IBIS2021 (https://ibisml.org/) での発表:「対照的自己教師付き表現学習おける負例数の解析」で使用したスライドです。
著者(所属):野沢健人, 佐藤一誠 (東京大学/理化学研究所, 東京大学)
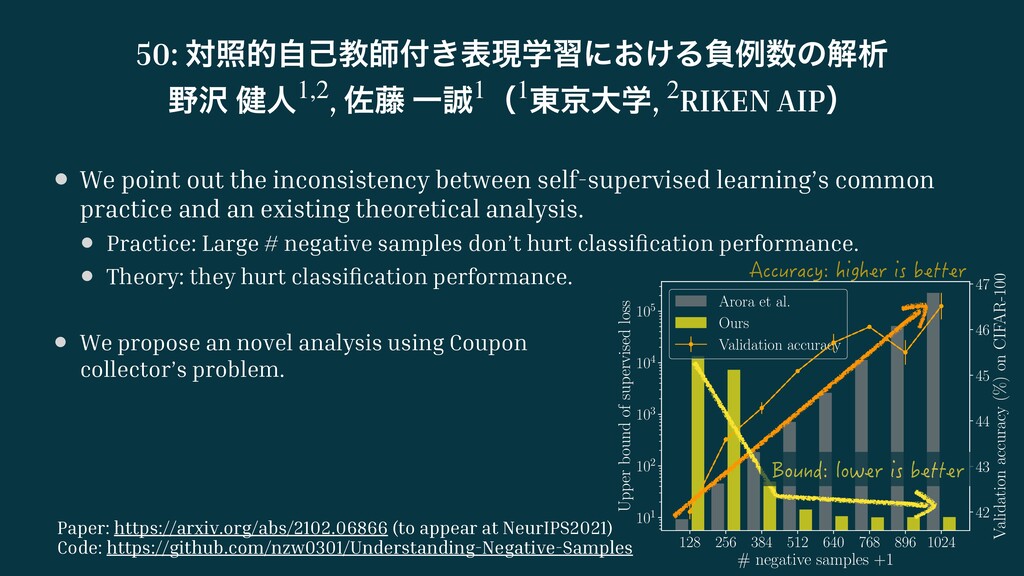
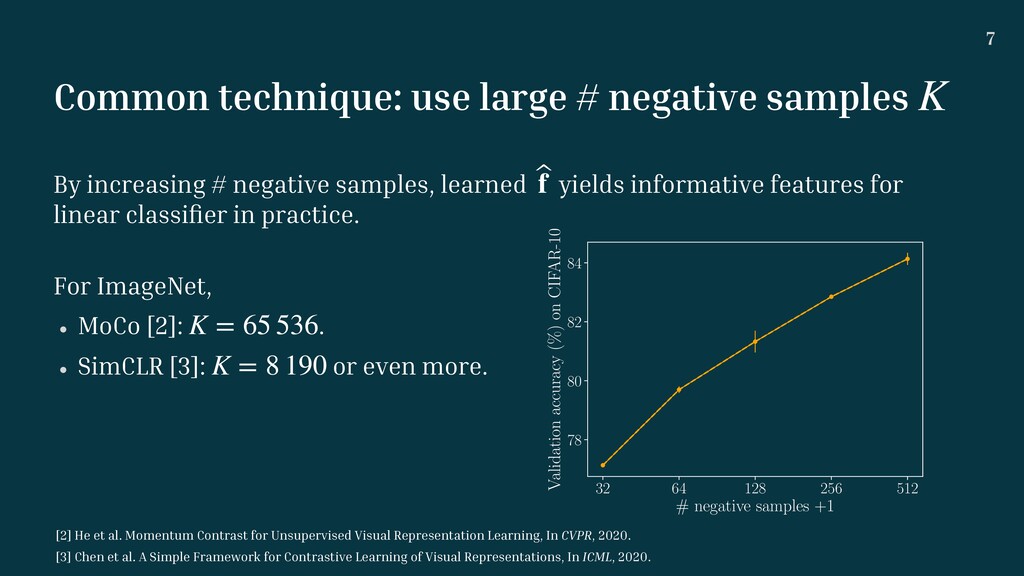
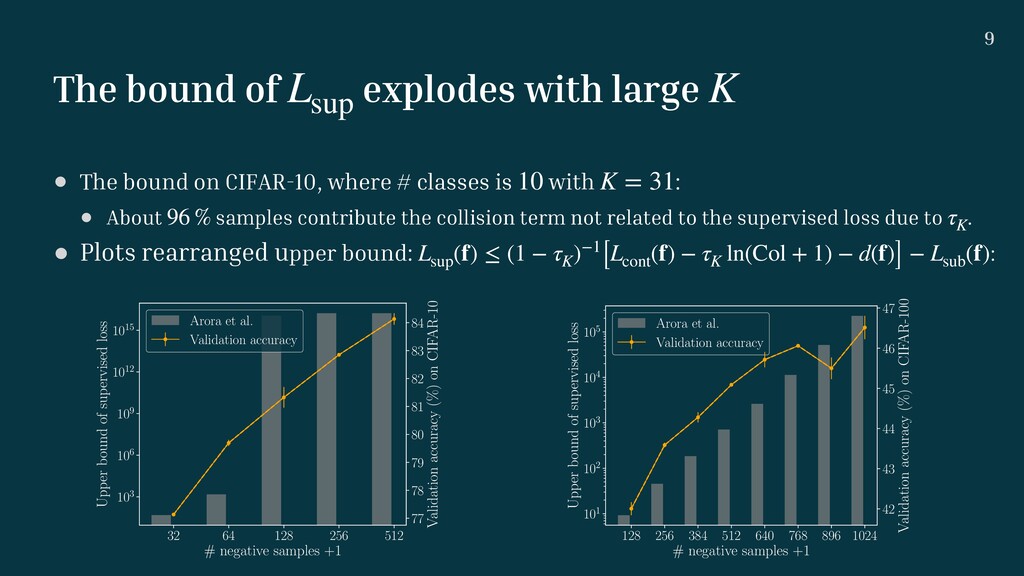
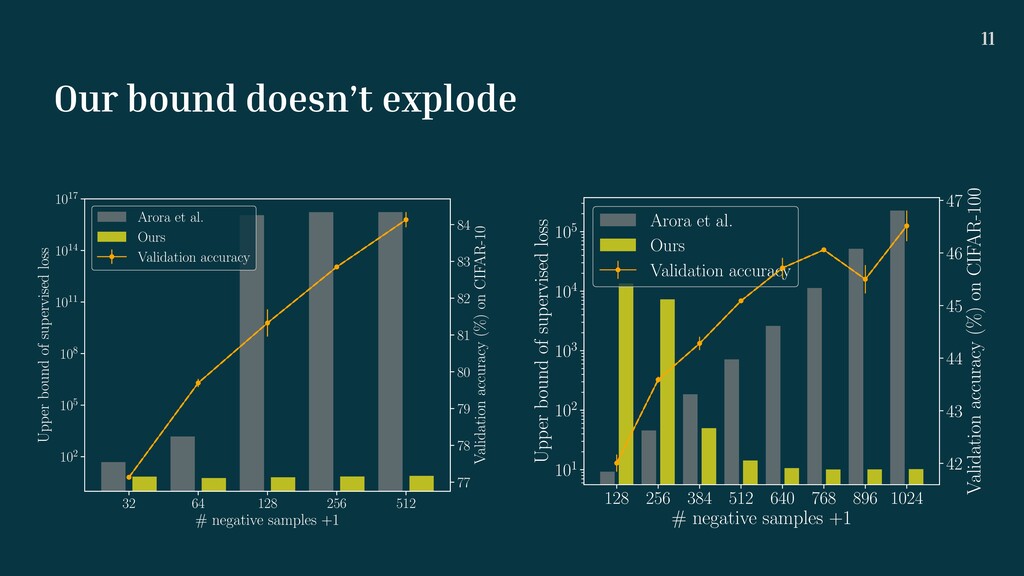
概要:敵対的自己教師付き表現学習は、大量の負例によって後続タスクの分類性能を向上させることが実験的に報告されているが、既存の理論解析では大量の負例は分類性能を下げることが示されている。本研究では、クーポンコレクタ問題を用いた解析の枠組みを提案することで、実験的な挙動を説明可能なバウンドを導出する。複数のデータセットで提案解析が成り立つことを検証した。
関連資料:
より詳細な内容: https://arxiv.org/abs/2102.06866 , https://openreview.net/forum?id=pZ5X_svdPQ
Code: https://github.com/nzw0301/Understanding-Negative-Samples
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![A theory of contrastive representation learning 8 Informal bound [4]](https://files.speakerdeck.com/presentations/8243d8c6e4424fde94fac9e9d1cbe89b/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}