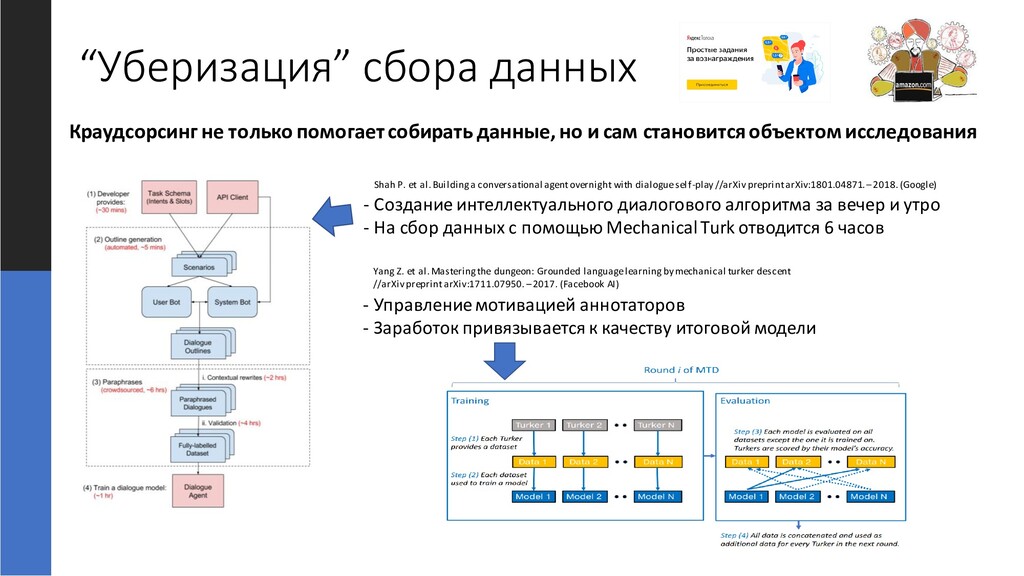
и сам становится объектом исследования Shah P. et al. Building a conversational agent overnight with dialogue self-play //arXiv preprint arXiv:1801.04871. –2018. (Google) - Создание интеллектуального диалогового алгоритма за вечер и утро - На сбор данных с помощью Mechanical Turk отводится 6 часов - Управление мотивацией аннотаторов - Заработок привязывается к качеству итоговой модели Yang Z. et al. Mastering the dungeon: Grounded language learning by mechanical turker descent //arXiv preprint arXiv:1711.07950. –2017. (Facebook AI)
многих языков есть модели, качественно распознающие и синтезирующие речь Развитие речевых технологий • Современные смартфоны с голосовым вводом • Популярность других устройств с голосовым управлением (колонки, «умные дома», экраны) Широкое распространение голосовыхустройств • Крупнейшие IT-компании развивают собственных голосовых ассистентов Конкуренция за данные пользователей
ответа Выбор шаблонной фразы ("температура: N градусов") Подстановка данных ("N = 10") Преобразование текста в речь 2. Анализ смысла Классификация интента ("вопрос о температуре") Извлечение сущностей ("дата: завтра, "место": Москва) 1. Перевод речи в текст Распознавание языка Преобразование в текст
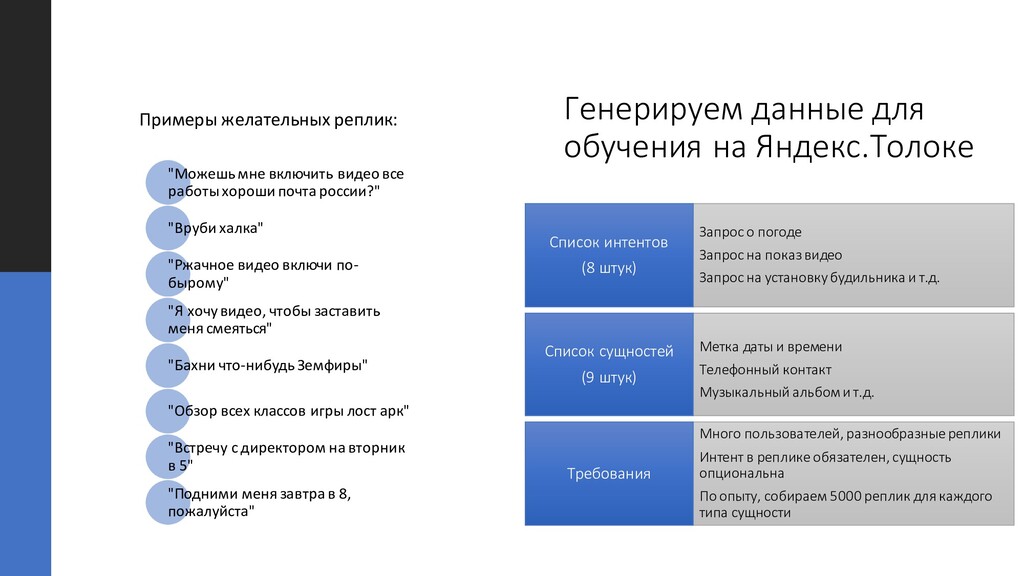
на показ видео Запрос на установкубудильника и т.д. Список интентов (8 штук) Метка даты и времени Телефонный контакт Музыкальный альбоми т.д. Список сущностей (9 штук) Много пользователей, разнообразные реплики Интент в репликеобязателен, сущность опциональна По опыту, собираем 5000 реплик для каждого типа сущности Требования "Можешь мне включить видео все работы хороши почта россии?" "Вруби халка" "Ржачное видео включи по- бырому" "Я хочу видео, чтобы заставить меня смеяться" "Бахни что-нибудь Земфиры" "Обзор всех классов игры лост арк" "Встречу с директором на вторник в 5" "Подними меня завтра в 8, пожалуйста" Примеры желательных реплик:
инструкции, детализировать задания Написали инструкцию Указали тему (интент) Попросили использовать сущности В результате, много реплик оказались мусором, часть релевантных оказалась не тем чем надо, сленг и обращения оказались непокрытыми "hgjkfshgkdfhjgkjdfhgkjdfhg" Бессмысленные наборы символов "Напишите вопрос о погоде на завтра (вторник)" Куски инструкции к заданию "Погода на завтра"/"Погода на вторник" Однообразные реплики "Надвор'е ў аўторак" Реплики на другом языке Мусор
и ручную проверки Уточнили инструкции и настройки пулов Перешли на детальные задания с ограничениями Все заработало ☺ Виды ограничений •Вопрос или просьба/указание •Максимальная/минимальная длина реплики •Наличие/отсутствие сущностей •Ограничения на вид сущностей •Ограничения на комбинации сущностей •Наличие/отсутствие указанных слов
содержание Попросить включить смешное видео. Не использовать слово "смешной" В вопросительной форме попросить сказать погоду на завтра в каком-то месте, использовать не менее 6 слов Запросить информацию о погоде в следующий вторник, не используя слово "погода" Попросить позвонить кому-нибудь из коллег, используя не более 3 слов и не используя слово "позвони" Потребоватьвключить песню какой-нибудь группы, употребив хотябы одно нецензурноеслово
Пишем подробную инструкцию Ставим тройное перекрытие Отправляем на разметку часть данных Фильтруем Отбираем реплики с согласованностью2/3 и 3/3 по всем сущностям Корректируем На корректных репликах обучаем модель NER Проверяем спорные реплики NER на совпадениес известными сущностями Авторазмечаемостальныеданные
балансировкисохранили частьреплик без сущностей(до 25%) Получилось~53К итоговых реплик Обучили тестовую модель Модель RuBERT отDeepPavlov Обучалимоделина различныхэтапах разметки Итоговая F1-мера длякаждого типа сущности на тестепревысила0.8 Получили пайплайн разметки Отработана генерация новых данных с помощьюкраудсорсинга
польским сразу возникли проблемы Толока • Мало польскоговорящих работников, очень медленная некачественная генерация Amazon Mechanical Turk • Официальная регистрация из РФ недоступна, получили два бана • Платформа не поддерживает фильтры пользователей за "быстрые" ответы Microworkers • Можно размечать с хорошим качеством, но очень медленно (250 реплик за неделю) Figure Eight • Платформа технически не позволила перейти от этапа формулировки задачик этапу загрузки конкретных заданий, поддержка доступна после покупки лицензии за 15000$
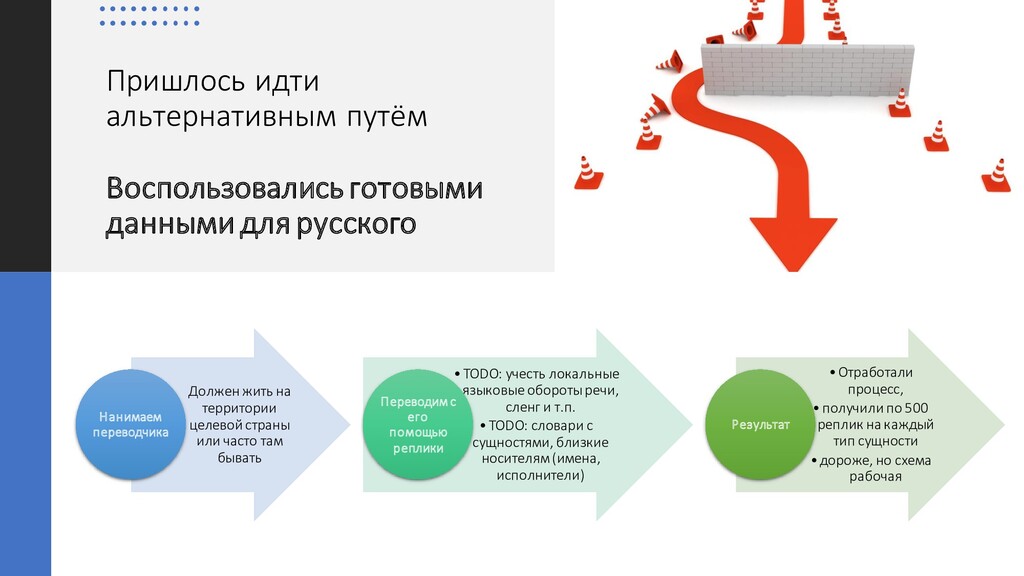
жить на территории целевой страны или часто там бывать Нанимаем переводчика •TODO: учесть локальные языковыеоборотыречи, сленг и т.п. •TODO: словари с сущностями, близкие носителям(имена, исполнители) Переводим с его помощью реплики •Отработали процесс, •получили по 500 реплик на каждый тип сущности •дороже, но схема рабочая Результат
под определенные слова, которые встретились только в некоторых классах, но на самом деле не являются важными. Пожалуйста, запусти Youtube play_music Я хочу пройти на Красную Площадь, чтобы сделать селфи с Лениным take_selfie Запусти в поисках Немо no intent Проложи маршрут от дома до Красной Площади CLS Нейронная сеть Классификатор intent: navigate - - - src - dst dst Метки параметров (слотов) для каждого слова
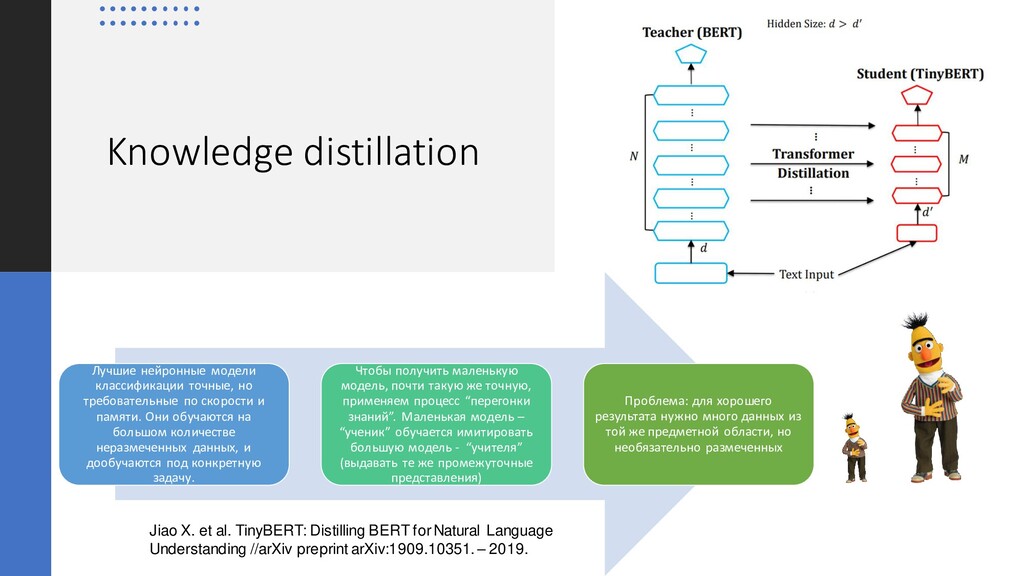
Natural Language Understanding //arXiv preprint arXiv:1909.10351. – 2019. Лучшие нейронные модели классификации точные, но требовательные по скорости и памяти. Они обучаются на большом количестве неразмеченных данных, и дообучаются под конкретную задачу. Чтобы получить маленькую модель, почти такую же точную, применяем процесс “перегонки знаний”. Маленькая модель – “ученик” обучается имитировать большую модель - “учителя” (выдавать те же промежуточные представления) Проблема: для хорошего результата нужно много данных из той же предметной области, но необязательно размеченных
все еще не хватает • Недостаточно разнообразны Точность моделирования нужно повышать • Можем обучить модель, с высокой точностью (~98%) на тестовой выборке, но точность значительно падает на реальных данных (~78%) Используем Data Augmentation • Искусственное расширение выборки (Data Augmentation) – это подход, позволяющий увеличить количество обучающих данных, а также сделать данные более разнообразными, а полученную модель – более устойчивой к небольшим изменениям распределения данных
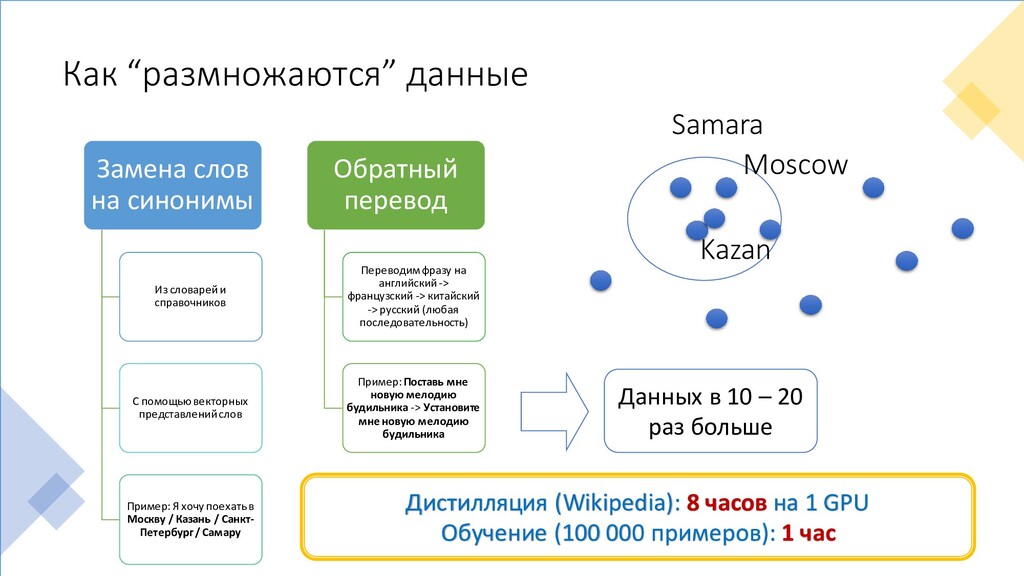
Из словарей и справочников С помощью векторных представлений слов Пример: Я хочу поехать в Москву / Казань / Санкт- Петербург / Самару Обратный перевод Переводим фразу на английский -> французский -> китайский -> русский (любая последовательность) Пример: Поставь мне новую мелодию будильника -> Установите мне новую мелодию будильника Данных в 10 – 20 раз больше Дистилляция (Wikipedia): 8 часов на 1 GPU Обучение (100 000 примеров): 1 час
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}