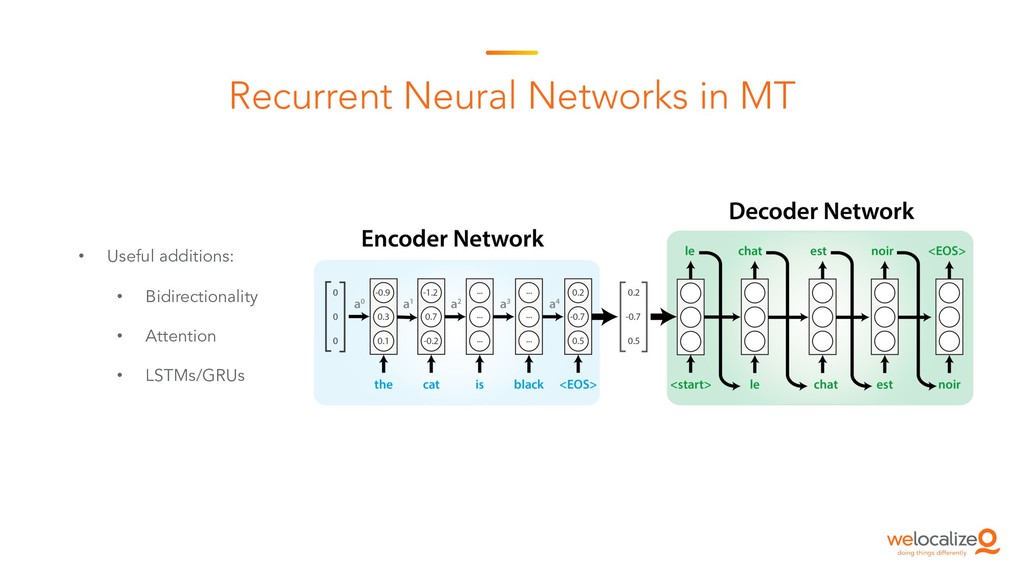
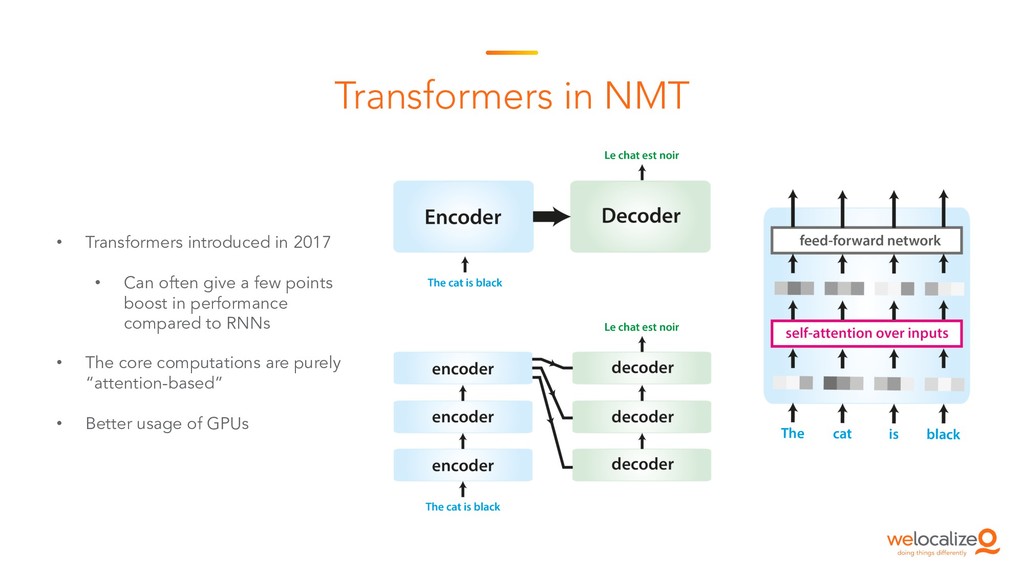
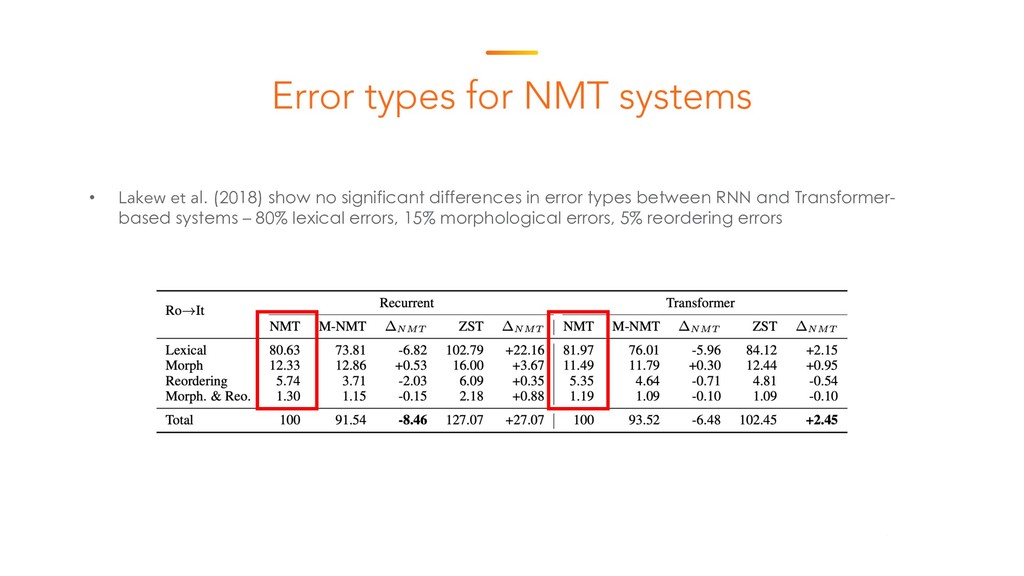
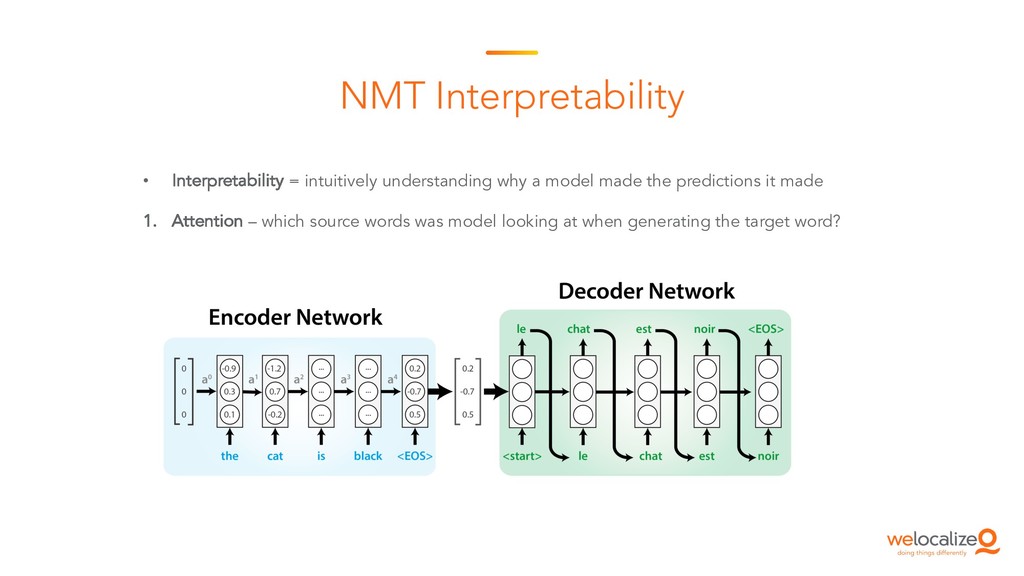
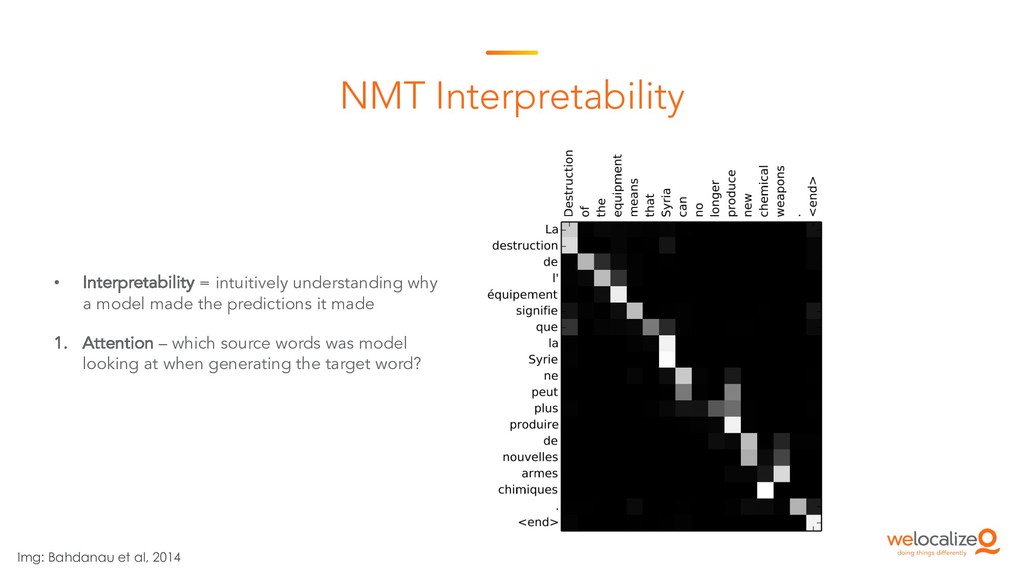
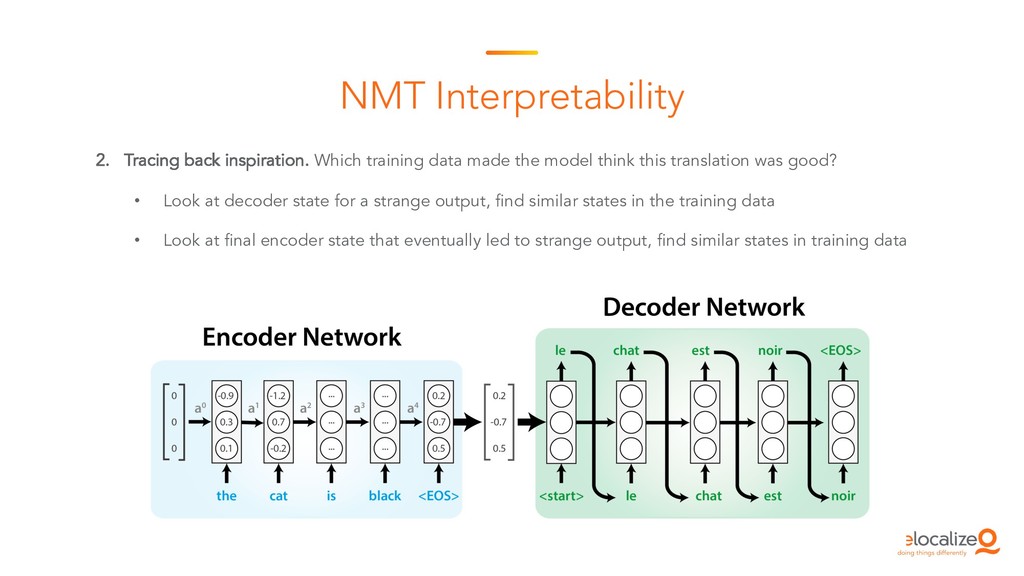
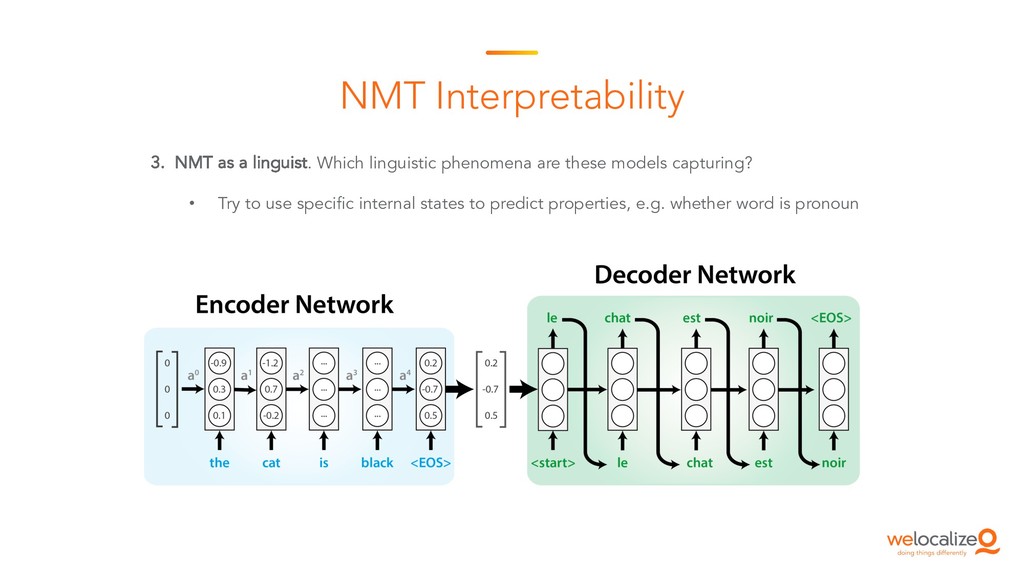
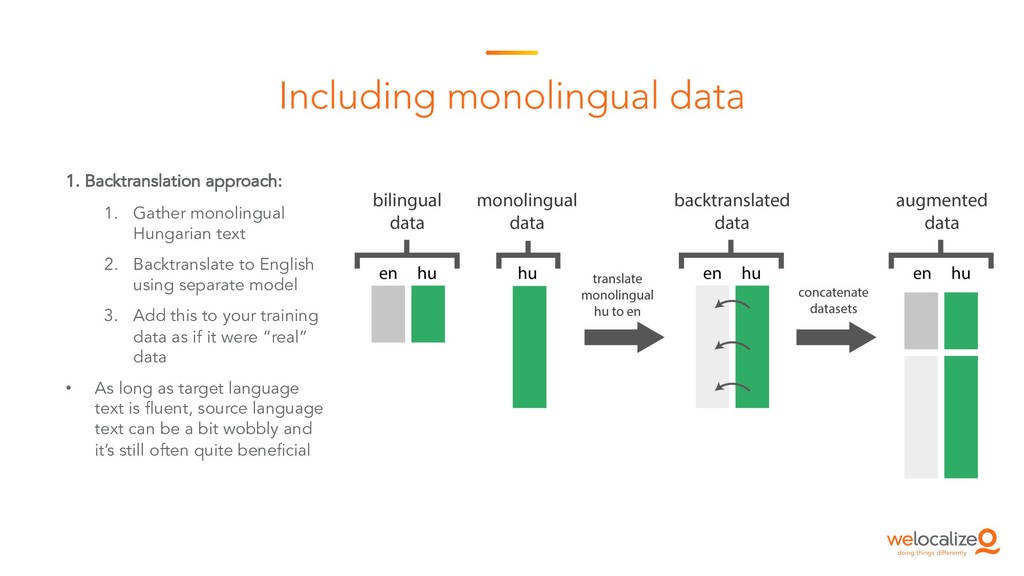
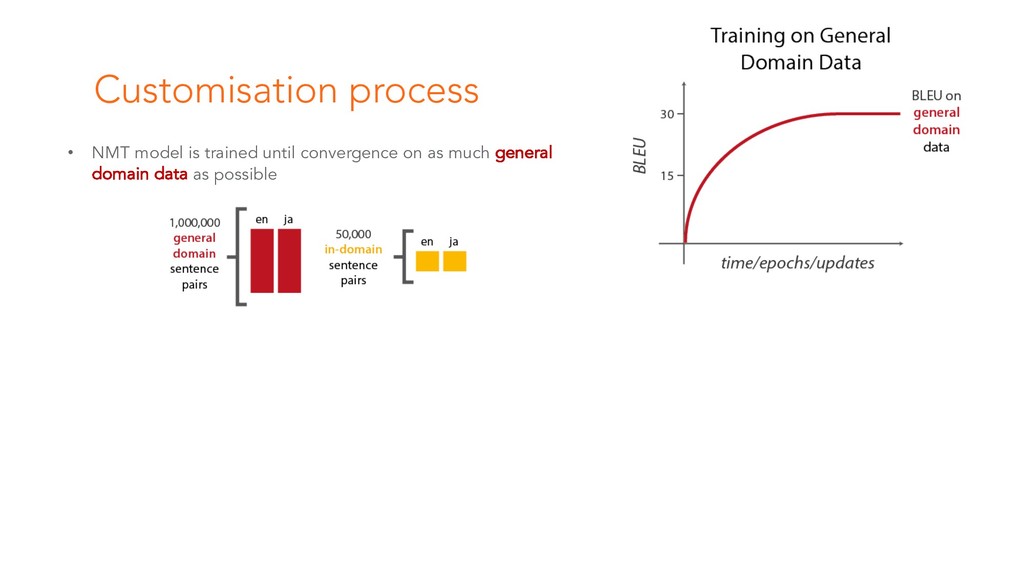
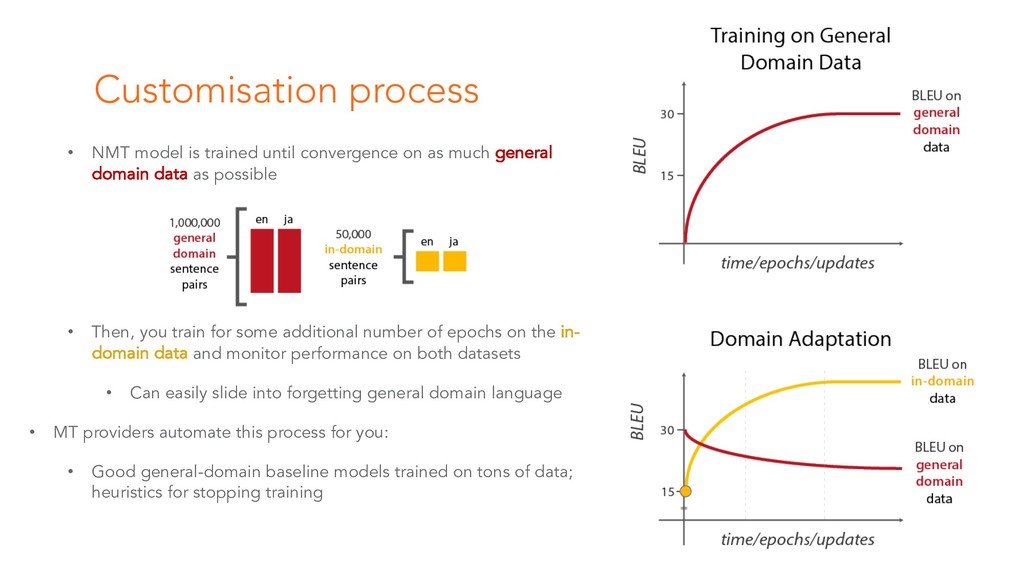
This is the starting session of the Machine Translation Summit tutorial on post-editing run by the Welocalize NLP Engineering team. This session provides an introduction to core neural machine translation concepts, including key architectures, the domain customisation process, and related research in neural network interpretability and monolingual data inclusion.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}