Legg, S., et al.. “Deep Reinforcement Learning from Human Preferences.” Advances in Neural Information Processing Systems, 2017. Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., et al.. “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.” arXiv preprint arXiv:2501.12948, 2025. Kaplan, J., McCandlish, S., Henighan, T., Brown, T., Chess, B., et al.. “Scaling Laws for Neural Language Models.” arXiv preprint arXiv:2001.08361, 2020. [link] Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., et al.. “Self-Refine: Iterative Refinement with Self-Feedback.” 2023. [link] OpenAI. “Introducing OpenAI o1-preview.” OpenAI Blog, 2024. [link] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., et al.. “Training language models to follow instructions with human feedback.” Advances in Neural Information Processing Systems, 2022. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., et al.. “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.” arXiv preprint arXiv:2402.03300, 2024. Sutton, R., and Barto, A.. “Reinforcement Learning: An Introduction.” MIT Press, 2018. [link] VJAI Seminar #2 - 2026 Reasoning Models in Practice 92/93
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
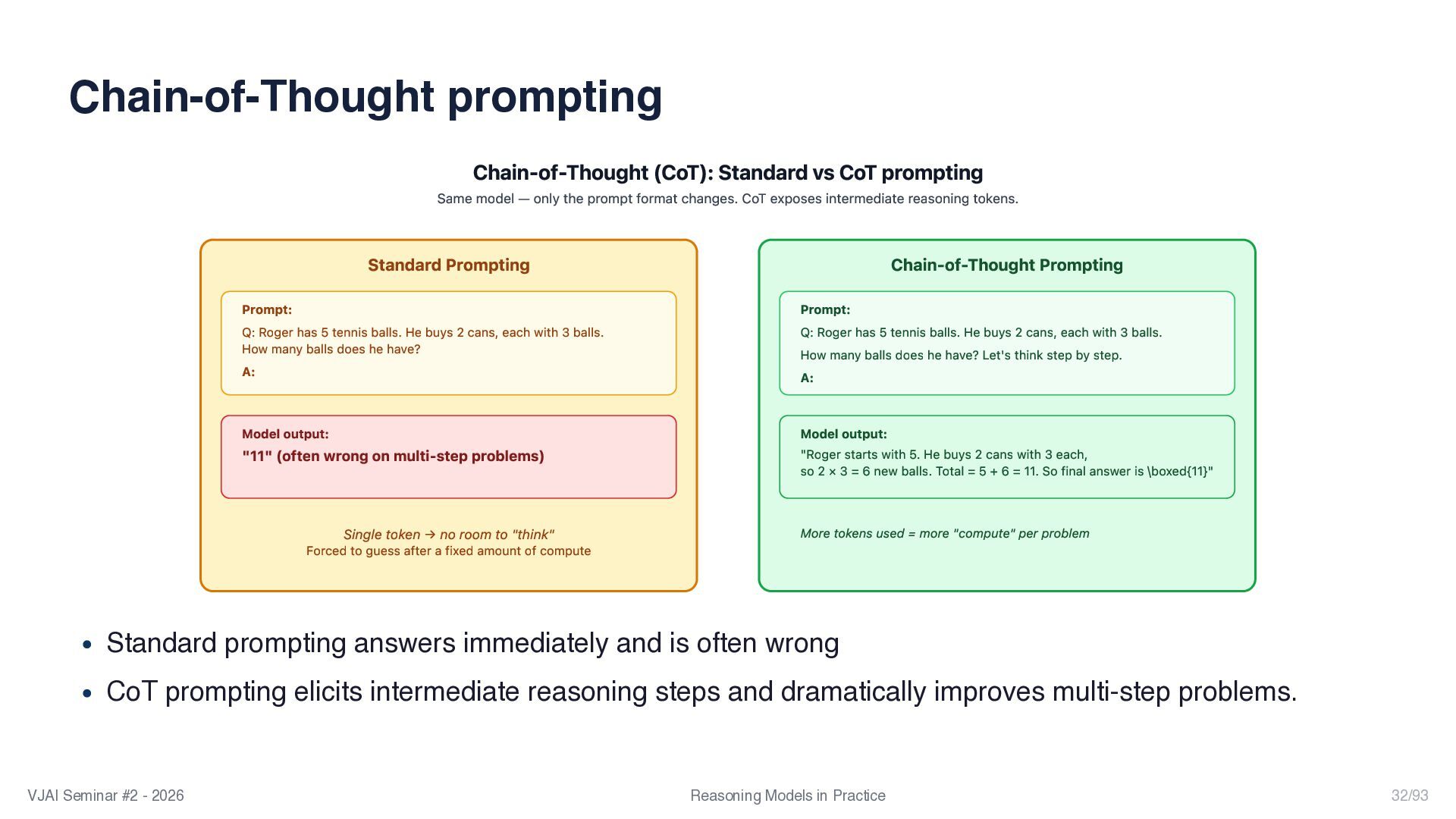{kind=link}
{kind=link}
{kind=link}
{kind=link}
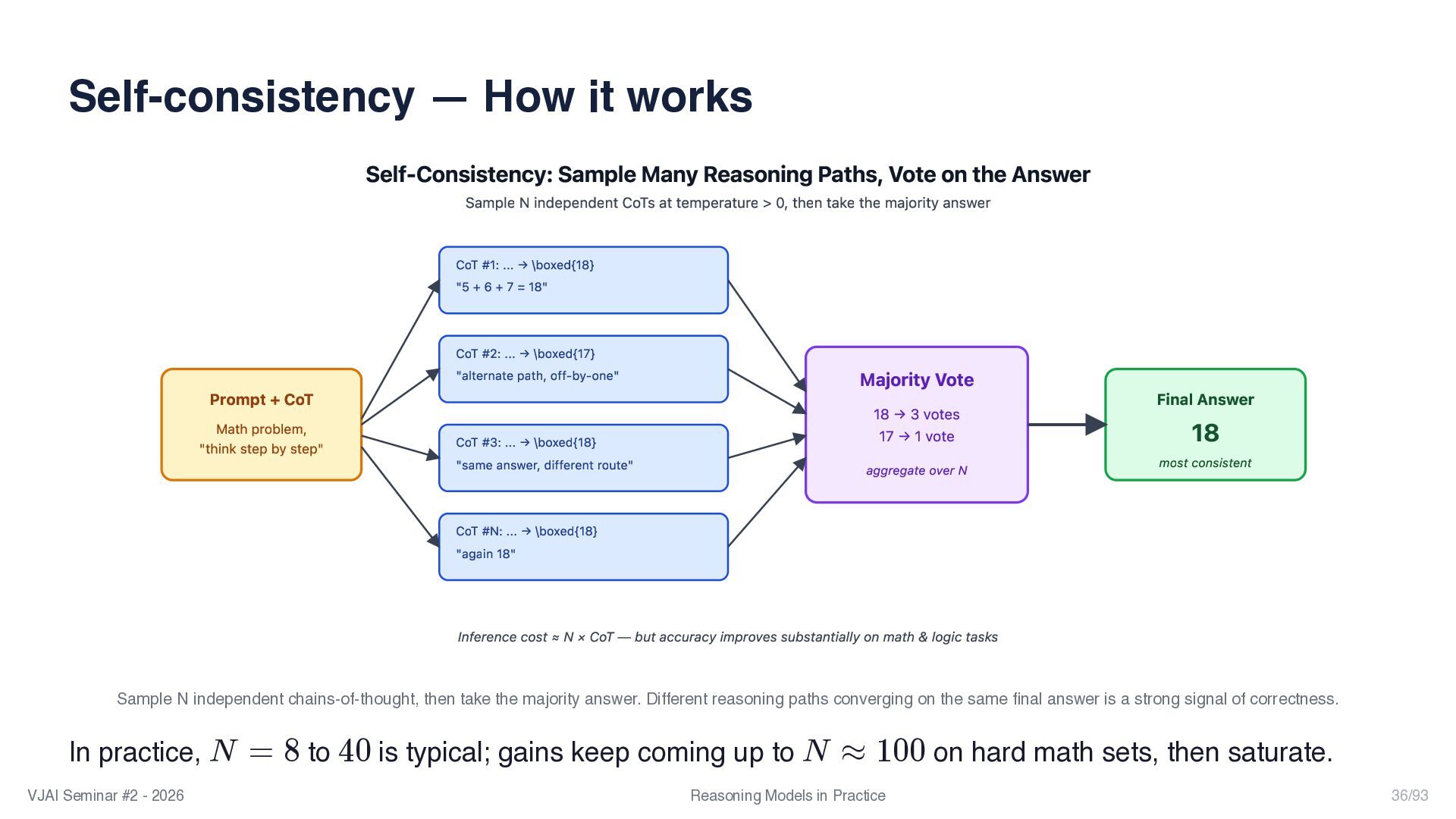{kind=link}
{kind=link}
{kind=link}
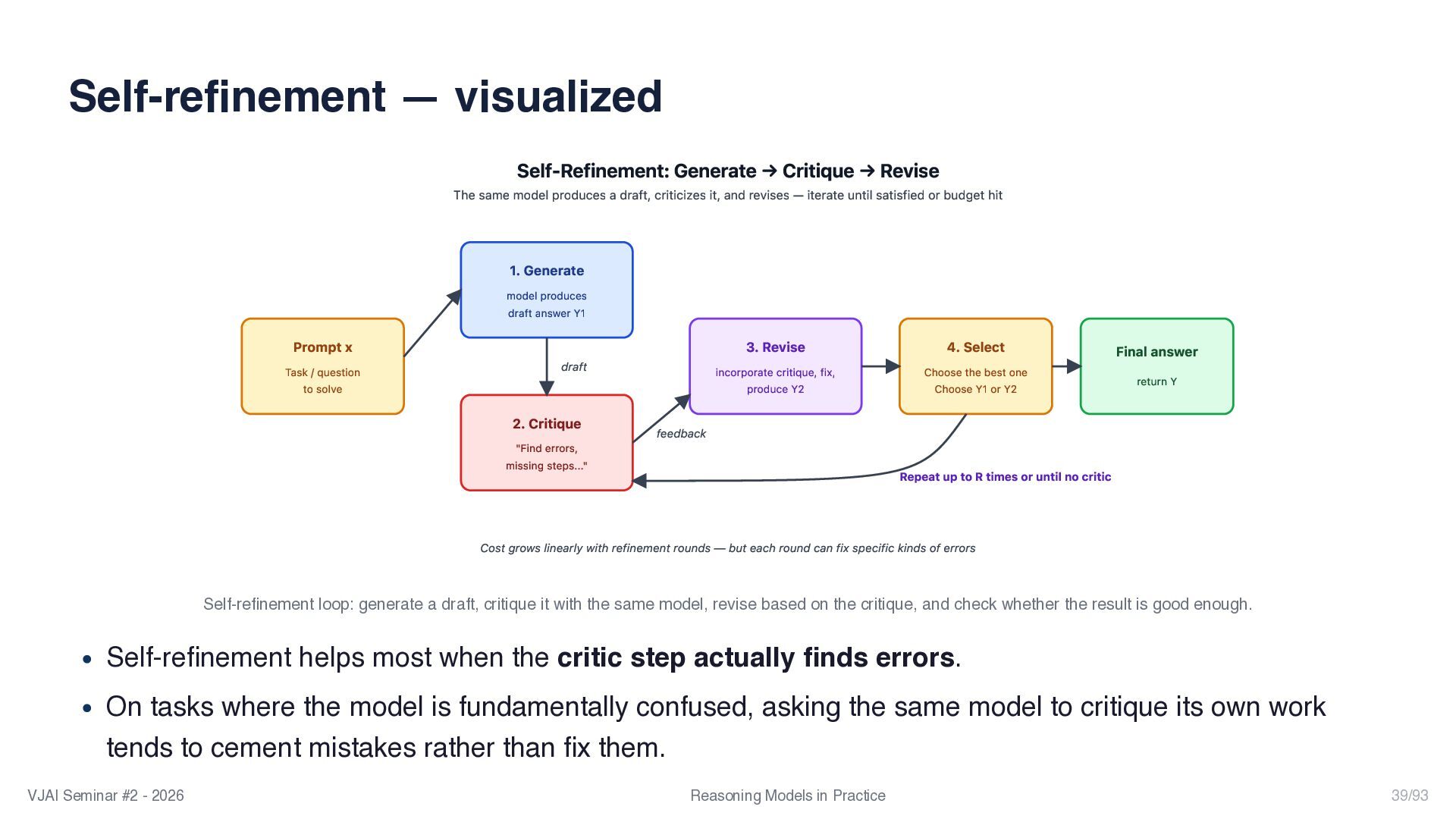{kind=link}
{kind=link}
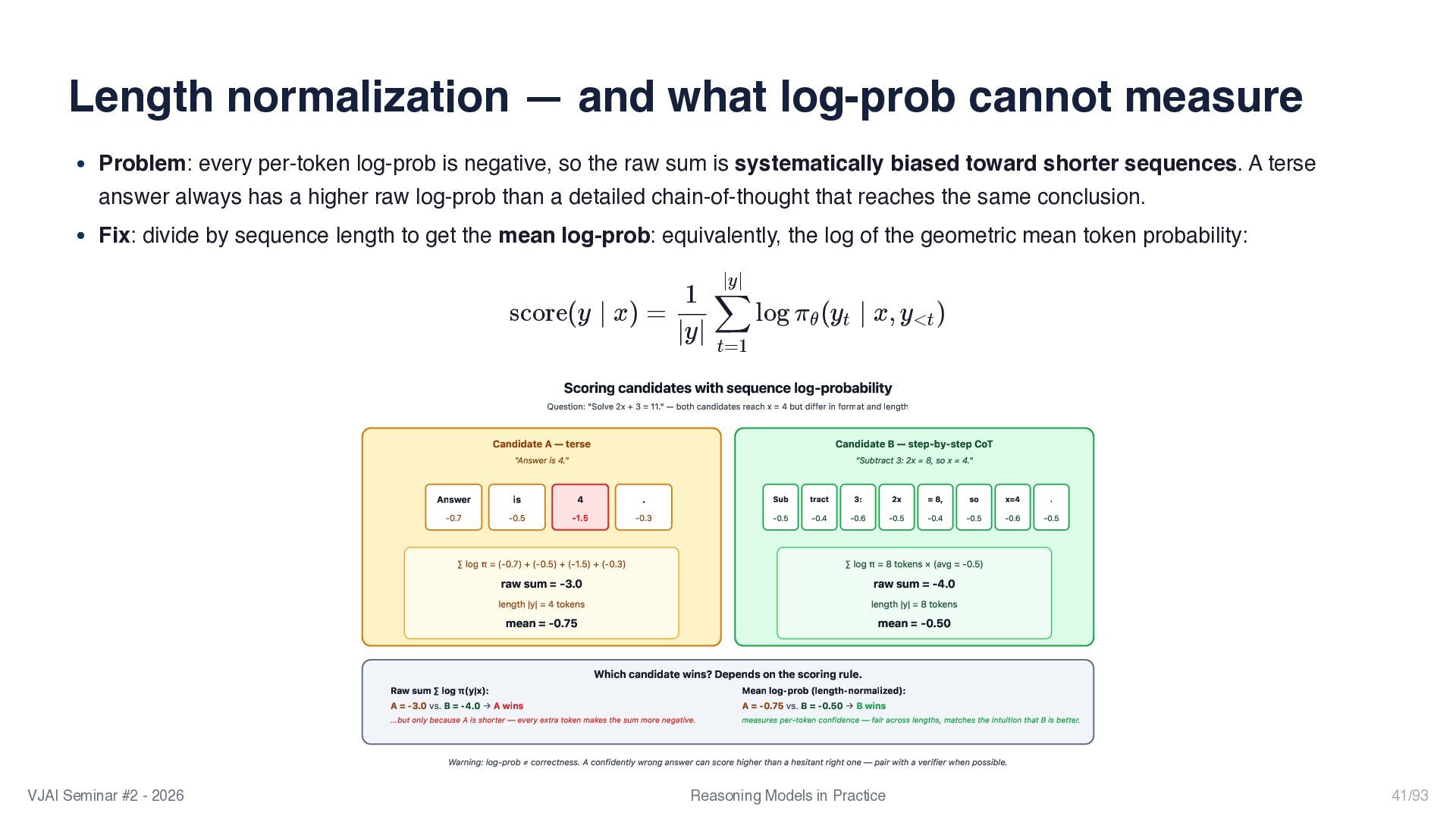{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
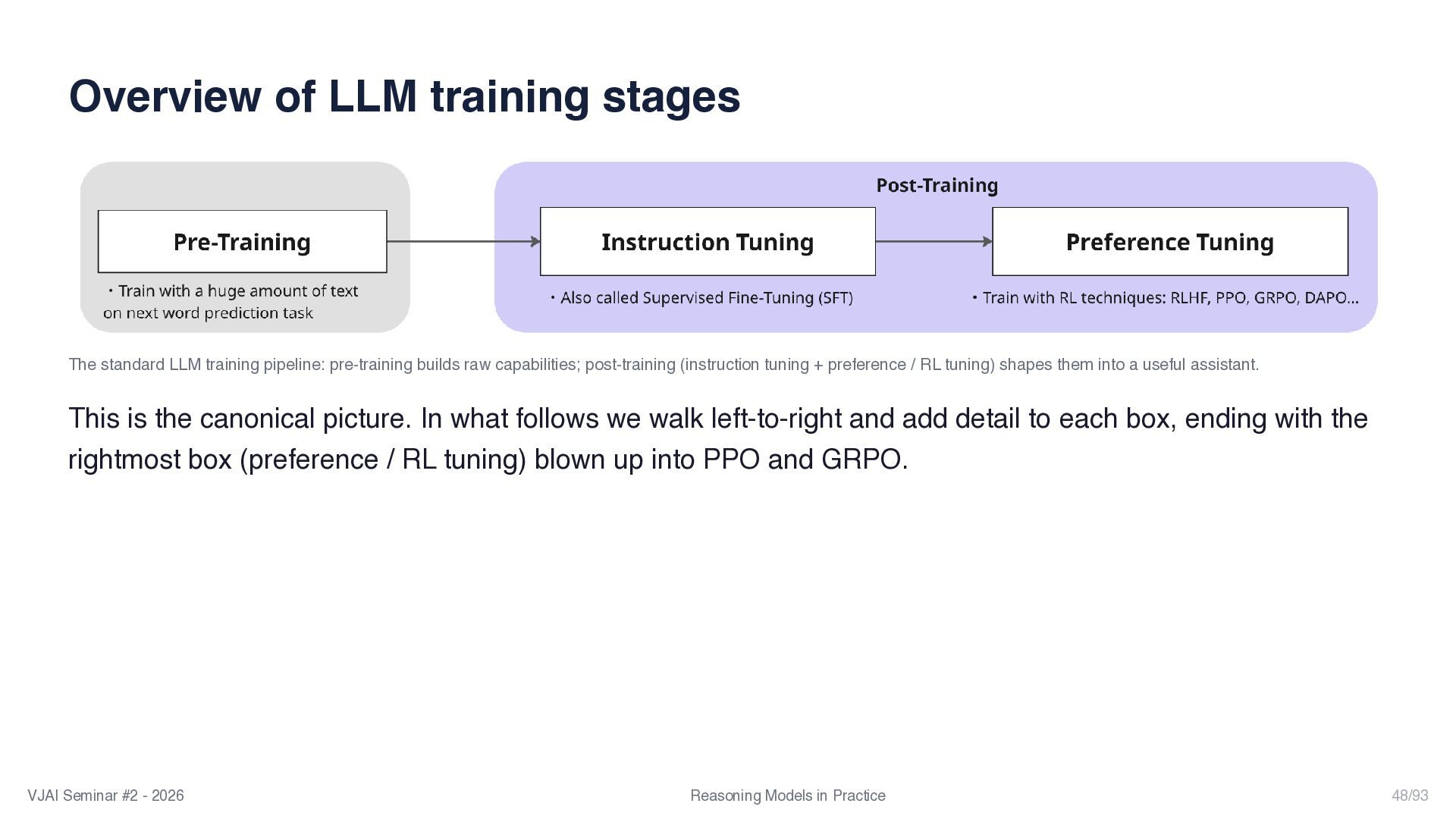{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
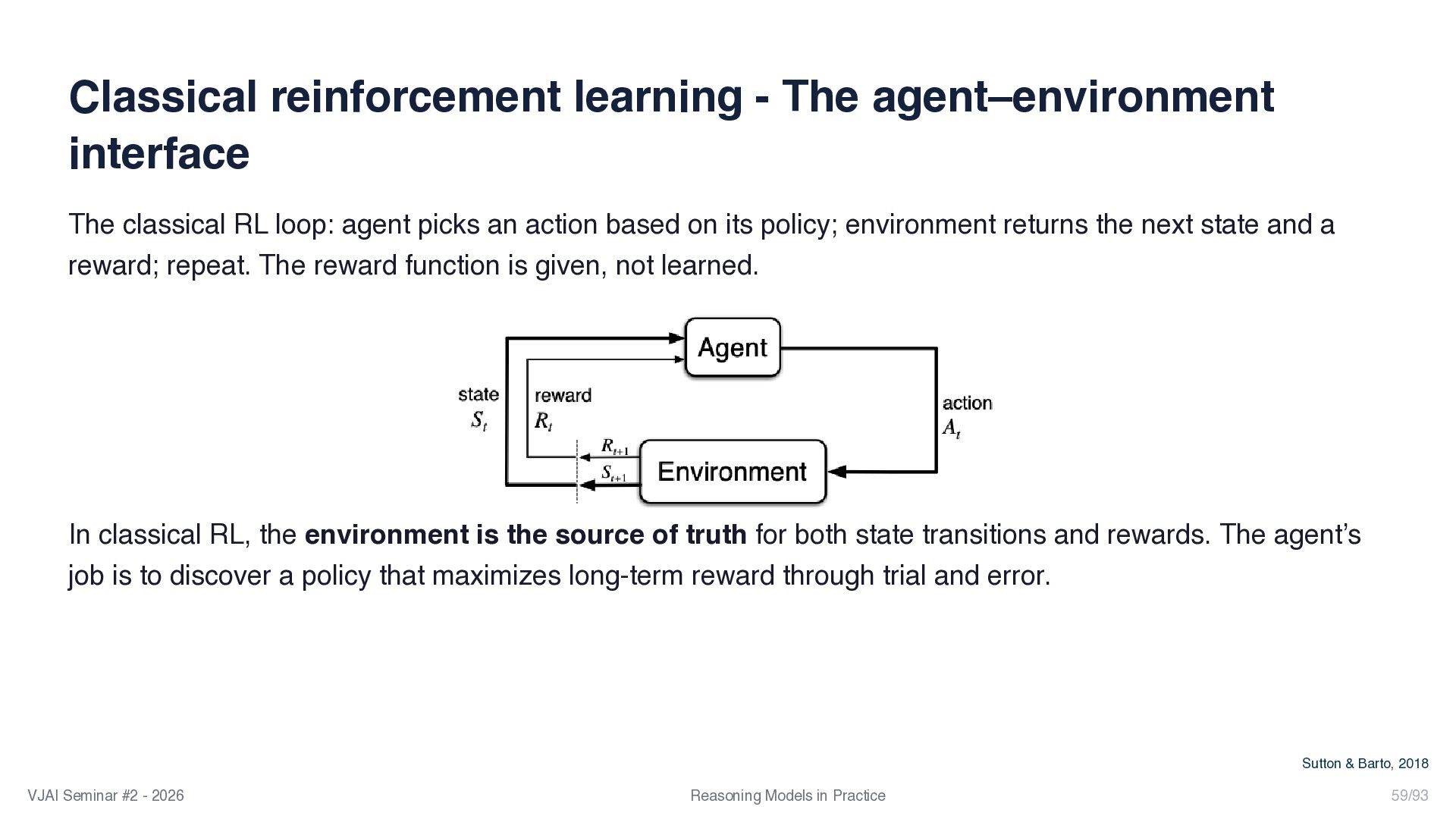{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
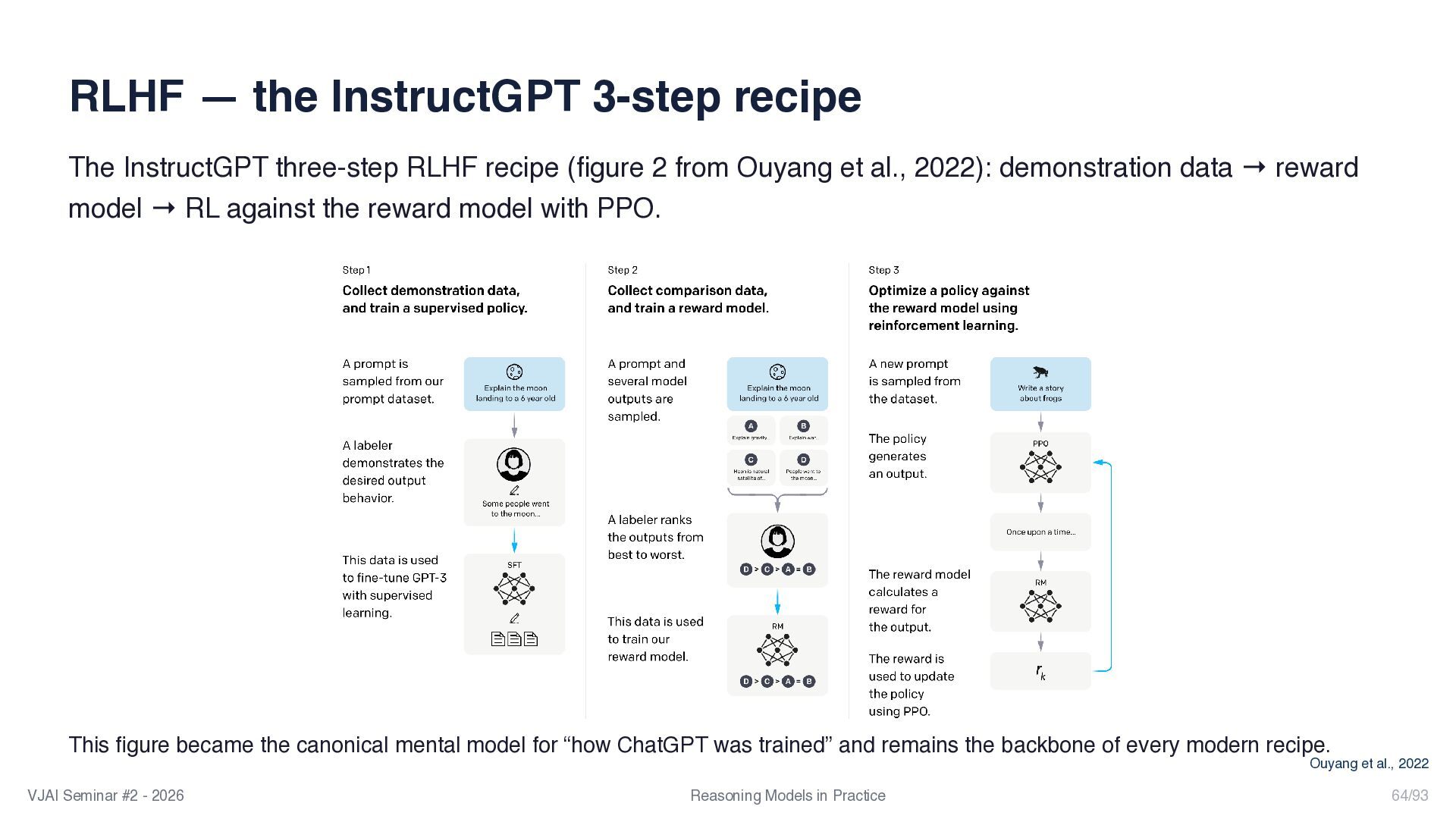{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
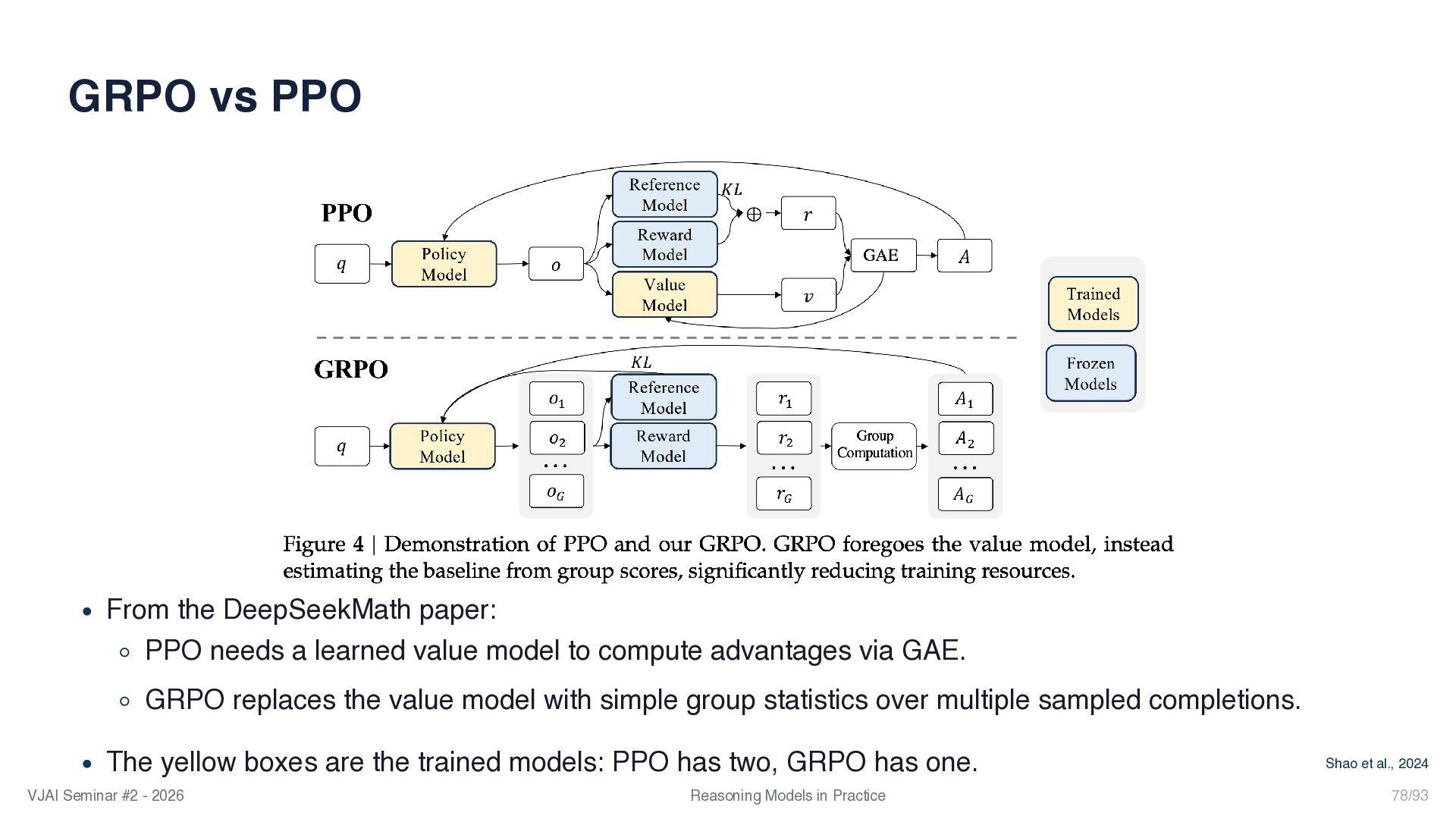{kind=link}
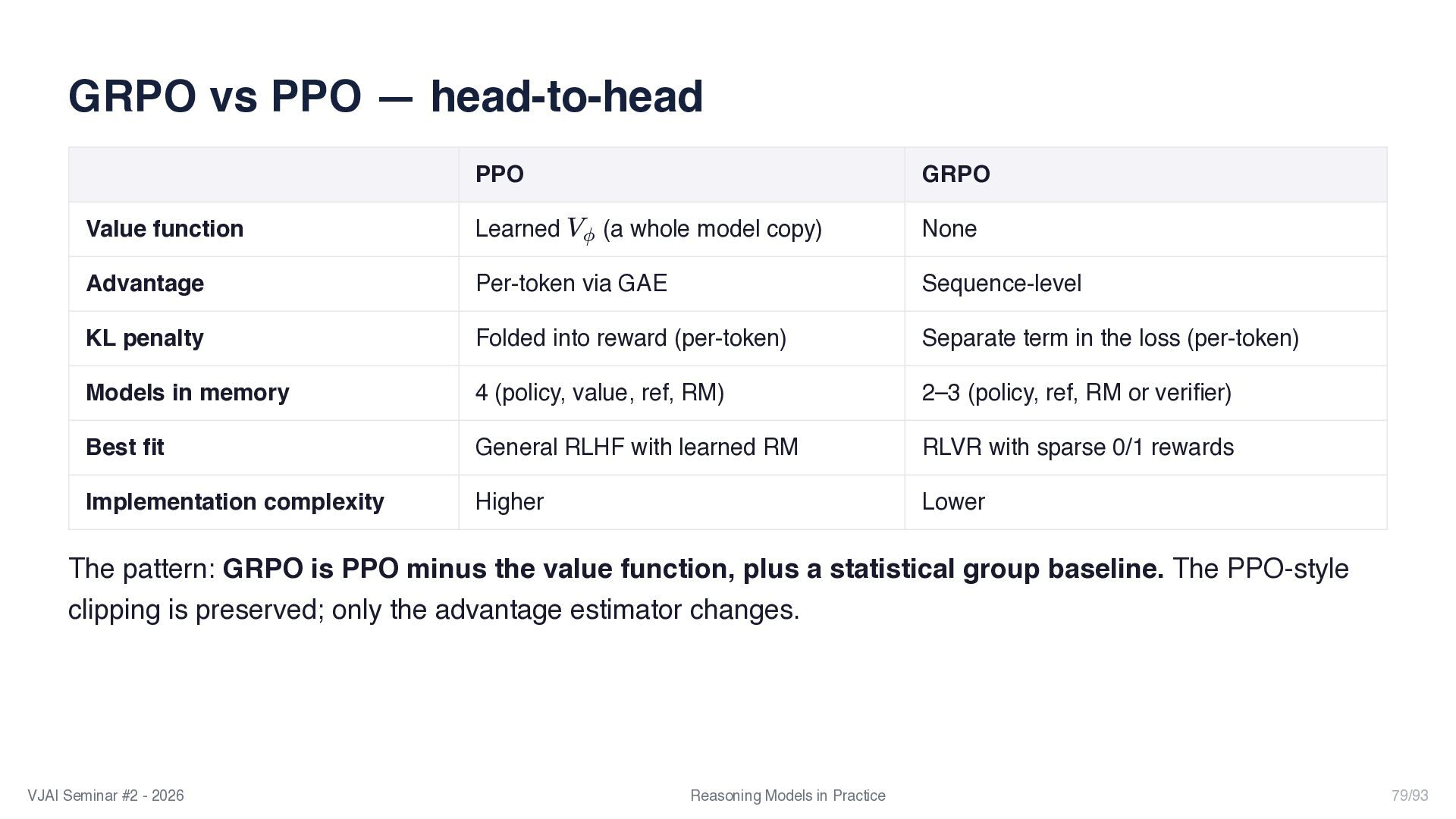{kind=link}
{kind=link}
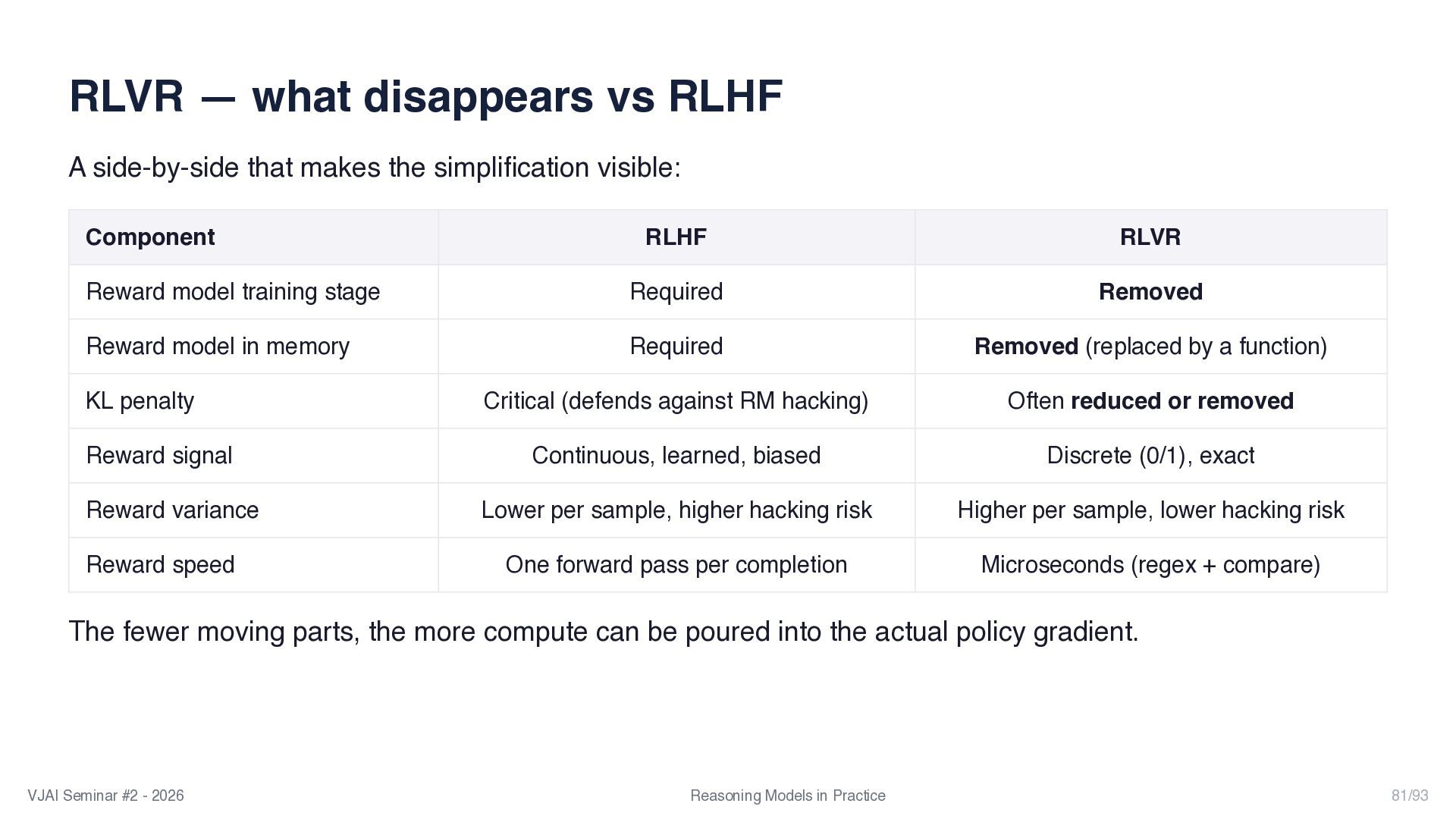{kind=link}
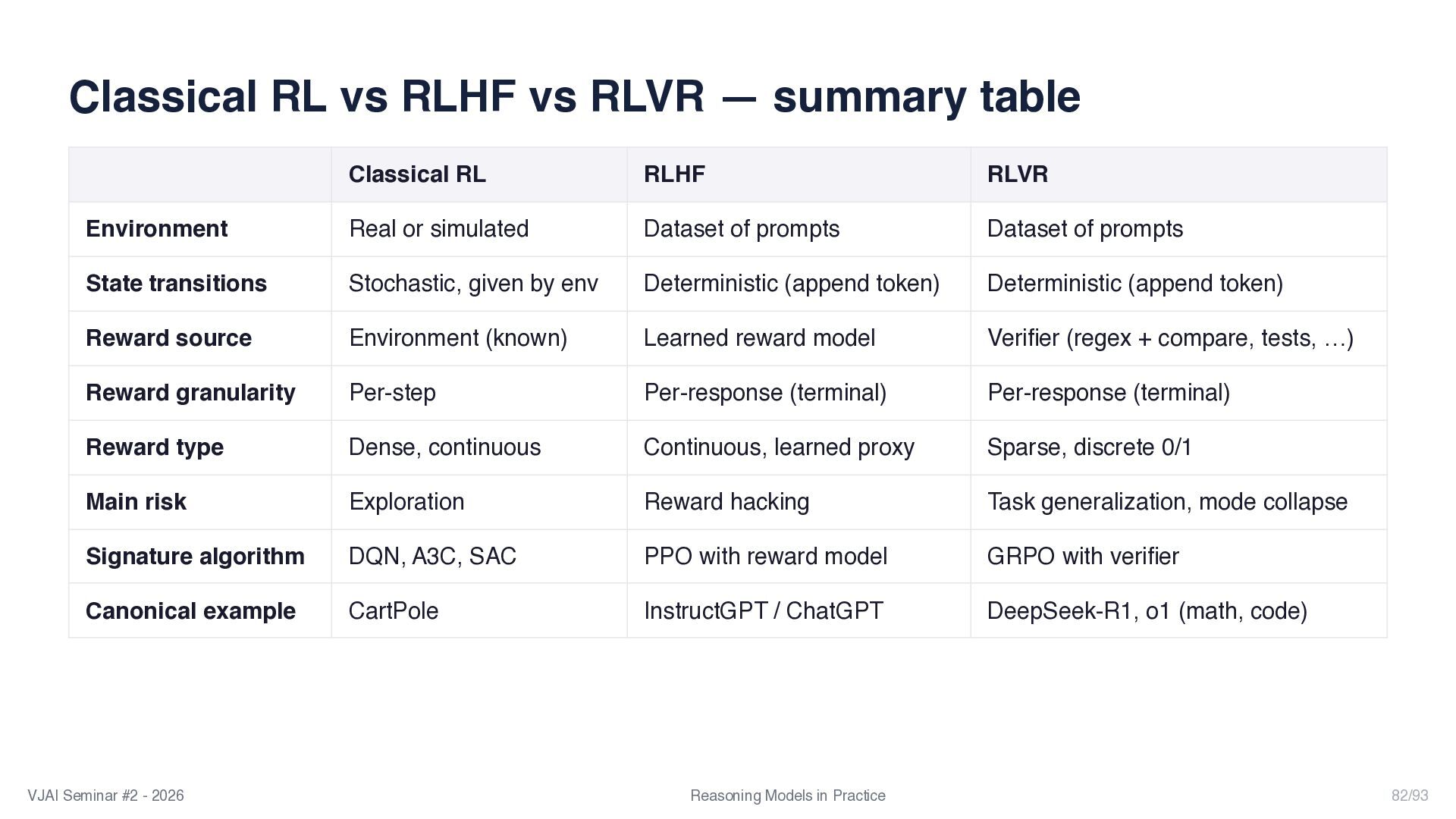{kind=link}
{kind=link}
{kind=link}
{kind=link}
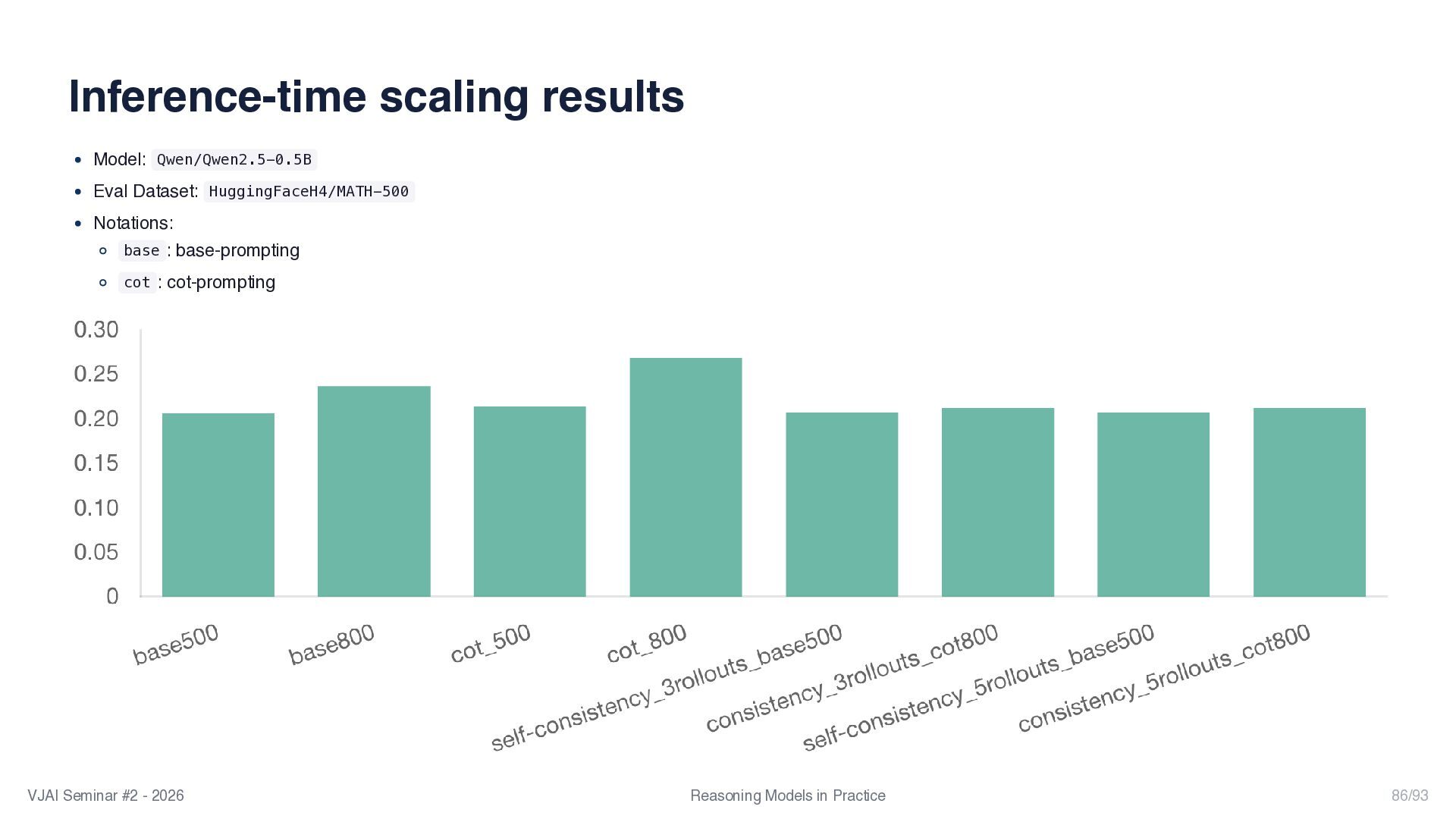{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you Questions / discussion Contact: [email protected] BUILT WITH natolambert/colloquium](https://files.speakerdeck.com/presentations/ae3c65536acd4690a6a3f6d2dbff4e8d/slide_90.jpg){kind=link}
{kind=link}
{kind=link}