詳細は、@sinhrks のさん下記を参照ください Python Dask.Array で 並列 / Out-Of-Core 処理 http://sinhrks.hatenablog.com/entry/2015/12/13/215858 u joblib でも並列処理可能 u dask.distributed では、ipyparallel と同様にクラスタを作って、 並列分散処理ができる u 何も考えずに、data frame のデータを勝⼿に並列処理してく れる世界が早く来て欲しい。 joblib.Parallel(n_jobs = 4)(joblib.delayed(exec_sample)(i) for i in range(10))
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
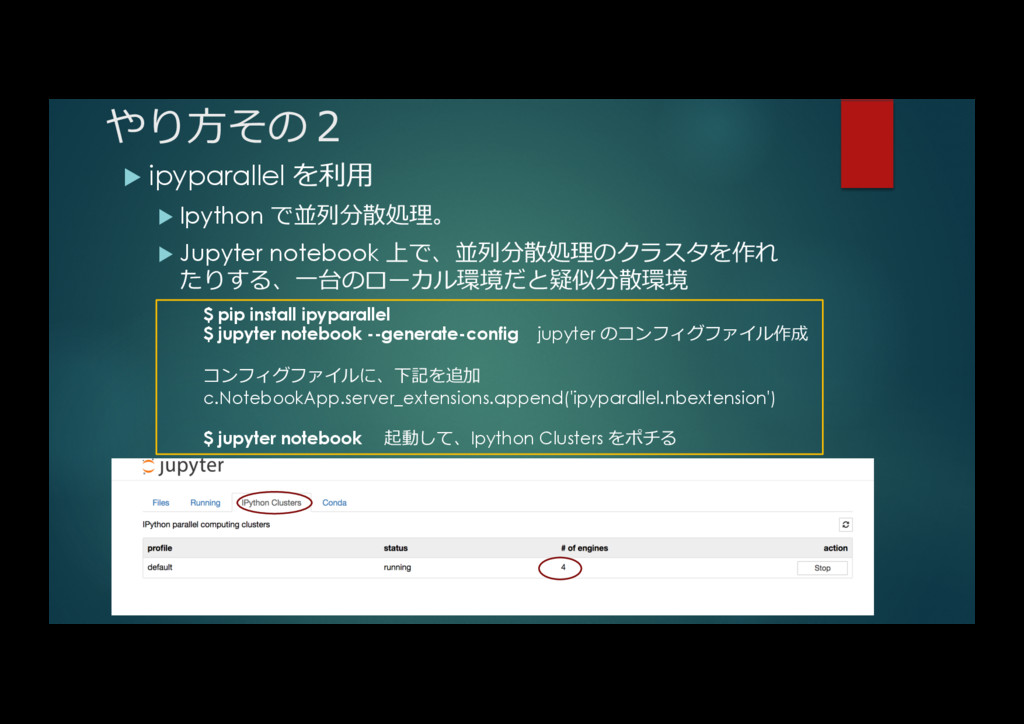{kind=link}
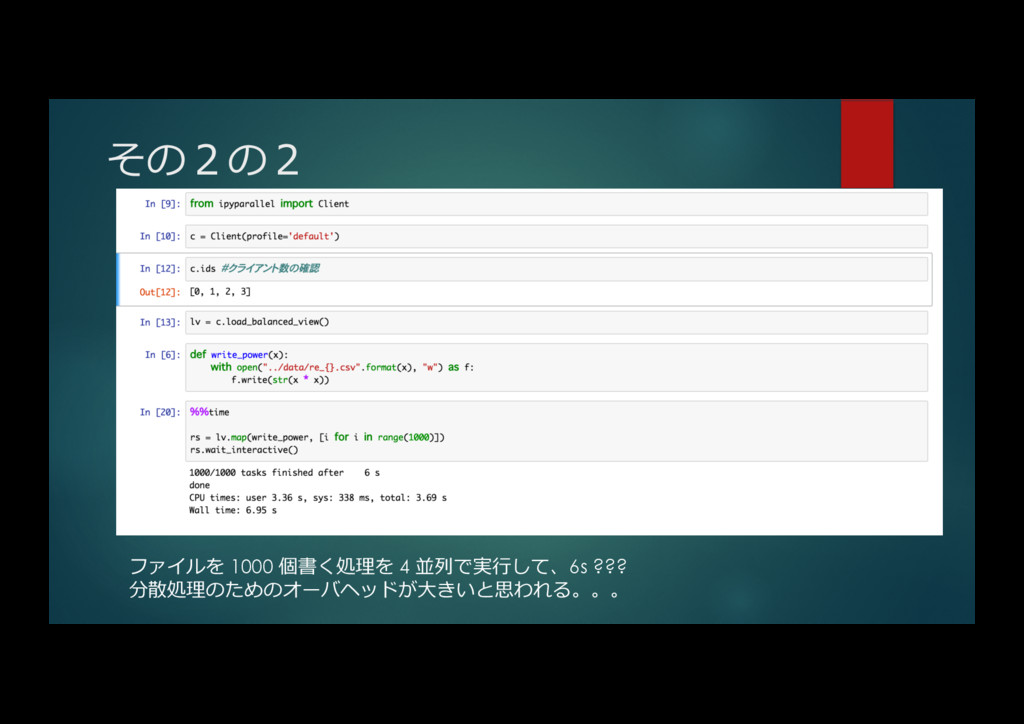{kind=link}
{kind=link}