ii. スパムを非スパムと判定し,受信ボックスへ:イラッとする程度 ◦ もっと直感的な例:きのこ分類器 i. 毒キノコを食用キノコと判定し,食べた:やばい,死ぬかもしれない ii. 食用きのこを毒キノコと判定し,捨てた:あとでしょんぼりする程度 • 対応例)誤差関数における前者のコストをあげる 1. 誤り方が平等でないケース 7
-5) ▪ learning_rate = 10log_learning_rate • Grid-searchよりも効率的 ◦ 特にあるパラメタが寄与が小さい場合 4.4 Random Search 31 Figure From Ian Goodfellow and Yoshua Bengio and Aaron Courville. Deep Learning. MIT Press, 2016.
is high a. 実装は正しくてoverfittingしてる b. test errorの計算に至るまでにバグがある c. test dataがtrain dataとは異なる前処理をされている • If both errors are high ◦ 以下が考えられるが,判断できない (次のスライドへ) ▪ 実装ミス ▪ underfitting Reason about software using training and test error 37
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
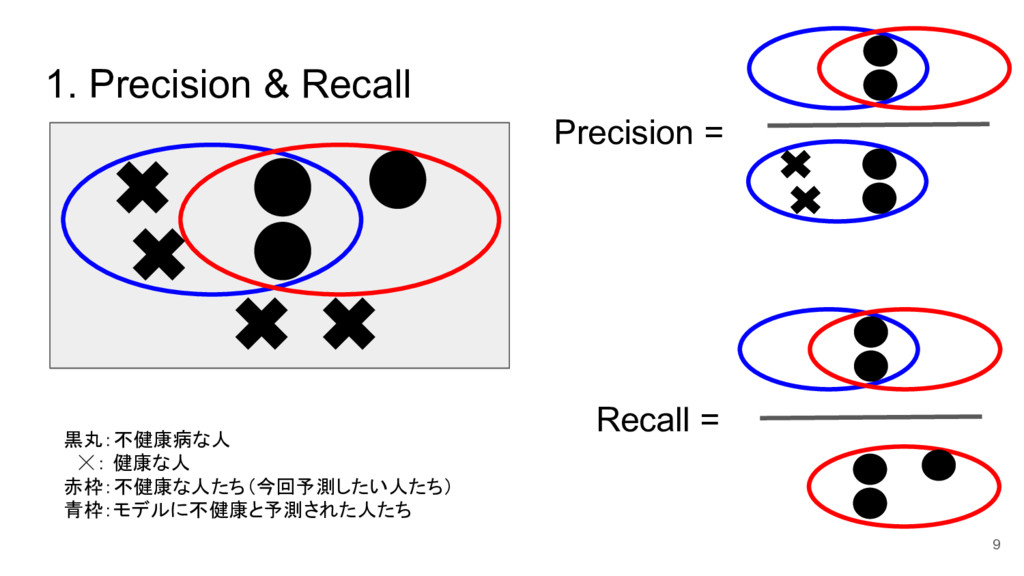{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
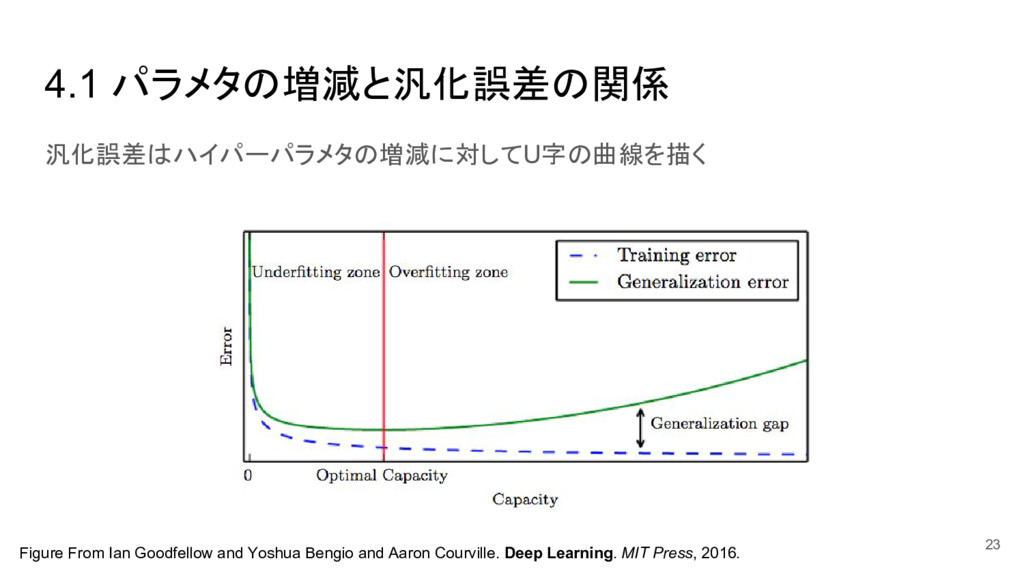{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}