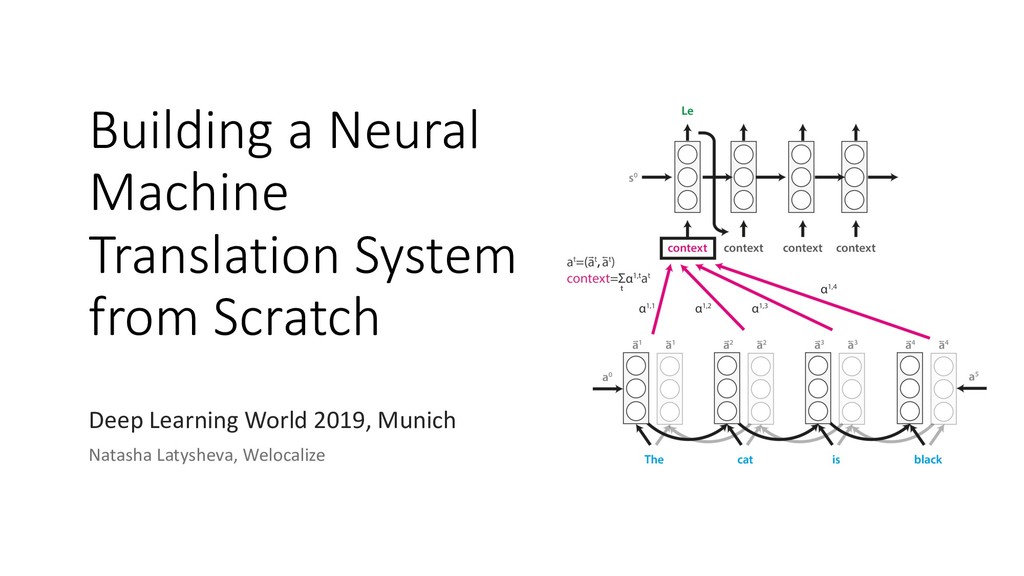
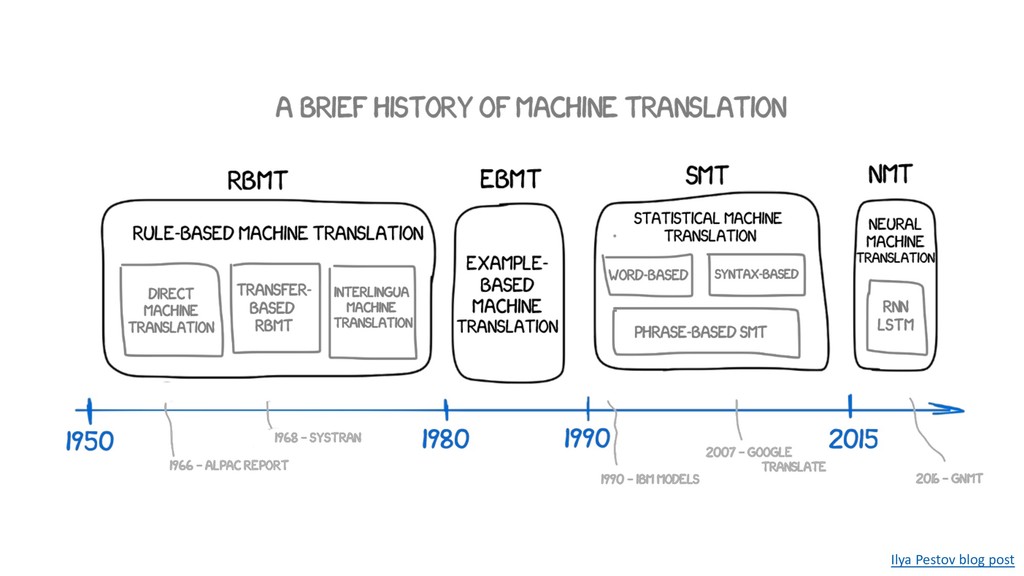
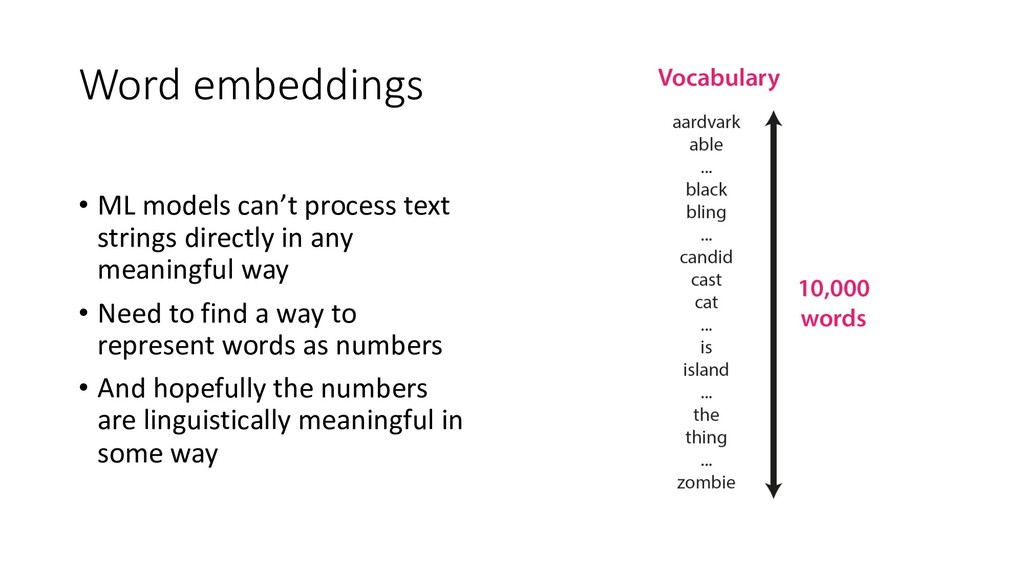
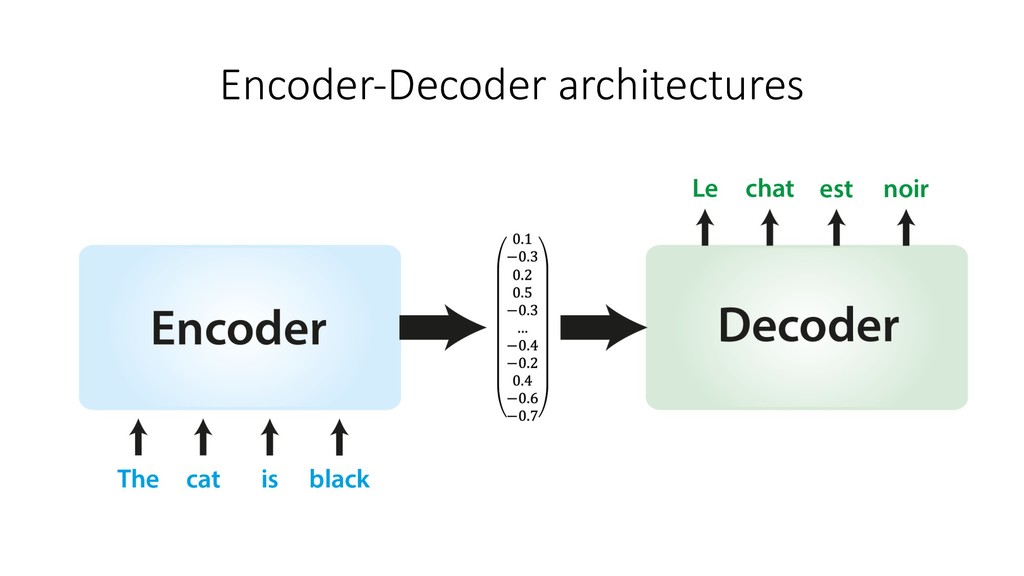
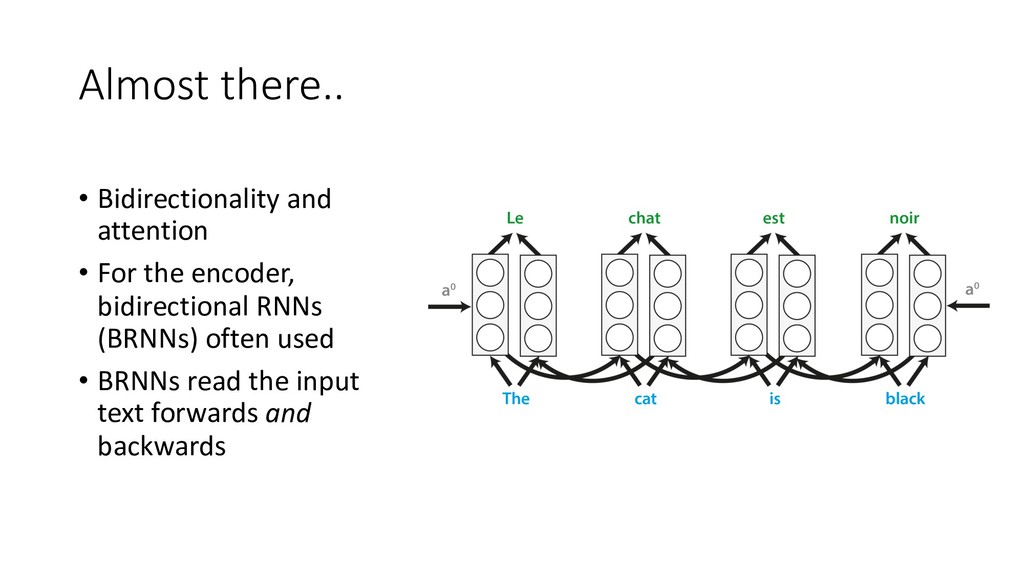
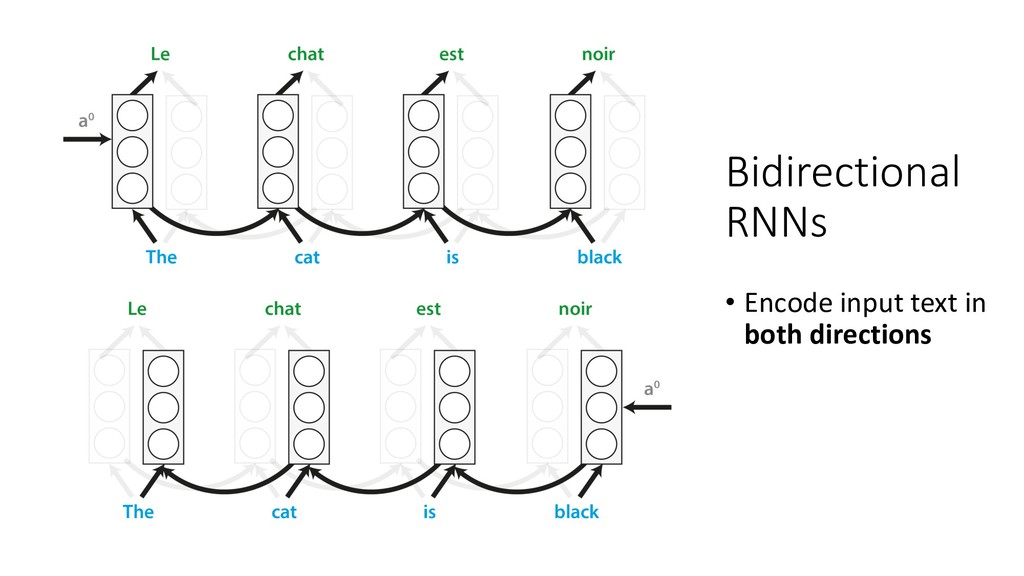
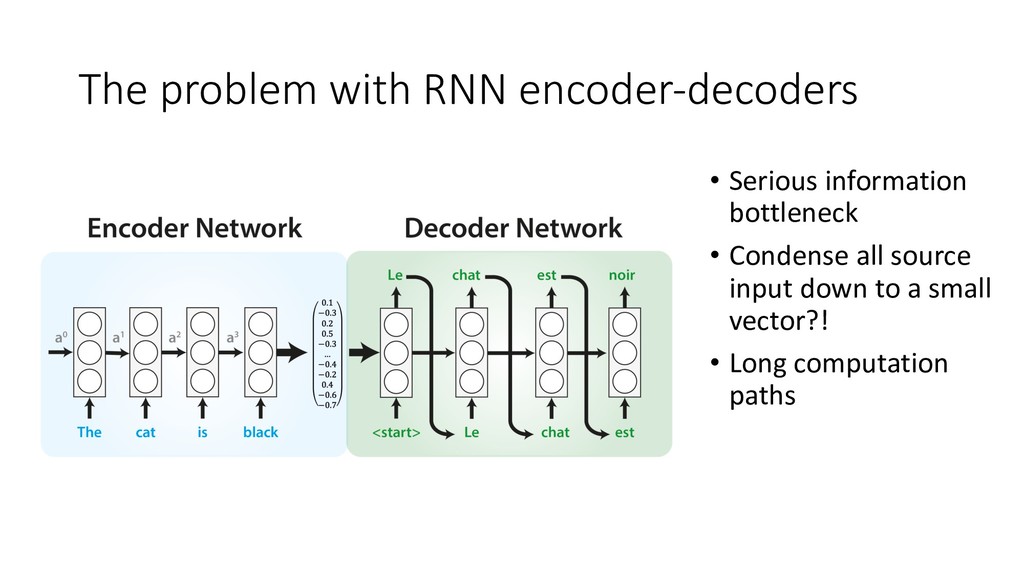
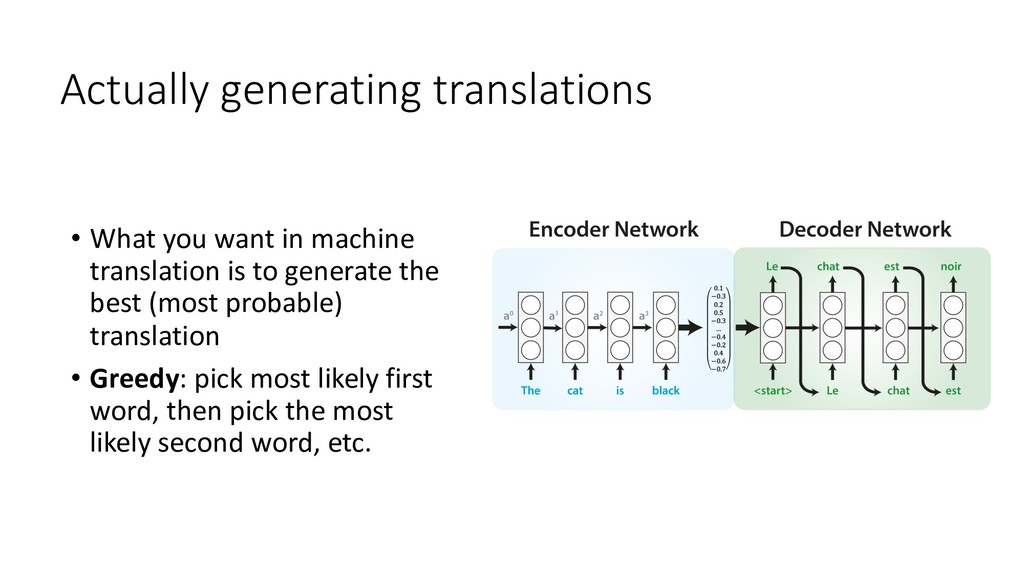
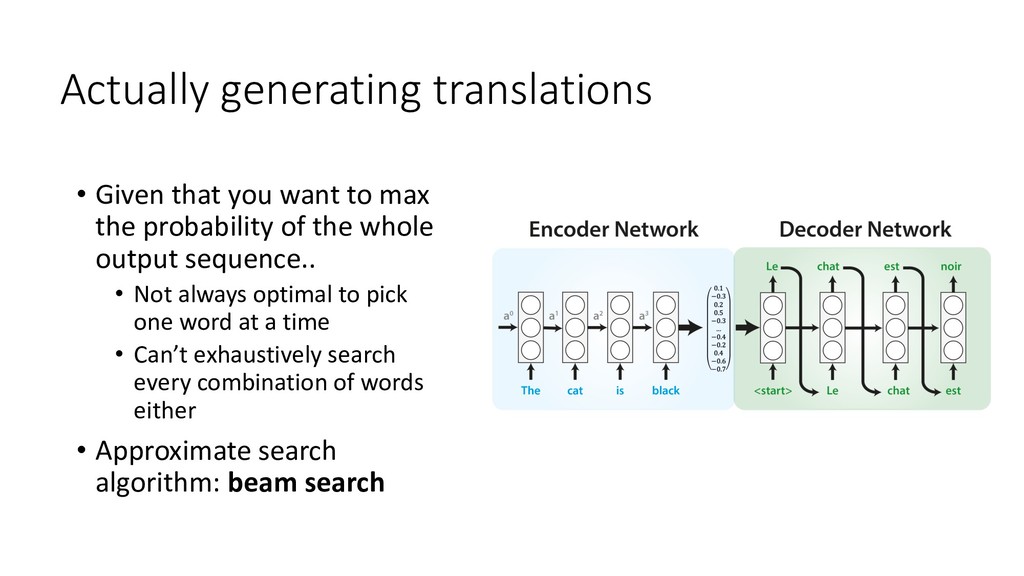
Human languages are complex, diverse and riddled with exceptions – translating between different languages is therefore a highly challenging technical problem. Deep learning approaches have proved powerful in modelling the intricacies of language, and have surpassed all statistics-based methods for automated translation. This session begins with an introduction to the problem of machine translation and discusses the two dominant neural architectures for solving it – recurrent neural networks and transformers. A practical overview of the workflow involved in training, optimising and adapting a competitive neural machine translation system is provided. Attendees will gain an understanding of the internal workings and capabilities of state-of-the-art systems for automatic translation, as well as an appreciation of the key challenges and open problems in the field.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}