「AIに毒を盛る」──学習用データを改ざんし、AIモデルをサイバー攻撃 Googleなどが脆弱性を発表, ITmedia, https://www.itmedia.co.jp/news/articles/2304/05/news050.html • Carlini et al., Poisoning Web-Scale Training Datasets is Practical. https://arxiv.org/abs/2302.10149 • N. Carlini, Poisoning the Unlabeled Dataset of Semi-Supervised Learning. https://arxiv.org/abs/2105.01622 • N. Carlini & A. Terzis, Poisoning and Backdooring Contrastive Learning. https://arxiv.org/abs/2106.09667 • Wiki40B 言語モデル, TensorFlow, https://www.tensorflow.org/hub/tutorials/wiki40b_lm?hl=ja
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
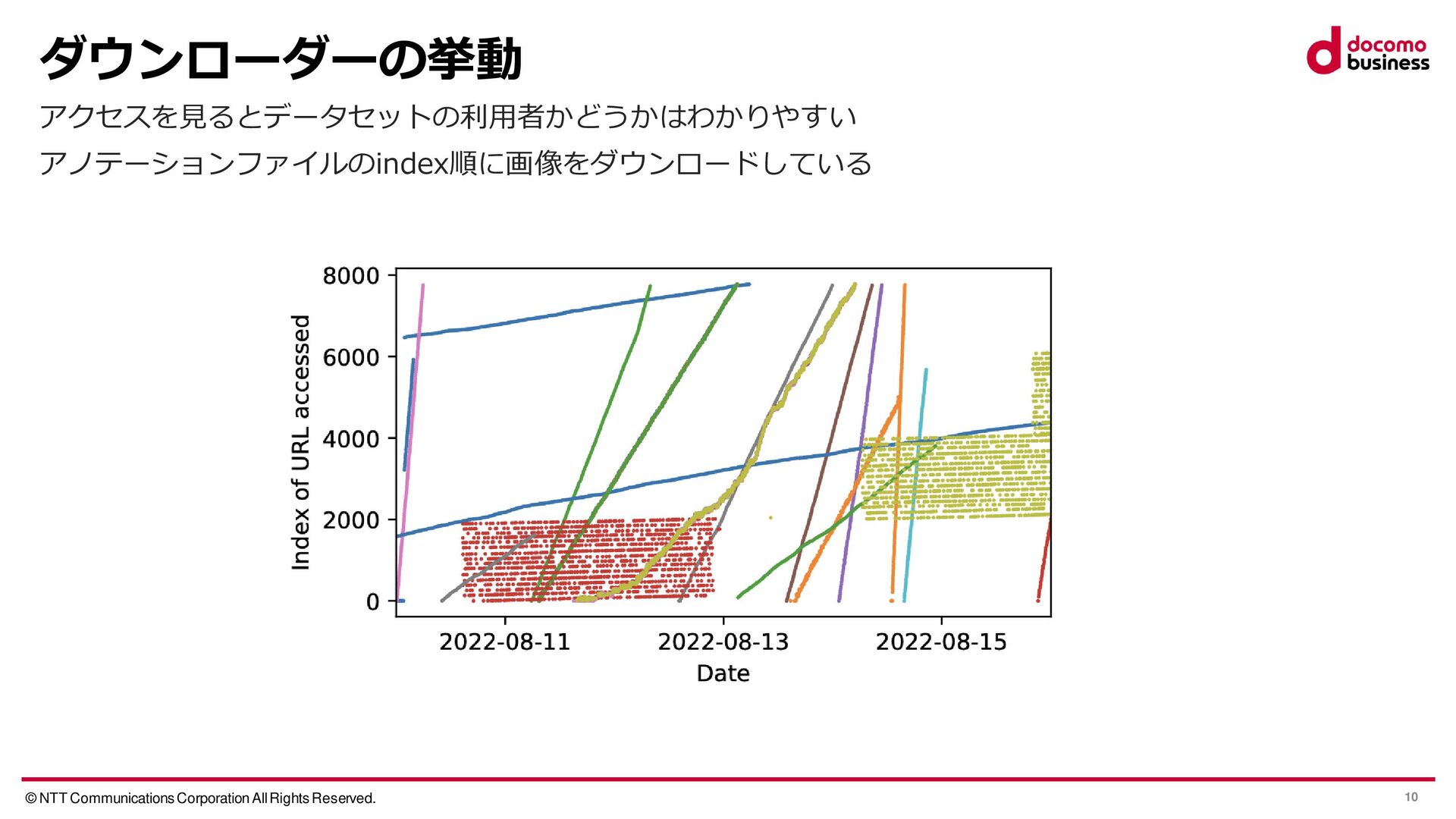{kind=link}
{kind=link}
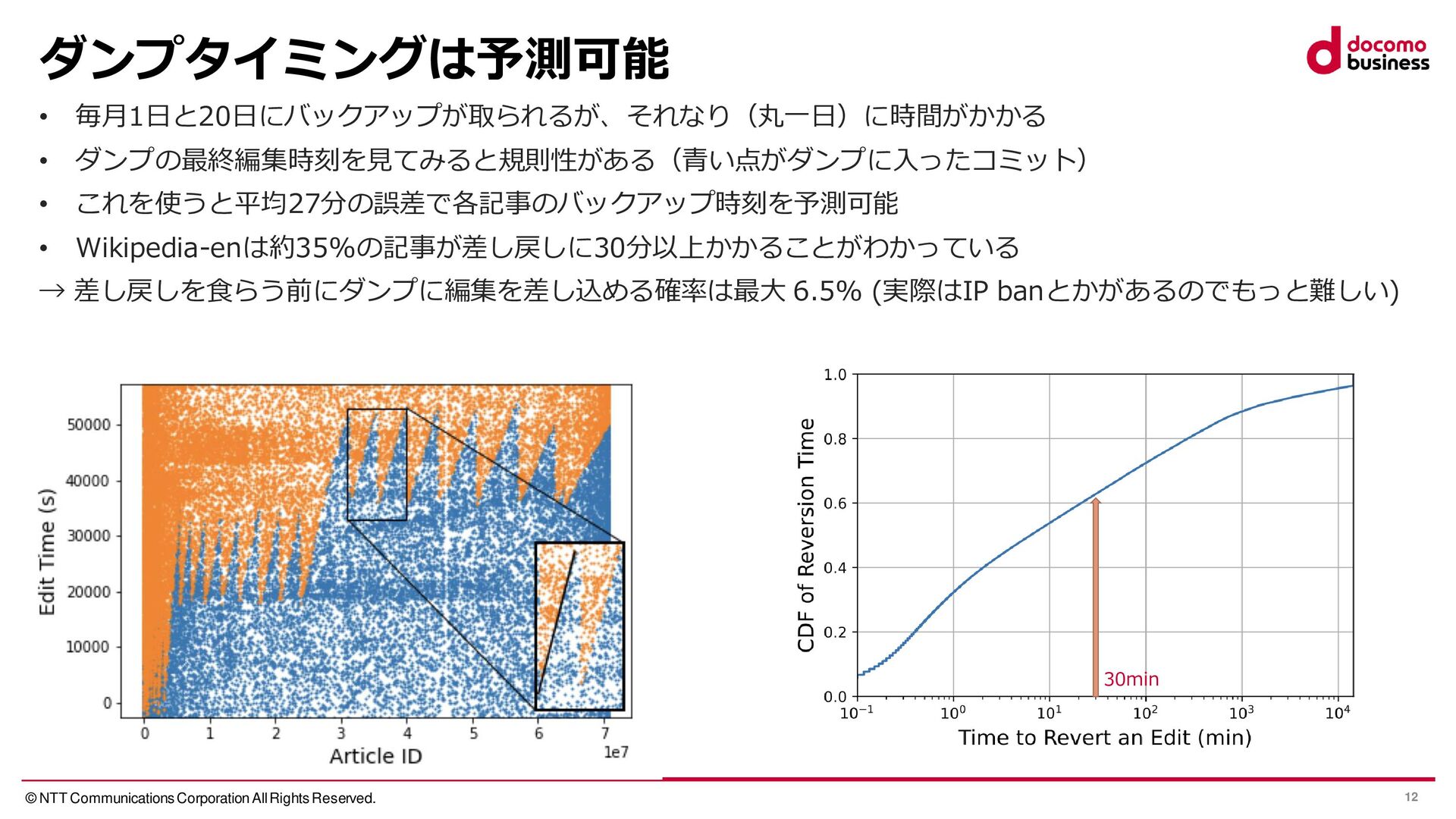{kind=link}
{kind=link}
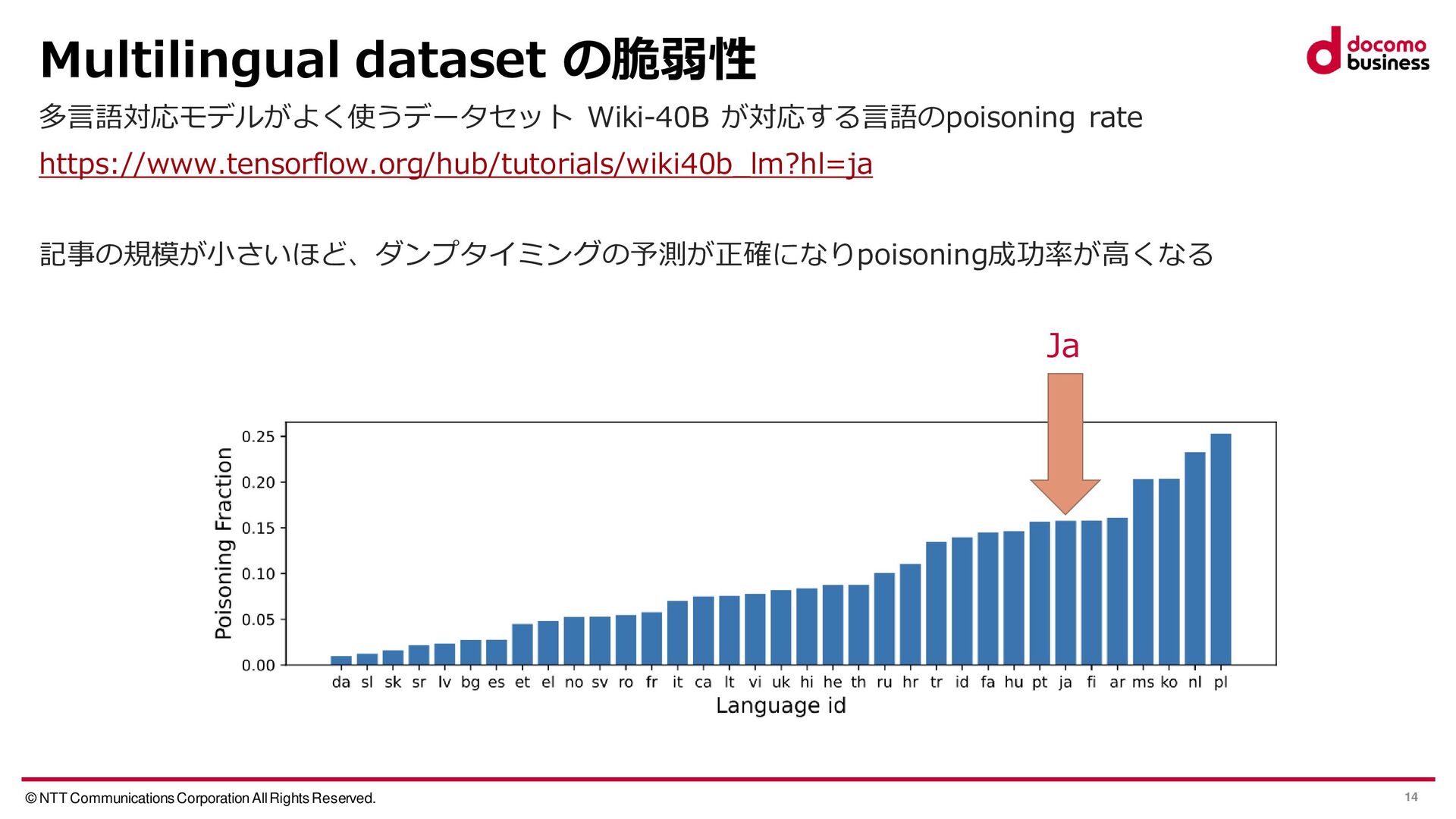{kind=link}
{kind=link}