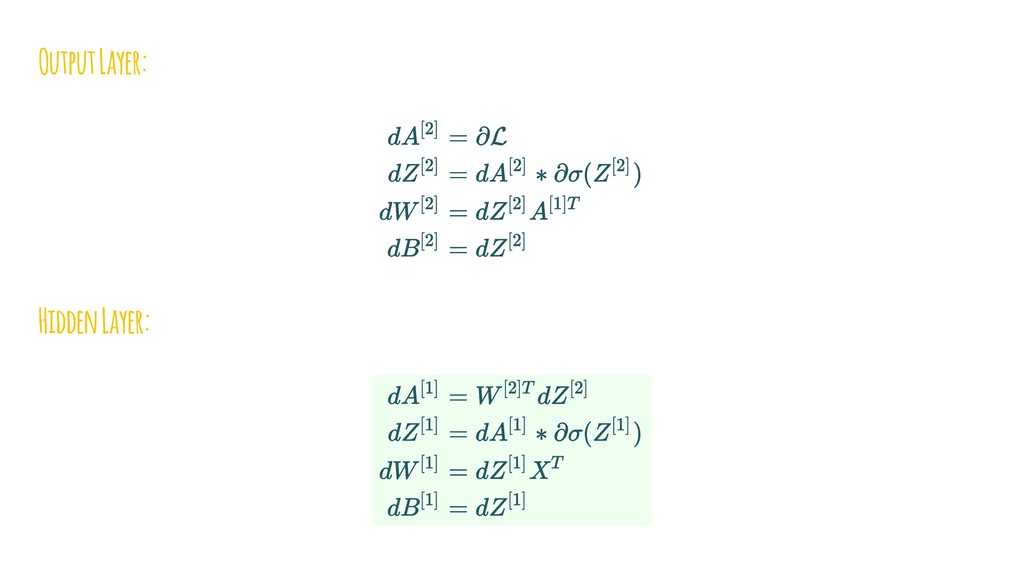{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
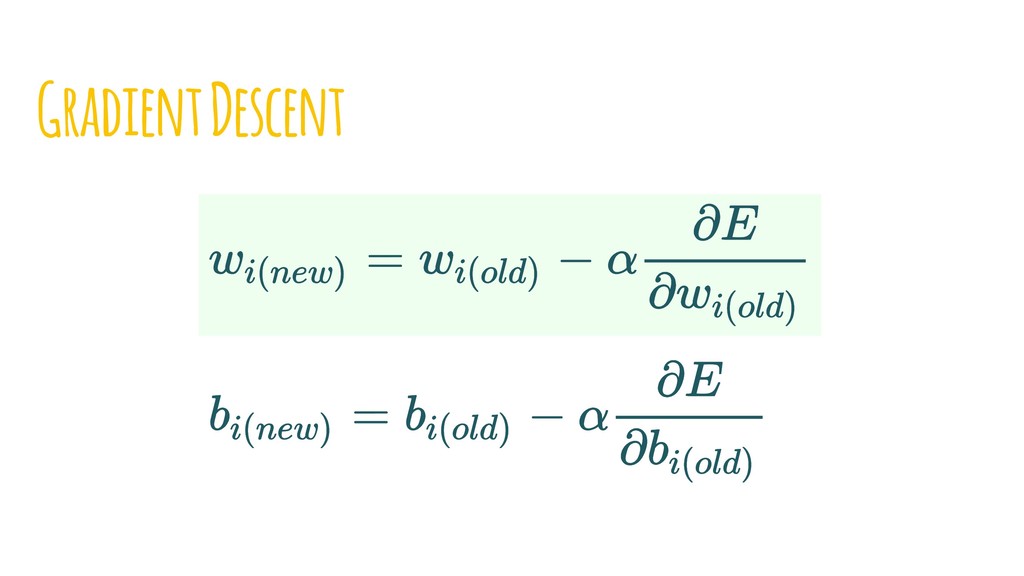{kind=link}
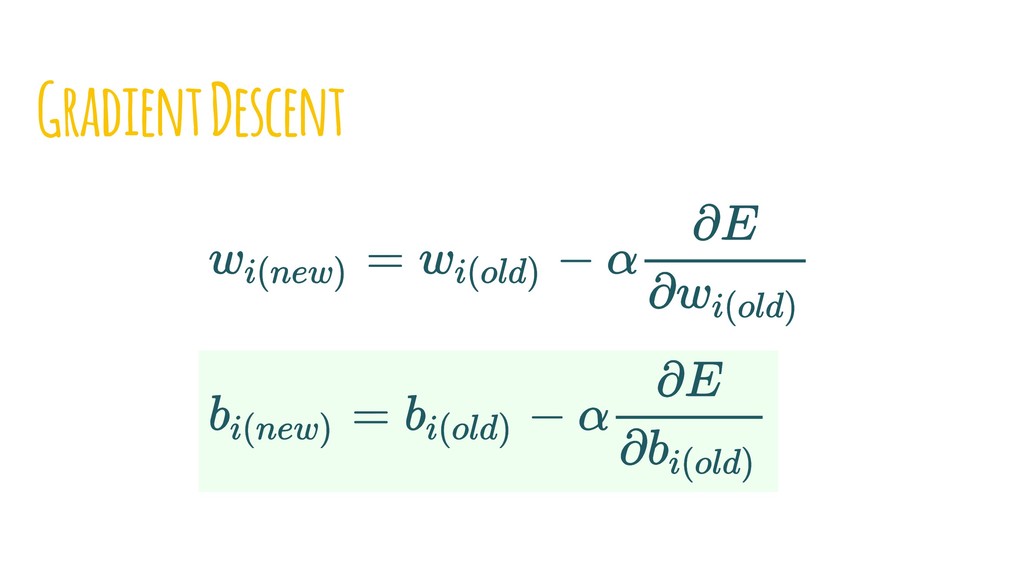{kind=link}
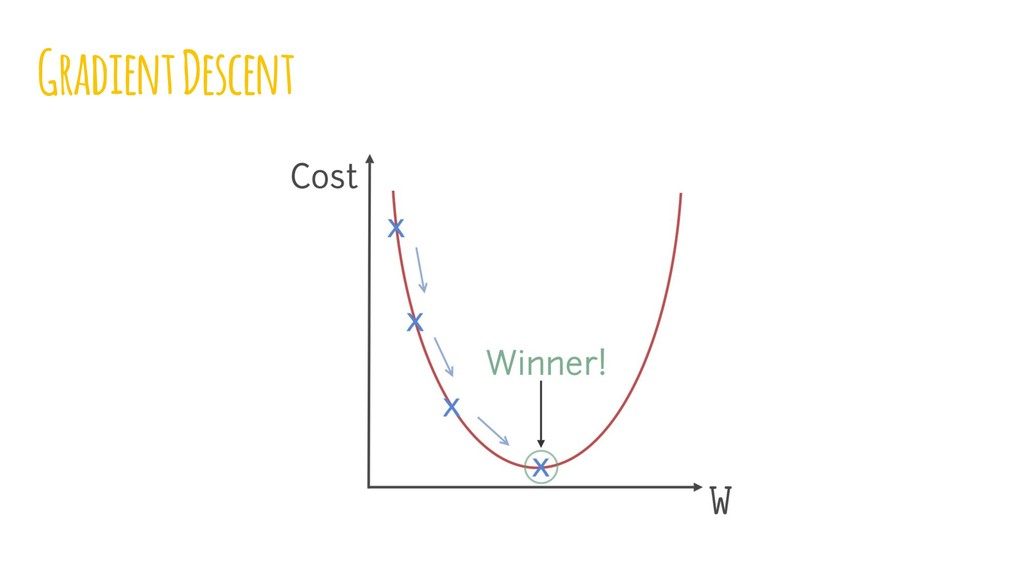{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
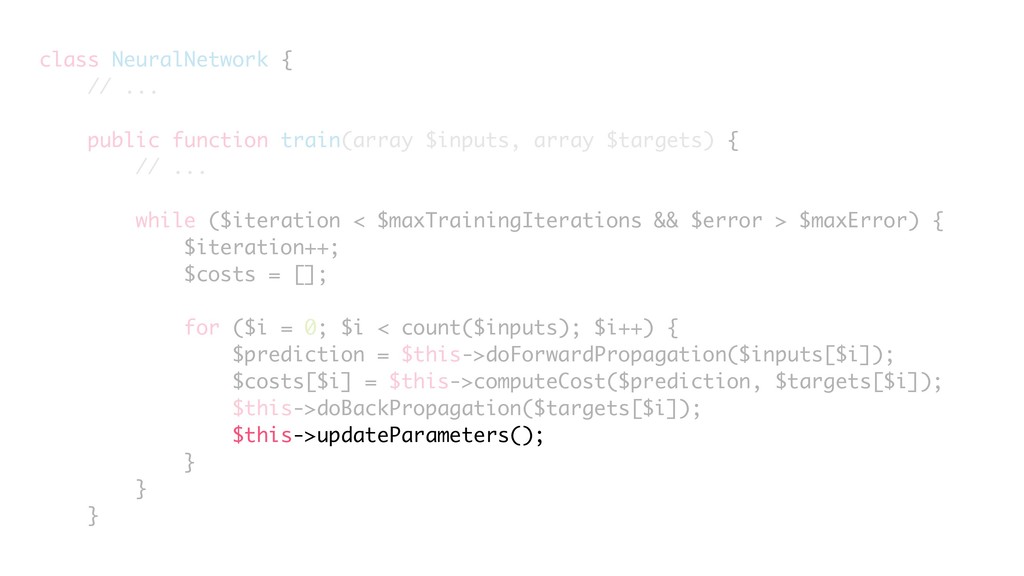{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
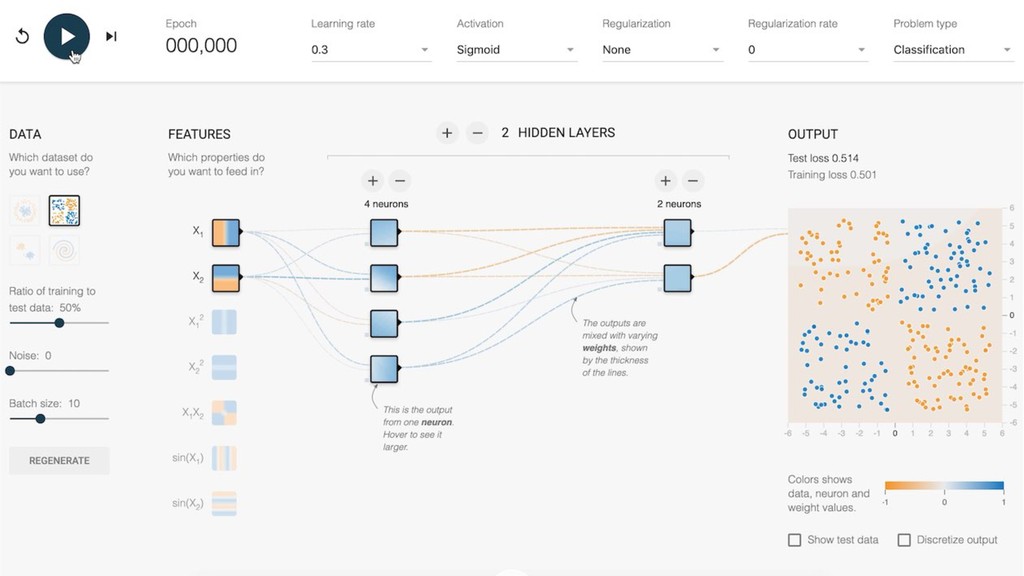{kind=link}
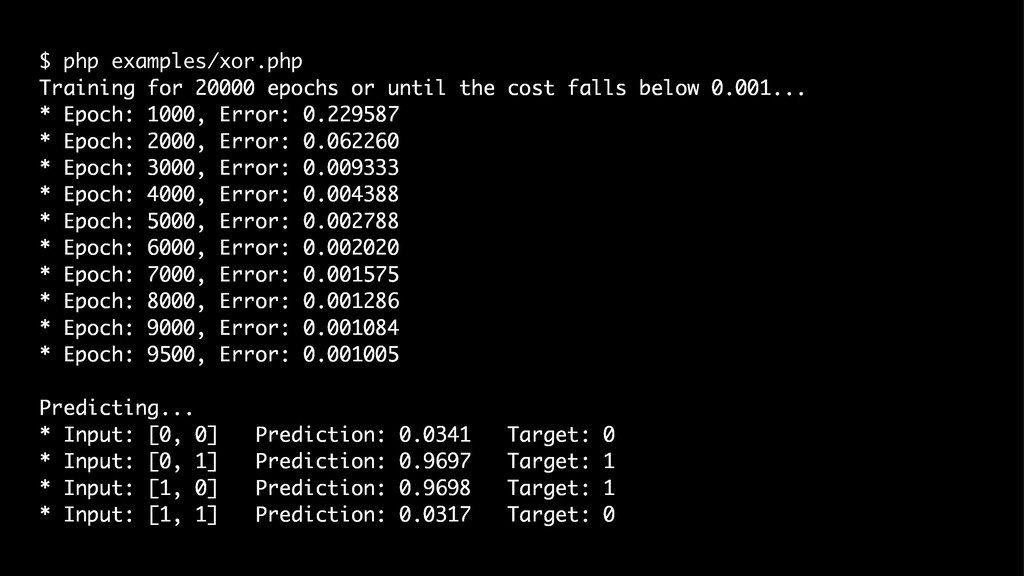{kind=link}
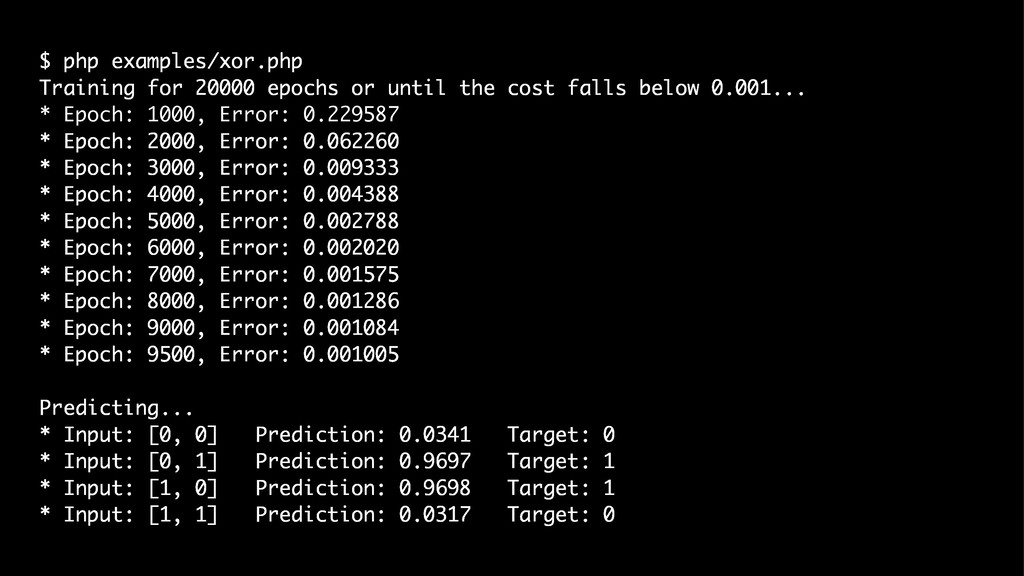{kind=link}
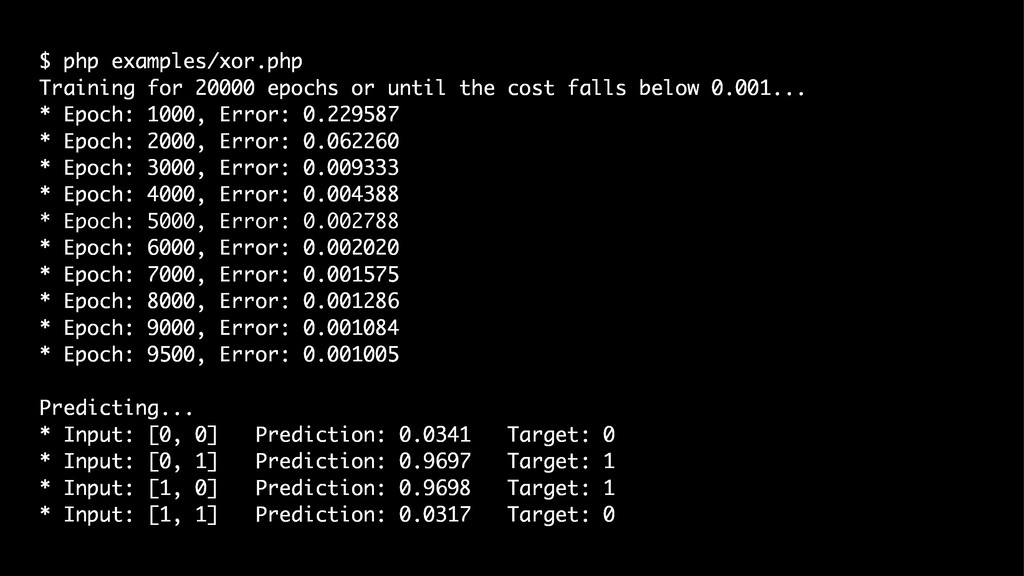{kind=link}
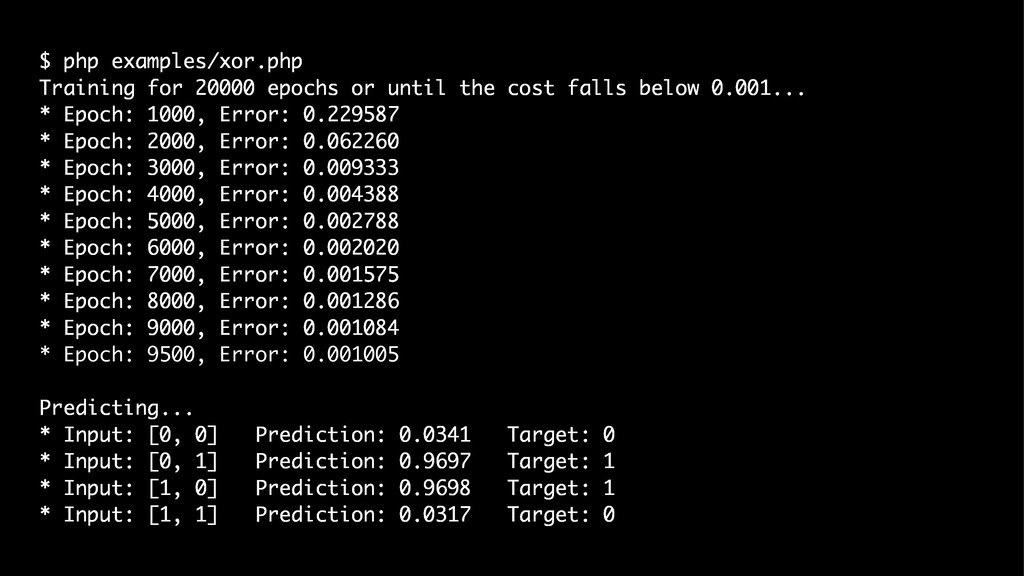{kind=link}
{kind=link}
![// › examples/xor.php $inputs = [ [0, 0], // 0](https://files.speakerdeck.com/presentations/4078addbc1454327a6f14d8e871369e7/slide_179.jpg){kind=link}
{kind=link}
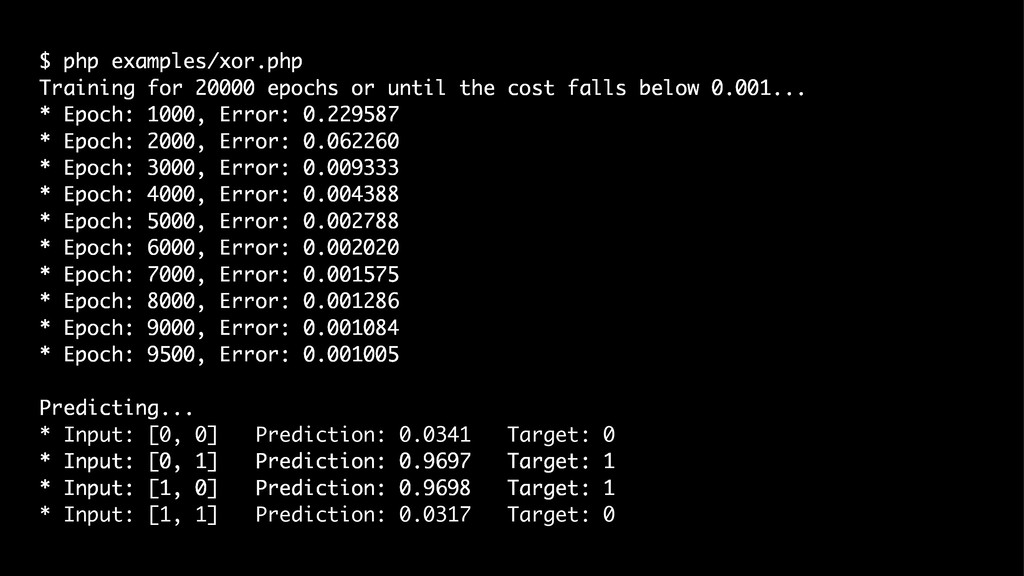{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
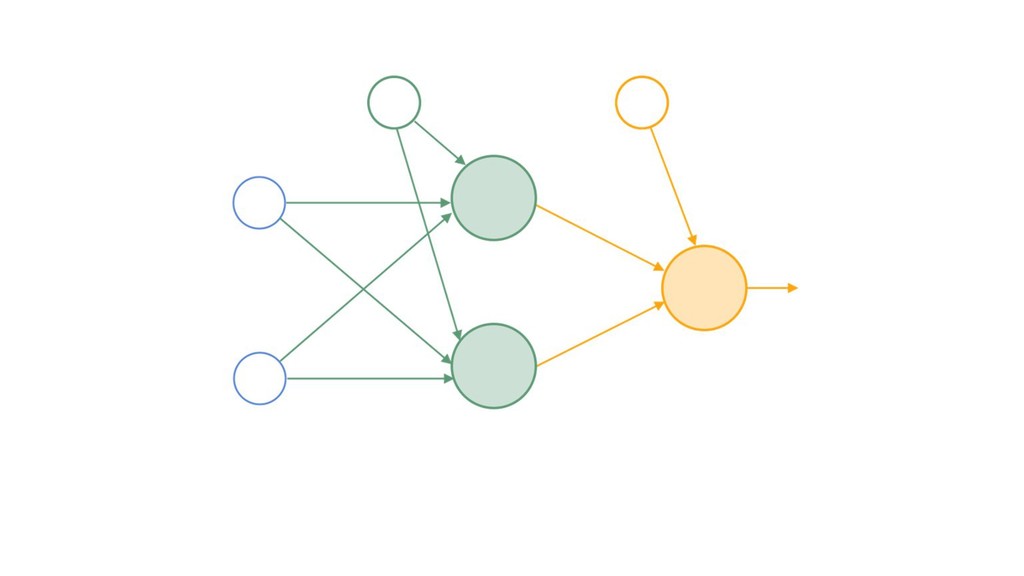{kind=link}
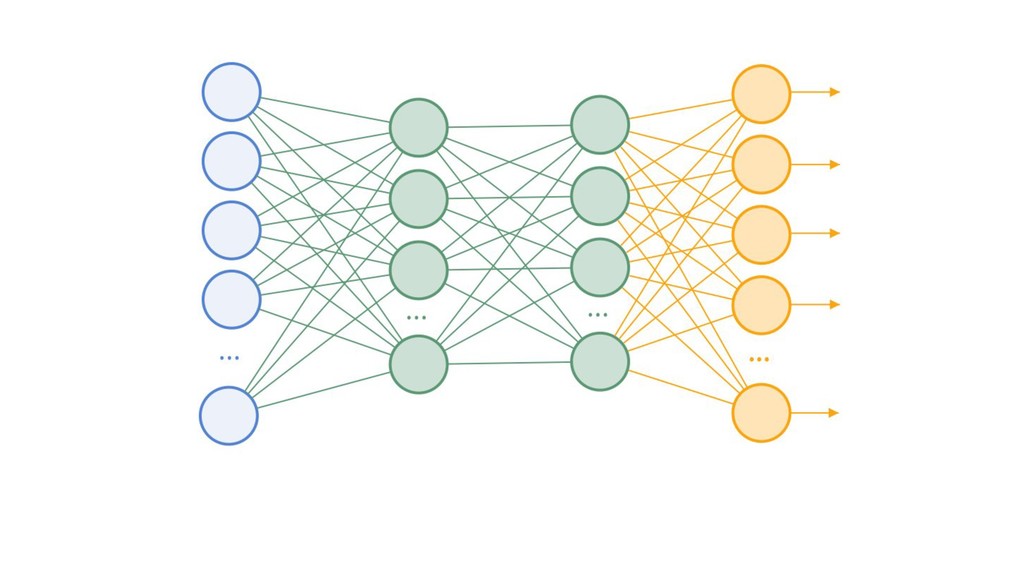{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}