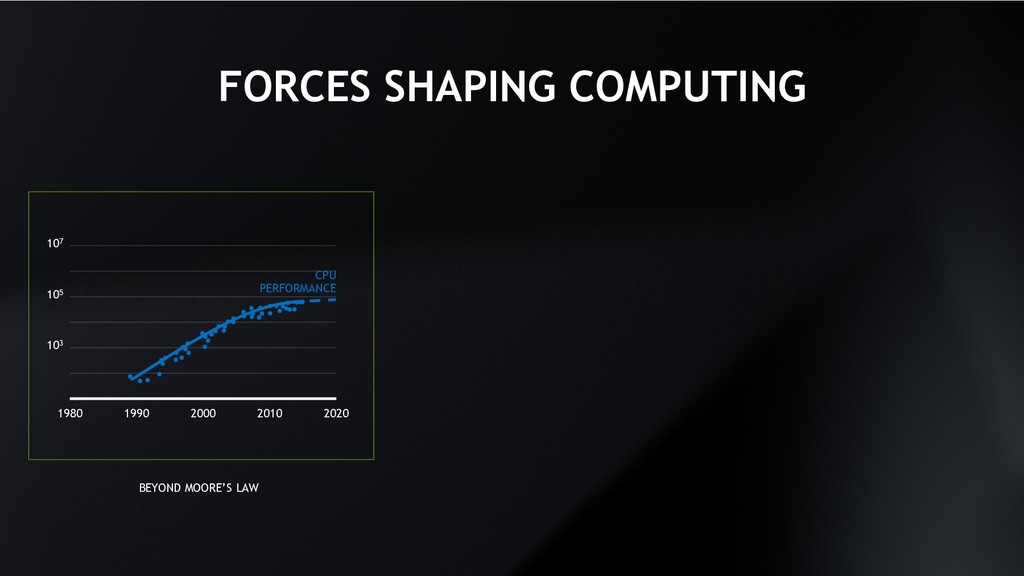
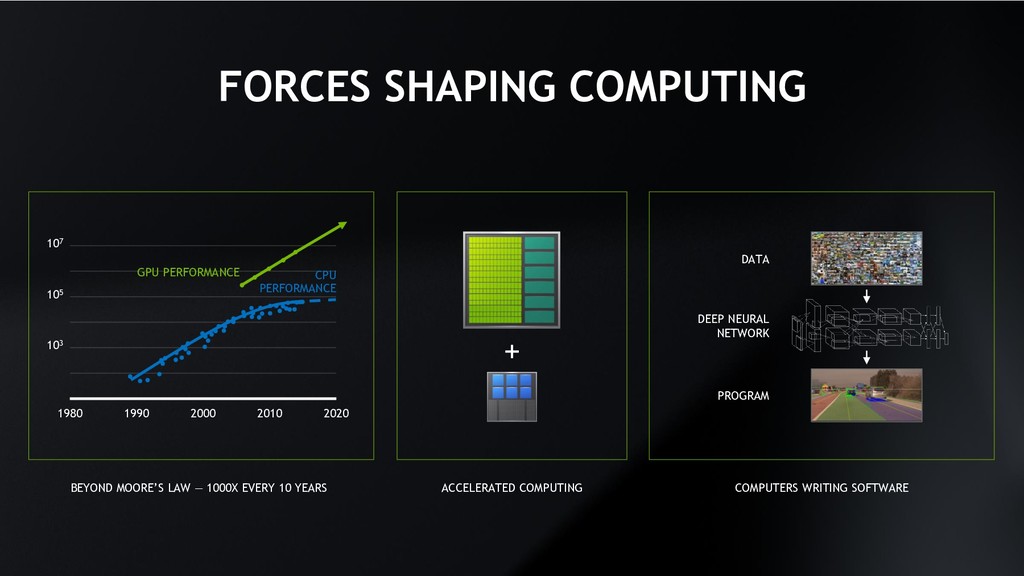
107 GPU PERFORMANCE CPU PERFORMANCE + BEYOND MOORE’S LAW — 1000X EVERY 10 YEARS ACCELERATED COMPUTING COMPUTERS WRITING SOFTWARE DATA DEEP NEURAL NETWORK PROGRAM
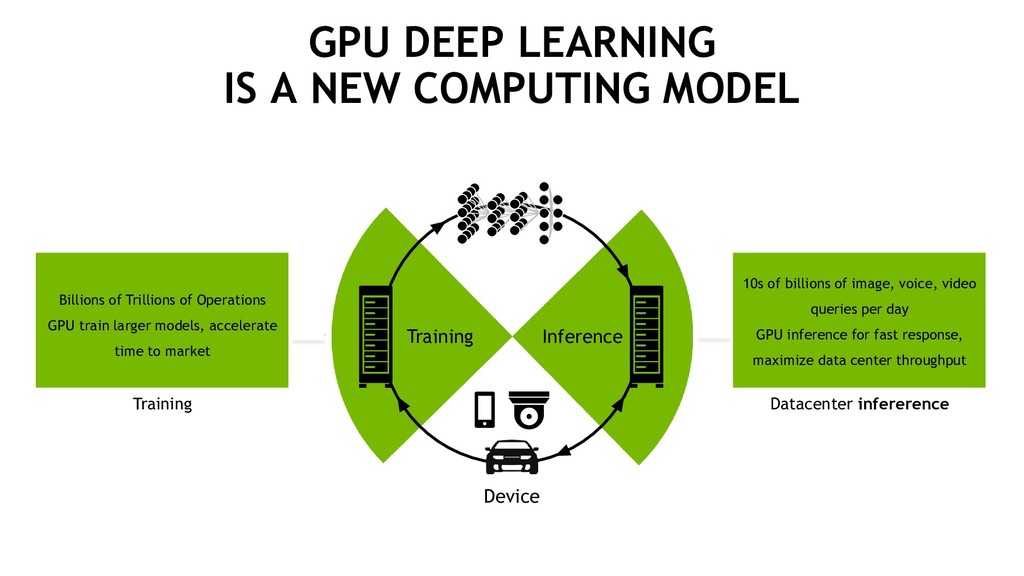
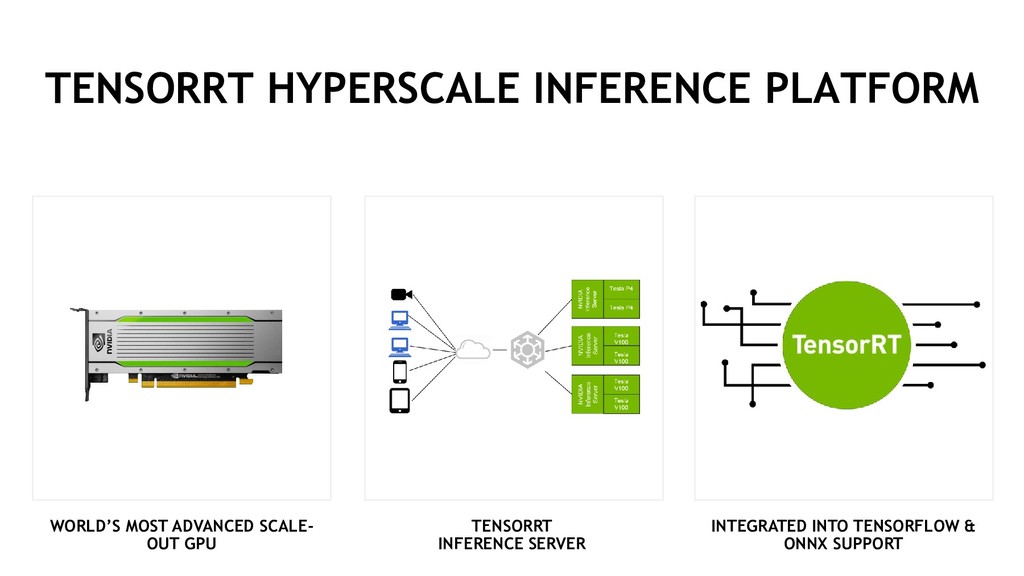
MODEL Training Billions of Trillions of Operations GPU train larger models, accelerate time to market Inference Datacenter infererence 10s of billions of image, voice, video queries per day GPU inference for fast response, maximize data center throughput
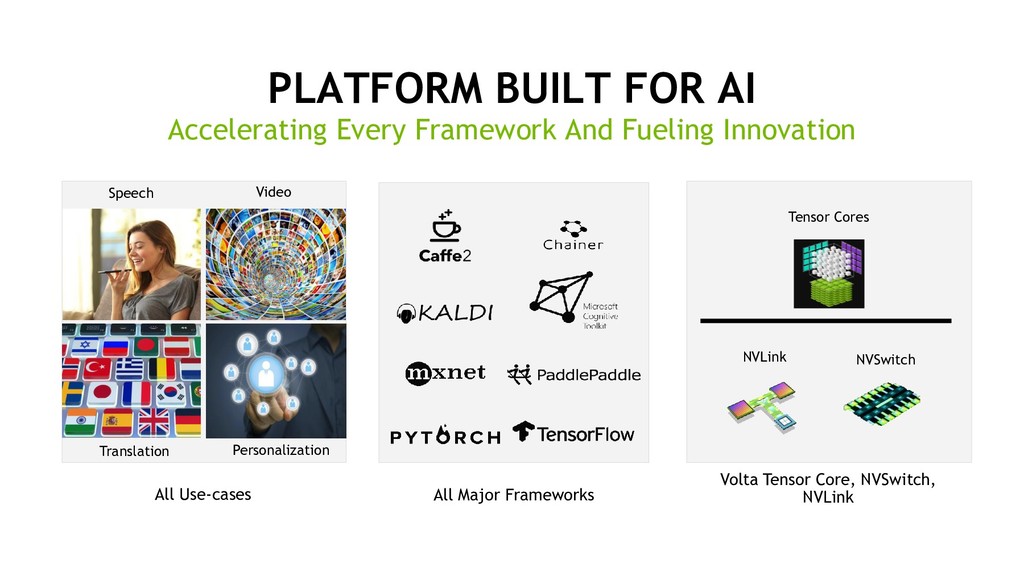
Innovation All Major Frameworks All Use-cases Speech Video Translation Personalization Volta Tensor Core, NVSwitch, NVLink Tensor Cores NVLink NVSwitch
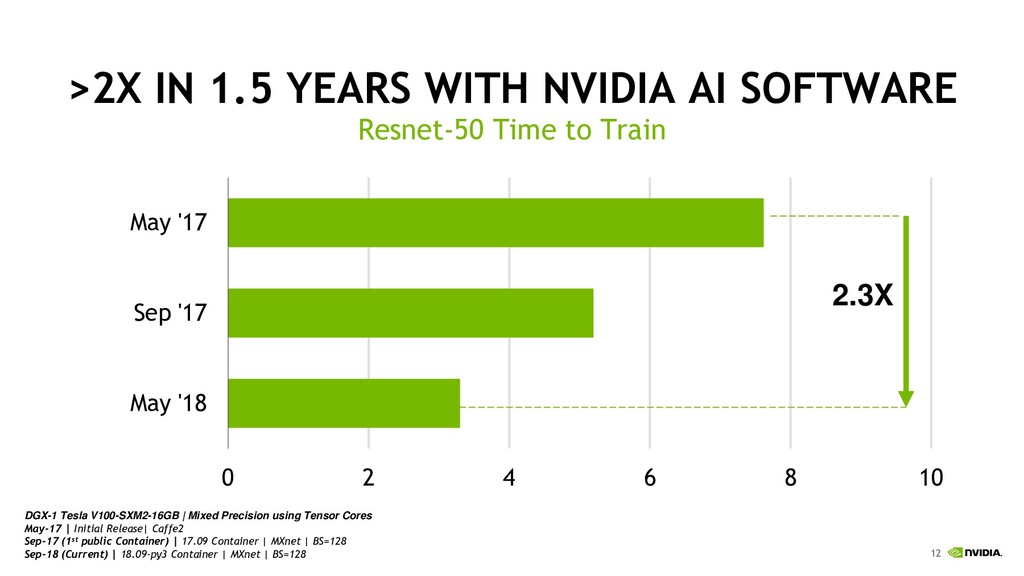
20 40 60 80 100 120 140 2x CPU Single Node 1X P100 Single Node 1X V100 DGX-1 8x V100 At scale 2176x V100 Relative Time to Train Improvements (ResNet-50) ResNet-50, 90 epochs to solution | CPU Server: dual socket Intel Xeon Gold 6140 Sony 2176x V100 record on https://nnabla.org/paper/imagenet_in_224sec.pdf <4 Minutes 3.3 Hours 25 Days 30 Hours 4.8 Days
CPU Servers 60 KWatts INFERENCE WORKLOAD: Speech, NLP and Video 1 T4-Accelerated Server 2 KWatts INFERENCE WORKLOAD: Speech, NLP and Video CPU-Only GPU-Accelerated 5 Racks in a Box
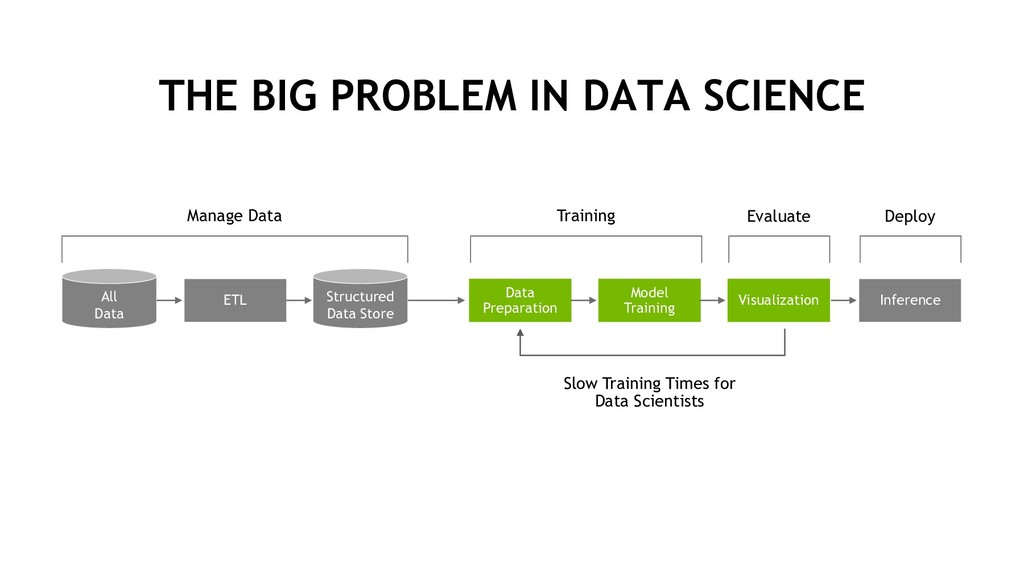
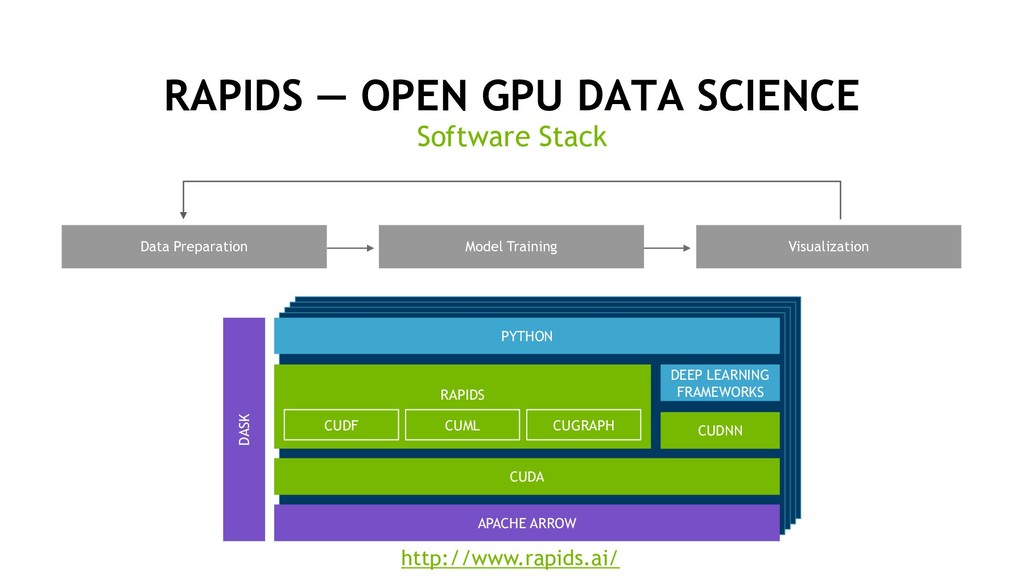
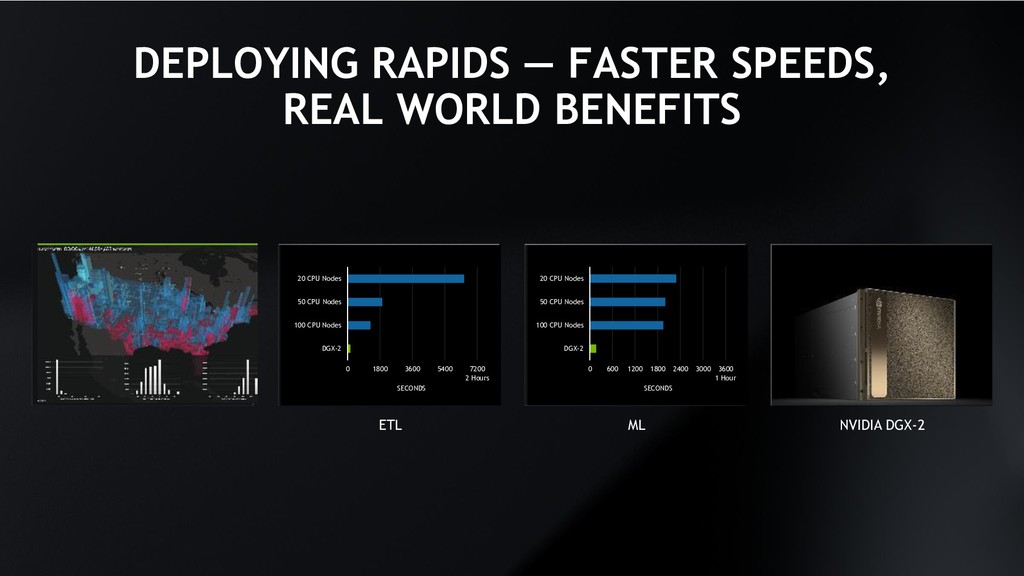
Manage Data Structured Data Store Data Preparation Training Model Training Visualization Evaluate Inference Deploy Slow Training Times for Data Scientists
Servers 180 KWatts Machine Learning: XGBoost 1 DGX-2 10 KWatts Machine Learning: XGBoost GPU-Accelerated CPU-Only Cluster SAME THROUGHPUT 1/8 THE COST 1/18 THE POWER 1/30 THE SPACE
HPC deployments are complex and time consuming to build, test and maintain Development of software frameworks by the community is moving very fast Requires high level of expertise to manage driver, library, framework dependencies NVIDIA Libraries NVIDIA Container Runtime NVIDIA Driver NVIDIA GPU Applications or Frameworks
SOLVING CHALLENGES NGC Accelerated Stacks for AI, Machine Learning, and HPC Research & Development Catapulting graphics industry into the AI chapter Autonomous Cars Super-real-time simulation for self-driving development Robotics Simulation of the real world to train robots RTX Graphics Real-time ray tracing and AI for creative applications
Practices Lessons learned from building the worlds largest AI Infrastructure Reference Architectures Partner Reference Architectures, Scale up racks Product Innovation & Quality Rapid exploration & resolution of customer issues
the foundation of SATURNV • Platform for NVIDIA’s MLPerf submission • Composed of DGX-1 and DGX-2 nodes, integrated rapidly (DGX POD) • Top60 class supercomputing cluster built in under 3 weeks • Differentiated architecture, breakthrough performance Our Latest Proof Point of Infrastructure Design Leadership
![AI TODAY AND TOMORROW Dmitry Konyagin | [email protected]](https://files.speakerdeck.com/presentations/42edae2f3eea4c6c8b72de96e29ee05c/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}