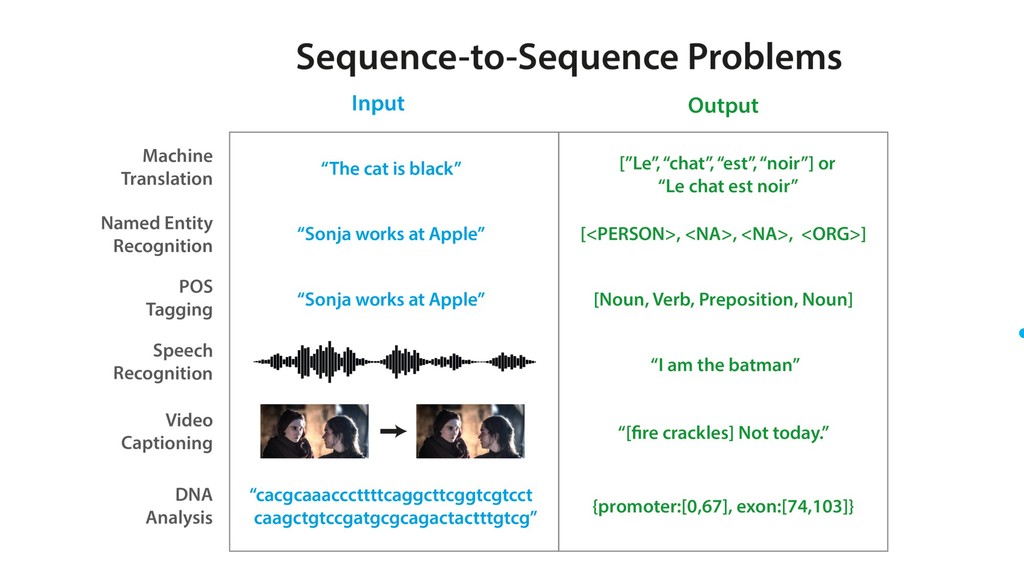
Much of data is sequential – think speech, text, DNA, stock prices, financial transactions and customer action histories. Modern methods for modelling sequence data are often deep learning-based, composed of either recurrent neural networks (RNNs) or attention-based Transformers. A tremendous amount of research progress has recently been made in sequence modelling, particularly in the application to NLP problems. However, the inner workings of these sequence models can be difficult to dissect and intuitively understand.
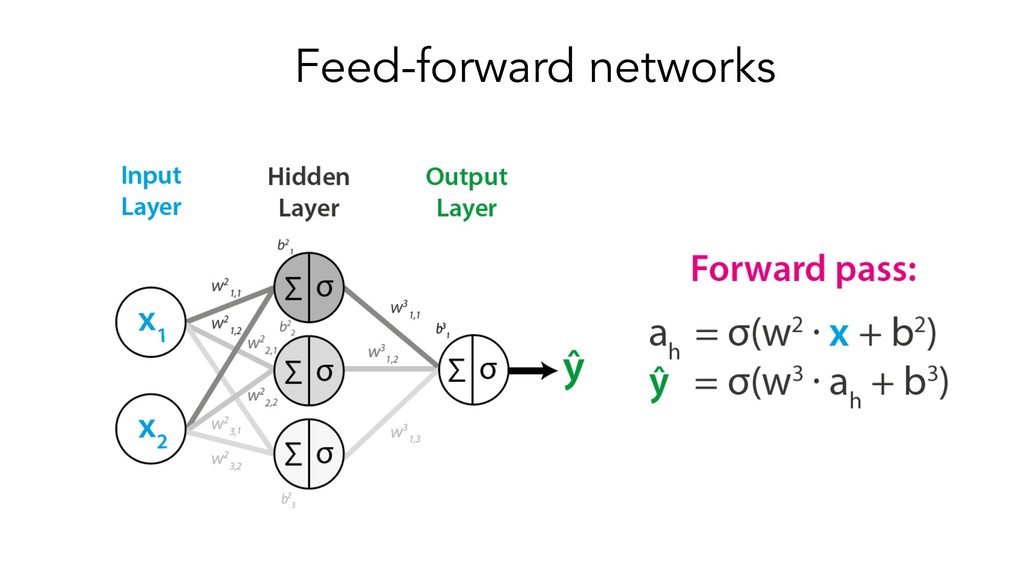
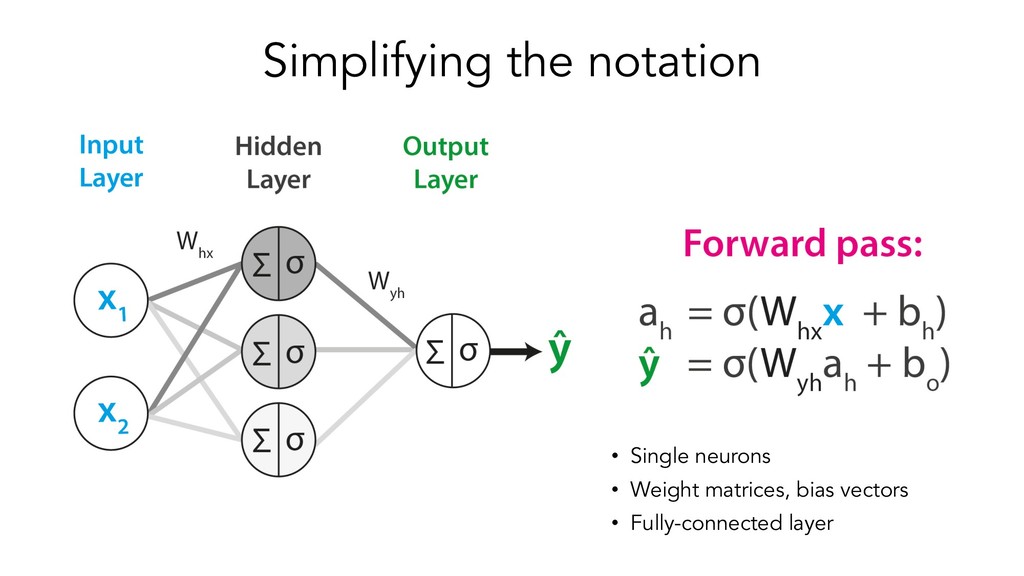
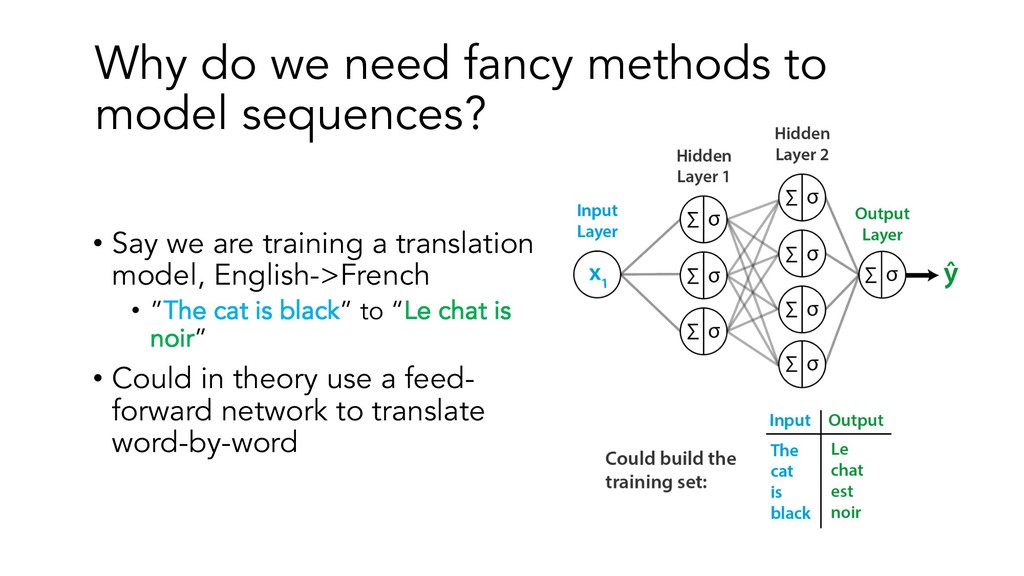
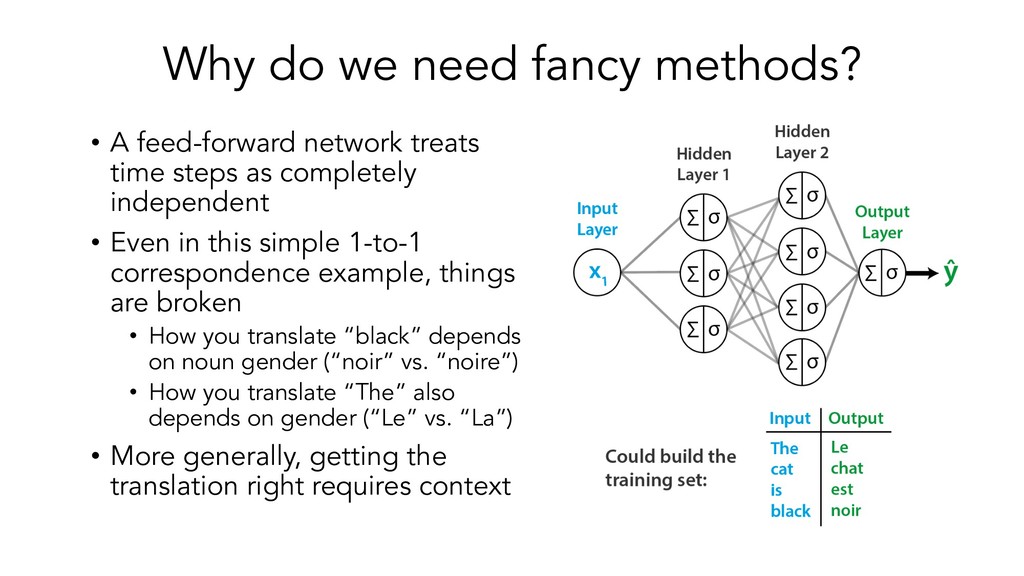
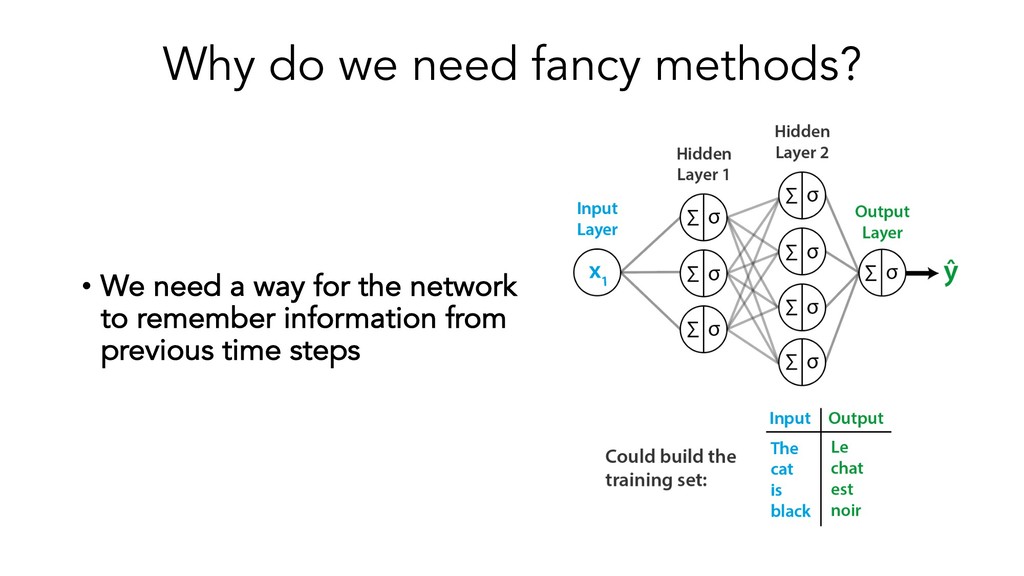
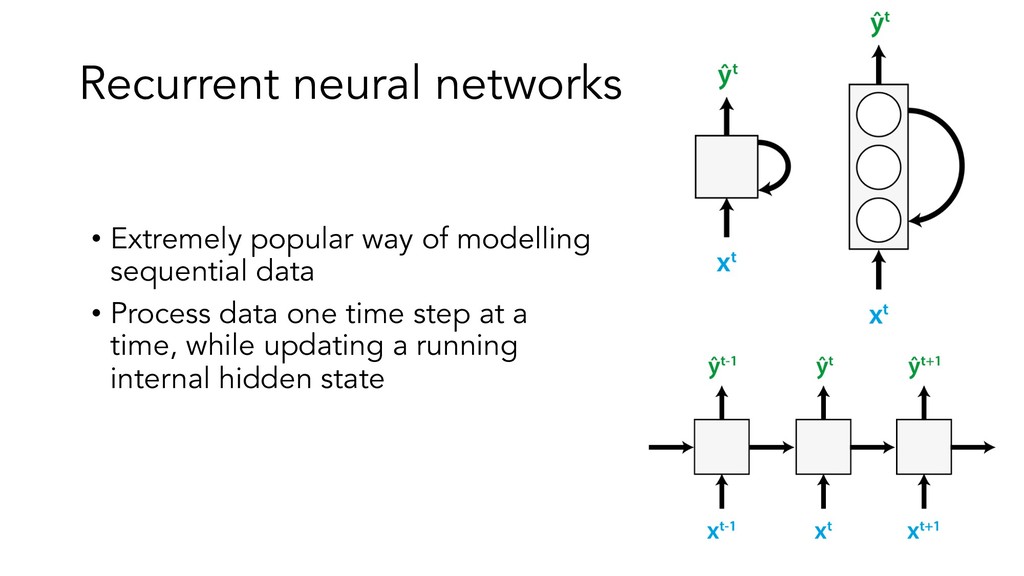
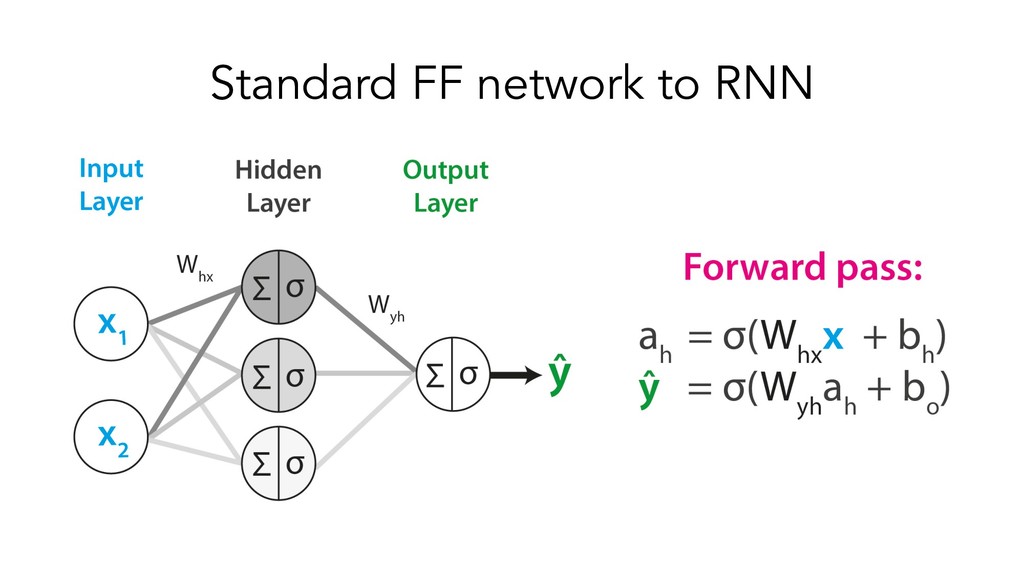
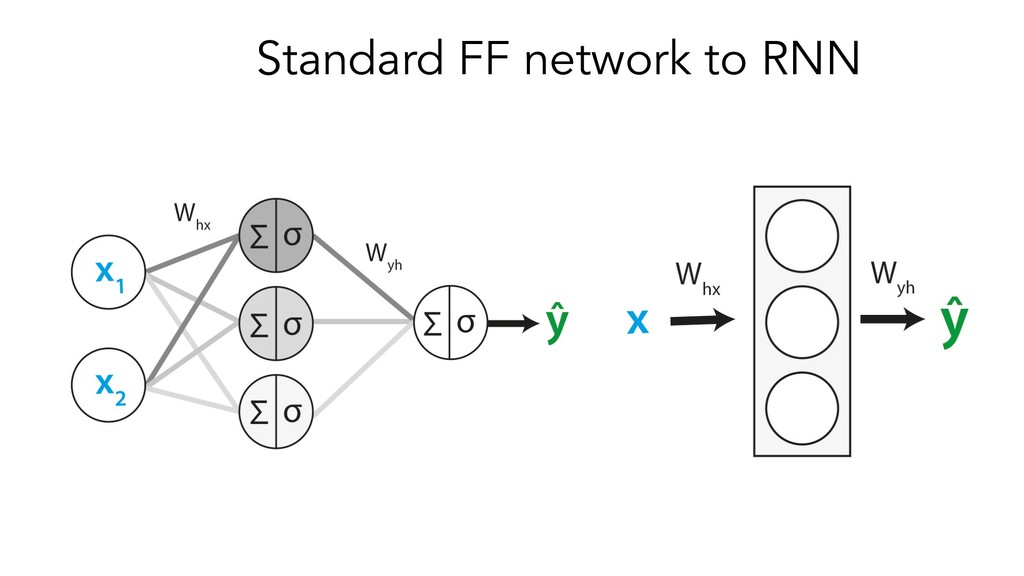
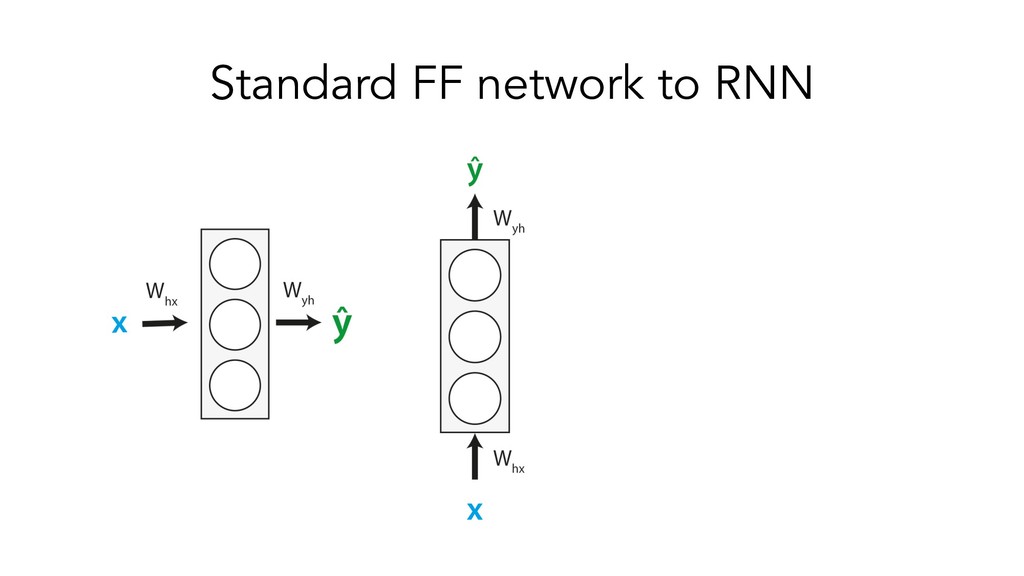
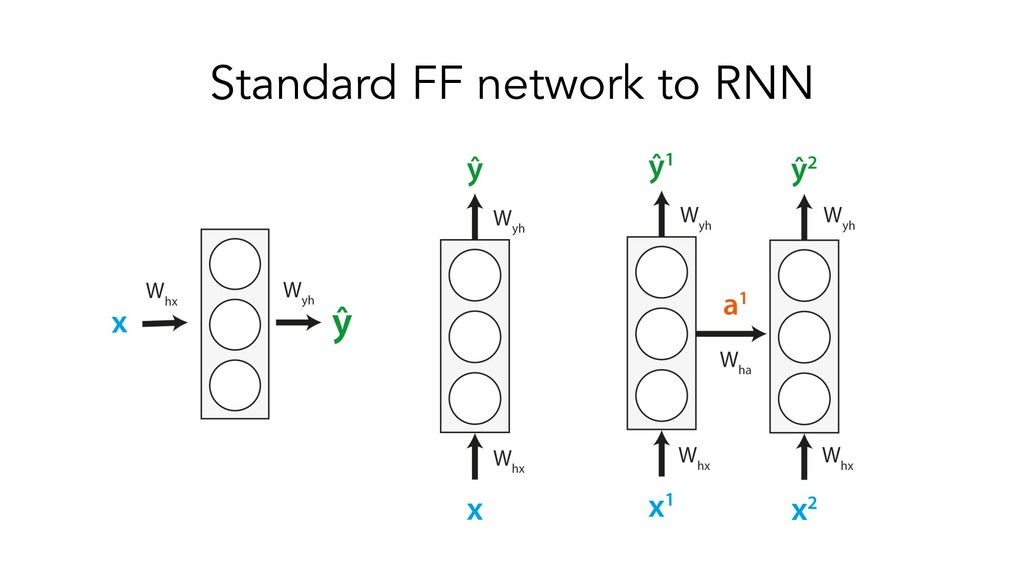
This presentation/tutorial will start from the basics and gradually build upon concepts in order to impart an understanding of the inner mechanics of sequence models – why do we need specific architectures for sequences at all, when you could use standard feed-forward networks? How do RNNs actually handle sequential information, and why do LSTM units help longer-term remembering of information? How can Transformers do such a good job at modelling sequences without any recurrence or convolutions?
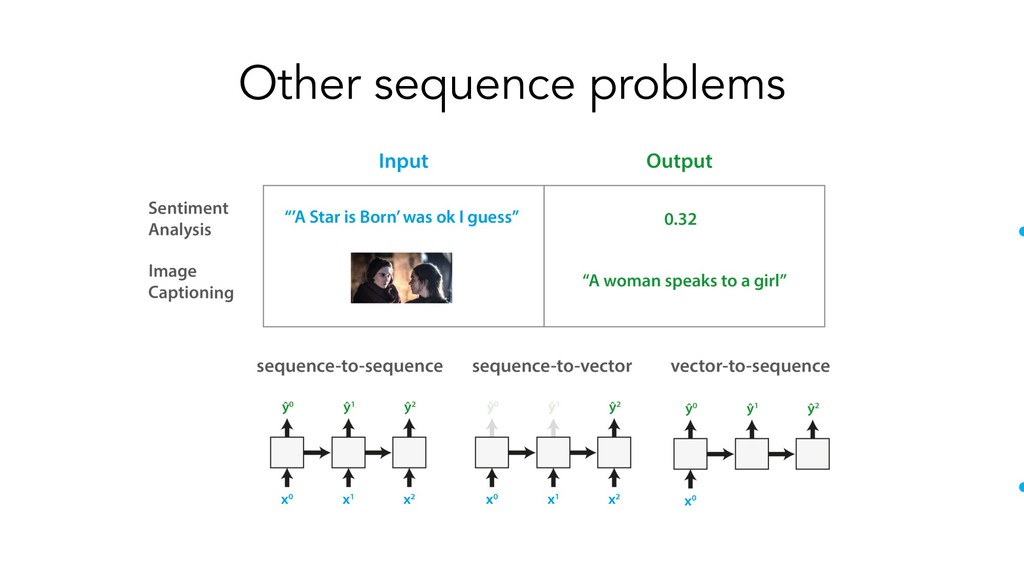
In the practical portion of this tutorial, attendees will learn how to build their own LSTM-based language model in Keras. A few other use cases of deep learning-based sequence modelling will be discussed – including sentiment analysis (prediction of the emotional valence of a piece of text) and machine translation (automatic translation between different languages).
The goals of this presentation are to provide an overview of popular sequence-based problems, impart an intuition for how the most commonly-used sequence models work under the hood, and show that quite similar architectures are used to solve sequence-based problems across many domains.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
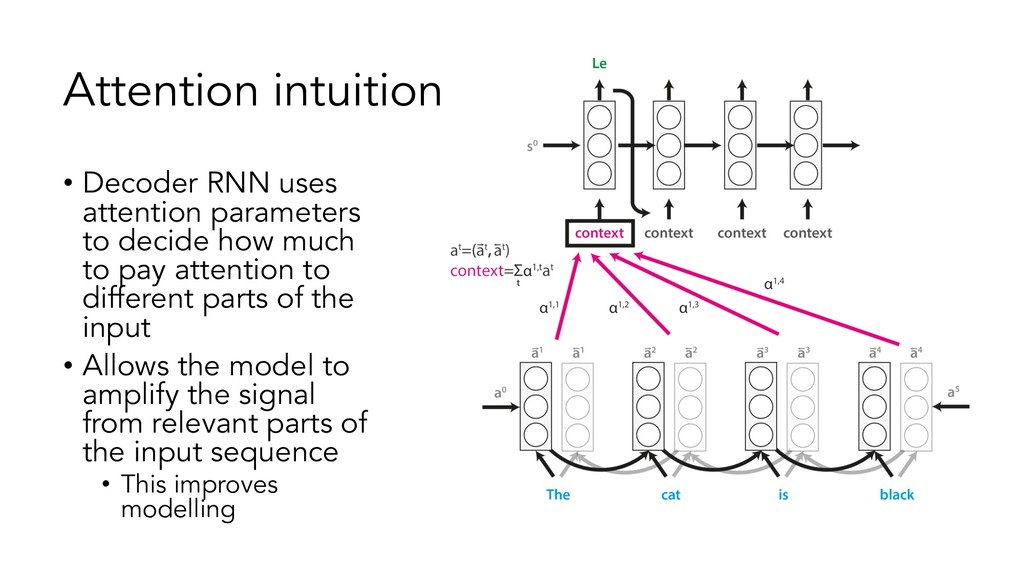{kind=link}
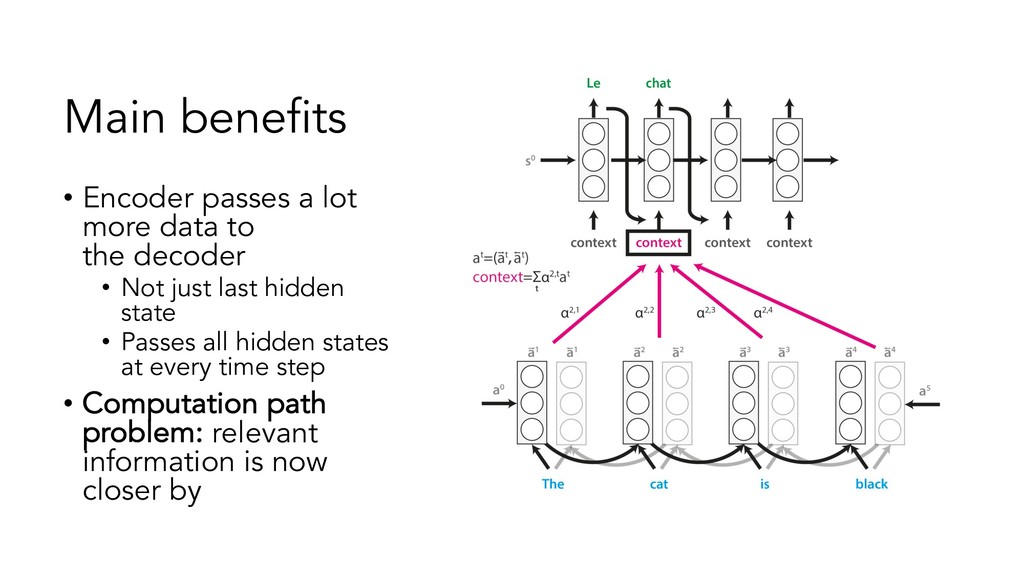{kind=link}
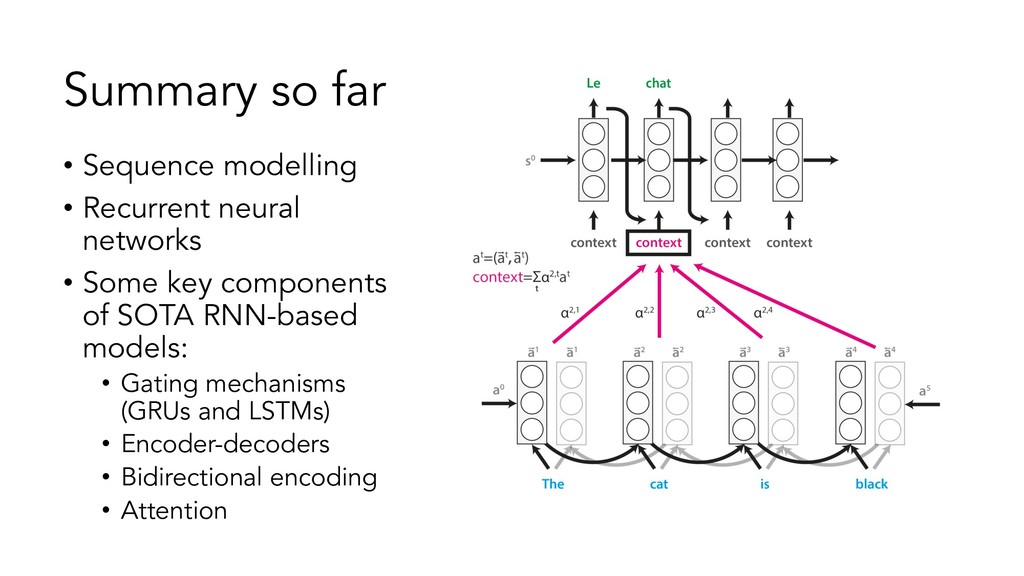{kind=link}
{kind=link}
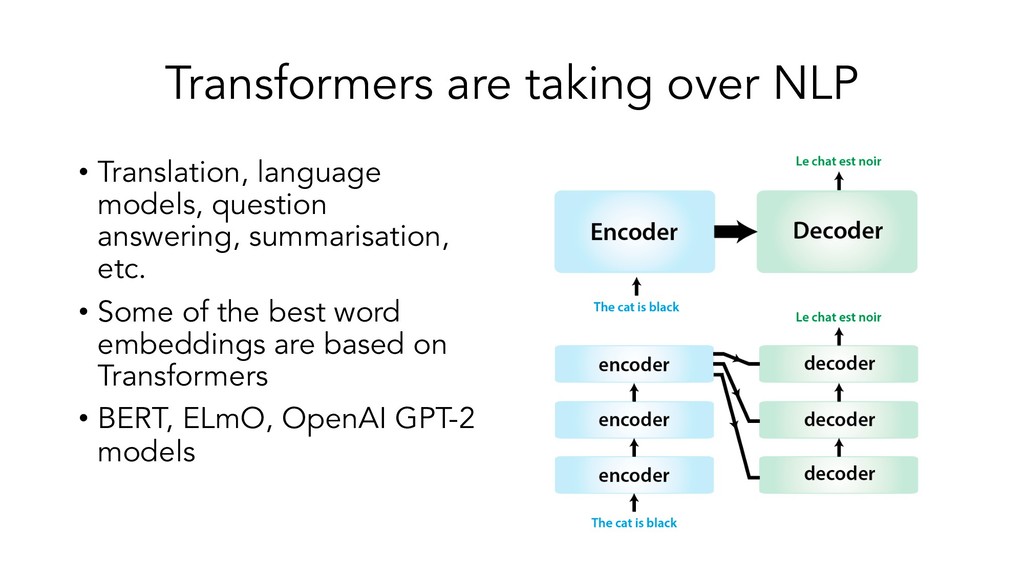{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}