Block) • GoogleͷAutoMLɿߏ׆ੑؔͷࣗಈܾఆɹ • Barret Zoph and Quoc Le. Neural Architecture Search with Reinforcement Learning. In Proc. ICLR, 2017. • ڧԽֶश • GPU: 800 • Esteban Real et al., Large-Scale Evolution of Image Classifiers. In Proc. ICML, 2017. • ਐԽతΞϧΰϦζϜ • Ϟσϧ: 1000
{kind=link}
{kind=link}
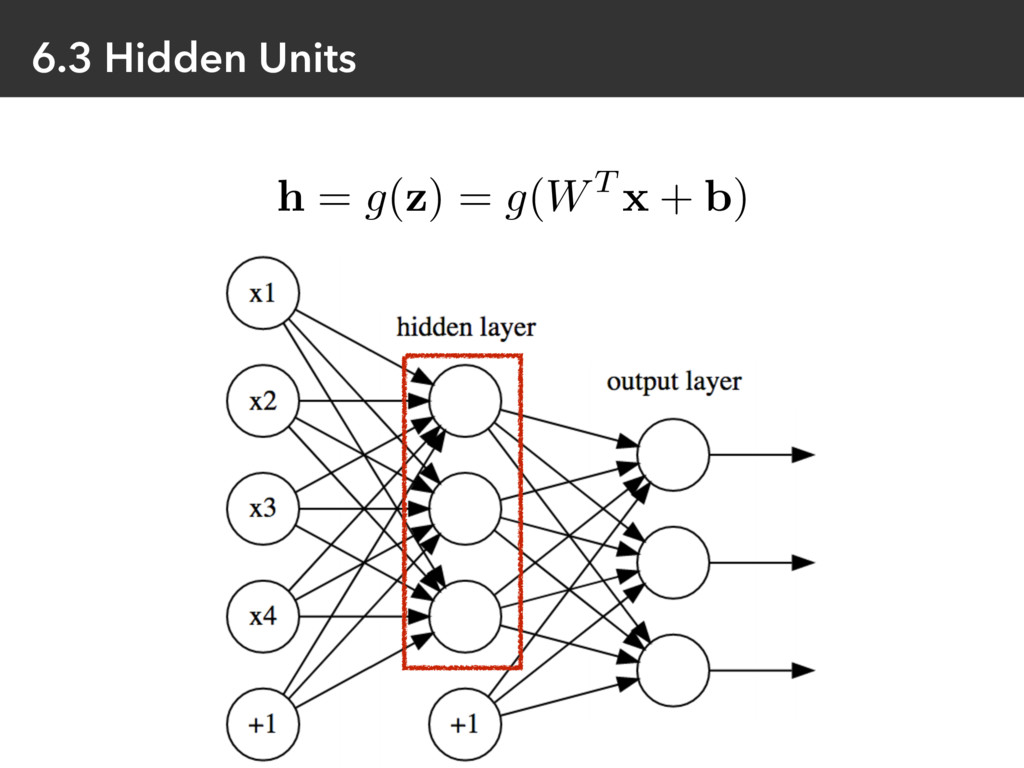{kind=link}
{kind=link}
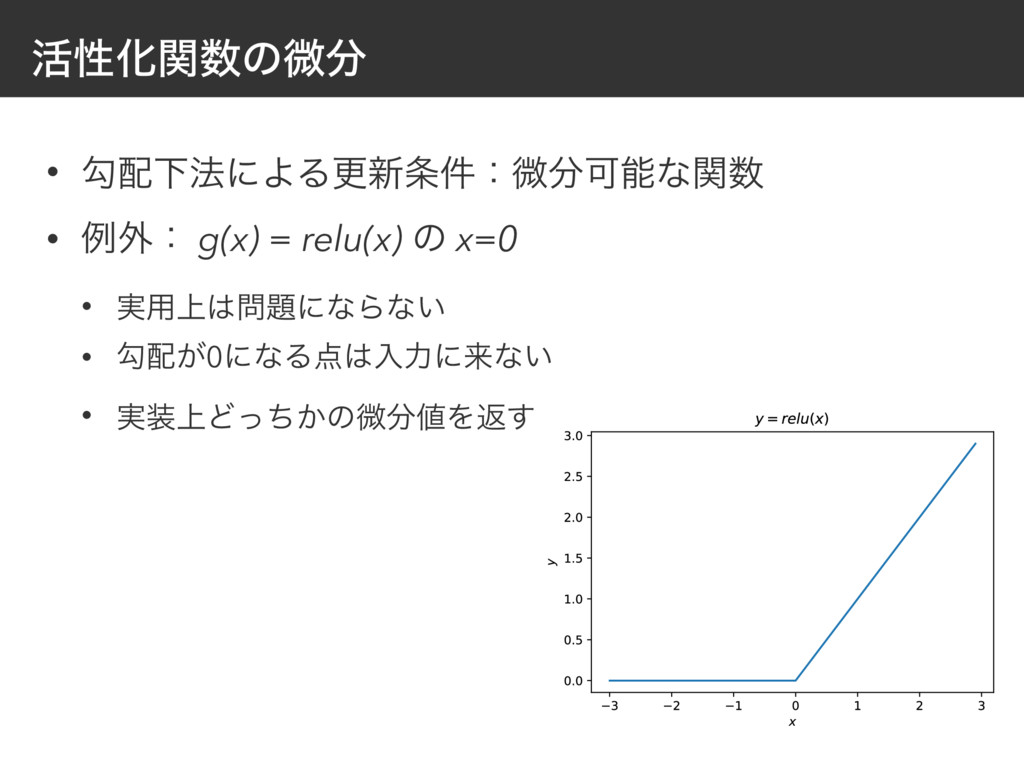{kind=link}
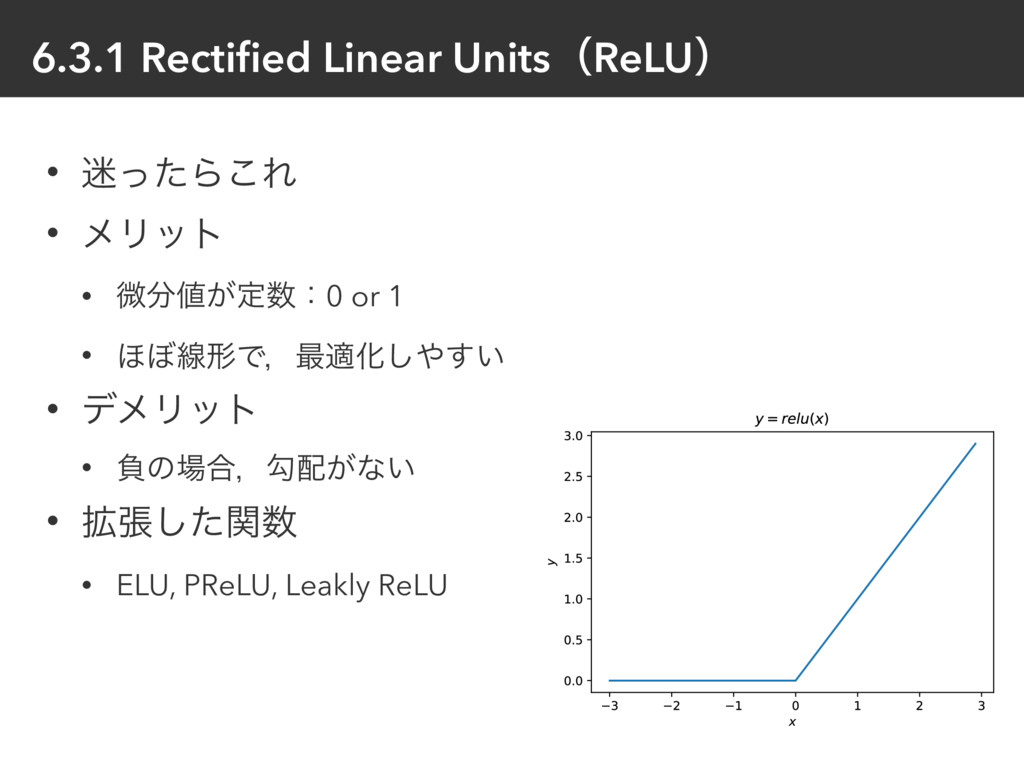{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}