the Pelias geocoder. Pelias is an open source, data-agnostic geocoder that we originally started building at Mapzen. Now you might have heard that Mapzen shut down last year, which is sad, but an amazing thing happened after that, where pretty much all the projects Mapzen started have continued on in some way. Score one for open source!
around geocoding and run geocode.earth, a hosted geocoding service. We’ve been able to keep working on and improving Pelias through our work. I want to talk a little bit about some of the problems we’ve solved, some of the problems we haven’t solved, and most importantly some of the ways OSM is uniquely suited to helping with geocoding in general, not just Pelias.
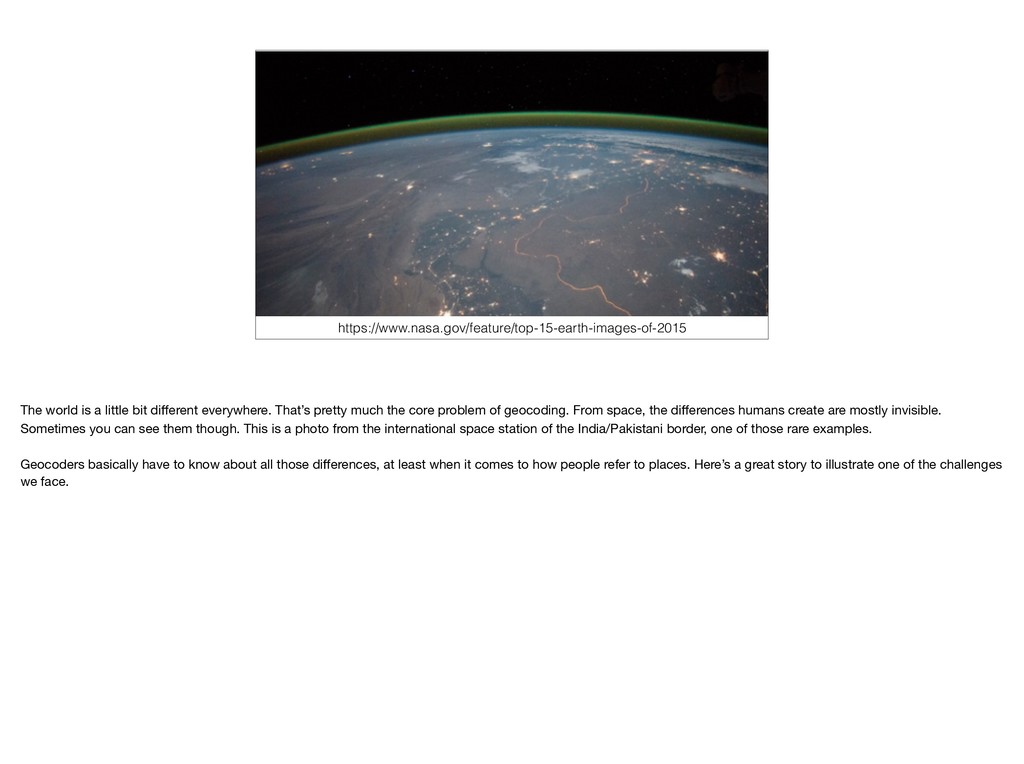
pretty much the core problem of geocoding. From space, the differences humans create are mostly invisible. Sometimes you can see them though. This is a photo from the international space station of the India/Pakistani border, one of those rare examples. Geocoders basically have to know about all those differences, at least when it comes to how people refer to places. Here’s a great story to illustrate one of the challenges we face.
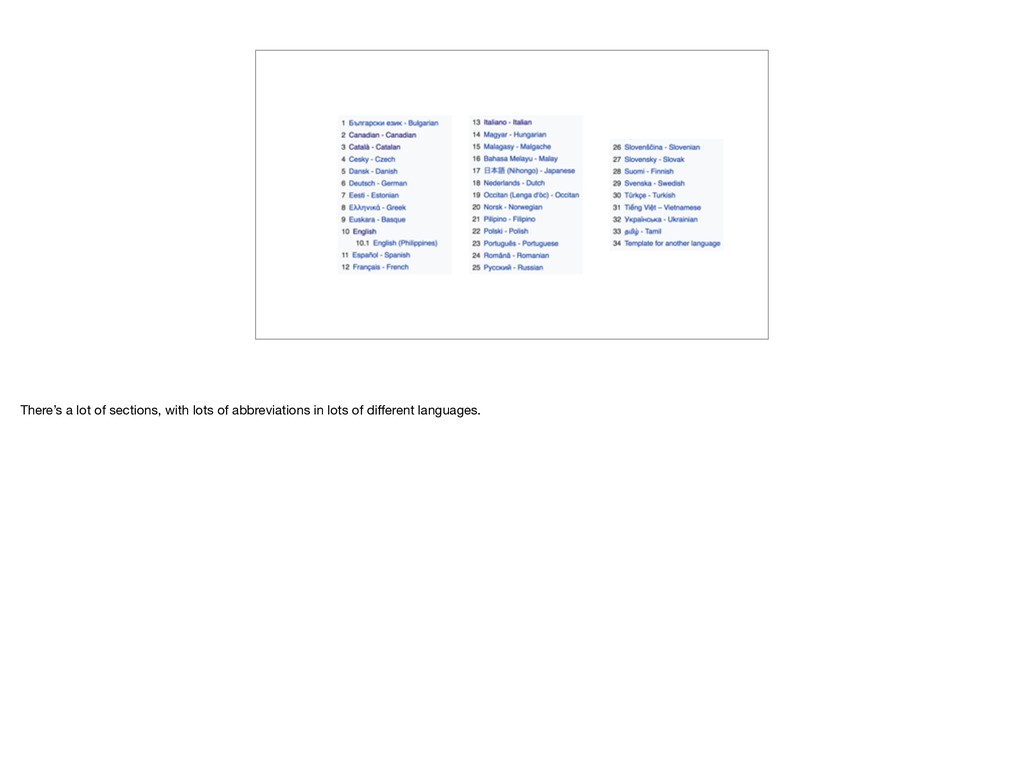
to something different in different places. In Germany, “st” expands to Sankt. Same meaning, same abbreviation, different spelling. So what do we need? Do we need a massive machine learning project to deduce the right behavior in every country? Probably not. We can get pretty far with a list of different abbreviations in different places.
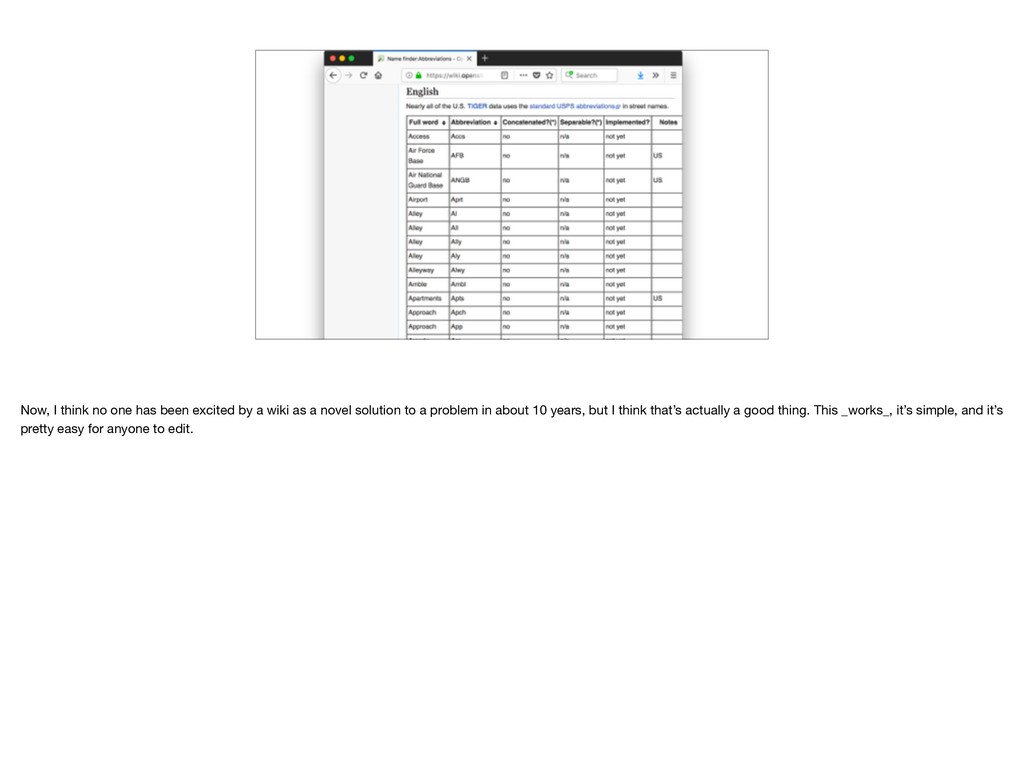
wiki as a novel solution to a problem in about 10 years, but I think that’s actually a good thing. This _works_, it’s simple, and it’s pretty easy for anyone to edit.
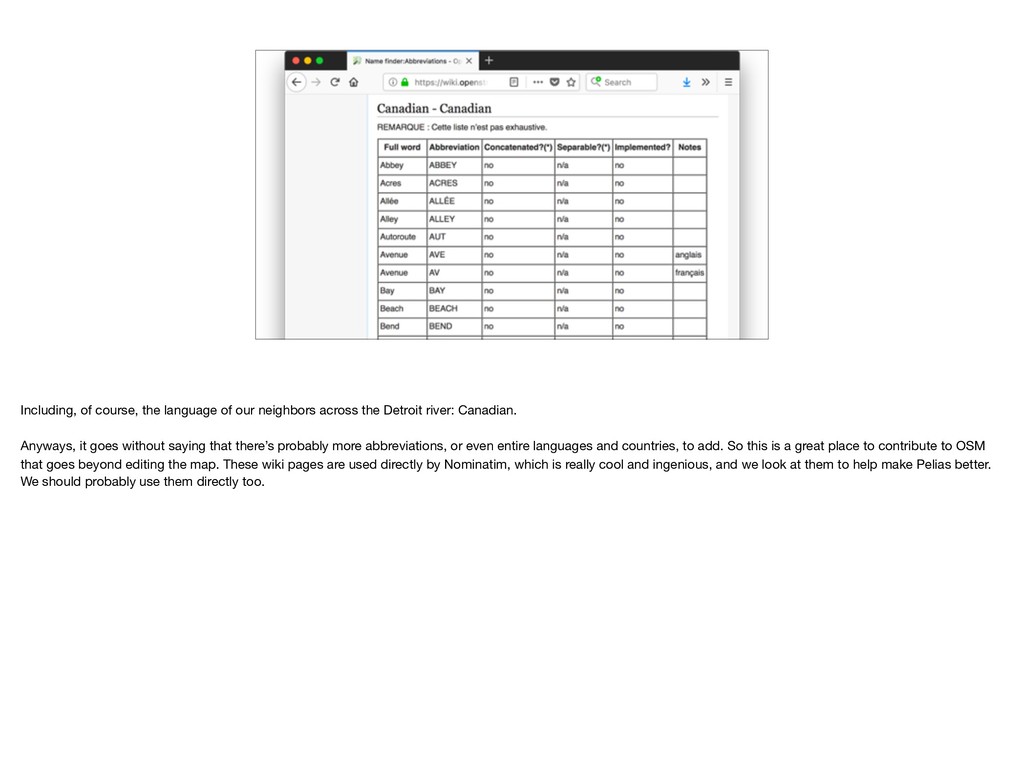
Detroit river: Canadian. Anyways, it goes without saying that there’s probably more abbreviations, or even entire languages and countries, to add. So this is a great place to contribute to OSM that goes beyond editing the map. These wiki pages are used directly by Nominatim, which is really cool and ingenious, and we look at them to help make Pelias better. We should probably use them directly too.
datasets out there. Many of them are just point data, like OpenAddresses. This can be really useful. Some datasets have polygon data. This can be useful too. But the _most_ useful of all are datasets that utilize both. OSM is one of them. All the examples I’m about to show comes from our work with the TriMet transit agency in Portland, Oregon (hence the cheesy image). Madeline Steele from their team was supposed to present here, and couldn’t make it, so I’ll do my best to show off some of the awesome work they’ve done, and the work we’ve done together.
screenshot of a route from Trimet’s trip planner. You might be wondering why it’s telling you to walk around to the BACK of the library. The answer is that for routing, you need a specific point to route to. Baring any other data, the best single point usually ends up being the centroid of the shape of the building, or something roughly equivalent. The centroid, oddly enough, was closest to the path going to the back of the building, so that explains the routing. But the solution here was already in OSM: entrance tags! Entrance tags perfectly solve the problem by specifying a point to go along with the shape of the building, for exactly where the door is.
results are perfect. Adding entrance tags to buildings of almost any size is a super useful way to add data that’s missing in quite a few places, even those that are pretty well mapped.
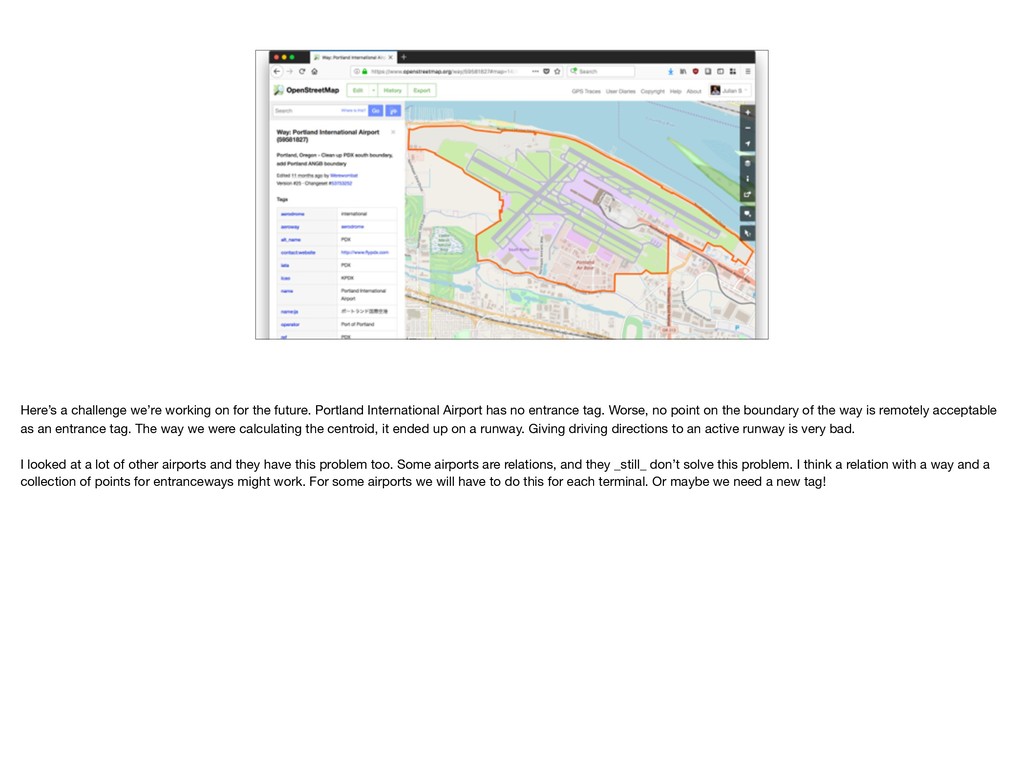
International Airport has no entrance tag. Worse, no point on the boundary of the way is remotely acceptable as an entrance tag. The way we were calculating the centroid, it ended up on a runway. Giving driving directions to an active runway is very bad. I looked at a lot of other airports and they have this problem too. Some airports are relations, and they _still_ don’t solve this problem. I think a relation with a way and a collection of points for entranceways might work. For some airports we will have to do this for each terminal. Or maybe we need a new tag!
you might cringe at the thought of coming up with consensus around a new tag, but really, the fact that we _can_ go through that process is one of OSMs strengths. No one knows how to build the perfect map, and OSM lets us all figure it out together. We probably need to make the process less painful, and we DEFINITELY need to have more voices involved in the discussion, but overall, it’s pretty awesome.
last problem I believe OSM can solve. Take a look at the two map screenshots above. They look pretty similar, right? Actually they’re from two very different cities on opposite sides of the planet. Anyone want to take a guess?
the city of Detroit has been undergoing a massive project to demolish abandoned buildings causing “blight”. They’ve done a great job! I think they’ve demolished over 14 thousand buildings, and while it’s not great that they had to do that, it’s better than the alternative. But that leads to something interesting.
places that both LOOK incomplete, but one is actually pretty complete. Unfortunately, geocoders have long had to deal with the idea of missing data. Both Pelias and Nominatim have excellent address interpolation engines, for example. How do we tell the interpolation engines that in Detroit, there’s nothing to interpolate, but in Johannesburg there is?
if you weren’t completely distracted by the beautiful mountains out the window, where he talked about Who’s on First. By the way, we use Who’s on First heavily in Pelias and it’s been an essential source of data. Aaron talks about the idea of _managing absense_. By that he meant managing lack of data, but there’s another type of absence, when we know something isn’t there. We’re lucky to be in a position to even start talking about this, but eventually we should think of something. After all, some day, the map, just like this talk, will be completely done, right? :)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}