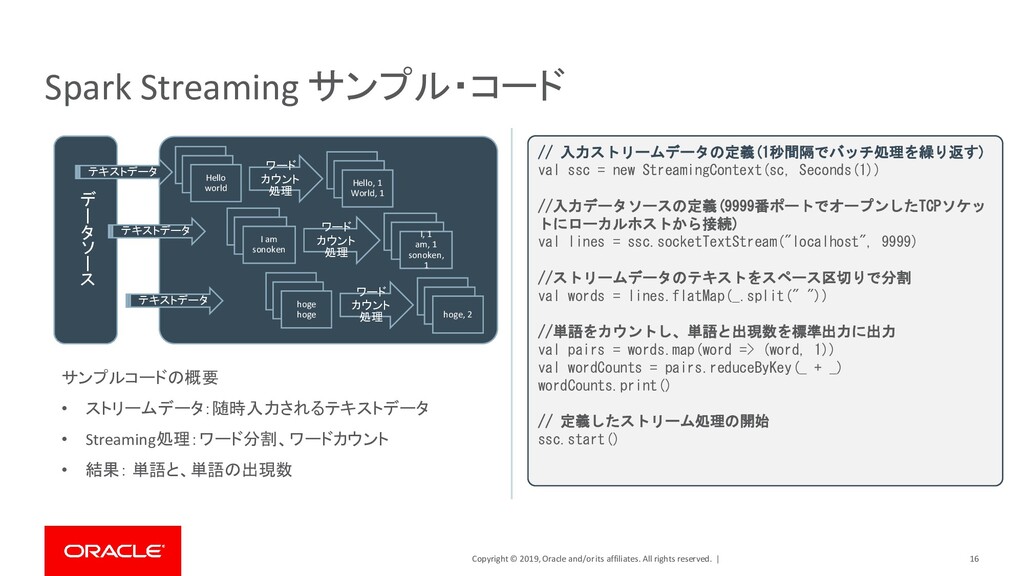
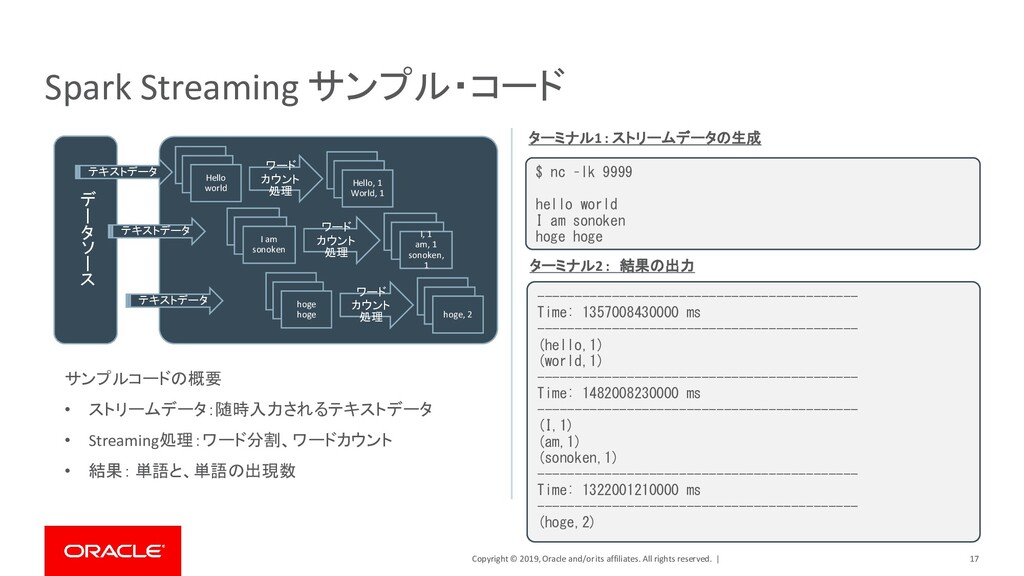
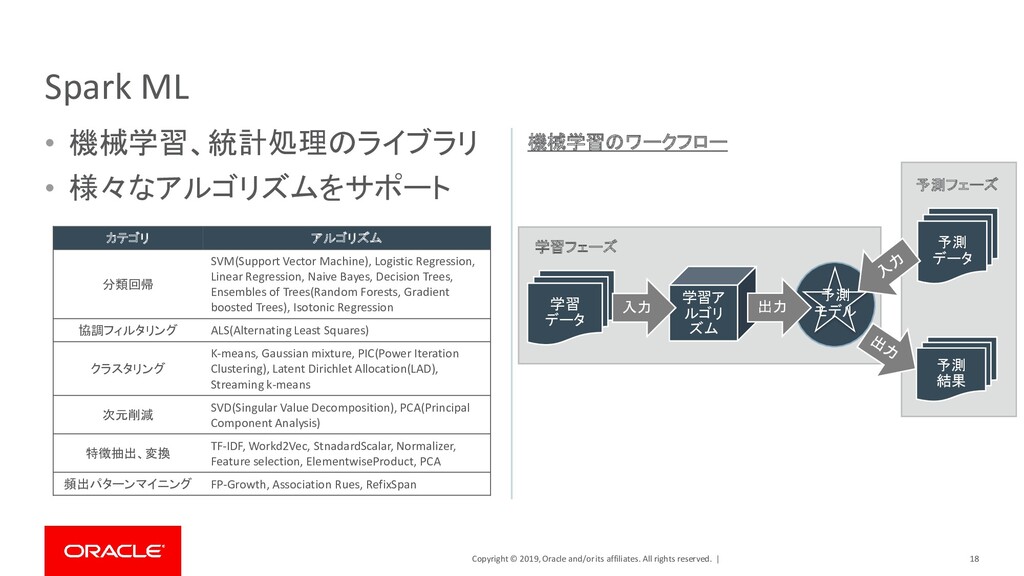
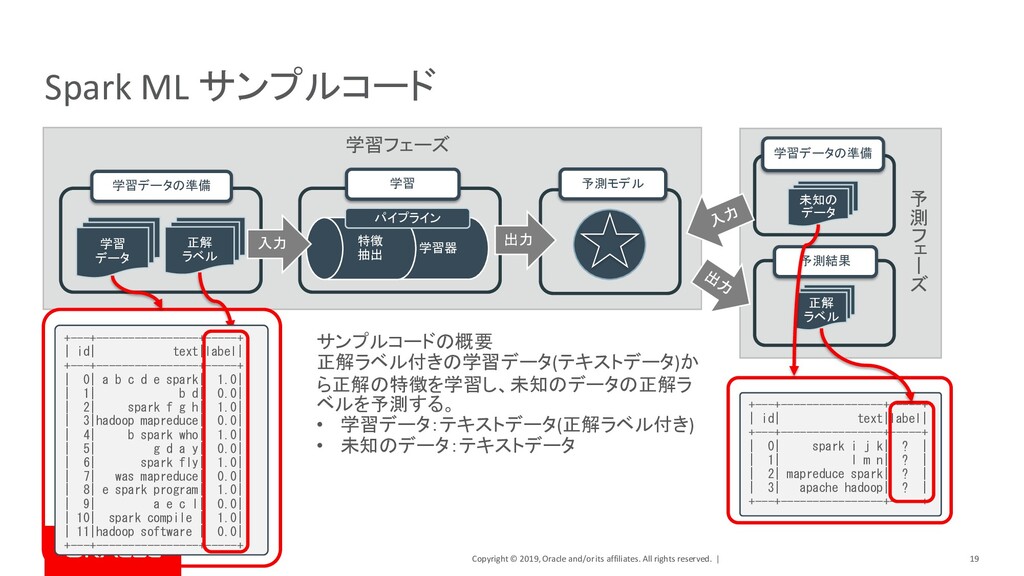
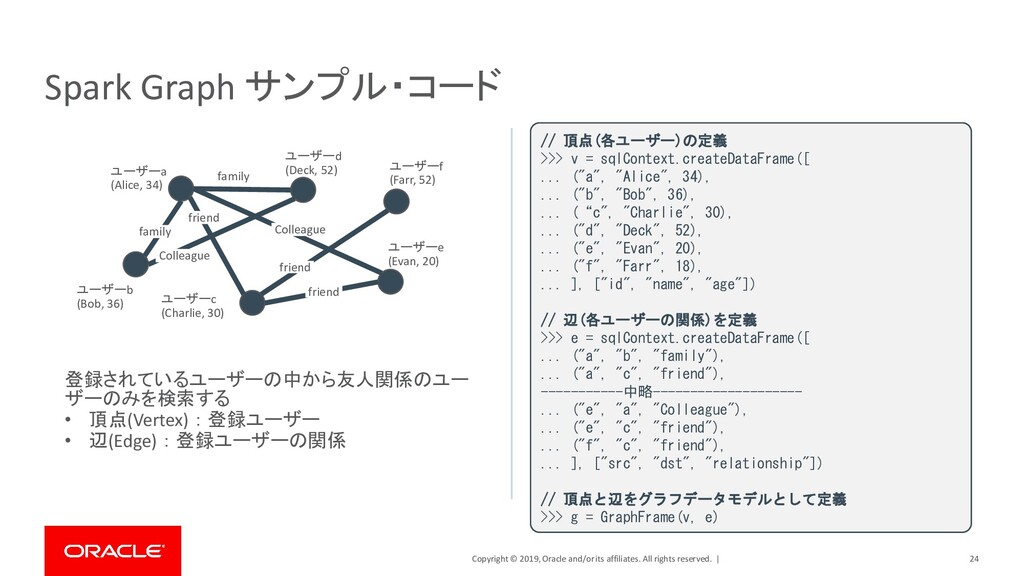
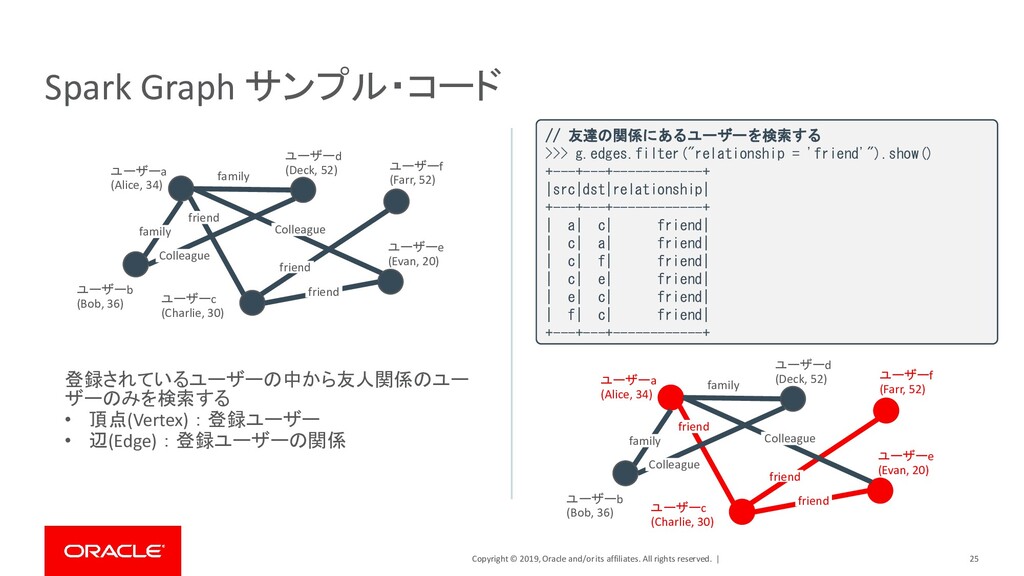
| 24 Spark Graph サンプル・コード ユーザーa (Alice, 34) ユーザーd (Deck, 52) ユーザーb (Bob, 36) ユーザーc (Charlie, 30) ユーザーe (Evan, 20) ユーザーf (Farr, 52) friend friend family family Colleague friend Colleague // 頂点(各ユーザー)の定義 >>> v = sqlContext.createDataFrame([ ... ("a", "Alice", 34), ... ("b", "Bob", 36), ... (“c", "Charlie", 30), ... ("d", "Deck", 52), ... ("e", "Evan", 20), ... ("f", "Farr", 18), ... ], ["id", "name", "age"]) // 辺(各ユーザーの関係)を定義 >>> e = sqlContext.createDataFrame([ ... ("a", "b", "family"), ... ("a", "c", "friend"), -----------中略-------------------- ... ("e", "a", "Colleague"), ... ("e", "c", "friend"), ... ("f", "c", "friend"), ... ], ["src", "dst", "relationship"]) // 頂点と辺をグラフデータモデルとして定義 >>> g = GraphFrame(v, e) 登録されているユーザーの中から友人関係のユー ザーのみを検索する • 頂点(Vertex) : 登録ユーザー • 辺(Edge) : 登録ユーザーの関係
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
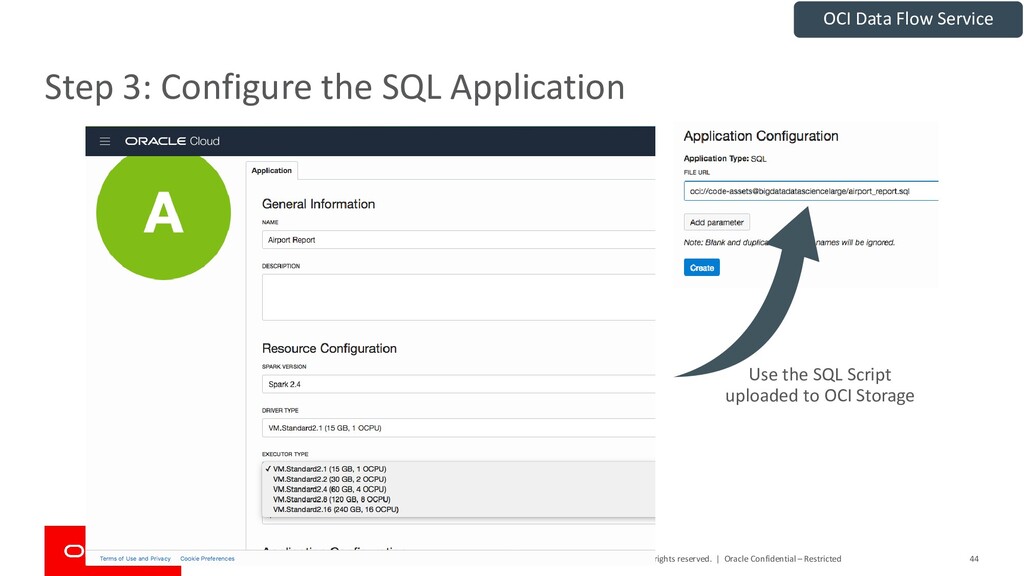{kind=link}
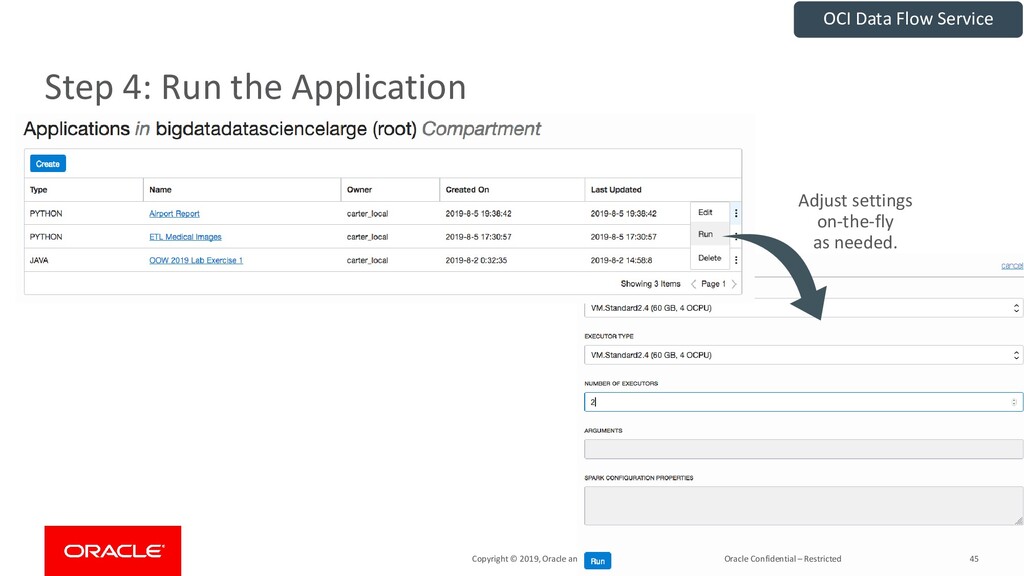{kind=link}
{kind=link}
{kind=link}
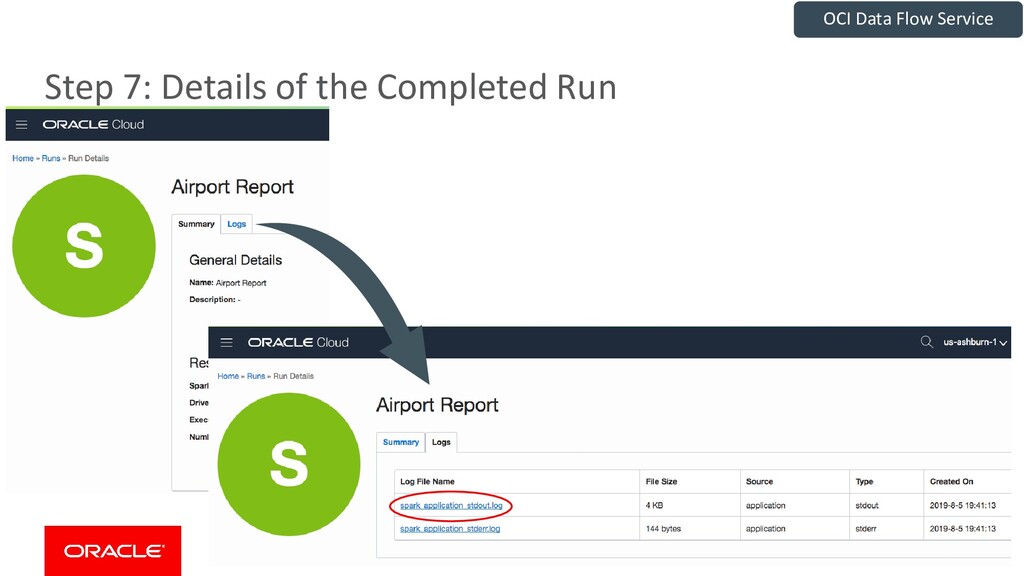{kind=link}
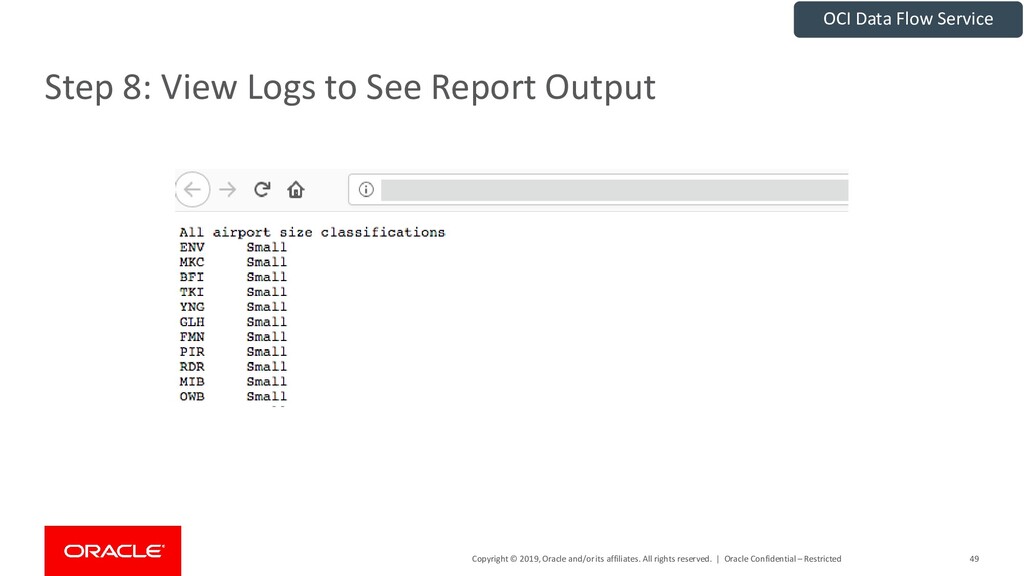{kind=link}
{kind=link}