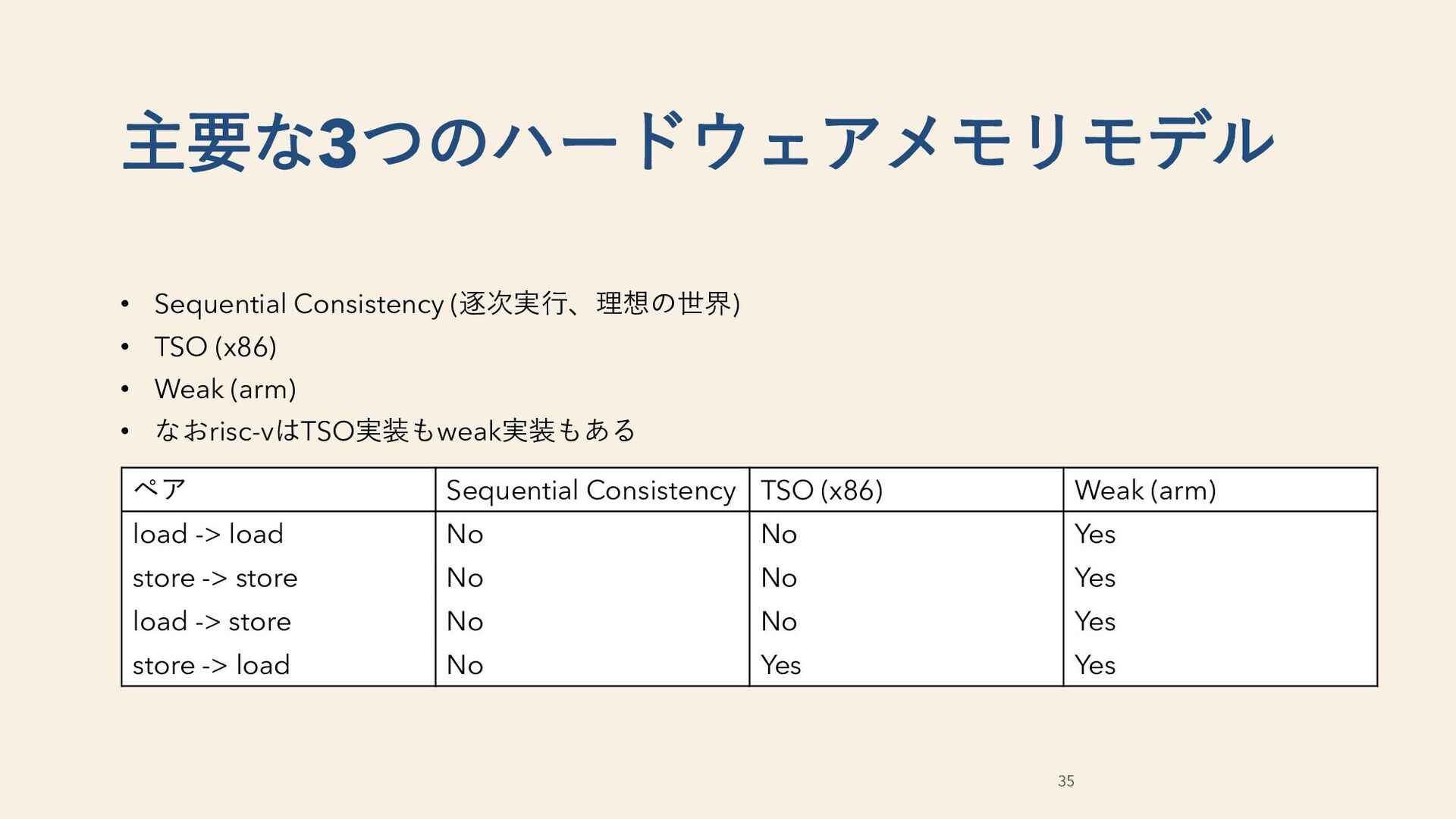
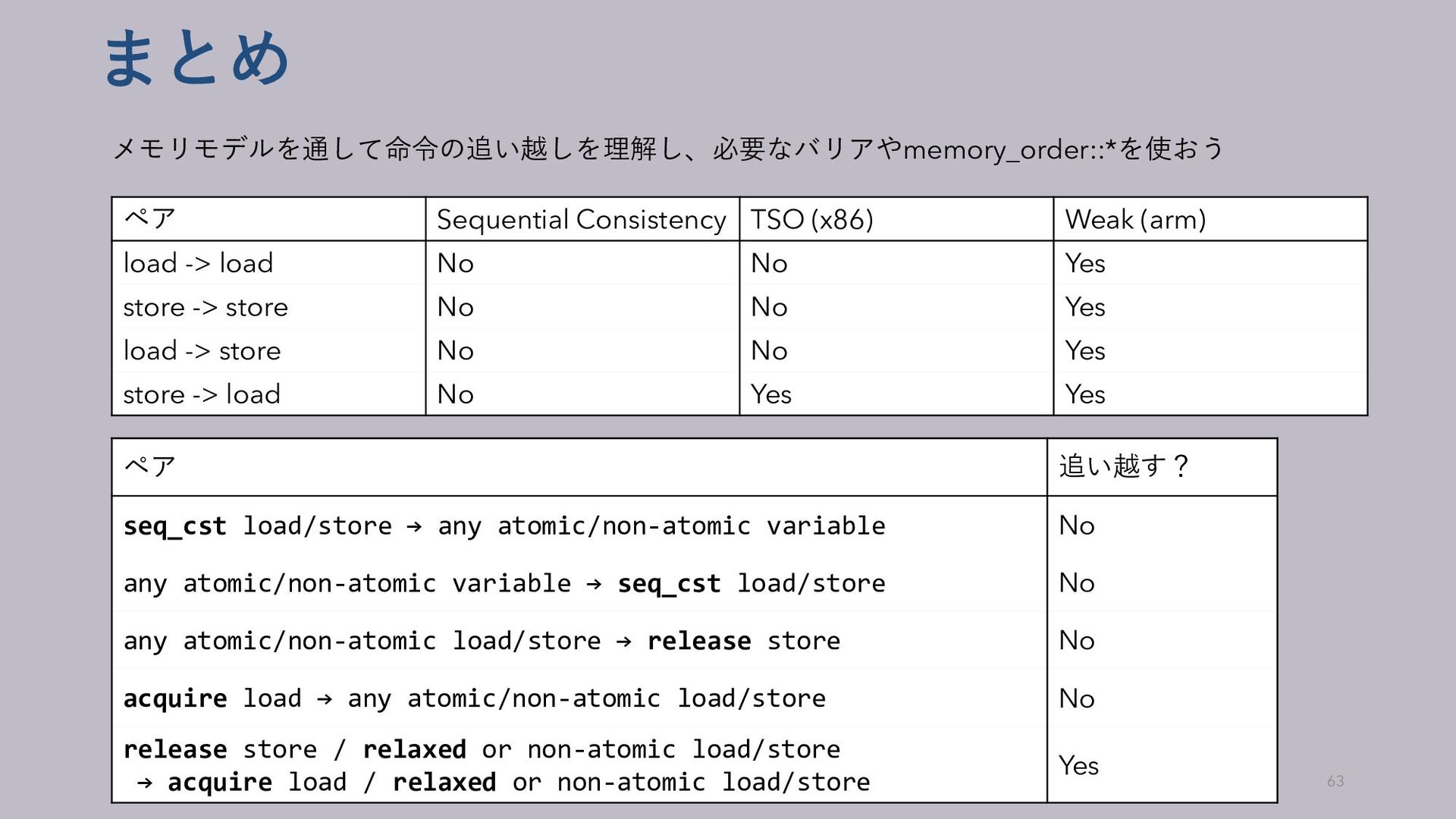
• なおrisc-vはTSO実装もweak実装もある 35 主要な3つのハードウェアメモリモデル ペア Sequential Consistency TSO (x86) Weak (arm) load -> load No No Yes store -> store No No Yes load -> store No No Yes store -> load No Yes Yes
の昇格を行える • 細かい命令はリファレンスを参照してね (lock, xchg, CPUID, .. も追い越し禁止をするよ) 41 メモリバリア命令 – フェンス mov [x] <- 1 mfence mov rax <- [y] ペア SC TSO (s86) load -> load No No store -> store No No load -> store No No store -> load No Yes mfence
a release operation on an atomic object M synchronizes with an atomic operation B that performs an acquire operation on M 10 50 acquire, release _人人人人人人人人人人人_ > なかなか意味不明! <  ̄Y^Y^Y^Y^Y^Y^Y^Y^Y ^
an atomic object M synchronizes with an atomic operation B that performs an acquire operation on M 10 “synchronizes”: ざっくり、 • あるスレッドのatomic変数への書き込みで、 同じatomic変数への読み込みで別のスレッドが入れた値を観測したら、 • 読み込み以降のメモリ操作はすべて書き込み以前のメモリ操作の結果を観測できる • 逆にそれ以外は保証しない まだ難しい • ちなみに基本的にペアで使うが、そろわなくても害はない 51 acquire, release
an atomic object M synchronizes with an atomic operation B that performs an acquire operation on M 10 “synchronizes”: • acquire loadで、release storeで別のスレッドが入れた値を観測したら、acquire以降 のメモリ操作はすべてrelease以前のメモリ操作の結果を観測できる → sd.rlは以前のメモリ命令を追い越さないことでこれを実装 • 逆にそれ以外は保証しない → releaseより後のメモリ操作はreleaseを追い越しているかもしれないし、 acquire側は先のメモリ命令を追い越しているかもしれない 60 acquire, release
→ release store No acquire load → any atomic/non-atomic load/store No release store / relaxed or non-atomic load/store → acquire load / relaxed or non-atomic load/store Yes release store → seq_cst load/store No seq_cst load/store → acquire load No
synchronizeの結果non-atomic変数のアクセス順序がきまるようにする 62 C++メモリモデルまとめ ペア 追い越す? seq_cst load/store → any atomic/non-atomic variable No any atomic/non-atomic variable → seq_cst load/store No any atomic/non-atomic load/store → release store No acquire load → any atomic/non-atomic load/store No release store / relaxed or non-atomic load/store → acquire load / relaxed or non-atomic load/store Yes
load -> load No No Yes store -> store No No Yes load -> store No No Yes store -> load No Yes Yes ペア 追い越す? seq_cst load/store → any atomic/non-atomic variable No any atomic/non-atomic variable → seq_cst load/store No any atomic/non-atomic load/store → release store No acquire load → any atomic/non-atomic load/store No release store / relaxed or non-atomic load/store → acquire load / relaxed or non-atomic load/store Yes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}