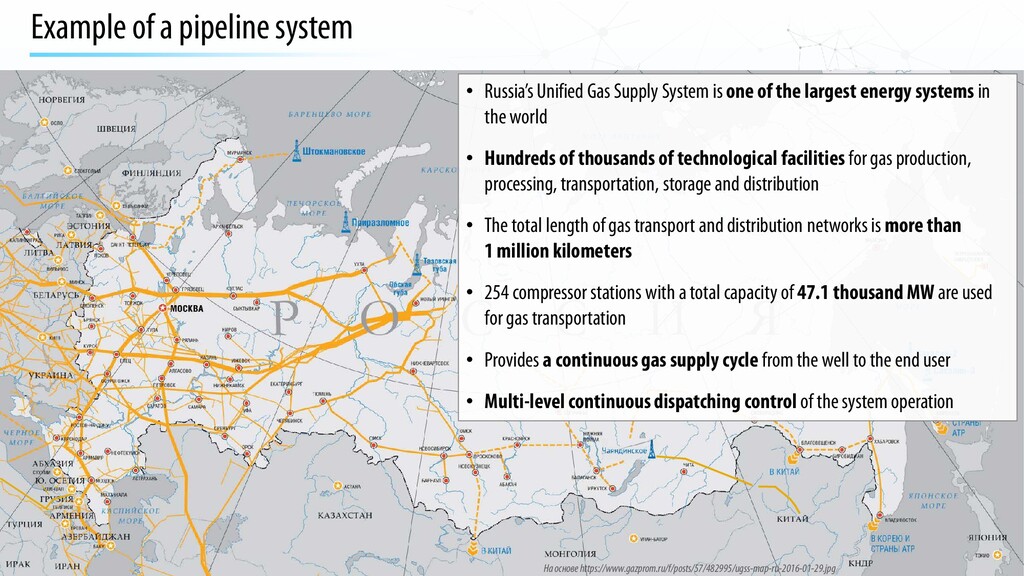
Supply System is one of the largest energy systems in the world • Hundreds of thousands of technological facilities for gas production, processing, transportation, storage and distribution • The total length of gas transport and distribution networks is more than 1 million kilometers • 254 compressor stations with a total capacity of 47.1 thousand MW are used for gas transportation • Provides a continuous gas supply cycle from the well to the end user • Multi-level continuous dispatching control of the system operation На основе https://www.gazprom.ru/f/posts/57/482995/ugss-map-ru-2016-01-29.jpg
processes Large geographically distributed network structures Large amounts of technological information coming from telemetry systems in a mode close to real-time The big cost of management decision errors A large number of equipment with different characteristics, operating in a single technological mode
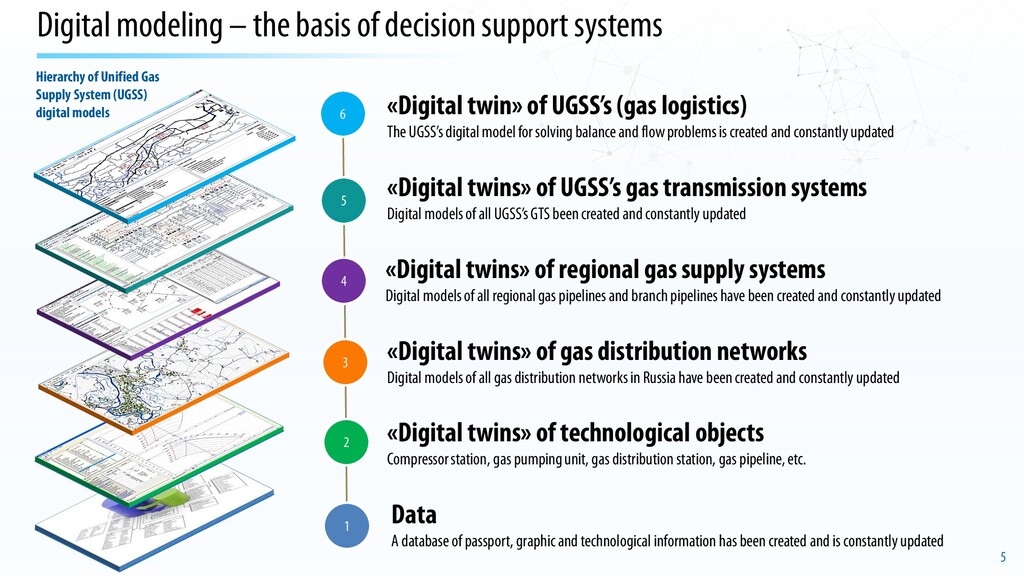
Hierarchy of Unified Gas Supply System (UGSS) digital models «Digital twins» of regional gas supply systems Digital models of all regional gas pipelines and branch pipelines have been created and constantly updated «Digital twin» of UGSS’s(gas logistics) The UGSS’s digital model for solving balance and flow problems is created and constantly updated 6 5 4 «Digital twins» of UGSS’s gas transmission systems Digital models of all UGSS’s GTS been created and constantly updated «Digital twins» of gas distribution networks Digital models of all gas distribution networks in Russia have been created and constantly updated 3 2 «Digital twins» of technological objects Compressor station, gas pumping unit, gas distribution station, gas pipeline, etc. Data A database of passport, graphic and technological information has been created and is constantly updated 1
of the Unified Gas Supply System of Russia) 40,6 billion m3 UGSS’s technological gas consumption in 2018 >1080 the number of optimization options at any given time (exceeds the number of atoms in the Universe) • Existing applied software do not allow us to effectively solve many current problems of real energy pipeline systems’ optimal control • People, even those equipped with modern applied software, are also not able to effectively solve problems of optimal pipeline systems’ control in real time Conceptual problems of existing applied software Benchmark –Google’s Self-Driving Data Center Management System 40 % actual energy savings Imperfection of existing technologies of complex engineering systems’ digital modeling is a barrier to improving the efficiency of modern energy management >400 million m3 per year effect when saving 1 % – exceeds the annual gas consumption of a large Russian city
local to entire system (multi-agent system) The need for coordinated decisions at all levels of control in real-time High dimension of the space of discrete-continuous control actions Stochastic dynamic systems A large effect of system’s optimization, including network topology optimization High inertia of technological processes
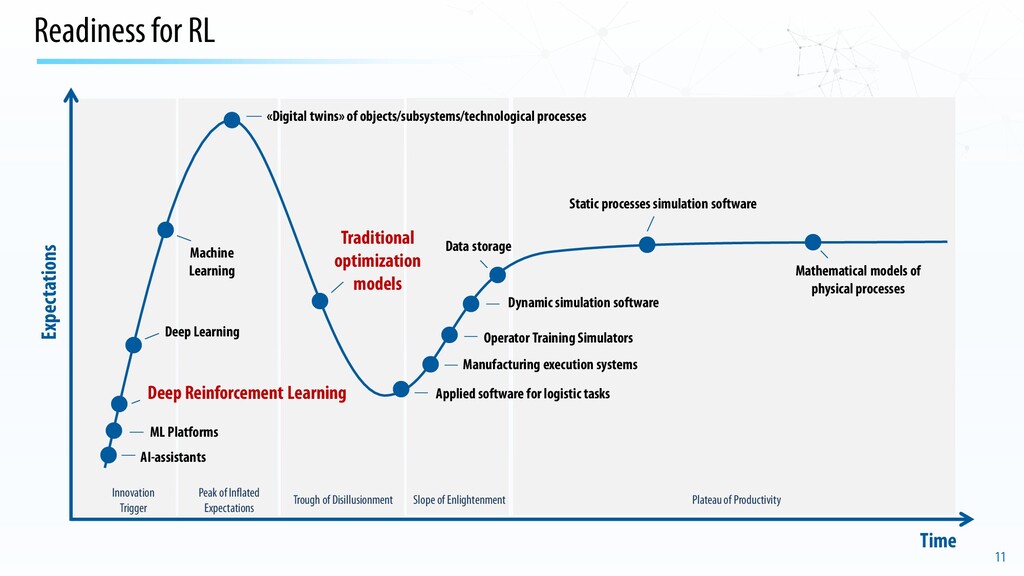
Peak of Inflated Expectations Trough of Disillusionment Slope of Enlightenment Plateau of Productivity Mathematical models of physical processes Operator Training Simulators «Digital twins» of objects/subsystems/technological processes Static processes simulation software Deep Learning Machine Learning AI-assistants ML Platforms Data storage Applied software for logistic tasks Manufacturing execution systems Dynamic simulation software Traditional optimization models
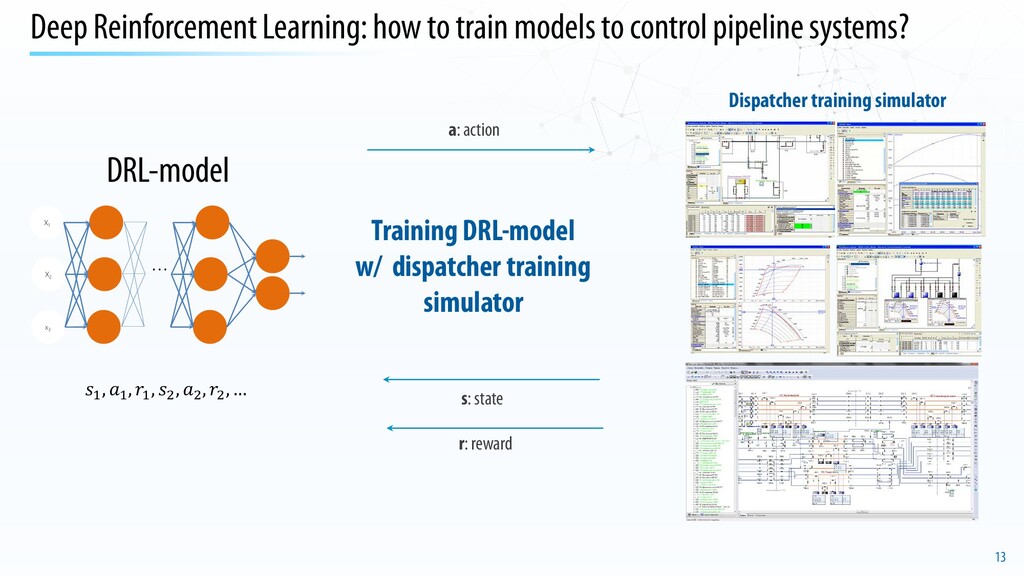
pipeline systems? Training center (Gubkin Russian state University of oil and gas) Dispatcher training simulator Formation of understanding: • how will the real system respond to actions • which of them are effective in different situations But how do people learn? person’s action system («digital twin») response
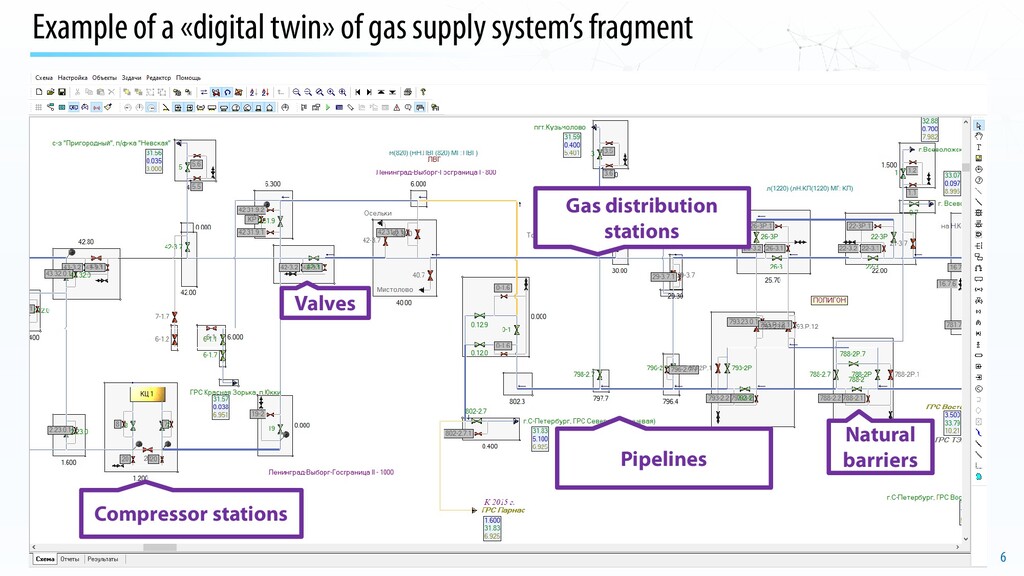
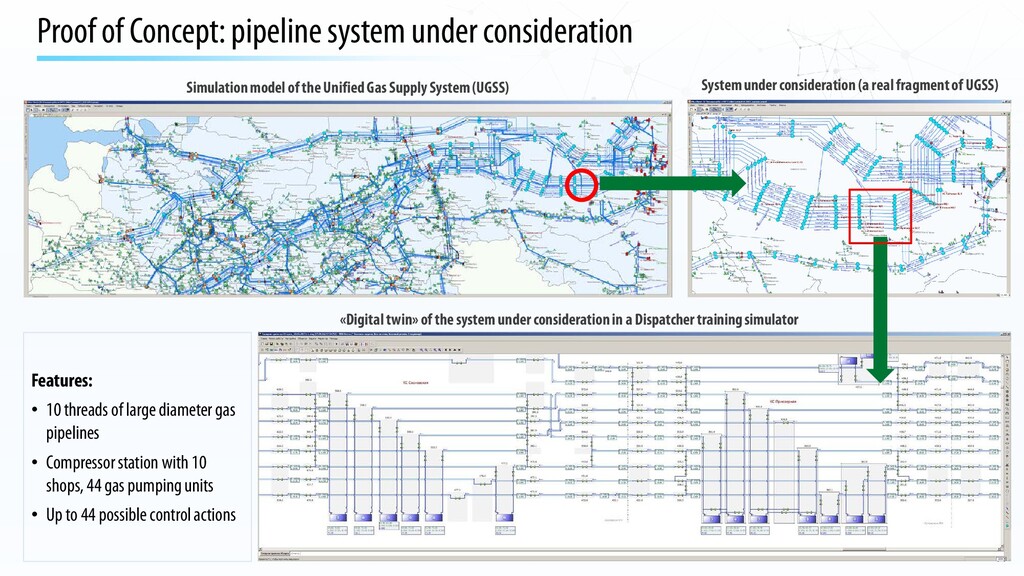
of the Unified Gas Supply System (UGSS) System under consideration (a real fragment of UGSS) «Digital twin»of the system under considerationin a Dispatcher training simulator Features: • 10 threads of large diameter gas pipelines • Compressor station with 10 shops, 44 gas pumping units • Up to 44 possible control actions
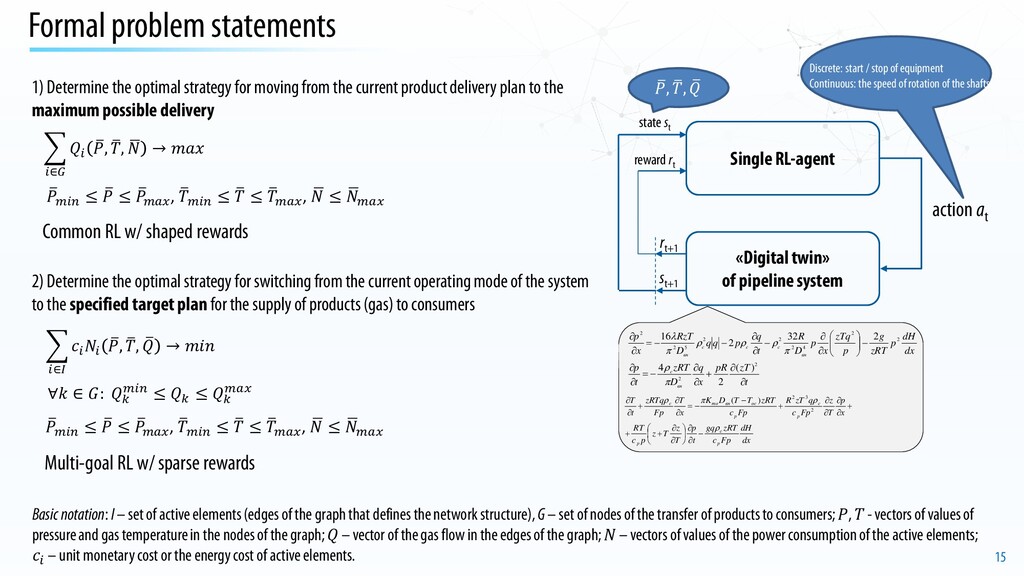
system rt+1 st+1 action at state st reward rt dx dH p zRT g p zTq x p D R t q p q q D RzT x p вн с c с вн 2 2 4 2 2 2 5 2 2 2 32 2 16 − ∂ ∂ − ∂ ∂ − − = ∂ ∂ π ρ ρ ρ π λ t zT pR x q D zRT t p вн с ∂ ∂ + ∂ ∂ − = ∂ ∂ 2 2 ) ( 2 4 π ρ dx dH Fp c zRT gq t p T z T z p c RT x p T z Fp c q zT R Fp c zRT T T D K x T Fp zRTq t T p с p p с p ос вн то с ρ ρ π ρ − ∂ ∂ ∂ ∂ + + + ∂ ∂ ∂ ∂ + − − = ∂ ∂ + ∂ ∂ 2 3 2 ) ( Basic notation: I – set of active elements (edges of the graph that defines the network structure), G – set of nodes of the transfer of products to consumers; , - vectors of values of pressure and gas temperature in the nodes of the graph; – vector of the gas flow in the edges of the graph; – vectors of values of the power consumption of the active elements; – unit monetary cost or the energy cost of active elements. Discrete: start / stop of equipment Continuous: the speed of rotation of the shafts � , � , � 1)Determine the optimal strategy for moving from the current product delivery plan to the maximum possible delivery Common RL w/ shaped rewards � ∈ � , � , � → 𝑚𝑚 � 𝑚𝑚 ≤ � ≤ � , � 𝑚𝑚 ≤ � ≤ � , � ≤ � 2)Determine the optimal strategy for switching from the current operating mode of the system to the specified target plan for the supply of products (gas) to consumers � 𝑚𝑚 ≤ � ≤ � , � 𝑚𝑚 ≤ � ≤ � , � ≤ � Multi-goal RL w/ sparse rewards � ∈ � , � , � → ∀ ∈ : 𝑚𝑚 ≤ ≤ 𝑎𝑎𝑎𝑎
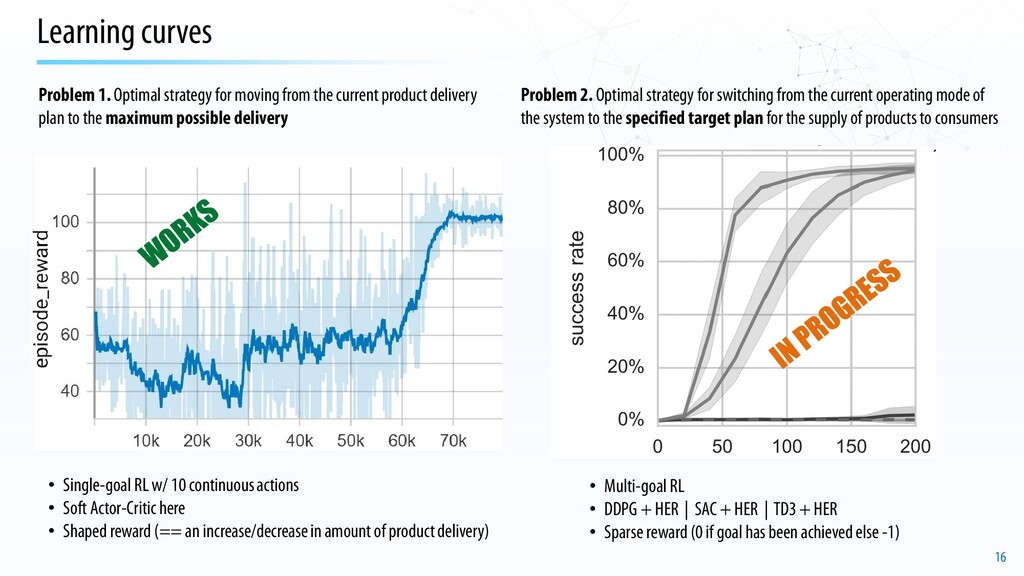
• Soft Actor-Critic here • Shaped reward (== an increase/decrease in amount of product delivery) Problem 1. Optimal strategy for moving from the current product delivery plan to the maximum possible delivery • Multi-goal RL • DDPG + HER | SAC + HER | TD3 + HER • Sparse reward (0 if goal has been achieved else -1) Problem 2. Optimal strategy for switching from the current operating mode of the system to the specified target planfor the supply of products to consumers
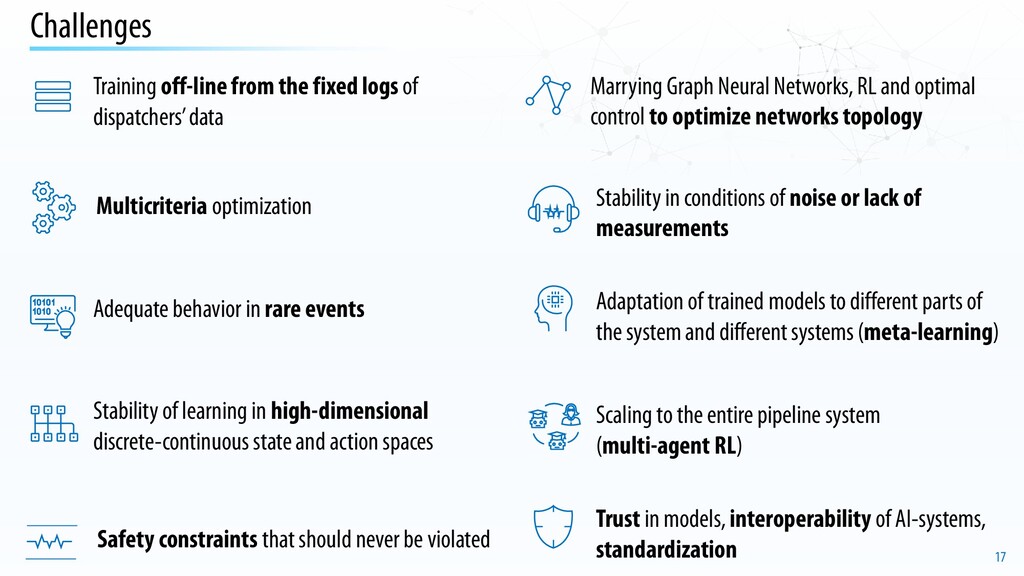
Trust in models, interoperability of AI-systems, standardization Adaptation of trained models to different parts of the system and different systems (meta-learning) Training off-line from the fixed logs of dispatchers’ data Adequate behavior in rare events Marrying Graph Neural Networks, RL and optimal control to optimize networks topology Stability of learning in high-dimensional discrete-continuous state and action spaces Safety constraints that should never be violated Stability in conditions of noise or lack of measurements Multicriteria optimization
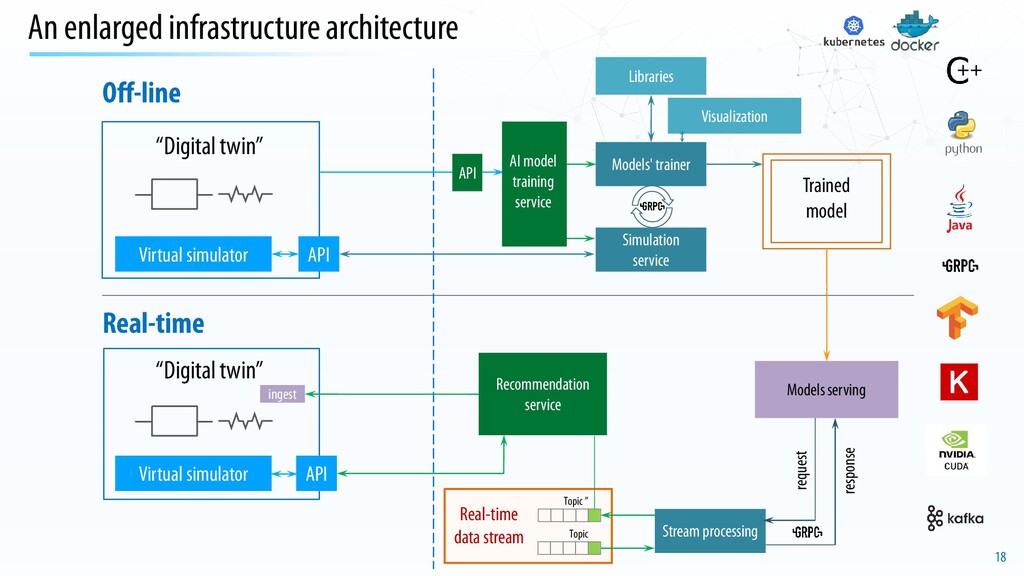
simulator Simulation service Models' trainer Libraries AI model training service Trained model “Digital twin” Topic ” Topic Real-time data stream Virtual simulator Stream processing request response Models serving Visualization API API Recommendation service ingest API
R&D on DRL projects A significant effect can be obtained from the implementation of DRL-projects There are a number of open questions for further R&D Thanks for your attention! Alexander BELINSKY М: 8-925-360-07-00 [email protected] www.ai-energy.ru
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}