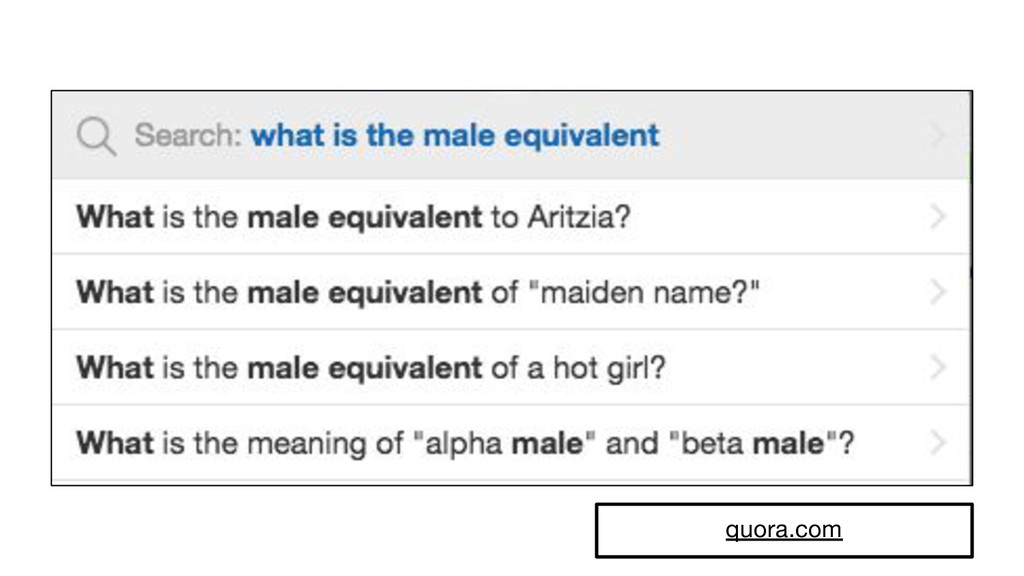
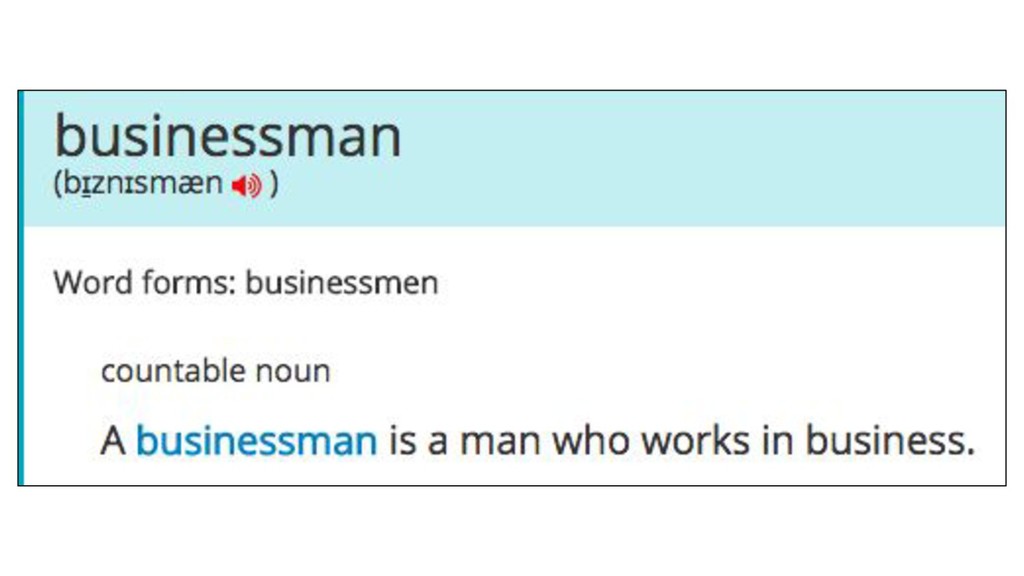
This talk is about data - where to get it and how to create it if it doesn’t exist. I’ll take the audience through the process of creating the dataset for my most recent project and show how to view unavailable data as an opportunity rather than an obstacle to answering questions. I’ll cover how to get and read data as well as popular libraries for data analysis and processing in Python — NLTK (Natural Language Toolkit), Panda, Gensim and techniques like regular expressions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![['woman', 'female', 'girl', 'lady', 'women', 'mother', 'daughter', 'wife'] ['man', 'male',](https://files.speakerdeck.com/presentations/776619446b5b4e6a85bbe0cfeee9697a/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![['woman', 'female', 'girl', 'lady', 'women', 'mother', 'daughter', 'wife'] ['man', 'male',](https://files.speakerdeck.com/presentations/776619446b5b4e6a85bbe0cfeee9697a/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
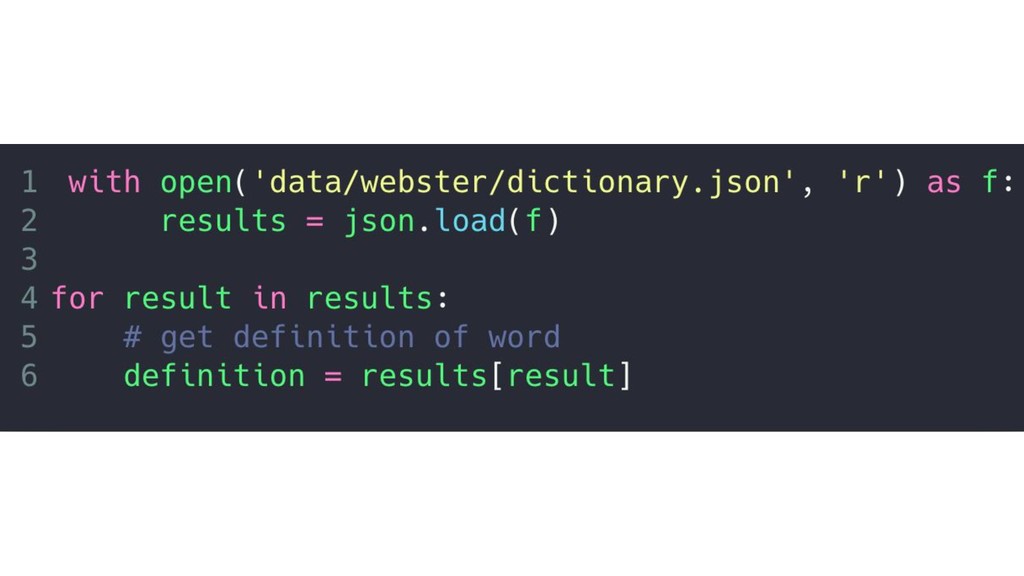{kind=link}
{kind=link}
![['woman', 'female', 'girl', 'lady', 'women', 'mother', 'daughter', 'wife'] ['man', 'male',](https://files.speakerdeck.com/presentations/776619446b5b4e6a85bbe0cfeee9697a/slide_29.jpg){kind=link}
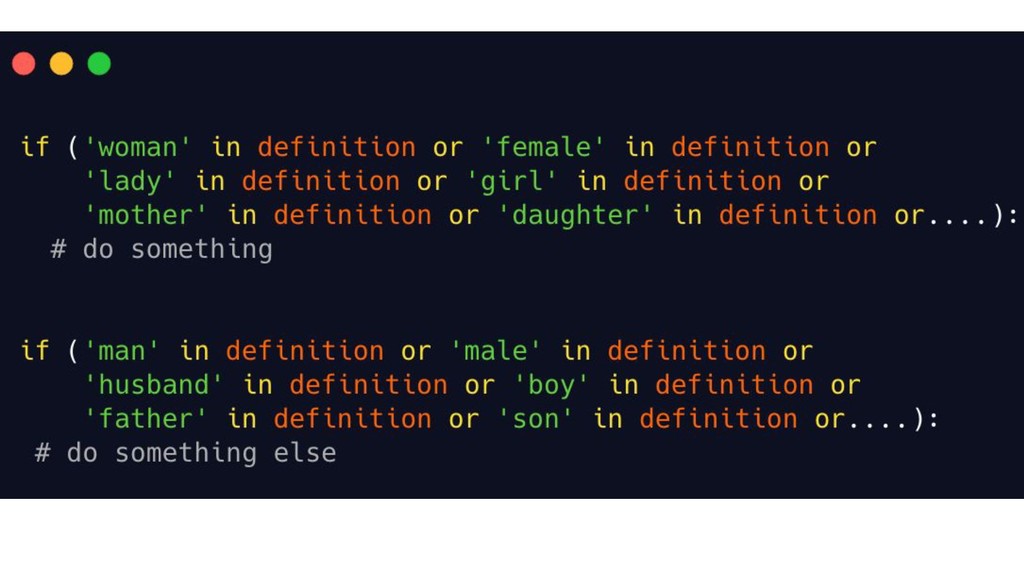{kind=link}
{kind=link}
{kind=link}
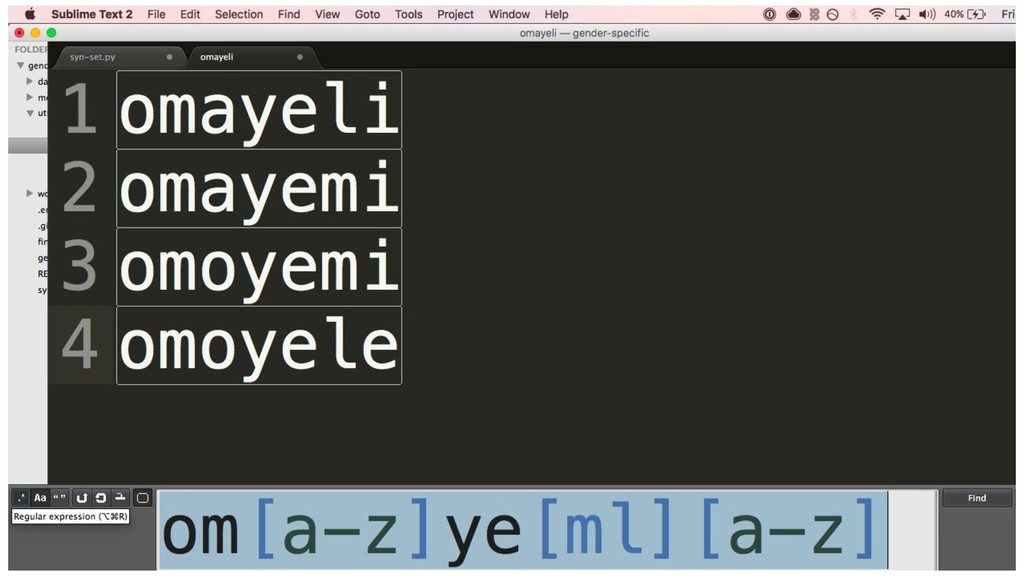{kind=link}
![['woman', 'female', 'girl', 'lady', 'women', 'mother', 'daughter', 'wife'] ['man', 'male',](https://files.speakerdeck.com/presentations/776619446b5b4e6a85bbe0cfeee9697a/slide_34.jpg){kind=link}
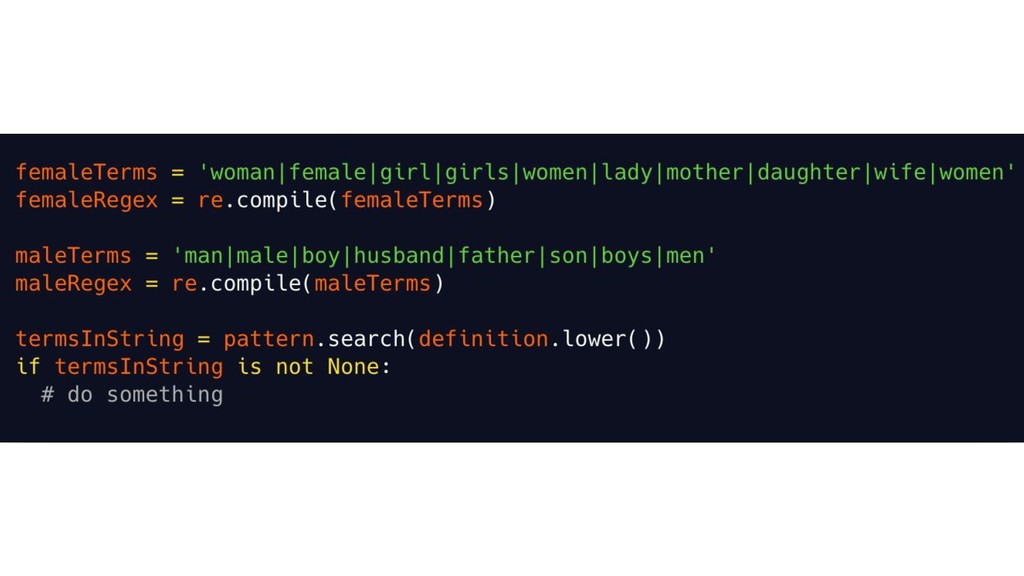{kind=link}
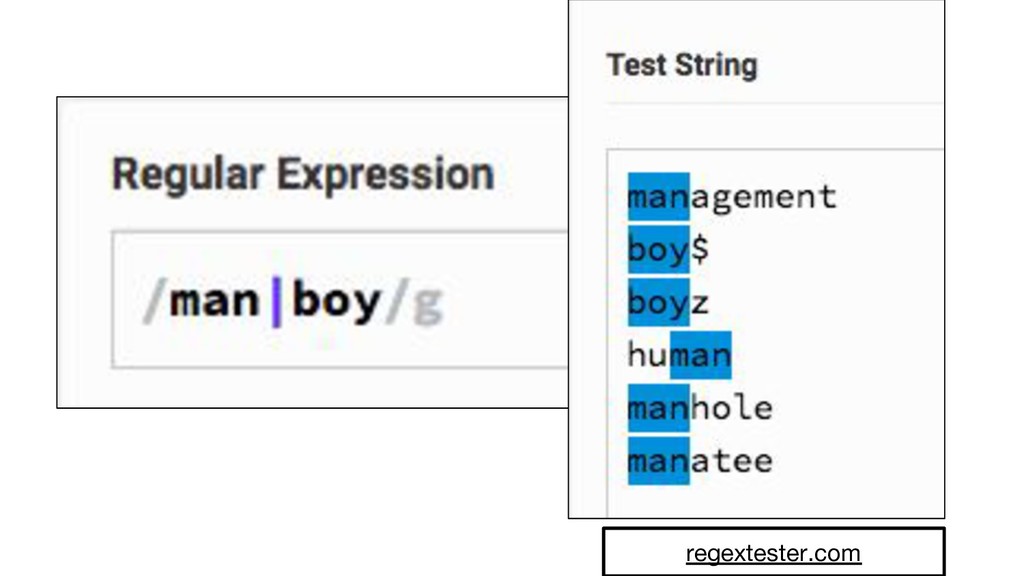{kind=link}
{kind=link}
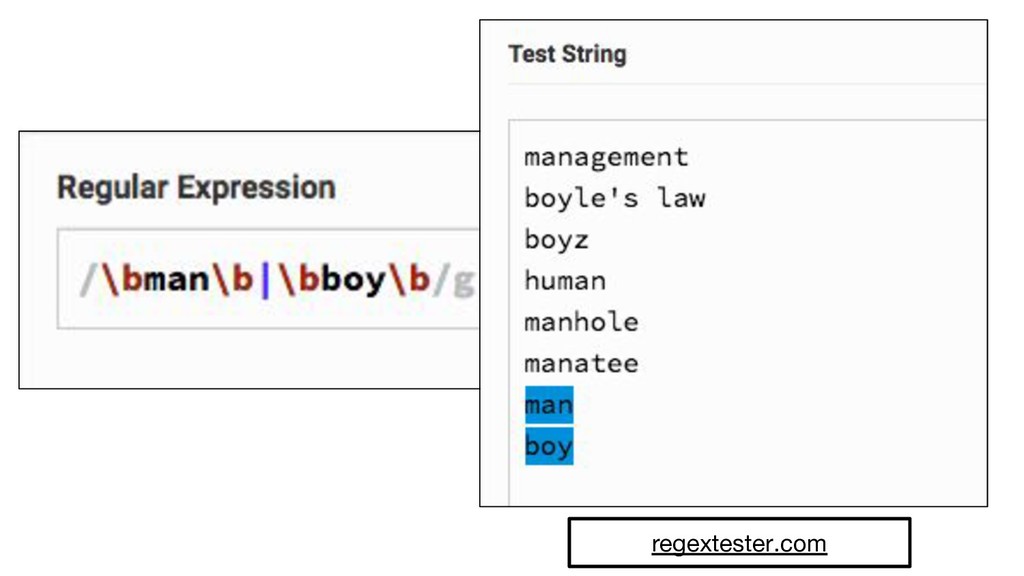{kind=link}
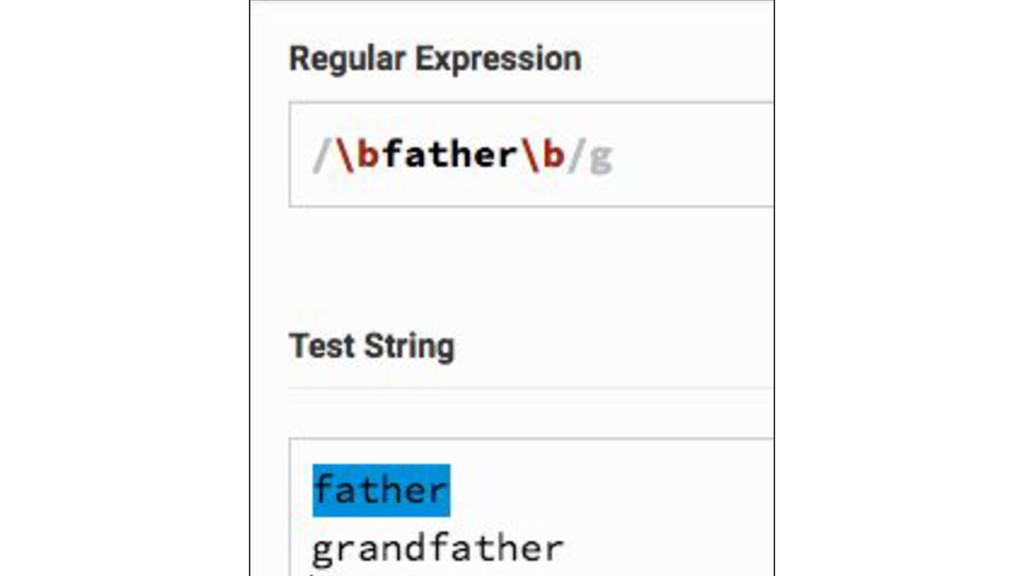{kind=link}
{kind=link}
{kind=link}
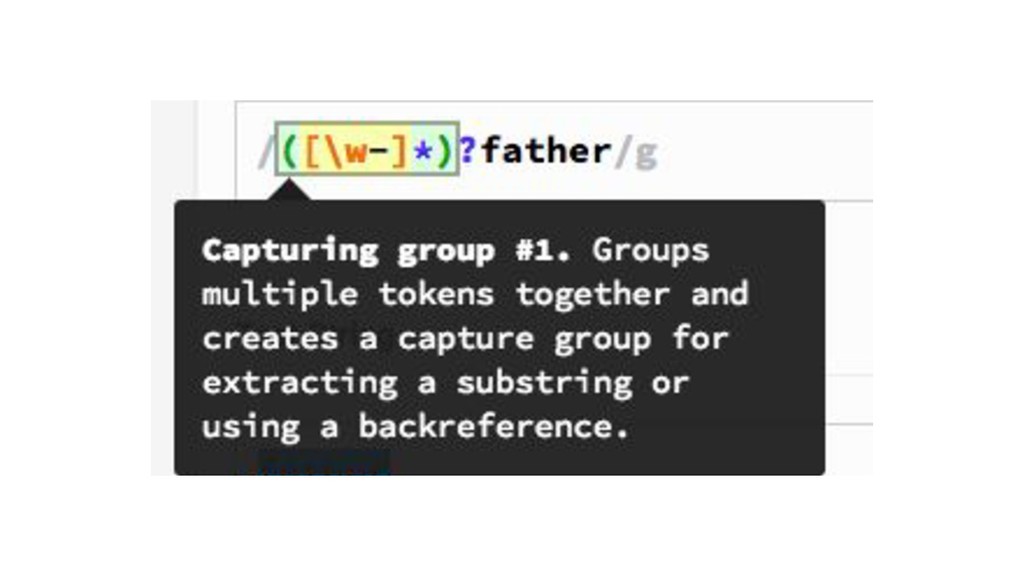{kind=link}
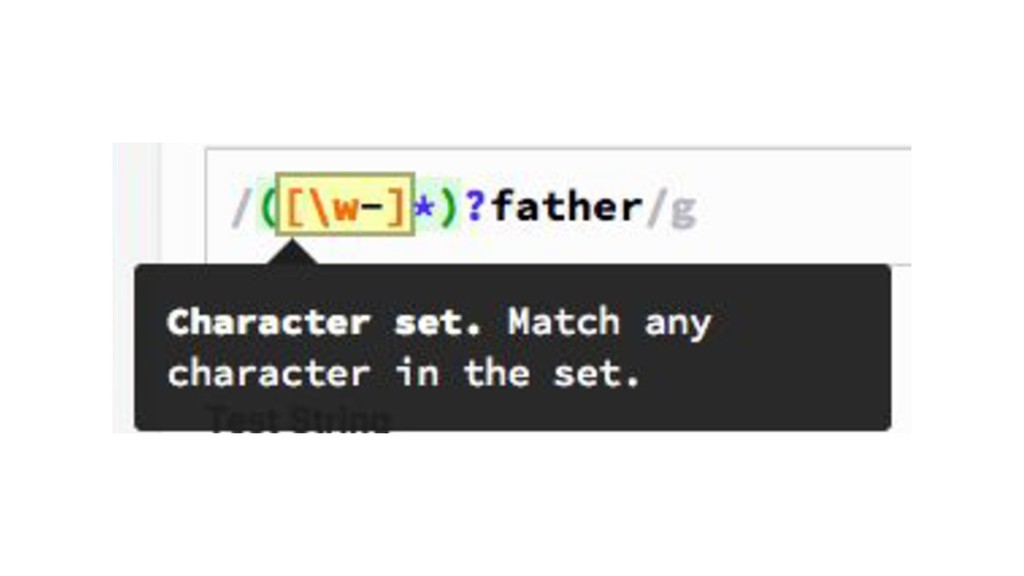{kind=link}
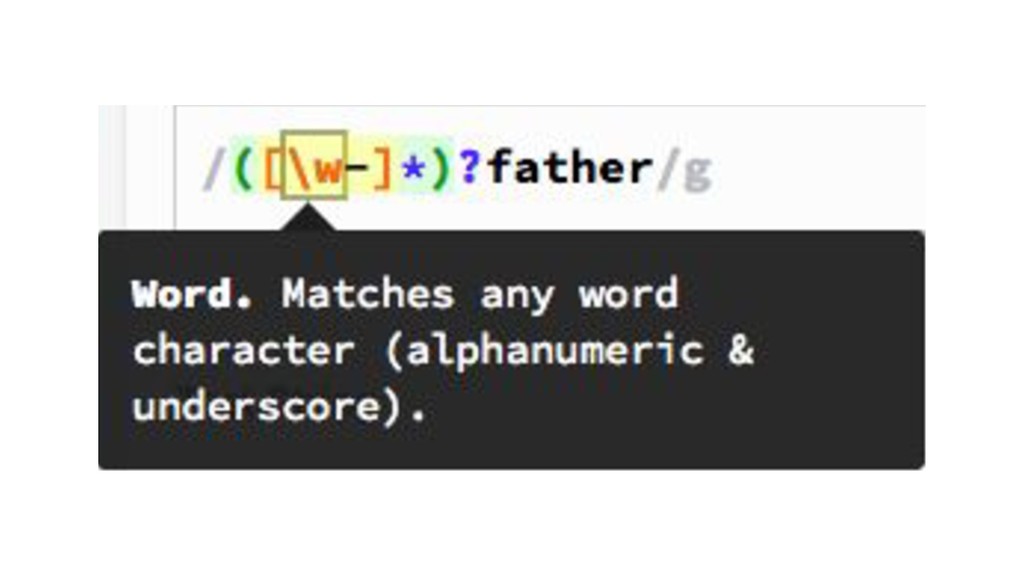{kind=link}
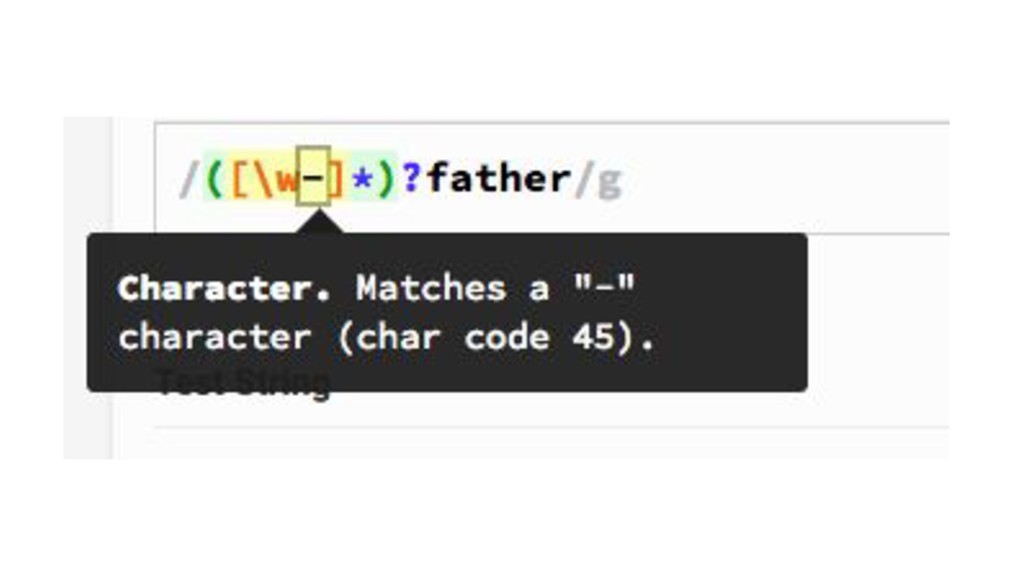{kind=link}
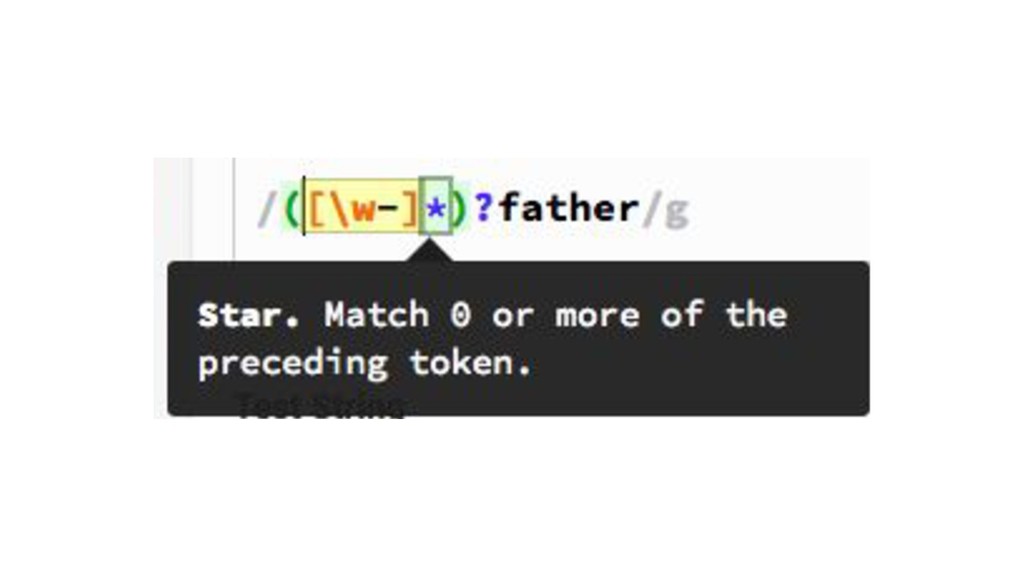{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
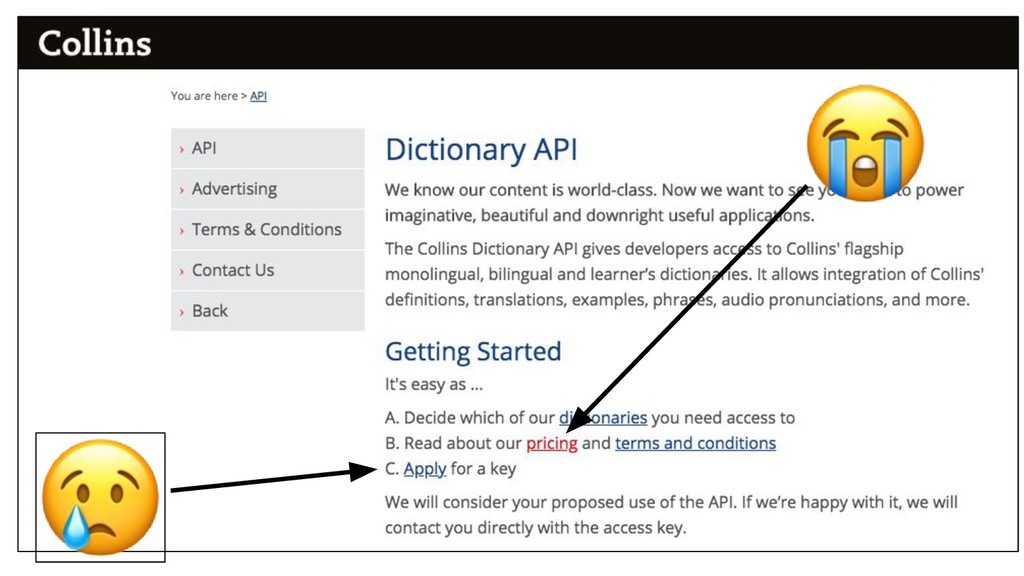{kind=link}
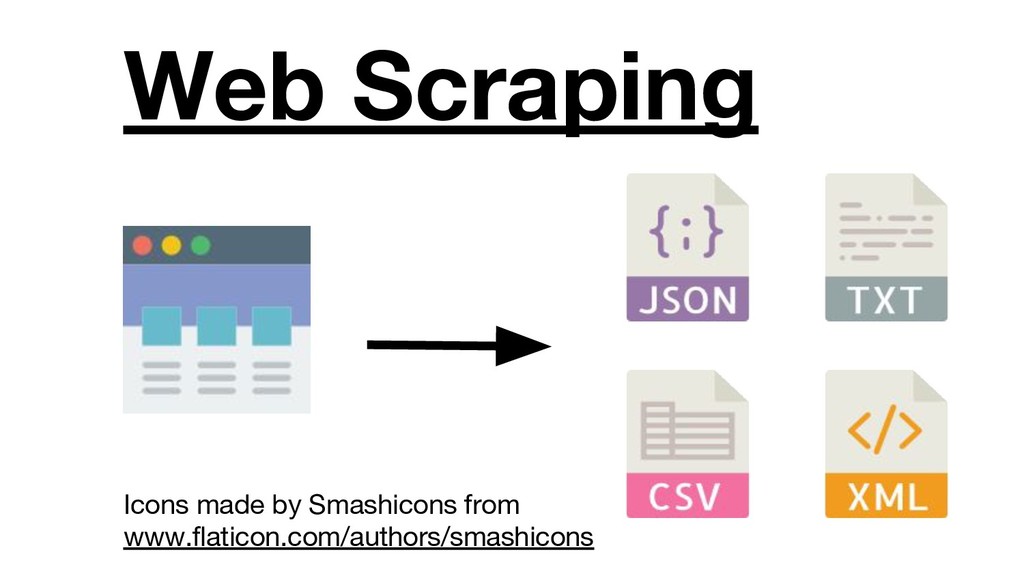{kind=link}
{kind=link}
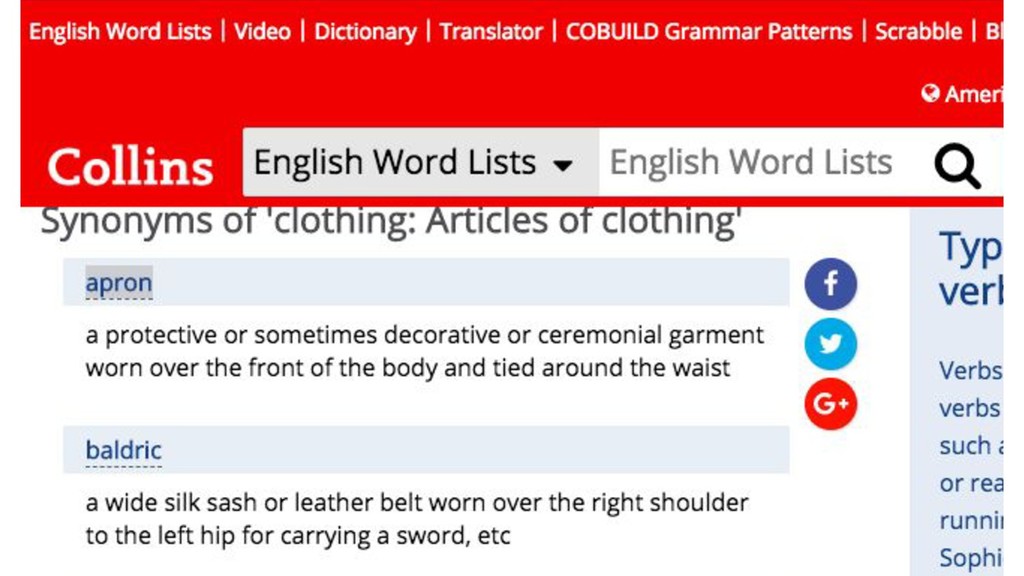{kind=link}
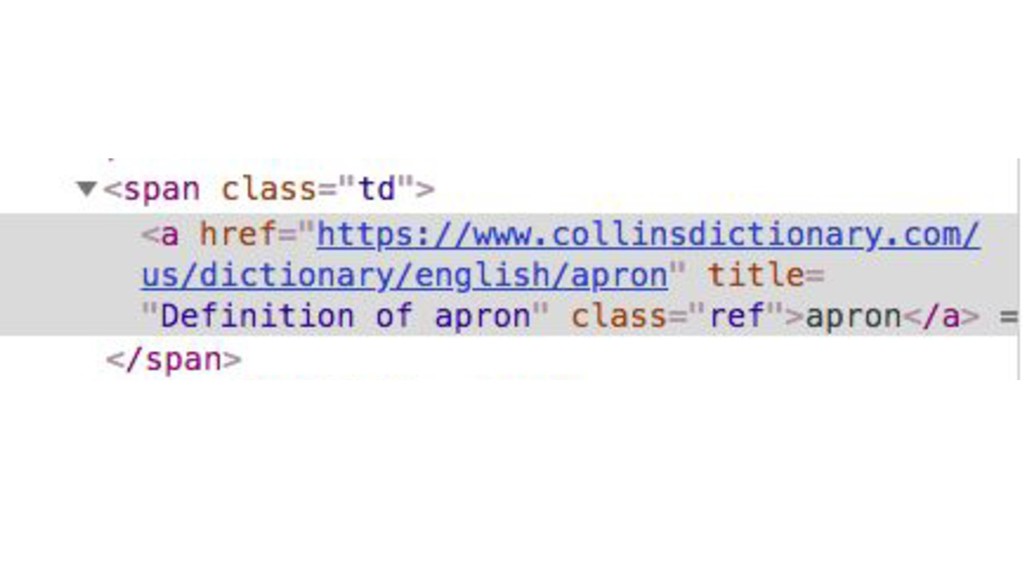{kind=link}
{kind=link}
{kind=link}
{kind=link}
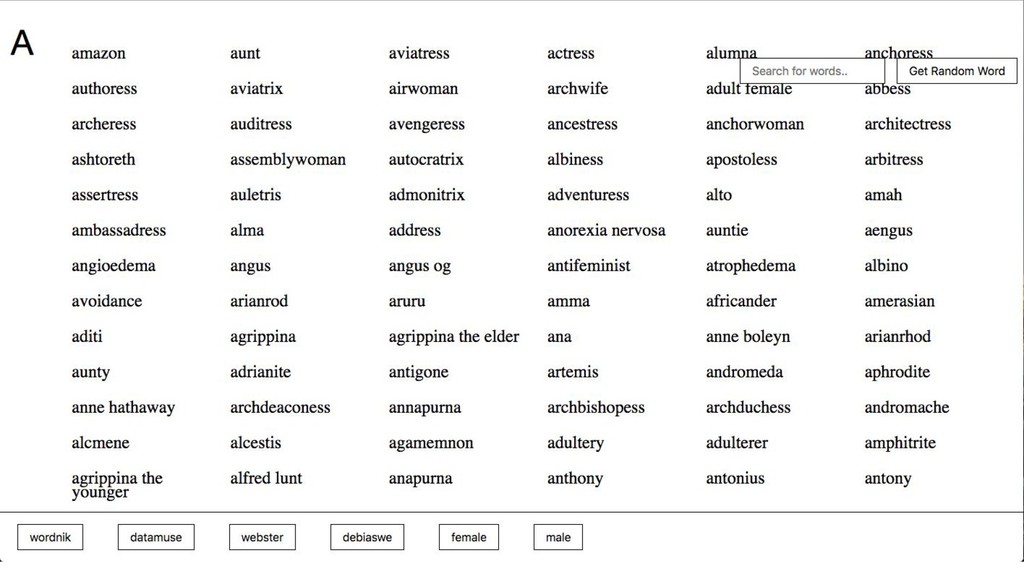{kind=link}
{kind=link}
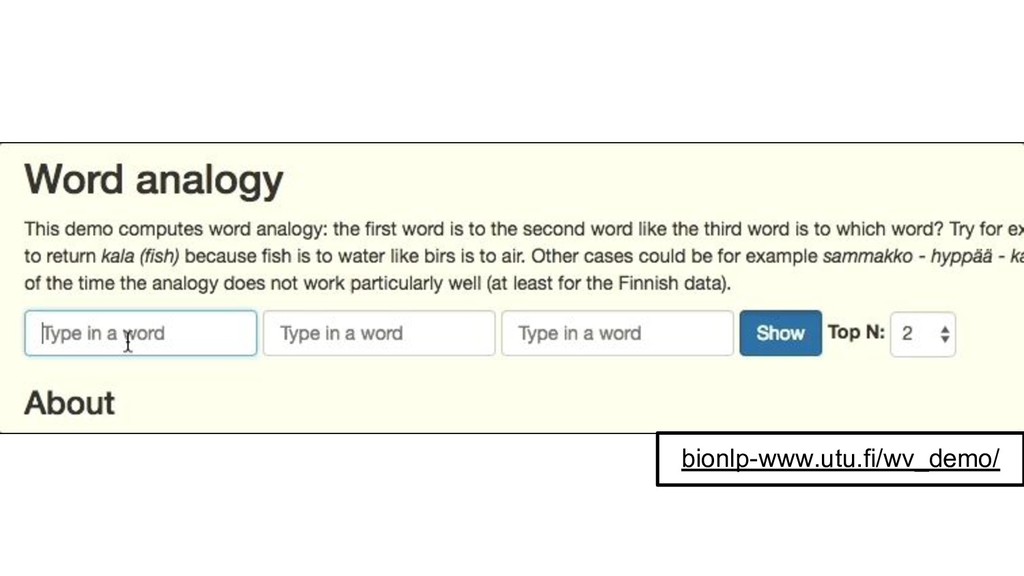{kind=link}
{kind=link}
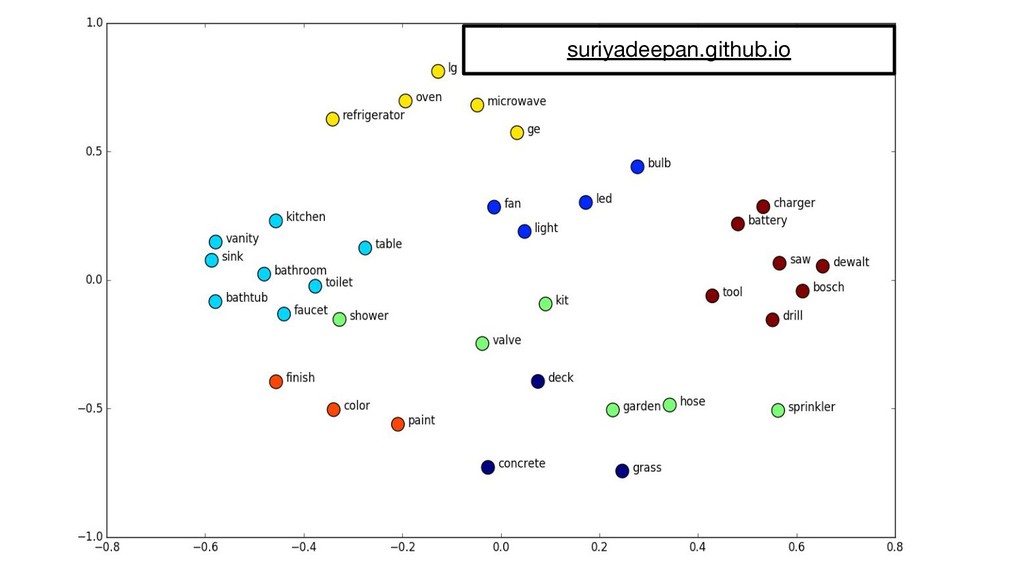{kind=link}
{kind=link}
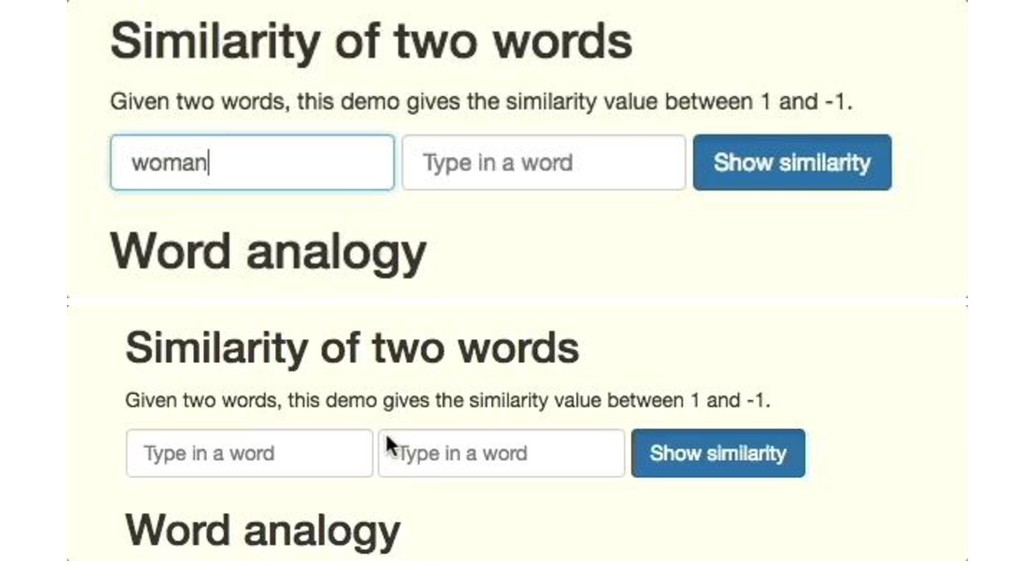{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}